【openGauss实战11】性能报告WDR深度解读
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前服务于工业互联网
擅长主流Oracle、MySQL、PG、高斯及GP 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.WDR报告概述
- 📣 2.WDR相关参数
- 📣 3.如何生成WDR报告
- ✨ 3.1 开启WDR
- ✨ 3.2 查询快照信息
- ✨ 3.3 生成WDR
- 📣 4.WDR解读
- 📣 4.1 WDR概况信息
- 📣 4.2 WDR实例的效
- 📣 4.3 Top 10事件
- 📣 4.4 等待类型统计
- 📣 4.5 CPU负载
- 📣 4.6 IO负载
- 📣 4.7 内存统计
- 📣 4.8 time model
- 📣 4.9 SQL Statistics
- 📣 4.10 Wait Events
- 📣 4.11 Cache IO Stats
- 📣 4.12 Object stats
前言
本篇介绍了openGauss的WDR报告的解读,可用于后期的性能的分析📣 1.WDR报告概述
在opengauss数据库中,WDR是(Workload Diagnosis Report)负载诊断报告,
是openGauss的工作负载诊断报告,常用于判断openGauss长期性能问题。
整个数据库在运行期间的现状或者说真实状态只有在被完整记录下来,
才是可查,可知,可比较,可推测或者说为未来性能优化调整提供支撑建议的基础。
📣 2.WDR相关参数
1.enable_wdr_snapshot:
是否开启数据库监控快照功能。
2.wdr_snapshot_retention_days:
系统中数据库监控快照数据的保留天数。当数据库运行过程期间所生成的快照量数超过保留天数内允许生成的快照数量的最大值时,系统将每隔wdr_snapshot_interval时间间隔,清理snapshot_id最小的快照数据。取值范围:整型,1~8
3.wdr_snapshot_interval:
后台线程Snapshot自动对数据库监控数据执行快照操作的时间间隔。
4.wdr_snapshot_query_timeout:
系统执行数据库监控快照操作时,设置快照操作相关的sql语句的执行超时时间。
如果语句超过设置的时间没有执行完并返回结果,则本次快照操作失败。取值范围:整型,100~INT_MAX(秒)

📣 3.如何生成WDR报告
✨ 3.1 开启WDR
生成WDR报告的前提条件是,打开参数enable_wdr_snapshot
gs_guc reload -Nall -I all -c “enable_wdr_snapshot=on”
说明:
WDR Snasphot在启动后,会在用户表空间"pg_default",数据库"postgres"下新建schema “snapshot”,用于持久化WDR快照数据。
✨ 3.2 查询快照信息
openGauss=# select * from snapshot.snapshot;snapshot_id | start_ts | end_ts
-------------+-------------------------------+-------------------------------1 | 2023-04-25 22:19:08.729911+08 | 2023-04-25 22:19:15.876007+082 | 2023-04-25 23:19:09.165954+08 | 2023-04-25 23:19:12.986594+08
(2 rows)openGauss-# \d snapshot.snapshotTable "snapshot.snapshot"Column | Type | Modifiers
-------------+--------------------------+-----------snapshot_id | bigint | not nullstart_ts | timestamp with time zone |end_ts | timestamp with time zone |
Indexes:"snapshot_pkey" PRIMARY KEY, btree (snapshot_id) TABLESPACE pg_default##手工创建快照可以通过以下命令
openGauss=# select create_wdr_snapshot();
openGauss=# select * from snapshot.snapshot;snapshot_id | start_ts | end_ts
-------------+-------------------------------+-------------------------------1 | 2023-04-25 22:19:08.729911+08 | 2023-04-25 22:19:15.876007+082 | 2023-04-25 23:19:09.165954+08 | 2023-04-25 23:19:12.986594+083 | 2023-04-26 00:03:03.374795+08 | 2023-04-26 00:03:05.801867+08postgres=# select * from dbms_om.snapshot where start_ts > '2021-02-21 03:00:00'::timestamptz
and start_ts < '2021-02-21 04:00:00'::timestamptz order by snapshot_id;
✨ 3.3 生成WDR
1)查询 pgxc_node_name参数值,或者使用查询视图:pg_node_env
openGauss=# show pgxc_node_name;pgxc_node_name
----------------dn_6001
(1 row)2) \a \t \o 服务器文件路径生成格式化性能报告
上述命令涉及参数说明如下:
\a:切换非对齐模式。
\t:切换输出的字段名的信息和行计数脚注。
\o:把所有的查询结果发送至服务器文件里。
服务器文件路径:生成性能报告文件存放路径。用户需要拥有此路径的读写权限
openGauss=# \a \t \o /home/omm/wdr_sarah.html3)向性能报告wdr_sarah.html中写入数据,从snapshot.snapshot视图中选取要生成WDR报告的时间点
gsql -d postgres -p 15400 -r -c"select generate_wdr_report(快照id1,快照id2,'all','node','pgxc_node_name参数值');"
select generate_wdr_report(快照id1,快照id2,'all','node','pgxc_node_name参数值');openGauss=# select generate_wdr_report(1,3,'all','node','dn_6001');4)postgres=# \o \a \t -- 关闭格式化输出
注意:生产数据库如果数据量大,快照建议1个小时的格式输出


