【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.2 多维数组切片:跨步访问与内存布局

2.2 多维数组切片:跨步访问与内存布局
目录/提纲
2.2.1 跨步(Strides)内存模型2.2.1.1 跨步概念2.2.1.2 跨步内存模型2.2.1.3 跨步的计算方法 2.2.2 负步长切片技巧2.2.2.1 负步长的概念2.2.2.2 负步长的应用2.2.2.3 负步长的内存布局 2.2.3 分块切片优化2.2.3.1 分块的概念2.2.3.2 分块切片的方法2.2.3.3 分块切片的性能优势 2.2.4 大数组切片性能陷阱2.2.4.1 内存复制问题2.2.4.2 视图 vs 复制2.2.4.3 优化策略
文章内容
NumPy 的多维数组切片是处理数组时非常强大的工具,它使得我们可以灵活地访问和操作数组中的子数组。本文将详细介绍多维数组切片的跨步访问机制、负步长切片技巧以及分块切片优化方法。通过本文的学习,读者将能够更好地理解 NumPy 的多维数组切片原理,并在实际应用中更加高效地使用这些功能。
2.2.1 跨步(Strides)内存模型
2.2.1.1 跨步概念
跨步(Strides)是 NumPy 数组的一个重要属性,它描述了每个维度上的元素在内存中的间隔。通过跨步,NumPy 可以高效地访问数组中的元素,而不需要重新分配内存。
原理说明
- 跨步的定义:跨步是指从当前元素到下一元素在内存中的字节数偏移量。对于多维数组,每个维度都有一个跨步值。
- 跨步的作用:跨步使得 NumPy 可以通过简单的指针操作来访问数组中的元素,而不需要重新计算每个元素的位置。
NumPy数组的跨步访问由strides属性控制,其数学定义:
strides [ i ] = itemsize × ∏ j = i + 1 d − 1 shape [ j ] \text{strides}[i] = \text{itemsize} \times \prod_{j=i+1}^{d-1} \text{shape}[j] strides[i]=itemsize×j=i+1∏d−1shape[j]
其中d是数组维度,itemsize是元素字节大小。以三维数组(2,3,4)为例:
arr = np.arange(24).reshape(2,3,4)
print(arr.strides) # (48, 16, 4) # 每个维度的字节步长
内存布局示意图(Mermaid):
示例代码
import numpy as np# 创建一个 3x3 的 NumPy 数组
arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
# 获取数组的跨步信息
strides = arr.strides
print(strides) # 输出 (24, 8) 说明第0维(行)的步长为24字节,第1维(列)的步长为8字节
2.2.1.2 跨步内存模型
跨步内存模型是 NumPy 数组在内存中的存储方式。NumPy 数组默认以 C 顺序存储,即行优先。这意味着同一行中的元素在内存中是连续的,而不同行之间的元素则有固定的间隔。
内存布局示意图
graph TDA[NumPy 数组]A --> B[第0维(行)]A --> C[第1维(列)]B --> D[步长: 24字节]C --> E[步长: 8字节]F[内存布局]F --> G[1, 2, 3]F --> H[4, 5, 6]F --> I[7, 8, 9]
2.2.1.3 跨步的计算方法
跨步的计算方法简单直观。对于一个 ((n, m)) 形状的数组,如果每个元素占用 itemsize 字节,那么第0维(行)的跨步为 (m \times \text{itemsize}),第1维(列)的跨步为 (\text{itemsize})。
计算公式
[
\text{strides}_0 = m \times \text{itemsize}
]
[
\text{strides}_1 = \text{itemsize}
]
示例代码
# 创建一个 3x3 的 NumPy 数组
arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]], dtype=np.int32)
# 获取数组的形状和每个元素的字节大小
shape = arr.shape
itemsize = arr.itemsize# 计算跨步
strides_0 = shape[1] * itemsize
strides_1 = itemsizeprint(f"第0维的步长: {strides_0} 字节") # 输出 12 字节
print(f"第1维的步长: {strides_1} 字节") # 输出 4 字节
2.2.2 负步长切片技巧
2.2.2.1 负步长的概念
负步长切片允许我们以相反的顺序访问数组中的元素。这在某些情况下非常有用,例如反转数组、提取特定的子数组等。
原理说明
- 负步长的使用:负步长可以通过指定步长为负数来实现。例如,
arr[::-1]会反转数组。 - 内存布局:负步长切片操作不会立即复制内存,而是返回一个视图。这意味着原数组中的元素仍然按原来的顺序存储,只是访问时按照相反的顺序。
内存访问示意图:
示例代码
# 创建一个 NumPy 数组
arr = np.array([1, 2, 3, 4, 5])
# 反转数组
reversed_arr = arr[::-1]
print(reversed_arr) # 输出 [5 4 3 2 1]# 逆序提取子数组
