详解八大排序算法-附动图和源码(插入,希尔,选择,堆排序,冒泡,快速,归并,计数)
目录
🍏一.排序的概念及应用🍏
1.排序的概念
2.排序的应用
3.常用的排序算法
🍎二.排序算法的实现🍎
1.插入排序
1.1直接插入排序
1.2希尔排序(缩小增量排序)
2.选择排序
2.1直接选择排序
2.2堆排序
3.比较排序
3.1冒泡排序
3.2快速排序
递归版本
快速排序递归优化
快速排序递归总过程
4.归并排序
5.计数排序
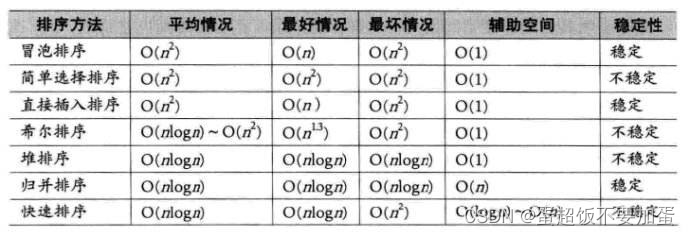
🍑三.排序总结🍑


🍏一.排序的概念及应用🍏
1.排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
我们可以通过学生的结构体来理解,把学生结构体看成记录,学生结构体里有姓名、成绩、学号等成员,任一成员都可以当成关键字,比如我们需要按照成绩对学生进行排名,则成绩作为关键字进行排序,即使得学生结构体这一记录通过成绩这一关键字进行排序
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
也就是有一个对于数组里面两个相同的数,比如说有一个5a和5b,排序前5a在5b前面,排序后5a依然在5b的前面,就说明此排序是稳定的,反之排序之后5a跑到5b的后面去了,就说明此排序是不稳定的
2.排序的应用
在我们日常购物中,我们经常会对物品进行排序,比如我要在京东买一个书包,我会优先选择很多人都买的,于是我会点击销量排序,选择销量好的书包
我们高考填志愿时,如果你考到了650分以上的成绩,你肯定会去找中国排名前几的大学去填志愿,而大学的排名就是根据综合实力和录取分数线进行排序的
3.常用的排序算法
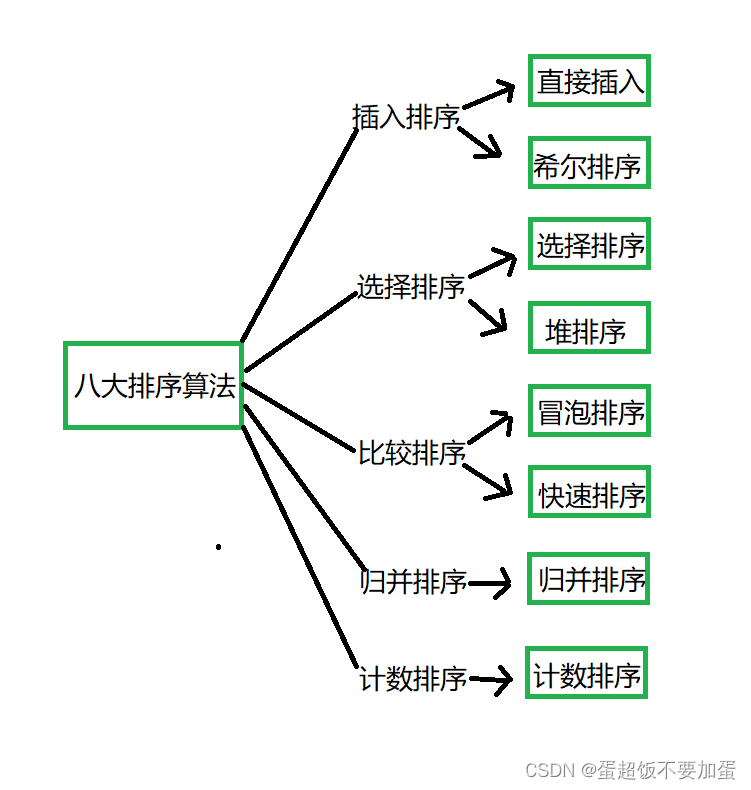
常用的排序算法有八大排序算法,分别是直接插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序、归并排序、计数排序
🍎二.排序算法的实现🍎
1.插入排序
本篇文章所有排序算法只讨论升序
1.1直接插入排序

代码:
void InsertSort(int* a, int n)
{for (int i = 0; i < n-1 ; i++){//end从第二个元素开始int end = i + 1;//保存待插入元素int tmp = a[end];int j;//j从待插入元素前一个元素开始比较for ( j = i; j >= 0; j--){if (a[j] > tmp)//如果元素比待插入元素大,则将该元素往后移a[j + 1] = a[j];else//如果遇到小于等于待插入元素的元素,则退出并将待插入元素放到该元素后面{break;}}/*把待插入元素放到该元素后面,如果上面循环结束之后依然没有找到比待插入元素小的说明待插入排序是最小的,即应该放到第一个位置,上面循环结束j为-1,j后面的位置即为下标为0的位置,符合要求*/a[j + 1] = tmp;}
}直接插入排序的特性总结:
1.元素集合越接近有序,直接插入排序的时间效率越高
由于待插入元素需要和前面已经有序的区间元素进行依次比较,假设原集合本身就是有序的,那么待插入元素只的前一个元素肯定比它小,所以只需比较一次,而所插入的位置就是待插入元素本身所在的位置,即减少了比较和移动的次数,所以当原集合有序或者接近有序时,直接插入的时间效率会大大提升
2.时间复杂度:O(N^2)
假设原集合是逆序的,那么从第二个元素开始,插入第二个元素要挪动1次,插入第三个元素要挪动2次,插入第四个元素要挪动3次,插入最后一个元素则要挪动n-1次,可以发现挪动的次数加起来是一个等差数列,1+2+3+4+..+n-1,由等差数列求和公式可以算出总移动次数为n*(n-1)/2,即时间复杂度为O(N^2)
3.空间复杂度:O(1)
由于直接插入元素是在原数组进行比较和移动的,没有开辟额外空间,也没有递归过程,故直接插入排序空间复杂度为O(1)
4.稳定性:稳定
由于直接插入排序在比较的过程中是遇到小于等于待插入元素的元素时就停止,即遇到相同的元素是将待插入元素放在该元素的后面而不是前面,故相同元素的相对前后位置不变,所以直接插入排序是稳定的排序
1.2希尔排序(缩小增量排序)
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个gap个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后,取新的gap为原来的一半,重复上述分组和排序的工作。当到达gap=1时,所有记录在统一组内排好序。
希尔排序是直接插入排序的一种优化,它把一组记录分成若干组进行类似于直接插入排序的操作,每一组数据中,从这组的第二个元素开始一次与前面的元素进行比较然后插入,只不过直接插入排序是与从相邻的元素开始比较,而组内的元素是从相邻gap的元素进行比较,将每组数据都排好后,我们会将新的gap变为原来的一半,然后继续分成gap组,每组元素进行类似直接插入排序,直到gap=1,当gap等于1的时候,就相当于就是直接插入排序了,由于之前每组元素都经过了排序,所以此时这组记录已经接近有序,利用直接插入排序就会大大提高效率
gap>1的分组排序操作称之为预排
gap=1时则为直接插入排序
即希尔排序的两个步骤为:
1.预排
2.直接插入排序
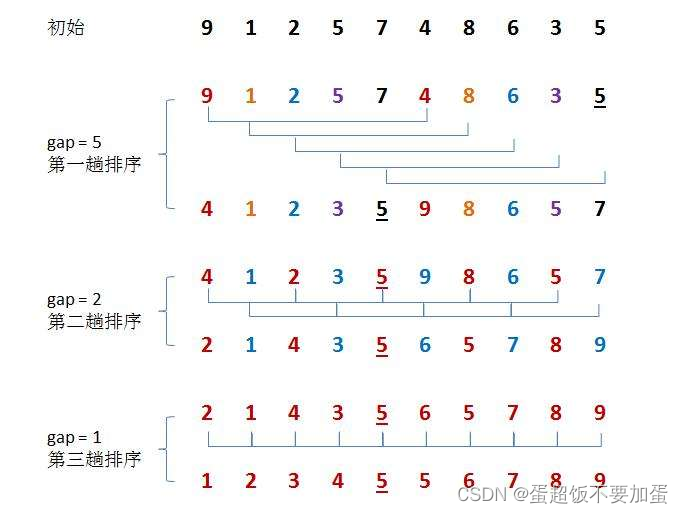
代码:
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap /= 2;//每次新的gap为原来的一半for (int i = 0; i < n - gap; i++)//从第二个元素开始,让此元素在所在的组内进行排序{int end = i + gap;//待插入元素的位置int tmp = a[end];//保存待插入元素int j = 0;for (j = i; j >= 0; j -= gap)//从待插入元素距离gap的第一个元素开始比较{if (a[j] > tmp)//元素大于待插入元素则往后挪动gap步a[j + gap] = a[j];else//元素小于等于待插入元素则退出break;}/*循环正常退出则说明待插入元素为该组最小的元素,即应该要插到该组第一个位置循环break退出则说明中途找到小于等于待插入元素的元素,插入到该元素后面距离gap的位置*/a[j + gap] = tmp;}}
}希尔排序的特性总结
1. 希尔排序是对直接插入排序的优化

