从零开始学架构——高可用存储架构
双机架构
存储高可用方案的本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用,其复杂性主要体现在如何应对复制延迟和中断导致的数据不一致问题。因此,对任何一个高可用存储方案,我们需要从以下几个方面去进行思考和分析:
数据如何复制?
各个节点的职责是什么?
如何应对复制延迟?
如何应对复制中断?
常见的高可用存储架构有主备、主从、主主、集群、分区。
主备复制
主备复制是最常见也是最简单的一种存储高可用方案,几乎所有的存储系统都提供了主备复制的功能,例如 MySQL、Redis、MongoDB 等。
- 基本实现
下面是标准的主备方案结构图:
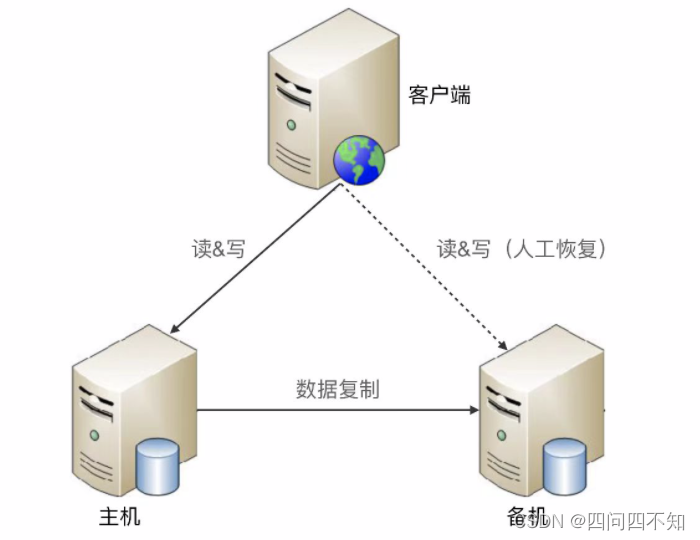
- 优缺点分析
-
优点:
1、无须感知备机存在;
2、对于主备,双方只需要进行数据复制即可,无须进行状态判断和主备切换操作; -
缺点:
1、备机仅仅只为备份,并没有提供读写操作;
2、故障后需要人工干预,无法自动恢复; -
使用场景:
内部的后台管理系统使用主备复制架构的情况会比较多,例如学生管理系统、员工管理系统、假期管理系统等,因为这类系统的数据变更频率低,即使在某些场景下丢失数据,也可以通过人工的方式补全
主从复制
主机负责读写操作,从机只负责读操作,不负责写操作。
- 基本实现
下面是标准的主从复制架构:
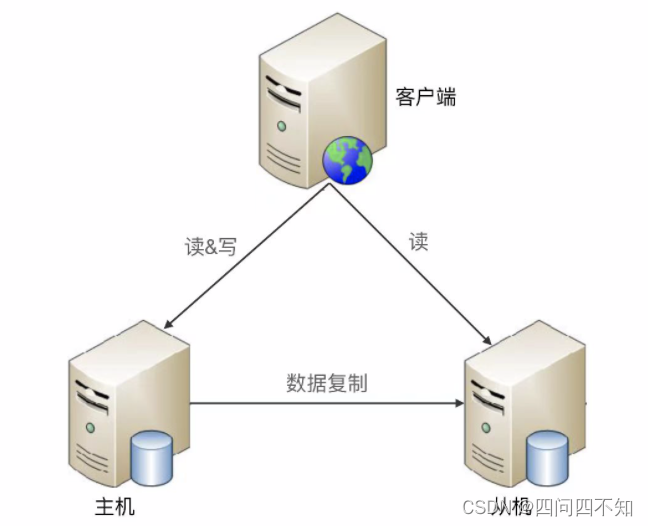
- 优缺点分析
-
优点:
1、主从复制在主机故障时,读操作相关的业务可以继续运行;
2、主从复制架构的从机提供读操作,发挥了硬件的性能; -
缺点:
1、客户端需要感知主从关系,并将不同的操作发给不同的机器进行处理;
2、如果主从复制延迟比较大,业务会因为数据不一致出现问题;
3、故障时需要人工干预; -
使用场景:
写少读多的业务场景使用主从复制架构较多。如,论坛,BBS、新闻网站等,读操作数量是写操作数量的10倍甚至100倍以上。
双机切换
主备复制和主从复制方案存在两个共性的问题:
- 1、主机故障后,无法进行写操作;
- 2、如果主机无法恢复,需要人工指定新的主机角色;
双机切换就是为了解决这两个问题而产生的,包括主备切换和主从切换两种方案。简单来说,这两个方案就是在原有方案的基础上增加“切换”功能,即系统自动决定主机角色,并完成角色切换。
要实现一个完善的切换方案,必须考虑这几个关键的设计点:
主备间状态判断
- 状态传递的渠道:是相互间互相连接,还是第三方仲裁?