📣 4.WDR解读
📣 4.1 WDR概况信息

这一部分是WDR报告的概况信息,从这一部分我们能得到如下信息:
| 信息分类 | 信息描述 |
|---|---|
| 报告采集类型 | Summary + Detail,即汇总数据+明细数据 |
| Snapshot信息 | 使用snapshot_id为1和3的快照采集2023-04-25(22:19~ 23:59)的运行信息 |
| 硬件配置 | 1*1C/1G |
| 节点名 | dn_6001 |
| openGauss版本 | openGauss 5.0.0 |
📣 4.2 WDR实例的效

这一部分是实例的效率百分比,目标值是100%,即越接近100%,数据库运行越健康。
1)Buffer Hit:
即数据库请求的数据在buffer中命中的比例,该指标越高代表openGauss在buffer中查询到目标数据的概率越高,数据读取性能越好。
2)Effective CPU:
即有效的CPU使用比例,该指标偏小则说明CPU的有效使用偏低,处于等待状态的比例可能较高。
3)WalWrite NoWait: 即WAL日志写入时不等待的比例,该指标接近100%,说明buffer容量充足,可以满足WAL写操作的需求,
若指标值偏小则可能需要调大buffer容量。
4)Soft Parse:即SQL软解析的比例,该指标接近100%,说明当前执行的SQL基本都可以在Buffer中找到,
若指标值偏小则说明存在大量硬解析,需要分析原因,对DML语句进行适度优化。
5)Non-Parse CPU:
即非解析占用的CPU比例,该指标接近100%,说明SQL解析并没有占用较多的CPU时间。
📣 4.3 Top 10事件

