A02、Java 设计模式优化
1、单例模式
1.1、什么是单例模式
它的核心在于,单例模式可以保证一个类仅创建一个实例,并提供一个访问它的全局访问点。该模式有三个基本要点:一是这个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。结合这三点,我们来实现一个简单的单例:
// 饿汉模式
public final class Singleton {private static Singleton instance = new Singleton(); // 自行创建实例private Singleton() {} // 构造函数public static Singleton getInstance() { // 通过该函数向整个系统提供实例return instance;}
}由于在一个系统中,一个类经常会被使用在不同的地方,通过单例模式,我们可以避免多次创建多个实例,从而节约系统资源。
1.2、饿汉模式
我们可以发现,以上第一种实现单例的代码中,使用了 static 修饰了成员变量 instance,所以该变量会在类初始化的过程中被收集进类构造器即 <clinit> 方法中。在多线程场景下,JVM 会保证只有一个线程能执行该类的 <clinit> 方法,其它线程将会被阻塞等待。
等到唯一的一次 <clinit> 方法执行完成,其它线程将不会再执行 <clinit> 方法,转而执行自己的代码。也就是说,static 修饰了成员变量 instance,在多线程的情况下能保证只实例化一次。
这种方式实现的单例模式,在类加载阶段就已经在堆内存中开辟了一块内存,用于存放实例化对象,所以也称为饿汉模式。
饿汉模式实现的单例的优点是,可以保证多线程情况下实例的唯一性,而且 getInstance 直接返回唯一实例,性能非常高。
然而,在类成员变量比较多,或变量比较大的情况下,这种模式可能会在没有使用类对象的情况下,一直占用堆内存。试想下,如果一个第三方开源框架中的类都是基于饿汉模式实现的单例,这将会初始化所有单例类,无疑是灾难性的。
1.3、懒汉模式
懒汉模式就是为了避免直接加载类对象时提前创建对象的一种单例设计模式。该模式使用懒加载方式,只有当系统使用到类对象时,才会将实例加载到堆内存中。通过以下代码,我们可以简单地了解下懒加载的实现方式:
// 懒汉模式
public final class Singleton {private static Singleton instance = null; // 不实例化private Singleton() {} // 构造函数public static Singleton getInstance() { // 通过该函数向整个系统提供实例if (null == instance) { // 当 instance 为 null 时,则实例化对象,否则直接返回对象instance = new Singleton(); // 实例化对象}return instance; // 返回已存在的对象}
}以上代码在单线程下运行是没有问题的,但要运行在多线程下,就会出现实例化多个类对象的情况。这是怎么回事呢?
当线程 A 进入到 if 判断条件后,开始实例化对象,此时 instance 依然为 null;又有线程 B 进入到 if 判断条件中,之后也会通过条件判断,进入到方法里面创建一个实例对象。
所以我们需要对该方法进行加锁,保证多线程情况下仅创建一个实例。这里我们使用 Synchronized 同步锁来修饰 getInstance 方法:
// 懒汉模式 + synchronized 同步锁
public final class Singleton {private static Singleton instance = null; // 不实例化private Singleton() {} // 构造函数public static synchronized Singleton getInstance() { // 加同步锁,通过该函数向整个系统提供实例if (null == instance) { // 当 instance 为 null 时,则实例化对象,否则直接返回对象instance = new Singleton(); // 实例化对象}return instance; // 返回已存在的对象}
}由于同步锁会增加锁竞争,带来系统性能开销,从而导致系统性能下降,因此这种方式也会降低单例模式的性能。
还有,每次请求获取类对象时,都会通过 getInstance() 方法获取,除了第一次为 null,其它每次请求基本都是不为 null 的。在没有加同步锁之前,是因为 if 判断条件为 null 时,才导致创建了多个实例。基于以上两点,我们可以考虑将同步锁放在 if 条件里面,这样就可以减少同步锁资源竞争。
// 懒汉模式 + synchronized 同步锁
public final class Singleton {private static Singleton instance= null;// 不实例化private Singleton(){}// 构造函数public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例if(null == instance){// 当 instance 为 null 时,则实例化对象,否则直接返回对象synchronized (Singleton.class){instance = new Singleton();// 实例化对象} }return instance;// 返回已存在的对象}
}看到这里,你是不是觉得这样就可以了呢?答案是依然会创建多个实例。这是因为当多个线程进入到 if 判断条件里,虽然有同步锁,但是进入到判断条件里面的线程依然会依次获取到锁创建对象,然后再释放同步锁。所以我们还需要在同步锁里面再加一个判断条件:
// 懒汉模式 + synchronized 同步锁 + double-check
public final class Singleton {private static Singleton instance= null;// 不实例化private Singleton(){}// 构造函数public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例if(null == instance){// 第一次判断,当 instance 为 null 时,则实例化对象,否则直接返回对象synchronized (Singleton.class){// 同步锁if(null == instance){// 第二次判断instance = new Singleton();// 实例化对象}} }return instance;// 返回已存在的对象}
}以上这种方式,通常被称为 Double-Check,它可以大大提高支持多线程的懒汉模式的运行性能。那这样做是不是就能保证万无一失了呢?还会有什么问题吗?
其实这里又跟 Happens-Before 规则和重排序扯上关系了,这里我们先来简单了解下 Happens-Before 规则和重排序。
编译器为了尽可能地减少寄存器的读取、存储次数,会充分复用寄存器的存储值,比如以下代码,如果没有进行重排序优化,正常的执行顺序是步骤 1\2\3,而在编译期间进行了重排序优化之后,执行的步骤有可能就变成了步骤 1/3/2,这样就能减少一次寄存器的存取次数。
int a = 1;// 步骤 1:加载 a 变量的内存地址到寄存器中,加载 1 到寄存器中,CPU 通过 mov 指令把 1 写入到寄存器指定的内存中
int b = 2;// 步骤 2 加载 b 变量的内存地址到寄存器中,加载 2 到寄存器中,CPU 通过 mov 指令把 2 写入到寄存器指定的内存中
a = a + 1;// 步骤 3 重新加载 a 变量的内存地址到寄存器中,加载 1 到寄存器中,CPU 通过 mov 指令把 1 写入到寄存器指定的内存中在 JMM 中,重排序是十分重要的一环,特别是在并发编程中。如果 JVM 可以对它们进行任意排序以提高程序性能,也可能会给并发编程带来一系列的问题。例如,我上面讲到的 Double-Check 的单例问题,假设类中有其它的属性也需要实例化,这个时候,除了要实例化单例类本身,还需要对其它属性也进行实例化:
// 懒汉模式 + synchronized 同步锁 + double-check
public final class Singleton {private static Singleton instance= null;// 不实例化public List<String> list = null;//list 属性private Singleton(){list = new ArrayList<String>();}// 构造函数public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例if(null == instance){// 第一次判断,当 instance 为 null 时,则实例化对象,否则直接返回对象synchronized (Singleton.class){// 同步锁if(null == instance){// 第二次判断instance = new Singleton();// 实例化对象}} }return instance;// 返回已存在的对象}
}在执行 instance = new Singleton(); 代码时,正常情况下,实例过程这样的:
- 给 Singleton 分配内存;
- 调用 Singleton 的构造函数来初始化成员变量;
- 将 Singleton 对象指向分配的内存空间(执行完这步 singleton 就为非 null 了)。
如果虚拟机发生了重排序优化,这个时候步骤 3 可能发生在步骤 2 之前。如果初始化线程刚好完成步骤 3,而步骤 2 没有进行时,则刚好有另一个线程到了第一次判断,这个时候判断为非 null,并返回对象使用,这个时候实际没有完成其它属性的构造,因此使用这个属性就很可能会导致异常。在这里,Synchronized 只能保证可见性、原子性,无法保证执行的顺序。
这个时候,就体现出 Happens-Before 规则的重要性了。通过字面意思,你可能会误以为是前一个操作发生在后一个操作之前。然而真正的意思是,前一个操作的结果可以被后续的操作获取。这条规则规范了编译器对程序的重排序优化。
我们知道 volatile 关键字可以保证线程间变量的可见性,简单地说就是当线程 A 对变量 X 进行修改后,在线程 A 后面执行的其它线程就能看到变量 X 的变动。除此之外,volatile 在 JDK1.5 之后还有一个作用就是阻止局部重排序的发生,也就是说,volatile 变量的操作指令都不会被重排序。所以使用 volatile 修饰 instance 之后,Double-Check 懒汉单例模式就万无一失了。
// 懒汉模式 + synchronized 同步锁 + double-check
public final class Singleton {private volatile static Singleton instance= null;// 不实例化public List<String> list = null;//list 属性private Singleton(){list = new ArrayList<String>();}// 构造函数public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例if(null == instance){// 第一次判断,当 instance 为 null 时,则实例化对象,否则直接返回对象synchronized (Singleton.class){// 同步锁if(null == instance){// 第二次判断instance = new Singleton();// 实例化对象}} }return instance;// 返回已存在的对象}
}1.4、通过内部类实现
以上这种同步锁 +Double-Check 的实现方式相对来说,复杂且加了同步锁,那有没有稍微简单一点儿的可以实现线程安全的懒加载方式呢?
我们知道,在饿汉模式中,我们使用了 static 修饰了成员变量 instance,所以该变量会在类初始化的过程中被收集进类构造器即 <clinit> 方法中。在多线程场景下,JVM 会保证只有一个线程能执行该类的 <clinit> 方法,其它线程将会被阻塞等待。这种方式可以保证内存的可见性、顺序性以及原子性。
如果我们在 Singleton 类中创建一个内部类来实现成员变量的初始化,则可以避免多线程下重复创建对象的情况发生。这种方式,只有在第一次调用 getInstance() 方法时,才会加载 InnerSingleton 类,而只有在加载 InnerSingleton 类之后,才会实例化创建对象。具体实现如下:
// 懒汉模式 内部类实现
public final class Singleton {public List<String> list = null;// list 属性private Singleton() {// 构造函数list = new ArrayList<String>();}// 内部类实现public static class InnerSingleton {private static Singleton instance=new Singleton();// 自行创建实例}public static Singleton getInstance() {return InnerSingleton.instance;// 返回内部类中的静态变量}
}2、原型模式与享元模式
2.1、原型模式
2.1.1、什么是原型模式
原型模式是通过给出一个原型对象来指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象,该模式就是用这种方式来创建出更多同类型的对象。
使用这种方式创建新的对象的话,就无需再通过 new 实例化来创建对象了。这是因为 Object 类的 clone 方法是一个本地方法,它可以直接操作内存中的二进制流,所以性能相对 new 实例化来说,更佳。
2.1.2、原型模式实现
// 实现 Cloneable 接口的原型抽象类 Prototype class Prototype implements Cloneable {// 重写 clone 方法public Prototype clone(){Prototype prototype = null;try{prototype = (Prototype)super.clone();}catch(CloneNotSupportedException e){e.printStackTrace();}return prototype;}}// 实现原型类class ConcretePrototype extends Prototype{public void show(){System.out.println(" 原型模式实现类 ");}}public class Client {public static void main(String[] args){ConcretePrototype cp = new ConcretePrototype();for(int i=0; i< 10; i++){ConcretePrototype clonecp = (ConcretePrototype)cp.clone();clonecp.show();}}}要实现一个原型类,需要具备三个条件:
