deep seek R1本地化部署及openAI API调用
先说几句题外话。
最近deep seek火遍全球,所以春节假期期间趁着官网优惠充值了deep seek的API,用openAI的接口方式尝试了下对deep seek的调用,并且做了个简单测试,测试内容确实非常简单:通过prompt提示词让大模型对用户提问做一个简单的提问场景判断,分了3个大类:一个是能耗问题,比如用户提问包括电流、电压、功率、能耗、耗能情况等等,判断为能耗问题。一个是生产问题,比如产量、产品等等,生产问题需要识别用户提问的日期范围之后转化为格式化输出,以便调用生产系统API获取数据。除此之外就是通用问题。
重点测试了生产相关的产量问题的日期范围测试,分别调用过讯飞的generalv3,智普的glm-4-plus,openAI的gpt-4o,提问比如上周的产量怎么样,不论我怎么调整提示词,generalv3都识别不出“上周”的时间范围,相同提示词的情况下,gpt-4o表现最好,识别的准确率最高,智普的glm-4-plus也还可以。
春节前用deepseek-reasoner试了下,对这个简单问题的表现很不错,因为我的openAI的apikey已经到期了所以没有办法对比测试了,但是单独测试deepseek-reasoner,每次都可以准确识别上周、上个月等时间范围。
其实这个测试是为了对function calling做一个简单的准备,验证一下将来如果有相关场景的话,是否可以通过funcation calling使大模型和业务系统做一个对接。前期测试结果并不能反映出模型是否支持我的业务场景,因为效果不好的直接原因可能就是我的提示词使用不当,不断优化提示词后应该能解决,因为问题确实非常简单。
好的,进入正题。
我的笔记本电脑配置很低,没有gpu,所以没有办法选择参数量比较大的模型做本地化部署,先选一个最小的,主要目的是验证一下本地化部署的步骤。
部署内容:
- Ollama:Ollama是开源大模型部署或管理工具,提供了对大部分知名模型的支持,对外提供了openAI的api接口、以及聊天窗口
- DeepSeek R1 1.5b:选了一个最小的模型,模型文件的大小是1.1GB,关键是推理过程中对GPU没有要求,我16g内存、无显卡的笔记本电脑,可以无障碍运行。
- 本地知识库搭建:搭建本地rag环境,安装embedding模型实现本地知识库的搭建(这一步还在摸索中,尚未找到合适的embedding模型,所以本次内容不涉及)。
下载安装Ollama
到Ollama官网:https://ollama.com/download 下载:

直接点击download for windows下载,不需要注册就可以下载。需要点时间,我还是下载了好一会儿的。
下载之后点击OllamaSetup.exe安装,点击安装之后,没有给用户提供参与的机会,直接默认安装到了:
C:\Users\username\AppData\Local\Programs\Ollama
你可以挪地方,比如整体copy到d盘,但是需要设置环境变量,将安装路径加入到path中。
安装deepseek R1
Ollama官网中,点击左上角右侧的models,发现deepseek-r1出现在很显眼的位置:

打开,选择1.5b,复制安装连接:

安装之前,需要先配置下环境变量OLLAMA_MODELS,OLLAMA_MODELS是指定Ollama的模型安装位置的:

准备好之后,运行上一步copy的安装命令,开始安装:
ollama run deepseek-r1:1.5b
首次运行,ollama会下载deepseek-r1:

安装完成后直接启动,在命令行窗口就可以直接使用了。
聊天窗口
Ollama有集成的Open WebUI聊天窗口,网上好多安装教程,这儿就不说了,不是本次研究内容,这次我也没安装。
openAI API调用
很简单,参考文档:
Ollama openai api 调用
python代码:
from openai import OpenAIclient = OpenAI(base_url='http://localhost:11434/v1/',# required but ignoredapi_key='ollama',
)chat_completion = client.chat.completions.create(messages=[{'role': 'user','content': '你好,你是谁,请将一个关于小明的笑话',}],model='deepseek-r1:1.5b',
)
print(chat_completion.choices[0].message.content)ollama本地安装后默认服务端口是11434,可以通过环境变量OLLAMA_HOST修改。
调试稍稍花了一点时间,是因为model没写对,刚开始写的deepseek-reasoner,调用报错404,之后命令行试了下:
C:\Users\zhang>ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 32 minutes ago
修改model为deepseek-r1:1.5b之后就ok可,调用成功了,但是讲的这个小明的笑话很是操蛋:
<think>
好的,我现在需要帮用户生成一个小明的笑话。首先,我得回想一下小明是个什么样的角色。小明应该是一个可爱的动物,可能从故事里看到他是哪个动物呢?比如兔子、松鼠或者狗之类的。接下来,笑话的核心是什么?一般来说,小明的好奇和困惑会让他的情节有趣。我可以利用这一点来设计谜题或矛盾。让我想想,小明每天都在做什么呢?如果他住在苹果树上,或者他在 garden里,这样的环境可以给他带来乐趣 。比如,他可能想算出苹果的数量或者解决蚂蚁困的难题。接着,我要考虑如何制造一个谜题或者谜语,让小明感到困惑和不安。我可以编一个关于天气的问题,比如“谁 在你的车里?”因为这个答案会让他陷入迷宫般的思考,而不是立刻告诉你答案。然后,我需要确保笑话有趣且容易理解。要让小明感觉困惑而不觉得奇怪,这样他的反应才会是那副可爱的猫头鹰样子。同时,谜题不能太难,保持简单的逻辑就可以了。最后,我要确保整个笑话结构清晰,开头点出小明的特点,接着制造疑问,然后解释答案或者引导到后面的内容。这样既符合用户的指示,又能传达出有趣的笑点。
</think>好的,以下是一个关于小明的笑话:---今天早上,小明刚从花园跑回来,看到花园里有一只受伤的大树被风吹坏了。“哎呀!谁在你的车里?”小明兴奋地指着旁边的一辆黑色轿车。“啊,别急,你就是那只兔子!”小东赶紧冲他微笑,“它经常在你那里偷吃苹果,所以今天 you 害死你。”小明眨了下眼睛,看着旁边的车窗上积了一层薄雾。突然之间,一个温暖的阳光照亮了整辆车。“对不起,请给我一杯饮料?”小明突然开口问道。“不用了,这是我刚才在 garden 发现的一个秘密洞穴。”小东笑着摇摇头,“那里住了一只小蚂蚁,它每天都会 自己结成一堆大面包。”“原来是这样啊!”小明开心地大笑起来,然后从车窗里的阳光中看去。“哦?你什么颜色眼睛?”小明兴奋地问道。“黄色。这就是我,我的新朋友凯特!”小东补充道,“我知道你在 garden 里看到了我们刚才说的苹果,后来那 个苹果树上的苹果都落下来了。”听到这笑语声后,小明忍不住笑了起来,终于找到了内心的平静点!---这样一个可爱的猫头鹰可爱的角色, Plus 这个谜题会让他的笑翻!
PS D:\develop\python\chatBot> & "D:/Program Files/python/python.exe" d:/develop/python/chatBot/base/test.py
<think>
嗯,用户给了我这个请求:“你好,你是谁,请将一个关于小明的笑话。” 我应该先分析一下这个问题。看起来 像是想测试我的知识,可能是在寻求帮助或获取一些信息。首先,“你好,你是谁”这句话本身就是一个常见的问候语,通常不会涉及到笑话。如果我回应“我是DeepSeek-R1-Lite-Preview”,可能会让用户觉得我只是在回答他的名字请求,而不是提供内容。接下来是关于小明的笑话。小明是一个常见的名字,而且中文里有很多关于小孩子的谐音 shorten语,比如“哪 里有我”、“永远抱我对不起你”。如果用户需要一些经典或有趣的笑话,我可以列举一些例子或者建议他找一些 记忆中和这些名字相关的梗。考虑到用户只是想要“一个”关于小明的笑话,我不确定是否有必要提供太多。所以我可能会列出几个常见的笑话来满足他的需求,同时鼓励他多提更多内容,这样我们能够更接近你的实际意图。此外,我也需要考虑用户的其他潜在需求,比如也许他们希望我帮助解答其他类型的提问,或者在写作中使用这个信息。因此,在回复时保持开放和友好的态度是比较好的策略,让用户知道我可以随时回应任何问题,即使是关于笑话的情况。总结一下,我的思考步骤包括:分析用户的问题,判断是否满足问候,检查是否有遗漏的可能内容,然后决定提供合适的回应,鼓励用户提供更多所需的内容。这样的条理确保我能够有效地帮助用户。
</think>你好!我是DeepSeek-R1-Lite-Preview。如果您指的是一个关于小明的笑话,我可以为您提供一些经典的小说梗、动画或儿童领域的梗。比如: 1. **小明遇到大 trouble**:小明在数学题中总是错,最终老师用他爸爸教他的方法纠正了他。
2. **小明的自白**:小明每次都在学校里说话的时候不小心把自己说出来。
3. **小明的搞笑表情和打字机**:- 你看看那个破手机,冲你的笑点喊“开”?让他帮你写个字。
4. **小明小时候喜欢学编程**:- 爸爸问他会不会能算错分数,可他说只要不教别人就好了。
5. **小明的迷路**:小明在放学路上不小心跌了一跤,撞到树上摔在地上。如果您希望一个更具体或针对某个故事的小明梗,请告诉我!
不过这里可以看到deepseek R1作为推理模型的影子,他的回答里有一部分括起来的内容,应该就是他的推理过程,很像其他模型中你用提示词告诉他要用到思维链的回答方式。
下次尝试补充embeding模型的本地化部署,在ollama官网看到了这个:
这几天找一个靠谱的、资源消耗低的,先研究下。
Thanks!
相关文章:
deep seek R1本地化部署及openAI API调用
先说几句题外话。 最近deep seek火遍全球,所以春节假期期间趁着官网优惠充值了deep seek的API,用openAI的接口方式尝试了下对deep seek的调用,并且做了个简单测试,测试内容确实非常简单:通过prompt提示词让大模型对用…...