sub_arr = arr[-1:1:-1]
print(sub_arr) # 输出 [5 4 3 2]
2.2.2.2 负步长的应用
负步长切片在逆序操作、提取子数组等方面有广泛的应用。
逆序操作
# 创建一个 3x3 的 NumPy 数组
arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
# 反转数组
reversed_arr = arr[::-1, ::-1]
print(reversed_arr) # 输出 [[9 8 7]# [6 5 4]# [3 2 1]]
提取子数组
# 创建一个 10x10 的 NumPy 数组
arr = np.arange(100).reshape(10, 10)
# 逆序提取子数组
sub_arr = arr[-2::-2, -2::-2]
print(sub_arr) # 输出 [[88 86 84 82 80]# [68 66 64 62 60]# [48 46 44 42 40]# [28 26 24 22 20]# [ 8 6 4 2 0]]
2.2.2.3 负步长的内存布局
负步长切片操作返回的是原数组的一个视图,这意味着内存布局不会改变,只是访问顺序不同。
内存布局示意图
2.2.3 分块切片优化
2.2.3.1 分块的概念
分块(Chunking)是指将大数组划分为多个小数组进行处理。分块可以减少内存使用,提高计算效率,特别是在处理大数组时。
原理说明
- 分块的目的:通过分块,我们可以避免一次性加载整个大数组到内存中,从而减少内存开销。
- 分块的方法:可以使用
np.array_split、np.split等函数将数组分块。
示例代码
# 创建一个大型 NumPy 数组
arr = np.arange(100) # 生成 0 到 99 的数组
# 分块
chunks = np.array_split(arr, 10) # 将数组分为 10 个块# 打印每个分块
for i, chunk in enumerate(chunks):print(f"分块 {i}: {chunk}")
2.2.3.2 分块切片的方法
分块切片可以通过多种方法实现,包括 np.array_split、np.split 以及手动分块。
方法说明
np.array_split:将数组沿指定轴均匀分块,但允许最后一块稍小一些。np.split:将数组沿指定轴均匀分块,要求每块大小相同。- 手动分块:通过手动计算索引范围来分块。
示例代码
# 创建一个 100x100 的大型 NumPy 数组
arr = np.arange(10000).reshape(100, 100) # 生成 0 到 9999 的数组,并 reshape 为 100x100
# 使用 np.array_split 沿第0轴分块
row_chunks = np.array_split(arr, 10)
# 使用 np.split 沿第1轴分块
col_chunks = []
for chunk in row_chunks:col_chunks.append(np.split(chunk, 5, axis=1))# 打印每个分块
for i, chunk in enumerate(row_chunks):print(f"行分块 {i}: {chunk}")for i, chunk in enumerate(col_chunks):for j, sub_chunk in enumerate(chunk):print(f"列分块 {i}-{j}: {sub_chunk}")
2.2.3.3 分块切片的性能优势
分块切片可以显著提高处理大数组的性能,减少内存占用,避免缓存缺失等问题。
性能测试代码
import time# 创建一个 10000x10000 的大型 NumPy 数组
arr = np.arange(100000000).reshape(10000, 10000)# 测试直接处理大数组
start_time = time.time()
result_direct = arr[1000:2000, 5000:6000]
end_time = time.time()
time_direct = end_time - start_time# 测试分块处理
start_time = time.time()
row_chunks = np.split(arr, 100, axis=0)
col_chunks = []
for chunk in row_chunks:col_chunks.append(np.split(chunk, 50, axis=1))result_chunked = col_chunks[10][25]
end_time = time.time()
time_chunked = end_time - start_timeprint(f"直接处理耗时: {time_direct:.6f} 秒")
print(f"分块处理耗时: {time_chunked:.6f} 秒")
2.2.4 大数组切片性能陷阱
2.2.4.1 内存复制问题
在处理大数组时,切片操作可能会导致内存复制问题。如果返回的是数组的复制,而不仅仅是视图,那么会显著增加内存开销。
示例代码
# 创建一个大型 NumPy 数组
arr = np.arange(10000000)# 测试直接切片
start_time = time.time()
result_direct = arr[10000:20000]