《数据结构-用面向对象方法与C++描述》--- 殷人昆

目前比较公认的一个数据为O(n^1.3)
2.选择排序
2.1直接选择排序
每一次从待排序的数据元素中选出最小和最大的一个元素,分别存放在数组的左端和右端,然后将待排序的范围减少2,即减去上次存放到的左端和右端,直到全部待排序的数据元素排完 。
下面为只选择最大或最小的元素的情况的动图展示,同时选择最大和最小的元素的情况同理
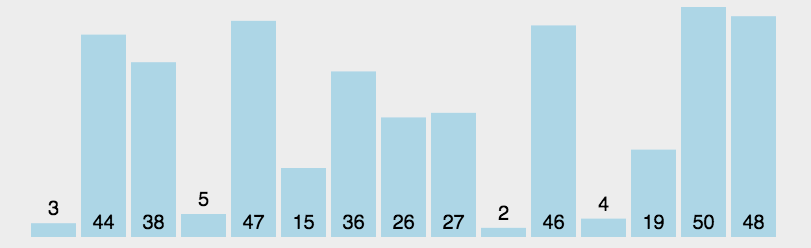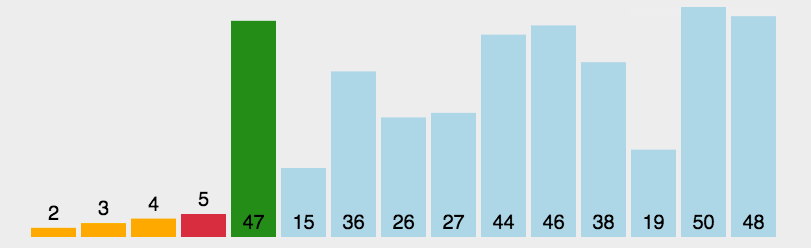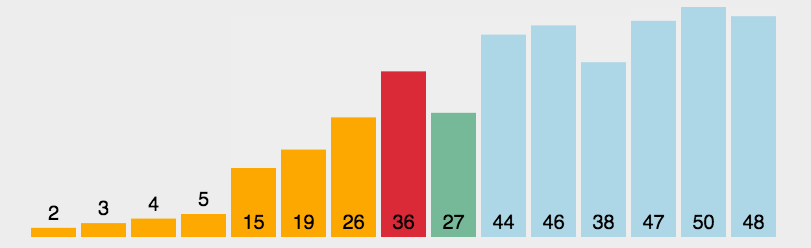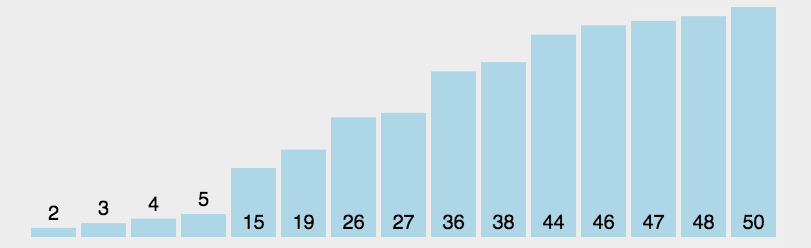
相当于每次排序我们都在待排序的范围内选出最大和最小的元素放在两端,然后待排序范围从两边慢慢往中间缩小,直到所有元素排序完成
代码:
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;//定义两个头尾下标while (begin < end){int max = begin, min = begin;//假设最大值和最小值为第一个元素for (int i = begin; i <= end; i++)//在排序范围内遍历比较{if (a[i] < a[min])//更新最小值min = i;if (a[i] > a[max])//更新最大值max = i;}//循环结束后即选出最大值和最小值//将最小值放到左端Swap(&a[begin], &a[min]);/*如果最大值的下标在左端,那么将最小值左端则会覆盖最大值而原来在左端的最大值交换之后就跑到最小值的下标去了,所以需要更新最大值的下标*/if (max == begin)max = min;//然后将最大值放到右端Swap(&a[end], &a[max]);//头下标++,尾下标--,即让待排序范围begin++;end--;}
}选择排序的特性总结
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2.时间复杂度:O(N^2)
由于选择排序无论什么情况下,遍历的比较次数都是一样的,即一开始遍历n次,找出一个最大和最小的元素之后,待排序范围减少2即为n-2,第二次遍历n-2次,相应地第三次遍历n-3,可以看到排序过程的总比较次数是一个等差数列,由等差数列求和公式可以得知时间复杂度为O(N^2)
3.空间复杂度:O(1)
由于选择排序只在原数组遍历和比较交换,没有开辟额外空间,也没有递归操作,故选择排序的的空间复杂度为O(1)
4.稳定性:不稳定
由于选择排序数据存在较大的跳跃交换,故选择排序不稳定
2.2堆排序
堆排序即利用堆的思想进行排序,总共分为两个步骤:
1.建堆
升序:建大堆
降序: 建小堆
2.利用堆删除思想来进行排序
建堆用到了向下调整,因此掌握了向下调整,就可以完成堆排序
向下调整算法:
以某一个父亲节点开始,让它与自己的孩子节点比较,当父节点小于最大的孩子节点时,(为什么要与最大的孩子节点交换,如果将较小的孩子换上去成为父节点,此父节点依然小于最大孩子节点)显然这不符合大堆的性质,于是需要将两个节点的值交换,最大孩子节点变为父节点,之前的父节点往下成为孩子节点,新的孩子节点作为父节点依然需要与下一个孩子节点比较,直到所有节点都符合大堆的性质,原来的父亲节点再调整的过程中不断往下走,故称为向下调整,如图所示
向下调整算法有一个前提:左右子树必须是一个堆,才能调整
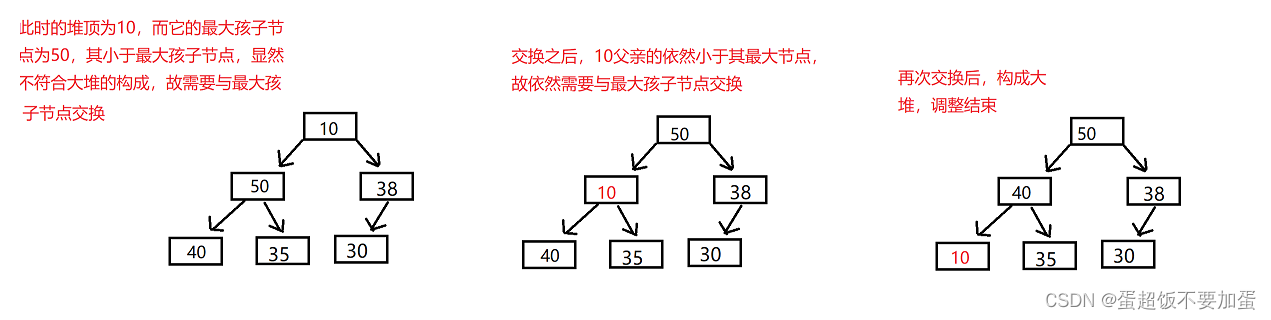
向下调整代码设计和过程:
函数的参数为一个数组以及数组的大小和父节点下标,首先通过父节点下标算出最大孩子节点的下标,接着进行两者的比较,如果父节点小于最大孩子节点则两者交换,并更新父节点,再算出新的最大孩子节点,以此循环直到符合大堆的性质或者父节点已经走到最后则调整结束
向下调整算法代码:
void AdjustDown(HPDataType* a, int n, int parent)
{assert(a);int child = parent * 2 + 1;//通过父节点算出最大孩子节点,假设最大孩子为左节点while (child<n){//如果右节点大于左节点,则将最大孩子设为右节点if (child+1<n&&a[child + 1] > a[child]){child++;}if (a[child] >a[parent])//父节点小于最大孩子节点则调整{Swap(&a[child], &a[parent]);//将父节点与最大孩子节点交换parent = child;//更新父节点child = parent * 2 + 1;//再算出新的最大孩子节点}else{break;//不需要调整则直接退出}}
}排序过程:建立大堆,大堆能够相对较大的元素在堆顶,首先让堆顶元素和最后一个元素交换,然后数组大小减1,再对堆顶元素应用向下调整(此时第二大的数就在堆顶了),第一轮就可以将最大的树放到数组最后面,依次进行,第二轮则可以将第二大的数放到数组的倒数第二个位置,直到数组的大小变为1即排序完成
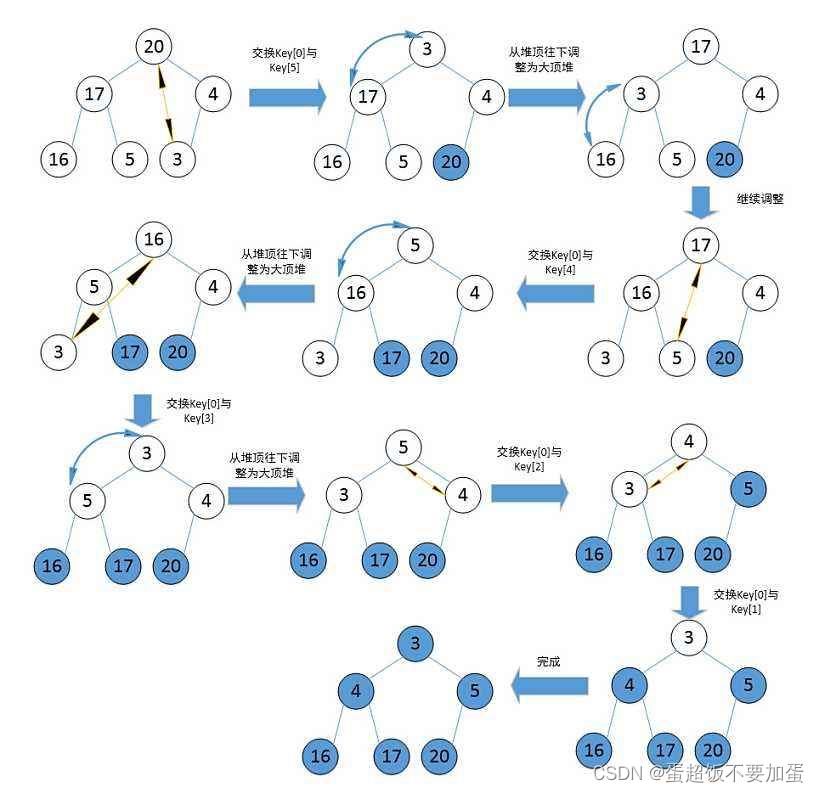
代码:
void HeapSort(int* a, int n)
