Python爬虫入门实例:Python7个爬虫小案例(附源码)
引言
随着互联网的快速发展,数据成为了新时代的石油。Python作为一种高效、易学的编程语言,在数据采集领域有着广泛的应用。本文将详细讲解Python爬虫的原理、常用库以及实战案例,帮助读者掌握爬虫技能。
一、爬虫原理
爬虫,又称网络爬虫,是一种自动获取网页内容的程序。它模拟人类浏览网页的行为,发送HTTP请求,获取网页源代码,再通过解析、提取等技术手段,获取所需数据。
1. HTTP请求与响应过程
爬虫首先向目标网站发送HTTP请求,请求可以包含多种参数,如URL、请求方法(GET或POST)、请求头(Headers)等。服务器接收到请求后,返回相应的HTTP响应,包括状态码、响应头和响应体(网页内容)。
2. 常用爬虫技术
(1)请求库:如requests、aiohttp等,用于发送HTTP请求。
(2)解析库:如BeautifulSoup、lxml、PyQuery等,用于解析网页内容。
(3)存储库:如pandas、SQLite等,用于存储爬取到的数据。
(4)异步库:如asyncio、aiohttp等,用于实现异步爬虫,提高爬取效率。
Python入门基础教程【文末有惊喜福利】
二、Python爬虫常用库
1. 请求库
(1)requests:简洁、强大的HTTP库,支持HTTP连接保持和连接池,支持SSL证书验证、Cookies等。
(2)aiohttp:基于asyncio的异步HTTP网络库,适用于需要高并发的爬虫场景。
2. 解析库
(1)BeautifulSoup:一个HTML和XML的解析库,简单易用,支持多种解析器。
(2)lxml:一个高效的XML和HTML解析库,支持XPath和CSS选择器。
(3)PyQuery:一个Python版的jQuery,语法与jQuery类似,易于上手。
3. 存储库
(1)pandas:一个强大的数据分析库,提供数据结构和数据分析工具,支持多种文件格式。
(2)SQLite:一个轻量级的数据库,支持SQL查询,适用于小型爬虫项目。
接下来将分享7个Python爬虫的小案例,帮助大家更好地学习和了解Python爬虫的基础知识。以下是每个案例的简介和源代码:
1. 爬取豆瓣电影Top250
这个案例使用BeautifulSoup库爬取豆瓣电影Top250的电影名称、评分和评价人数等信息,并将这些信息保存到CSV文件中。
import requests
from bs4 import BeautifulSoup
import csv# 请求URL
url = ‘https://movie.douban.com/top250’
# 请求头部
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’
}# 解析页面函数
def parse_html(html):
soup = BeautifulSoup(html, ‘lxml’)
movie_list = soup.find(‘ol’, class_=‘grid_view’).find_all(‘li’)
for movie in movie_list:
title = movie.find(‘div’, class_=‘hd’).find(‘span’, class_=‘title’).get_text()
rating_num = movie.find(‘div’, class_=‘star’).find(‘span’, class_=‘rating_num’).get_text()
comment_num = movie.find(‘div’, class_=‘star’).find_all(‘span’)[-1].get_text()
writer.writerow([title, rating_num, comment_num])# 保存数据函数
def save_data():
f = open(‘douban_movie_top250.csv’, ‘a’, newline=‘’, encoding=‘utf-8-sig’)
global writer
writer = csv.writer(f)
writer.writerow([‘电影名称’, ‘评分’, ‘评价人数’])
for i in range(10):
url = ‘https://movie.douban.com/top250start=’ + str(i*25) + ‘&filter=’
response = requests.get(url, headers=headers)
parse_html(response.text)
f.close()if __name__ == ‘__main__’:
save_data()
2. 爬取猫眼电影Top100
这个案例使用正则表达式和requests库爬取猫眼电影Top100的电影名称、主演和上映时间等信息,并将这些信息保存到TXT文件中。
import requests import re # 请求URL url = '<https://maoyan.com/board/4>' # 请求头部 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } # 解析页面函数 def parse_html(html): pattern = re.compile('<p class="name"><a href=".*?" title="(.*?)" data-act="boarditem-click" data-val="{movieId:\\d+}">(.*?)</a></p>.*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', re.S) items = re.findall(pattern, html) for item in items: yield { '电影名称': item[1], '主演': item[2].strip(), '上映时间': item[3] } # 保存数据函数 def save_data(): f = open('maoyan_top100.txt', 'w', encoding='utf-8') for i in range(10): url = '<https://maoyan.com/board/4?offset=>' + str(i*10) response = requests.get(url, headers=headers) for item in parse_html(response.text): f.write(str(item) + '\ ') f.close() if __name__ == '__main__': save_data()
3. 爬取全国高校名单
这个案例使用正则表达式和requests库爬取全国高校名单,并将这些信息保存到TXT文件中。
import requests import re # 请求URL url = '<http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html>' # 请求头部 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } # 解析页面函数 def parse_html(html): pattern = re.compile('<tr class="alt">.*?<td>(.*?)</td>.*?<td><div align="left">.*?<a href="(.*?)" target="_blank">(.*?)</a></div></td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S) items = re.findall(pattern, html) for item in items: yield { '排名': item[0], '学校名称': item[2], '省市': item[3], '总分': item[4] } # 保存数据函数 def save_data(): f = open('university_top100.txt', 'w', encoding='utf-8') response = requests.get(url, headers=headers) for item in parse_html(response.text): f.write(str(item) + '\ ') f.close() if __name__ == '__main__': save_data()
4. 爬取中国天气网城市天气
这个案例使用xpath和requests库爬取中国天气网的城市天气,并将这些信息保存到CSV文件中。
import requests
from lxml import etree
import csv# 请求URL
url = '<http://www.weather.com.cn/weather1d/101010100.shtml>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):
selector = etree.HTML(html)
city = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/h1/text()')[0]
temperature = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/i/text()')[0]
weather = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/@title')[0]
wind = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/span/text()')[0]
return city, temperature, weather, wind# 保存数据函数
def save_data():
f = open('beijing_weather.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(f)
writer.writerow(['城市', '温度', '天气', '风力'])
for i in range(10):
response = requests.get(url, headers=headers)
city, temperature, weather, wind = parse_html(response.text)
writer.writerow([city, temperature, weather, wind])
f.close()if __name__ == '__main__':
save_data()
5. 爬取当当网图书信息
这个案例使用xpath和requests库爬取当当网图书信息,并将这些信息保存到CSV文件中。
import requests
from lxml import etree
import csv# 请求URL
url = '<http://search.dangdang.com/?key=Python&act=input>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):
selector = etree.HTML(html)
book_list = selector.xpath('//*[@id="search_nature_rg"]/ul/li')
for book in book_list:
title = book.xpath('a/@title')[0]
link = book.xpath('a/@href')[0]
price = book.xpath('p[@class="price"]/span[@class="search_now_price"]/text()')[0]
author = book.xpath('p[@class="search_book_author"]/span[1]/a/@title')[0]
publish_date = book.xpath('p[@class="search_book_author"]/span[2]/text()')[0]
publisher = book.xpath('p[@class="search_book_author"]/span[3]/a/@title')[0]
yield {
'书名': title,
'链接': link,
'价格': price,
'作者': author,
'出版日期': publish_date,
'出版社': publisher
}# 保存数据函数
def save_data():
f = open('dangdang_books.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(f)
writer.writerow(['书名', '链接', '价格', '作者', '出版日期', '出版社'])
response = requests.get(url, headers=headers)
for item in parse_html(response.text):
writer.writerow(item.values())
f.close()if __name__ == '__main__':
save_data()
6. 爬取糗事百科段子
这个案例使用xpath和requests库爬取糗事百科的段子,并将这些信息保存到TXT文件中。
import requests
from lxml import etree# 请求URL
url = '<https://www.qiushibaike.com/text/>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):
selector = etree.HTML(html)
content_list = selector.xpath('//div[@class="content"]/span/text()')
for content in content_list:
yield content# 保存数据函数
def save_data():
f = open('qiushibaike_jokes.txt', 'w', encoding='utf-8')
for i in range(3):
url = '<https://www.qiushibaike.com/text/page/>' + str(i+1) + '/'
response = requests.get(url, headers=headers)
for content in parse_html(response.text):
f.write(content + '\
')
f.close()
if __name__ == '__main__':
save_data()
7. 爬取新浪微博
这个案例使用selenium和requests库爬取新浪微博,并将这些信息保存到TXT文件中。
import time
from selenium import webdriver
import requests# 请求URL
url = '<https://weibo.com/>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):
print(html)# 保存数据函数
def save_data():
f = open('weibo.txt', 'w', encoding='utf-8')
browser = webdriver.Chrome()
browser.get(url)
time.sleep(10)
browser.find_element_by_name('username').send_keys('username')
browser.find_element_by_name('password').send_keys('password')
browser.find_element_by_class_name('W_btn_a').click()
time.sleep(10)
response = requests.get(url, headers=headers, cookies=browser.get_cookies())
parse_html(response.text)
browser.close()
f.close()if __name__ == '__main__':
save_data()
希望这7个小案例能够帮助大家更好地掌握Python爬虫的基础知识!
Python入门基础教程【文末有惊喜福利】
爬虫注意事项与技巧
-
遵循Robots协议
-
尊重网站的爬虫协议,避免爬取禁止爬取的内容。
-
设置合理的请求间隔
-
避免对目标网站服务器造成过大压力,合理设置请求间隔。
-
处理反爬虫策略
-
了解并应对网站的反爬虫策略,如IP封禁、验证码等。
-
使用代理IP、Cookies等技巧
-
提高爬虫的稳定性和成功率。
-
分布式爬虫的搭建与优化
-
使用Scrapy-Redis等框架,实现分布式爬虫,提高爬取效率。
Python爬虫框架
-
Scrapy:强大的Python爬虫框架,支持分布式爬取、多种数据格式、强大的插件系统等。
-
Scrapy-Redis:基于Scrapy和Redis的分布式爬虫框架,实现分布式爬取和去重功能。
结语:
通过本文的讲解,相信读者已经对Python爬虫有了较为全面的认识。爬虫技能在数据分析、自然语言处理等领域具有广泛的应用,希望读者能够动手实践,不断提高自己的技能水平。同时,请注意合法合规地进行爬虫,遵守相关法律法规。祝您学习愉快!
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
②Python、PyCharm学习工具包全家桶,环境配置教程视频
③Python全套电子书籍PDF,全部都是干货知识
④ 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
⑤ 100多个Python实战案例,学习不再是只会理论
全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。