- 状态检测的内容:例如机器是否掉电、进程是否存在、响应是否缓慢等。
切换决策
- 切换时机:什么情况下备机应该升级为主机?是机器掉电后备机才升级,还是主机上的进程不存在就升级,还是主机响应时间超过2秒就升级,还是3分钟内主机连续重启3次就升级等。
- 切换策略:原来的主机故障恢复后,要再次切换,确保原来的主机继续做主机,还是原来的主机故障恢复后自动成为新的备机?
- 自动程度:切换是完全自动还是半自动的?
数据冲突解决
当原有故障的主机恢复后,新旧主机之间可能存在数据冲突。例如,用户在旧主机上新增了一条ID为100的数据,这个数据还没有复制到旧的备机,此时发生切换,用户又在新的主机新增了一条ID为100的数据,当旧的故障主机恢复后,这两条ID重复的数据如何处理。
根据状态传递渠道的不同,常见的主备切换架构有三种形式:互连式、中介式和模拟式。
互连式
互连式是指主备机直接建立状态传递的渠道,存在状态传递通道故障的问题
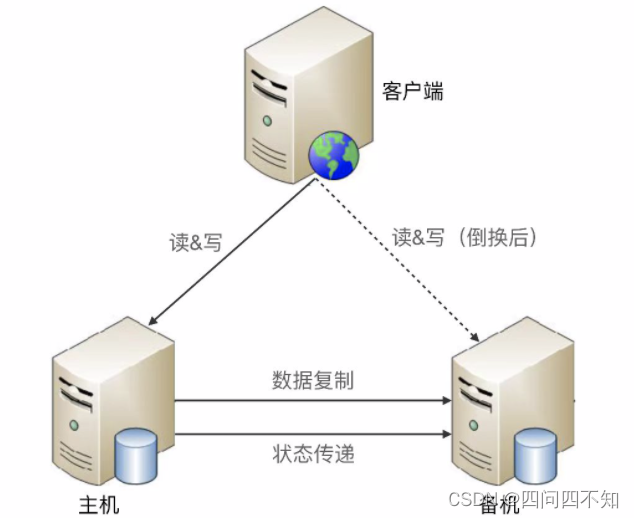
可以是主机发送状态给备机,也可以是备机到主机来获取状态信息。
可以和数据复制通道共用,也可以独立一条通道。
为了充分利用切换方案能够自动决定主机这个优势,客户端也会有一些相应的改变,常见方式如下:
1、为了切换后不影响客户端的访问,主机和备机之间共享一个对客户端来说唯一的地址。例如虚拟 IP,主机需要绑定这个虚拟的 IP。
2、客户端同时记录主备机的地址;
3、备机虽然能收到客户端的操作请求,但是会直接拒绝,拒绝的原因就是“备机不对外提供服务”;
互连式缺点:
1、状态传递的通道故障时,可能导致备机也认为主机故障了从而升级为主机,导致出现两个主机;
2、如果增加多个通道增强状态传递的可靠性,只是降低通道故障概率,不能根本解决这个缺点,并且通道越多状态决策越复杂。
中介式
中介式指的是在主备两者之外引入第三方中介,主备机之间不直接连接,而都去连接中介,并且通过中介来传递状态信息
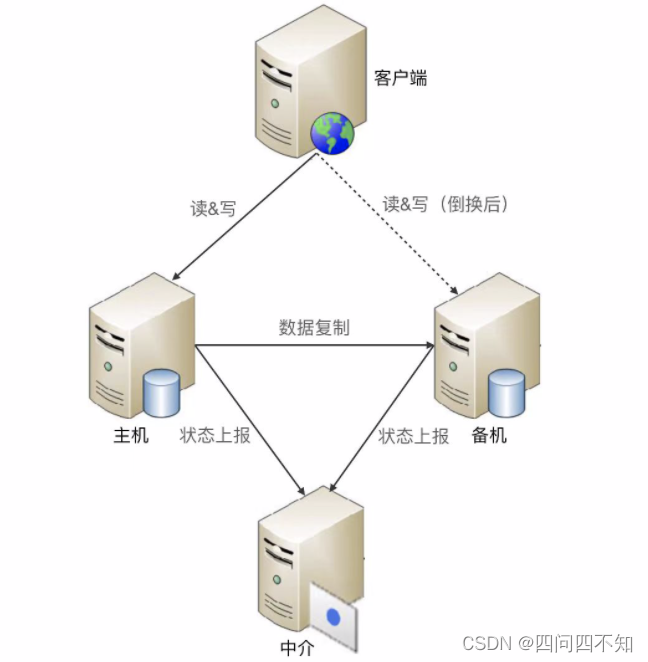
虽然中介式在状态传递和状态决策上更加简单,但存在如何保证中介本身的高可用问题。如果中介自己宕机了,整个系统就进入了双备的状态,写操作相关的业务就不可用了。
MongoDB的Replica Set采取的就是中介式,架构图如下,
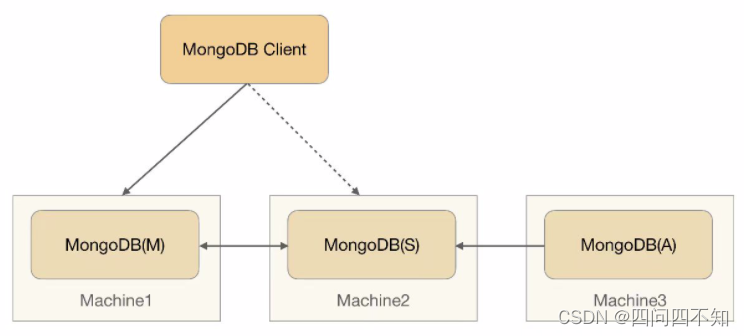