{for (int i = n/2; i>=0; i--)//从倒数第一个非叶子结点开始建立大堆{AdjustDwon(a, n, i);}int end = n - 1;while (end>0){Swap(&a[0], &a[end]);//将堆顶元素与最后一个元素交换AdjustDwon(a, end, 0);//然后将堆顶元素进行向下调整end--;//数组范围减1}
}堆排序的特性总结
1.时间复杂度O(N*logN)
建堆的时间复杂度为O(N)(详见文章【数据结构】树和二叉树——堆),有n个元素,堆顶元素和最后一个元素交换的次数为n-1,每次交换之后需要进行向下调整,向下调整算法时间复杂度为O(logN),所以总的时间复杂度为O(N*logN)
2.空间复杂度:O(1)
由于堆排序只在原数组上进行建堆和比较交换,没有开辟额外空间,也没有递归操作,故选择排序的的空间复杂度为O(1)
3.稳定性:不稳定
由于堆排序过程中堆顶与最后一个元素,存在较大的数据跳跃交换,故堆排序不稳定
3.比较排序
3.1冒泡排序
冒泡排序可以说我们大学生的最爱了,因为我们学习编程语言时接触到的第一个排序一般就是冒泡排序,因为其简单易理解,所以知名度很高
冒泡排序基本思想:从一个元素开始进行相邻元素两两比较,即一个元素与第二个元素,然后第二个元素与第三个元素比较,依次类推直到倒数第二个元素与最后一个元素进行比较,在两两比较的过程中如果前面的元素大于后面的元素(即逆序)则将两个元素交换,进行一轮之后可以发现将最大的元素换到了最后,然后将排序的范围减1,再进行一轮则将第二大的元素换到最后(即整体的倒数第二个位置,因为排序的范围已经减1),这样每次都把相对较大的数换到最后面,类似与水中的起泡过程,所以叫做冒泡排序
n个元素每次将相对较大的数换到后面,需要换n-1趟,因为只剩一个数的时候已经有序,然后每一趟的比较次数是n-1-i,i为已经换到最后的数
第一趟的比较有n个元素,所以需要两两比较n-1次,第一趟后排好一个数,排序范围减1
第二趟的比较有n-1个元素,所以需要两两比较n--2次,第二趟后排好两个数,排序范围减1
...
下面是动图展示
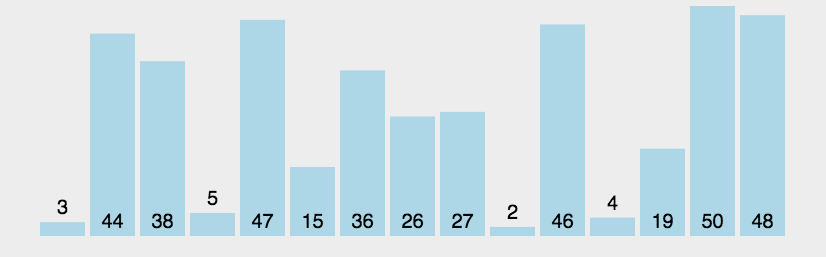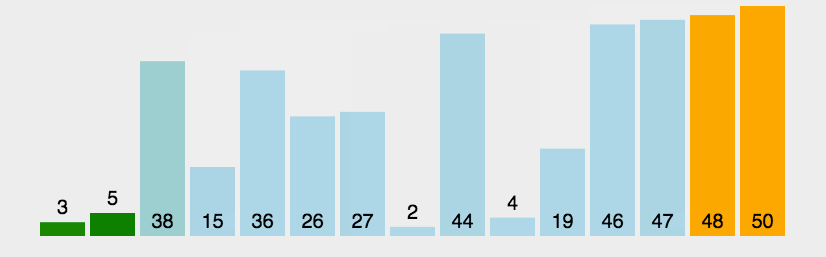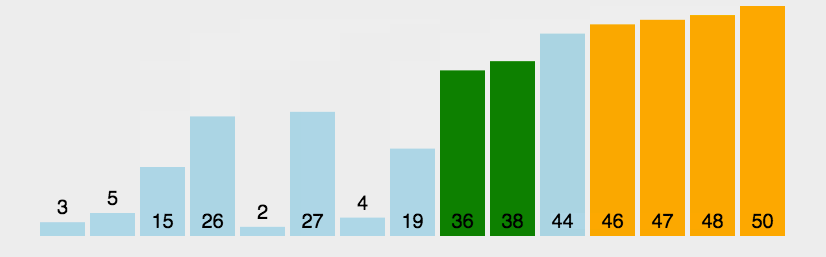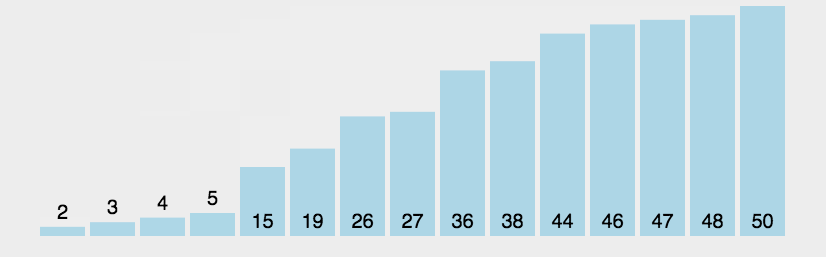
代码:
void BubbleSort(int* a, int n)
{for (int i = 0; i < n - 1; i++)//n个元素需要进行n-1趟比较{int flag = 0;//定义一个变量,用来判断是否发生交换for (int j = 0; j < n - 1 - i; j++)//每一趟的比较次数为n-1-i{if (a[j + 1] < a[j])//如果前面元素大于后面,则将两者交换{Swap(&a[j + 1], &a[j]);flag = 1;//判断变量置为1}}if (flag == 0)//如果一趟比较后flag依然为0,说明没有发生交换,则证明已经有序,退出排序break;}
}冒泡排序的特性总结:
1.时间复杂度:O(N^2)
最坏情况下即数组的元素为逆序,第一趟交换次数为n-1次,第二趟交换次数为n-2,以此类推我们可以发现每一趟比较次数构成等差数列,由等差数列求和公式可以求得时间复杂度为O(N^2)
2.空间复杂度:O(1)
由于冒泡排序只在原数组进行比较和交换,没有开辟额外空间,也没有递归过程,故冒泡排序空间复杂度为O(1)
3.稳定性:稳定
冒泡排序每一趟只进行两两比较,而且只在前面元素大于后面元素的情况下发生交换,没有发生元素跳跃交换,故冒泡排序是稳定排序
3.2快速排序
递归版本
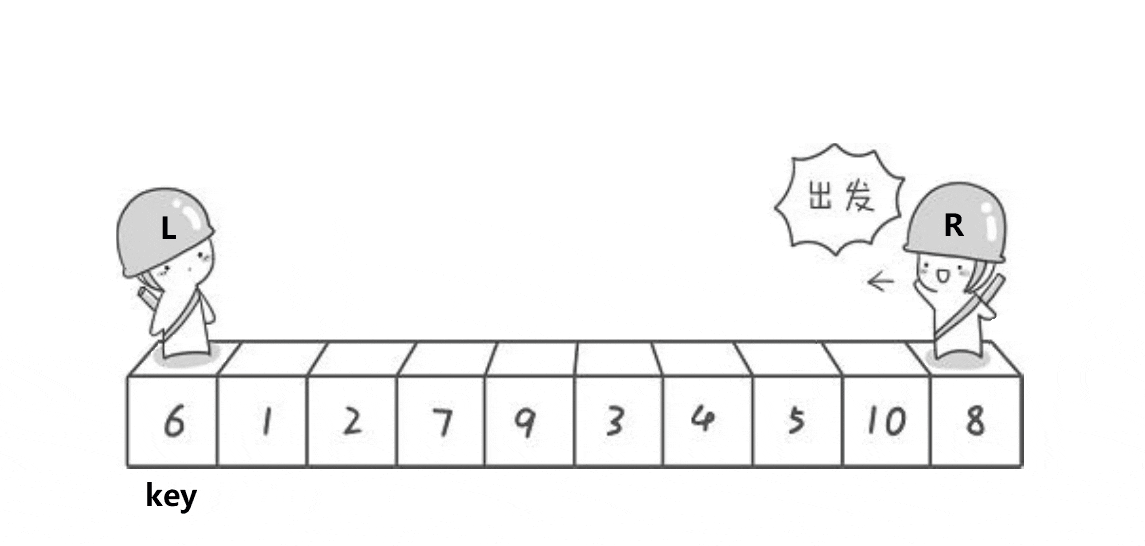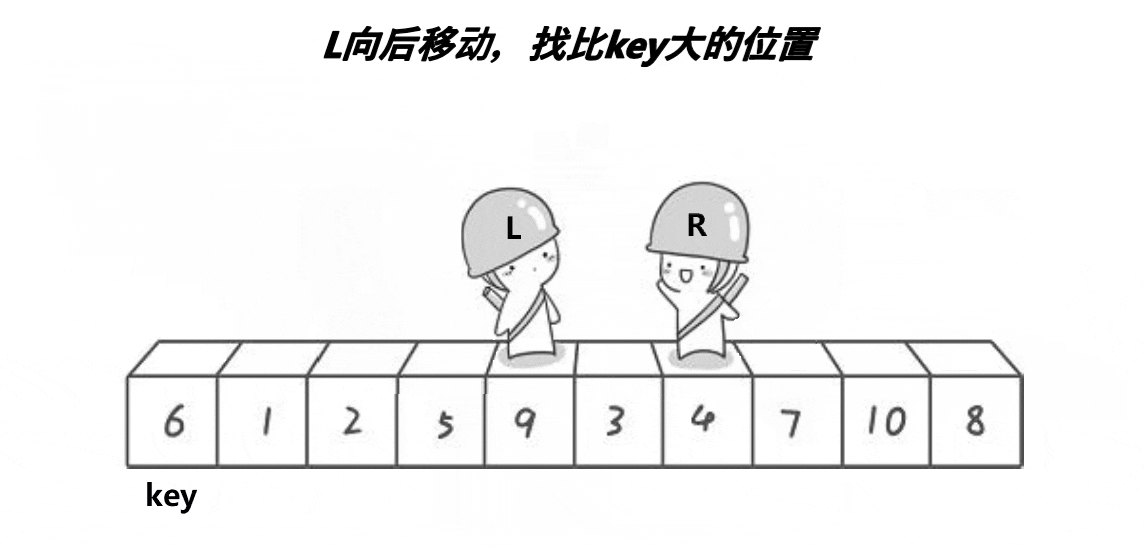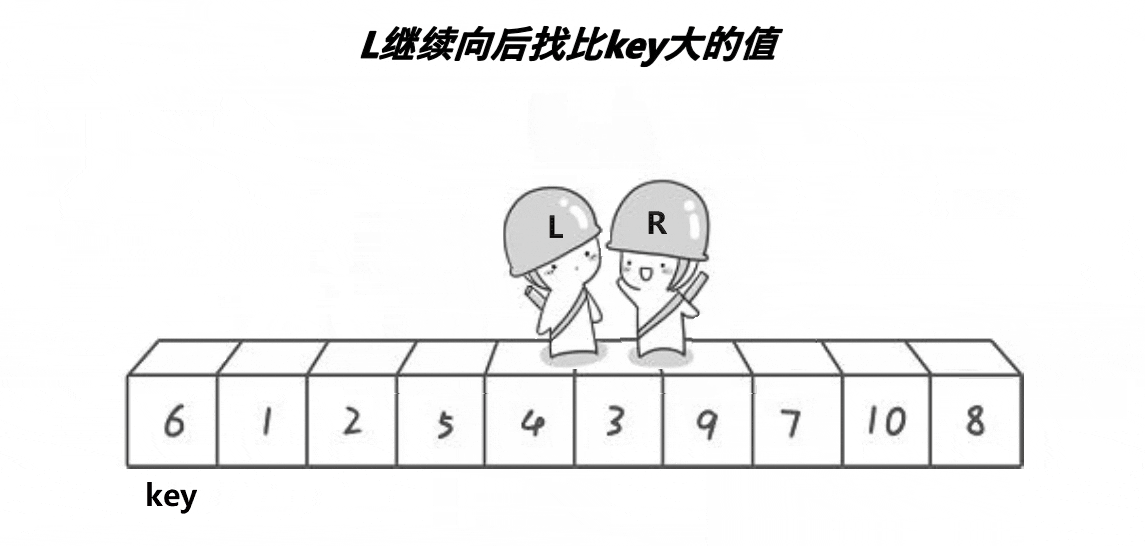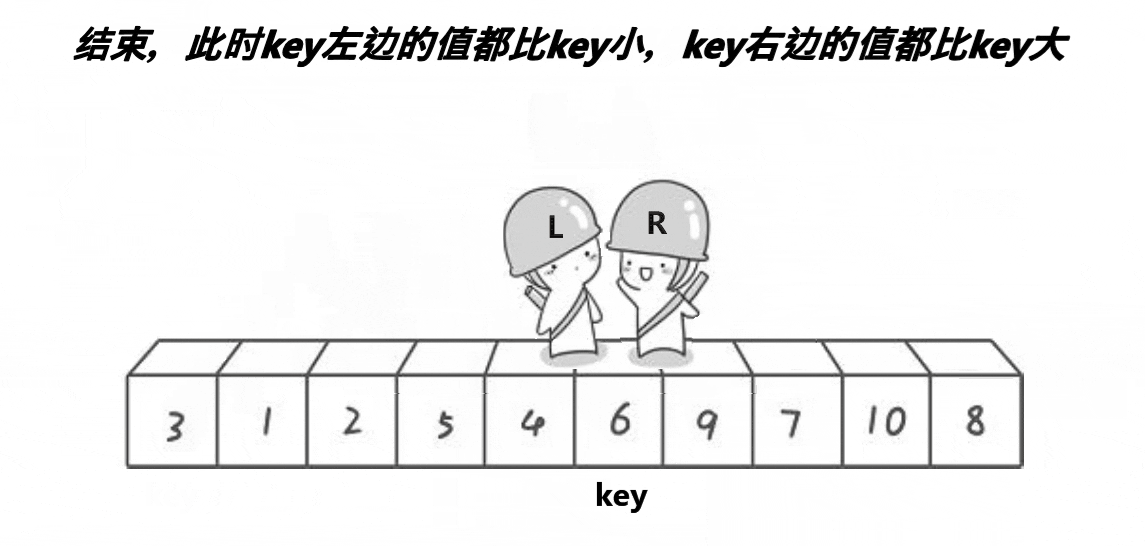
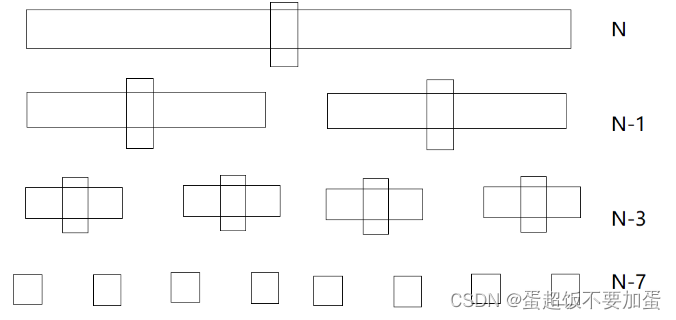
分割完区间之后类似于下面的示意图,可以发现该过程与二叉树的前序遍历相似,所以整体逻辑可以按照前序遍历的思想进行,关键在于单趟排序的设计
单趟代码:
int PartSort1(int* a, int left, int right)
{int mid = GetMidIndex(a, left, right);//三数取中选取基准值Swap(&a[left], &a[mid]);//将选取的基准值放到最左边int begin = left, end = right;//定义左右指针int keyi = left;//基准值下标while (begin < end){while (begin < end && a[end] >= a[keyi])//右指针找到小于基准值的元素才停下end--;while (begin < end && a[begin] <= a[keyi])//右指针停下后让左指针找大再停下begin++;Swap(&a[begin], &a[end]);//交换两个指针对应的值}Swap(&a[keyi], &a[begin]);//两个指针相遇则循环结束,让基准值和两个指针指向的值交换keyi = begin;//基准值的下标变为指针相遇的地方return keyi;//返回基准值的下标
}每一趟排序都将基准值交换到了它该位于的位置,因为排序后左边区间都是小于等于它的值,右边区间都是大于等于它的值
下面我们讨论为什么为什么两个指针相遇地方的值一定小于基准值