二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


希望这些内容对大家有所帮助,因为你我都是热爱python的编程语言爱好者。
相关文章:
Python爬虫入门实例:Python7个爬虫小案例(附源码)
引言 随着互联网的快速发展,数据成为了新时代的石油。Python作为一种高效、易学的编程语言,在数据采集领域有着广泛的应用。本文将详细讲解Python爬虫的原理、常用库以及实战案例,帮助读者掌握爬虫技能。 一、爬虫原理 爬虫,又…...
 算法MNIST图像生成任务及CelebA图像超分辨率任务)
生成对抗网络 (Generative Adversarial Network, GAN) 算法MNIST图像生成任务及CelebA图像超分辨率任务
生成对抗网络 (Generative Adversarial Network, GAN) 算法详解与PyTorch实现 目录 生成对抗网络 (Generative Adversarial Network, GAN) 算法详解与PyTorch实现1. 生成对抗网络 (GAN) 算法概述1.1 生成器与判别器1.2 GAN的优势2. GAN的核心技术2.1 目标函数2.2 生成器2.3 判别…...

快速排序排序方法演示及算法分析(附代码和实例)
基本思想: 任取一个元素(比如第一个)为中心,称为枢轴(pivot)所有比它小的元素一律前放,比它大的元素后放,形成左右两个子表对各子表重新选择中心元素并以此规则调整直到每个子表的元…...

库迪困境:供应链补救失效背后的市场错配
作者 | 曾响铃 文 | 响铃说 近日,红餐网证实了库迪咖啡暂停便捷店招商的消息。库迪官方回应称,店中店模式招商只是按下了暂停键,不排除未来重启的可能。 但一批被“暂停”的便捷店加盟商,不知道等不等起库迪的未来重启。 小红…...

解决openpyxl操纵带公式的excel或者csv之后,pandas无法读取数值的问题
1 功能特点 openpyxl: 这是一个专门用于操作Excel文件(.xlsx/.xlsm)的库。它提供了丰富的功能来读取、写入和修改Excel文件的各个元素,如单元格、行、列、工作表等。例如,可以通过openpyxl轻松地创建一个新的Excel工作…...
与物理信息神经网络(PINN)求解泊松方程(附Pytorch源代码))
基于傅立叶神经网络(FNN)与物理信息神经网络(PINN)求解泊松方程(附Pytorch源代码)
基于傅立叶神经网络(FNN)与物理信息神经网络(PINN)求解泊松方程 一、引言 偏微分方程(Partial Differential Equation, PDE)在科学与工程领域有着广泛的应用。传统数值方法(如有限差分法、有限元法)在求解这类问题时,尽管已经非常成熟,但随着问题复杂度的增加,其计…...

