Linux Ubuntu 安装配置RabbitMQ,springboot使用RabbitMQ
rabbit-Ubuntu
一篇文章学会RabbitMQ
在Ubuntu上查看RabbitMQ状态可以通过多种方式进行,包括使用命令行工具和Web管理界面。以下是一些常用的方法:
1-使用systemctl命令:
sudo systemctl start rabbitmq-server sudo systemctl status rabbitmq-server
-
2-使用
service命令-
启动服务:同样地,如果RabbitMQ服务尚未启动,可以使用以下命令启动服务
sudo service rabbitmq-server start sudo service rabbitmq-server status -
查看状态:使用
service命令查看RabbitMQ服务的状态[^2^][^3^]。如果服务正在运行,你会看到“Active: active (running)”的信息:
-
-
使用
rabbitmqctl命令-
查看状态:如果你已经安装了RabbitMQ的管理工具(如
rabbitmq-server),你可以直接使用rabbitmqctl命令来查看RabbitMQ的状态[^4^]。但请注意,这个命令在某些情况下可能需要在RabbitMQ的安装目录或特定目录下执行:rabbitmqctl status -
在某些情况下,你可能需要进入RabbitMQ的安装目录(如
/opt/rabbitmq/sbin或/usr/lib/rabbitmq/bin)后才能执行rabbitmqctl命令[^1^]。例如:cd /opt/rabbitmq/sbin ./rabbitmqctl status
-
在Ubuntu上安装RabbitMQ
在Ubuntu上安装RabbitMQ的步骤包括更新系统、安装Erlang环境、添加GPG密钥、安装RabbitMQ、启动服务、启用管理插件以及创建用户等。以下是详细的步骤:
-
更新系统:确保你的Ubuntu系统是最新的,以避免由于软件包过时导致的兼容性问题。打开终端并运行以下命令来更新系统的软件包列表
-
sudo apt update sudo apt upgrade -y -
安装Erlang环境:RabbitMQ是基于Erlang语言开发的,因此需要先安装Erlang运行环境。执行以下命令来安装Erlang
sudo apt install -y curl gnupg curl -fsSL https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc | sudo gpg --dearmor -o /usr/share/keyrings/rabbitmq-archive-keyring.gpg echo "deb [signed-by=/usr/share/keyrings/rabbitmq-archive-keyring.gpg] http://dl.bintray.com/rabbitmq-erlang/debian bionic erlang" | sudo tee /etc/apt/sources.list.d/rabbitmq-erlang.list sudo apt update sudo apt install -y erlang -
添加RabbitMQ的GPG密钥:为了能够从官方源下载RabbitMQ,需要添加其GPG密钥
curl -fsSL https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc | sudo gpg --dearmor -o /usr/share/keyrings/rabbitmq-archive-keyring.gpg -
安装RabbitMQ:现在可以安装RabbitMQ服务器了。执行以下命令来添加RabbitMQ的APT源并安装RabbitMQ[^2^][^3^]:
echo "deb [signed-by=/usr/share/keyrings/rabbitmq-archive-keyring.gpg] http://dl.bintray.com/rabbitmq/debian focal main" | sudo tee /etc/apt/sources.list.d/rabbitmq.list sudo apt update sudo apt install -y rabbitmq-server -
启动RabbitMQ服务:安装完成后,启动RabbitMQ服务并设置开机自启
sudo systemctl start rabbitmq-server sudo systemctl enable rabbitmq-server -
启用管理插件:RabbitMQ提供了一个Web管理界面,可以通过启用管理插件来访问[^2^][^3^]。
sudo rabbitmq-plugins enable rabbitmq_management -
创建用户:为了安全起见,建议创建一个新的用户并为其分配权限