- 实现 Cloneable 接口:Cloneable 接口与序列化接口的作用类似,它只是告诉虚拟机可以安全地在实现了这个接口的类上使用 clone 方法。在 JVM 中,只有实现了 Cloneable 接口的类才可以被拷贝,否则会抛出 CloneNotSupportedException 异常。
- 重写 Object 类中的 clone 方法:在 Java 中,所有类的父类都是 Object 类,而 Object 类中有一个 clone 方法,作用是返回对象的一个拷贝。
- 在重写的 clone 方法中调用 super.clone():默认情况下,类不具备复制对象的能力,需要调用 super.clone() 来实现。
从上面我们可以看出,原型模式的主要特征就是使用 clone 方法复制一个对象。通常,有些人会误以为 Object a=new Object();Object b=a; 这种形式就是一种对象复制的过程,然而这种复制只是对象引用的复制,也就是 a 和 b 对象指向了同一个内存地址,如果 b 修改了,a 的值也就跟着被修改了。我们可以通过一个简单的例子来看看普通的对象复制问题:
class Student { private String name; public String getName() { return name; } public void setName(String name) { this.name= name; } }
public class Test { public static void main(String args[]) { Student stu1 = new Student(); stu1.setName("test1"); Student stu2 = stu1; stu1.setName("test2"); System.out.println(" 学生 1:" + stu1.getName()); System.out.println(" 学生 2:" + stu2.getName()); }
}如果是复制对象,此时打印的日志应该为:
学生 1:test1
学生 2:test2然而,实际上是:
学生 2:test2
学生 2:test2通过 clone 方法复制的对象才是真正的对象复制,clone 方法赋值的对象完全是一个独立的对象。刚刚讲过了,Object 类的 clone 方法是一个本地方法,它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。我们可以用 clone 方法再实现一遍以上例子。
// 学生类实现 Cloneable 接口
class Student implements Cloneable{ private String name; // 姓名public String getName() { return name; } public void setName(String name) { this.name= name; } // 重写 clone 方法public Student clone() { Student student = null; try { student = (Student) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } }
public class Test { public static void main(String args[]) { Student stu1 = new Student(); // 创建学生 1stu1.setName("test1"); Student stu2 = stu1.clone(); // 通过克隆创建学生 2stu2.setName("test2"); System.out.println(" 学生 1:" + stu1.getName()); System.out.println(" 学生 2:" + stu2.getName()); }
}//运行结果:
学生 1:test1
学生 2:test2
2.1.3、深拷贝和浅拷贝
在调用 super.clone() 方法之后,首先会检查当前对象所属的类是否支持 clone,也就是看该类是否实现了 Cloneable 接口。
如果支持,则创建当前对象所属类的一个新对象,并对该对象进行初始化,使得新对象的成员变量的值与当前对象的成员变量的值一模一样,但对于其它对象的引用以及 List 等类型的成员属性,则只能复制这些对象的引用了。所以简单调用 super.clone() 这种克隆对象方式,就是一种浅拷贝。
所以,当我们在使用 clone() 方法实现对象的克隆时,就需要注意浅拷贝带来的问题。我们再通过一个例子来看看浅拷贝。
// 定义学生类
class Student implements Cloneable{ private String name; // 学生姓名private Teacher teacher; // 定义老师类public String getName() { return name; } public void setName(String name) { this.name = name; } public Teacher getTeacher() { return teacher; } public void setName(Teacher teacher) { this.teacher = teacher; } // 重写克隆方法public Student clone() { Student student = null; try { student = (Student) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } } // 定义老师类
class Teacher implements Cloneable{ private String name; // 老师姓名public String getName() { return name; } public void setName(String name) { this.name= name; } // 重写克隆方法,堆老师类进行克隆public Teacher clone() { Teacher teacher= null; try { teacher= (Teacher) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } }
public class Test { public static void main(String args[]) {Teacher teacher = new Teacher (); // 定义老师 1teacher.setName(" 刘老师 ");Student stu1 = new Student(); // 定义学生 1stu1.setName("test1"); stu1.setTeacher(teacher);Student stu2 = stu1.clone(); // 定义学生 2stu2.setName("test2"); stu2.getTeacher().setName(" 王老师 ");// 修改老师System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu1.getTeacher().getName); System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu2.getTeacher().getName); }
}//运行结果:
学生 test1 的老师是:王老师
学生 test2 的老师是:王老师
观察以上运行结果,我们可以发现:在我们给学生 2 修改老师的时候,学生 1 的老师也跟着被修改了。这就是浅拷贝带来的问题。
我们可以通过深拷贝来解决这种问题,其实深拷贝就是基于浅拷贝来递归实现具体的每个对象,代码如下:
public Student clone() {Student student = null;try {student = (Student) super.clone();Teacher teacher = this.teacher.clone(); // 克隆 teacher 对象student.setTeacher(teacher);} catch (CloneNotSupportedException e) {e.printStackTrace();}return student;
}适用场景
在一些重复创建对象的场景下,我们就可以使用原型模式来提高对象的创建性能。例如,我在开头提到的,循环体内创建对象时,我们就可以考虑用 clone 的方式来实现。例如:
for(int i=0; i<list.size(); i++){Student stu = new Student(); //...
}//优化后
Student stu = new Student();
for(int i=0; i<list.size(); i++){Student stu1 = (Student)stu.clone();//...
}除此之外,原型模式在开源框架中的应用也非常广泛。例如 Spring 中,@Service 默认都是单例的。用了私有全局变量,若不想影响下次注入或每次上下文获取 bean,就需要用到原型模式,我们可以通过以下注解来实现,@Scope(“prototype”)。
2.2、享元模式
享元模式是运用共享技术有效地最大限度地复用细粒度对象的一种模式。该模式中,以对象的信息状态划分,可以分为内部数据和外部数据。内部数据是对象可以共享出来的信息,这些信息不会随着系统的运行而改变;外部数据则是在不同运行时被标记了不同的值。
享元模式一般可以分为三个角色,分别为 Flyweight(抽象享元类)、ConcreteFlyweight(具体享元类)和 FlyweightFactory(享元工厂类)。抽象享元类通常是一个接口或抽象类,向外界提供享元对象的内部数据或外部数据;具体享元类是指具体实现内部数据共享的类;享元工厂类则是主要用于创建和管理享元对象的工厂类。
实现享元模式
// 抽象享元类
interface Flyweight {// 对外状态对象void operation(String name);// 对内对象String getType();
}// 具体享元类
class ConcreteFlyweight implements Flyweight {private String type;public ConcreteFlyweight(String type) {this.type = type;}@Overridepublic void operation(String name) {System.out.printf("[类型 (内在状态)] - [%s] - [名字 (外在状态)] - [%s]\n", type, name);}@Overridepublic String getType() {return type;}
}// 享元工厂类
class FlyweightFactory {private static final Map<String, Flyweight> FLYWEIGHT_MAP = new HashMap<>();// 享元池,用来存储享元对象public static Flyweight getFlyweight(String type) {if (FLYWEIGHT_MAP.containsKey(type)) {// 如果在享元池中存在对象,则直接获取return FLYWEIGHT_MAP.get(type);} else {// 在响应池不存在,则新创建对象,并放入到享元池ConcreteFlyweight flyweight = new ConcreteFlyweight(type);FLYWEIGHT_MAP.put(type, flyweight);return flyweight;}}
}public class Client {public static void main(String[] args) {Flyweight fw0 = FlyweightFactory.getFlyweight("a");Flyweight fw1 = FlyweightFactory.getFlyweight("b");Flyweight fw2 = FlyweightFactory.getFlyweight("a");Flyweight fw3 = FlyweightFactory.getFlyweight("b");fw1.operation("abc");System.out.printf("[结果 (对象对比)] - [%s]\n", fw0 == fw2);System.out.printf("[结果 (内在状态)] - [%s]\n", fw1.getType());}
}执行输出结果:
[类型 (内在状态)] - [b] - [名字 (外在状态)] - [abc]
[结果 (对象对比)] - [true]
[结果 (内在状态)] - [b]观察以上代码运行结果,我们可以发现:如果对象已经存在于享元池中,则不会再创建该对象了,而是共用享元池中内部数据一致的对象。这样就减少了对象的创建,同时也节省了同样内部数据的对象所占用的内存空间。
适用场景:
享元模式在实际开发中的应用也非常广泛。例如 Java 的 String 字符串,在一些字符串常量中,会共享常量池中字符串对象,从而减少重复创建相同值对象,占用内存空间。代码如下:
String s1 = "hello";String s2 = "hello";System.out.println(s1==s2);//true还有,在日常开发中的应用。例如,线程池就是享元模式的一种实现;将商品存储在应用服务的缓存中,那么每当用户获取商品信息时,则不需要每次都从 redis 缓存或者数据库中获取商品信息,并在内存中重复创建商品信息了。
3、优化并发编程
3.1、线程上下文设计模式
线程上下文是指贯穿线程整个生命周期的对象中的一些全局信息。例如,我们比较熟悉的 Spring 中的 ApplicationContext 就是一个关于上下文的类,它在整个系统的生命周期中保存了配置信息、用户信息以及注册的 bean 等上下文信息。
在执行一个比较长的请求任务时,这个请求可能会经历很多层的方法调用,假设我们需要将最开始的方法的中间结果传递到末尾的方法中进行计算,一个简单的实现方式就是在每个函数中新增这个中间结果的参数,依次传递下去。代码如下:
public class ContextTest {// 上下文类public class Context {private String name;private long idpublic long getId() {return id;}public void setId(long id) {this.id = id;}public String getName() {return this.name;}public void setName(String name) {this.name = name;}}// 设置上下文名字public class QueryNameAction {public void execute(Context context) {try {Thread.sleep(1000L);String name = Thread.currentThread().getName();context.setName(name);} catch (InterruptedException e) {e.printStackTrace();}}}// 设置上下文 IDpublic class QueryIdAction {public void execute(Context context) {try {Thread.sleep(1000L);long id = Thread.currentThread().getId();context.setId(id);} catch (InterruptedException e) {e.printStackTrace();}}}// 执行方法public class ExecutionTask implements Runnable {private QueryNameAction queryNameAction = new QueryNameAction();private QueryIdAction queryIdAction = new QueryIdAction();@Overridepublic void run() {final Context context = new Context();queryNameAction.execute(context);System.out.println("The name query successful");queryIdAction.execute(context);System.out.println("The id query successful");System.out.println("The Name is " + context.getName() + " and id " + context.getId());}}public static void main(String[] args) {IntStream.range(1, 5).forEach(i -> new Thread(new ContextTest().new ExecutionTask()).start());}
}执行结果输出:
The name query successful
The name query successful
The name query successful
The name query successful
The id query successful
The id query successful
The id query successful
The id query successful
The Name is Thread-1 and id 11
The Name is Thread-2 and id 12
The Name is Thread-3 and id 13
The Name is Thread-0 and id 10然而这种方式太笨拙了,每次调用方法时,都需要传入 Context 作为参数,而且影响一些中间公共方法的封装。
除了以上这些方法,其实我们还可以使用 ThreadLocal 实现上下文。ThreadLocal 是线程本地变量,可以实现多线程的数据隔离。ThreadLocal 为每一个使用该变量的线程都提供一份独立的副本,线程间的数据是隔离的,每一个线程只能访问各自内部的副本变量。
ThreadLocal 中有三个常用的方法:set、get、initialValue,我们可以通过以下一个简单的例子来看看 ThreadLocal 的使用:
private void testThreadLocal() {Thread t = new Thread() {ThreadLocal<String> mStringThreadLocal = new ThreadLocal<String>();@Overridepublic void run() {super.run();mStringThreadLocal.set("test");mStringThreadLocal.get();}};t.start();
}接下来,我们使用 ThreadLocal 来重新实现最开始的上下文设计。你会发现,我们在两个方法中并没有通过变量来传递上下文,只是通过 ThreadLocal 获取了当前线程的上下文信息:
public class ContextTest {// 上下文类public static class Context {private String name;private long id;public long getId() {return id;}public void setId(long id) {this.id = id;}public String getName() {return this.name;}public void setName(String name) {this.name = name;}}// 复制上下文到 ThreadLocal 中public final static class ActionContext {private static final ThreadLocal<Context> threadLocal = new ThreadLocal<Context>() {@Overrideprotected Context initialValue() {return new Context();}};public static ActionContext getActionContext() {return ContextHolder.actionContext;}public Context getContext() {return threadLocal.get();}// 获取 ActionContext 单例public static class ContextHolder {private final static ActionContext actionContext = new ActionContext();}}// 设置上下文名字public class QueryNameAction {public void execute() {try {Thread.sleep(1000L);String name = Thread.currentThread().getName();ActionContext.getActionContext().getContext().setName(name);} catch (InterruptedException e) {e.printStackTrace();}}}// 设置上下文 IDpublic class QueryIdAction {public void execute() {try {Thread.sleep(1000L);long id = Thread.currentThread().getId();ActionContext.getActionContext().getContext().setId(id);} catch (InterruptedException e) {e.printStackTrace();}}}// 执行方法public class ExecutionTask implements Runnable {private QueryNameAction queryNameAction = new QueryNameAction();private QueryIdAction queryIdAction = new QueryIdAction();@Overridepublic void run() {queryNameAction.execute();// 设置线程名System.out.println("The name query successful");queryIdAction.execute();// 设置线程 IDSystem.out.println("The id query successful");System.out.println("The Name is " + ActionContext.getActionContext().getContext().getName() + " and id " + ActionContext.getActionContext().getContext().getId())}}public static void main(String[] args) {IntStream.range(1, 5).forEach(i -> new Thread(new ContextTest().new ExecutionTask()).start());}
}执行结果输出:
The name query successful
The name query successful
The name query successful
The name query successful
The id query successful
The id query successful
The id query successful
The id query successful
The Name is Thread-2 and id 12
The Name is Thread-0 and id 10
The Name is Thread-1 and id 11
The Name is Thread-3 and id 13
3.2、Thread-Per-Message 设计模式
Thread-Per-Message 设计模式翻译过来的意思就是每个消息一个线程的意思。例如,我们在处理 Socket 通信的时候,通常是一个线程处理事件监听以及 I/O 读写,如果 I/O 读写操作非常耗时,这个时候便会影响到事件监听处理事件。
这个时候 Thread-Per-Message 模式就可以很好地解决这个问题,一个线程监听 I/O 事件,每当监听到一个 I/O 事件,则交给另一个处理线程执行 I/O 操作。下面,我们还是通过一个例子来学习下该设计模式的实现。
//IO 处理
public class ServerHandler implements Runnable{private Socket socket;public ServerHandler(Socket socket) {this.socket = socket;}public void run() {BufferedReader in = null;PrintWriter out = null;String msg = null;try {in = new BufferedReader(new InputStreamReader(socket.getInputStream()));out = new PrintWriter(socket.getOutputStream(),true);while ((msg = in.readLine()) != null && msg.length()!=0) {// 当连接成功后在此等待接收消息(挂起,进入阻塞状态)System.out.println("server received : " + msg);out.print("received~\n");out.flush();}} catch (Exception e) {e.printStackTrace();} finally {try {in.close();} catch (IOException e) {e.printStackTrace();}try {out.close();} catch (Exception e) {e.printStackTrace();}try {socket.close();} catch (IOException e) {e.printStackTrace();}}}
}//Socket 启动服务
public class Server {private static int DEFAULT_PORT = 12345;private static ServerSocket server;public static void start() throws IOException {start(DEFAULT_PORT);}public static void start(int port) throws IOException {if (server != null) {return;}try {// 启动服务server = new ServerSocket(port);// 通过无线循环监听客户端连接while (true) {Socket socket = server.accept();// 当有新的客户端接入时,会执行下面的代码long start = System.currentTimeMillis();new Thread(new ServerHandler(socket)).start();long end = System.currentTimeMillis();System.out.println("Spend time is " + (end - start));}} finally {if (server != null) {System.out.println(" 服务器已关闭。");server.close();}}}public static void main(String[] args) throws InterruptedException{// 运行服务端new Thread(new Runnable() {public void run() {try {Server.start();} catch (IOException e) {e.printStackTrace();}}}).start();}
}使用这种设计模式,如果遇到大的高并发,就会出现严重的性能问题。如果针对每个 I/O 请求都创建一个线程来处理,在有大量请求同时进来时,就会创建大量线程,而此时 JVM 有可能会因为无法处理这么多线程,而出现内存溢出的问题。
面对这种情况,我们可以使用线程池来代替线程的创建和销毁,这样就可以避免创建大量线程而带来的性能问题,是一种很好的调优方法。
3.3、Worker-Thread 设计模式
这里的 Worker 是工人的意思,代表在 Worker Thread 设计模式中,会有一些工人(线程)不断轮流处理过来的工作,当没有工作时,工人则会处于等待状态,直到有新的工作进来。除了工人角色,Worker Thread 设计模式中还包括了流水线和产品。
这种设计模式相比 Thread-Per-Message 设计模式,可以减少频繁创建、销毁线程所带来的性能开销,还有无限制地创建线程所带来的内存溢出风险。
我们可以假设一个场景来看下该模式的实现,通过 Worker Thread 设计模式来完成一个物流分拣的作业。
假设一个物流仓库的物流分拣流水线上有 8 个机器人,它们不断从流水线上获取包裹并对其进行包装,送其上车。当仓库中的商品被打包好后,会投放到物流分拣流水线上,而不是直接交给机器人,机器人会再从流水线中随机分拣包裹。代码如下:
// 包裹类
public class Package {private String name;private String address;public String getName() {return name;}public void setName(String name) {this.name = name;}public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}public void execute() {System.out.println(Thread.currentThread().getName()+" executed "+this);}