小程序组件 —— 28 组件案例 - 推荐商品区域 - 实现结构样式
这一节目标是实现底部推荐商品的结构和样式,由于这里要求横向滚动,所以需要使用上节介绍的 scroll-view 功能,并使用 scroll-x 属性支持横向滚动,推荐商品区域中的每一个商品是一个单独的 view,每个view 中需要写三个组…...
)
Flink读写Kafka(DataStream API)
在Flink里,已经预定义了kafka connector,使用该connector我们可以读写kafka,并且能实现exactly once的语义。 要使用需要引入相关的maven依赖,在这里,因为读写kafka,就会涉及一个问题,kafka-client和broker的版本兼容问题,不过因为kafka client和broker的双向兼容的良…...

SCAU期末笔记 - 数据库系统概念往年试卷解析
数据库搞得人一头雾水,题型太多太杂,已经准备摆烂了。就刷刷往年试卷,挂不挂听天由命。 2019年 Question 1 选择题 1. R ∩ S R∩S R∩S等于一下哪个选项? 画个文氏图秒了 所以选A. R ∩ S R − ( R − S ) R∩SR-(R-S) R∩…...

flutter在windows平台中运行报错
PS D:\F\luichun> flutter run当运行flutter项目时,【解决如下报错】 /C:/flutter/packages/flutter/lib/src/painting/star_border.dart:530:27: Error: The getter Matrix4 isnt defined for the class _StarGenerator.- _StarGenerator is from package:flut…...

HTML——75. 内联框架
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>内联框架</title><style type"text/css">iframe{width: 100%;height: 500px;}</style></head><body><!--iframe元素会创建包含…...

python对mongodb的增删查改
python对mongodb的增删查改 1. 安装 pymongo2. 连接 MongoDB3. 创建(插入)文档插入单个文档插入多个文档 4. 查询文档查询单个文档查询多个文档复杂查询嵌套查询分页条件查询(通用模版) 5. 更新文档更新单个文档更新多个文档更新嵌…...
和 Promise.race()区别)
【JS】期约的Promise.all()和 Promise.race()区别
概述 Promise.all() 和 Promise.race() 都是 JavaScript 中处理多个异步操作的 Promise 方法,但它们的行为和返回结果有所不同。 Promise.all()和Promise.race() 1. Promise.all() Promise.all() 接受一个由多个 Promise 实例组成的可迭代对象(例如数…...

使用 RxJS 库实现响应式编程
什么是 RxJS? RxJS(Reactive Extensions for JavaScript)是一个用于响应式编程的库,它使得处理异步数据流变得更加简单和优雅。通过使用 Observables(可观察对象),你可以轻松地处理事件、HTTP …...
)
ARP攻击的原理和实现 (网络安全)
ARP攻击的原理和实现 ARP(Address Resolution Protocol,地址解析协议)是一种网络协议,用于在局域网内将IP地址映射到MAC地址。在以太网中,设备通过广播ARP请求来查询目标IP地址对应的MAC地址,从而建立通信…...

chatgpt model spec 2024
概述 这是模型规范的初稿,该文档规定了我们在OpenAI API和ChatGPT中的模型的期望行为。它包括一组核心目标,以及关于如何处理冲突目标或指令的指导。 我们打算将模型规范作为研究人员和数据标注者创建数据的指南,这是一种称为从人类反馈中进…...

单片机-LED实验
1、51工程模版 #include "reg52.h" void main(){ while(1){ } } 2、LED灯亮 #include "reg52.h" sbit LED1P2^0; void main(){ while(1){ LED10; } } 3、LED闪烁 #include "reg52.h" sbit LED1P2^0; //P2大…...

QILSTE H10-C321HRSYYA高亮红光和黄光LED灯珠
在深入探讨H10-C321HRSYYA型号的复杂特性之前,我们首先需要明确其基本参数和功能。这款型号的LED产品以其独特的双色设计和卓越的性能在众多同类产品中脱颖而出。其外观尺寸为3.0x1.0x2.1mm,采用高亮黄光和红光的双色组合,赋予了其在多种应用…...

Appium(一)--- 环境搭建
一、Android自动化环境搭建 1、JDK 必须1.8及以上(1) 安装:默认安装(2) 环境变量配置新建JAVA_HOME:安装路径新建CLASSPath%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar在path中增加:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;(3) 验证…...