sudo rabbitmqctl add_user myuser mypassword sudo rabbitmqctl set_user_tags myuser administrator sudo rabbitmqctl set_permissions -p / myuser ".*" ".*" ".*"
-
访问管理界面:默认情况下,RabbitMQ的管理界面运行在15672端口。打开浏览器,访问http://<your-server-ip>:15672,使用刚刚创建的用户名和密码登录[^2^]。
http://47.97.22.101:15672
重点:服务器上添加rabbitMQ账户
原因 RabbitMQ默认的guest账号密码只能使用localhost登录,服务器上的RabbitMQ只能在电脑浏览器登录,必须新建账户。
1、 创建一个新的用户 sudo rabbitmqctl add_user <username> <password>
2、 设置管理角色 sudo rabbitmqctl set_user_tags <username> administrator 3、 设置用户权限 sudo rabbitmqctl set_permissions -p / <username> ".*" ".*" ".*" 4、 确认权限设置 sudo rabbitmqctl list_user_permissions andy
5、 添加别的虚拟主机(可选) sudo rabbitmqctl add_vhost <vhost_name>
6、 设置权限 sudo rabbitmqctl set_permissions -p <vhost_name> andy ".*" ".*" ".*"
7、 确认用户标签 sudo rabbitmqctl list_user_tags <username>
8、 禁用guest账户(可选) sudo rabbitmqctl delete_user guest
RabbitMQ 命令
http://localhost:15672/
登陆rabbitmq:成功启动服务后,使用以下链接访问主页,则会进入到登陆页面 # 访问rabbitmq主页 http://localhost:15672/
注意:默认是账户名和密码都是:“guest”,表示来宾客户。 由于账号guest具有所有的操作权限,且是默认账号,出于安全因素的考虑,guest用户只能通过localhost登陆使用, 并建议修改guest用户的密码以及新建其他账号管理使用rabbitmq。
服务器上的RabbitMQ,在本地浏览器中无法登录
--------------------------------状态
# 查询rabbitmq的状态 sudo rabbitmqctl status
# 查询rabbitmq的进程 ps -ef | grep rabbitmq ===linux sudo service rabbitmq-server status ==win and mac rabbitmqctl status
# 杀掉rabbitmq进程 ps -ef | grep rabbitmq | grep -v grep | awk '{print $2}' | xargs kill -9
--------------------------------启动
# 启动服务 sudo rabbitmq-server # 后台启动命令 sudo rabbitmq-server -detached
---mac---
brew services start rabbitmq brew services info
--- # 启动插件 sudo rabbitmq-plugins enable rabbitmq_management
--------------------------------关闭
sudo rabbitmqctl stop # 查找rabbitmq在哪 find / -name 'rabbitmq' -type d # rabbitmq内存限制 # 系数计算,假设机器内存32g,以下命令限制的最高内存为,32*0.06=1.92g rabbitmqctl set_vm_memory_high_watermark 0.06 # rabbitmq添加消息日志记录 rabbitmq-plugins enable rabbitmq_tracing
springboot使用RabbitMQ
1-pom.xml
<!--Spring AMQP依赖-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>2-application.yml
rabbitmq:host: 47.97.22.101port: 15672virtual-host: /andyusername: andypassword: andypublisher-confirm-type: correlated# 消息发送到交换机确认publisher-returns: true#消息发送到队列确认
# publisher-confirms: true
# Deprecated configuration property 'spring.rabbitmq.publisher-confirms'弃用的配置属性
3-登录客户端