- MongoDB(M),主节点:存储数据
- MongoDB(S):备节点:存储数据
- MongoDB(A):仲裁节点:不存储数据
客户端连接主备节点。
开源方案已经有比较成熟的中介式解决方案,例如 ZooKeeper 和 Keepalived。ZooKeeper 本身已经实现了高可用集群架构,因此已经帮我们解决了中介本身的可靠性问题,在工程实践中推荐基于 ZooKeeper 搭建中介式切换架构。
模拟式
模拟式指主备机之间并不传递任何状态数据,而是备机模拟成一个客户端,向主机发起模拟的读写操作,根据读写操作的响应情况来判断主机的状态。
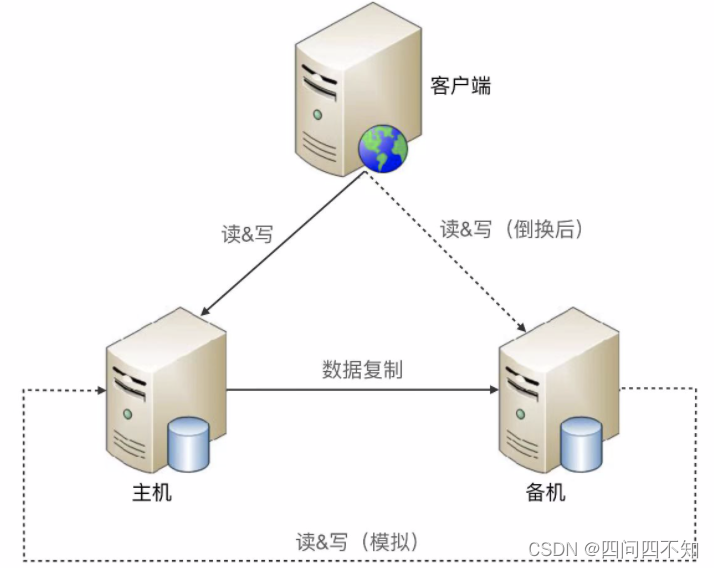
模拟式切换与互连式切换相比,优点是实现更加简单,因为省去了状态传递通道的建立和管理工作。
简单既是优点,同时也是缺点。因为模拟式读写操作获取的状态信息只有响应信息(例如,HTTP 404,超时、响应时间超过 3 秒等),没有互连式那样多样(除了响应信息,还可以包含 CPU 负载、I/O 负载、吞吐量、响应时间等),基于有限的状态来做状态决策,可能出现偏差。
主主复制
主主复制指的是两台机器都是主机,互相将数据复制给对方,客户端可以任意挑选其中一台机器进行读写操作
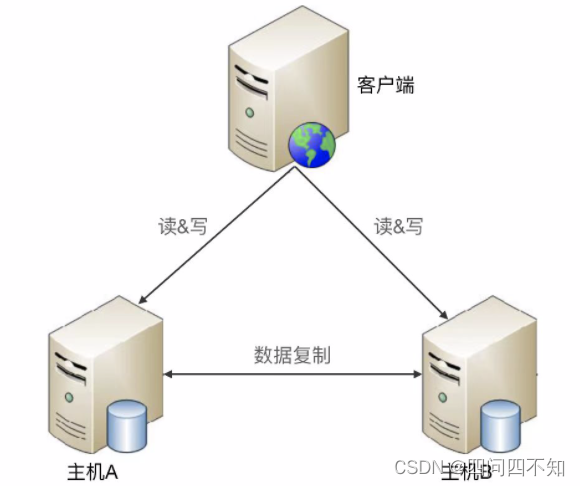
主主复制从总体上来看要简单很多,无须状态信息传递,也无须状态决策和状态切换,但是其对使用场景有限制,如果采取主主复制架构,必须保证数据能够双向复制,而很多数据是不能双向复制的。例如:
- 1、用户注册后生成的用户 ID,如果按照数字增长,那就不能双向复制,否则就会出现多台主机出现同一ID;
- 2、库存不能双向复制,一台主机减了,另一台主机也减了,复制后被覆盖掉;
因此,主主复制架构对数据的设计有严格的要求,一般适合于那些临时性、可丢失、可覆盖的数据场景。例如,用户登录产生的 session 数据(可以重新登录生成)、用户行为的日志数据(可以丢失)、论坛的草稿数据(可以丢失)等。
集群和分区
数据集群
主备、主从、主主架构本质上都有一个隐含的假设:主机能够存储所有数据,主机本身的存储和处理能力有极限。单台服务器肯定是无法存储和处理的,我们必须使用多台服务器来存储数据,这就是数据集群架构。
集群就是多台机器组合在一起形成一个统一的系统,这里的“多台”,数量上至少是 3 台;相比而言,主备、主从都是 2 台机器。根据集群中机器承担的不同角色来划分,集群可以分为两类:数据集中集群、数据分散集群。
