Python3遍历文件夹提取关键字及其附近字符
要求:
1,遍历文件夹下所有的.xml文件
2,从.xml文件中提取关键字以及左右十个字符
3,输出到excel
一:遍历文件夹找到所有xml文件及其路径
for root, dirs, files in os.walk(self.inputFilePath):for file in files:targetFilePath = os.path.join(root, file)if not targetFilePath.endswith(".xml"):continuexmlFileData = open(targetFilePath,'r',encoding='utf-8').read()os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情
def walk(top, topdown=True, onerror=None, followlinks=False):参数解释:
- top – 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
- topdown的默认值是“True”,表示首先返回根目录树下的文件,然后遍历目录树下的子目录。值设为False时,则表示先遍历目录树下的子目录,返回子目录下的文件,最后返回根目录下的文件。
- topdown设值不同,os.walk()返回的列表元素顺序不同(但不是相反),所以遍历后的结果也不同
- onerror – 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks – 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
我们只传入一个目录参数,它会遍历当前目录,及其子目录。
返回的是一个三元组(root,dirs,files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
二:对xml文件提取关键字及其左右的十个字符
xmlFileData = open(targetFilePath,'r',encoding='utf-8').read()
for m in re.finditer(self.keyWords, xmlFileData, re.I):#re.I标志是大小写不敏感extractKeywords = xmlFileData[m.start()-OFFSET:m.end()+OFFSET]self.keywordInfoList.append((targetFilePath,extractKeywords))用到了re模块的finditer方法,用过re模块的相信都用过findall()方法,该方法能一次性找出所有的正则匹配结果,但是也有局限性,其不能提供所在的位置,并且是一起返回的,如果有数万个一起返回来,就不太好处理了,因此要使用finditer()函数来实现每次只返回一个,并且返回所在的位置。
re.finditer(pattern, string, flags=0)参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |

针对re.finditer返回的迭代对象,每一个迭代子对象都有start和end方法,start定位到关键字开始的位置,end定位到关键字结尾的位置,我们再定义一个偏移值(建议用宏,可以统一修改)来提取关键字及其左右偏移的字符
三:写入excel
def writeToExcel(self):workBook = openpyxl.Workbook()sheetPos = 0for ele in self.keywordInfoList:oneLine = list()rootPathSplit = ele[0].split('\\')firstDirIndex = rootPathSplit.index(self.firstDirName)#获取当前目录的索引newSheet = rootPathSplit[firstDirIndex+1]if newSheet not in workBook.sheetnames:workSheet = workBook.create_sheet(newSheet, sheetPos)sheetPos += 1oneLine.extend(rootPathSplit[firstDirIndex+1:])oneLine.append(ele[1])workSheet.append(oneLine)print(oneLine)workBook.save("xmlExtractKeyword.xlsx")用到了openpyxl模块,下面给出常用的方法
创建:
from openpyxl import Workbook
# 实例化
wb = Workbook()
# 激活 worksheet
ws = wb.active打开已有:
from openpyxl import load_workbookwb2 = load_workbook('文件名称.xlsx')储存数据:
# 方式一:数据可以直接分配到单元格中(可以输入公式)
ws['A1'] = 42
# 方式二:可以附加行,从第一列开始附加(从最下方空白处,最左开始)(可以输入多行)
ws.append([1, 2, 3])
# 方式三:Python 类型会被自动转换
ws['A3'] = datetime.datetime.now().strftime("%Y-%m-%d")创建表(sheet):
# 方式一:插入到最后(default)
>>> ws1 = wb.create_sheet("Mysheet")
# 方式二:插入到最开始的位置
>>> ws2 = wb.create_sheet("Mysheet", 0)选择表(sheet):
# sheet 名称可以作为 key 进行索引
>>> ws3 = wb["New Title"]
>>> ws4 = wb.get_sheet_by_name("New Title")
>>> ws is ws3 is ws4
True查看表名(sheet):
# 显示所有表名
>>> print(wb.sheetnames)
['Sheet2', 'New Title', 'Sheet1']
# 遍历所有表
>>> for sheet in wb:
... print(sheet.title)更多方法请见:python-- openpyxl详解_像风一样的男人@的博客-CSDN博客
相关文章:
Python3遍历文件夹提取关键字及其附近字符
要求: 1,遍历文件夹下所有的.xml文件 2,从.xml文件中提取关键字以及左右十个字符 3,输出到excel 一:遍历文件夹找到所有xml文件及其路径 for root, dirs, files in os.walk(self.inputFilePath):for file in files:…...

