【机器学习】【集成学习——决策树、随机森林】从零起步:掌握决策树、随机森林与GBDT的机器学习之旅
这里写目录标题
- 一、引言
- 机器学习中集成学习的重要性
- 二、决策树 (Decision Tree)
- 2.1 基本概念
- 2.2 组成元素
- 2.3 工作原理
- 分裂准则
- 2.4 决策树的构建过程
- 2.5 决策树的优缺点
- (1)决策树的优点
- (2)决策树的缺点
- (3)过拟合问题及解决方法
- 2.6 举例说明
- 三、随机森林 (Random Forest)
- 3.1 基本概念
- 3.2 工作原理
- 构建过程
- 随机森林的预测过程
- 数学公式说明
- 3.3 应用场景
- 实例说明
- 3.4 随机森林的优缺点
- (1)随机森林的优点
- (2)随机森林的缺点
- 四、 梯度提升决策树 (Gradient Boosting Decision Tree, GBDT)
- 4.1 基本概念
- 关键术语
- 提升法的基本思想
- 4.2 工作原理
- (1)初始化模型
- (2)迭代训练
- (3)梯度计算
- (4)停止条件
- (5)最终预测:
- 4.3 应用场景
- 4.4 GBDT的优缺点
- GBDT的优点
- GBDT的缺点
- 4.5 举例说明
- 4.6 实际应用中的考虑
- 五、三种方法对比分析
- 5.1 工作方式对比
- 决策树 (Decision Tree)
- 随机森林 (Random Forest)
- GBDT (Gradient Boosting Decision Tree)
- 5.2 各自的优点与局限性
- 5.3 实际应用中如何选择合适的模型
- 六、案例实战
- 6.1 基于决策树的案例实战——房价预测
- 问题背景
- 解题步骤
- 1.数据生成:
- 2.数据转换:
- 3.数据集分割:
- 4.模型创建与训练:
- 5.模型预测:
- 6.模型评估:
- 7.数据可视化:
- 8.特征重要性输出:
- 决策树解决结果
- 完整代码
- 6.2 基于随机森林的案例实战——房价预测
- 问题背景
- 解题步骤
- 1. 数据准备
- 2. 数据处理
- 3. 模型训练
- 4. 模型评估
- 随机森林解决结果
- 完整代码
- 七、总结
一、引言
在机器学习领域,集成学习(Ensemble Learning)是一种强大的技术,它通过组合多个模型来提高预测性能,增强模型的泛化能力。集成学习的核心思想是“三个臭皮匠,赛过诸葛亮”,即多个弱模型的组合往往能够胜过单一的强模型。在众多集成学习方法中,决策树、随机森林和梯度提升决策树(GBDT)是最为常见且强大的几种。
机器学习中集成学习的重要性
集成学习通过构建并结合多个学习器来提升模型的性能,主要目的是减少模型的偏差和方差,从而提高模型的准确性和稳定性。在实际应用中,集成学习模型通常能够提供比单一模型更可靠的预测结果。在众多机器学习算法中,基于树的模型占据了重要的位置。这类模型以树形结构表示决策过程,每个内部节点代表一个属性上的测试,每个分支代表一个测试结果,而每个叶节点则代表一种类别或输出值。这种直观的结构使得树模型不仅易于解释,而且对于非专业用户来说也更容易理解。
具体来说,决策树作为最基础的树模型,提供了一个简单但强大的框架;随机森林通过集成多棵决策树,进一步提高了模型的准确性和稳定性;**梯度提升决策树(GBDT)**则引入了序列化构建弱学习器的思想,通过逐步优化模型,实现了更高的预测性能。这三种模型各有千秋,在不同的应用场景下发挥着不可替代的作用。
接下来,我们将分别深入探讨这三种树模型的基本概念、工作原理以及它们之间的区别与联系。

