TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
- 0. 前言
- 1. 神经网络基础
- 1.1 神经网络简介
- 1.2 神经网络的训练
- 1.3 神经网络的应用
- 2. 从零开始构建前向传播
- 2.1 计算隐藏层节点值
- 2.2 应用激活函数
- 2.3 计算输出层值
- 2.4 计算损失值
- 2.4.1 在连续变量预测过程中计算损失
- 2.4.2 在分类(离散)变量预测中计算损失
- 2.4.3 计算网络损失值
- 2.5 使用 Python 实现网络前向传播
- 3. 从零开始构建反向传播
- 小结
0. 前言
神经网络是一种性能强大的学习算法,其灵感来自大脑的运作方式。类似于神经元在大脑中彼此连接的方式,神经网络获取输入后,通过某些函数在网络中进行传递输入信息,连接在其后的一些神经元会被激活,从而产生输出。
1. 神经网络基础
1.1 神经网络简介
人工神经网络 (Artificial Neural Network, ANN) 是人类中枢神经系统研究启发的机器学习模型,每个 ANN 由多个相互连接的“神经元”组成,构成网络“层”,一层的神经元将信息传递给下一层的神经元(称为“激活”),这就是神经网络的计算方式。
神经网络的研究最早始于 1950 年代初期,引入了用于简单操作的“感知器”,随后在1960年代末期,引入了用于高效训练多层网络的“反向传播”算法。在 1980 年代,一些更简单的方法的出现曾一度令神经网络的研究陷入停滞。然而,自 2000 年代中期以来,得益于算法的改进、大型数据集的可用性和能够用于大规模数值计算的图形处理器 (Graphic Processing Unit, GPU),神经网络再次引发了研究热潮。这些研究为深度学习奠定了基础,深度学习模型是一类具有大量神经元(层)的神经网络,能够基于逐步抽象的层次结构训练相当复杂的模型。
从本质上讲,ANN 是对线性回归和逻辑回归的一种改进,神经网络在计算输出时引入了多种非线性函数。此外,神经网络在修改网络体系结构以利用结构化和非结构化数据跨多个域解决问题方面具有极大的灵活性。函数越复杂,网络对于输入的数据拟合能力就越大,因此预测的准确性就越高。神经网络的典型结构如下:

神经网络中的层 (layer) 是一个或多个节点(或称计算单元)的集合,层中的每个节点都连接到下一层中的每个节点。输入层由预测输出值所需的输入变量组成。输出层中节点的数量取决于我们要预测连续变量还是分类变量。如果输出是连续变量,则输出层一个节点。
如果输出结果是 n n n 个类别的预测类的分类,则输出层中将有 n n n 个节点。隐藏层用于将输入层的值转换为高维空间中的值,以便我们可以从输入中了解数据的更多特征。隐藏层中节点的工作方式如下:

在上图中, x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn 是自变量, x 0 x_0 x0 是偏置项,类似于线性方程 y = k x + b y=kx+b y=kx+b 里的 b b b, w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1,w2,...,wn 是赋予每个输入变量的权重。如果 a a a 是隐藏层中的节点之一,则计算方法如下所示:
a = f ( ∑ w i N w i x i ) a=f(\sum _{w_i} ^N w_ix_i) a=f(wi∑Nwixi)
f f f 函数是激活函数,用于在输入和它们相应的权重值的总和上引入非线性。可以通过使用多个隐藏层实现更强的非线性能力。
综上,神经网络是相互连接的层中节点权重的集合。该集合分为三个主要部分:输入层,隐藏层和输出层。神经网络中可以具有 n n n 个隐藏层,术语“深度学习”通常表示具有多个隐藏层的神经网络。 当神经网络需要学习具有复杂上下文(例如图像识别)或上下文不明显的任务时,就必须具有隐藏层,隐藏层也被称为中间层。
1.2 神经网络的训练
训练神经网络实际上就是通过重复两个关键步骤来调整神经网络中的权重:前向传播和反向传播。
- 在前向传播中,我们将一组权重应用于输入数据,将其传递给隐藏层,对隐藏层计算后的输出使用非线性激活,通过若干个隐藏层后,将最后一个隐藏层的输出与另一组权重相乘,就可以得到输出层的结果。对于第一次正向传播,权重的值将随机初始化。
- 在反向传播中,尝试通过测量输出的误差,然后相应地调整权重以降低误差。神经网络重复正向传播和反向传播以预测输出,直到获得令误差较小的权重为止。
1.3 神经网络的应用
最近,神经网络在各种应用中的广泛采用。神经网络可以通过多种方式进行构建,以下是一些常见的构建方法:

底部的紫色框代表输入,其后是隐藏层(中间的黄色框),顶部的粉色框是输出层。一对一的体系结构是典型的神经网络,在输入和输出层之间具有隐藏层。不同体系结构的示例如下:
| 架构 | 示例 |
|---|---|
| one-to-many | 输入是图像,输出是图像的预测类别概率 |
| many-to-one | 输入是电影评论,输出评论是好评或差评 |
| many-to-many | 将一种语言的句子使用神经网络翻译成另一种语言的句子 |
现代神经网络中经常用到的一种架构称为卷积神经网络 (Convolutional Neural Networks, CNN),可以用来理解图像中的内容并检测目标内容所在的位置,该体系架构如下所示(在之后的学习中会进行详细介绍):

神经网络在推荐系统,图像分析,文本分析和音频分析的都有着广泛的应用,神经网络能够灵活地使用多种体系结构解决问题,可以预料的是,神经网络的使用范围将会越来越广。
接下来,我们将根据神经网络训练的两个关键步骤——前向传播和反向传播——介绍神经网络模型的构建。
2. 从零开始构建前向传播
为了进一步了解前向传播的工作方式,我们将通过一个简单的示例来构建神经网络,其中神经网络的输入为 (1, 1),对应的输出为 0。
我们使用的神经网络具有一个隐藏层,一个输入层和一个输出层。由于要使输入层能够以更大的维度表示,因此隐藏层中的神经元数量多于输入层中的神经元。
2.1 计算隐藏层节点值
第一次进行正向传播时,首先需要为所有连接分配权重,这些权重是基于高斯分布随机选择的,但是神经网络训练过程之后的最终权重不需要服从特定分布,假定初始网络权重如下:

接下来,我们将输入与权重相乘以计算隐藏层中隐藏单元的值,隐藏层的节点单位值计算结果如下:
h 1 = 1 × 0.8 + 1 × 0.2 = 1 h 2 = 1 × 0.4 + 1 × 0.9 = 1.3 h 3 = 1 × 0.3 + 1 × 0.5 = 0.8 h_1=1\times 0.8+1\times 0.2 = 1\\ h_2=1\times 0.4+1\times 0.9 = 1.3\\ h_3=1\times 0.3+1\times 0.5 = 0.8 h1=1×0.8+1×0.2=1h2=1×0.4+1×0.9=1.3h3=1×0.3+1×0.5=0.8
下图展示了计算隐藏层的节点值后的网络示意图:

在以上步骤中,我们计算了隐藏节点的值。为简单起见,我们并未在隐藏层的节点中添加偏置项。接下来,我们将通过激活函数传递隐藏层的值,以便在输出中增加非线性。
NOTE:如果我们不在隐藏层中应用非线性激活函数,则神经网络本质上将成为从输入到输出线性连接。
2.2 应用激活函数
可以在网络中的多个网络层中应用激活函数,使用它们可以实现高度非线性,这对于建模输入和输出之间的复杂关系非常关键。在我们的示例中,使用 Sigmoid 激活函数如下所示:
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\frac 1 {1+e^{-x}} sigmoid(x)=1+e−x1
通过将 Sigmoid 激活函数应用于隐藏层,我们得到以下结果:
f i n a l _ h 1 = s i g m o i d ( 1.0 ) = 0.73 f i n a l _ h 2 = s i g m o i d ( 1.3 ) = 0.78 f i n a l _ h 3 = s i g m o i d ( 0.8 ) = 0.69 final\_h_1 = sigmoid(1.0) = 0.73\\ final\_h_2 = sigmoid(1.3) = 0.78\\ final\_h_3 = sigmoid(0.8) = 0.69 final_h1=sigmoid(1.0)=0.73final_h2=sigmoid(1.3)=0.78final_h3=sigmoid(0.8)=0.69
下图展示了隐藏层的应用非线性激活函数后节点值的情况:

关于更多激活函数的介绍,参考《深度学习常用激活函数》。
2.3 计算输出层值
现在我们已经计算了隐藏层的值,最后将计算输出层的值。在下图中,我们将隐藏层值通过随机初始化的权重值连接到输出层。计算隐藏层值和权重值乘积的总和,得到输出值:
o u t p u t = 0.73 × 0.3 + 0.79 × 0.5 + 0.69 × 0.9 = 1.235 output = 0.73\times 0.3+0.79\times 0.5 + 0.69\times 0.9= 1.235 output=0.73×0.3+0.79×0.5+0.69×0.9=1.235
使用隐藏层值和权重值,我们可以得到网络的输出值,如下图所示:

因为第一次正向传播使用随机权重,所以输出神经元的值与目标相差很大,相差为 +1.235 (目标值为0)。
2.4 计算损失值
损失值(也称为成本函数)是在神经网络中优化的值。为了了解如何计算损失值,我们分析以下两种情况:
- 连续变量预测
- 分类(离散)变量预测
2.4.1 在连续变量预测过程中计算损失
通常,当预测值为连续变量时,损失函数使用平方误差,也就是说,我们尝试通过更改与神经网络相关的权重值来最小化均方误差:
J ( θ ) = 1 m ∑ i = 1 m ( h ( x i ) − y i ) 2 J(\theta)=\frac 1 m \sum _{i=1} ^m(h(x_i)-y_i)^2 J(θ)=m1i=1∑m(h(xi)−yi)2
其中, y i y_i yi 是实际值, h ( x ) h(x) h(x) 是我们对输入 x x x 进行变换以获得预测值 y y y 的网络模型, m m m 是输入数据集中的数据个数。
2.4.2 在分类(离散)变量预测中计算损失
当要预测的变量是离散变量时(也就是说,变量中只有几个类别),我们通常使用分类交叉熵损失函数。当要预测的变量具有两个不同的值时,损失函数为二分类交叉熵,而当要预测的变量具有多个不同的值时,损失函数为多分类交叉熵。
- 二分类交叉熵公式如下:
( y l o g ( p ) + ( 1 − y ) l o g ( 1 − p ) ) (ylog(p)+(1−y)log(1−p)) (ylog(p)+(1−y)log(1−p))
- 多分类交叉熵定义如下:
− ∑ i = 1 n y i l o g ( p n ) -\sum _{i=1} ^n y_i log(p_n) −i=1∑nyilog(pn)
其中, y y y 是输入实际对应的真实值, p p p 是输出的预测值, n n n 是数据量的总数。
2.4.3 计算网络损失值
由于我们在以上示例中预测的结果是连续的,因此损失函数值是均方误差,其计算方法如下:
e r r o r = 1.23 5 2 = 1.52 error = 1.235^2 = 1.52 error=1.2352=1.52
2.5 使用 Python 实现网络前向传播
通过以上学习,我们知道了通过在输入数据之上执行以下步骤以在前向传播中可以得出误差值:
- 随机初始化权重
- 通过将输入值乘以权重来计算隐藏层节点值
- 对隐藏层值执行激活
- 将隐藏层值连接到输出层
- 计算平方误差损失
计算所有数据点的平方误差损失值:
import numpy as np
def feed_forward(inputs, outputs, weights):pre_hidden = np.dot(inputs,weights[0])+ weights[1]hidden = 1/(1+np.exp(-pre_hidden))out = np.dot(hidden, weights[2]) + weights[3]squared_error = (np.square(pred_out - outputs))return squared_error
在前面的函数中,我们将输入变量值、权重(如果是第一次迭代,则随机初始化)以及数据集中的实际输出作为 feed_forward 函数的输入。
我们通过对输入和权重进行矩阵乘法来计算隐藏层的值。此外,将偏置值添加到隐藏层中:
pre_hidden = np.dot(inputs,weights[0])+ weights[1]
其中 weights[0] 是权重值,weights[1] 是偏置值,利用此权重和偏置就可以将输入层连接到隐藏层。计算隐藏层的值后,就可以在隐藏层的值上使用激活函数:
hidden = 1/(1+np.exp(-pre_hidden))
通过将隐藏层的输出乘以将隐藏层连接到输出的权重,然后在输出上添加偏置项,来计算隐藏层的输出:
pred_out = np.dot(hidden, weights[2]) + weights[3]
一旦计算出输出,我们就可以计算出每一输入的平方误差损失,如下所示:
squared_error = (np.square(pred_out - outputs))
在前面的代码中,pred_out 是预测输出,而 outputs 是输入应对应的实际输出。通过以上简单的步骤,我们便可以在网络前向传播时计算损失值。
3. 从零开始构建反向传播
在正向传播中,我们将输入层与隐藏层连接到输出层。 在反向传播中,我们使用相反的过程。 每次将神经网络中的每个权重进行少量更改。权重值的变化将对最终损失值(增加或减少的损失)产生影响,我们需要朝着减少损失的方向更新权重。通过每次轻微更新权重并测量权重更新导致的误差变化,我们可以完成以下操作:
- 确定权重更新的方向
- 确定权重更新的幅度
在实施反向传播之前,我们首先了解神经网络的另一重要概念:学习率。学习率有助于我们建立更稳定的算法。例如,在确定权重更新的大小时,我们不会一次性就对其进行大幅度更改,而是采取更谨慎的方法来缓慢地更新权重。这使模型获得更高的稳定性;在之后的学习中,我们还将研究学习率如何帮助提高稳定性。
更新权重以减少误差的整个过程称为梯度下降技术,随机梯度下降是将误差最小化的手段。更直观地讲,梯度代表差异(即实际值和预测值之间的差异),而下降则表示差异减小;随机代表选择随机样本进行训练,并据此做出决策。除了随机梯度下降外,还有许多其他优化技术可以用于减少损失值。之后的学习中,还将讨论不同的优化技术。
反向传播的工作原理如下:
- 利用前向传播过程计算损失值。
- 略微改变所有的权重。
- 计算权重变化对损失函数的影响。
- 根据权重更新是增加还是减少了损失值,在损失减少的方向上更新权重值。
对数据集中的所有数据执行 1 次训练过程(前向传播+反向传播),称为 1 个 epoch。
为了进一步巩固我们对神经网络中反向传播的理解,让我们拟合一个已知的简单函数,查看如何得出权重。假设,待拟合函数为 y = 3 x y = 3x y=3x,我们期望得出权重值和偏置值(分别为 3 和 0)。