力扣第435场周赛讲解
文章目录 题目总览题目详解3442.奇偶频次间的最大差值I3443.K次修改后的最大曼哈顿距离3444. 使数组包含目标值倍数的最少增量3445.奇偶频次间的最大差值 题目总览 奇偶频次间的最大差值I K次修改后的最大曼哈顿距离 使数组包含目标值倍数的最少增量 奇偶频次间的最大差值II …...

初入机器学习
写在前面 本专栏专门撰写深度学习相关的内容,防止自己遗忘,也为大家提供一些个人的思考 一切仅供参考 概念辨析 深度学习: 本质是建模,将训练得到的模型作为系统的一部分使用侧重于发现样本集中隐含的规律难点是认识并了解模型&…...

Signature
Signature 题目是: import ecdsaimport randomdef ecdsa_test(dA,k):sk ecdsa.SigningKey.from_secret_exponent(secexpdA,curveecdsa.SECP256k1)sig1 sk.sign(databHi., kk).hex()sig2 sk.sign(databhello., kk).hex()#不同的kr1 int(sig1[:64], 16)s1 i…...

93,【1】buuctf web [网鼎杯 2020 朱雀组]phpweb
进入靶场 页面一直在刷新 在 PHP 中,date() 函数是一个非常常用的处理日期和时间的函数,所以应该用到了 再看看警告的那句话 Warning: date(): It is not safe to rely on the systems timezone settings. You are *required* to use the date.timez…...
笔灵ai写作技术浅析(四):知识图谱
知识图谱(Knowledge Graph)是一种结构化的知识表示方式,通过将知识以图的形式进行组织,帮助AI系统更好地理解和利用信息。在笔灵AI写作中,知识图谱技术被广泛应用于结构化组织各种领域的知识,使AI能够根据写作主题快速获取相关的背景知识、概念关系等,从而为生成内容提供…...
Chromium132 编译指南 - Android 篇(四):配置 depot_tools
1. 引言 在前面的章节中,我们详细介绍了编译 Chromium 132 for Android 所需的系统和硬件要求,以及如何安装和配置基础开发环境和常用工具。完成这些步骤后,接下来需要配置 depot_tools,这是编译 Chromium 的关键工具集。depot_t…...