二、决策树 (Decision Tree)
决策树是一种监督学习方法,广泛应用于分类和回归任务中。它以直观的树形结构表示数据,每个节点代表一个属性上的测试,每个分支代表一个测试结果,而每个叶节点则代表一种类别或输出值。它是一种常见的机器学习算法,它模仿人类决策过程,通过一系列问题对数据进行分类或回归。
2.1 基本概念
想象一下你正在玩一个猜谜游戏,比如“二十个问题”。每当你问一个问题时,对方的回答(是/否)会引导你提出下一个问题。最终,通过一系列的问题,你可以确定答案。决策树的工作方式与此类似,它是一系列规则的集合,这些规则帮助我们根据某些特征做出决定或分类。
决策树是一种树形结构,其中每个内部节点代表一个属性上的测试,每个分支代表测试的一个结果,每个叶节点代表一个分类或回归结果,用于分类和回归任务。它通过学习简单的决策规则来预测结果。最早的决策树算法由Hunt等人于1966年提出,称为Hunt算法,它是许多决策树算法的基础,包括ID3、C4.5和CART等。但直到1986年,J. R. Quinlan提出的ID3算法才使得决策树在机器学习领域得到广泛应用。
2.2 组成元素
-
节点(Node):就像一棵真实的树有分支点一样,决策树也有节点。每个节点代表一个问题或条件。分为两种类型:
- 内部节点:这些节点用于做决定的地方。例如,“年龄是否大于30岁?”。
- 叶节点:当所有问题都回答完毕后,到达这里得出结论。例如,“购买电脑”。
-
分支(Branch):从一个节点引出的线段表示不同可能的答案。比如对于“年龄是否大于30岁?”这个问题,会有两个分支:“是”和“否”。
-
根节点(Root Node):这是整个决策过程的起点,通常位于图表的顶部。例如,在上面的例子中,“年龄是否大于30岁?”就是根节点。
举个简单的例子,假设我们要建立一个决策树来决定一个人是否会喜欢某部电影。我们可以从根节点开始问“这个人是否喜欢科幻片?”,如果答案是肯定的,那么我们继续问“他是否看过这部电影的导演之前的作品?”;如果答案是否定的,我们可能会直接得出结论说这个人可能不会喜欢这部电影。
2.3 工作原理
分裂准则
在构建决策树时,我们需要知道如何选择最好的问题来分割数据。这涉及到一些数学公式,但我会尽量用简单的语言解释它们。
- 熵(Entropy):熵是用来衡量混乱程度的一个术语。在决策树中,它告诉我们一组数据的混合度。如果我们有一组数据完全由同一类样本组成(例如全是喜欢科幻片的人),那么它的熵很低;相反,如果数据中包含多种类别(例如一半人喜欢科幻片,另一半不喜欢),则熵较高。熵的计算公式如下:
H ( S ) = − ∑ i = 1 C p i log 2 p i H(S) = -\sum_{i=1}^{C} p_i \log_2 p_i H(S)=−i=1∑Cpilog2pi
其中 p i p_i pi 是指属于第 i i i类样本的比例。这个公式看起来复杂,但其实只是在计算各类别概率的加权平均值。
- 信息增益(Information Gain):当我们选择了一个属性进行分裂后,我们会看到数据变得更加有序,即熵减少了。信息增益就是这种减少量。它告诉我们,选择某个属性作为分裂标准能让我们获得多少新的信息。计算方法为:
I G ( A ) = H ( S ) − ∑ v ∈ V a l u e s ( A ) ∣ S v ∣ ∣ S ∣ H ( S v ) IG(A) = H(S) - \sum_{v \in Values(A)} \frac{|S_v|}{|S|} H(S_v) IG(A)=H(S)−v∈Values(A)∑∣S∣∣Sv∣H(Sv)
这里 S v S_v Sv 表示根据属性A的不同取值划分出来的子集。
- 基尼不纯度(Gini Impurity):基尼不纯度也是一种衡量数据混合度的方法。它更倾向于选择二元分割(即只有两种结果)。其计算公式为:
G i n i ( S ) = 1 − ∑ i = 1 C p i 2 Gini(S) = 1 - \sum_{i=1}^{C} p_i^2 Gini(S)=1−i=1∑Cpi2
通过比较不同的分裂准则,我们可以找到最适合当前数据集的那一个。
2.4 决策树的构建过程
构建一棵决策树就像是玩一个问答游戏。以下是具体步骤:
- 初始化:首先,我们把所有的训练数据放在根节点上。
- 选择最佳分割属性:接下来,我们尝试找出哪个属性能够最好地区分不同的类别。例如,在预测电影喜好时,可能是“是否喜欢科幻片”或者“是否看过导演的其他作品”。我们使用前面提到的信息增益或其他分裂准则来评估每个属性的好坏。
- 创建分支:一旦选定了一个属性,我们就根据它的不同取值创建分支。例如,对于“是否喜欢科幻片”,我们将有两个分支:“是”和“否”。
- 递归构建子树:然后,我们重复上述过程,直到不能再进一步细分为止。也就是说,对于每个分支上的数据子集,我们再次选择最佳属性并创建新的分支。
- 生成叶节点:最后,当无法再继续分裂时,我们就到达了叶节点,并在这里给出最终的分类结果或预测值。
2.5 决策树的优缺点
(1)决策树的优点
-
易于理解和解释:
- 决策树的结果可以被可视化为树状图,这种图形表示方式使得非技术人员也能够轻松理解模型的工作原理和预测逻辑。
-
不需要数据预处理:
- 决策树对输入数据的要求较低,不需要像其他一些算法那样进行归一化或标准化处理。它们可以直接处理数值型、分类型以及缺失值的数据。
-
非参数模型:
- 决策树是基于规则的模型,不依赖于特定的数据分布假设,因此适用于各种类型的数据集。
-
可以处理非线性关系:
- 决策树能够捕捉到特征之间的复杂非线性关系,而无需显式地定义这些关系。
(2)决策树的缺点
-
容易过拟合:
- 如果没有适当的限制条件,决策树可能会过度拟合训练数据,即模型过于精确地记住了训练样本中的细节,从而导致泛化能力差,在未见过的新数据上的表现不佳。
-
不稳定:
- 决策树对数据变化敏感,即使是微小的数据变动也可能导致生成完全不同的树结构,进而影响预测结果的一致性和可靠性。
-
不适合连续变量:
- 虽然决策树可以处理连续变量,但与离散变量相比,连续变量的分裂点选择更加复杂,可能导致性能下降或者需要额外的计算成本。
为了克服上述缺点,实践中经常使用集成方法如随机森林(Random Forests)和梯度提升决策树(GBDT),这些方法通过组合多棵决策树来提高模型的稳定性和准确性,同时也降低了过拟合的风险。
(3)过拟合问题及解决方法
过拟合是决策树训练过程中一个常见的问题,指的是模型过于关注训练数据中的细节,以至于在新数据上表现不佳。想象一下,如果你在一个游戏中总是记住对手每次出招的方式,而不是理解他们的策略,那么面对不同的对手时就会遇到麻烦。决策树也是一样,如果它试图记住每一个训练样本,就会失去泛化能力。
解决过拟合的方法
- 预剪枝(Pre-pruning):这意味着在树还没有完全生长出来之前就提前停止。例如,我们可以设定一个最大深度,或者规定每个节点至少需要多少样本才能继续分裂。
- 后剪枝(Post-pruning):另一种方法是先让树充分生长,然后再去掉那些不必要的部分。例如,我们可以移除那些导致验证集误差增加的节点。还可以采用代价复杂度剪枝(Cost Complexity Pruning, CCP),通过引入一个正则化参数α来平衡树的复杂度和训练误差。
2.6 举例说明
假设我们有一组数据,包含天气和是否去打网球的信息:
| 天气 | 温度 | 湿度 | 风速 | 是否打网球 |
|---|---|---|---|---|
| 晴 | 热 | 高 | 弱 | 否 |
| 晴 | 热 | 高 | 强 | 否 |
| 阴 | 热 | 高 | 弱 | 是 |
| … | … | … | … | … |
构建决策树的过程可能如下:
- 计算每个属性的熵或基尼不纯度,选择最优的分裂属性(例如“天气”)。
- 根据天气的不同取值(晴、阴、雨)分裂数据集。
- 对每个子集递归执行上述步骤,直到满足停止条件。
这个过程可以用以下伪代码表示:
def build_tree(data, split_criterion):if stopping_condition(data):return create_leaf_node(data)best_attribute = choose_best_attribute(data, split_criterion)tree = create_node(best_attribute)for value in best_attribute.values:subtree = build_tree(split_data(data, best_attribute, value), split_criterion)add_branch(tree, value, subtree)return tree
最后建立起来的决策树可能就是:

三、随机森林 (Random Forest)
随机森林是一种集成学习方法,它通过构建多个决策树并进行投票来提高预测的准确性和稳定性。
3.1 基本概念
随机森林是由Leo Breiman在2001年提出的一种算法,它基于决策树集成(Decision Tree Ensemble)的思想。随机森林通过在训练过程中引入随机性来提高模型的泛化能力,减少过拟合的风险。
随机森林中的每棵树都是一棵决策树,但这些树在训练时并不是使用全部的数据集,而是使用从原始数据集中随机抽取的样本集来训练。同时,在构建每棵树的每个节点时,也不是考虑所有的特征,而是随机选择一部分特征来决定最优的分裂点。与单棵决策树相比,随机森林能够提供更高的准确性和稳定性,因为它减少了单一决策树可能存在的过拟合问题。
随机森林的“随机”体现在两个方面:
-
数据集的随机选取:在训练过程中,每棵树不是基于整个原始数据集构建的,而是从原始数据集中随机抽取一定数量的样本(通常是放回抽样,也称为Bootstrap抽样)。这意味着每棵树都是基于不同的子集进行训练的。
-
特征的随机选取:在选择分裂属性时,随机森林不会考虑所有特征,而是在每个节点上随机选择一部分特征作为候选,然后从中挑选最佳的分裂点。这种做法增加了模型的多样性,有助于提高整体性能。
3.2 工作原理
构建过程
-
准备阶段:
- 收集并准备好用于训练的数据集。假设我们有一个包含 N N N 个样本的数据集 D \mathcal{D} D.
-
生成多棵决策树:
- 对于每一棵树 T i T_i Ti ( i = 1 , 2 , . . . , B i = 1, 2, ..., B i=1,2,...,B),其中 B B B是随机森林中树的数量:
- Bootstrap抽样:从原始数据集 D \mathcal{D} D 中有放回地随机抽取 N N N 个样本形成新的训练集 D i \mathcal{D}_i Di。注意,某些样本可能会被多次选中,而另一些则可能完全不出现。
- 特征随机选取:在每个内部节点处,随机选择 m m m 个特征( m < M m < M m<M),其中 M M M 是总特征数),然后根据选定的分裂准则(如信息增益、基尼不纯度等)确定最佳分裂点。
- 递归分裂:重复上述步骤直到满足停止条件(例如,所有样本属于同一类别、没有更多可用特征等)。
- 生成叶节点:当无法继续分裂时,将当前节点标记为叶节点,并赋予其多数类标签(分类问题)或平均值(回归问题)。
- 对于每一棵树 T i T_i Ti ( i = 1 , 2 , . . . , B i = 1, 2, ..., B i=1,2,...,B),其中 B B B是随机森林中树的数量:
-
组合预测结果:
- 对于分类问题,随机森林通过对所有树的预测结果进行投票,选择得票最多的类别作为最终预测。
- 对于回归问题,则取所有树预测结果的平均值作为最终输出。
随机森林的预测过程
随机森林的预测过程包括以下步骤:
- 输入样本:将待预测的样本输入到每个决策树中。
- 决策树预测:每个决策树根据其自身的结构和规则,输出一个预测结果。
- 结果汇总:对于分类任务,随机森林的输出是所有决策树输出的众数;对于回归任务,随机森林的输出是所有决策树输出的平均值。
数学公式说明
为了更清晰地描述随机森林的工作机制,我们可以引入一些数学符号:
- 设 X = ( x 1 , x 2 , . . . , x M ) X = (x_1, x_2, ..., x_M) X=(x1,x2,...,xM) 表示一个输入样本,其中 x j x_j xj 是第 j j j 个特征。
- 每棵树 T i T_i Ti的输出可以表示为 f i ( X ) f_i(X) fi(X),对于分类问题是类别标签,对于回归问题是数值预测。
- 对于分类问题,随机森林的最终预测可以表示为:
F R F ( X ) = argmax y ( 1 B ∑ i = 1 B I ( f i ( X ) = y ) ) F_{RF}(X) = \text{argmax}_{y} \left( \frac{1}{B} \sum_{i=1}^{B} \mathbb{I}(f_i(X) = y) \right) FRF(X)=argmaxy(B1i=1∑BI(fi(X)=y))
这里 I ( ⋅ ) \mathbb{I}(\cdot) I(⋅)是指示函数,当条件成立时返回1,否则返回0; argmax y \text{argmax}_{y} argmaxy 表示找出使得括号内表达式最大的 y y y 值。
- 对于回归问题,随机森林的最终预测是所有树预测值的平均:
F R F ( X ) = 1 B ∑ i = 1 B f i ( X ) F_{RF}(X) = \frac{1}{B} \sum_{i=1}^{B} f_i(X) FRF(X)=B1i=1∑Bfi(X)
3.3 应用场景
随机森林广泛应用于分类和回归任务中,尤其是在处理高维数据、存在噪声或缺失值的情况下表现尤为出色。由于其强大的泛化能力和相对简单的实现方式,随机森林成为了许多实际应用中的首选算法之一。
实例说明
想象一下你正在玩一个猜数字的游戏,规则是从1到100之间猜一个数字。如果只有一棵树参与这个游戏,它可能会因为运气不好而猜错很多次。但是如果你有100棵树一起玩这个游戏,每棵树独立地猜测一次,最后你们一起讨论并选择最常被提到的那个数字作为答案,那么成功的几率就会大大增加。这就是随机森林的思想——通过集体智慧做出更好的决策。
3.4 随机森林的优缺点
(1)随机森林的优点
- 减少过拟合:由于每棵树都是基于不同子集训练的,并且每次分裂时只考虑部分特征,因此随机森林不容易过拟合。
- 提高准确性:通过集成多棵树的结果,随机森林通常能获得比单棵决策树更好的性能。
- 处理缺失值和异常值:随机森林可以很好地应对数据中的缺失值和异常值,因为它不需要对输入数据做太多预处理。
- 并行计算友好:由于每棵树可以独立训练,因此非常适合并行计算环境。
(2)随机森林的缺点
- 计算资源需求较高:构建和评估大量决策树需要更多的内存和时间。
- 难以解释:虽然单棵决策树很容易解释,但当涉及到成百上千棵树时,解释变得复杂得多。
- 对高度相关的特征敏感:如果数据集中存在高度相关的特征,随机森林可能会倾向于优先选择这些特征,从而影响模型的稳定性和准确性。
四、 梯度提升决策树 (Gradient Boosting Decision Tree, GBDT)
梯度提升决策树是一种强大的机器学习算法,它通过迭代地训练决策树来最小化损失函数,常用于分类和回归问题。
4.1 基本概念
GBDT是由Jerome Friedman在2001年提出的一种提升(Boosting)算法。提升是一种集成学习技术,它通过顺序地训练一系列模型并将它们组合起来,每个新模型都尝试纠正前一个模型的错误。GBDT的核心思想是利用损失函数的负梯度来训练一系列的决策树,每棵树都是为了减少之前模型的残差(即预测值与真实值之间的差异)。
GBDT是一种集成学习方法,它通过构建一系列的弱学习器(通常是决策树),并将它们按顺序组合起来,以逐步优化预测结果。与随机森林不同的是,GBDT中的每棵树都是基于前一棵树的误差进行改进的,因此它是一种序列化的模型。
关键术语
- 残差: 在回归问题中,残差是预测值与真实值之间的差异。
- 梯度: 在数学中,梯度是一个向量,指向函数在给定点的最大增加方向。在GBDT中,梯度是损失函数对模型预测的导数。
- 提升: 一种集成学习技术,通过结合多个弱学习器来构建一个强学习器。
提升法的基本思想
提升法(Boosting)的核心思想是通过结合多个弱学习器来构建一个强学习器。这里的“弱”指的是单个学习器的表现仅略好于随机猜测。在GBDT中,每一棵新的树都会尝试纠正之前所有树的错误,从而逐渐提高整体模型的性能。
4.2 工作原理
(1)初始化模型
GBDT开始于一个初始模型,通常是一个常数,这个常数是目标变量的平均值(对于回归问题)或者类别的先验概率(对于分类问题)。
(2)迭代训练
GBDT的训练过程是一个迭代过程,每次迭代都会训练一棵新的决策树来拟合当前模型的残差。以下是详细的步骤:
-
计算残差: 对于每个样本,计算当前模型预测的残差,即真实值与当前模型预测值之间的差异。
对于回归问题,残差 r t i r_{ti} rti 可以表示为:
r t i = y i − y ^ t − 1 ( x i ) r_{ti} = y_i - \hat{y}_{t-1}(x_i) rti=yi−y^t−1(xi)
其中, y i y_i yi 是真实值, y ^ t − 1 ( x i ) \hat{y}_{t-1}(x_i) y^t−1(xi) 是前 t − 1 t-1 t−1 棵树对样本 x i x_i xi 的累积预测。 -
拟合残差: 使用决策树来拟合这些残差。决策树的目标是最小化残差的平方和(或其他损失函数)。
-
更新模型: 将新训练的决策树添加到模型中,用于下一次迭代的预测。
模型的更新可以表示为:
y ^ t ( x ) = y ^ t − 1 ( x ) + η ⋅ f t ( x ) \hat{y}_t(x) = \hat{y}_{t-1}(x) + \eta \cdot f_t(x) y^t(x)=y^t−1(x)+η⋅ft(x)
其中, η \eta η 是学习率, f t ( x ) f_t(x) ft(x) 是第 t t t 棵树对样本 x x x 的预测。 -
重复过程: 重复步骤1到3,直到达到预定的迭代次数或残差足够小。
(3)梯度计算
在GBDT中,梯度是损失函数对模型预测值的导数。对于不同的损失函数,梯度的计算方式也不同。以下是一些常见损失函数的梯度:
- 平方损失(回归问题):
∇ y ^ L ( y , y ^ ) = y ^ − y \nabla_{\hat{y}} L(y, \hat{y}) = \hat{y} - y ∇y^L(y,y^)=y^−y - 对数损失(分类问题):
∇ y ^ L ( y , y ^ ) = y ^ − y y ^ ( 1 − y ^ ) \nabla_{\hat{y}} L(y, \hat{y}) = \frac{\hat{y} - y}{\hat{y}(1 - \hat{y})} ∇y^L(y,y^)=y^(1−y^)y^−y
(4)停止条件
GBDT的训练过程通常有以下停止条件:
- 达到预定的迭代次数。
- 残差的变化小于某个阈值。
- 新添加的决策树对模型的改进非常小。
(5)最终预测:
当所有树都构建完毕后,我们可以得到最终的预测值 (\hat{y}_i^{(M)})。对于分类问题,可能还需要经过一个转换步骤(如Sigmoid函数)将预测值映射到概率空间。
4.3 应用场景
GBDT广泛应用于分类和回归任务中,尤其适合处理结构化数据。由于其强大的泛化能力和高准确性,GBDT成为了许多实际应用中的首选算法之一,如广告点击率预测、信用评分等。
4.4 GBDT的优缺点
GBDT的优点
- 高效利用数据:GBDT能够充分利用训练数据中的信息,尤其是那些难以被其他模型捕捉到的复杂模式。
- 处理非线性关系:GBDT可以很好地处理特征之间的非线性关系,而无需显式地定义这些关系。
- 鲁棒性强:由于它是基于残差进行优化的,GBDT对异常值和噪声具有较好的抵抗能力。
- 支持多种损失函数:除了常见的均方误差(MSE)外,GBDT还可以使用其他损失函数(如对数损失、Huber损失等),适用于不同类型的任务。
GBDT的缺点
- 容易过拟合:如果参数设置不当或树的数量过多,GBDT可能会过度拟合训练数据,导致泛化能力下降。因此,适当的调参非常重要。
- 计算资源需求较高:相比于随机森林,GBDT需要更多的内存和时间来进行训练,因为它是一个序列化的过程,不能像随机森林那样并行化训练。
- 较难解释:虽然单棵决策树很容易解释,但当涉及到成百上千棵树时,解释变得复杂得多。
4.5 举例说明
假设我们有以下简单的回归数据集:
| 实际值 (y) | 预测值 (ŷ) |
|---|---|
| 3 | 2 |
| 5 | 4 |
| 2 | 3 |
| … | … |
在第一次迭代中,我们计算每个样本的残差:
| 实际值 (y) | 预测值 (ŷ) | 残差 ® |
|---|---|---|
| 3 | 2 | 1 |
| 5 | 4 | 1 |
| 2 | 3 | -1 |
| … | … | … |
然后,我们使用这些残差来训练第一棵决策树。在后续的迭代中,我们使用新的残差(即前一棵树的预测值与实际值之间的差异)来训练下一棵树。
这个过程可以用以下伪代码表示:
def gradient_boosting_train(data, num_iterations, learning_rate):model =model = initialize_model(data) # 初始化模型,通常是目标变量的均值for t in range(num_iterations):residuals = compute_residuals(data, model) # 计算当前模型的残差tree = train_decision_tree(data, residuals) # 使用残差训练决策树update_model(model, tree, learning_rate) # 更新模型,通常是加上学习率乘以新树的预测return modeldef predict(model, x):prediction = 0for tree in model.trees:prediction += learning_rate * tree.predict(x)return prediction
# 伪代码中的具体函数实现细节省略,实际实现时需要定义这些函数的具体操作
4.6 实际应用中的考虑
在实际应用中,GBDT算法通常需要以下考虑:
- 特征选择: 在训练每棵树时,通常会随机选择一部分特征来训练,这有助于提高模型的泛化能力。
- 正则化: 为了防止过拟合,可以引入正则化项,如树的深度、叶子节点的数量等。
- 学习率: 学习率是一个超参数,它决定了每棵树对最终模型的影响。较小的学习率通常需要更多的树来达到良好的性能,但可以减少过拟合的风险。
通过上述详细的介绍,我们可以看到GBDT是一种强大且灵活的算法,它在许多机器学习任务中都表现出色。然而,它也有其局限性,比如训练时间较长,对超参数的选择比较敏感等。因此,在实际应用中,需要根据具体问题来调整算法的参数。
五、三种方法对比分析
5.1 工作方式对比
决策树 (Decision Tree)
- 单棵决策树:基于一个数据集构建一棵树,通过一系列规则对数据进行分类或回归。
- 分裂准则:使用熵、信息增益、基尼不纯度等标准选择最佳分裂点。
- 易过拟合:如果树长得太深,容易记住训练数据的细节,导致泛化能力差。
随机森林 (Random Forest)
- 集成多棵决策树:通过Bootstrap抽样和特征随机选取构建多个决策树。
- 并行训练:每棵树可以独立训练,不需要依赖其他树的结果。
- 投票机制:对于分类问题,采用多数投票;对于回归问题,取所有树预测结果的平均值。
- 减少过拟合:由于每棵树都是基于不同子集训练的,随机森林不容易过拟合。
GBDT (Gradient Boosting Decision Tree)
- 序列化构建弱学习器:每一棵新树都基于前一棵树的误差进行改进,逐步优化预测结果。
- 残差拟合:新树的目标是拟合之前所有树的预测值与真实标签之间的差异(即残差)。
- 迭代更新:通过引入学习率控制每棵树的影响程度,逐步更新预测值。
- 提高准确性:通过不断修正错误,GBDT通常能获得比单棵决策树更好的性能。
5.2 各自的优点与局限性
| 特征/模型 | 决策树 | 随机森林 | GBDT |
|---|---|---|---|
| 优点 | - 易于理解和解释 - 不需要预处理 | - 提高准确性和稳定性 - 减少过拟合 | - 强大的泛化能力 - 处理非线性关系 |
| - 支持多输出问题 | - 并行计算友好 | - 支持多种损失函数 | |
| - 快速训练 | - 鲁棒性强 | ||
| 局限性 | - 容易过拟合 | - 较难解释 | - 计算资源需求较高 |
| - 对数据变化敏感 | - 可能偏向多类别的类别 | - 容易过拟合(参数不当) | |
| - 偏向多类别的类别 | - 序列化训练,难以并行化 |
5.3 实际应用中如何选择合适的模型
在实际应用中,选择哪种模型取决于具体的应用场景、数据特点以及计算资源等因素。以下是选择模型的一些指导原则:
-
数据量和复杂度:
- 如果数据量较小且特征相对简单,单棵决策树可能是足够的,尤其是在需要可解释性的场合。
- 对于中等规模的数据集,随机森林通常是一个不错的选择,因为它既能提供较好的性能又能保持一定的解释性。
- 当面对大规模数据集或高度复杂的非线性关系时,GBDT往往能带来更高的准确性和更强的泛化能力。
-
计算资源和时间限制:
- 如果计算资源有限或者需要快速得到结果,决策树或随机森林可能更适合,因为它们的训练速度较快。
- 如果有足够的计算资源并且追求最高精度,GBDT是个好选项,尽管它的训练过程较慢。
-
模型解释性:
- 如果模型的可解释性非常重要(例如医疗诊断),那么单棵决策树或随机森林可能是更好的选择,因为它们更容易被人类理解。
- 如果解释性不是首要考虑因素,而更关注预测性能,那么GBDT可能会是更优的选择。
-
处理不平衡数据:
- 在类别不平衡的情况下,GBDT可以通过调整损失函数来更好地处理少数类,但需要注意调参以避免过拟合。
- 随机森林也可以通过设置类权重等方式应对不平衡数据,但它可能会偏向样本数较多的类别。
-
异常值和噪声:
- 决策树对异常值较为敏感,因此在数据有较多噪声时表现不佳。
- 随机森林和GBDT则相对更能抵抗异常值的影响,尤其是GBDT通过对残差的优化能够有效减轻异常值带来的影响。
-
并行化支持:
- 如果希望利用并行计算加速训练过程,随机森林是首选,因为它的每棵树可以独立训练。
- GBDT虽然也支持一定程度的并行化,但由于其序列化的特性,整体效率不如随机森林。

