分布式事务组件Seata简介与使用,搭配Nacos统一管理服务端和客户端配置
文章目录
- 一. Seata简介
- 二. 官方文档
- 三. Seata分布式事务代码实现
- 0. 环境简介
- 1. 添加undo_log表
- 2. 添加依赖
- 3. 添加配置
- 4. 开启Seata事务管理
- 5. 启动演示
- 四. Seata Server配置Nacos
- 1. 修改配置类型
- 2. 创建Nacos配置
- 五. Seata Client配置Nacos
- 1. 增加Seata关联Nacos的配置
- 2. 在Nacos中对应的train-group添加配置
- 3. 测试有效性
一. Seata简介
Seata 是一款开源的分布式事务解决方案,旨在解决微服务架构下的数据一致性问题。它支持 AT、TCC、Saga 和 XA 四种事务模式,能够适应不同的业务场景。
AT模式,默认,简单,需要增加undo_log表,生成反向SQL,性能高;回滚后,原来没数据的,现在还是没数据TCC模式,try confirm/cancel,三个阶段的代码都得自己实现,Seata只负责调度;对业务代码侵入性较强,必要时可能还要修改数据库SAGA模式,长事务解决方案,需要程序员自己编写两阶段代码(AT模式不需要写第二阶段);基于状态机来实现的,需要一个JSON文件,可异步执行XA模式,XA 协议是由 X/Open 组织提出的分布式事务处理规范,基于数据库的XA协议来实现2PC发称为XA方案,适用于强一致性的场景,比如金融、银行等
Seata 的核心架构包括事务协调器(TC)、事务管理器(TM)和资源管理器(RM),通过两阶段提交协议实现全局事务的管理。其优势在于对业务代码侵入性低、性能高效,且与 Spring Cloud、Dubbo 等主流微服务框架无缝集成,是构建高可靠分布式系统的理想选择。
二. 官方文档
官方文档
下载地址
GitHub 仓库
Seata 示例项目
三. Seata分布式事务代码实现
接下来将用代码模拟AT模式的分布式事务管理。
0. 环境简介
项目模拟12306会员购票场景,购票后需要进行余票更新以及会员购票信息保存的操作,分别对应business模块和member模块的操作。要求business通过feign调用member的保存功能。
此时如果用传统事务注解@Transactional,仅仅在business模块的方法进行事务管理,是无法管理远程调用的模块同样进行回滚的。
此时就要用到Seata进行分布式事务管理,同时演示的是AT模式,自动生成反向SQL。
1. 添加undo_log表
在business和member数据库中添加undo_log表,执行SQL:
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2. 添加依赖
在business和member模块中添加Seata依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
3. 添加配置
在business和member模块的bootstrap.properties添加配置:
# 事务组名称service.vgroupMapping.train-group=default
seata.tx-service-group=train-group
# 事务组和seata集群做关联
seata.service.vgroup-mapping.train-group=default
# seata集群对应的机器
seata.service.grouplist.default=127.0.0.1:8091
一个项目的多个模块,配置成同一个事务组
4. 开启Seata事务管理
仅需要service业务逻辑方法上添加注解,即可开启Seata事务管理:
import io.seata.spring.annotation.GlobalTransactional;@GlobalTransactional
5. 启动演示
- 启动Seata服务
解压Seata文件夹,双击bin目录下的seata-server.bat


Seata服务可视化界面启动在7091端口,而监听端口是8091
- 启动SpringBoot服务


可以看到启动后Seata打印的日志,表明SpringBoot应用和Seata成功连接,成功注册两个TM和RM
- 异常设置
为了显示事务回滚效果,在member模块保存的业务逻辑中,手动添加事务异常:
public void save(MemberTicketReq req) throws Exception {LOG.info("seata全局事务ID save: {}", RootContext.getXID());DateTime now = DateTime.now();Ticket ticket = BeanUtil.copyProperties(req, Ticket.class);ticket.setId(SnowUtil.getSnowflakeNextId());ticket.setCreateTime(now);ticket.setUpdateTime(now);ticketMapper.insert(ticket);// 模拟被调用方出现异常if (1 == 1) {throw new Exception("测试异常11");}}
预计效果为,Seata回滚余票更新,并向前端抛出异常
- 测试结果