使用真实 Elasticsearch 进行高级集成测试
作者:来自 Elastic Piotr Przybyl 掌握高级 Elasticsearch 集成测试:更快、更智能、更优化。 在上一篇关于集成测试的文章中,我们介绍了如何通过改变数据初始化策略来缩短依赖于真实 Elasticsearch 的集成测试的执行时间。在本期中࿰…...

SQL进阶实战技巧:如何分析浏览到下单各步骤转化率及流失用户数?
目录 0 问题描述 1 数据准备 2 问题分析 3 问题拓展 3.1 跳出率计算...
机器学习--概览
一、机器学习基础概念 1. 定义 机器学习(Machine Learning, ML):通过算法让计算机从数据中自动学习规律,并利用学习到的模型进行预测或决策,而无需显式编程。 2. 与编程的区别 传统编程机器学习输入:规…...

低代码系统-产品架构案例介绍、炎黄盈动-易鲸云(十二)
易鲸云作为炎黄盈动新推出的产品,在定位上为低零代码产品。 开发层 表单引擎 表单设计器,包括设计和渲染 流程引擎 流程设计,包括设计和渲染,需要说明的是:采用国际标准BPMN2.0,可以全球通用 视图引擎 视图…...
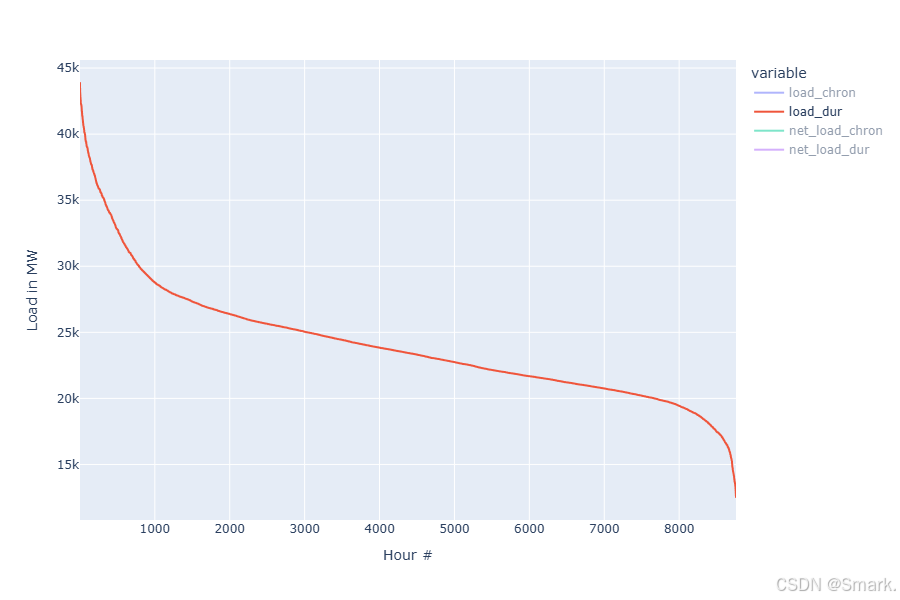
Electricity Market Optimization 探索系列(二)
本文参考链接link 负荷持续时间曲线 (Load Duration Curve),是根据实际的符合数据进行降序排序之后得到的一个曲线 这个曲线能够发现负荷在某个区间时,将会持续多长时间,有助于发电容量的规划 净负荷(net load) 是指预期负荷和预期可再生…...