数据集中集群
1 主多备或者 1 主多从。无论是 1 主 1 从、1 主 1 备,还是 1 主多备、1 主多从,数据都只能往主机中写,而读操作可以参考主备、主从架构进行灵活多变。下图是读写全部到主机的一种架构:
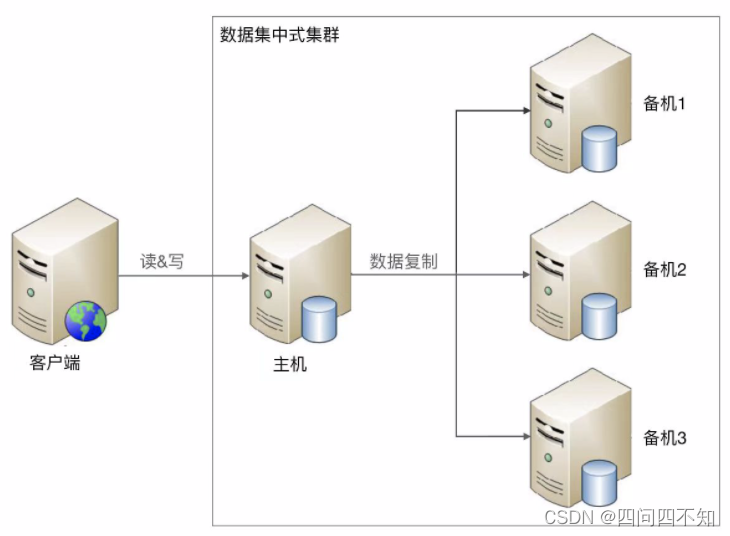
虽然架构上是类似的,但由于集群里面的服务器数量更多,导致复杂度整体更高一些,具体体现在:
- 1、主机如何将数据复制给备机
主备和主从架构中,只有一条复制通道,而数据集中集群架构中,存在多条复制通道。多条复制通道首先会增大主机复制的压力,某些场景下我们需要考虑如何降低主机复制压力,或者降低主机复制给正常读写带来的压力。
其次,多条复制通道可能会导致多个备机之间数据不一致,某些场景下我们需要对备机之间的数据一致性进行检查和修正。
- 2、备机如何检测主机状态
主备和主从架构中,只有一台备机需要进行主机状态判断。在数据集中集群架构中,多台备机都需要对主机状态进行判断,而不同的备机判断的结果可能是不同的,如何处理不同备机对主机状态的不同判断,是一个复杂的问题?
- 3、主机故障后,如何决定新的主机
主从架构中,如果主机故障,将备机升级为主机即可;而在数据集中集群架构中,有多台备机都可以升级为主机,但实际上只能允许一台备机升级为主机,那么究竟选择哪一台备机作为新的主机,备机之间如何协调?
目前开源的数据集中集群以 ZooKeeper 为典型,ZooKeeper 通过 ZAB 算法来解决上述提到的几个问题,但 ZAB 算法的复杂度是很高的。
数据分散集群
数据分散集群指多个服务器组成一个集群,每台服务器都会负责存储一部分数据;同时,为了提升硬件利用率,每台服务器又会备份一部分数据。
数据分散集群的复杂点在于如何将数据分配到不同的服务器上,算法需要考虑这些设计点:
-
均衡性
算法需要保证服务器上的数据分区基本是均衡的,不能存在某台服务器上的分区数量是另外一台服务器的几倍的情况。 -
容错性
当出现部分服务器故障时,算法需要将原来分配给故障服务器的数据分区分配给其他服务器。 -
可伸缩性
当集群容量不够,扩充新的服务器后,算法能够自动将部分数据分区迁移到新服务器,并保证扩容后所有服务器的均衡性。