指针相遇有两种情况
1.右指针停下,左指针与它相遇,右指针遇到小才停下,所以左指针与它相遇对应的值比基准值小
2.左指针停下,右指针与它相遇,左指针遇到大停下,而后与右指针的值交换,由于右指针的值是小于基准值的,所以交换后左指针指向的值就是小于基准值的值,所以右指针与它相遇对应的值比基准值小
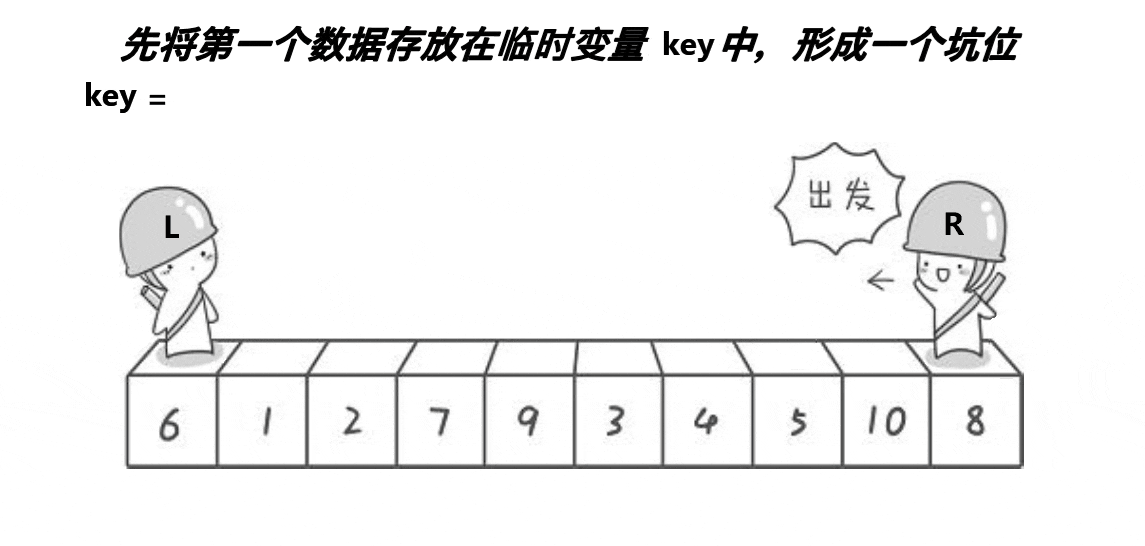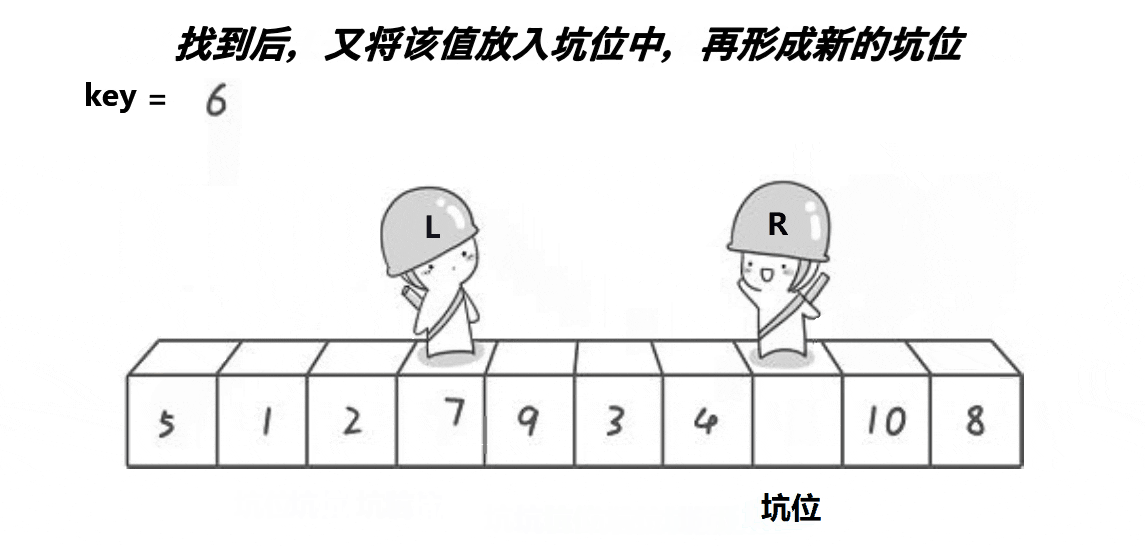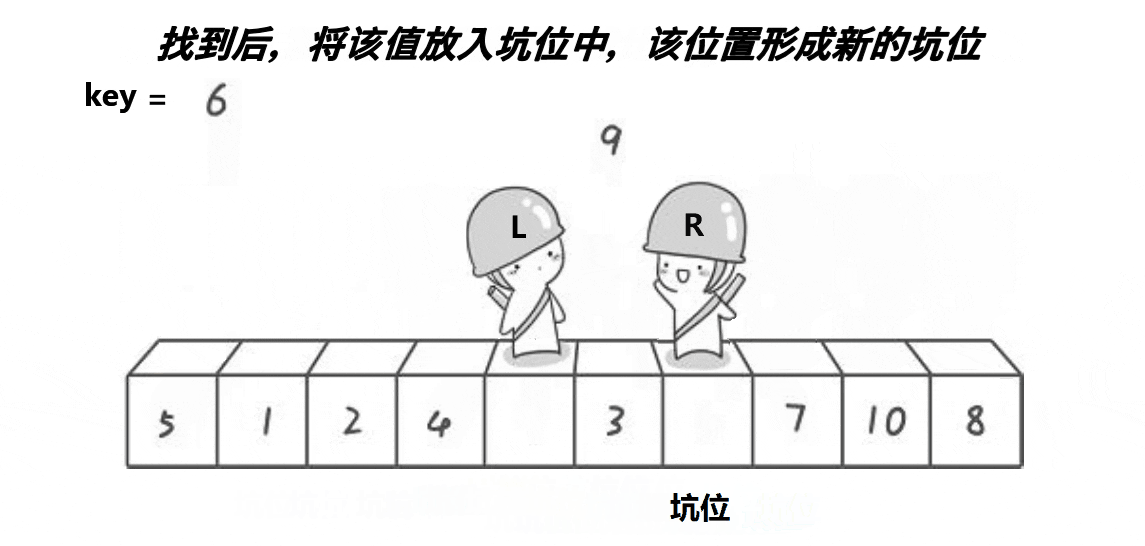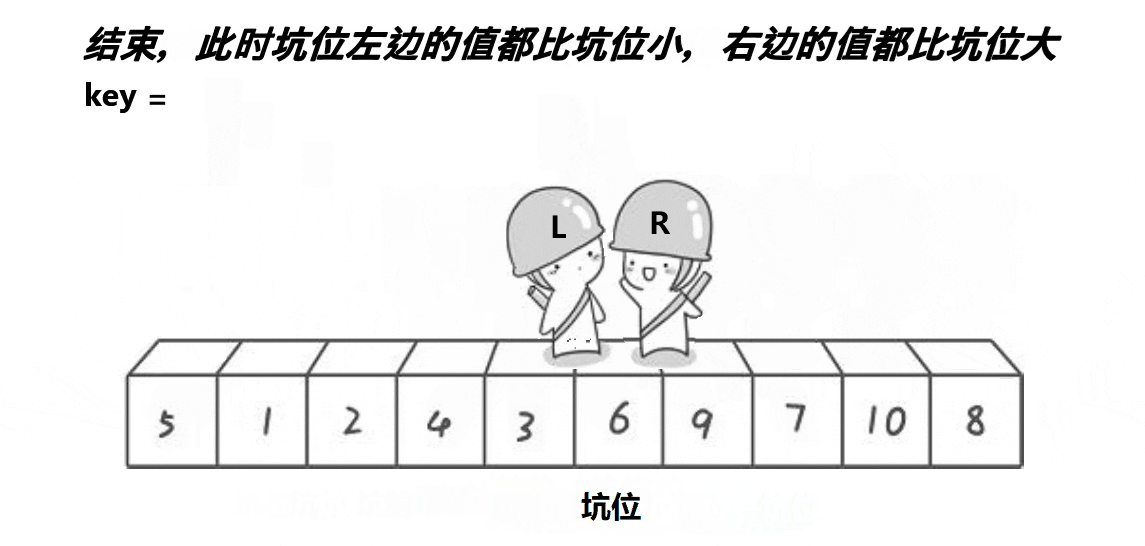
2.挖坑法版本
基本思想:定义两个左右指针,再定义一个坑位(下标),开始默认坑位是第一个位置,选择一开始坑位所在的值为基准值,同样也是右指针先走,不同的是,右指针找到小之后将值放到坑位,然后坑位更新为右指针指向的位置,然后让左指针找大,找到大之后将值放到坑位,然后坑位更新为左指针指向的位置,直到两个指针相遇,然后将基准住放到两个指针相遇的地方,继续以指针相遇的地方分割左区间和右区间进行递归
下面是动图展示
单趟排序代码:
int PartSort2(int* a, int left, int right)
{int mid = GetMidIndex(a, left, right);//三数取中选取基准值Swap(&a[left], &a[mid]);//将基准值放到第一个元素int begin = left, end = right;//定义前后指针int key = a[begin];//保存基准值int hole = begin;//一开始坑位默认为第一个位置while (begin < end){while (begin < end && a[end] >= key)//右指针找小才停下right--;a[hole] = a[right];//把找到的小的值放到坑位hole = right;//坑位更新为右指针指向的位置while (begin < end && a[begin] <=key)//然后让左指针找大begin++;a[hole] = a[begin];//将找到的大的值放到坑位hole = begin;//坑位更新为左指针指向的位置}a[hole] = key;//两个指针相遇后,将保存的基准值放到两个指针相遇的地方,即最后的坑位return hole;//返回坑位以进行分割区间进行递归
}下面我们讨论为什么两个指针会相遇在坑位上
指针相遇有两种情况
1.右指针停下,左指针与它相遇,右指针找到小才停下,然后把小的值放到坑位后,坑位更新为右指针指向的地方,所以右指针停下之后会成为坑位,所以左指针与它相遇会相遇在坑位
2.左指针停下,右指针与它相遇,左指针找到大才停下,然后把大的值放到坑位后,坑位更新为左指针指向的地方,所以左指针停下之后会成为坑位,所以右指针与它相遇会相遇在坑位
3.前后指针版本
基本思想:定义一个前指针pre指向第二个位置,定义一个后指针cur指向第二个位置,选取基准值,然后让cur指针先走,当cur指针找到小之后,让pre指针向前一步,然后再交换两个指针指向的值,以此类推,直到cur指针走过最后一个位置,最后让基准值与pre指针指向的值进行交换,然后将基准值的下标更新为pre的位置,以便返回新的基准值的下标进行分割区间递归
下面是动图展示
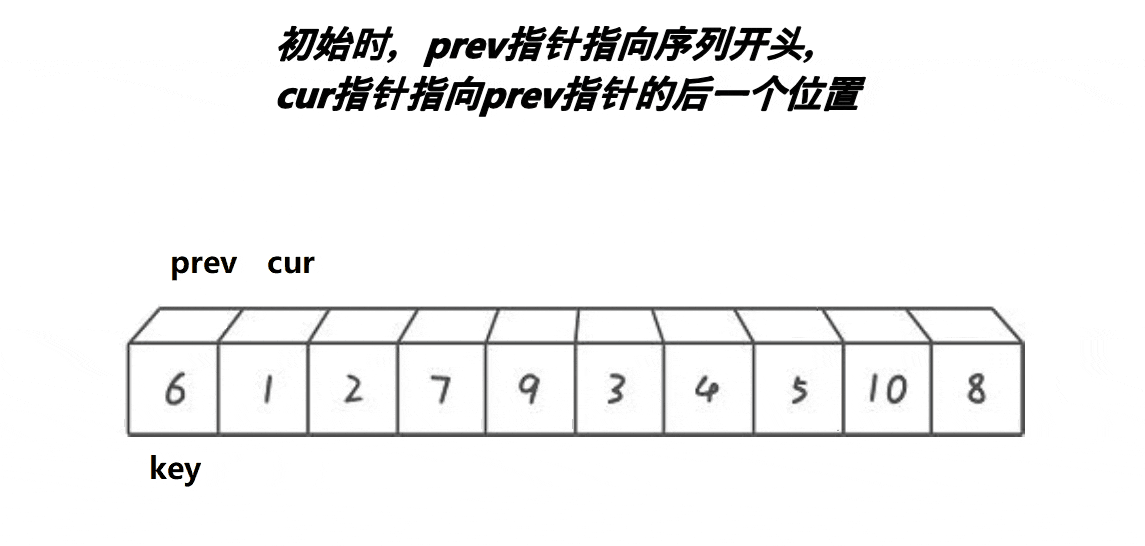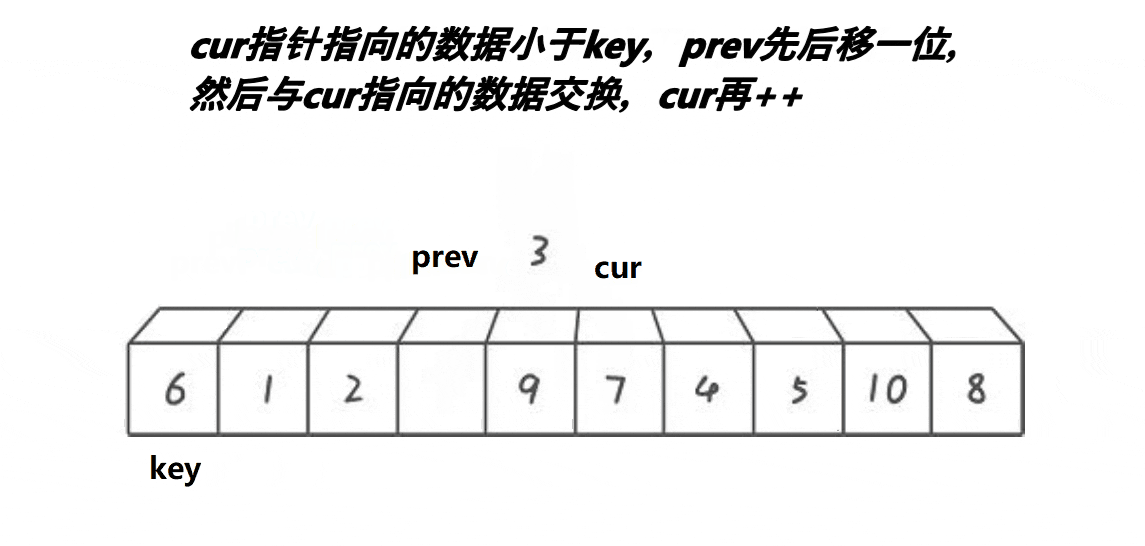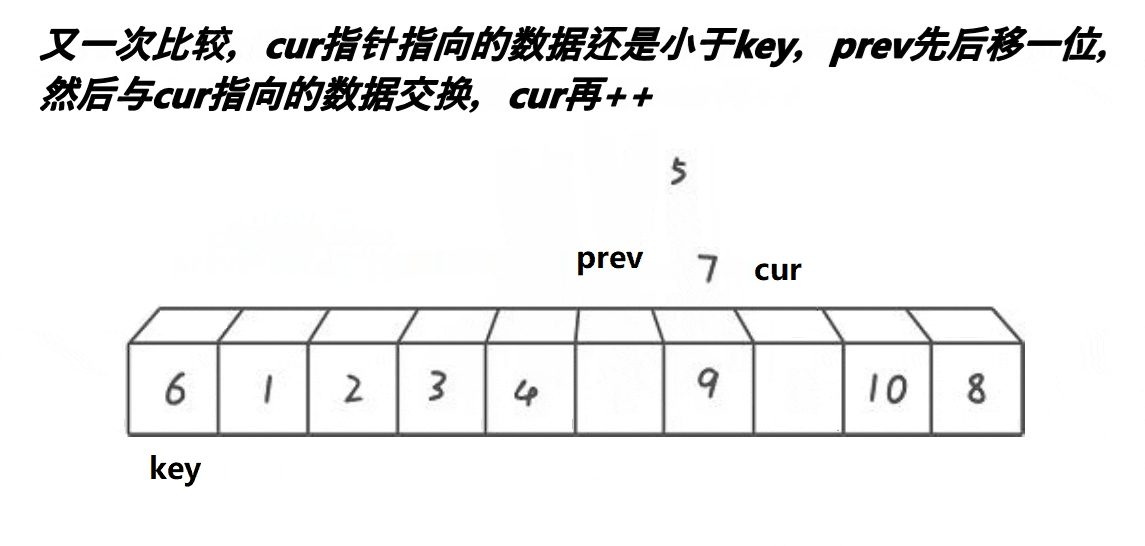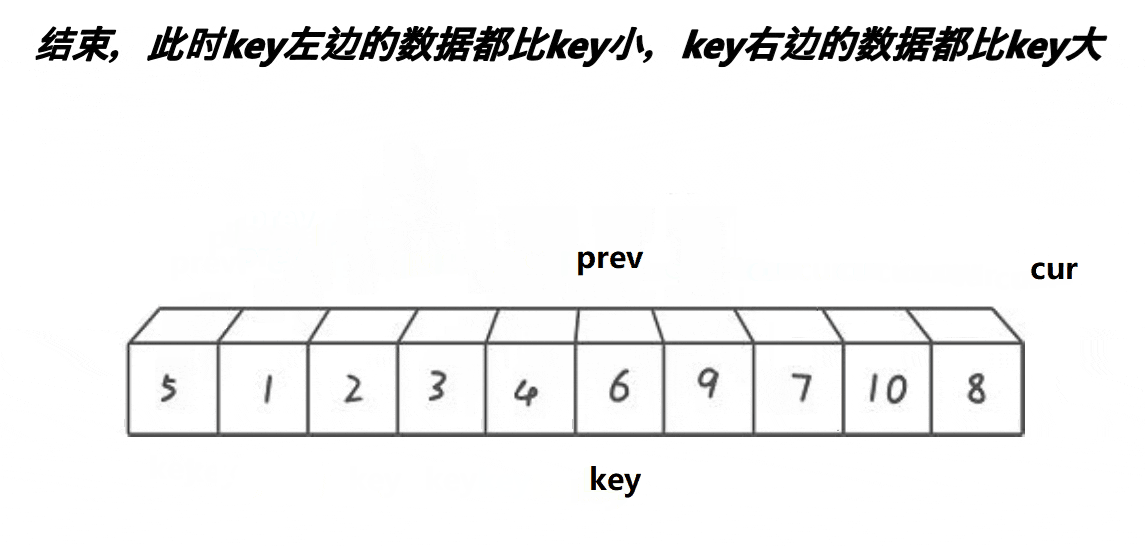
单趟代码:
int PartSort3(int* a, int left, int right)
{int mid = GetMidIndex(a, left, right);//三数取中选取基准值Swap(&a[left], &a[mid]);//将基准值放到第一个位置int keyi = left;//由于left下标整个过程不变,所以保存基准值的下标int pre = left;//定义前指针指向第一个元素int cur = left + 1;//定义后指针指向第二个元素while (cur <= right){if (a[cur] < a[keyi] && ++pre != cur)//后指针找到小,且pre指针向前一步的值不与后指针的值相等就交换Swap(&a[cur], &a[pre]);cur++;//后指针向后走}Swap(&a[keyi], &a[pre]);//循环结束后,将基准值放到pre的位置keyi = pre;//基准值下标更新为pre的位置return keyi;//返回新的基准值以分割区间进行递归
}上面我们对快速排序递归单趟的三种版本进行了学习,下面我们进行一些优化
快速排序递归优化
1.三数取中
当原来的元素已经是有序或者接近时,我们每次选取最左边的元素作为基准值,则会导致选取的基准值每次都是最大或者最小的,一趟排序后,就会变成基准值的左边都是小于等于的值而右边没有值(基准值为最大的值),或者基准值的左边没有值而右边都是大于等于的值(基准值为最小的值),这样我们进行递归分割区间时,每次区间只缩小了1,所以第一趟排序遍历比较的次数为n-1,第二个排序遍历比较的次数为n-2,以此类推可以发现每一趟的比较次数是一个等差数列,n-1+n-2+n-3+..3+2+1,由等差数列的求和公式可以求得此时的时间复杂度为O(N^2)