添加对列,一定要提前添加

添加用户 
添加交换机
4-消费者
/*** 4-创建消息消费者* 创建一个消息消费者类,用于接收并处理来自RabbitMQ队列的订单消息:*/
@Slf4j
@Component
public class Consumer
{private static final int MAX_RETRIES = 3; // 最大重试次数private final static String QUEUE_NAME = "orderQueue";@AutowiredIXOrdersService xOrdersService;@AutowiredRabbitTemplate rabbitTemplate;@RabbitListener(queues = QUEUE_NAME)public void handleOrder( XOrders xOrders, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, Channel channel ) throws IOException{// 将message转为string// String messageStr = new String( xOrders.getBody(), StandardCharsets.UTF_8 );// 生产者手动序列化,消费者使用相同 json 反序列化// Order order = new ObjectMapper().readValue( message.getBody(), Order.class );// Order order = JSONUtil.toBean( messageStr, Order.class );//处理订单逻辑log.info( "--------Consumer-------rabbitMQ received message:" + xOrders );try{// 处理订单创建xOrdersService.insertXOrders( xOrders );channel.basicAck( deliveryTag, false );//消息确认}catch ( Exception e ){// 失败处理(例如重试机制)log.error( "--------Consumer-------rabbitMQ received message error:" + e.getMessage() );// 增加重试次数,并重新发送消息到队列int retryCount = xOrders.getRetryCount() != null ? xOrders.getRetryCount() : 0;if ( retryCount < MAX_RETRIES ){xOrders.setRetryCount( retryCount + 1 );sendToQueue( xOrders );//重新发送消息}else{// 重试次数超过限制,将订单发送到死信队列sendToDeadLetterQueue( xOrders );}channel.basicNack( deliveryTag, false, false ); // 拒绝消息, 将消息重新放回队列}}private void sendToQueue( XOrders orderMessage ){rabbitTemplate.convertAndSend( "order.exchange", "order.routing.key", orderMessage );}private void sendToDeadLetterQueue( XOrders orderMessage ){rabbitTemplate.convertAndSend( "order.dlx.exchange", "order.dlx.routing.key", orderMessage );}// public static void main( String[] args ) throws IOException, TimeoutException// {// // 创建服务器的连接// ConnectionFactory factory = new ConnectionFactory();// factory.setHost( "localhost" );// Connection connection = factory.newConnection();// Channel channel = connection.createChannel();// channel.queueDeclare( QUEUE_NAME, false, false, false, null );// //用于处理消费者接收信息的回调函数// DeliverCallback deliverCallback = new DeliverCallback()// {// @Override// public void handle( String consumerTag, Delivery delivery ) throws IOException// {// String s = new String( delivery.getBody(), StandardCharsets.UTF_8 );// System.out.println( consumerTag + " [x] Received '" + s + "'" );// }// };// /**// * QUEUE_NAME`:表示要消费的队列名。// `true`:表示自动确认消息,当消费者接收到一条消息后就会自动向消息队列发送确认消息,告诉消息队列这条消息已经被消费处理完成。// `deliverCallback`:表示接收到消息后的处理逻辑,将在 `handle` 方法中执行。// `consumerTag -> {}`:表示用于接收消费者标识的回调函数。在上面的 `basicCancel` 方法中同样需要传入该回调函数中的消费者标识才能成功取消消费者的订阅// */// channel.basicConsume( QUEUE_NAME, true, deliverCallback, consumerTag -> {// System.out.println( consumerTag );// } );//// }
}
5-生产者
/**** 3-创建消息生产者* 创建一个消息生产者类,用于发送订单消息到RabbitMQ队列:*/
@Slf4j
@Component
public class Producer
{@Autowiredprivate AmqpTemplate amqpTemplate;@Autowiredprivate RabbitTemplate rabbitTemplate;//对列名private final static String QUEUE_NAME = "orderQueue";public void sendOrder( XOrders xOrders ) throws JsonProcessingException{log.info( "---------------Producer-----------rabbitMQ convertAndSend----- " );//amqpTemplate.convertAndSend(【交换机,有默认值】,【队列名称】 QUEUE_NAME, 【信息】order );// 生产者手动序列化,消费者使用相同 json 反序列化-- 1-实体实现serializable接口,2-序列化String jsonStr = JSONUtil.toJsonStr( xOrders );amqpTemplate.convertAndSend( QUEUE_NAME, jsonStr );// rabbitTemplate.convertAndSend("order.exchange", "order.routing.key", orderMessage);rabbitTemplate.convertAndSend( "order.exchange", "order.routing.key", xOrders );}public static void main( String[] args ) throws IOException, TimeoutException{//创建一个连接工厂ConnectionFactory factory = new ConnectionFactory();//设置连接工厂的参数factory.setHost( "localhost" );// factory.setPort( 5672 );// factory.setUsername( "guest" );// factory.setPassword( "guest" );//创建一个连接Connection connection = factory.newConnection();/**在 RabbitMQ 中,Channel 指的是在连接(Connection)上创建的一个逻辑通道,用来进行发送和接收消息的操作。每一个 Channel 都会拥有独立的 ID,可以根据这个 ID 与 RabbitMQ 服务器进行通信。通过 Channel,应用程序可以进行以下操作:声明队列(Queue)和交换器(Exchange)。将队列绑定到交换器上。发布消息到指定的交换器上。消费指定队列上的消息。在 RabbitMQ 中,每个 Connection 都支持多个 Channel,应用程序可以根据自己的需求创建多个 Channel,从而实现并发和优化网络带宽的利用。但是需要注意,对于一个 Connection 可能存在的并发限制,在应用程序中需要合理控制 Channel 的数量。*///创建一个通道Channel channel = connection.createChannel();channel.queueDeclare( QUEUE_NAME, false, false, false, null );/*** 这段代码是通过 RabbitMQ 的 Java 客户端创建一个名为 `QUEUE_NAME` 的队列。其中,代码参数的含义如下:* `QUEUE_NAME`:队列名,即要创建的队列的名称。* `false`:指定是否为持久化队列。设置为 `false` 表示创建的队列在 RabbitMQ 服务器重启后会被删除。* `false`:指定是否为排他队列。设置为 `false` 表示队列可以被其他连接访问。* `false`:指定队列是否应该自动删除。设置为 `false` 表示当没有任何消费者使用该队列时,该队列不会自动删除。* `null`:指定队列的属性。设置为 `null` 表示不需要为队列设置任何属性。* 当该方法被成功执行后,就可以使用 `channel.basicPublish()` 方法向队列发送消息,并使用 `channel.basicConsume()` 方法从队列中获取消息。该队列的状态信息也可以通过 `com.rabbitmq.client.AMQP.Queue.DeclareOk` 对象来进行监控。**/String message = "Hello World!";channel.basicPublish( "", QUEUE_NAME, null, message.getBytes( StandardCharsets.UTF_8 ) );System.out.println( " [x] Sent '" + message + "'" );}
}
6-配置文件
/***@Description 配置RabbitMQ*@Author Andy Fan*@Date 2024/12/4 13:19*@ClassName RabbitConfig* 补偿机制和重试策略* 1-重试机制(RabbitMQ的死信队列)* 为了保证消息不丢失,并且在处理失败时能够进行重试,可以使用RabbitMQ的死信队列(DLX, Dead Letter Exchange)机制。* 在RabbitMQ中,死信队列用于存储无法成功消费的消息。在消息消费者处理失败时,可以将消息发送到死信队列,待后续处理。**/
@Configuration
public class RabbitConfig
{//声明需要使用的交换机/路由Key/队列的名称public static final String DEFAULT_EXCHANGE = "exchange";public static final String DEFAULT_ROUTE = "route";public static final String DEFAULT_QUEUE = "queue";// 声明队列,@Beanpublic Queue orderQueue(){return QueueBuilder.durable( "order.queue" ).deadLetterExchange( "order.dlx.exchange" ) // 设置死信交换机.deadLetterRoutingKey( "order.dlx.routing.key" ) // 设置死信路由.build();}// 声明交换机,@Beanpublic DirectExchange orderExchange(){return new DirectExchange( "order.exchange" );}@Beanpublic DirectExchange orderDlxExchange(){return new DirectExchange( "order.dlx.exchange" );}//声明路由Key(交换机和队列的关系),需要几个声明几个,这里就一个@Beanpublic Binding binding( Queue orderQueue, DirectExchange orderExchange ){return BindingBuilder.bind( orderQueue ).to( orderExchange ).with( "order.routing.key" );}@Beanpublic Binding dlxBinding( Queue dlxQueue, DirectExchange orderDlxExchange ){return BindingBuilder.bind( dlxQueue ).to( orderDlxExchange ).with( "order.dlx.routing.key" );}@Beanpublic Queue dlxQueue(){return new Queue( "order.dlx.queue" );}
}
7-死信对列
/***@Description*@Author Andy Fan*@Date 2024/12/4 14:00*@ClassName DeadLetterQueueConsumer*/
@Slf4j
@Component
public class DeadLetterQueueConsumer
{@Autowiredprivate IXOrdersService xOrdersService;@RabbitListener(queues = "order.dlx.queue")public void handleDeadLetterQueue( XOrders orderMessage ){// 处理死信队列中的消息,进行补偿操作,例如手动通知用户或采取其他措施// 这里可以手动通知管理员,或者尝试人工干预log.error( "Failed to process order after multiple attempts: " + orderMessage );}}
rabbitmq 怎么保证消息的稳定性?