六、案例实战
6.1 基于决策树的案例实战——房价预测
问题背景
在当今数据驱动的时代,准确的分类和预测模型在各个领域都变得至关重要。特别是在房地产市场,了解不同特征(如房屋面积、位置、房间数量等)对房价的影响,可以帮助买家和投资者做出更明智的决策。本示例使用决策树算法对生成的二维数据进行分类,旨在展示如何通过机器学习模型识别和区分不同类别,从而为类似的实际应用提供基础。这种方法不仅可以用于房价预测,还可以扩展到其他领域,如客户分类、疾病诊断等,帮助决策者更好地理解数据背后的模式。
解题步骤
1.数据生成:
- 使用 NumPy 生成随机的二维特征数据,模拟一个简单的分类问题。
- 创建目标变量 y,根据样本点到原点的距离,将样本分为两个类别(0 和 1)。
2.数据转换:
- 将生成的特征数据和目标变量转换为 Pandas DataFrame,以便于数据的查看和操作。
3.数据集分割:
- 使用 train_test_split 将数据集分为训练集和测试集,通常训练集占 80%,测试集占 20%。这样可以在训练模型后评估其性能。
4.模型创建与训练:
- 创建一个决策树分类器,设置最大深度以防止过拟合。
- 在训练集上训练决策树模型,使其学习特征与目标变量之间的关系。
5.模型预测:
- 使用训练好的模型在测试集上进行预测,得到预测结果。
6.模型评估:
- 计算模型的准确率,并生成分类报告,评估模型在测试集上的表现。
7.数据可视化:
- 使用 Matplotlib 可视化原始数据的分布,展示不同类别的样本点。
- 绘制决策边界,展示模型如何将特征空间划分为不同的类别区域。
8.特征重要性输出:
- 计算并输出每个特征在决策树模型中的重要性,帮助理解哪些特征对分类结果影响最大。
决策树解决结果



