遗传算法与深度学习实战(26)——编码卷积神经网络架构
遗传算法与深度学习实战(26)——编码卷积神经网络架构
- 0. 前言
- 1. EvoCNN 原理
- 1.1 工作原理
- 1.2 基因编码
- 2. 编码卷积神经网络架构
- 小结
- 系列链接
0. 前言
我们已经学习了如何构建卷积神经网络 (Convolutional Neural Network, CNN),在本节中,我们将了解如何将 CNN 模型的网络架构编码为基因,这是将基因序列进化在为给定数据集上训练最佳模型的先决条件。
1. EvoCNN 原理
进化卷积神经网络 (Evolutionary Convolutional Neural Network, EvoCNN) 是一种结合了进化算法和卷积神经网络的方法。
我们知道进化算法是一类基于生物进化过程中的选择、变异和竞争机制的优化算法。在进化卷积神经网络中,进化算法用来优化卷积神经网络 (Convolutional Neural Network, CNN) 的结构或超参数,以提升其性能和适应特定任务的能力。
1.1 工作原理
EvoCNN 可以利用进化算法来自动设计 CNN 的网络结构,包括卷积层的数量、每层的卷积核大小、池化操作的类型等。自动设计的过程可以帮助避免人工设计网络结构时的主观偏差,并且可以根据具体任务调整网络结构。
除了网络结构外,进化算法还可以用于优化 CNN 的超参数,如学习率、批处理大小等,以提升训练效率和模型性能。
EvoCNN 的另一个优点是其适应性强,能够适应不同的任务和数据集。通过进化算法,网络可以在训练过程中动态调整,以适应变化的输入数据和任务要求。
1.2 基因编码
EvoCNN 是演化 CNN 模型架构的模型,其定义了一种将卷积网络编码为可变长度基因序列的过程,如下图所示。

2. 编码卷积神经网络架构
(1) 首先,导入所需库,并加载数据集:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import numpy as np
import math
import time
import randomimport matplotlib.pyplot as plt
from livelossplot import PlotLossesKerasdataset = datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = dataset.load_data()# normalize and reshape data
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype("float32") / 255.0
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype("float32") / 255.0x_train = x_train[:1000]
y_train= y_train[:1000]
x_test = x_test[:100]
y_test= y_test[:100]class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']def plot_data(num_images, images, labels):grid = math.ceil(math.sqrt(num_images))plt.figure(figsize=(grid*2,grid*2))for i in range(num_images):plt.subplot(grid,grid,i+1)plt.xticks([])plt.yticks([])plt.grid(False) plt.imshow(images[i].reshape(28,28))plt.xlabel(class_names[labels[i]]) plt.show()plot_data(25, x_train, y_train)
构建基因序列时,我们希望定义一个基本规则,所有模型都以卷积层开始,并以全连接层作为输出层结束。为了简化问题,我们无需编码最后的输出层。
(2) 在每个主要网络层内部,我们还需要定义相应的超参数选项,例如滤波器数量和卷积核大小。为了编码多样化数据,我们需要分离主要网络层和相关超参数。设置常量用于定义网络层类型和长度以封装各种相关的超参数。定义总最大网络层数和各种网络层超参数的范围,之后,定义每种类型的块标识符及其相应的大小(该值表示每个层定义的长度,包括超参数):
max_layers = 5
max_neurons = 128
min_neurons = 16
max_kernel = 5
min_kernel = 2
max_pool = 3
min_pool = 2CONV_LAYER = -1
CONV_LAYER_LEN = 4
POOLING_LAYER = -2
POOLING_LAYER_LEN = 3
BN_LAYER = -3
BN_LAYER_LEN = 1
DENSE_LAYER = -4
DENSE_LAYER_LEN = 2
下图展示了编码层块及其相应超参数的基因序列。需要注意的是,负值 -1、-2、-3 和 -4 表示网络层的开始。然后,根据层类型,进一步定义滤波器数量和卷积核大小等超参数。