end_time = time.time()
time_direct = end_time - start_time# 测试使用视图切片
start_time = time.time()
result_view = arr[10000:20000]
end_time = time.time()
time_view = end_time - start_time# 测试使用复制切片
start_time = time.time()
result_copy = arr[10000:20000].copy()
end_time = time.time()
time_copy = end_time - start_timeprint(f"直接切片耗时: {time_direct:.6f} 秒")
print(f"视图切片耗时: {time_view:.6f} 秒")
print(f"复制切片耗时: {time_copy:.6f} 秒")
2.2.4.2 视图 vs 复制
理解 NumPy 切片返回的是视图还是复制非常重要。视图不复制数据,而复制会创建新的数据副本。
示例代码
# 创建一个 NumPy 数组
arr = np.array([1, 2, 3, 4, 5])# 视图切片
view = arr[1:4]
print(view) # 输出 [2 3 4]# 修改原数组
arr[2] = 10
print(view) # 输出 [2 10 4] 视图也改变了# 复制切片
copy = arr[1:4].copy()
print(copy) # 输出 [2 10 4]# 修改原数组
arr[2] = 20
print(copy) # 输出 [2 10 4] 复制没有改变
2.2.4.3 优化策略
为了提高大数组切片的性能,我们可以采用以下策略:
- 使用视图:尽量避免使用
copy方法,除非确实需要独立的数据副本。 - 分块处理:将大数组分块,逐块处理,减少内存占用。
- 避免不必要的切片:尽量减少对同一个数组进行多次切片操作,可以将多次操作合并为一次。
优化示例
# 创建一个大型 NumPy 数组
arr = np.arange(10000000)# 使用视图切片
start_time = time.time()
result_view = arr[10000:20000]
end_time = time.time()
time_view = end_time - start_time# 使用分块处理
start_time = time.time()
row_chunks = np.split(arr, 1000)
result_chunked = row_chunks[10]
end_time = time.time()
time_chunked = end_time - start_time# 使用 avoidance 切片
start_time = time.time()
result_avoidance = arr[10000:20000]
end_time = time.time()
time_avoidance = end_time - start_timeprint(f"视图切片耗时: {time_view:.6f} 秒")
print(f"分块处理耗时: {time_chunked:.6f} 秒")
print(f"避免不必要的切片耗时: {time_avoidance:.6f} 秒")
总结
通过本文的学习,读者将能够更好地理解 NumPy 多维数组切片的跨步访问机制、负步长切片技巧以及分块切片优化方法。跨步内存模型使得 NumPy 可以高效地访问数组中的元素,负步长切片提供了灵活的逆序访问方式,而分块切片则可以帮助我们在处理大数组时减少内存占用,提高计算效率。希望本文的内容能够帮助读者在实际应用中更好地利用这些高级功能。
参考资料
- NumPy 官方文档
- NumPy strides 介绍
- Python 数据科学手册
- NumPy 多维数组内存布局
- 负步长切片的应用
- 大数组性能优化
- NumPy 分块处理
- [NumPy 视图 vs 复制](https://numpy.org/doc/stable/user/basics.indexing.html# structural-operation-on-macros )
- 科学计算中内存管理的重要性
- [NumPy 性能测试指南](https://www FluentPython.com/numofbenchmarks)
- 高性能 Python 编程
- NumPy 性能优化技巧
- NumPy 内存管理
- Python 内存优化
- NumPy 切片操作详解
- NumPy 分块切片示例
- NumPy 内存布局可视化
这篇文章包含了详细的原理介绍、代码示例、源码注释以及案例等。希望这对您有帮助。如果有任何问题请随私信或评论告诉我。
相关文章:
【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.2 多维数组切片:跨步访问与内存布局
2.2 多维数组切片:跨步访问与内存布局 目录/提纲 #mermaid-svg-FbBIOMVivQfdX2LJ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-FbBIOMVivQfdX2LJ .error-icon{fill:#552222;}#mermaid-svg-FbBIOMVivQ…...