(1)模型准确率:
模型的准确率为 0.93,这表明在测试集上,约 93% 的样本被正确分类。这个准确率是相当高的,说明模型在区分两个类别方面表现良好。
(2)分类报告:
- 类别 0.0:
- 精确率 (Precision): 0.96,表示在所有被预测为类别 0 的样本中,有 96% 实际上也是类别 0。
- 召回率 (Recall): 0.89,表示在所有实际为类别 0 的样本中,有 89% 被正确预测为类别 0。
- F1 分数 (F1-score): 0.93,综合考虑了精确率和召回率,表明模型在类别 0 的分类上表现良好。
- 类别 1.0:
- 精确率: 0.91,表示在所有被预测为类别 1 的样本中,有 91% 实际上也是类别 1。
- 召回率: 0.97,表示在所有实际为类别 1 的样本中,有 97% 被正确预测为类别 1。
- F1 分数: 0.94,说明模型在类别 1 的分类上也表现出色。
- 宏平均 (Macro avg): 显示在不同类别上的平均性能,精确率、召回率和 F1 分数均在 0.93 到 0.94 之间,说明模型在两个类别上的表现相对均衡。
- 加权平均 (Weighted avg): 反映了考虑样本数量后的平均性能,结果与宏平均相似,进一步确认模型的稳定性。
(3)特征重要性:
- 特征 feature1 的重要性为 0.43999,特征 feature2 的重要性为 0.56001。这表明 feature2 对模型的决策影响更大,可能是因为它在区分两个类别时提供了更多的信息。
- 了解特征的重要性有助于进一步优化模型和进行特征选择,可能在未来的模型训练中考虑去除重要性较低的特征,以简化模型。
总体来看,该决策树模型在分类任务中表现出色,具有较高的准确率和良好的分类性能。特征分析也为后续的模型改进和特征选择提供了有价值的信息。可以考虑在实际应用中进一步测试和验证模型的鲁棒性,尤其是在不同的数据集上。
完整代码
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('Agg') # 设置后端为 Agg
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler# 生成示例数据
np.random.seed(42)
n_samples = 300# 为两个特征生成数据
X = np.random.randn(n_samples, 2)
# 创建两个圆形分布的类别
y = np.zeros(n_samples)
for i in range(n_samples):if np.sqrt((X[i,0])**2 + (X[i,1])**2) > 1:y[i] = 1# 将数据转换为DataFrame以便于查看和操作
df = pd.DataFrame(X, columns=['feature1', 'feature2'])
df['target'] = y# 数据集分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练决策树模型
dt_classifier = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_classifier.fit(X_train, y_train)# 模型预测
y_pred = dt_classifier.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
print("\n模型准确率:", accuracy)
print("\n分类报告:")
print(classification_report(y_test, y_pred))# 可视化原始数据
plt.figure(figsize=(12, 5))# 绘制原始数据分布
plt.subplot(1, 2, 1)
plt.title("原始数据分布")
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', alpha=0.6, s=100) # 增加点的大小和透明度
plt.colorbar(scatter, label='类别')
plt.xlabel('特征 1')
plt.ylabel('特征 2')# 添加图例
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=scatter.cmap(0), markersize=10, label='类别 0'),plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=scatter.cmap(1), markersize=10, label='类别 1')]
plt.legend(handles=legend_elements, loc='upper right')# 添加网格线
plt.grid(True, linestyle='--', alpha=0.7)# 绘制决策边界
plt.subplot(1, 2, 2)
plt.title("决策边界可视化")# 创建网格点
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# 预测网格点的类别
Z = dt_classifier.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界
contour = plt.contourf(xx, yy, Z, alpha=0.4, cmap='viridis')
scatter2 = plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8, cmap='viridis', s=100, edgecolor='black') # 添加黑色边框
plt.xlabel('特征 1')
plt.ylabel('特征 2')
plt.colorbar(contour, label='预测类别')
plt.grid(True, linestyle='--', alpha=0.7)# 为第二个图创建新的图例
colors = plt.cm.viridis([0., 1.]) # 获取 viridis 颜色映射的两端颜色
legend_elements2 = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=colors[0], markeredgecolor='black',markersize=10, label='类别 0'),plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=colors[1], markeredgecolor='black',markersize=10, label='类别 1')]
plt.legend(handles=legend_elements2, loc='upper right')plt.tight_layout()
plt.savefig('data_visualization.png', dpi=300, bbox_inches='tight')
plt.close()# 输出特征重要性
feature_importance = pd.DataFrame({'feature': ['feature1', 'feature2'],'importance': dt_classifier.feature_importances_
})
print("\n特征重要性:")
print(feature_importance)6.2 基于随机森林的案例实战——房价预测
问题背景
某房地产公司在当前动态市场环境下面临着准确定价的挑战。他们收集了过去几年各种房屋特征及其对应售价的数据。公司希望开发一种数据驱动的方法,基于房屋面积、卧室数量、位置质量、房龄和到市中心距离等特征来预测房价。这将帮助他们做出更明智的定价决策,并为买卖双方提供更好的建议。
解题步骤
使用随机森林算法预测房价。我们模拟了一个包含1000个房屋样本的数据集,每个样本包含面积、卧室数量、位置评分、房龄和到市中心距离等特征。通过随机森林回归分析这些因素如何影响房价,并通过特征重要性分析和性能指标来展示模型的预测能力。
1. 数据准备
- 生成1000个房屋样本的模拟数据
- 包含关键特征:
- 面积(平方米)
- 卧室数量(1-5间)
- 位置评分(1-10分)
- 房龄(0-50年)
- 到市中心距离(1-30公里)
- 创建具有实际关联性的价格数据,并添加随机噪声
2. 数据处理
- 将数据整理成pandas数据框架
- 分离特征(X)和目标变量(价格)
- 将数据集分为训练集(80%)和测试集(20%)
3. 模型训练
- 初始化包含100棵树的随机森林回归器
- 使用训练数据集训练模型
- 由于随机森林对数据尺度不敏感,无需进行特征缩放
4. 模型评估
- 计算均方误差(MSE)来衡量预测准确度
- 计算R²分数来评估模型的解释能力
- 分析特征重要性,了解哪些因素对房价影响最大