与预期结果相同,测试成功!
四. Seata Server配置Nacos
让Nacos统一设置Seata Server的配置,以免再去手动修改配置文件。
nacos的介绍和使用可以参考我之前的博客:传送门
1. 修改配置类型
- 打开配置文件
seata\conf\application.yml,修改以下内容:
seata:config:# support: nacos, consul, apollo, zk, etcd3type: fileregistry:# support: nacos, eureka, redis, zk, consul, etcd3, sofatype: file
更改为nacos的注册中心和配置中心:
seata:config:# support: nacos, consul, apollo, zk, etcd3type: nacosnacos:server-addr: 127.0.0.1:8848namespace: traingroup: SEATA_GROUPusername: nacospassword: nacoscontext-path:##if use MSE Nacos with auth, mutex with username/password attribute#access-key:#secret-key:data-id: seataServer.propertiesregistry:# support: nacos, eureka, redis, zk, consul, etcd3, sofatype: nacosnacos:application: seata-serverserver-addr: 127.0.0.1:8848group: SEATA_GROUPnamespace: traincluster: defaultusername: nacospassword: nacoscontext-path:##if use MSE Nacos with auth, mutex with username/password attribute#access-key:#secret-key:
!!! 注意每个:后面都要空一格
namespace: 设置nacos中的命名空间,用于项目间隔离
group:nacos中分组名称
username和password:nacos的用户名和密码,默认都为nacos
- 重启Seata服务

可见配置已生效,注册服务成功。登录Nacos客户端也可以看到配置的服务:

2. 创建Nacos配置
- 创建本地数据库seata:
在seata数据库中执行以下sql语句,创建四张表:
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`status` TINYINT NOT NULL,`application_id` VARCHAR(32),`transaction_service_group` VARCHAR(32),`transaction_name` VARCHAR(128),`timeout` INT,`begin_time` BIGINT,`application_data` VARCHAR(2000),`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`xid`),KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(`branch_id` BIGINT NOT NULL,`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`resource_group_id` VARCHAR(32),`resource_id` VARCHAR(256),`branch_type` VARCHAR(8),`status` TINYINT,`client_id` VARCHAR(64),`application_data` VARCHAR(2000),`gmt_create` DATETIME(6),`gmt_modified` DATETIME(6),PRIMARY KEY (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(`row_key` VARCHAR(128) NOT NULL,`xid` VARCHAR(128),`transaction_id` BIGINT,`branch_id` BIGINT NOT NULL,`resource_id` VARCHAR(256),`table_name` VARCHAR(32),`pk` VARCHAR(36),`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`row_key`),KEY `idx_status` (`status`),KEY `idx_branch_id` (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;CREATE TABLE IF NOT EXISTS `distributed_lock`
(`lock_key` CHAR(20) NOT NULL,`lock_value` VARCHAR(20) NOT NULL,`expire` BIGINT,primary key (`lock_key`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
- 新建配置如下:

store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true
store.db.user=seata
store.db.password=seata
数据库、用户名和密码需要修改为自己的
这样就成功利用Nacos管理Seata的服务端配置了!
五. Seata Client配置Nacos
接下来还需要用Nacos管理Seata的客户端配置。
1. 增加Seata关联Nacos的配置
在Seata管理的模块的bootstrap.properties中添加Nacos配置:
# seata注册中心,要和seata server的application.yml配置保持一致
seata.registry.type=nacos
seata.registry.nacos.application=seata-server
seata.registry.nacos.server-addr=127.0.0.1:8848
seata.registry.nacos.group=SEATA_GROUP
seata.registry.nacos.namespace=train
seata.registry.nacos.username=nacos
seata.registry.nacos.password=nacos# seata配置中心,要和seata server的application.yml配置保持一致
seata.config.type=nacos
seata.config.nacos.server-addr=127.0.0.1:8848
seata.config.nacos.group=SEATA_GROUP
seata.config.nacos.namespace=train
seata.config.nacos.dataId=seataServer.properties
seata.config.nacos.username=nacos
seata.config.nacos.password=nacos# 事务组名称,必须在nacos中有配置过:service.vgroupMapping.train-group=default
seata.tx-service-group=train-group
2. 在Nacos中对应的train-group添加配置