这一部分列出了数据库Top 10的等待事件、等待次数、总等待时间、平均等待时间、等待事件类型。
等待事件主要分为等待状态、等待轻量级锁、等待IO、等待事务锁这4类(STATUS、LWLOCK_EVENT、IO_EVENT、LOCK_EVENT)
1)等待状态列表
说明:当Type为LWLOCK_EVENT、LOCK_EVENT或者wait IO_EVENT时,表示有等待事件。
正在等待获取wait_event列对应类型的轻量级锁、事务锁,或者正在进行IO。none:没在等任意事件。
acquire lock:等待加锁,要么加锁成功,要么加锁等待超时。
acquire lwlock:等待获取轻量级锁。
wait io:等待IO完成。
wait cmd:等待完成读取网络通信包。
wait pooler get conn:等待pooler完成获取连接。
wait pooler abort conn:等待pooler完成终止连接。
wait pooler clean conn:等待pooler完成清理连接。
pooler create conn: [\nodename], total N:等待pooler建立连接,当前正在与nodename指定节点建立连接,且仍有N个连接等待建立。
get conn:获取到其他节点的连接。
set cmd: [\nodename]:在连接上执行SET/RESET/TRANSACTION BLOCK LEVEL PARA SET/SESSION LEVEL PARA SET,当前正在nodename指定节点上执行。cancel query:取消某连接上正在执行的SQL语句。
stop query:停止某连接上正在执行的查询。
wait node: [\nodename](plevel), total N, [phase]:
等待接收与某节点的连接上的数据,当前正在等待nodename节点plevel线程的数据,且仍有N个连接的数据待返回。如果状态包含phase信息,则可能的阶段状态有:
begin:表示处于事务开始阶段。
commit:表示处于事务提交阶段。
rollback:表示处于事务回滚阶段。wait transaction sync: xid 等待xid指定事务同步。
wait wal sync:等待特定LSN的wal log完成到备机的同步。
wait data sync:等待完成数据页到备机的同步。
wait data sync queue:等待把行存的数据页或列存的CU放入同步队列。
flush data: [\nodename](plevel), [phase]
等待向网络中nodename指定节点的plevel对应线程发送数据。如果状态包含phase信息,则可能的阶段状态为wait quota,即当前通信流正在等待quota值。stream get conn: [\nodename], total N
初始化stream flow时,等待与nodename节点的consumer对象建立连接,且当前有N个待建连对象。wait producer ready: [\nodename](plevel), total N
初始化stream flow时,等待每个producer都准备好,当前正在等待nodename节点plevel对应线程的producer对象准备好,且仍有N个producer对象处于等待状态。synchronize quit:stream plan结束时,等待stream线程组内的线程统一退出。
wait stream nodegroup destroy:stream plan结束时,等待销毁stream node group。
wait active statement:等待作业执行,正在资源负载管控中。analyze: [relname], [phase]
当前正在对表relname执行analyze。如果状态包含phase信息,则为autovacuum,表示是数据库自动开启AutoVacuum线程执行的analyze分析操作。vacuum: [relname], [phase]
当前正在对表relname执行vacuum。如果状态包含phase信息,则为autovacuum,表示是数据库自动开启AutoVacuum线程执行的vacuum清理操作。vacuum full: [relname]
当前正在对表relname执行vacuum full清理。create index:当前正在创建索引。HashJoin - [ build hash | write file ]
当前是HashJoin算子,主要关注耗时的执行阶段。
build hash:表示当前HashJoin算子正在建立哈希表。
write file:表示当前HashJoin算子正在将数据写入磁盘。HashAgg - [ build hash | write file ]
当前是HashAgg算子,主要关注耗时的执行阶段。