}// 流水线
public class PackageChannel {private final static int MAX_PACKAGE_NUM = 100;private final Package[] packageQueue;private final Worker[] workerPool;private int head;private int tail;private int count;public PackageChannel(int workers) {this.packageQueue = new Package[MAX_PACKAGE_NUM];this.head = 0;this.tail = 0;this.count = 0;this.workerPool = new Worker[workers];this.init();}private void init() {for (int i = 0; i < workerPool.length; i++) {workerPool[i] = new Worker("Worker-" + i, this);}}/*** push switch to start all of worker to work*/public void startWorker() {Arrays.asList(workerPool).forEach(Worker::start);}public synchronized void put(Package packagereq) {while (count >= packageQueue.length) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}this.packageQueue[tail] = packagereq;this.tail = (tail + 1) % packageQueue.length;this.count++;this.notifyAll();}public synchronized Package take() {while (count <= 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}Package request = this.packageQueue[head];this.head = (this.head + 1) % this.packageQueue.length;this.count--;this.notifyAll();return request;}}// 机器人
public class Worker extends Thread{private static final Random random = new Random(System.currentTimeMillis());private final PackageChannel channel;public Worker(String name, PackageChannel channel) {super(name);this.channel = channel;}@Overridepublic void run() {while (true) {channel.take().execute();try {Thread.sleep(random.nextInt(1000));} catch (InterruptedException e) {e.printStackTrace();}}}}public class Test {public static void main(String[] args) {// 新建 8 个工人final PackageChannel channel = new PackageChannel(8);// 开始工作channel.startWorker();// 为流水线添加包裹for(int i=0; i<100; i++) {Package packagereq = new Package();packagereq.setAddress("test");packagereq.setName("test");channel.put(packagereq);}}
}4、电商库存设计优化
4.1、生产消费
4.1.1、Lock 中 Condition 的 await/signal/signalAll
相对 Object 类提供的 wait/notify/notifyAll 方法实现的生产者消费者模式,我更推荐使用 java.util.concurrent 包提供的 Lock && Condition 实现的生产者消费者模式。
在接口 Condition 类中定义了 await/signal/signalAll 方法,其作用与 Object 的 wait/notify/notifyAll 方法类似,该接口类与显示锁 Lock 配合,实现对线程的阻塞和唤醒操作。
显示锁 ReentrantLock 或 ReentrantReadWriteLock 都是基于 AQS 实现的,而在 AQS 中有一个内部类 ConditionObject 实现了 Condition 接口。我们知道 AQS 中存在一个同步队列(CLH 队列),当一个线程没有获取到锁时就会进入到同步队列中进行阻塞,如果被唤醒后获取到锁,则移除同步队列。
除此之外,AQS 中还存在一个条件队列,通过 addWaiter 方法,可以将 await() 方法调用的线程放入到条件队列中,线程进入等待状态。当调用 signal 以及 signalAll 方法后,线程将会被唤醒,并从条件队列中删除,之后进入到同步队列中。条件队列是通过一个单向链表实现的,所以 Condition 支持多个等待队列。
由上可知,Lock 中 Condition 的 await/signal/signalAll 实现的生产者消费者模式,是基于 Java 代码层实现的,所以在性能和扩展性方面都更有优势。下面来看一个案例,我们通过一段代码来实现一个商品库存的生产和消费。
public class LockConditionTest {private LinkedList<String> product = new LinkedList<String>();private int maxInventory = 10; // 最大库存private Lock lock = new ReentrantLock();// 资源锁private Condition condition = lock.newCondition();// 库存非满和非空条件/*** 新增商品库存* @param e*/public void produce(String e) {lock.lock();try {while (product.size() == maxInventory) {condition.await();}product.add(e);System.out.println(" 放入一个商品库存,总库存为:" + product.size());condition.signalAll();} catch (Exception ex) {ex.printStackTrace();} finally {lock.unlock();}}/*** 消费商品* @return*/public String consume() {String result = null;lock.lock();try {while (product.size() == 0) {condition.await();}result = product.removeLast();System.out.println(" 消费一个商品,总库存为:" + product.size());condition.signalAll();} catch (Exception e) {e.printStackTrace();} finally {lock.unlock();}return result;}/*** 生产者* @author admin**/private class Producer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {produce(" 商品 " + i);}}}/*** 消费者* @author admin**/private class Customer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {consume();}}}public static void main(String[] args) {LockConditionTest lc = new LockConditionTest();new Thread(lc.new Producer()).start();new Thread(lc.new Customer()).start();new Thread(lc.new Producer()).start();new Thread(lc.new Customer()).start();}
}从代码中应该不难发现,生产者和消费者都在竞争同一把锁,而实际上两者没有同步关系,由于 Condition 能够支持多个等待队列以及不响应中断, 所以我们可以将生产者和消费者的等待条件和锁资源分离,从而进一步优化系统并发性能,代码如下:
/*** @Author: blnp 2045165565@qq.com* @Date: 2024-11-25 23:03:11* @LastEditors: blnp 2045165565@qq.com* @LastEditTime: 2024-11-25 23:10:12* @FilePath: src/main/java/com/blnp/demos/muilty/LockConditionTest.java* @Description: 这是默认设置, 可以在设置》工具》File Description中进行配置*/
package com.blnp.demos.muilty;import java.util.LinkedList;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;/*** <p></p>** @author lyb 2045165565@qq.com* @version 1.0* @since 2024/11/25/025 23:03*/
public class LockConditionTest {private LinkedList<String> product = new LinkedList<String>();// 实时库存private AtomicInteger inventory = new AtomicInteger(0);// 最大库存private int maxInventory = 10;// 资源锁private Lock consumerLock = new ReentrantLock();// 资源锁private Lock productLock = new ReentrantLock();// 库存满和空条件private Condition notEmptyCondition = consumerLock.newCondition();// 库存满和空条件private Condition notFullCondition = productLock.newCondition();/*** 用途:生产库存商品* @author liaoyibin* @since 23:07 2024/11/25/025* @params [e] * @param e * @return void**/public void produce(String e) {productLock.lock();try {while (inventory.get() == maxInventory) {notFullCondition.await();}product.add(e);System.out.println(" 放入一个商品库存,总库存为:" + inventory.incrementAndGet());if(inventory.get()<maxInventory) {notFullCondition.signalAll();}} catch (Exception ex) {ex.printStackTrace();} finally {productLock.unlock();}if(inventory.get()>0) {try {consumerLock.lockInterruptibly();notEmptyCondition.signalAll();} catch (InterruptedException e1) {// TODO Auto-generated catch blocke1.printStackTrace();}finally {consumerLock.unlock();}}}/*** 用途:消费商品* @author liaoyibin* @since 23:08 2024/11/25/025* @params [] * @param * @return java.lang.String**/public String consume() {String result = null;consumerLock.lock();try {while (inventory.get() == 0) {notEmptyCondition.await();}result = product.removeLast();System.out.println(" 消费一个商品,总库存为:" + inventory.decrementAndGet());if(inventory.get()>0) {notEmptyCondition.signalAll();}} catch (Exception e) {e.printStackTrace();} finally {consumerLock.unlock();}if(inventory.get()<maxInventory) {try {productLock.lockInterruptibly();notFullCondition.signalAll();} catch (InterruptedException e1) {// TODO Auto-generated catch blocke1.printStackTrace();}finally {productLock.unlock();}}return result;}/*** 用途:生产者* @author liaoyibin* @since 23:09 2024/11/25/025* @params * @return **/private class Producer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {produce(" 商品 " + i);}}}private class Customer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {consume();}}}public static void main(String[] args) {LockConditionTest lc = new LockConditionTest();new Thread(lc.new Producer()).start();new Thread(lc.new Customer()).start();}
}