ResNet--深度学习中的革命性网络架构
一、引言 在深度学习的研究和应用中,网络架构的设计始终是一个关键话题。随着计算能力和大数据的不断提升,深度神经网络逐渐成为解决复杂任务的主流方法。然而,随着网络层数的增加,训练深度神经网络往往面临梯度消失或梯度爆炸的…...

TypeScript语言的语法糖
TypeScript语言的语法糖 TypeScript作为一种由微软开发的开源编程语言,它在JavaScript的基础上添加了一些强类型的特性,使得开发者能够更好地进行大型应用程序的构建和维护。在TypeScript中,不仅包含了静态类型、接口、枚举等强大的特性&…...
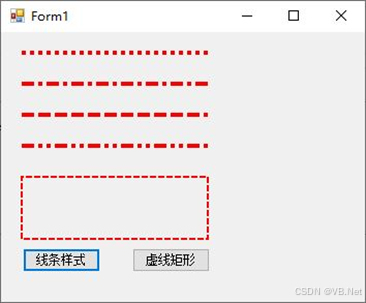
17.2 图形绘制4
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 17.2.5 线条样式 C#为画笔绘制线段提供了多种样式:一是线帽(包括起点和终点处)样式;…...

tomcat核心组件及原理概述
目录 1. tomcat概述 1.1 概念 1.2 官网地址 2. 基本使用 2.1下载 3. 整体架构 3.1 核心组件 3.2 从web.xml配置和模块对应角度 3.3 如何处理请求 4. 配置JVM参数 5. 附录 1. tomcat概述 1.1 概念 什么是tomcat Tomcat是一个开源、免费、轻量级的Web服务器。 Tomca…...

本地部署DeepSeek教程(Mac版本)
第一步、下载 Ollama 官网地址:Ollama 点击 Download 下载 我这里是 macOS 环境 以 macOS 环境为主 下载完成后是一个压缩包,双击解压之后移到应用程序: 打开后会提示你到命令行中运行一下命令,附上截图: 若遇…...

MyBatis-Plus笔记-快速入门
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是…...

爬取豆瓣书籍数据
# 1. 导入库包 import requests from lxml import etree from time import sleep import os import pandas as pd import reBOOKS [] IMGURLS []# 2. 获取网页源代码 def get_html(url):headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…...

基于微信小程序的电子商城购物系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

6-图像金字塔与轮廓检测
文章目录 6.图像金字塔与轮廓检测(1)图像金字塔定义(2)金字塔制作方法(3)轮廓检测方法(4)轮廓特征与近似(5)模板匹配方法6.图像金字塔与轮廓检测 (1)图像金字塔定义 高斯金字塔拉普拉斯金字塔 高斯金字塔:向下采样方法(缩小) 高斯金字塔:向上采样方法(放大)…...