| x | 1 | 3 | 4 | 8 | 10 |
|---|---|---|---|---|---|
| y | 3 | 9 | 12 | 24 | 30 |
以上数据集可以表示为线性回归 y = a x + b y = ax + b y=ax+b,我们将尝试计算 a a a 和 b b b 的值(虽然我们已知它们分别是 2 和 0,但我们的目的是研究如何使用梯度下降获得这些值),将 a a a 和 b b b 参数随机初始化为 2.269 2.269 2.269 和 1.01 1.01 1.01 的值。接下来,我们将从零构建反向传播算法,以便清楚地了解如何在神经网络中计算权重。简单起见下,将构建一个没有隐藏层的简单神经网络。
- 初始化数据集,如下所示:
x = np.array([[1], [3], [4], [8], [10]])
y = np.array([[3], [9], [12], [24], [30]])
- 随机初始化权重和偏差值(在尝试确定 y = a x + b y = ax + b y=ax+b 方程中 a a a 和 b b b 的最优值时,只需要一个权重和一个偏置值):
w = np.array([[[2.269]], [[1.01]]])
- 定义神经网络并计算平方误差损失值:
import numpy as np
def feed_forward(inputs, outputs, weights):out = np.dot(inputs, weights[0]) + weights[1]squared_error = np.square(out - outputs)return squared_error
在上述代码中,对输入与随机初始化的权重值进行了矩阵乘法,然后将其与随机初始化的偏置值相加。得到输出值后,便可以计算出实际值与预测值之差的平方误差值。
- 少量增加每个权重和偏置值,并针对每个权重和偏差更新一次计算一个平方误差损失值。
如果平方误差损失值随权重的增加而减小,则权重值应增加,权重值应增加的大小与权重变化减少的损失值的大小成正比。反之亦然。另外,通过学习率确保增加的权重值小于因权重变化而导致的损失值变化,这样可以确保损失值更平稳地减小。
接下来,创建一个名为update_weights的函数,该函数执行反向传播过程以更新在权重,该函数运行epochs次:
from copy import deepcopy
def update_weights(inputs, outputs, weights, epochs): for epoch in range(epochs):
- 将输入通过神经网络传递,以计算权重未更新时的损失:
org_loss = feed_forward(inputs, outputs, weights)
- 确保对权重列表进行深复制,由于权重将在后续步骤中进行操作,深复制可解决由于子变量的更改而影响父变量的问题:
wts_tmp = deepcopy(weights)wts_tmp2 = deepcopy(weights)
- 循环遍历所有权重值,然后对其进行较小的更改 (
+0.0001):
for ix, wt in enumerate(weights): wts_tmp[ix] += 0.0001
- 当权重修改后,计算更新的前向传播损失。计算由于权重的微小变化而造成的损失变化,因为我们要计算所有输入采样的均方误差,因此将损失的变化除以输入的数据数量:
loss = feed_forward(inputs, outputs, wts_tmp)del_loss = np.sum(org_loss - loss)/(0.0001*len(inputs))
以较小的值更新权重,然后计算其对损失值的影响,等效于计算权重变化的导数(即反向梯度传播)。
- 通过损失变化来更新权重。通过将损失的变化乘以一个很小的数字(0.01)来缓慢更新权重,这就是学习率参数:
wts_tmp2[ix] += del_loss*0.01wts_tmp = deepcopy(weights)
- 返回更新的权重和偏差值:
weights = deepcopy(wts_tmp2)
return wts_tmp2
整体 update_weights() 函数如下所示:
from copy import deepcopy
def update_weights(inputs, outputs, weights, epochs): for epoch in range(epochs):org_loss = feed_forward(inputs, outputs, weights)wts_tmp = deepcopy(weights)wts_tmp2 = deepcopy(weights)for ix, wt in enumerate(weights): wts_tmp[ix] += 0.0001loss = feed_forward(inputs, outputs, wts_tmp)del_loss = np.sum(org_loss - loss)/(0.0001*len(inputs))wts_tmp2[ix] += del_loss*0.01wts_tmp = deepcopy(weights)weights = deepcopy(wts_tmp2)return wts_tmp2
通过更新网络 1000 次,查看训练后网络中的参数和偏置值:
weights = update_weights(x, y, w, 1000)
print(weights)
打印权重如下所示,可以看到其与预期的结果 (w=3.0, b=0.0) 非常接近:
[[[2.99929065]][[0.00478785]]]
神经网络中的还有一个重要参数是在计算损失值时需要考虑的批大小 (batch size)。在以上示例中,我们同时为所有数据计算损失值。但是,当我们有成千上万个数据时,在计算损失值时增加大量数据的增量贡献将导致训练困难,甚至可能超出内存上限无法计算,因此通常在一个 epoch 中将数据分为多个 batch 送入网络进行训练,建立模型时常用的 batch 大小在 16 ~ 512 之间。
小结
在本文中, 我们了解了神经网络的相关基础知识,同时看到了神经网络常见的模型架构与其在实际中的广泛应用,同时利用 Python 从零开始实现了神经网络的训练过程——前向传播和反向传播,了解了神经网络的通用训练流程。
相关文章:
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解 0. 前言1. 神经网络基础1.1 神经网络简介1.2 神经网络的训练1.3 神经网络的应用 2. 从零开始构建前向传播2.1 计算隐藏层节点值2.2 应用激活函数2.3 计算输出层值2.4 计算损失值2.4.1 在连续变…...