数据分散集群和数据集中集群的不同点在于,数据分散集群中的每台服务器都可以处理读写请求,因此不存在数据集中集群中负责写的主机那样的角色。但在数据分散集群中,必须有一个角色来负责执行数据分配算法,这个角色可以是独立的一台服务器,也可以是集群自己选举出的一台服务器。如果是集群服务器选举出来一台机器承担数据分区分配的职责,则这台服务器一般也会叫作主机,但我们需要知道这里的“主机”和数据集中集群中的“主机”,其职责是有差异的。
Hadoop 的实现就是独立的服务器负责数据分区的分配,这台服务器叫作 Namenode。Hadoop 的数据分区管理架构如下:
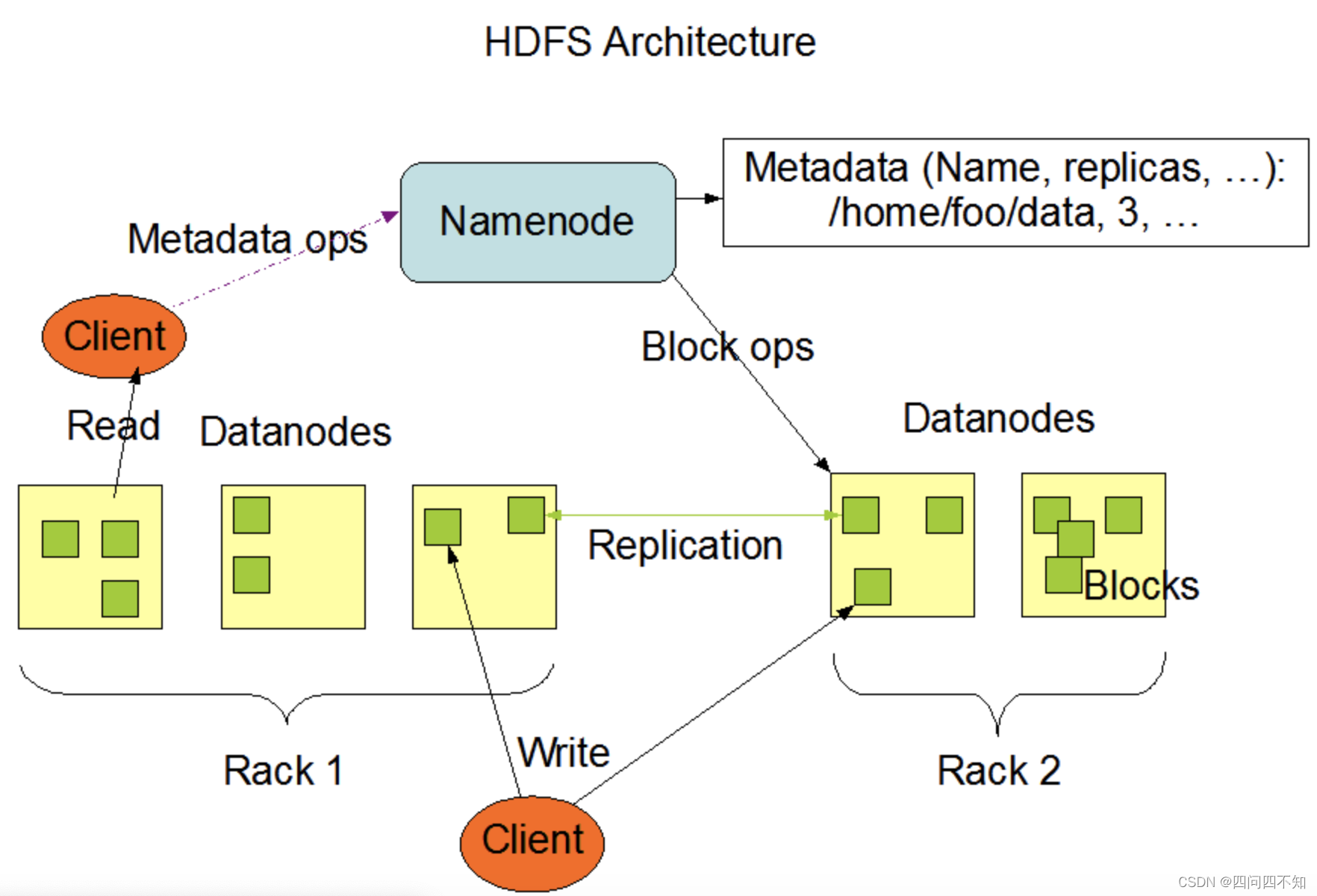
Hadoop官方网站——HDFS架构
下面是 Hadoop 官方的解释,能够说明集中式数据分区管理的基本方式。
- HDFS 采用 master/slave 架构。一个 HDFS 集群由一个 Namenode 和一定数目的Datanodes 组成。
- Namenode 是一个中心服务器,负责管理文件系统的名字空间(namespace),以及客户端对文件的访问。
- 集群中的 Datanode 一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode 上。
- Namenode 执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体 Datanode节点的映射。
- Datanode 负责处理文件系统客户端的读写请求。在 Namenode 的统一调度下进行数据块的创建、删除和复制操作。
与 Hadoop 不同的是,Elasticsearch 集群通过选举一台服务器来做数据分区的分配,叫作 master node,其数据分区管理架构是:
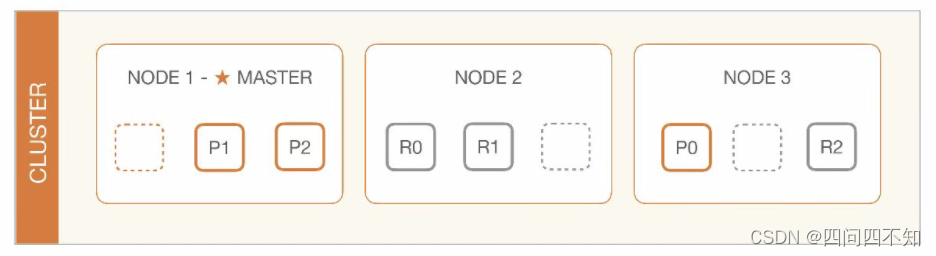
其中 master 节点的职责如下:
The master node is responsible for lightweight cluster-wide actions such as creating or deleting an index, tracking which nodes are part of the cluster, and deciding which shards to allocate to which nodes. It is important for cluster health to have a stable master node.