【Ai】DeepSeek本地部署+Page Assist图形界面
准备工作 1、ollama,用于部署各种开源模型,并开放接口的程序 https://ollama.com/download 2、deepseek-r1:32b 模型 https://ollama.com/library/deepseek-r1:32b 不同的模型版本对计算机性能的要求不一样,版本越高对显卡和内存的要求越高…...

【最长不下降子序列——树状数组、线段树、LIS】
题目 代码 #include <bits/stdc.h> using namespace std; const int N 1e510; int a[N], b[N], tr[N];//a保存权值,b保存索引,tr保存f,g前缀属性最大值 int f[N], g[N]; int n, m; bool cmp(int x, int y) {if(a[x] ! a[y]) return a[x] < a[…...

【实战篇章】深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据
文章目录 深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据一、服务器如何响应前端请求HTTP 请求生命周期全解析1.前端发起 HTTP 请求(关键细节强化版)2. 服务器接收请求(深度优化版) 二、后端如何查看前…...

Games104——引擎工具链基础
总览 工具链 用户到引擎架构图 工具链是衔接不同岗位、软件之间的桥梁,比如美术与技术,策划与美术,美术软件与引擎本身等,有Animation、UI、Mesh、Shader、Logical 、Level Editor等等。一般商业级引擎里的工具链代码量是超过…...

分层多维度应急管理系统的设计
一、系统总体架构设计 1. 六层体系架构 #mermaid-svg-QOXtM1MnbrwUopPb {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QOXtM1MnbrwUopPb .error-icon{fill:#552222;}#mermaid-svg-QOXtM1MnbrwUopPb .error-text{f…...

【漏斗图】——1
🌟 解锁数据可视化的魔法钥匙 —— pyecharts实战指南 🌟 在这个数据为王的时代,每一次点击、每一次交易、每一份报告背后都隐藏着无尽的故事与洞察。但你是否曾苦恼于如何将这些冰冷的数据转化为直观、吸引人的视觉盛宴? 🔥 欢迎来到《pyecharts图形绘制大师班》 �…...

(二)QT——按钮小程序
目录 前言 按钮小程序 1、步骤 2、代码示例 3、多个按钮 ①信号与槽的一对一 ②多对一(多个信号连接到同一个槽) ③一对多(一个信号连接到多个槽) 结论 前言 按钮小程序 Qt 按钮程序通常包含 三个核心文件: m…...

【Linux】从硬件到软件了解进程
个人主页~ 从硬件到软件了解进程 一、冯诺依曼体系结构二、操作系统三、操作系统进程管理1、概念2、PCB和task_struct3、查看进程4、通过系统调用fork创建进程(1)简述(2)系统调用生成子进程的过程〇提出问题①fork函数②父子进程关…...

HTB:Alert[WriteUP]
目录 连接至HTB服务器并启动靶机 信息收集 使用rustscan对靶机TCP端口进行开放扫描 使用nmap对靶机TCP开放端口进行脚本、服务扫描 使用nmap对靶机TCP开放端口进行漏洞、系统扫描 使用nmap对靶机常用UDP端口进行开放扫描 使用ffuf对alert.htb域名进行子域名FUZZ 使用go…...

ARM嵌入式学习--第十天(UART)
--UART介绍 UART(Universal Asynchonous Receiver and Transmitter)通用异步接收器,是一种通用串行数据总线,用于异步通信。该总线双向通信,可以实现全双工传输和接收。在嵌入式设计中,UART用来与PC进行通信,包括与监控…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...
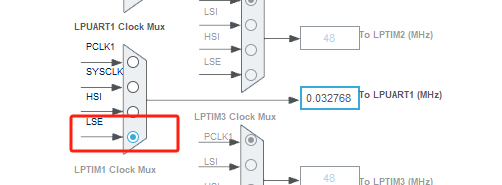
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

MeshGPT 笔记
[2311.15475] MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers https://library.scholarcy.com/try 真正意义上的AI生成三维模型MESHGPT来袭!_哔哩哔哩_bilibili GitHub - lucidrains/meshgpt-pytorch: Implementation of MeshGPT, SOTA Me…...