03篇--二值化与自适应二值化
二值化 定义 何为二值化?顾名思义,就是将图像中的像素值改为只有两种值,黑与白。此为二值化。 二值化操作的图像只能是灰度图,意思就是二值化也是一个二维数组,它与灰度图都属于单信道,仅能表示一种色调…...
脚本)
基于python的一个简单的压力测试(DDoS)脚本
DDoS测试脚本 声明:本文所涉及代码仅供学习使用,任何人利用此造成的一切后果与本人无关 源码 import requests import threading# 目标URL target_url "http://47.121.xxx.xxx/"# 发送请求的函数 def send_request():while True:try:respo…...

基于 Spring Boot 实现图片的服务器本地存储及前端回显
??导读:本文探讨了在网站开发中图片存储的各种方法,包括本地文件系统存储、对象存储服务(如阿里云OSS)、数据库存储、分布式文件系统及内容分发网络(CDN)。文中详细对比了这些方法的优缺点,并…...

深入 TCP VJ-Style
接着 TCP 的文化内涵 继续扯一会儿。 自 30 instruction TCP receive 往前追溯,论文 Jacobson88 源自第一次拥塞崩溃,这篇著名文档在同时期的另一个缘起是另一篇考古文献 [Zhang86] Why TCP Timers Don’t Work Well,后面这篇文献提出了 TCP…...

go高性能单机缓存项目
代码 // Copyright 2021 ByteDance Inc. // // Licensed under the Apache License, Version 2.0 (the "License"); // you may not use this file except in compliance with the License. // You may obtain a copy of the License at // // http://www.apach…...

数据结构绪论
文章目录 绪论数据结构三要素算法 🏡作者主页:点击! 🤖数据结构专栏:点击! ⏰️创作时间:2024年12月12日01点09分 绪论 数据是信息的载体,描述客观事物属性的数、字符及所有能输入…...

前端开发常用四大框架学习难度咋样?