「1」线性代数(期末复习)
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 第一章 行列式 行列式是一个数,是一个结果三阶行列式的计算:主对角线的乘…...

C++7:STL-模拟实现vector
目录 vector的成员变量 构造函数 reserve size() capacity() push_back 一些小BUG 赋值操作符重载 析构函数 【】操作符重载 resize pop_back Insert 迭代器失效 erase 二维数组问题 总结一下 vector,翻译软件会告诉你它的意思是向量,但其…...

笑死,面试官又问我SpringBoot自动配置原理
面试官:好久没见,甚是想念。今天来聊聊SpringBoot的自动配置吧? 候选者:嗯,SpringBoot的自动配置我觉得是SpringBoot很重要的“特性”了。众所周知,SpringBoot有着“约定大于配置”的理念,这一…...
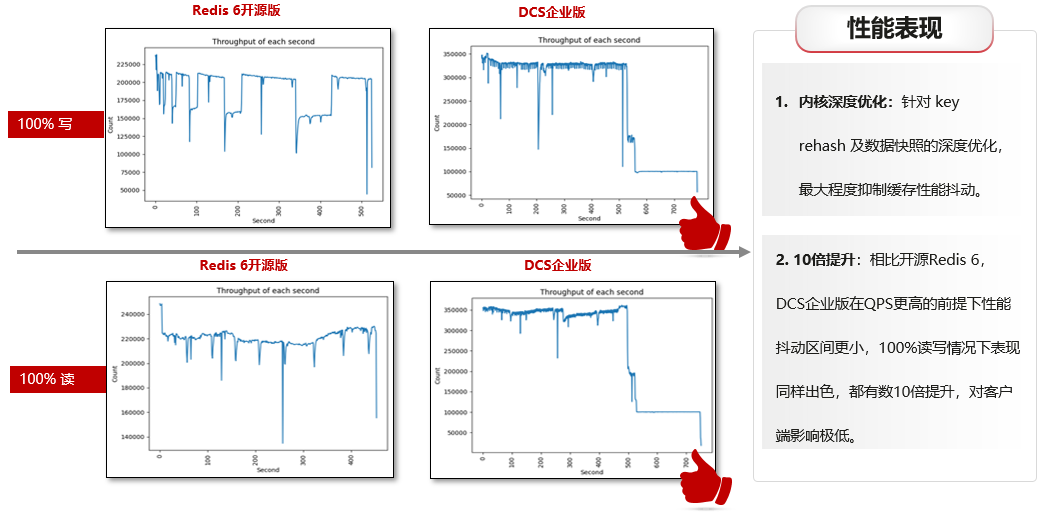
分布式缓存服务DCS-企业版性能更强,稳定性更高
背景介绍 近年来,随着各行业业务需求急速增加,数据量和并发访问量呈指数级增长,原来只能依附于关系型数据库的传统“缓存”逐渐难以支撑上层业务,开源Redis也面临着如“容量有限”、 “可靠性有限”、 “数据重复拷贝,…...

HTTP基本原理
目录URL简单定义格式HTTP和HTTPSHTTP的请求过程。请求响应响应体HTTP2.0总结URL 简单定义 通过一个链接,使我们可以找到网络上的某个资源,这个链接就是URL。 格式 URL并不是随便写的,而是有固定的格式。基本的组成格式如下。 schme://[us…...
最新版本详细保姆级安装教程)
【云原生】Kubernetes(k8s)最新版本详细保姆级安装教程
前言 Kubernetes简称k8s,是一个开源的,用于管理云平台中多个主机上的容器化的应用,k8s目标是让部署容器化的应用简单并且高效,k8s提供了应用部署,规划,更新,维护的一种机制。 本文是总结了在安…...