build hash:表示当前HashAgg算子正在建立哈希表。
write file:表示当前HashAgg算子正在将数据写入磁盘。HashSetop - [build hash | write file ]
当前是HashSetop算子,主要关注耗时的执行阶段。
build hash:表示当前HashSetop算子正在建立哈希表。
write file:表示当前HashSetop算子正在将数据写入磁盘。Sort | Sort - write file
当前是Sort算子做排序,write file表示Sort算子正在将数据写入磁盘。Material | Material - write file
当前是Material算子,write file表示Material算子正在将数据写入磁盘。NestLoop:当前是NestLoop算子。
wait memory:等待内存获取。
wait sync consumer next step:Stream算子等待消费者执行。
wait sync producer next step:Stream算子等待生产者执行
2)轻量级锁等待事件
说明:当Type值为LWLOCK_EVENT(轻量级锁)时对应的wait_event等待事件类型即为轻量级锁等待。
wait_event为extension时,表示此时的轻量级锁是动态分配的锁,未被监控ShmemIndexLock:用于保护共享内存中的主索引哈希表。
OidGenLock:用于避免不同线程产生相同的OID。
XidGenLock:用于避免两个事务获得相同的xid。
ProcArrayLock:用于避免并发访问或修改ProcArray共享数组。
SInvalReadLock:用于避免与清理失效消息并发执行。
SInvalWriteLock:用于避免与其它写失效消息、清理失效消息并发执行。
WALInsertLock:用于避免与其它WAL插入操作并发执行。
WALWriteLock:用于避免并发WAL写盘。
ControlFileLock:用于避免pg_control文件的读写并发、写写并发。
CheckpointLock:用于避免多个checkpoint并发执行。
CLogControlLock:用于避免并发访问或者修改Clog控制数据结构。
SubtransControlLock:用于避免并发访问或者修改子事务控制数据结构。
MultiXactGenLock:用于串行分配唯一MultiXact id。
MultiXactOffsetControlLock:用于避免对pg_multixact/offset的写写并发和读写并发。
MultiXactMemberControlLock:用于避免对pg_multixact/members的写写并发和读写并发。
RelCacheInitLock:用于失效消息场景对init文件进行操作时加锁。
CheckpointerCommLock:用于向checkpointer发起文件刷盘请求场景,需要串行的向请求队列插入请求结构。
TwoPhaseStateLock:用于避免并发访问或者修改两阶段信息共享数组。
TablespaceCreateLock:用于确定tablespace是否已经存在。
BtreeVacuumLock:用于防止vacuum清理B-tree中还在使用的页面。
AutovacuumLock:用于串行化访问autovacuum worker数组。
AutovacuumScheduleLock:用于串行化分配需要vacuum的table。
AutoanalyzeLock:用于获取和释放允许执行Autoanalyze的任务资源。
SyncScanLock:用于确定heap扫描时某个relfilenode的起始位置。
NodeTableLock:用于保护存放数据库节点信息的共享结构。
PoolerLock:用于保证两个线程不会同时从连接池里取到相同的连接。
RelationMappingLock:用于等待更新系统表到存储位置之间映射的文件。
AsyncCtlLock:用于避免并发访问或者修改共享通知状态。
AsyncQueueLock:用于避免并发访问或者修改共享通知信息队列。
SerializableXactHashLock:用于避免对于可串行事务共享结构的写写并发和读写并发。
SerializableFinishedListLock:用于避免对于已完成可串行事务共享链表的写写并发和读写并发。
SerializablePredicateLockListLock:用于保护对于可串行事务持有的锁链表。
OldSerXidLock:用于保护记录冲突可串行事务的结构。
FileStatLock:用于保护存储统计文件信息的数据结构。
SyncRepLock:用于在主备复制时保护xlog同步信息。
DataSyncRepLock:用于在主备复制时保护数据页同步信息。
CStoreColspaceCacheLock:用于保护列存表的CU空间分配。