前端开发常用四大框架指的是 jQuery vue react angular jQuery: 学习难度:相对较低特点:jQuery 是一个快速、小巧、功能丰富的 JavaScript 库。它使得 HTML 文档遍历和操作、事件处理、动画和 Ajax 交互更加简单。适用场景&a…...

OWASP 十大安全漏洞的原理
1. Broken Access Control(访问控制失效) 原理:应用程序未正确实施权限检查,导致攻击者通过篡改请求、强制浏览或权限提升等手段绕过访问控制。 攻击手段: 修改 URL、HTML、或 API 请求以访问未经授权的资源。 删除…...

论文 | ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
本文详细介绍了一种新颖的检索增强生成(Retrieval-Augmented Generation, RAG)系统方法——ChunkRAG,该方法通过对文档的分块语义分析和过滤显著提升了生成系统的准确性和可靠性。 1. 研究背景与问题 1.1 检索增强生成的意义 RAG系统结合…...

ORACLE SQL思路: 多行数据有相同字段就合并成一条数据 分页展示
数据 分数表: 学号,科目名(A,B,C),分数 需求 分页列表展示, 如果一个学号的科目有相同的分数, 合并成一条数据,用 拼接 科目名 ORACLE SQL 实现 SELECT Z.*, SUBSTR(DECODE(f…...
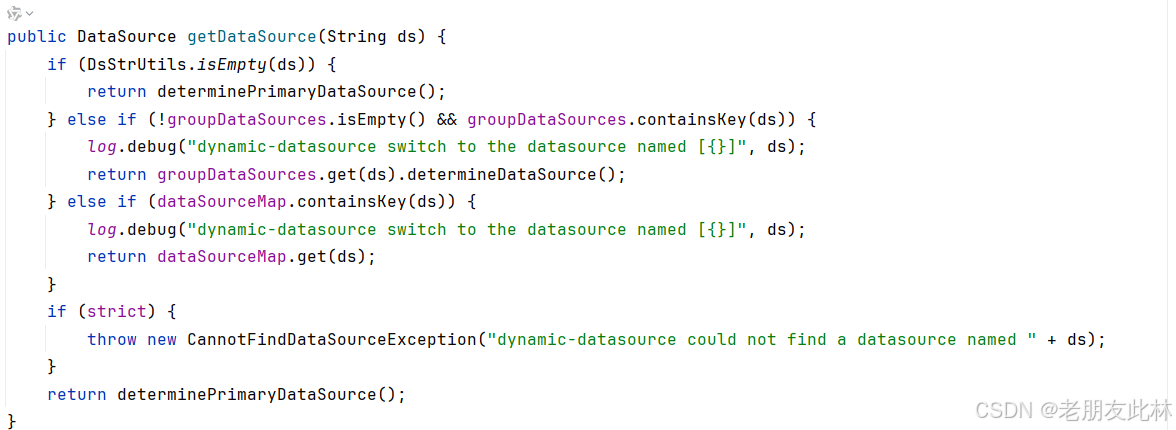
SpringBoot 手动实现动态切换数据源 DynamicSource (中)
大家好,我是此林。 SpringBoot 手动实现动态切换数据源 DynamicSource (上)-CSDN博客 在上一篇博客中,我带大家手动实现了一个简易版的数据源切换实现,方便大家理解数据源切换的原理。今天我们来介绍一个开源的数据源…...
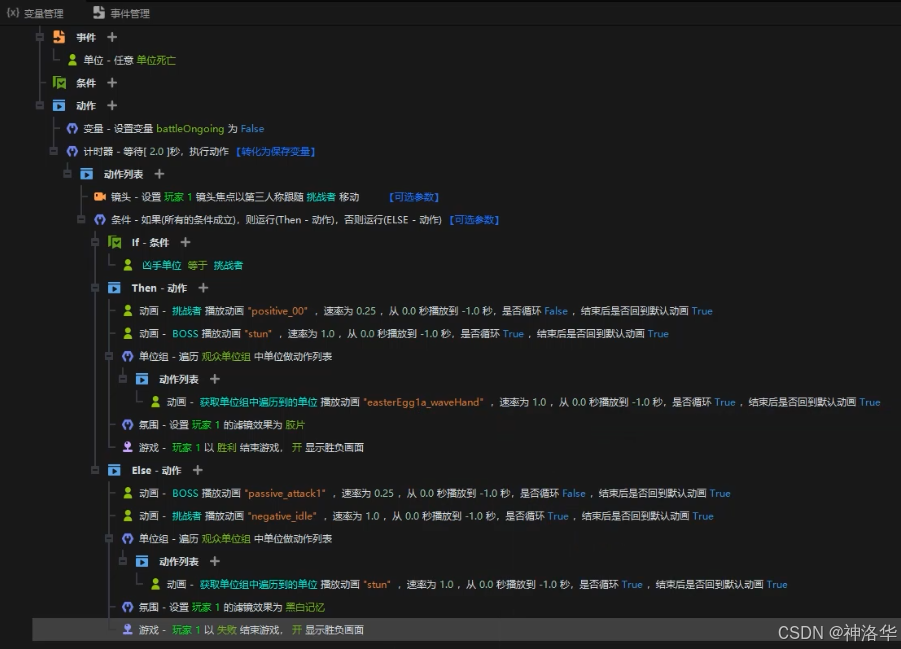
y3编辑器教学5:触发器2 案例演示
文章目录 一、探索1.1 ECA1.1.1 ECA的定义1.1.2 使用触发器实现瞬间移动效果 1.2 变量1.2.1 什么是变量1.2.2 使用变量存储碎片收集数量并展现 1.3 if语句(魔法效果挂接)1.3.1 地形设置1.3.2 编写能量灌注逻辑1.3.3 编写能量灌注后,实现传送逻…...