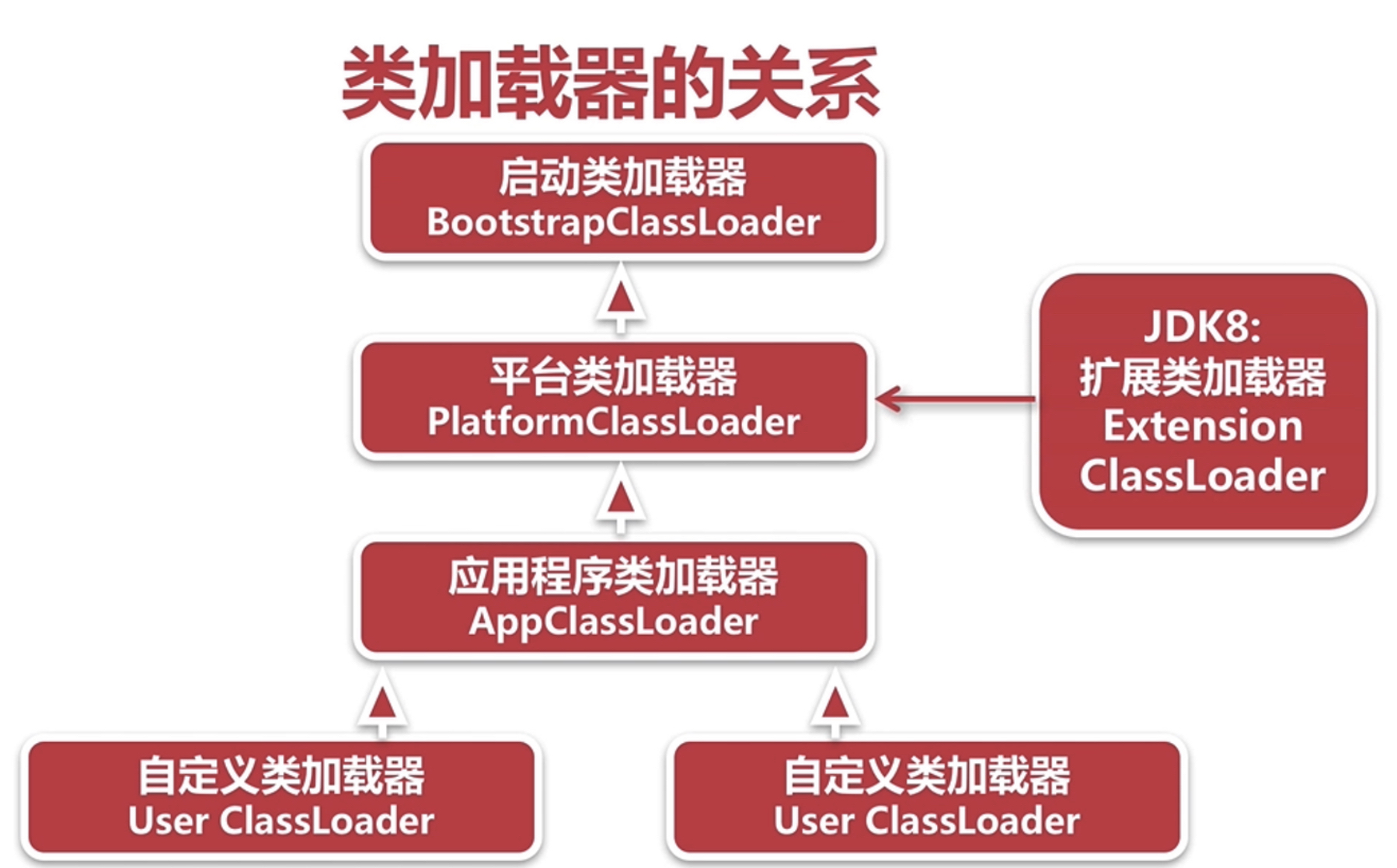
JVM - 类加载,连接和初始化
目录 类加载和类加载器 概述 类加载要完成的功能 加载类的方式 类加载器 类加载器的关系 类加载器说明 双亲委派模型 工作过程如下: 双亲委派模型说明: 破坏双亲委派模型: 类连接和初始化 类连接主要验证的内容 类连接中的解析…...