CStoreCUCacheSweepLock:用于列存CU Cache循环淘汰。
MetaCacheSweepLock:用于元数据循环淘汰。
ExtensionConnectorLibLock:用于初始化ODBC连接场景,在加载与卸载特定动态库时进行加锁。
SearchServerLibLock:用于GPU加速场景初始化加载特定动态库时,对读文件操作进行加锁。
LsnXlogChkFileLock:用于串行更新特定结构中记录的主备机的xlog flush位置点。
ReplicationSlotAllocationLock:用于主备复制时保护主机端的流复制槽的分配。
ReplicationSlotControlLock:用于主备复制时避免并发更新流复制槽状态。
ResourcePoolHashLock:用于避免并发访问或者修改资源池哈希表。
WorkloadStatHashLock:用于避免并发访问或者修改包含数据库主节点的SQL请求构成的哈希表。
WorkloadIoStatHashLock:用于避免并发访问或者修改用于统计当前数据库节点的IO信息的哈希表。
WorkloadCGroupHashLock:用于避免并发访问或者修改Cgroup信息构成的哈希表。
OBSGetPathLock:用于避免对obs路径的写写并发和读写并发。
WorkloadUserInfoLock:用于避免并发访问或修改负载管理的用户信息哈希表。
WorkloadRecordLock:用于避免并发访问或修改在内存自适应管理时对数据库主节点收到请求构成的哈希表。
WorkloadIOUtilLock:用于保护记录iostat,CPU等负载信息的结构。
WorkloadNodeGroupLock:用于避免并发访问或者修改内存中的nodegroup信息构成的哈希表。
JobShmemLock:用于定时任务功能中保护定时读取的全局变量。
OBSRuntimeLock:用于获取环境变量,如GASSHOME。
LLVMDumpIRLock:用于导出动态生成函数所对应的汇编语言。
LLVMParseIRLock:用于在查询开始处从IR文件中编译并解析已写好的IR函数。
CriticalCacheBuildLock:用于从共享或者本地缓存初始化文件中加载cache的场景。
WaitCountHashLock:用于保护用户语句计数功能场景中的共享结构。
BufMappingLock:用于保护对共享缓冲映射表的操作。
LockMgrLock:用于保护常规锁结构信息。
PredicateLockMgrLock:用于保护可串行事务锁结构信息。
OperatorRealTLock:用于避免并发访问或者修改记录算子级实时数据的全局结构。
OperatorHistLock:用于避免并发访问或者修改记录算子级历史数据的全局结构。
SessionRealTLock:用于避免并发访问或者修改记录query级实时数据的全局结构。
SessionHistLock:用于避免并发访问或者修改记录query级历史数据的全局结构。
CacheSlotMappingLock:用于保护CU Cache全局信息。
BarrierLock:用于保证当前只有一个线程在创建Barrier。
dummyServerInfoCacheLock:用于保护缓存加速openGauss连接信息的全局哈希表。
RPNumberLock:用于加速openGauss的数据库节点对正在执行计划的任务线程的计数。
ClusterRPLock:用于加速openGauss的CCN中维护的openGauss负载数据的并发存取控制。
CBMParseXlogLock:Cbm 解析xlog时的保护锁
RelfilenodeReuseLock:避免错误地取消已重用的列属性文件的链接。
RcvWriteLock:防止并发调用WalDataRcvWrite。
PercentileLock:用于保护全局PercentileBuffer
CSNBufMappingLock:保护csn页面
UniqueSQLMappingLock:用于保护uniquesql hash table
DelayDDLLock:防止并发ddl。
CLOG Ctl:用于避免并发访问或者修改Clog控制数据结构
Async Ctl:保护Async buffer
MultiXactOffset Ctl:保护MultiXact offet的slru buffer
MultiXactMember Ctl:保护MultiXact member的slrubuffer
OldSerXid SLRU Ctl:保护old xids的slru buffer
ReplicationSlotLock:用于保护ReplicationSlot
PGPROCLock:用于保护pgproc
MetaCacheLock:用于保护MetaCache
DataCacheLock:用于保护datacache