(3) 构建个体的基因序列(染色体),create_offspring() 函数是构建序列的基础。此代码循环遍历最大层数次,并检查是否(以 50% 的概率)添加卷积层。如果是,则进一步检查是否(以 50% 的概率)添加批归一化和池化层:
def create_offspring():ind = []for i in range(max_layers):if random.uniform(0,1)<.5:#add convolution layerind.extend(generate_conv_layer())if random.uniform(0,1)<.5:#add batchnormalizationind.extend(generate_bn_layer())if random.uniform(0,1)<.5:#add max pooling layerind.extend(generate_pooling_layer())ind.extend(generate_dense_layer())return ind
(4) 编写用于构建网络层的辅助函数:
def generate_neurons():return random.randint(min_neurons, max_neurons)def generate_kernel():part = []part.append(random.randint(min_kernel, max_kernel))part.append(random.randint(min_kernel, max_kernel))return partdef generate_bn_layer():part = [BN_LAYER] return partdef generate_pooling_layer():part = [POOLING_LAYER] part.append(random.randint(min_pool, max_pool))part.append(random.randint(min_pool, max_pool))return partdef generate_dense_layer():part = [DENSE_LAYER] part.append(generate_neurons()) return partdef generate_conv_layer():part = [CONV_LAYER] part.append(generate_neurons())part.extend(generate_kernel())return part
(5) 调用 create_offspring() 生成基因序列,输出如下所示。可以多次调用该函数,观察创建的基因序列的变化:
individual = create_offspring()
print(individual)
# [-1, 37, 5, 2, -3, -1, 112, 4, 2, -4, 25]
(6) 获取基因序列后,继续构建模型,解析基因序列并创建 Keras 模型。build_model 的输入是单个基因序列,利用基因序列产生 Keras 模型。定义网络层之后,根据网络层类型添加超参数:
def build_model(individual):model = models.Sequential()il = len(individual)i = 0while i < il:if individual[i] == CONV_LAYER: n = individual[i+1]k = (individual[i+2], individual[i+3])i += CONV_LAYER_LENif i == 0: #first layer, add input shape model.add(layers.Conv2D(n, k, activation='relu', padding="same", input_shape=(28, 28, 1))) else:model.add(layers.Conv2D(n, k, activation='relu', padding="same")) elif individual[i] == POOLING_LAYER: #add pooling layerk = k = (individual[i+1], individual[i+2])i += POOLING_LAYER_LENmodel.add(layers.MaxPooling2D(k, padding="same")) elif individual[i] == BN_LAYER: #add batch normal layermodel.add(layers.BatchNormalization())i += 1 elif individual[i] == DENSE_LAYER: #add dense layermodel.add(layers.Flatten()) model.add(layers.Dense(individual[i+1], activation='relu'))i += 2model.add(layers.Dense(10))return modelmodel = build_model(individual)
(7) 创建一个新的个体基因序列,根据序列构建一个模型,然后训练模型,输出训练/验证过程中模型性能:
individual = create_offspring()model = build_model(individual) model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])history = model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test),callbacks=[PlotLossesKeras()],verbose=0)model.summary()
model.evaluate(x_test, y_test)
模型性能的优略取决于随机初始序列,多次运行代码,以观察不同初始随机个体之间的差异。可以通过完成以下问题进一步了解网络架构编码:
- 通过调用循环中的
create_offspring函数,创建一个新的基因编码序列列表,打印并比较不同个体 - 修改最大/最小范围超参数,然后生成一个新的后代列表
- 添加一个新输入到
create_offspring函数,将概率从0.5更改为其他值。然后,生成一个后代列表进行比较
小结
进化卷积神经网络 (Evolutionary Convolutional Neural Network, EvoCNN) 通过结合进化算法的优势,提供了一种自动化设计和优化深度学习模型的方法。在本节中,我们介绍了如何将卷积神经网络架构编码为基因序列,为构建进化卷积神经网络奠定基础。
系列链接
遗传算法与深度学习实战(1)——进化深度学习
遗传算法与深度学习实战(2)——生命模拟及其应用
遗传算法与深度学习实战(3)——生命模拟与进化论
遗传算法与深度学习实战(4)——遗传算法(Genetic Algorithm)详解与实现
遗传算法与深度学习实战(5)——遗传算法中常用遗传算子
遗传算法与深度学习实战(6)——遗传算法框架DEAP
遗传算法与深度学习实战(7)——DEAP框架初体验
遗传算法与深度学习实战(8)——使用遗传算法解决N皇后问题
遗传算法与深度学习实战(9)——使用遗传算法解决旅行商问题
遗传算法与深度学习实战(10)——使用遗传算法重建图像
遗传算法与深度学习实战(11)——遗传编程详解与实现
遗传算法与深度学习实战(12)——粒子群优化详解与实现
遗传算法与深度学习实战(13)——协同进化详解与实现
遗传算法与深度学习实战(14)——进化策略详解与实现
遗传算法与深度学习实战(15)——差分进化详解与实现
遗传算法与深度学习实战(16)——神经网络超参数优化
遗传算法与深度学习实战(17)——使用随机搜索自动超参数优化
遗传算法与深度学习实战(18)——使用网格搜索自动超参数优化
遗传算法与深度学习实战(19)——使用粒子群优化自动超参数优化
遗传算法与深度学习实战(20)——使用进化策略自动超参数优化
遗传算法与深度学习实战(21)——使用差分搜索自动超参数优化
遗传算法与深度学习实战(22)——使用Numpy构建神经网络
遗传算法与深度学习实战(23)——利用遗传算法优化深度学习模型
遗传算法与深度学习实战(24)——在Keras中应用神经进化优化
遗传算法与深度学习实战(25)——使用Keras构建卷积神经网络
相关文章:
遗传算法与深度学习实战(26)——编码卷积神经网络架构
遗传算法与深度学习实战(26)——编码卷积神经网络架构 0. 前言1. EvoCNN 原理1.1 工作原理1.2 基因编码 2. 编码卷积神经网络架构小结系列链接 0. 前言 我们已经学习了如何构建卷积神经网络 (Convolutional Neural Network, CNN),在本节中&a…...