显然,当原来的元素已经有序或者将接近有序时,就成为了快速排序的最坏情况,再利用原来的每次只选取最左边的元素作为基准值已经行不通,于是有人提出了一种优化方法——三数取中法
三数取中:
选取三个元素:最左边的元素,中间位置的元素,最右边的元素,然后两两进行比较,选出中间大小的那个数,然后把这个数放到最左边作为基准值
代码:
int GetMidIndex(int *a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] > a[end]){if (a[end] > a[mid])return end;else if (a[begin] > a[mid])return mid;elsereturn begin;}else{if (a[begin] > a[mid])return end;else if (a[begin] > a[mid])return mid;elsereturn begin;}
}2.小区间优化
我们前面已经介绍过,快速排序的递归过程类似于二叉树的前序遍历,而我们知道二叉树最后几层的元素个数是占据绝大部分的,当递归到区间很小时,比如递归区间只有10个数,显然递归到只剩10个数时已经递归到最后几层,对于10个数排序调用递归而且递归那么多次,显然是杀鸡用了牛刀,费时费空间而且效率也低,于是有人提出了一种优化——小区间优化
小区间优化,即当递归区间已经很小的时候,可以选用直接插入排序对递归区间进行排序,这样就减少了递归过程中绝大数的递归次数,提高了快速排序的效率
快速排序递归总过程
先判断区间是否只有一个值或者不存在,如果是,一个值可以认为其已经有序,则直接返回,如果不是,则执行排序过程,先进行小区间优化,非小区间则进行三数取中法选取基准值,然后进行上面三个版本的任一单趟过程,单趟排序后被分割成两个区间,然后对这两个区间分别进行递归排序
总代码:
void QuickSort(int* a, int left, int right)
{if (left >= right)//left等于right则说明该区间只有一个值,大于则说明区间不存在return;if(left-right + 1 < 10)//小区间优化,如果区间范围小于10则进行直接插入排序{InsertSort(a + left, right-left+1);}else{int keyi = PartSort3(a,left,right);//单趟排序后返回更新后的基准值下标//以单趟排序后的更新后基准值下标k为分割,分割成[left,keyi-1] keyi [keyi+1,right]QuickSort(a, left, keyi - 1);//递归左区间QuickSort(a, keyi+1, right);//递归右区间}
}快速排序非递归
基本思想:利用栈模拟递归过程,先让整体区间入栈,先入栈区间左下标,再入栈区间右下标,然后再将区间下标出栈调用单趟排序,单趟排序后分割成两个区间,由于栈是先进后出的区间,低估过程是先递归左边,所以单趟排序后先入栈右区间,再入栈左区间,然后接着出栈一个区间进行单趟排序,排序后再入栈分割后的右区间和左区间,直到栈为空则排序完成
代码:
void QuickSortNonR(int* a, int left, int right)
{Stack st;//定义栈StackInit(&st);//栈的初始化StackPush(&st, left);//入栈区间左下标StackPush(&st, right);//再入栈区间右下标while (!StackEmpty(&st))//栈为空则结束{//取出一个区间进行单趟排序int right = StackTop(&st);StackPop(&st);int left = StackTop(&st);StackPop(&st);int keyi = PartSort3(a, left, right);//调用单趟排序,然后分割两个区间if (keyi + 1 < right)//如果右区间存在则先入栈右区间{StackPush(&st, keyi + 1);StackPush(&st,right);}if (left < keyi-1)//如果左区间存在则入栈左区间{StackPush(&st, left);StackPush(&st, keyi-1);}}StackDestroy(&st);//销毁栈
}快速排序的特性总结:
4.归并排序
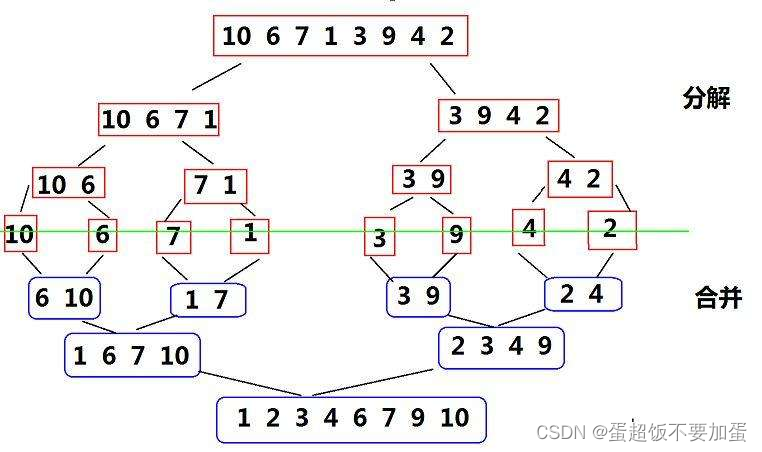
可以看出归并排序递归过程可以看成是二叉树的后续遍历,即让左右区间先排序,等左右区间都有序了再将左右区间合并一起排序。
归并排序是每次将区间二分进行递归,直到递归到只有一个元素过着区间不存在,只有一个元素可以认为其已经有序,所以回溯至上一层,然后上一层将左右区间合并排序再回溯至上一层,直到回溯到顶层将整体的左右区间进行合并,两个区间的合并过程类似于合并两个有序数组的过程,详情见代码
实际上是空间换时间的思想,归并排序一开始就开辟了待排序元素的等额空间,每趟合并在额外空间排序,然后将合并后的元素又拷贝至原数组
下面是动图展示
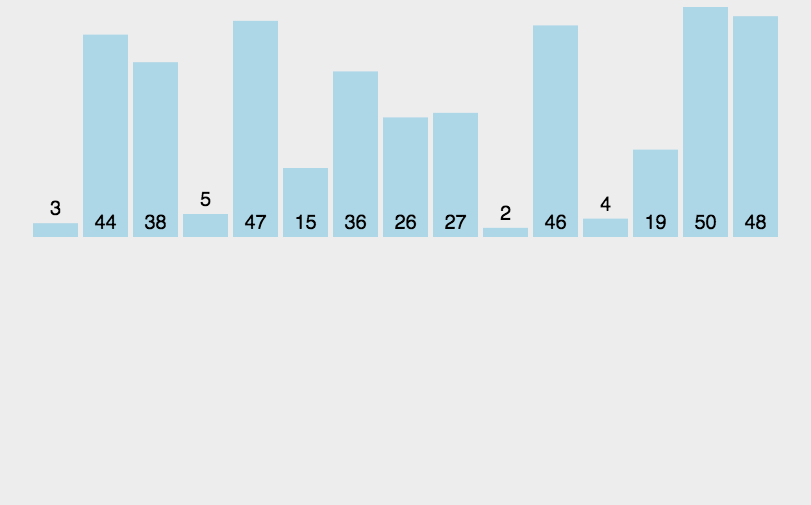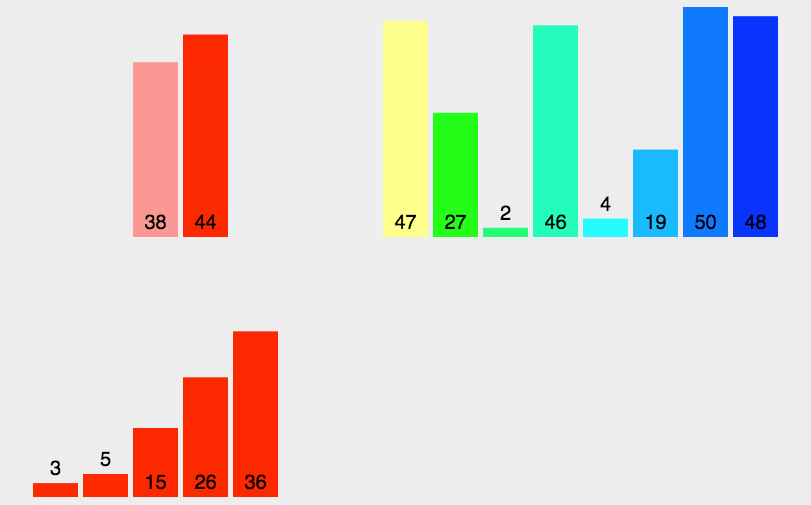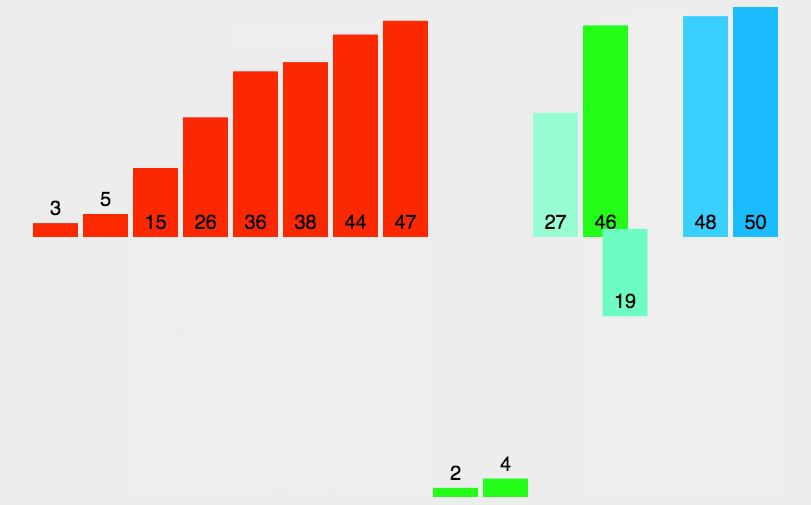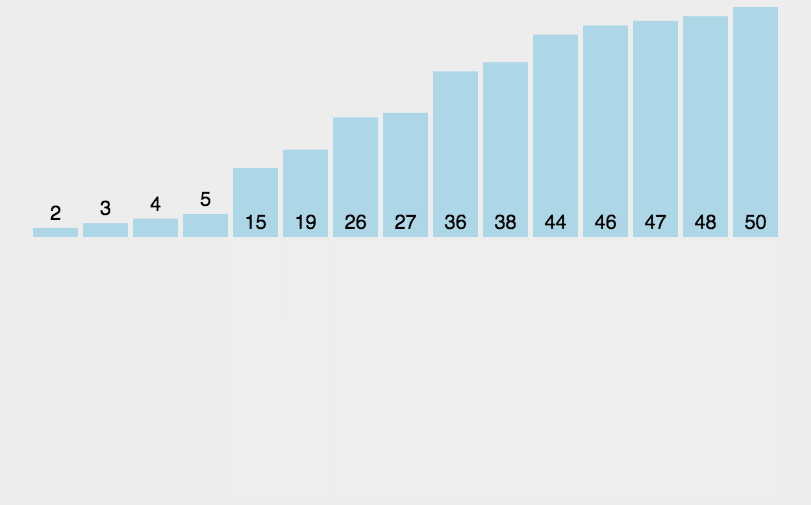
代码:
void _MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end)//只有一个元素或者区间不存在则已经有序,直接返回return;int mid = (begin + end) / 2;//二分区间_MergeSort(a, begin, mid,tmp);//递归左区间_MergeSort(a,mid+1, end,tmp);//递归右区间//左右区间有序后进行合并int begin1 = begin, end1 = mid;//定义左区间指针(下标)int begin2 = mid + 1, end2 = end;//定义右区间指针(下标)int j = begin;//从区间起始位置开始存元素while (begin1 <= end1 && begin2 <= end2)//有一个区间元素放完了就结束{if (a[begin1] <= a[begin2])//如果左区间指针指向的元素比右区间指针指向的元素小,则将小的元素放到tmp数组内tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];//反之}//有一个区间的元素元素放完了,但是不知道具体哪个区间还没有放完,所以两个区间都将剩下的元素放进tmp数组while(begin1<=end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//单趟合并后将元素拷贝至原数组memcpy(a + begin, tmp + begin, sizeof(int)*(end2 - begin + 1));
}
void MergeSort(int* a, int n)
{int* tmp = malloc(sizeof(int) * n);//开辟额外的等额数组空间if (tmp == NULL)//检查是否开辟成功{perror("malloc fail");exit(-1);}_MergeSort(a, 0, n - 1, tmp);//调用归并排序free(tmp);//释放额外空间tmp = NULL;
}归并排序非递归版本
基本思想:先让每个区间只有一个元素,只有一个元素认为有序即每个区间都是有序的,则每两个区间两两归并,然后让每个区间只有两个元素,然后让每两个区间进行两两归并,每次让区间的元素个数扩大两倍,直到每个区间的元素数设定超过元素总数即结束
非递归过程过程中存在的问题:由于区间的元素个数是成倍增长的,而待排序元素个数不一定是区间元素个数的倍数,这必然会导致在取区间的时候存在越界问题
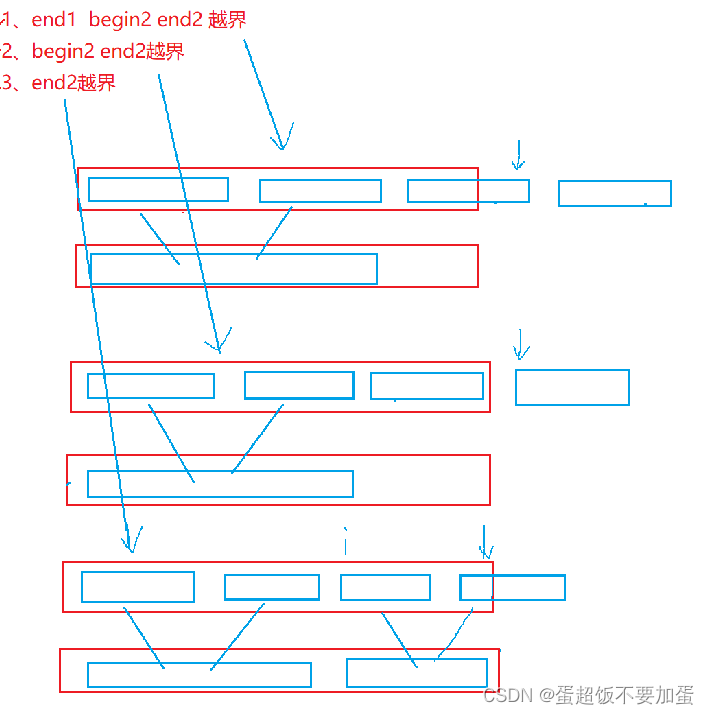
解决方法:
1.end1越界
en1越界,则begin2和end2也越界,由于只有最区间一部分元素合法,右区间都不合法,即没有两个可以合并的区间,则直接break,跳出此次循环
2.begin2越界
begin2越界,则end2必越界,也是和第一点一样,整个右区间都不合法,即没有两个可以合并的区间,则直接break,跳出此次循环
3.只有end2越界
只有end2越界说明右区间也是有一部分合法的元素,我们只需将end2修正为n-1即可,然后将两个区间合并
代码:
void MergeSortNonR(int* a, int n)
{int* tmp = (int *)malloc(sizeof(int)*n);//开辟额外的等额空间int gap = 1;//定义每个区间的元素个数,一开始为1while (gap < n){for (int i = 0; i < n; i +=2*gap){int begin1 = i, end1 = i + gap - 1;//划分左区间int begin2 = i + gap, end2 = i + 2 * gap - 1;//划分右区间int j = i;//解决区间越界问题if (end1 >= n)break;else if (begin2 >= n)break;else if (end2 >= n){end2 = n - 1;}//合并两个区间while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//合并之后将元素拷贝至原数组memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;//让区间的元素个数翻倍}free(tmp);//排序完后释放额外空间tmp == NULL;
}归并排序的特性总结:
1.归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题
2.时间复杂度:O(NlogN)
由归并排序的递归过程可以发现,其类似于二叉树的后序遍历过程,总共由logN层,每一层都要遍历N个元素,所以时间复杂度为O(N*logN)
3.空间复杂度:O(N)
归并排序主要应用了空间换时间的思想,开辟了等额的空间,故空间复杂度为O(N)
4.稳定性:稳定
由于归并排序是分区间排序然后再合并,且在小区间比较过程没有发生大的跳跃交换过程中,故归并排序是稳定排序
5.计数排序
基本思想:遍历找出待排序元素的最大值和最小值,并求出它们的差值,然后开辟差值数量大小的空间并全都初始化为0,遍历原数组,将每一数组元素减去最小值(相对映射),然后得到一个下标,将次下标对应的额外空间的值加1,然后遍历完原数组后再将额外空间的每个下标的值的次数将元素放回原数组
总步骤:
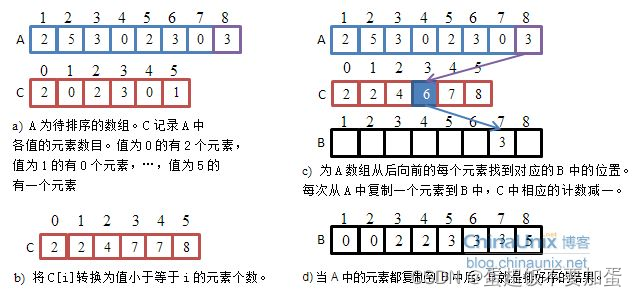
代码:
void CountSort(int* a, int n)
{int min = a[0], max = a[0];//假设最小值和最大值for (int i = 0; i < n; i++)//遍历原数组找出最小值和最大值{if (a[i] < min)min = a[i];if (a[i] > max)max = a[i];}int range = max - min + 1;//求出最大值和最下值的差值int* tmp = (int *)calloc(range,sizeof(int));//开辟差值数量大小的空间并都初始化为0if (tmp == NULL)//检查是否开辟成功{perror("calloc fail");exit(-1);}for (int i = 0; i < n; i++)//遍历原数组,将每个元素减去最小值得到一个下标,将额外空间的次下标的值加1{tmp[(a[i] - min)]++;}int j = 0;for ( int i = 0; i < range; i++)//遍历完之后按照额外空间的值的大小将元素放回原数组{while (tmp[i]--){a[j++] = i + min;}}free(tmp);//排序完释放额外空间tmp = NULL;
}计数排序的特性总结:
🍑三.排序总结🍑
好啦,关于八大排序的学习我们就先学到这里,如果对您有所帮助,欢迎一键三连~
相关文章:
详解八大排序算法-附动图和源码(插入,希尔,选择,堆排序,冒泡,快速,归并,计数)
目录 🍏一.排序的概念及应用🍏 1.排序的概念 2.排序的应用 3.常用的排序算法 🍎二.排序算法的实现🍎 1.插入排序 1.1直接插入排序 1.2希尔排序(缩小增量排序) 2.选择排序 2.1直接选择排序 2.2堆排序…...