service.vgroupMapping.train-group=default
service.default.grouplist=127.0.0.1:8091
解释:
原来这两行是在SpringBoot中配置的,而现在配置了Seata+Nacos,等于是Nacos统一管理配置了,不用在本地一处处修改了,只要在线上统一管理即可。而在本地仅需要配置事务组名称即可,简化了配置。
3. 测试有效性
还是手动抛出异常,查看是否回滚:

成功回滚,则线上配置生效
相关文章:
分布式事务组件Seata简介与使用,搭配Nacos统一管理服务端和客户端配置
文章目录 一. Seata简介二. 官方文档三. Seata分布式事务代码实现0. 环境简介1. 添加undo_log表2. 添加依赖3. 添加配置4. 开启Seata事务管理5. 启动演示 四. Seata Server配置Nacos1. 修改配置类型2. 创建Nacos配置 五. Seata Client配置Nacos1. 增加Seata关联Nacos的配置2. 在…...

JavaScript常用的内置构造函数
JavaScript作为一种广泛应用的编程语言,提供了丰富的内置构造函数,帮助开发者处理不同类型的数据和操作。这些内置构造函数在创建和操作对象时非常有用。本文将详细介绍JavaScript中常用的内置构造函数及其用途。 常用内置构造函数概述 1. Object Obj…...
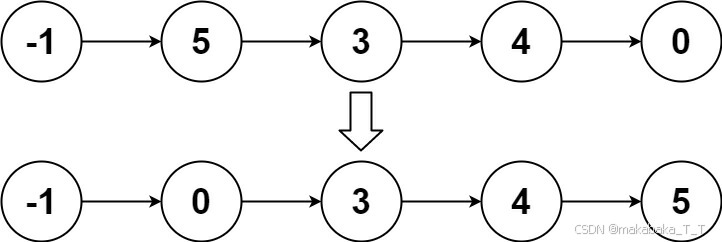
25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录 240. 搜索二维矩阵 II题目描述题解 148. 排序链表题目描述题解 240. 搜索二维矩阵 II 点此跳转题目链接 题目描述 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到…...
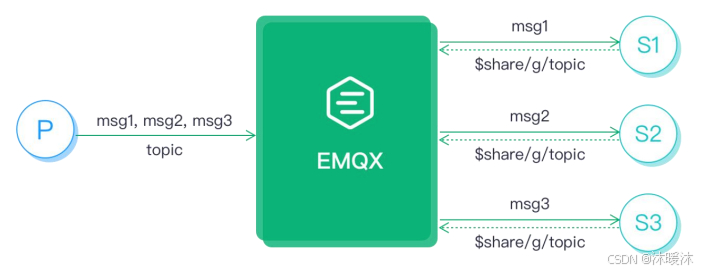
MQTT知识
MQTT协议 MQTT 是一种基于发布/订阅模式的轻量级消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用而设计,可以用极少的代码为联网设备提供实时可靠的消息服务。MQTT 协议广泛应用于物联网、移动互联网、智能硬件、车联网、智慧城市、远程医疗、…...

【机器学习与数据挖掘实战】案例11:基于灰色预测和SVR的企业所得税预测分析
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈机器学习与数据挖掘实战 ⌋ ⌋ ⌋ 机器学习是人工智能的一个分支,专注于让计算机系统通过数据学习和改进。它利用统计和计算方法,使模型能够从数据中自动提取特征并做出预测或决策。数据挖掘则是从大型数据集中发现模式、关联…...

新一代搜索引擎,是 ES 的15倍?
Manticore Search介绍 Manticore Search 是一个使用 C 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码…...