在使用 RabbitMQ 进行消息队列处理时,消息的稳定性是确保消息不会丢失、重复处理或被错误消费的关键。RabbitMQ 提供了多种机制来保障消息的稳定性,以下是几种常用的策略及其原理:
1. 持久化消息 (Message Persistence)
目的:防止 RabbitMQ 服务重启或宕机时消息丢失。
-
队列持久化:将队列声明为持久化队列,即使 RabbitMQ 重启后队列也能恢复。
-
消息持久化:在发送消息时标记消息为持久化,确保消息写入磁盘。
实现方式:
-
声明队列时设置
durable为true,确保队列本身是持久化的。 -
发送消息时设置
MessageProperties.PERSISTENT_TEXT_PLAIN,确保消息在队列中是持久化存储的。
// 声明持久化队列boolean durable = true;
// 队列持久化 channel.queueDeclare("my_queue", durable, false, false, null);
// 发送持久化消息String message = "Hello World!";
AMQP.BasicProperties props = MessageProperties.PERSISTENT_TEXT_PLAIN; channel.basicPublish("", "my_queue", props, message.getBytes());注意:持久化会稍微影响性能,因为写入磁盘比写入内存慢。
2. 确认机制 (Publisher Confirms)
目的:确保生产者成功将消息发送到 RabbitMQ,并确认消息被 RabbitMQ 正确接收。
-
RabbitMQ 提供了确认机制,生产者在发送消息后会收到来自 RabbitMQ 的确认(
ack),确保消息已成功进入队列。 -
如果没有收到确认,生产者可以选择重发消息,避免消息丢失。
实现方式:
-
启用发布确认模式 (
Publisher Confirms)。 -
监听 RabbitMQ 的确认或失败回调。
// 启用发布确认模式 channel.confirmSelect(); String message = "Hello, RabbitMQ!"; channel.basicPublish("", "my_queue", null, message.getBytes());
// 等待确认if (channel.waitForConfirms()) { System.out.println("Message successfully sent to RabbitMQ"); } else { System.out.println("Message failed to send to RabbitMQ"); }
3. 消息应答 (Consumer Acknowledgments)
目的:确保消息被消费者成功处理后才从队列中移除,防止消息丢失或未被正确消费。
-
默认情况下,消息一旦发送给消费者就从队列中移除。为了确保消息处理成功,RabbitMQ 提供了手动
ack应答机制。 -
消费者处理完消息后,手动发送
ack(确认)。如果消费者宕机或处理失败而未发送ack,消息会重新返回队列并重新分配给其他消费者。
实现方式:
-
设置消费者的
autoAck参数为false,启用手动应答。 -
消费者在处理完消息后,调用
channel.basicAck()手动确认。 -
boolean autoAck = false; // 手动应答模式channel.basicConsume("my_queue", autoAck, new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag, Envelope envelope, -
AMQP.BasicProperties properties, bytebody) throws IOException {String message = new String(body, "UTF-8");System.out.println("Received message: "message); -
try {// 处理消息// ...(业务逻辑)// 手动应答channel.basicAck(envelope.getDeliveryTag(), false);} catch (Exception e) {// 处理失败,可以选择不应答,或者重新回到队列channel.basicNack(envelope.getDeliveryTag(), false, true);}}});
4. 消息重发与死信队列 (Dead Letter Exchanges - DLX)
目的:处理无法正常消费或被拒绝的消息,确保消息不会意外丢失。
-
当消息无法被正确处理时,可以设置重发机制或将消息转移到死信队列(DLX)中。
-
死信队列是一种特殊的队列,用来存储处理失败、被拒绝或过期的消息,方便后续进行排查和处理。
实现方式:
-
配置队列的
x-dead-letter-exchange参数,指定消息被拒绝或无法消费时要转发的死信交换机。
代码示例:
// 创建死信队列 Map<String, Object> args = new HashMap<>(); args.put("x-dead-letter-exchange", "dlx_exchange"); channel.queueDeclare("my_queue", true, false, false, args);
// 创建死信交换机和队列 channel.exchangeDeclare("dlx_exchange", "direct"); channel.queueDeclare("dlx_queue", true, false, false, null); channel.queueBind("dlx_queue", "dlx_exchange", "dlx_routing_key");
5. 限流机制 (Consumer Prefetching)
目的:防止消费者因为无法及时处理消息导致消息堆积、超时或丢失。
-
RabbitMQ 提供了限流机制,消费者可以通过设置
prefetch值来控制每次最多消费多少条消息,确保消息处理能力不会被超载。 -
这样可以避免消费者因为处理不过来而出现未应答的消息。
实现方式:
-
使用
channel.basicQos()来设置prefetchCount,控制每个消费者最多消费多少条未确认的消息。
代码示例:
int prefetchCount = 10; // 每次最多消费10条消息 channel.basicQos(prefetchCount); // 消费消息 channel.basicConsume("my_queue", false, consumer);
6. 事务机制 (Transactions)
目的:确保消息的发送和处理具备原子性,防止消息在发送或消费过程中丢失或失败。
-
RabbitMQ 支持事务,但事务会影响性能,因此更多情况下会使用发布确认机制(
Publisher Confirms)替代事务。 -
如果需要,可以在发送消息时开启事务,确保消息的发送和处理一致。
实现方式:
try { channel.txSelect();
// 开启事务 channel.basicPublish("", "my_queue", null, "Hello Transaction!".getBytes());
channel.txCommit();
// 提交事务
} catch (Exception e) { channel.txRollback();
// 发生错误时回滚事务 }
7. 集群与高可用模式 (Clustering and High Availability)
目的:确保 RabbitMQ 服务本身的稳定性,防止由于服务宕机导致消息丢失。
-
RabbitMQ 支持集群模式,将多个节点组成集群来提高可用性。