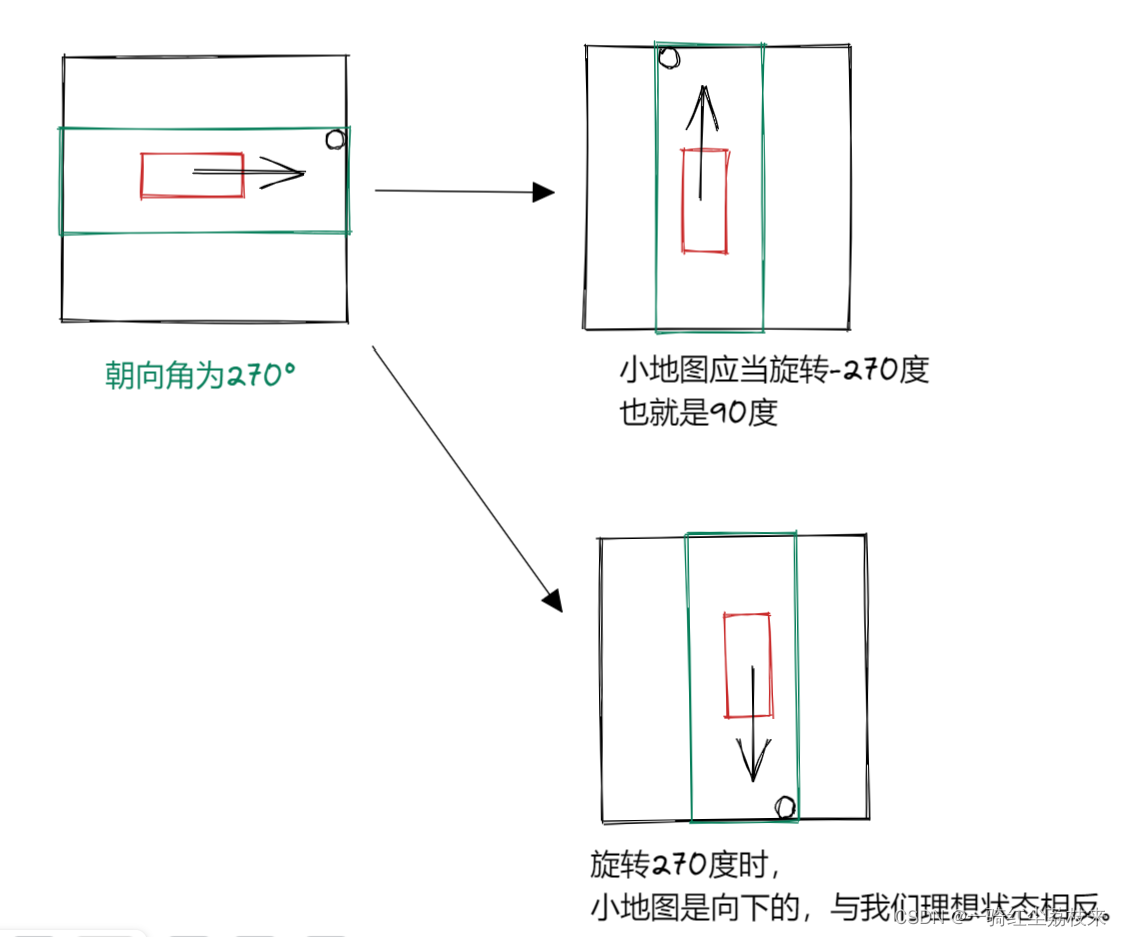
[carla]关于odometry坐标中的角度坐标系 以及 到地图的映射问题
1.获取车辆的Odometry原始信息 在carla中,通过订阅/carla/ego_vecle/odometry 可以查看车辆的全局位置信息,例如: > header: seq: 118872stamp: secs: 5946nsecs: 5720187frame_id: "map" child_frame_id: "ego_vehicle" pos…...

Python 正则表达式
正则表达式主要用来查找和匹配字符串的。 一、正在表达式基础 字符 描述 示例 TIY\ 示意特殊序列(也可用于转义特殊字符)如:空白字符 "\s" . 任何字符(换行符除外) "he..o" ^ 起始于 "^h…...

spark03-读取文件数据分区数量个数原理
代码val conf: SparkConf new SparkConf().setMaster("local").setAppName("wordcount")val sc: SparkContext new SparkContext(conf)val rdd: RDD[String] sc.textFile("datas/1.txt",2)rdd.saveAsTextFile("output")数据格式 &a…...