elasticsearch官方文档——modules-node
数据集中集群架构中,客户端只能将数据写到主机;数据分散集群架构中,客户端可以向任意服务器中读写数据。正是因为这个关键的差异,决定了两种集群的应用场景不同。一般来说,数据集中集群适合数据量不大,集群机器数量不多的场景。例如,ZooKeeper 集群,一般推荐 5 台机器左右,数据量是单台服务器就能够支撑;而数据分散集群,由于其良好的可伸缩性,适合业务数据量巨大、集群机器数量庞大的业务场景。例如,Hadoop 集群、HBase 集群,大规模的集群可以达到上百台甚至上千台服务器。
数据分区
前面我们讨论的存储高可用架构都是基于硬件故障的场景去考虑和设计的,主要考虑当部分硬件可能损坏的情况下系统应该如何处理,但对于一些影响非常大的灾难或者事故来说,有可能所有的硬件全部故障。例如,新奥尔良水灾、美加大停电、洛杉矶大地震等这些极端灾害或者事故,可能会导致一个城市甚至一个地区的所有基础设施瘫痪,这种情况下基于硬件故障而设计的高可用架构不再适用,我们需要基于地理级别的故障来设计高可用架构,这就是数据分区架构产生的背景。
不同分区分布在不同的地理位置上,每个分区存储一部分数据,通过这种方式来规避地理级别的故障所造成的巨大影响。
数据量
数据量的大小直接决定了分区的规则复杂度。例如,使用 MySQL 来存储数据,假设一台 MySQL 存储能力是 500GB,那么 2TB 的数据就至少需要 4 台 MySQL 服务器;而如果数据是 200TB,并不是增加到 800 台的 MySQL 服务器那么简单。如果按照 4 台服务器那样去平行管理 800 台服务器,复杂度会发生本质的变化,具体表现为:
800 台服务器里面可能每周都有一两台服务器故障,从 800 台里面定位出 2 台服务器故障,很多情况下并不是一件容易的事情,运维复杂度高。
增加新的服务器,分区相关的配置甚至规则需要修改,而每次修改理论上都有可能影响已有的 800 台服务器的运行,不小心改错配置的情况在实践中太常见了。
如此大量的数据,如果在地理位置上全部集中于某个城市,风险很大,遇到了水灾、大停电这种灾难性的故障时,数据可能全部丢失,因此分区规则需要考虑地理容灾。
分区规则
洲际分区主要用于面向不同大洲提供服务,由于跨洲通讯的网络延迟已经大到不适合提供在线服务了,因此洲际间的数据中心可以不互通或者仅仅作为备份;国家分区主要用于面向不同国家的用户提供服务,不同国家有不同语言、法律、业务等,国家间的分区一般也仅作为备份;城市分区由于都在同一个国家或者地区内,网络延迟较低,业务相似,分区同时对外提供服务,可以满足业务异地多活之类的需求。
复制规则
数据分散在多个地区,分区架构,同样需要考虑复制方案。
复制规则有三种:集中式、互备式和独立式。
- 集中式
集中式备份指存在一个总的备份中心,所有的分区都将数据备份到备份中心,其基本架构如下:
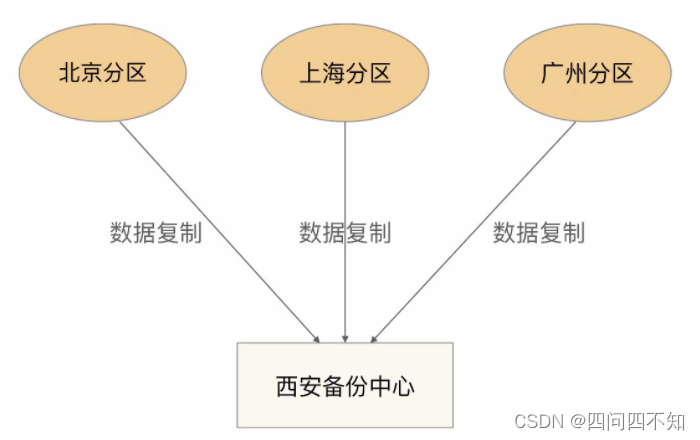
优缺点是:
设计简单,各分区之间并无直接联系,可以做到互不影响。
扩展容易,如果要增加第四个分区(例如,武汉分区),只需要将武汉分区的数据复制到西安备份中心即可,其他分区不受影响。
成本较高,需要建设一个独立的备份中心。
- 互备式
互备式备份指每个分区备份另外一个分区的数据,其基本架构如下:
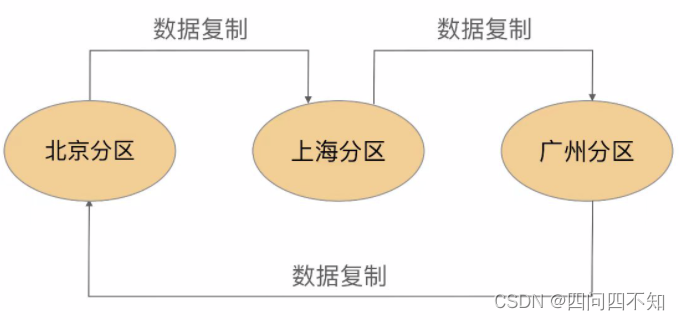
优缺点是:
设计比较复杂,各个分区除了要承担业务数据存储,还需要承担备份功能,相互之间互相关联和影响。
扩展麻烦,如果增加一个武汉分区,则需要修改广州分区的复制指向武汉分区,然后将武汉分区的复制指向北京分区。而原有北京分区已经备份了的广州分区的数据怎么处理也是个难题,不管是做数据迁移,还是广州分区历史数据保留在北京分区,新数据备份到武汉分区,无论哪种方式都很麻烦。
成本低,直接利用已有的设备。
- 独立式