InstrUserLock:用于保护InstrUserHTAB。
BadBlockStatHashLock:用于保护global_bad_block_stat hash表。
BufFreelistLock:用于保证共享缓冲区空闲列表操作的原子性。
CUSlotListLock:用于控制列存缓冲区槽位的并发操作。
AddinShmemInitLock:保护共享内存对象的初始化。
AlterPortLock:保护协调节点更改注册端口号的操作。
FdwPartitionCaheLock:HDFS分区表缓冲区的管理锁。
DfsConnectorCacheLock:DFSConnector缓冲区的管理锁。
DfsSpaceCacheLock:HDFS表空间管理缓冲区的管理锁。
FullBuildXlogCopyStartPtrLock:用于保护全量Build中Xlog拷贝的操作。
DfsUserLoginLock:用于HDFS用户登录以及认证。
LogicalReplicationSlotPersistentDataLock:用于保护逻辑复制过程中复制槽位的数据。
WorkloadSessionInfoLock:保护负载管理session info内存hash表访问。
InstrWorkloadLock:保护负载管理统计信息的内存hash表访问。
PgfdwLock:用于管理实例向Foreign server建立连接。
InstanceTimeLock:用于获取实例中会话的时间信息。
XlogRemoveSegLock:保护Xlog段文件的回收操作。
DnUsedSpaceHashLock:用于更新会话对应的空间使用信息。
CsnMinLock:用于计算CSNmin。
GPCCommitLock:用于保护全局Plan Cache hash表的添加操作。
GPCClearLock:用于保护全局Plan Cache hash表的清除操作。
GPCTimelineLock:用于保护全局Plan Cache hash表检查Timeline的操作。
TsTagsCacheLock:用于时序tag缓存管理。
InstanceRealTLock:用于保护共享实例统计信息hash表的更新操作。
CLogBufMappingLock:用于提交日志缓存管理。
GPCMappingLock:用于全局Plan Cache缓存管理。
GPCPrepareMappingLock:用于全局Plan Cache缓存管理。
BufferIOLock:保护共享缓冲区页面的IO操作。
BufferContentLock:保护共享缓冲区页面内容的读取、修改。
CSNLOG Ctl:用于CSN日志管理。
DoubleWriteLock:用于双写的管理操作。
RowPageReplicationLock:用于管理行存储的数据页复制。
extension:其他轻量锁
3)IO等待事件列表
当Type值为IO_EVENT时对应的wait_event等待事件类型即为IO等待事件。BufFileRead:从临时文件中读取数据到指定buffer。
BufFileWrite:向临时文件中写入指定buffer中的内容。
ControlFileRead:读取pg_control文件。主要在数据库启动、执行checkpoint和主备校验过程中发生。
ControlFileSync:将pg_control文件持久化到磁盘。数据库初始化时发生。
ControlFileSyncUpdate:将pg_control文件持久化到磁盘。主要在数据库启动、执行checkpoint和主备校验过程中发生。
ControlFileWrite:写入pg_control文件。数据库初始化时发生。
ControlFileWriteUpdate:更新pg_control文件。主要在数据库启动、执行checkpoint和主备校验过程中发生。
CopyFileRead:copy文件时读取文件内容。
CopyFileWrite:copy文件时写入文件内容。
DataFileExtend:扩展文件时向文件写入内容。
DataFileFlush:将表数据文件持久化到磁盘
DataFileImmediateSync:将表数据文件立即持久化到磁盘。
DataFilePrefetch:异步读取表数据文件。
DataFileRead:同步读取表数据文件。
DataFileSync:将表数据文件的修改持久化到磁盘。
DataFileTruncate:表数据文件truncate。
DataFileWrite:向表数据文件写入内容。
LockFileAddToDataDirRead:读取”postmaster.pid”文件。
LockFileAddToDataDirSync:将”postmaster.pid”内容持久化到磁盘。
LockFileAddToDataDirWrite:将pid信息写到”postmaster.pid”文件。