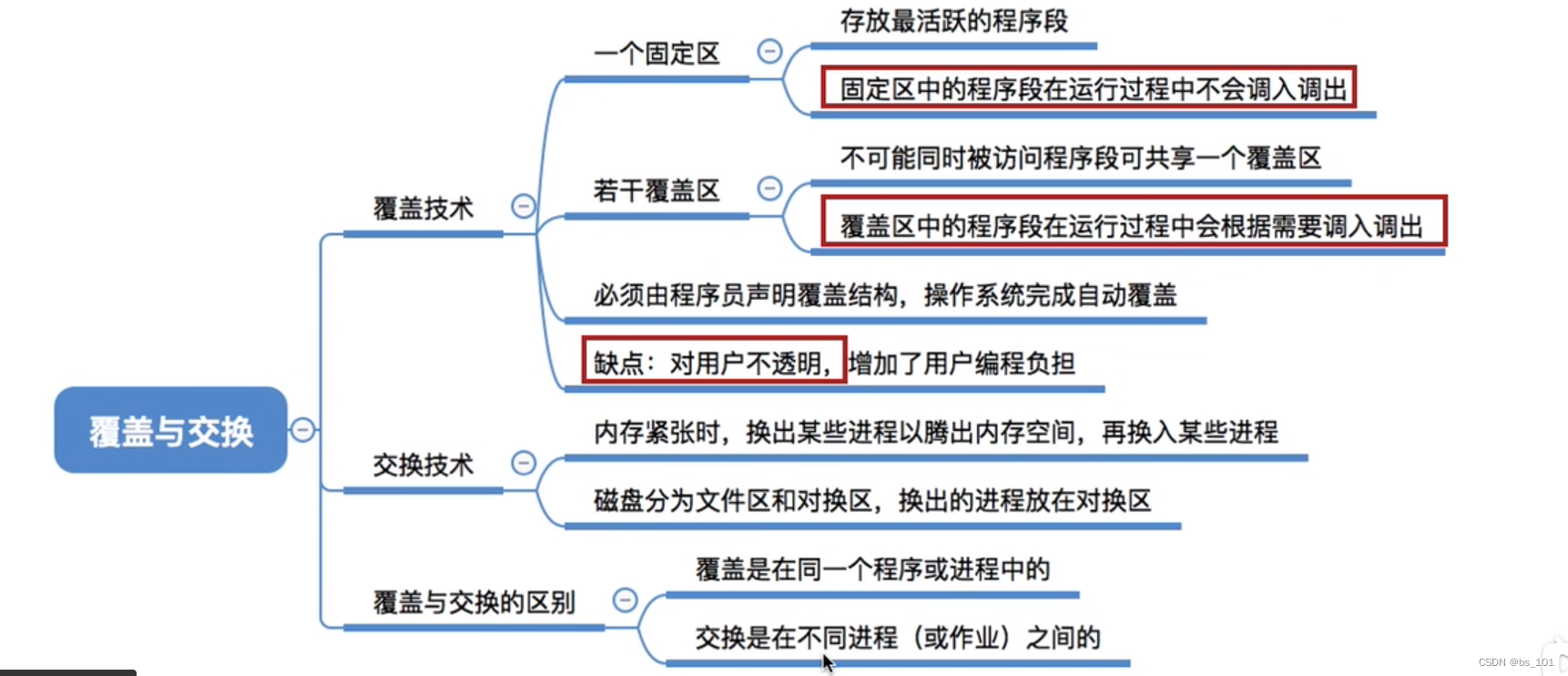
操作系统(day08)内存
存储单元 内存的几个基本概念 存储单元 内存地址从0开始,每个地址对应一个存储单元 存储单元大小根据计算机按照什么方式编址 按字节编址 则每个存储单元大小为一字节,即1B,即8个二进制位按字编址 看这个计算的字长是多少位,如…...
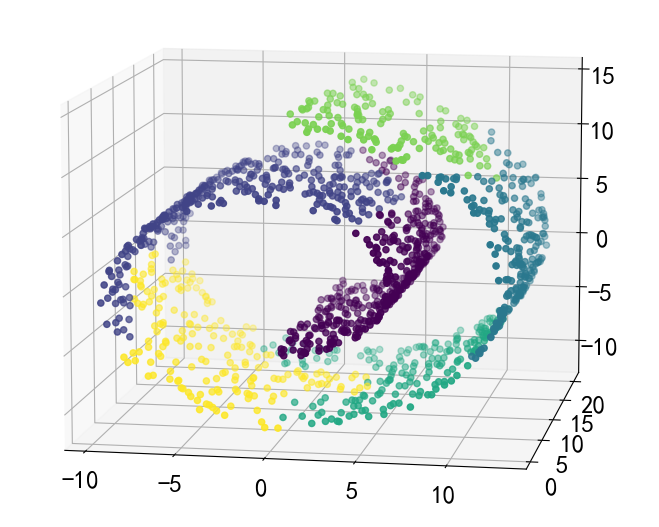
11- 聚类算法 (KMeans/DBSCAN/agg) (机器学习)
聚类算法 聚类算法和降维算法那都属于无监督算法。KMeans 是以一个值为中心, 然后所有其他点到该点距离最小值的累积和。 kmeans KMeans(n_clusters3) # n_clusters 分类数量 kmeans.fit(data.iloc[:,1:]) # 无监督,只需要给数据X就可以 DBSCAN 算法是…...