-
可以使用镜像队列,将队列数据复制到集群中的多个节点,确保一个节点宕机后,消息仍然可以被处理。
配置方式:
-
在 RabbitMQ 集群中配置队列策略,将队列设置为镜像模式。
rabbitmqctl set_policy ha-all "^my_queue$" '{"ha-mode":"all"}'
总结
RabbitMQ 通过多种机制来保证消息的稳定性:
-
持久化消息:确保消息存储在磁盘上,防止服务宕机后丢失。
-
发布确认机制:确保生产者能确认消息是否成功发送到队列。
-
消费者手动应答:确保消息被消费者成功处理后才从队列中移除。
-
死信队列:处理失败消息,避免消息丢失。
-
限流机制:防止消费者过载,保证消息被及时处理。
-
集群与高可用:确保 RabbitMQ 服务的稳定性。
这些机制可以结合使用,根据业务需求选择最合适的方式来保证消息的可靠性。
消息队列优缺点
关于消息队列的优点也就是上面列举的,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?如何保证消息队列的高可用,可以点击这里查看。
系统复杂度提高
硬生生加个 MQ 进来,你怎么[保证消息没有重复消费]?怎么[处理消息丢失的情况]?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已。
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。
RabbitMQ出现后,国内大部分公司都从ActiveMQ切换到了RabbitMQ,基本代替了activeMQ的位置。它的社区还是很活跃的。
它的单机吞吐量也是万级,对于需要支持特别高的并发的情况,它是无法担当重任的。
在高可用上,它使用的是镜像集群模式,可以保证高可用。
在消息可靠性上,它是可以保证数据不丢失的,这也是它的一大优点。
同时它也支持一些消息中间件的高级功能,如:消息重试、死信队列等。
rabbitmq问答
135.rabbitmq 的使用场景有哪些?
-
抢购活动,削峰填谷,防止系统崩塌。
-
延迟信息处理,比如 10 分钟之后给下单未付款的用户发送邮件提醒。
-
解耦系统,对于新增的功能可以单独写模块扩展,比如用户确认评价之后,新增了给用户返积分的功能,这个时候不用在业务代码里添加新增积分的功能,只需要把新增积分的接口订阅确认评价的消息队列即可,后面再添加任何功能只需要订阅对应的消息队列即可。
136.rabbitmq 有哪些重要的角色?
rabbitmq 中重要的角色有:生产者、消费者和代理:
-
生产者:消息的创建者,负责创建和推送数据到消息服务器;
-
消费者:消息的接收方,用于处理数据和确认消息;
-
代理:就是 rabbitmq 本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
137.rabbitmq 有哪些重要的组件?
-
ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用。
-
Channel(信道):消息推送使用的通道。
-
Exchange(交换器):用于接受、分配消息。
-
Queue(队列):用于存储生产者的消息。
-
RoutingKey(路由键):用于把生成者的数据分配到交换器上。
-
BindingKey(绑定键):用于把交换器的消息绑定到队列上。
138.rabbitmq 中 vhost 的作用是什么?
vhost:每个 rabbitmq 都能创建很多 vhost,我们称之为虚拟主机,每个虚拟主机其实都是 mini 版的rabbitmq,它拥有自己的队列,交换器和绑定,拥有自己的权限机制。
139.rabbitmq 的消息是怎么发送的?
首先客户端必须连接到 rabbitmq 服务器才能发布和消费消息,客户端和 rabbit server 之间会创建一个 tcp 连接,一旦 tcp 打开并通过了认证(认证就是你发送给 rabbit 服务器的用户名和密码),你的客户端和 rabbitmq 就创建了一条 amqp 信道(channel),信道是创建在“真实” tcp 上的虚拟连接,amqp 命令都是通过信道发送出去的,每个信道都会有一个唯一的 id,不论是发布消息,订阅队列都是通过这个信道完成的。
140.rabbitmq 怎么保证消息的稳定性?
-
提供了事务的功能。
-
通过将 channel 设置为 confirm(确认)模式。
141.rabbitmq 怎么避免消息丢失?
-
把消息持久化磁盘,保证服务器重启消息不丢失。
-
每个集群中至少有一个物理磁盘,保证消息落入磁盘。
142.要保证消息持久化成功的条件有哪些?
-
声明队列必须设置持久化 durable 设置为 true.
-
消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
-
消息已经到达持久化交换器。
-
消息已经到达持久化队列。
以上四个条件都满足才能保证消息持久化成功。
143.rabbitmq 持久化有什么缺点?
持久化的缺地就是降低了服务器的吞吐量,因为使用的是磁盘而非内存存储,从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
144.rabbitmq 有几种广播类型?
-
direct(默认方式):最基础最简单的模式,发送方把消息发送给订阅方,如果有多个订阅者,默认采取轮询的方式进行消息发送。
-
headers:与 direct 类似,只是性能很差,此类型几乎用不到。
-
fanout:分发模式,把消费分发给所有订阅者。
-
topic:匹配订阅模式,使用正则匹配到消息队列,能匹配到的都能接收到。
145.rabbitmq 怎么实现延迟消息队列?
延迟队列的实现有两种方式:
-
通过消息过期后进入死信交换器,再由交换器转发到延迟消费队列,实现延迟功能;
-
使用 rabbitmq-delayed-message-exchange 插件实现延迟功能。
146.rabbitmq 集群有什么用?
集群主要有以下两个用途:
-
高可用:某个服务器出现问题,整个 rabbitmq 还可以继续使用;
-
高容量:集群可以承载更多的消息量。
147.rabbitmq 节点的类型有哪些?
-
磁盘节点:消息会存储到磁盘。
-
内存节点:消息都存储在内存中,重启服务器消息丢失,性能高于磁盘类型。
148.rabbitmq 集群搭建需要注意哪些问题?
-
各节点之间使用“--link”连接,此属性不能忽略。
-
各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
-
整个集群中必须包含一个磁盘节点。
149.rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
不是,原因有以下两个:
-
存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
-
性能的考虑:如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
150.rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,不能进行以下操作:
-
不能创建队列
-
不能创建交换器
-
不能创建绑定
-
不能添加用户
-
不能更改权限
-
不能添加和删除集群节点
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西。
rabbitmq 对集群节点停止顺序有要求吗?
rabbitmq 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
------
消息队列“四大天王”:Rabbit、Rocket、Kafka、Pulsar