Linux无线网络配置工具:iwconfig vs iw
在Linux系统中,无线网络配置和管理是网络管理员和开发者的常见任务。本文将详细介绍两个常用的无线网络配置命令行工具:iwconfig 和 iw,并对比它们之间的区别,帮助您更好地选择合适的工具进行无线网络配置。 一、iwconfig 简介 …...

RabbitMQ介绍及安装
文章目录 一. MQ二. RabbitMQ三. RabbitMQ作用四. MQ产品对比五. 安装RabbitMQ1. 安装erlang2. 安装rabbitMQ3. 安装RabbitMQ管理界⾯4. 启动服务5. 访问界面6. 添加管理员用户7. 重新登录 一. MQ MQ( Message queue ), 从字⾯意思上看, 本质是个队列, FIFO 先⼊先出ÿ…...

借助 AI 工具,共享旅游-卡-项目助力年底增收攻略
年底了,大量的商家都在开始筹备搞活动,接下来的双十二、元旦、春节、开门红、寒假,各种活动,目的就是为了拉动新客户。 距离过年还有56 天,如何破局? 1、销售渠道 针对旅游卡项目,主要销售渠道…...

Docker Compose 和 Kubernetes 之间的区别?
一、简介🎀 1.1 Docker Compose Docker Compose 是 Docker 官方的开源项目,负责实现对 Docker 容器集群的快速编排,可以管理多个 Docker 容器组成一个应用。你只需定义一个 YAML 格式的配置文件 docker-compose.yml ,即可创建并…...

node.js常用的模块和中间件?
Node.js常用的模块和中间件包括以下几种: Express:Express是一个灵活的Node.js web应用框架,提供了丰富的API来处理HTTP请求和响应。它支持中间件系统,可以轻松地添加各种功能,如路由、模板引擎、静态文件服务…...

Llama模型分布式训练(微调)
1 常见大模型 1.1 参数量对照表 模型参数量发布时间训练的显存需求VGG-19143.68M2014~5 GB(单 224x224 图像,batch_size32)ResNet-15260.19M2015~7 GB(单 224x224 图像,batch_size32)GPT-2 117M117M2019~…...