网络编程--协议、协议族、地址族
写在前面 这里先介绍下socket函数(Windows版本)的函数声明,后续内容均围绕该声明展开: #include <winsock2.h> //af: 指定该套接字的协议族 //type: 指定该套接字的数据传输方式 //protocol: 指定该套接字的最终协议 //返…...
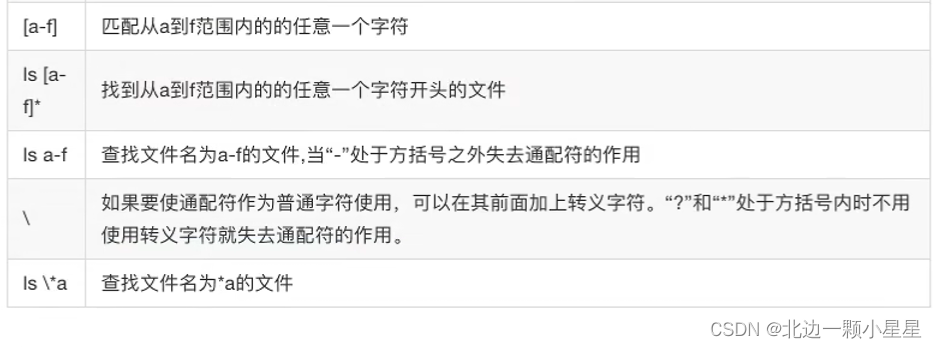
Linux入门操作
pwd 查看当前目录 与 自动补全 文件详情 drwxrwxr-x d代表文件夹 -代表文件 其中rwx rwx r-x r是可读 w是可写 x 执行 第一组(前三个)指文件拥有者的权限 第二组(中三个)代表文件拥有的组的权限 第三组(后三个&am…...
1。C语言基础知识回顾
学习嵌入式的C基础知识,主要包括几个核心知识点:三大语法结构、常用的数据类型、函数、结构体、指针、文件操作。 一、顺序结构 程序自上而下依次执行、没有分支、代码简单。 常见顺序结构有:四则运算:,-࿰…...