LockFileCreateRead:读取LockFile文件”%s.lock”。
LockFileCreateSync:将LockFile文件”%s.lock”内容持久化到磁盘。
LockFileCreateWRITE:将pid信息写到LockFile文件”%s.lock”。
RelationMapRead:读取系统表到存储位置之间的映射文件
RelationMapSync:将系统表到存储位置之间的映射文件持久化到磁盘。
RelationMapWrite:写入系统表到存储位置之间的映射文件。
ReplicationSlotRead:读取流复制槽文件。重新启动时发生。
ReplicationSlotRestoreSync:将流复制槽文件持久化到磁盘。重新启动时发生。
ReplicationSlotSync:checkpoint时将流复制槽临时文件持久化到磁盘。
ReplicationSlotWrite:checkpoint时写流复制槽临时文件。SLRUFlushSync:
将pg_clog、pg_subtrans和pg_multixact文件持久化到磁盘。主要在执行checkpoint和数据库停机时发生。SLRURead:读取pg_clog、pg_subtrans和pg_multixact文件。SLRUSync:
将脏页写入文件pg_clog、pg_subtrans和pg_multixact并持久化到磁盘。主要在执行checkpoint和数据库停机时发生。SLRUWrite:写入pg_clog、pg_subtrans和pg_multixact文件。
TimelineHistoryRead:读取timeline history文件。在数据库启动时发生。
TimelineHistorySync:将timeline history文件持久化到磁盘。在数据库启动时发生。
TimelineHistoryWrite:写入timeline history文件。在数据库启动时发生。
TwophaseFileRead:读取pg_twophase文件。在两阶段事务提交、两阶段事务恢复时发生。
TwophaseFileSync:将pg_twophase文件持久化到磁盘。在两阶段事务提交、两阶段事务恢复时发生。
TwophaseFileWrite:写入pg_twophase文件。在两阶段事务提交、两阶段事务恢复时发生。
WALBootstrapSync:将初始化的WAL文件持久化到磁盘。在数据库初始化发生。
WALBootstrapWrite:写入初始化的WAL文件。在数据库初始化发生。
WALCopyRead:读取已存在的WAL文件并进行复制时产生的读操作。在执行归档恢复完后发生。
WALCopySync:将复制的WAL文件持久化到磁盘。在执行归档恢复完后发生。
WALCopyWrite:读取已存在WAL文件并进行复制时产生的写操作。在执行归档恢复完后发生。
WALInitSync:将新初始化的WAL文件持久化磁盘。在日志回收或写日志时发生。
WALInitWrite:将新创建的WAL文件初始化为0。在日志回收或写日志时发生。
WALRead:从xlog日志读取数据。两阶段文件redo相关的操作产生。
WALSyncMethodAssign:将当前打开的所有WAL文件持久化到磁盘。
WALWrite:写入WAL文件。
WALBufferAccess:WAL Buffer访问(出于性能考虑,内核代码里只统计访问次数,未统计其访问耗时)。
WALBufferFull:WAL Buffer满时,写wal文件相关的处理。
DoubleWriteFileRead:双写文件读取。
DoubleWriteFileSync:双写文件强制刷盘。
DoubleWriteFileWrite:双写文件写入。
PredoProcessPending:并行日志回放中当前记录回放等待其它记录回放完成。
PredoApply:并行日志回放中等待当前工作线程等待其他线程回放至本线程LSN。
DisableConnectFileRead:HA锁分片逻辑文件读取。
DisableConnectFileSync:HA锁分片逻辑文件强制刷盘。
DisableConnectFileWrite:HA锁分片逻辑文件写入
4)事务锁等待事件列表
当wait_status值为LOCK_EVENT(事务锁)时对应的wait_event等待事件类型为事务锁等待事件。
relation:对表加锁
extend:对表扩展空间时加锁
partition:对分区表加锁
partition_seq:对分区表的分区加锁
page:对表页面加锁
tuple:对页面上的tuple加锁
transactionid:对事务ID加锁
virtualxid:对虚拟事务ID加锁
object:加对象锁
cstore_freespace:对列存空闲空间加锁
userlock:加用户锁
advisory:加advisory锁
📣 4.4 等待类型统计