基于交换机(Exchange)和队列(Queue)的灵活路由
- 交换机(Exchange):消息发布到交换机,通过路由键(Routing Key)决定消息发送到哪个队列。
- 队列(Queue):消息存储的地方,消费者从队列中获取消息。
- 路由键(Routing Key):用于匹配消息和队列的键。
- 绑定(Binding):连接交换机和队列,定义路由规则。
消息传递模式:
- Direct:消息通过精确匹配路由键发送到队列。
- Fanout:消息广播到所有绑定的队列。
- Topic:消息按模式匹配路由键发送到队列。
1.创建连接工厂,给连接工厂配置账号密码等信息
2.通过连接工厂创建了连接
3.通过连接创建一个通道
4. 为通道声明队列(队列名字,对列是否持久化,是否具有排他性,最后一个消费者消费完之后是否自动删除队列,该队列携带什么参数)
5.准备消息内容
6.发送消息给队列
7.关闭通道
8.关闭连接
为什么RabbitMQ是基于通道(channal)处理,而不是连接(connection)?
connection是一个短连接,短连接会经过三次握手四次挥手,这个过程很慢,耗费资源,耗时长,连接开关会造成很大的性能开销
所以connection在 TCP/IP 的基础之上开发一个长连接的信道,即为channal,channal是网络信道,几乎所有的操作都在chanal中进行,一个connection可以开启多个channal,从而大大提高了性能
2.Rabbitmq为什么需要信道,为什么不是TCP直接通信
1、TCP的创建和销毁,开销大,创建要三次握手,销毁要4次分手。
2、如果不用信道,那应用程序就会TCP连接到Rabbit服务器,高峰时每秒成千上万连接就会造成资源的巨大浪费,而且==底层操作系统每秒处理tcp连接数也是有限制的,==必定造成性能瓶颈。
3、信道的原理是一条线程一条信道,多条线程多条信道同用一条TCP连接,一条TCP连接可以容纳无限的信道,即使每秒成千上万的请求也不会成为性能瓶颈。
3.queue队列到底在消费者创建还是生产者创建?
1:一般建议是在rabbitmq操作面板创建。这是一种稳妥的做法。
2∶按照常理来说,确实应该消费者这边创建是最好,消息的消费是在这边。这样你承受一个后果,可能我生产在生产消息可能会丢失消息。
3:在生产者创建队列也是可以,这样稳妥的方法,消息是不会出现丢失。
4:如果你生产者和消费都创建的队列,谁先启动谁先创建,后面启动就覆盖前面的
4.可以存在没有交换机的队列吗?
不可能存在,虽然没有指定交换机,但是一定会存在一个默认的交换机,因为没有交换机队列就不会存在消息
交换机负责消息的接受,队列不会接收消息,是交换机投递消息给队列,而不是队列去接收消息
//6.发送消息给队列
/**
* @Params1 交换机(最好指定一个叫交换机名字,不然就会使用默认的交换机)
* @Params2 队列,路由key
* @Params3 消息的状态控制
* @Params4 消息主题
*/
channel.basicPublish("",queueName, null,message.getBytes());
5.模式
1.简单模式(default)
通过默认交换机投递消息给指定队列
2.发布订阅模式(fanout)
通过交换机与队列进行绑定,交换机会将消息投递到所有与之绑定的队列
类似于一些粉丝关注一个博主之后,这个博主发布视频,所有订阅这个博主的粉丝都会看到这个视频
3.路由模式(direct)
这个模式是发布订阅模式的延伸,本质还是将交换机与队列进行绑定,但是绑定的同时还要加上 Routing Key ,当交换机投递消息时,带上某个路由key,这条消息就会投递到有这个路由key的队列
可以理解为交换机投递信息给队列的时候要根据某个条件投递,交换机只会投递给满足条件的队列
场景:
当一个用户注册某个平台的账号,会把注册通知发送到邮箱,短信与微信,会对用户造成很大的不便,如果指定某个路由key,在发送注册通知的时候在路由key中带上emai,那么这个通知就只会发到带有路由key “email”的队列中
4.主题模式(tocpic)
这个模式是路由模式的延伸
就是在路由模式的基础上,添加模糊条件绑定功能,其中有#,*两种符号来控制条件
符号#:表示0个或一个或多个
符号*:表示一定要有一个并且只有一个
示例:
#.com.#: 满足这个条件的路由key是(com 或者 xxx.com.xxx或者xxx.com.xxx.xxx等等)
*.com.*:满足这个条件的路由key是(xxx.com.xxx)
#.com.*:满足这个条件的路由key是(xxx.xxx.com.x或者com.xxx)
5.headers模式
这个模式也是通过条件来进行发布消息,这个条件是就是参数
交换机先通过参数绑定队列,比如X=1绑定到queue1
在投递消息的时候携带x=1的参数即可将消息投递到queue1
6.Work模式
轮询分发
轮询分发就是指按均分配,消息分发默认就是轮询分发
轮询分发不依赖于消费者的处理速度,即使两个消费者处理速度相差很大,他们处理的消息数量也是一样的
轮询分发下,消费者消费的时候既可以设置为手动,应可以设置为自动应答
公平分发
公平分发就是按劳分配
消息分发取决于消费者的处理速度,如果消费者处理快,那这个消费者就能处理更多的消息,反之处理更少的消息
公平分发下,消费者消费的时候必须设置为手动应答,如果autoAck参数设置为true,那就会变成轮询分发
//设置为手动应答
finalChannel.basicAck(message.getEnvelope().getDeliveryTag(),false);
相关文章:
Linux Ubuntu 安装配置RabbitMQ,springboot使用RabbitMQ
rabbit-Ubuntu 一篇文章学会RabbitMQ 在Ubuntu上查看RabbitMQ状态可以通过多种方式进行,包括使用命令行工具和Web管理界面。以下是一些常用的方法: 1-使用systemctl命令: sudo systemctl start rabbitmq-server sudo systemctl status ra…...