随机森林解决结果


通过分析发现,模型的表现相当不错,R²值达到0.8836,说明模型能够解释约88.36%的房价变动。通过特征重要性分析,我们发现:
- 位置评分是最关键的影响因素,占总重要性的78.92%,这表明房屋所处位置的质量对房价有决定性影响
- 到市中心距离是第二重要的因素(8.23%),反映了便利性对房价的影响
- 卧室数量(5.15%)和面积(5.09%)的重要性相近,但相对较小
- 房龄的影响最小(2.61%),说明在其他因素相同的情况下,房屋年龄对价格的影响较为有限
这些发现符合"地段为王"的房地产市场特点,为房地产公司的定价策略提供了重要参考。建议公司在评估房产时重点关注位置因素,其次考虑交通便利性,而房屋本身的物理特征(如面积、卧室数量)可作为次要考虑因素。
完整代码
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('Agg') # 设置后端为Agg
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score# 生成仿真数据
np.random.seed(42)# 生成1000个样本
n_samples = 1000# 生成特征
area = np.random.normal(150, 50, n_samples) # 面积(平方米)
bedrooms = np.random.randint(1, 6, n_samples) # 卧室数量
location_score = np.random.uniform(1, 10, n_samples) # 位置评分
house_age = np.random.randint(0, 50, n_samples) # 房龄
distance_to_center = np.random.uniform(1, 30, n_samples) # 到市中心距离(公里)# 创建价格(加入一些非线性关系和噪声)
price = (area * 1000 + # 面积影响bedrooms * 50000 + # 卧室数量影响location_score * 100000 + # 位置评分影响-house_age * 2000 + # 房龄影响(负相关)-distance_to_center * 10000 + # 距离市中心影响(负相关)np.random.normal(0, 100000, n_samples) # 随机噪声
)# 创建数据框
data = pd.DataFrame({'area': area,'bedrooms': bedrooms,'location_score': location_score,'house_age': house_age,'distance_to_center': distance_to_center,'price': price
})# 划分特征和目标变量
X = data.drop('price', axis=1)
y = data['price']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)# 进行预测
y_pred = rf_model.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print("\nModel Evaluation Results:")
print(f"Mean Squared Error (MSE): {mse:.2f}")
print(f"R² Score: {r2:.4f}")# 特征重要性分析
feature_importance = pd.DataFrame({'feature': X.columns,'importance': rf_model.feature_importances_
})
feature_importance = feature_importance.sort_values('importance', ascending=False)print("\nFeature Importance:")
print(feature_importance)# 绘制特征重要性图
plt.figure(figsize=(10, 6))
plt.bar(feature_importance['feature'], feature_importance['importance'])
plt.title('Feature Importance Analysis')
plt.xlabel('Features')
plt.ylabel('Importance')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('feature_importance.png')
plt.close()# 绘制预测值vs实际值的散点图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('Predicted vs Actual Values')
plt.tight_layout()
plt.savefig('prediction_vs_actual.png')
plt.close()七、总结
在本次分享中,我们探讨了集成学习中的三种重要模型:决策树、随机森林和梯度提升决策树(GBDT)。决策树以其简单直观的特点成为入门级算法的理想选择,但容易过拟合;随机森林通过构建多个决策树并进行投票来提高预测的准确性和稳定性,特别适合处理高维数据;而GBDT则通过顺序训练一系列弱学习器逐步优化预测结果,在许多实际应用中展示了强大的泛化能力和高准确性。每种模型都有其独特的优势和局限性,适用于不同的应用场景。
作为初学者,如果有任何写错的地方或存在疑问,欢迎大家随时交流,共同进步。😊😊😊
希望这份总结对你有所帮助,并期待与你一起探讨更多机器学习的知识!😋😋😋
相关文章:
【机器学习】【集成学习——决策树、随机森林】从零起步:掌握决策树、随机森林与GBDT的机器学习之旅
这里写目录标题 一、引言机器学习中集成学习的重要性 二、决策树 (Decision Tree)2.1 基本概念2.2 组成元素2.3 工作原理分裂准则 2.4 决策树的构建过程2.5 决策树的优缺点(1)决策树的优点(2)决策树的缺点(3࿰…...
如何选择)
Flink执行模式(批和流)如何选择
DataStream API支持不同的运行时执行模式(batch/streaming),你可以根据自己的需求选择对应模式。 DataStream API的默认执行模式就是streaming,用于需要连续增量处理并且预计会一直保持在线的无界(数据源输入是无限的)作业。 而batch执行模式则用于有界(输入有限)作业…...