OpenAI 实战进阶教程 - 第一节:OpenAI API 架构与基础调用
目标 掌握 OpenAI API 的基础调用方法。理解如何通过 API 进行内容生成。使用实际应用场景帮助零基础读者理解 API 的基本用法。 一、什么是 OpenAI API? OpenAI API 是一种工具,允许开发者通过编程方式与 OpenAI 的强大语言模型(例如 gpt-…...
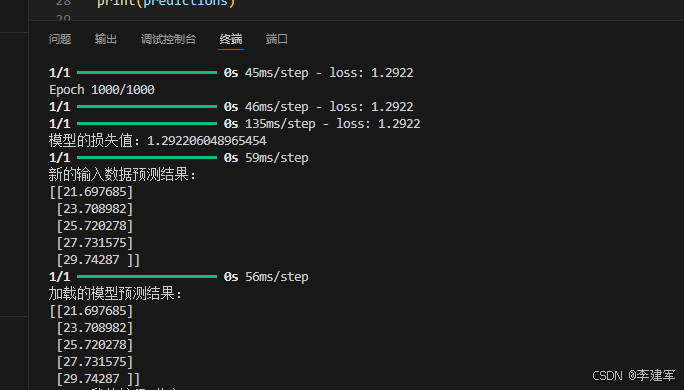
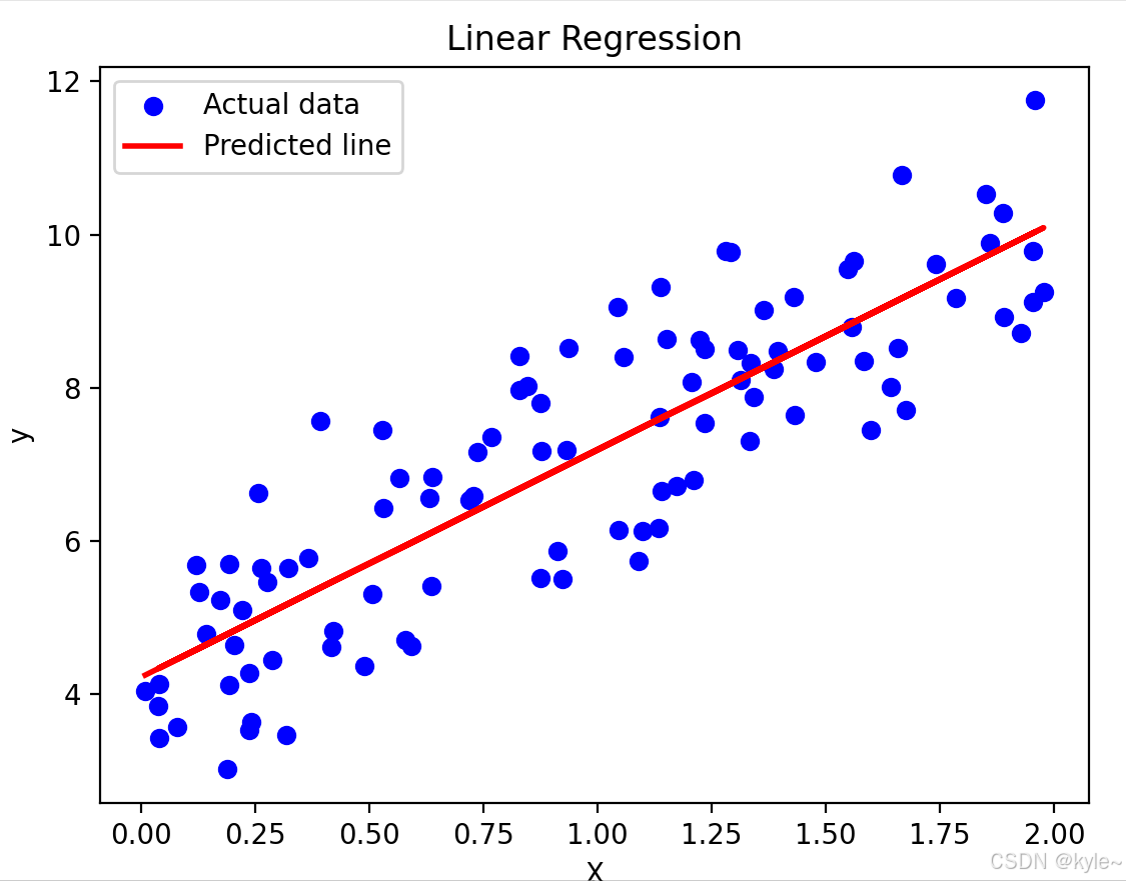
TensorFlow简单的线性回归任务
如何使用 TensorFlow 和 Keras 创建、训练并进行预测 1. 数据准备与预处理 2. 构建模型 3. 编译模型 4. 训练模型 5. 评估模型 6. 模型应用与预测 7. 保存与加载模型 8.完整代码 1. 数据准备与预处理 我们将使用一个简单的线性回归问题,其中输入特征 x 和标…...