云数据库 MongoDB
MongoDB 是一个基于文档的 NoSQL 数据库,它与传统的关系型数据库不同,采用的是灵活的文档结构(类似 JSON 格式)。MongoDB 是开源的,且高度可扩展,通常用于处理大量的非结构化或半结构化数据。 云数据库 Mon…...

Ionic 8.4 简介
Ionic 是一个用于开发混合移动应用、渐进式Web应用(PWA)以及桌面应用的开源框架。它结合了 Angular、React 或 Vue.js 等现代前端框架与 Cordova/PhoneGap 的力量,允许开发者使用 Web 技术(HTML, CSS, JavaScript)构建…...

蓝桥杯系列---class1
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 我们今天会再开一个系列,那就是蓝桥杯系列,我们会从最基础的开始讲起,大家想要备战明年蓝桥杯的,让我们一起加油。 工具安装 DevC…...
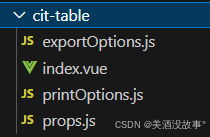
vue3+elementPlus封装的一体表格
目录结构 源码 exportOptions.js export default reactive([{label: 导出本页,key: 1,},{label: 导出全部,key: 2,}, ])index.vue <template><div class"flex flex-justify-between flex-items-end"><div><el-button-group><slot name…...

Junit5 单元测试入门
基础知识 常用注解含义 Test:标记一个方法为测试方法BeforeEach:标记的方法会在每个测试方法执行前执行AfterEach:标记的方法会在每个测试方法执行后执行BeforeAll:标记的方法会在所有测试方法执行前执行一次AfterAll࿱…...

数字信号处理-数学基础
来源哪都有,个人复习使用 一 积分 常用积分公式: 基本积分方法 凑微分法(也称第一换元法): 换元: 分部积分: 卷积 这里有动图解释: https://mathworld.wolfram.com/Convolution.html 欧拉公式 e i x…...

【Exp】# Microsoft Visual C++ Redistributable 各版本下载地址
Microsoft官方页面 https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads Redistributable 2019 X86: https://aka.ms/vs/16/release/VC_redist.x86.exe X64: https://aka.ms/vs/16/release/VC_redist.x64.exe Redistributable 201…...

Hive 分桶表的创建与填充操作详解
Hive 分桶表的创建与填充操作详解 在 Hive 数据处理中,分桶表是一个极具实用价值的功能,它相较于非分桶表能够实现更高效的采样,并且后续还可能支持诸如 Map 端连接等节省时间的操作。不过,值得注意的是,在向表写入数…...

[小白系列]Ubuntu安装教程-安装prometheus和Grafana
Docker安装prometheus 拉取镜像 docker pull prom/prometheus 配置文件prometheus.yml 在/data/prometheus/建立prometheus.yml配置文件。(/data/prometheus/可根据自己需要调整) global:scrape_interval: 15s # By default, scrape targets ev…...

Flask使用长连接
Flask使用flask_socketio实现websocket Python中的单例模式 在HTTP通信中,连接复用(Connection Reuse)是一个重要的概念,它允许客户端和服务器在同一个TCP连接上发送和接收多个HTTP请求/响应,而不是为每个新的请求/响…...

数据分析思维案例:游戏评分低,怎么办?
【面试题】 某款手游在应用市场评分相比同类型游戏处于劣势。 请分析可能的原因并给出相关建议。 【分析思路】 一、明确问题 1. 明确业务指标 定义:应用市场评分一般指某一应用在某个应用市场上线以来的总体平均评分。 除“总体平均评分”以外,部分应用…...

【学习总结|DAY012】Javabean书写练习
一、主要代码 public class Phone {public Phone() {}public Phone(String brand, int price, String color) {this.brand brand;this.price price;this.color color;}String brand;int price;String color;public String getBrand() {return brand;}public void setBrand(…...

Mac环境下brew安装LNMP
安装不同版本PHP 在Mac环境下同时运行多个版本的PHP,同Linux环境一样,都是将后台运行的php-fpm设置为不同的端口号,下面将已php7.2 和 php7.4为例 添加 tap 目的:homebrew仅保留最近的php版本,可能没有你需要的版本…...

openEuler 知:安装系统
文章目录 前言图形化安装文本方式安装 前言 本文只介绍安装过程中需要特别注意的地方,常规的内容需要参考其它文档。 图形化安装 自定义分区: 说明:anaconda 默认分区,在 OSNAME.conf 中进行了配置,openEuler 默认根…...

Zephyr 入门-设备树与设备驱动模型
学习链接:https://www.bilibili.com/video/BV1L94y1F7qS/?spm_id_from333.337.search-card.all.click&vd_source031c58084cf824f3b16987292f60ed3c 讲解清晰,逻辑清楚。 1. 设备树概述(语法,如何配置硬件,c代码如…...

点云标注软件SUSTechPOINTS的安装和使用,自测win10和ubuntu20.04下都可以用
点云标注软件SUSTechPOINTS的安装和使用 github项目源码:https://github.com/naurril/SUSTechPOINTS gitee源码以及使用教程:https://gitee.com/cuge1995/SUSTechPOINTS 首先拉取源码 git clone https://github.com/naurril/SUSTechPOINTS最好是在cond…...

etcd资源超额
集群内apiserver一直重启,重启kubelet服务后查看日志发现一下报错: Error from server: etcdserver: mvcc: database space exceeded 报错原因: etcd服务未设置自动压缩参数(auto-compact) etcd 默认不会自动 compa…...
AndroidStudio-常见界面控件
一、Button package com.example.review01import androidx.appcompat.app.AppCompatActivity import android.os.Bundle import android.widget.Button import android.widget.TextViewclass Review01Activity : AppCompatActivity() {override fun onCreate(savedInstanceStat…...

网络协议(TCP/IP模型)
目录 网络初识 网络协议 协议分层 协议拆分 分层 协议分层的优势 1.封装效果 2.解耦合 TCP/IP五层模型 协议之间配合工作(详解) 网络初识 网络核心概念: 局域网:若干电脑连接在一起,通过路由器进行组网。 …...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...