Matlab模块From Workspace使用数据类型说明
Matlab原文连接:Load Data Using the From Workspace Block 模型: 从信号来源的数据: timeseries 数据: sampleTime 0.01; numSteps 1001;time sampleTime*[0:(numSteps-1)]; time time;data sin(2*pi/3*time);simin time…...

LangChain学习笔记(一)-LangChain简介
LangChain学习笔记(一)-LangChain简介 langChain是一个人工智能大语言模型的开发框架,主要构成为下图。 一、核心模块 (一)模型I/O模块 负责与现有大模型进行交互,由三部分组成: 提…...

k8s,声明式API对象理解
命令式API 比如: 先kubectl create,再replace的操作,我们称为命令式配置文件操作 kubectl replace的执行过程,是使用新的YAML文件中的API对象,替换原有的API对象;而kubectl apply,则是执行了一…...

KubeBlocks v0.9.2发布啦!支持容器镜像滚动更新、MySQL支持Jemalloc...快来升级体验更多新功能!
KubeBlocks v0.9.2 正式发布啦!本次发布包含了一些新功能、关键的错误修复以及各种改进。以下是详细的更新内容。 升级文档 v0.9.2 升级方式与 v0.9.1 相同,替换版本即可哦~ https://kubeblocks.io/docs/release-0.9/user_docs/upgrade/up…...

Linux-虚拟环境
文章目录 一. 虚拟机二. 虚拟化软件三. VMware WorkStation四. 安装CentOS操作系统五. 在VMware中导入CentOS虚拟机六. 远程连接Linux系统1. Finalshell安装2. 虚拟机网络配置3. 连接到Linux系统 七. 虚拟机快照 一. 虚拟机 借助虚拟化技术,我们可以在系统中&#…...

window系统下的git怎么在黑窗口配置代理
在Windows系统下,通过黑窗口(命令行界面)配置Git代理主要有两种方式:配置HTTP代理和配置SOCKS5代理。以下是具体的步骤: 配置HTTP代理 临时代理设置(仅对当前命令行会话有效): set …...

网络和通信详解
一、Java 网络编程基础 IP 地址和端口号 IP 地址: IP 地址是互联网协议地址,用于标识网络中的设备。在 Java 中,InetAddress类是用于表示 IP 地址的主要类。例如,InetAddress.getByName("www.example.com")可以获取指定…...

网络安全框架及模型-PPDR模型
网络安全框架及模型-PPDR模型 概述: 为了有效应对不断变化的网络安全环境,人们意识到需要一种综合性的方法来管理和保护网络安全。因此,PPDR模型应运而生。它将策略、防护、检测和响应四个要素结合起来,提供了一个全面的框架来处理网络安全问题。 工作原理: PPDR模型的…...

WPF+LibVLC开发播放器-LibVLC播放控制
接上一篇: LibVLC在C#中的使用 实现LibVLC播放器播放控制 界面 界面上添加一个Button按钮用于控制播放 <ButtonGrid.Row"1"Width"88"Height"24"Margin"10,0,0,0"HorizontalAlignment"Left"VerticalAlignme…...

子模块、Fork、NPM 包与脚手架概述
子模块 在 Git 仓库中嵌套另一个仓库,通过引用的方式引入到主项目,版本管理依赖 Git 提交记录或分支,更新需手动拉取并提交,适用于共享代码并保持项目独立性。 优点:子模块支持直接查看和修改,保持子模块…...

基于Java Springboot蛋糕订购小程序
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 微信…...

【el-table】表格后端排序
在需要排序的列添加属性 sortable,后端排序,需将sortable设置为custom 如果需要自定义轮转添加 sort-orders 属性,数组中的元素需为以下三者之一:ascending 表示升序,descending 表示降序,null 表示还原为原…...