LeetCode:101. 对称二叉树
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode:101. 对称二叉树 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输…...

LDO输入电压不满足最小压差时输出会怎样?
1、LDO最小压差 定义:低压差稳压器(Low-dropout regulator,LDO)LDO的最小压差Vdo指的是LDO正常工作时,LDO的输入电压必须高于LDO输出电压的差值,即Vin≥VdoVout Vdo的值不是定值,会随着负载…...

源码分析之Openlayers中ZoomSlider滑块缩放控件
概述 ZoomSlider滑块缩放控件就是Zoom缩放控件的异形体,通过滑块的拖动或者点击滑槽,实现地图的缩放;另外其他方式控制地图缩放时,也会引起滑块在滑槽中的位置改变;即ZoomSlider滑块缩放控件会监听地图的缩放级别&…...

在Win11系统上安装Android Studio
诸神缄默不语-个人CSDN博文目录 下载地址:https://developer.android.google.cn/studio?hlzh-cn 官方安装教程:https://developer.android.google.cn/studio/install?hlzh-cn 点击Next,默认会同时安装Android Studio和Android虚拟机&#…...

华为ensp--BGP路径选择-AS_Path
学习新思想,争做新青年,今天学习的是BGP路径选择-AS_Path 实验目的: 理解AS_Path属性的概念 理解通过AS_Path属性进行选路的机制 掌握修改AS_Path属性的方法 实验内容: 本实验模拟了一个运营商网络场景,所有路由器都运行BGP协议ÿ…...

Android Java Ubuntu系统如何编译出 libopencv_java4.so
Cmake: cd ~ wget https://github.com/Kitware/CMake/releases/download/v3.30.3/cmake-3.30.3-linux-x86_64.tar.gztar -xzvf cmake-3.30.3-linux-x86_64.tar.gz sudo ln -sf $(pwd)/cmake-3.30.3-linux-x86_64/bin/* /usr/bin/cmake --versionAndroid NDK: wget https://…...

WPF Binding 绑定
绑定是 wpf 开发中的精髓,有绑定才有所谓的数据驱动。 1 . 背景 目前 wpf 界面可视化的控件,继承关系如下, 控件的数据绑定,基本上都要借助于 FrameworkElement 的 DataContext 属性。 只有先设置了控件的 DataContext 属性&…...
算法笔记—前缀和(动态规划)
【模板】前缀和_牛客题霸_牛客网 (nowcoder.com) #include <initializer_list> #include <iostream> #include <vector> using namespace std;int main() {//输入数据int n,q;cin>>n>>q;vector<int> arr;arr.resize(n1);for(int i1;i<…...
无水印版)
将HTML转换为PDF:使用Spire.Doc的详细指南(二)无水印版
目录 引言 一、准备工作 1. 下载Spire.Doc for Java破解版 2. 将JAR包安装到本地Maven (1) 打开命令提示符 (2) 输入安装命令 (3) 在pom.xml中导入依赖 二、实现HTML到PDF的转换 1. 创建Java类 2. 完整代码示例 3. 代码解析 4. 处理图像 5. 性能优化 6. 错误处理…...

V900新功能-电脑不在旁边,通过手机给PLC远程调试网关配置WIFI联网
您使用BDZL-V900时,是否遇到过以下这种问题? 去现场配置WIFI发现没带电脑,无法联网❌ 首次配置WIFI时需使用网线连电脑,不够快捷❌ 而博达智联为解决该类问题,专研了一款网关配网工具,实现用户现场使用手机…...
prober.php探针
raw.githubusercontent.com/kmvan/x-prober/master/dist/prober.php...
esp8266_TFTST7735语音识别UI界面虚拟小助手
文章目录 一 实现思路1 项目简介1.1 项目效果1.2 实现方式 2 项目构成2.1 软硬件环境2.2 完整流程总结(重点整合)(1) 功能逻辑图(2) 接线(3) 使用esp8266控制TFT屏(4)TFT_espI库配置方法(5) TFT_esp库常用代码详解(6)TFT屏显示图片(7) TFT屏显示汉字(8) …...

【CSS in Depth 2 精译_086】14.3:CSS 剪切路径(clip-path)的用法
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第四部分 视觉增强技术 ✔️【第 14 章 蒙版、形状与剪切】 ✔️ 14.1 滤镜 14.1.1 滤镜的类型14.1.2 背景滤镜 14.2 蒙版 14.2.1 带渐变效果的蒙版特效14.2.2 基于亮度来定义蒙版14.2.3 其他蒙版属…...