使用 Context API 管理临时状态,避免 Redux/Zustand 的持久化陷阱
在开发 React Native 应用时,我们经常需要管理全局状态,比如用户信息、主题设置、网络状态等。而对于某些临时状态,例如 数据同步进行中的状态 (isSyncing),我们应该选择什么方式来管理它? 在项目开发过程中ÿ…...
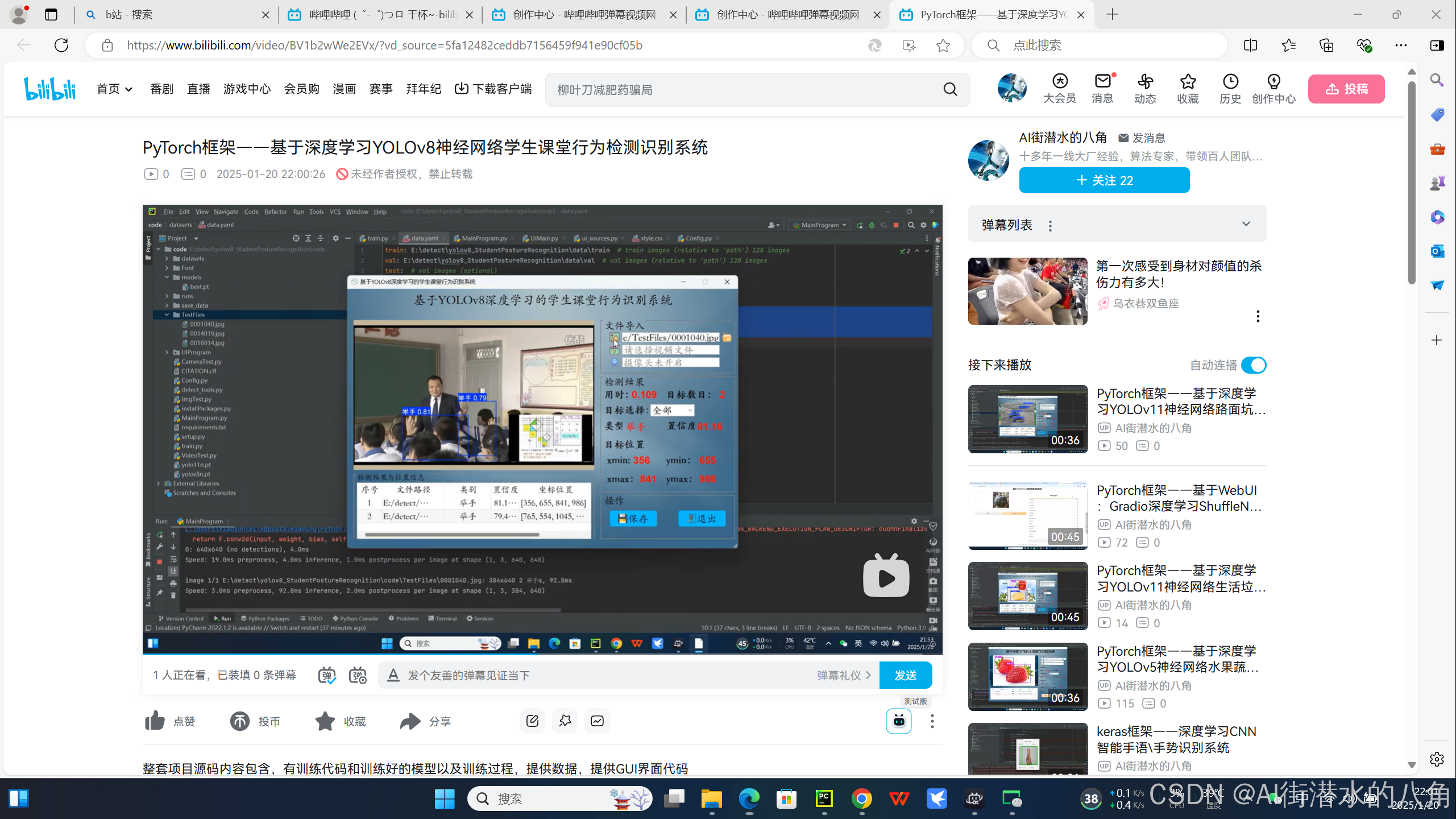
PyTorch框架——基于深度学习YOLOv8神经网络学生课堂行为检测识别系统
基于YOLOv8深度学习的学生课堂行为检测识别系统,其能识别三种学生课堂行为:names: [举手, 读书, 写字] 具体图片见如下: 第一步:YOLOv8介绍 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本…...