APP聊天项目介绍
项目结构说明 res/layout目录:存放布局相关的 XML 文件,用于定义界面的外观,包含activity_main.xml(主界面布局)和message_item.xml(聊天消息项布局)。 res/drawable目录:存放一些…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...
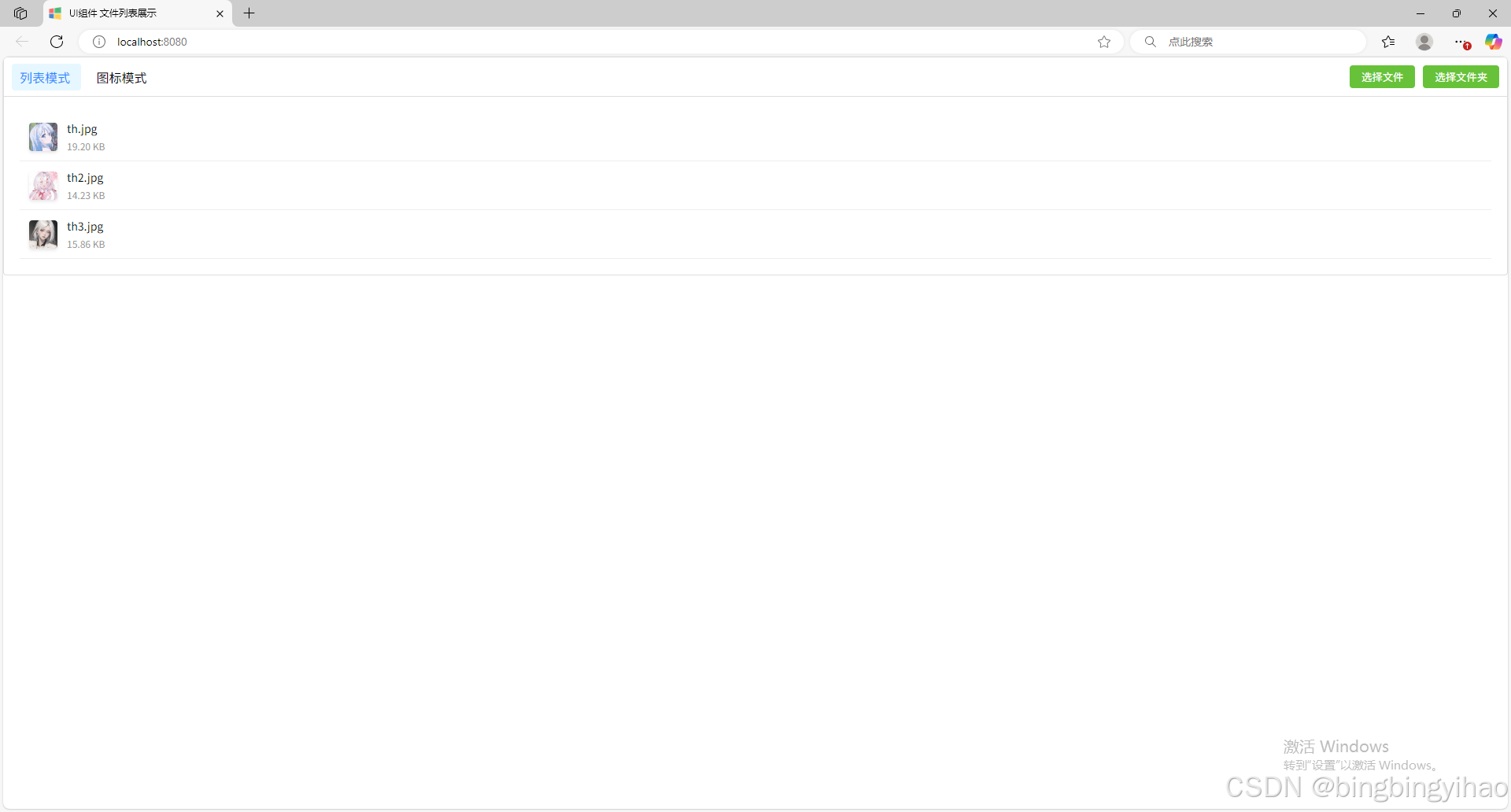
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...