量子力学复习
黑体辐射 热辐射 绝对黑体: (辐射能力很强,完全的吸收体,理想的发射体) 辐射实验规律: 温度越高,能量越大,亮度越亮 温度越高,波长越短 光电效应 实验装置…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析 一、第一轮基础概念问题 1. Spring框架的核心容器是什么?它的作用是什么? Spring框架的核心容器是IoC(控制反转)容器。它的主要作用是管理对…...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...
麒麟系统使用-进行.NET开发
文章目录 前言一、搭建dotnet环境1.获取相关资源2.配置dotnet 二、使用dotnet三、其他说明总结 前言 麒麟系统的内核是基于linux的,如果需要进行.NET开发,则需要安装特定的应用。由于NET Framework 是仅适用于 Windows 版本的 .NET,所以要进…...
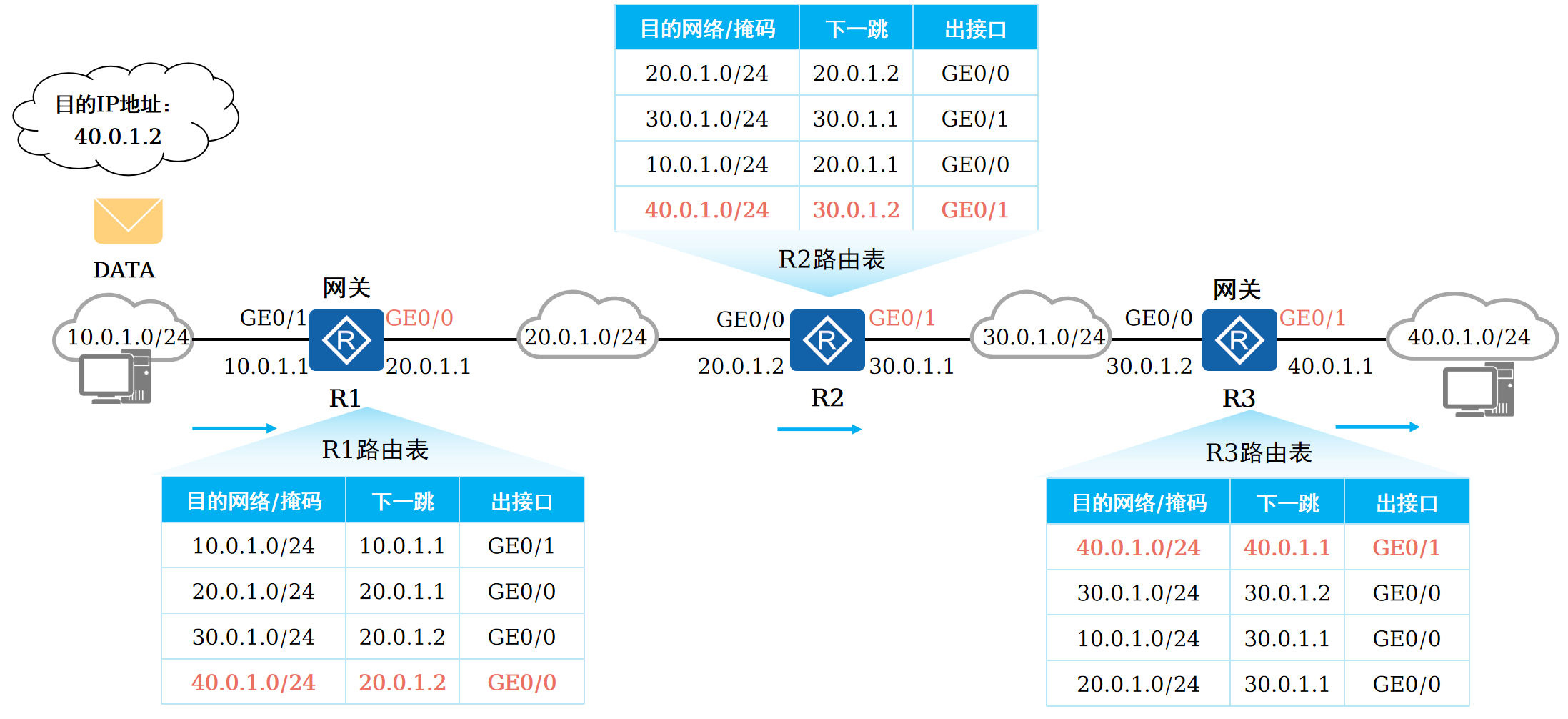
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...

EEG-fNIRS联合成像在跨频率耦合研究中的创新应用
摘要 神经影像技术对医学科学产生了深远的影响,推动了许多神经系统疾病研究的进展并改善了其诊断方法。在此背景下,基于神经血管耦合现象的多模态神经影像方法,通过融合各自优势来提供有关大脑皮层神经活动的互补信息。在这里,本研…...