【视频+图文详解】HTML基础4-html标签的基本使用
图文教程 html标签的基本使用 无序列表 作用:定义一个没有顺序的列表结构 由两个标签组成:<ul>以及<li>(两个标签都属于容器级标签,其中ul只能嵌套li标签,但li标签能嵌套任何标签,甚至ul标…...

在Arm芯片苹果Mac系统上通过homebrew安装多版本mysql并解决各种报错,感谢deepseek帮助解决部分问题
背景: 1.苹果设备上安装mysql,随着苹果芯片的推出,很多地方都变得不一样了。 2.很多时候为了老项目能运行,我们需要能安装mysql5.7或者mysql8.0或者mysql8.2.虽然本文编写时最新的默认mysql已经是9.2版本。 安装步骤 1.执行hom…...

c++可变参数详解
目录 引言 库的基本功能 va_start 宏: va_arg 宏 va_end 宏 va_copy 宏 使用 处理可变参数代码 C11可变参数模板 基本概念 sizeof... 运算符 包扩展 引言 在C编程中,处理不确定数量的参数是一个常见的需求。为了支持这种需求,C标准库提供了 &…...
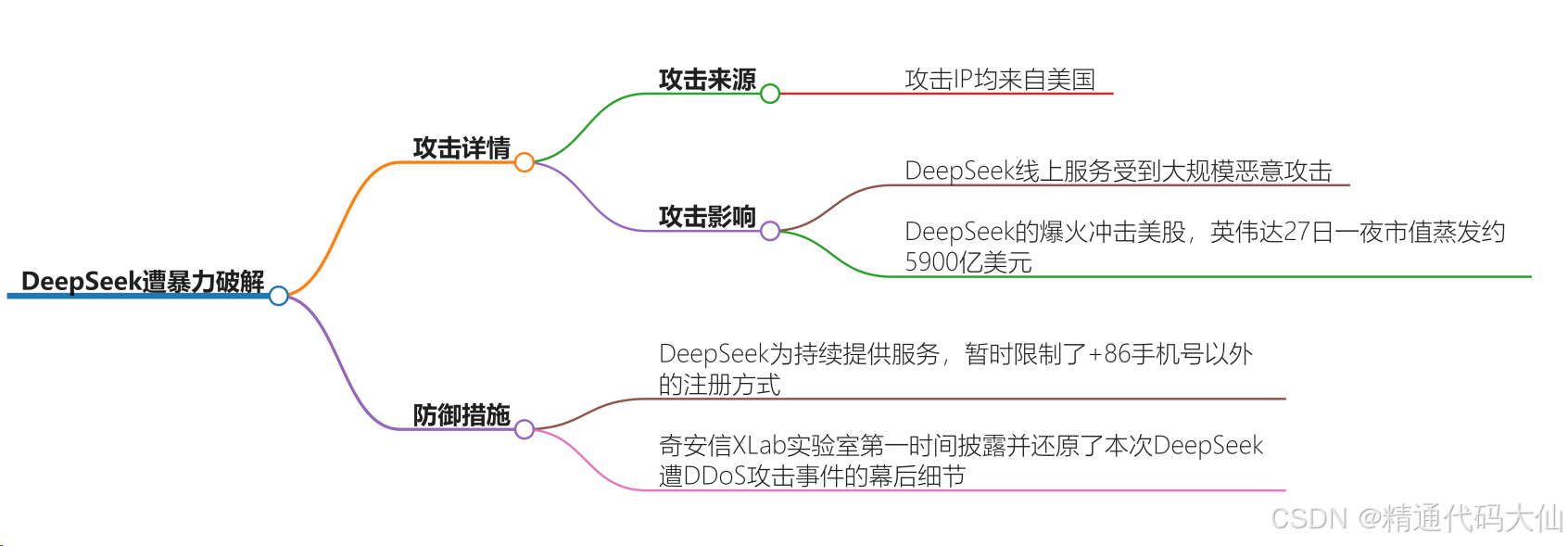
【深度分析】DeepSeek 遭暴力破解,攻击 IP 均来自美国,造成影响有多大?有哪些好的防御措施?