独立式备份指每个分区自己有独立的备份中心,其基本架构如下:
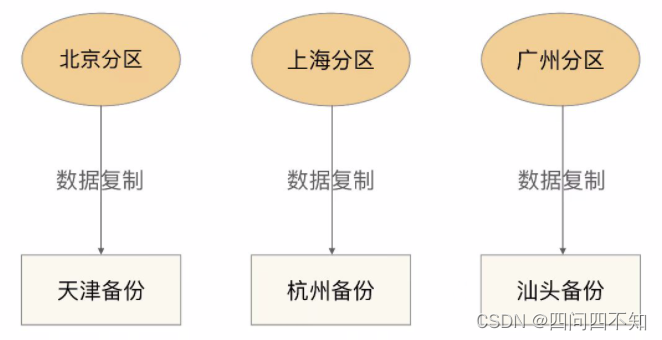
独立式备份架构的优缺点是:
设计简单,各分区互不影响。
扩展容易,新增加的分区只需要搭建自己的备份中心即可。
成本高,每个分区需要独立的备份中心,备份中心的场地成本是主要成本,因此独立式比集中式成本要高很多。
相关文章:
从零开始学架构——高可用存储架构
双机架构 存储高可用方案的本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用,其复杂性主要体现在如何应对复制延迟和中断导致的数据不一致问题。因此,对任何一个高可用存储方案,我们需要从以下几个方面去进…...

连ChatGPT都不懂的五一调休,到底怎么来的?
今天是周几? 你上了几天班了? 还要上几天班放假? 五一啥安排? 出行的票抢到了吗? 调休到底是谁发明的?! 五一劳动节是要劳动吗? 为什么昨天是周一,今天还是周一&a…...

AES工作流程
工作流程 模式 1:加密 ⚫ 复位EN 重置AES模块 ⚫ 设置模式寄存器mode[1:0]00,设置流数据处理模式寄存器CHMOD[1:0] ⚫ 写AES_KEYRx寄存器,CTR和CBC模式下写AES_IVRx寄存器 ⚫ 写EN1,使能AES ⚫ 写AES_DINR 寄存器4次 ⚫ 等待CCF标…...

C++11
C11 统一的列表初始化 在介绍这里的列表初始化之前,首先我认为这是一个比较鸡肋的功能特性,而且使用起来会和之前C98时有些区别。 // 首先可以定义普通的内置类型的变量int x1 1;int x2 { 1 };int x3{ 1 }; // 这样看起来着实有些怪int arry1[] { 1,…...

ubuntu18.04 配置zlmediakit 支持ffmpeg转码记录
1、zlmediakt 默认不支持ffmepg转码,需要在根目录下的CamkeLists.txt里面option(ENABLE_FFMPEG "Enable FFmpeg" OFF) 将OFF改成ON, 删除原有的build目录,sudo mkdir build. cd build,cmake .. 这样在编译生成文件夹release/linux/debug/生…...

H68K配置路由功能
系统环境Armbian ubuntu系统 参考 如何使用Debian/Ubuntu等Linux做软路由(物理机版本,非虚拟机容器版) - 知乎 https://zhuanlan.zhihu.com/p/587068225 按照他操作的结果,就是只有一个网卡正常 最后一顿操作就出现了我这么个配置 更新源…...

*2.5 迭代法的收敛阶与加速收敛方法
学习目标: 了解迭代法的基本概念和原理。学习者需要理解迭代法的基本概念和原理,包括迭代过程、迭代格式、收敛性等基本概念。 熟练掌握迭代法的收敛阶和收敛速度。学习者需要了解迭代法的收敛阶和收敛速度,掌握如何计算迭代法的收敛阶和收敛…...

仪表板展示 | X-lab开放实验室GitHub开源项目洞察大屏
背景介绍 X-lab开放实验室是一个开源软件产业开放式创新的共同体,由来自国内外著名高校、创业公司、部分互联网与IT企业的专家学者与工程师所构成,目前已在包括开源治理标准制定、开源社区行为度量与分析、开源社区流程自动化、开源全域数据治理与洞察等…...
【c语言】五大内存区域 | 堆区详解
创作不易,本篇文章如果帮助到了你,还请点赞支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ…...
【JavaScript】动态表格
🎊专栏【 前端易错合集】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 大一同学小吉,欢迎并且感谢大家指出我的问题🥰 🍔介绍 就是在输入框中输入数字后,再按…...