我们分别创建 productLock 以及 consumerLock 两个锁资源,前者控制生产者线程并行操作,后者控制消费者线程并发运行;同时也设置两个条件变量,一个是notEmptyCondition,负责控制消费者线程状态,一个是 notFullCondition,负责控制生产者线程状态。这样优化后,可以减少消费者与生产者的竞争,实现两者并发执行。
我们这里是基于 LinkedList 来存取库存的,虽然 LinkedList 是非线程安全,但我们新增是操作头部,而消费是操作队列的尾部,理论上来说没有线程安全问题。而库存的实际数量 inventory 是基于 AtomicInteger(CAS 锁)线程安全类实现的,既可以保证原子性,也可以保证消费者和生产者之间是可见的。
4.1.2、BlockingQueue
相对前两种实现方式,BlockingQueue 实现是最简单明了的,也是最容易理解的。
因为 BlockingQueue 是线程安全的,且从队列中获取或者移除元素时,如果队列为空,获取或移除操作则需要等待,直到队列不为空;同时,如果向队列中添加元素,假设此时队列无可用空间,添加操作也需要等待。所以 BlockingQueue 非常适合用来实现生产者消费者模式。还是以一个案例来看下它的优化,代码如下:
public class BlockingQueueTest {private int maxInventory = 10; // 最大库存private BlockingQueue<String> product = new LinkedBlockingQueue<>(maxInventory);// 缓存队列/*** 新增商品库存* @param e*/public void produce(String e) {try {product.put(e);System.out.println(" 放入一个商品库存,总库存为:" + product.size());} catch (InterruptedException e1) {// TODO Auto-generated catch blocke1.printStackTrace();}}/*** 消费商品* @return*/public String consume() {String result = null;try {result = product.take();System.out.println(" 消费一个商品,总库存为:" + product.size());} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}return result;}/*** 生产者* @author admin**/private class Producer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {produce(" 商品 " + i);}}}/*** 消费者* @author admin**/private class Customer implements Runnable {public void run() {for (int i = 0; i < 20; i++) {consume();}}}public static void main(String[] args) {BlockingQueueTest lc = new BlockingQueueTest();new Thread(lc.new Producer()).start();new Thread(lc.new Customer()).start();new Thread(lc.new Producer()).start();new Thread(lc.new Customer()).start();}
}在这个案例中,我们创建了一个 LinkedBlockingQueue,并设置队列大小。之后我们创建一个消费方法 consume(),方法里面调用 LinkedBlockingQueue 中的 take() 方法,消费者通过该方法获取商品,当队列中商品数量为零时,消费者将进入等待状态;我们再创建一个生产方法 produce(),方法里面调用 LinkedBlockingQueue 中的 put() 方法,生产方通过该方法往队列中放商品,如果队列满了,生产者就将进入等待状态。
4.2、电商库存的设计
电商系统中经常会有抢购活动,在这类促销活动中,抢购商品的库存实际是存在库存表中的。为了提高抢购性能,我们通常会将库存存放在缓存中,通过缓存中的库存来实现库存的精确扣减。在提交订单并付款之后,我们还需要再去扣除数据库中的库存。如果遇到瞬时高并发,我们还都去操作数据库的话,那么在单表单库的情况下,数据库就很可能会出现性能瓶颈。
而我们库存表如果要实现分库分表,势必会增加业务的复杂度。试想一个商品的库存分别在不同库的表中,我们在扣除库存时,又该如何判断去哪个库中扣除呢?
如果随意扣除表中库存,那么就会出现有些表已经扣完了,有些表中还有库存的情况,这样的操作显然是不合理的,此时就需要额外增加逻辑判断来解决问题。
在不分库分表的情况下,为了提高订单中扣除库存业务的性能以及吞吐量,我们就可以采用生产者消费者模式来实现系统的性能优化。
创建订单等于生产者,存放订单的队列则是缓冲容器,而从队列中消费订单则是数据库扣除库存操作。其中存放订单的队列可以极大限度地缓冲高并发给数据库带来的压力。
5、装饰器模式
5.1、什么是装饰器模式
装饰器模式包括了以下几个角色:接口、具体对象、装饰类、具体装饰类。
接口定义了具体对象的一些实现方法;具体对象定义了一些初始化操作,比如开头设计装修功能的案例中,水电装修、天花板以及粉刷墙等都是初始化操作;装饰类则是一个抽象类,主要用来初始化具体对象的一个类;其它的具体装饰类都继承了该抽象类。下面我们就通过装饰器模式来实现下装修功能,代码如下:
/*** 定义一个基本装修接口* @author admin**/
public interface IDecorator {/*** 装修方法*/void decorate();}/*** 装修基本类* @author admin**/
public class Decorator implements IDecorator{/*** 基本实现方法*/public void decorate() {System.out.println(" 水电装修、天花板以及粉刷墙。。。");}}/*** 基本装饰类* @author admin**/
public abstract class BaseDecorator implements IDecorator{private IDecorator decorator;public BaseDecorator(IDecorator decorator) {this.decorator = decorator;}/*** 调用装饰方法*/public void decorate() {if(decorator != null) {decorator.decorate();}}
}/*** 窗帘装饰类* @author admin**/
public class CurtainDecorator extends BaseDecorator{public CurtainDecorator(IDecorator decorator) {super(decorator);}/*** 窗帘具体装饰方法*/@Overridepublic void decorate() {System.out.println(" 窗帘装饰。。。");super.decorate();}}public static void main( String[] args ){IDecorator decorator = new Decorator();IDecorator curtainDecorator = new CurtainDecorator(decorator);curtainDecorator.decorate();}//运行结果:
//窗帘装饰。。。
//水电装修、天花板以及粉刷墙。。。通过这个案例,我们可以了解到:如果我们想要在基础类上添加新的装修功能,只需要基于抽象类 BaseDecorator 去实现继承类,通过构造函数调用父类,以及重写装修方法实现装修窗帘的功能即可。在 main 函数中,我们通过实例化装饰类,调用装修方法,即可在基础装修的前提下,获得窗帘装修功能。
5.2、如何优化
相信你一定不陌生,购买商品时经常会用到的限时折扣、红包、抵扣券以及特殊抵扣金等,种类很多,如果换到开发视角,实现起来就更复杂了。
例如,每逢双十一,为了加大商城的优惠力度,开发往往要设计红包 + 限时折扣或红包 + 抵扣券等组合来实现多重优惠。而在平时,由于某些特殊原因,商家还会赠送特殊抵扣券给购买用户,而特殊抵扣券 + 各种优惠又是另一种组合方式。
要实现以上这类组合优惠的功能,最快、最普遍的实现方式就是通过大量 if-else 的方式来实现。但这种方式包含了大量的逻辑判断,致使其他开发人员很难读懂业务, 并且一旦有新的优惠策略或者价格组合策略出现,就需要修改代码逻辑。
这时,刚刚介绍的装饰器模式就很适合用在这里,其相互独立、自由组合以及方便动态扩展功能的特性,可以很好地解决 if-else 方式的弊端。下面我们就用装饰器模式动手实现一套商品价格策略的优化方案。
首先,我们先建立订单和商品的属性类,在本次案例中,为了保证简洁性,我只建立了几个关键字段。以下几个重要属性关系为,主订单包含若干详细订单,详细订单中记录了商品信息,商品信息中包含了促销类型信息,一个商品可以包含多个促销类型(本案例只讨论单个促销和组合促销):
/*** 主订单* @author admin**/
public class Order {private int id; // 订单 IDprivate String orderNo; // 订单号private BigDecimal totalPayMoney; // 总支付金额private List<OrderDetail> list; // 详细订单列表
}/*** 详细订单* @author admin**/
public class OrderDetail {private int id; // 详细订单 IDprivate int orderId;// 主订单 IDprivate Merchandise merchandise; // 商品详情private BigDecimal payMoney; // 支付单价
}/*** 商品* @author admin**/
public class Merchandise {private String sku;// 商品 SKUprivate String name; // 商品名称private BigDecimal price; // 商品单价private Map<PromotionType, SupportPromotions> supportPromotions; // 支持促销类型
}/*** 促销类型* @author admin**/
public class SupportPromotions implements Cloneable{private int id;// 该商品促销的 IDprivate PromotionType promotionType;// 促销类型 1\优惠券 2\红包private int priority; // 优先级private UserCoupon userCoupon; // 用户领取该商品的优惠券private UserRedPacket userRedPacket; // 用户领取该商品的红包// 重写 clone 方法public SupportPromotions clone(){SupportPromotions supportPromotions = null;try{supportPromotions = (SupportPromotions)super.clone();}catch(CloneNotSupportedException e){e.printStackTrace();}return supportPromotions;}
}/*** 优惠券* @author admin**/
public class UserCoupon {private int id; // 优惠券 IDprivate int userId; // 领取优惠券用户 IDprivate String sku; // 商品 SKUprivate BigDecimal coupon; // 优惠金额
}/*** 红包* @author admin**/
public class UserRedPacket {private int id; // 红包 IDprivate int userId; // 领取用户 IDprivate String sku; // 商品 SKUprivate BigDecimal redPacket; // 领取红包金额
}/*** 计算支付金额接口类* @author admin**/
public interface IBaseCount {BigDecimal countPayMoney(OrderDetail orderDetail);}/*** 支付基本类* @author admin**/
public class BaseCount implements IBaseCount{public BigDecimal countPayMoney(OrderDetail orderDetail) {
orderDetail.setPayMoney(orderDetail.getMerchandise().getPrice());System.out.println(" 商品原单价金额为:" + orderDetail.getPayMoney());return orderDetail.getPayMoney();}}/*** 计算支付金额的抽象类* @author admin**/
public abstract class BaseCountDecorator implements IBaseCount{private IBaseCount count;public BaseCountDecorator(IBaseCount count) {this.count = count;}public BigDecimal countPayMoney(OrderDetail orderDetail) {BigDecimal payTotalMoney = new BigDecimal(0);if(count!=null) {payTotalMoney = count.countPayMoney(orderDetail);}return payTotalMoney;}
}/*** 计算使用优惠券后的金额* @author admin**/
public class CouponDecorator extends BaseCountDecorator{public CouponDecorator(IBaseCount count) {super(count);}public BigDecimal countPayMoney(OrderDetail orderDetail) {BigDecimal payTotalMoney = new BigDecimal(0);payTotalMoney = super.countPayMoney(orderDetail);payTotalMoney = countCouponPayMoney(orderDetail);return payTotalMoney;}private BigDecimal countCouponPayMoney(OrderDetail orderDetail) {BigDecimal coupon = orderDetail.getMerchandise().getSupportPromotions().get(PromotionType.COUPON).getUserCoupon().getCoupon();System.out.println(" 优惠券金额:" + coupon);orderDetail.setPayMoney(orderDetail.getPayMoney().subtract(coupon));return orderDetail.getPayMoney();}
}/*** 计算使用红包后的金额* @author admin**/
public class RedPacketDecorator extends BaseCountDecorator{public RedPacketDecorator(IBaseCount count) {super(count);}public BigDecimal countPayMoney(OrderDetail orderDetail) {BigDecimal payTotalMoney = new BigDecimal(0);payTotalMoney = super.countPayMoney(orderDetail);payTotalMoney = countCouponPayMoney(orderDetail);return payTotalMoney;}private BigDecimal countCouponPayMoney(OrderDetail orderDetail) {BigDecimal redPacket = orderDetail.getMerchandise().getSupportPromotions().get(PromotionType.REDPACKED).getUserRedPacket().getRedPacket();System.out.println(" 红包优惠金额:" + redPacket);orderDetail.setPayMoney(orderDetail.getPayMoney().subtract(redPacket));return orderDetail.getPayMoney();}
}/*** 计算促销后的支付价格* @author admin**/
public class PromotionFactory {public static BigDecimal getPayMoney(OrderDetail orderDetail) {// 获取给商品设定的促销类型Map<PromotionType, SupportPromotions> supportPromotionslist = orderDetail.getMerchandise().getSupportPromotions();// 初始化计算类IBaseCount baseCount = new BaseCount();if(supportPromotionslist!=null && supportPromotionslist.size()>0) {for(PromotionType promotionType: supportPromotionslist.keySet()) {// 遍历设置的促销类型,通过装饰器组合促销类型baseCount = protmotion(supportPromotionslist.get(promotionType), baseCount);}}return baseCount.countPayMoney(orderDetail);}/*** 组合促销类型* @param supportPromotions* @param baseCount* @return*/private static IBaseCount protmotion(SupportPromotions supportPromotions, IBaseCount baseCount) {if(supportPromotions.getPromotionType()==PromotionType.COUPON) {baseCount = new CouponDecorator(baseCount);}else if(supportPromotions.getPromotionType()==PromotionType.REDPACKED) {baseCount = new RedPacketDecorator(baseCount);}return baseCount;}}public static void main( String[] args ) throws InterruptedException, IOException{Order order = new Order();init(order);for(OrderDetail orderDetail: order.getList()) {BigDecimal payMoney = PromotionFactory.getPayMoney(orderDetail);orderDetail.setPayMoney(payMoney);System.out.println(" 最终支付金额:" + orderDetail.getPayMoney());}}相关文章:
A02、Java 设计模式优化
1、单例模式 1.1、什么是单例模式 它的核心在于,单例模式可以保证一个类仅创建一个实例,并提供一个访问它的全局访问点。该模式有三个基本要点:一是这个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向…...
)
jdk8没有Buffer.put()
在Java中,Buffer是一个抽象类,它定义了缓冲区的通用行为。不过,Buffer本身并没有直接提供put()方法。put()方法是在Buffer的子类中定义的,比如ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer和DoubleB…...