学习如何通过构建一个简单的JavaScript颜色游戏来操作DOM
学习如何通过构建一个简单的JavaScript颜色游戏来操作DOM 题目要求 我们将构建一个简单的颜色猜谜游戏。每次游戏启动时,都会选择一个随机的RGB颜色代码。根据游戏模式,我们将在屏幕上提供三个(简单)或六个(困难&…...

【算法学习】—n皇后问题(回溯法)
【算法学习】—n皇后问题(回溯法) 1. 什么是回溯法? 相信"迷宫"是许多人儿时的回忆,大家小时候一定都玩过迷宫游戏。我们从不用别人教,都知道走迷宫的策略是: 当遇到一个岔路口,会有以下两种情况…...

万亿OTA市场进入新爆发期,2025或迎中国汽车软件付费元年
伴随智能汽车市场规模发展,越来越多的汽车产品具备OTA能力,功能的优化、以及服务的差异化,成为了车企竞争的新战场。 例如,今年初,问界M5 EV迎来了首次OTA升级,升级内容覆盖用户在实际用车中的多个场景&am…...
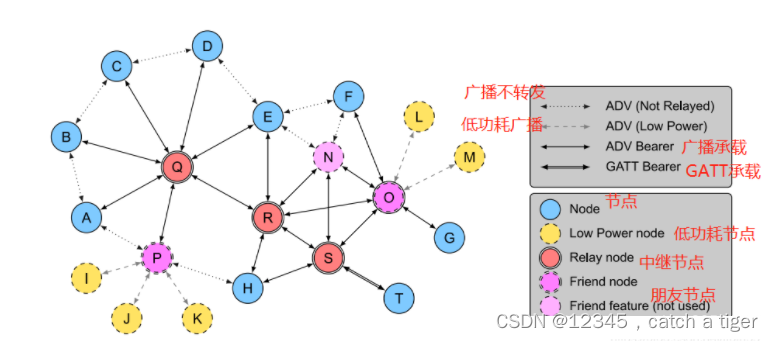
Android硬件通信之 蓝牙Mesh通信
一,简介 蓝牙4.0以下称为传统蓝牙,4.0以上是低功耗蓝牙,5.0开始主打物联网 5.0协议蓝牙最重要的技术就是Mesh组网,实现1对多,多对多的无线通信。即从点对点传输发展为网络拓扑结构,主要领域如灯光控制等&…...