word2vec 实战应用介绍
Word2Vec 是一种由 Google 在 2013 年推出的重要词嵌入模型,通过将单词映射为低维向量,实现了对自然语言处理任务的高效支持。其核心思想是利用深度学习技术,通过训练大量文本数据,将单词表示为稠密的向量形式,从而捕捉单词之间的语义和语法关系。以下是关于 Word2Vec 实战…...

C# 操作符重载对象详解
.NET学习资料 .NET学习资料 .NET学习资料 一、操作符重载的概念 在 C# 中,操作符重载允许我们为自定义的类或结构体定义操作符的行为。通常,我们熟悉的操作符,如加法()、减法(-)、乘法&#…...

python学opencv|读取图像(五十四)使用cv2.blur()函数实现图像像素均值处理
【1】引言 前序学习进程中,对图像的操作均基于各个像素点上的BGR值不同而展开。 对于彩色图像,每个像素点上的BGR值为三个整数,因为是三通道图像;对于灰度图像,各个像素上的BGR值是一个整数,因为这是单通…...
: 非极大值抑制(Non-Maximum Suppression, NMS))
CNN的各种知识点(四): 非极大值抑制(Non-Maximum Suppression, NMS)
非极大值抑制(Non-Maximum Suppression, NMS) 1. 非极大值抑制(Non-Maximum Suppression, NMS)概念:算法步骤:具体例子:PyTorch实现: 总结: 1. 非极大值抑制(…...

虚幻基础16:locomotion direction
locomotion locomotion:角色运动系统的总称:包含移动、奔跑、跳跃、转向等。 locomotion direction 玩家输入 玩家输入:通常代表玩家想要的移动方向。 direction 可以计算当前朝向与移动方向的Δ。从而实现朝向与移动(玩家输入)方向的分…...

C++游戏开发实战:从引擎架构到物理碰撞
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 C 是游戏开发中最受欢迎的编程语言之一,因其高性能、低延迟和强大的底层控制能力,被广泛用于游戏…...

代理模式——C++实现
目录 1. 代理模式简介 2. 代码示例 1. 代理模式简介 代理模式是一种行为型模式。 代理模式的定义:由于某些原因需要给某对象提供一个代理以控制该对象的访问。这时,访问对象不适合或者不能直接访问引用目标对象,代理对象作为访问对象和目标…...

什么情况下,C#需要手动进行资源分配和释放?什么又是非托管资源?
扩展:如何使用C#的using语句释放资源?什么是IDisposable接口?与垃圾回收有什么关系?-CSDN博客 托管资源的回收有GC自动触发,而非托管资源需要手动释放。 在 C# 中,非托管资源是指那些不由 CLR(…...

LeetCode 2909. 元素和最小的山形三元组 II
**### LeetCode 2909. 元素和最小的山形三元组 II 问题描述 给定一个下标从 0 开始的整数数组 nums,我们需要找到一个“山形三元组”(i, j, k)满足以下条件: i < j < knums[i] < nums[j] 且 nums[k] < nums[j] 并…...

搬迁至bilibili声明
我将搬迁到bilibili ,用户名:北苏清风 在这个用户名上的文章部分将出自csdn的这个账号,均属于本人原创...

【周易哲学】生辰八字入门讲解(八)
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文讲解【周易哲学】生辰八字入门讲解,期待与你一同探索、学习、进步,一起卷起来叭! 目录 一、六亲女命六亲星六亲宫位相互关系 男命六亲星…...

复制粘贴小工具——Ditto
在日常工作中,复制粘贴是常见的操作,但Windows系统自带的剪贴板功能较为有限,只能保存最近一次的复制记录,这对于需要频繁复制粘贴的用户来说不太方便。今天,我们介绍一款开源、免费且功能强大的剪贴板增强工具——Dit…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...