Artec Leo:航海设备维护的便携式3D扫描利器【沪敖3D】
挑战:海军服务提供商USP Maritime需要CAD数据来执行维修和改装任务,特别是在偏远地区的任务,以及原始设计丢失的情况下。 解决方案:Artec Leo, Artec Studio, Autodesk Inventor 效果:高精度船舶组件和船坞机械模型&…...

HCIA笔记6--路由基础
0. 概念 自治系统:一个统一管理的大型网络,由路由器组成的集合。 路由器隔离广播域,交换机隔离冲突域。 1.路由器工作原理 路由器根据路由表进行转发数据包; 路由表中没有路由,直接丢弃该数据包路由表中只有一条路…...

说说Elasticsearch拼写纠错是如何实现的?
大家好,我是锋哥。今天分享关于【说说Elasticsearch拼写纠错是如何实现的?】面试题。希望对大家有帮助; 说说Elasticsearch拼写纠错是如何实现的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Elasticsearch 中&…...

Ubuntu20.04运行R-VIO2
目录 1.环境配置2.构建项目3. 运行 VIO 模式4.结果图 1.环境配置 CMakeLists.txt中 C 使用 14、opencv使用4 2.构建项目 克隆代码库: 在终端中执行以下命令克隆项目:git clone https://github.com/rpng/R-VIO2.git编译项目: 使用 catkin_m…...