Css如何优雅的实现抽奖转盘
如图,抽奖转盘,可以拆分为几部分: 1.底部大圆; 2.中间小圆; 3.扇形区; 4.扇形内部奖品区; 5.抽奖按钮; 6.点击抽奖按钮时旋转动效及逻辑; 这其中,扇形区&am…...

在Java的小问题
问题1:如何在Java中创建一个对象? 解决方法: 在Java中,要创建一个对象,需要以下步骤: 创建一个类,定义对象的属性和行为。在类中定义一个构造函数,用于初始化对象的属性。在程序中…...
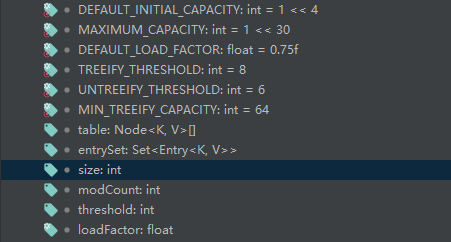
HashMap的扩容机制、初始化容量大小的选择、容量为什么是2的次幂
前置知识 先来看看HashMap中的成员属性 解释: size当前的容器中Entry的数量,也就是当前K-V的数量loadFactory装载因子,用来衡量HashMap满的程度,loadFactory的默认值是0.75threshold临界值,当实际KV数量超过threshol…...
[jenkins自动化2]: linux自动化部署方式之流水线(下篇)
目录 1. 引言: 2. 进阶操作 流水线 -> 2.1 简介: -> 2.2 最终效果图展示: -> 2.3 有没有心动, 真的像流水线一样, 实现了一键部署启动 3. 实现方式 3.1 下载几个插件 3.2 创建流水线任务 3.3 点击配置 3.4 根据流水线语法 写一个简单的helloworld 3.5 执行…...

idea使用 ( 二 ) 创建java项目
3.创建java项目 3.1.创建普通java项目 3.1.1.打开创建向导 接 2.3.1.创建新的项目 也可以 从菜单选择建立项目 会打开下面的选择界面 3.1.2.不使用模板 3.1.3.设置项目名 Project name : 项目名 Project location : 项目存放的位置 确认创建 3.1.4.关闭tips 将 Dont s…...
RabbitMq-接收消息+redis消费者重复接收
在接触RammitMQ时,好多文章都说在配置中设置属性 # rabbitmq 配置 rabbitmq:host: xxx.xxx.xxx.xxxport: xxxxusername: xxxpassword: xxxxxx## 生产端配置# 开启发布确认,就是confirm模式. 消费端ack应答后,才将消息从队列中删除#确认消息已发送到队列(Queue)pub…...
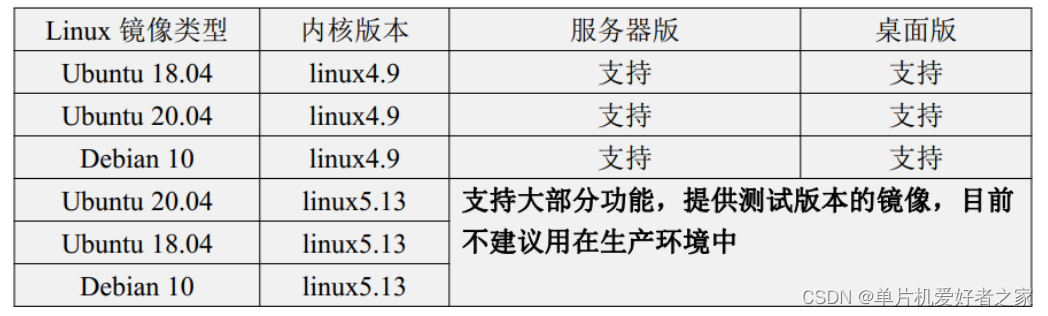
Orangepi Zero2 全志H616简介
为什么学 学习目标依然是Linux 系统 ,平台是 ARM 架构 蜂巢快递柜,配送机器人,这些应用场景用C51,STM32单片机无法实现 第三方介入库的局限性,比如刷脸支付和公交车收费设备需要集成支付宝SDK,提供的libalipay.so 是…...

Golang每日一练(leetDay0047)
目录 138. 复制带随机指针的链表 Copy List with Random-pointer 🌟🌟 139. 单词拆分 Word Break 🌟🌟 140. 单词拆分 II Word Break II 🌟🌟🌟 🌟 每日一练刷题专栏 &…...
HCL Nomad Web 1.0.7发布和新功能验证
大家好,才是真的好。 要问在HCL Notes/Domino系列产品中,谁更新得最快,那么答案一定是HCL Nomad Web。 你看上图右边,从1.0.1更新到1.0.7,都没花多少时间。 从HCL Nomad Web 1.0.5版本开始,可以支持直接…...

春招网申简历填写三技巧
网申第一关很重要,不夸张的说网申决定了你的笔试机会,从如信银行考试中心了解到,银行网申筛选过程中,有机器筛选人工筛选两道程序,掌握填写技巧后对提升简历通过率有较大帮助,一定要把握住,关于…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...