日日顺供应链|想要看清供应链发展趋势,先回答这三个问题
技术变革如何支撑供应链及管理服务的发展? 数字化与科技化开始承托供应链管理能力的升级与变革? 如何从客户需求的纬度反推供应链及管理服务的模式变革?在过去的三年中,我国的供应链企业经受了最为极端的挑战,但当下&a…...

5守护进程与线程
进程组 多个进程的集合,第一个进程就是组长,组长进程的PID等于进程组ID。 进程组生存期:进程组创建到最后一个进程离开(终止或转移到另一个进程组)。与组长进程是否终止无关。 一个进程可以为自己或子进程设置进程组 ID 相关函数 pid_t …...
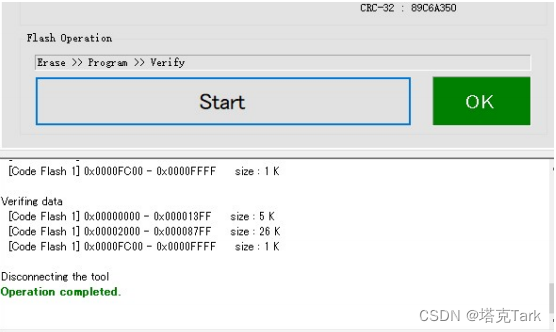
EZ-Cube简易款下载器烧写使用方法
一、硬件连接 跟目标芯片接4根线 VCC、GND、TOOL、REST 四根线,如果板子芯片自己外接电源的,VCC 线可以不接。 二、 安装烧写软件和驱动 烧写软件:https://download.csdn.net/download/Stark_/87444744?spm1001.2014.3001.5503 驱动程序&a…...
sql server安装并SSMS连接
博主简介:原互联网大厂tencent员工,网安巨头Venustech员工,阿里云开发社区专家博主,微信公众号java基础笔记优质创作者,csdn优质创作博主,创业者,知识共享者,欢迎关注,点赞ÿ…...

Python_pytorch (二)
python_pytorch 小土堆pytotch学习视频链接 from的是一个个的包(package) import 的是一个个的py文件(file.py) 所使用的一般是文件中的类(.class) 第一步实例化所使用的类,然后调用类中的方法(def) Torchvision 数据集 数据集使用(CI…...
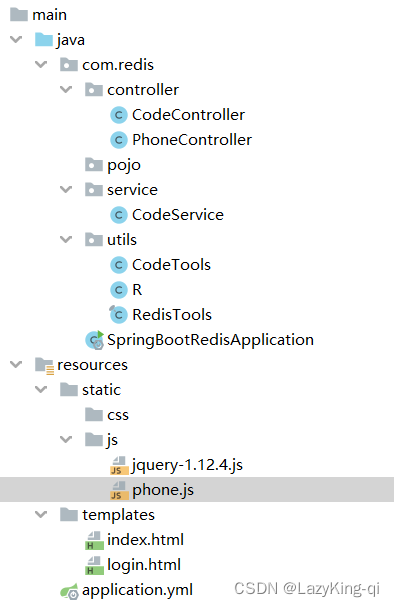
java手机短信验证,并存入redis中,验证码时效5分钟
目录 1、注册发送短信账号一个账号 2、打开虚拟机,将redis服务端打开 3、创建springboot工程,导入相关依赖 4、写yml配置 5、创建controller层,并创建controller类 6、创建service层,并创建service类 7、创建工具类&#x…...

kubectl命令控制远程k8s集群(Windows系统、Ubuntu系统、Centos系统)
文章目录1. 本地是linux2. 本地是Windows1. 本地是linux 安装kubectl命令 法一:从master的/usr/bin目录下拷贝kubectl文件到本机/usr/bin目录下法二:GitHub下载kubectl文件 在家目录下创建.kube目录config文件 法一:将master上对应用户的~/.…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...