【软件项目测试文档大全】软件测试方案,验收测试计划,验收测试报告,测试用例,集成测试,测试规程和指南,等保测试(Word原件)
1. 引言 1.1. 编写目的 1.2. 项目背景 1.3. 读者对象 1.4. 参考资料 1.5. 术语与缩略语 2. 测试策略 2.1. 测试完成标准 2.2. 测试类型 2.2.1. 功能测试 2.2.2. 性能测试 2.2.3. 安全性与访问控制测试 2.3. 测试工具 3. 测试技术 4. 测试资源 4.1. 人员安排 4.…...
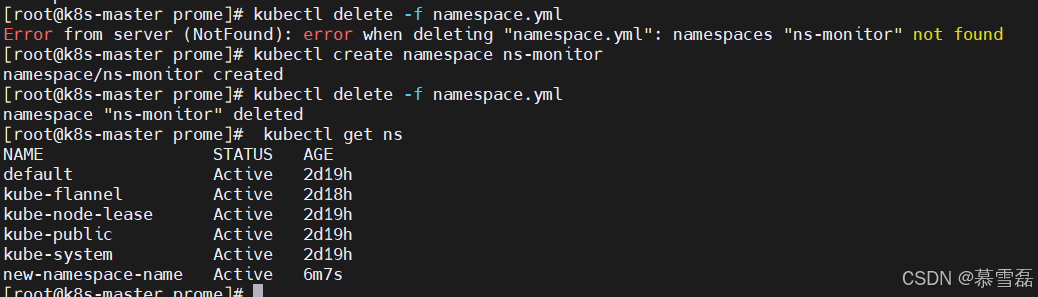
Kubernetes集群操作
查看集群信息: kubectl get nodes 删除节点 (⽆效且显示的也可以删除) 后期如果 要删除某个节点,为了不增加其他节点的访问压力,先增加一个节点,再删除要删除的节点 语法 :kubect delete…...