技术铁幕下的暗战:当算力博弈演变为代码战争 一场针对中国AI独角兽的全球首例国家级密码爆破,揭开了数字时代技术博弈的残酷真相。DeepSeek服务器日志中持续跳动的美国IP地址,不仅是网络攻击的地理坐标,更是技术霸权对新兴挑战者的…...
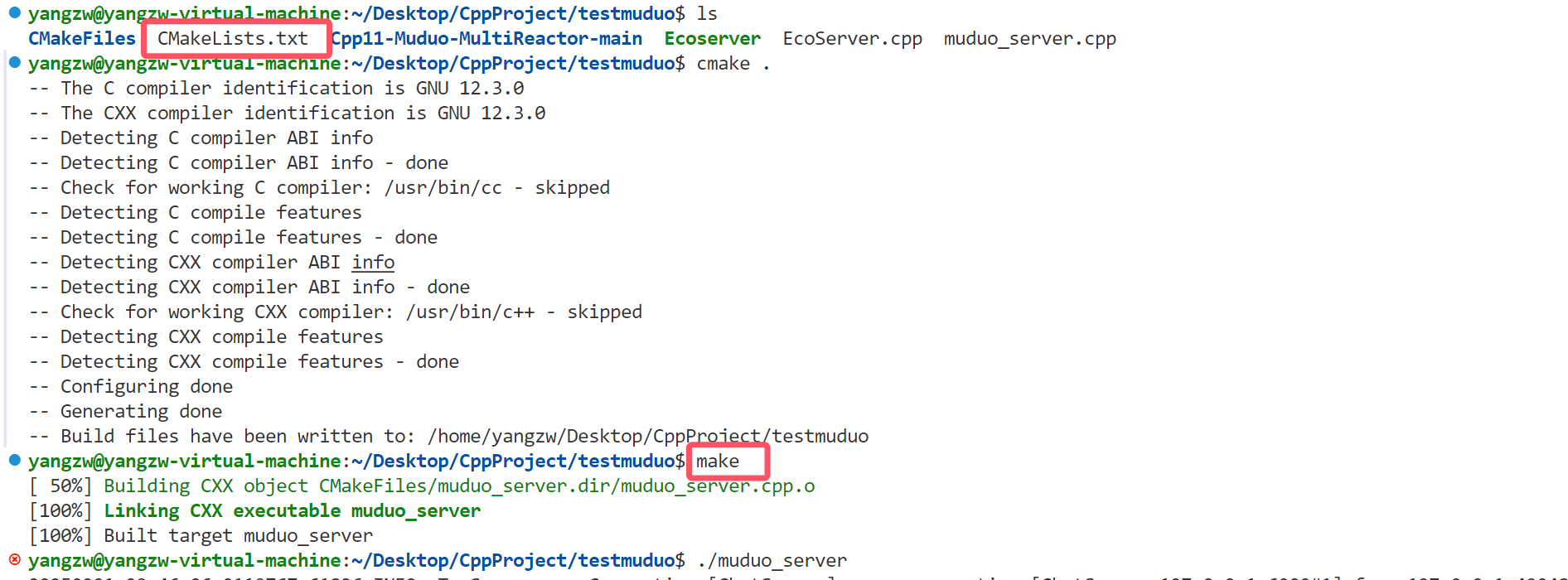
CMake项目编译与开源项目目录结构
Cmake 使用简单方便,可以跨平台构建项目编译环境,尤其比直接写makefile简单,可以通过简单的Cmake生成负责的Makefile文件。 如果没有使用cmake进行编译,需要如下命令:(以muduo库echo服务器为例)…...

完全卸载mysql server步骤
1. 在控制面板中卸载mysql 2. 打开注册表,运行regedit, 删除mysql信息 HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->EventLog->Application->Mysql HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->Mysql …...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...