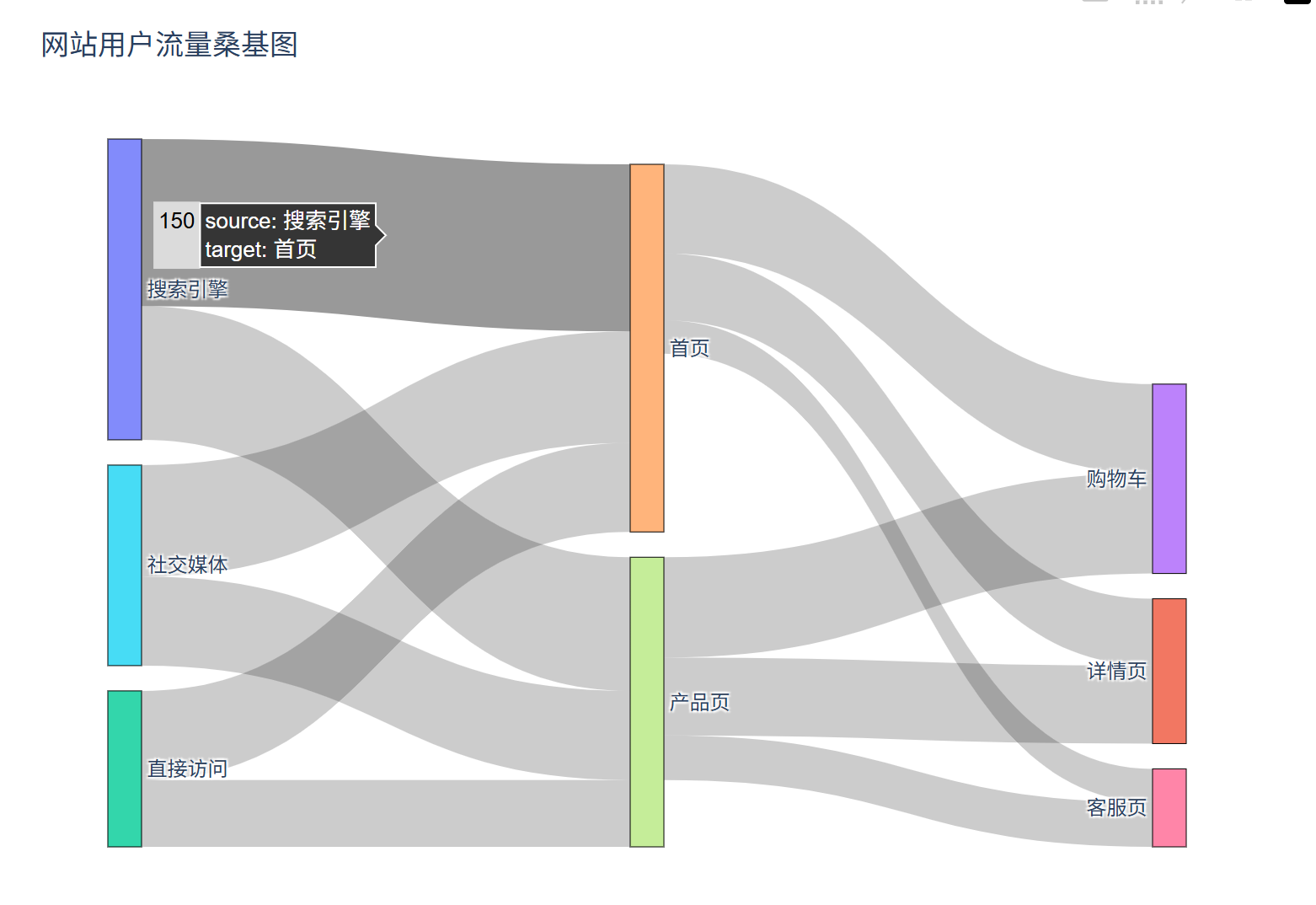
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...

ThreadLocal 源码
ThreadLocal 源码 此类提供线程局部变量。这些变量不同于它们的普通对应物,因为每个访问一个线程局部变量的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocal 实例通常是类中的私有静态字段,这些类希望将…...