分布式事务调研
目录 需求背景: 本地事务 分布式基本理论 1、CAP 定理 2、BASE理论 分布式事务方案 #2PC #1. 运行过程 #1.1 准备阶段 #1.2 提交阶段 #2. 存在的问题 #2.1 同步阻塞 #2.2 单点问题 #2.3 数据不一致 #2.4 太过保守 3PC #本地消息表 TCC TCC原理 …...

Webpack 的构建流程
Webpack 的构建流程可以概括为以下几个步骤: 1. 初始化: Webpack 读取配置文件(webpack.config.js),合并默认配置和命令行参数,初始化Compiler对象。 2. 构建依赖图: 从入口文件开始递归地分…...

Cesium 当前位置矩阵的获取
Cesium 位置矩阵的获取 在 3D 图形和地理信息系统(GIS)中,位置矩阵是将地理坐标(如经纬度)转换为世界坐标系的一种重要工具。Cesium 是一个强大的开源 JavaScript 库,用于创建 3D 地球和地图应用。在 Cesi…...

ubuntu24.04 python环境
ubuntu24.04 python环境 0.引言1.使用整理 0.引言 新系统安装依赖库时报错: pip3installrequirements.txterror:externally−managed−environmentThisenvironmentisexternallymanaged╰–>ToinstallPythonpackagessystem−wide,tryaptinstallpython3−xyz,whe…...

YOLO系列论文综述(从YOLOv1到YOLOv11)【第9篇:YOLOv7——跨尺度特征融合】
YOLOv7 1 摘要2 网络架构3 改进点4 和YOLOv4及YOLOR的对比 YOLO系列博文: 【第1篇:概述物体检测算法发展史、YOLO应用领域、评价指标和NMS】【第2篇:YOLO系列论文、代码和主要优缺点汇总】【第3篇:YOLOv1——YOLO的开山之作】【第…...

Elasticearch索引mapping写入、查看、修改
作者:京东物流 陈晓娟 一、ES Elasticsearch是一个流行的开源搜索引擎,它可以将大量数据快速存储和检索。Elasticsearch还提供了强大的实时分析和聚合查询功能,数据模式更加灵活。它不需要预先定义固定的数据结构,可以随时添加或修…...

【大模型微调】一些观点的总结和记录
垂直领域大部分不用保持通用能力的,没必要跟淘宝客服聊天气预报,但是主要还是领导让你保持 微调方法没有大变数了,只能在数据上下功夫,我能想到的只有提高微调数据质量。 sft微调的越多,遗忘的越多. 不过对于小任务,rank比较低(例如8,16)的任务,影响还是有有限的。一…...

Vue 3 Hooks 教程
Vue 3 Hooks 教程 1. 什么是 Hooks? 在 Vue 3 中,Hooks 是一种组织和复用组件逻辑的强大方式。它们允许您将组件的状态逻辑提取到可重用的函数中,从而简化代码并提高代码的可维护性。 2. 基本 Hooks 介绍 2.1 ref 和 reactive 这两个函数…...

pandas数据处理及其数据可视化的全流程
Pandas数据处理及其可视化的全流程是一个复杂且多步骤的过程,涉及数据的导入、清洗、转换、分析、可视化等多个环节。以下是一个详细的指南,涵盖了从数据准备到最终的可视化展示的全过程。请注意,这个指南将超过4000字,因此请耐心…...
docker 在ubuntu系统安装,以及常用命令,配置阿里云镜像仓库,搭建本地仓库等
1.docker安装 1.1 先检查ubuntu系统有没有安装过docker 使用 docker -v 命令 如果有请先卸载旧版本,如果没有直接安装命令如下: 1.1.0 首先,确保你的系统包是最新的: 如果是root 权限下面命令的sudo可以去掉 sudo apt-get upda…...

torch.maximum函数介绍
torch.maximum 函数介绍 定义:torch.maximum(input, other) 返回两个张量的逐元素最大值。 输入参数: input: 张量,表示第一个输入。other: 张量或标量,表示第二个输入。若为张量,其形状需要能与 input 广播。输出&a…...

Java面试之多线程并发篇(9)
前言 本来想着给自己放松一下,刷刷博客,突然被几道面试题难倒!引用类型有哪些?有什么区别?说说你对JMM内存模型的理解?为什么需要JMM?多线程有什么用?似乎有点模糊了,那…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...