数值分析——插值法(二)
文章目录 前言一、Hermite插值1.两点三次Hermite插值2.两点三次Hermite插值的推广3.非标准型Hermite插值 二、三次样条插值1.概念2.三弯矩方程 前言 之前写过Lagrange插值与Newton插值法的内容,这里介绍一些其他的插值方法,顺便复习数值分析. 一、Hermi…...
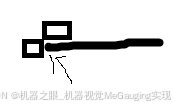
杨振宁大学物理视频中黄色的字,c#写程序去掉
先看一下效果:(还有改进的余地) 写了个程序消除杨振宁大学物理中黄色的字 我的方法是笨方法,也比较刻板。 1,首先想到,把屏幕打印下来。c#提供了这样一个函数: Bitmap bmp new Bitmap(640, 48…...

uni-app 设置缓存过期时间【跨端开发系列】
🔗 uniapp 跨端开发系列文章:🎀🎀🎀 uni-app 组成和跨端原理 【跨端开发系列】 uni-app 各端差异注意事项 【跨端开发系列】uni-app 离线本地存储方案 【跨端开发系列】uni-app UI库、框架、组件选型指南 【跨端开…...

微信小程序base64图片与临时路径互相转换
1、base64图片转临时路径 /*** 将base64图片转临时路径* param {*} dataurl* param {*} filename* returns*/base64ImgToFile(dataurl, filename "file") {const base64 dataurl; // base64码const time new Date().getTime();const imgPath wx.env.USER_DATA_P…...

蓝桥杯刷题——day2
蓝桥杯刷题——day2 题目一题干题目解析代码 题目二题干解题思路代码 题目一 题干 三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要…...

5.删除链表的倒数第N个节点
19.删除链表的倒数第N个节点 题目: 19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode) 分析: 要删除倒数第几个节点,那么我们需要怎么做呢?我们需要定义两个指针,快指针和慢指针,…...

自己总结:selenium高阶知识
全篇大概10000字(含代码),建议阅读时间30min 一、等待机制 如果有一些内容是通过Ajax加载的内容,那就需要等待内容加载完毕才能进行下一步操作。 为了避免人为操作等待,会遇到的问题, selenium将等待转换…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...