PG数据库实现bool自动转smallint的方式
删除函数: 语法: DROP FUNCTION IF EXISTS your_schema_name.function_name(arg_type1, arg_type2) CASCADE RESTRICT; 实例: DROP FUNCTION IF EXISTS platformyw.boolean_to_smallint(bool) CASCADE RESTRICT; 查询是否存在函数 语法: SELE…...
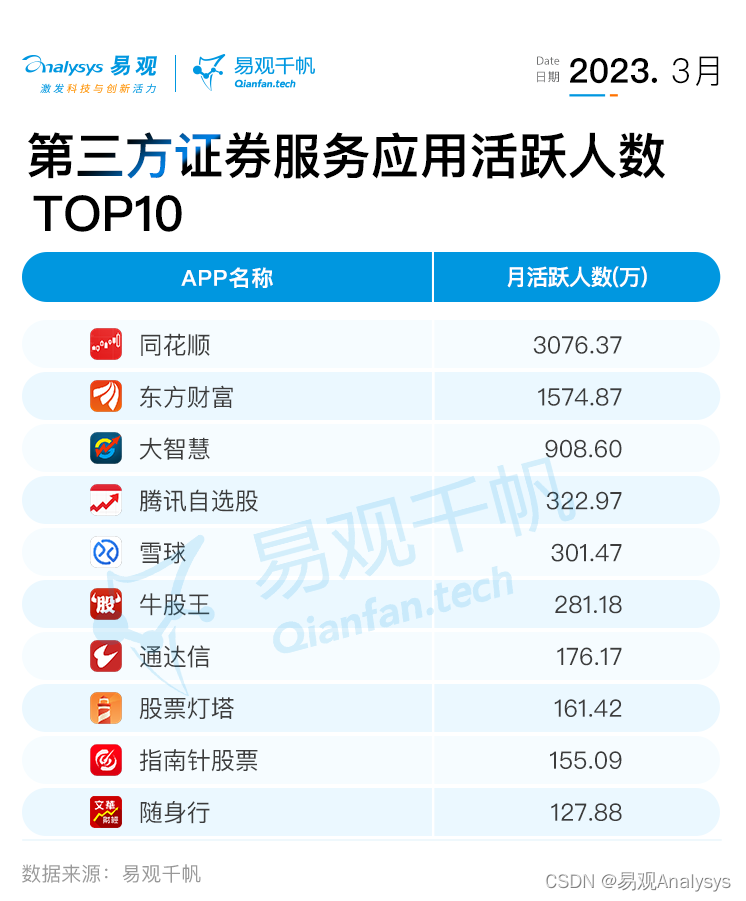
易观千帆 | 2023年3月证券APP月活跃用户规模盘点
易观:2023年3月证券服务应用活跃人数14131.58万人,相较上月,环比增长0.61%,同比增长0.60%;2023年3月自营类证券服务应用Top10 活跃人数6221.44万人,环比增长0.08%;2023年3月第三方证券服务应用T…...
2023年江苏专转本成绩查询步骤
2023年江苏专转本成绩查询时间 2023年江苏专转本成绩查询时间预计在5月初,参加考试的考生,可以关注考试院发布的消息。江苏专转本考生可在规定时间内在省教育考试院网,在查询中心页面中输入准考证号和身份证号进行查询,或者拨…...
函数)
JavaScript中sort()函数
sort()函数是javascript中自带函数,这个函数的功能是排序。 使用sort()函数时,函数参数如果不设置的话,以默认方式进行排序,就是以字母顺序进行排序,准确的讲就是按照字符编码的顺序进行排序。 var arr [3,2,3,34,1…...

泰克Tektronix DPO5204B混合信号示波器
特征 带宽:2 GHz输入通道:4采样率:1 或 2 个通道上为 5 GS/s、10 GS/s记录长度:所有 4 个通道 25M,50M:1 或 2 个通道上升时间:175 皮秒MultiView zoom™ 记录长度高达 250 兆点>250,000 wf…...
突破传统监测模式:业务状态监控HM的新思路
作者:京东保险 管顺利 一、传统监控系统的盲区,如何打造业务状态监控。 在系统架构设计中非常重要的一环是要做数据监控和数据最终一致性,关于一致性的补偿,已经由算法部的大佬总结过就不在赘述。这里主要讲如何去补偿ÿ…...

0Ω电阻在PCB板中的5大常见作用
在PCB板中,时常见到一些阻值为0Ω的电阻。我们都知道,在电路中,电阻的作用是阻碍电流,而0Ω电阻显然失去了这个作用。那它存在于PCB板中的原因是什么呢?今天我们一探究竟。 1、充当跳线 在电路中,0Ω电阻…...

分布式消息队列Kafka(三)- 服务节点Broker
1.Kafka Broker 工作流程 (1)zookeeper中存储的kafka信息 1)启动 Zookeeper 客户端。 [zrclasshadoop102 zookeeper-3.5.7]$ bin/zkCli.sh 2)通过 ls 命令可以查看 kafka 相关信息。 [zk: localhost:2181(CONNECTED) 2]…...

蠕动泵说明书_RDB
RDB_2T-S蠕 动 泵 概述 蠕动灌装泵是一种高性能、高质量的泵。采用先进的微处理技术及通讯方式做成的控制器和步进电机驱动器,配以诚合最新研制出的泵头,使产品在稳定性、先进性和性价比上达到一个新的高度。适用饮料、保健品、制药、精细化工等诸流量…...

浅谈react如何自定义hooks
react 自定义 hooks 简介 一句话:使用自定义hooks可以将某些组件逻辑提取到可重用的函数中。 自定义hooks是一个从use开始的调用其他hooks的Javascript函数。 下面以一个案例: 新闻发布操作,来简单说一下react 自定义 hooks。 不使用自定义hooks时 …...
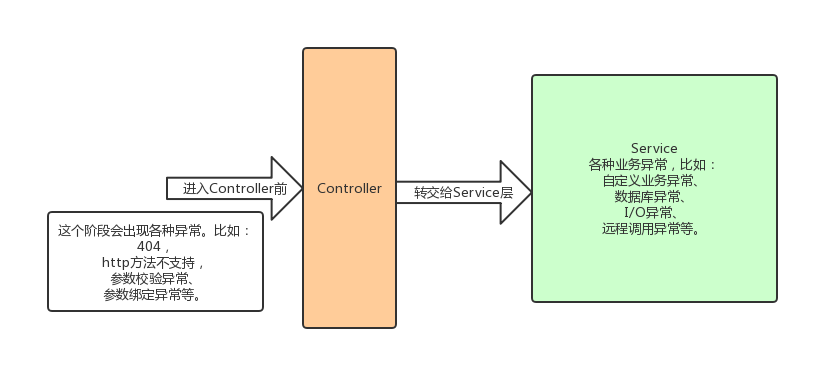
如何优雅的写个try catch的方式!
软件开发过程中,不可避免的是需要处理各种异常,就我自己来说,至少有一半以上的时间都是在处理各种异常情况,所以代码中就会出现大量的try {...} catch {...} finally {...} 代码块,不仅有大量的冗余代码,而…...
海尔智家:智慧场景掌握「主动」权,用户体验才有话语权
2023年1月,《福布斯》AI专栏作家Rob Toews发布了年度AI发展预测,指出人工智能的发展将带来涉及各行业、跨学科领域的深远影响。变革将至,全球已掀起生成式AI热,以自然语言处理为代表的人工智能技术在快速进化,积极拥抱…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...
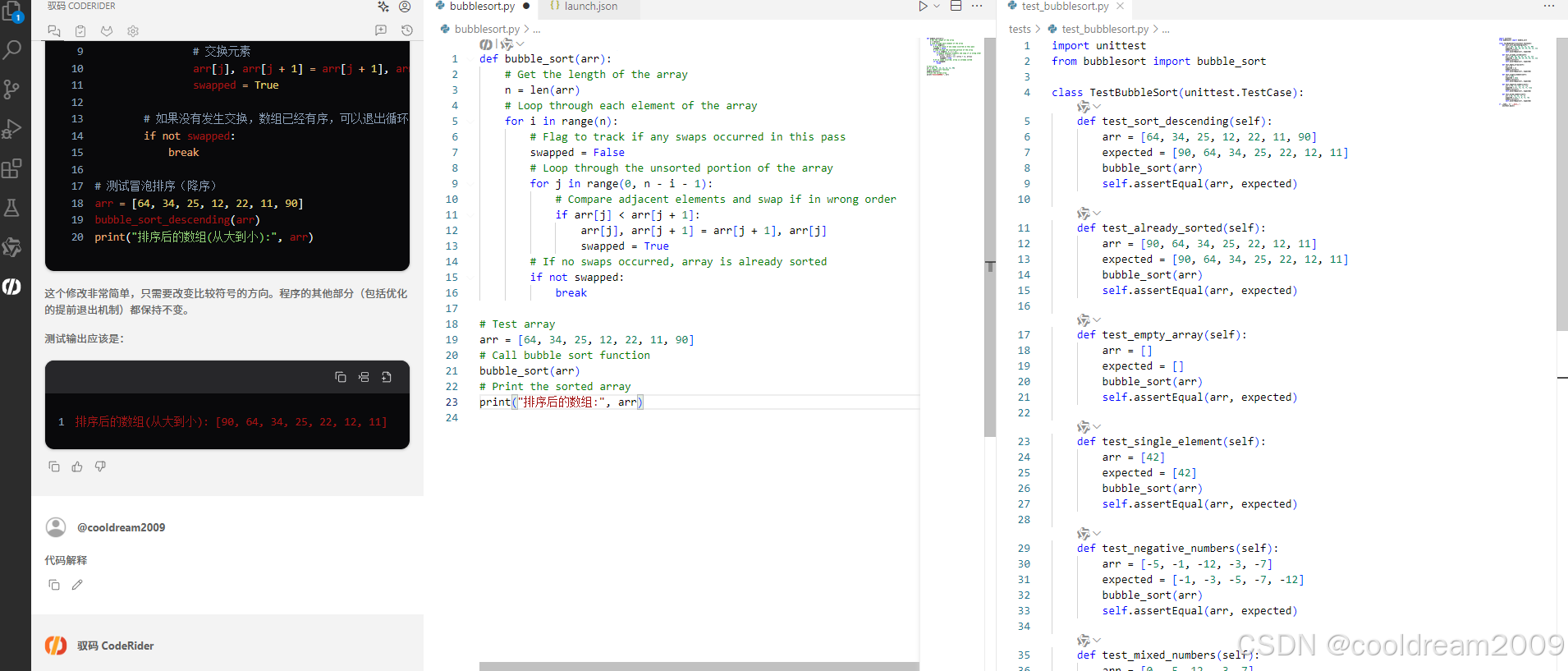
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...

FOPLP vs CoWoS
以下是 FOPLP(Fan-out panel-level packaging 扇出型面板级封装)与 CoWoS(Chip on Wafer on Substrate)两种先进封装技术的详细对比分析,涵盖技术原理、性能、成本、应用场景及市场趋势等维度: 一、技术原…...