【服务器】MyBatis是如何在java中使用并进行分页的?
MyBatis 是一个支持普通 SQL 查询、存储过程和高级映射的持久层框架。它消除了几乎所有的 JDBC 代码和参数的手动设置以及结果集的检索。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 …...

vue 文本域 展示的内容格式要和填写时保持一致
文本域 展示的内容格式要和填写时保持一致 <el-inputtype"textarea":rows"5"placeholder"请输入内容"v-model"formCredit.point"style"width:1010px;" > </el-input> 样式加个: white-space: pre-w…...

linux-----进程及基本操作
进程的基本概念 定义:在Linux系统中,进程是正在执行的一个程序实例,它是资源分配和调度的基本单位。每个进程都有自己独立的地址空间、数据段、代码段、栈以及一组系统资源(如文件描述符、内存等)。进程的组成部分&am…...
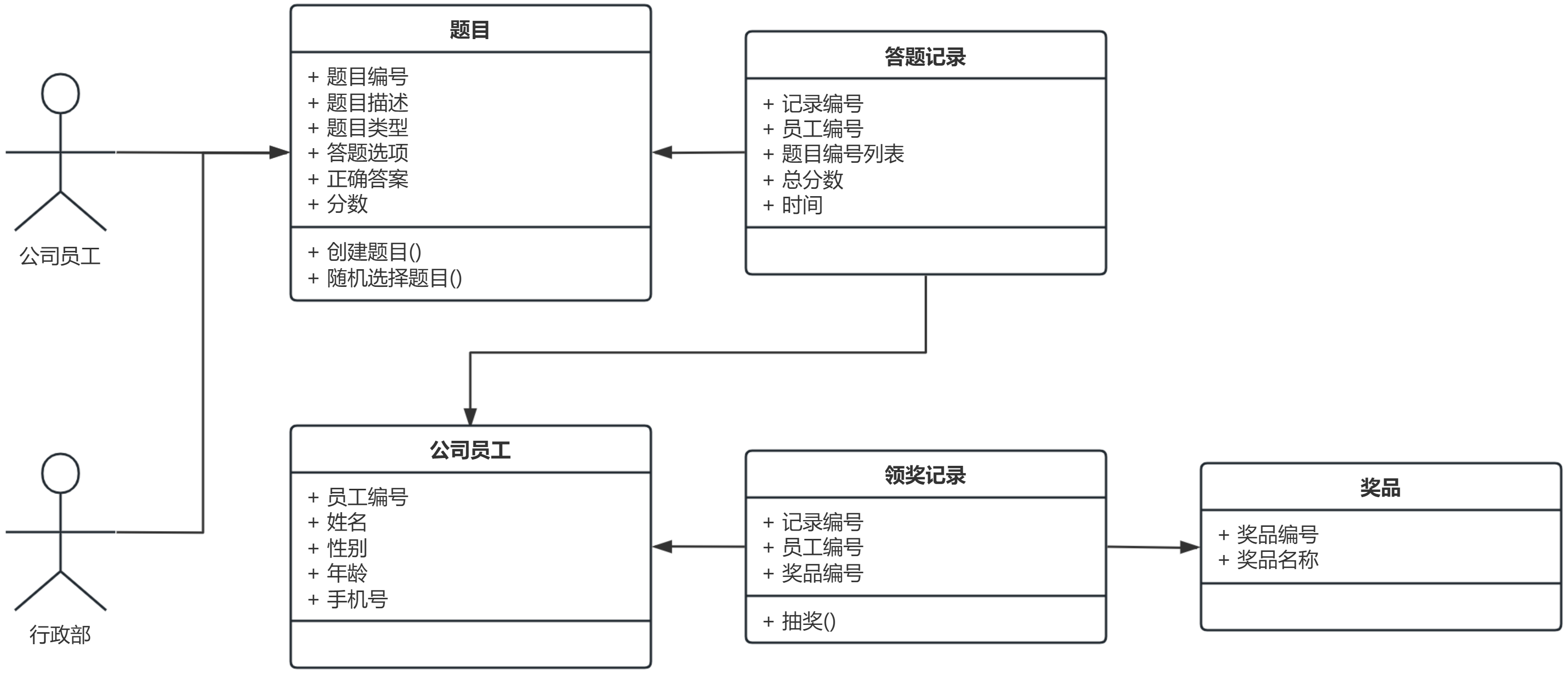
[Python学习日记-73] 面向对象实战1——答题系统
[Python学习日记-73] 面向对象实战1——答题系统 简介 需求模型——5w1h8c 领域模型 设计模型 实现模型 案例:年会答题系统 简介 在学习完面向对象之后你会发现,你还是不会自己做软件做系统,这是非常正常的,这是因为计算机软…...
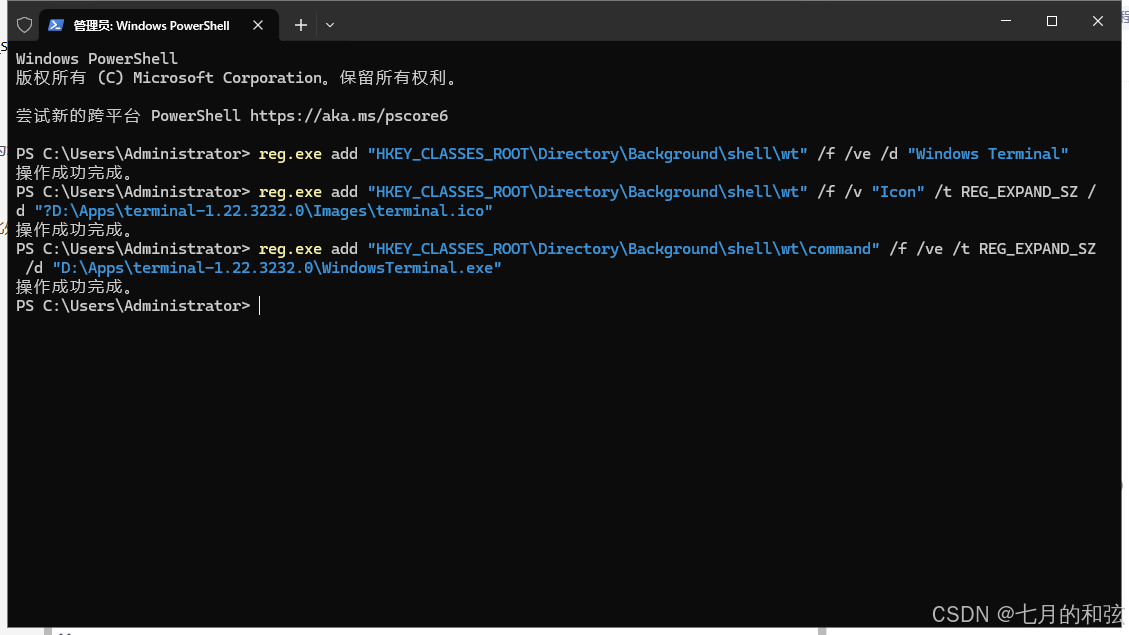
Win10将WindowsTerminal设置默认终端并添加到右键(无法使用微软商店)
由于公司内网限制,无法通过微软商店安装 Windows Terminal,本指南提供手动安装和配置新版 Windows Terminal 的步骤,并添加右键菜单快捷方式。 1. 下载新版终端安装包: 访问 Windows Terminal 的 GitHub 发布页面:https://githu…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...