这一部分按照等待类型(STATUS、IO_EVENT、LWLOCK_EVENT、LOCK_EVENT),分类统计等待次数、总等待时间、平均等待时间。
📣 4.5 CPU负载

这一部分主机CPU的负载情况:CPU的平均负载、用户使用占比、系统使用占比、IO等待占比、空闲占比
📣 4.6 IO负载

这一部分描述了openGauss在快照期间的IO负载情况。
Database requests: 即每秒IO请求次数,包括请求次数总和、读请求次数、写请求次数.
Database(blocks): 即每秒block请求数量,包含请求的block总和数量、读block的数量和写block的数量.
Database(MB): 即将block换算成容量(MB)[如:blocks * 8/1024],增加数据的可读性。
Redo requests和Redo(MB) 分别表示每秒redo的写请求次数和redo写的数据量
📣 4.7 内存统计


这一部分描述了节点内存的变化信息,通过这些变化信息,我们可以了解到在两次快照期间,数据库的内存变化情况,作为数据库性能分析或异常分析的参考。
数据来源于snapshot.snap_global_memory_node_detail。
这部分分别描述了: 内存的类型 以及 对应的起始大小和终止大小。
注:请确保disable_memory_protect=on才可以,测试环境内存太小,导致启动时将memory protect关闭了

📣 4.8 time model
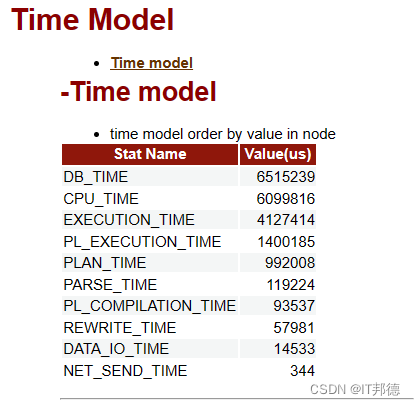
这一部分描述了数据库各种状态所消耗的时间,关于Stat Name的解释如下

📣 4.9 SQL Statistics
这一部分分别从SQL执行时间、SQL消耗CPU的时间、SQL返回的行数、SQL扫描的行数、SQL执行的次数、SQL物理读的次数、SQL逻辑读的次数等多维度对两次快照期间的SQL执行情况进行统计。


📣 4.10 Wait Events
这一部分分别从等待时长、等待次数这两个维度对等待事件进行统计。


📣 4.11 Cache IO Stats
这一部分根据Heap block的命中率排序统计用户表的IO活动状态。

数据来源于snapshot.snap_global_statio_all_indexes表和snapshot.snap_global_statio_all_tables表。
该表相关列的介绍如下:

📣 4.12 Object stats
这一部分描述用户表状态的统计信息,数据源于snapshot.snap_global_stat_all_tables表。

这一部分描述用户索引状态的统计信息,数据源于snapshot.snap_global_stat_all_indexes表。

这一部分描述坏块的统计信息,数据源于snapshot.snap_global_stat_bad_block表。

这一部分描述的是数据库参数配置信息,数据源于snapshot.snap_global_config_settings表。



相关文章:
【openGauss实战11】性能报告WDR深度解读
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Vue3实现打字机效果
typeit 介绍 typeit是一款轻量级打字机特效插件。该打印机特效可以设置打字速度,是否显示光标,是否换行和延迟时间等属性,它可以打印单行文本和多行文本,并具有可缩放、响应式等特点。官方文档 安装 # npm npm install typeit # …...

maven无法依赖spring-cloud-stater-zipkin如何解决?
当 Maven 无法依赖 spring-cloud-starter-zipkin 时,您可以尝试以下方法解决: 确保拼写正确:请检查项目中的 pom.xml 文件,确保依赖的拼写正确。正确的依赖名称应为:spring-cloud-starter-zipkin。添加 Spring Cloud …...

实战踩坑---MFC---CreateEvent
使用事件CreateEvent注意事项 HANDLECreateEvent( LPSECURITY_ATTRIBUTESlpEventAttributes,// 安全属性 BOOLbManualReset,// 复位方式 BOOLbInitialState,// 初始状态 LPCTSTRlpName // 对象名称 );[1] 参数 lpEventAttributes[输入] 一个指向SECURITY_ATTRIBUTES结构…...

JavaWeb学习------jQuery
JavaWeb学习------jQuery jQuery函数库下载 jQuery函数库下载官网:Download jQuery | jQuery配套资料,免费下载 链接:https://pan.baidu.com/s/1aXBfItEYG4uM53u6PUEMTg 提取码:6c9i 然后下载? 来到官网…...

米哈游测开岗 【一面总结】
目录 1.黑盒测试与白盒测试的区别 2.测试一个下单功能 3.get与post的区别 4.一次get请求产生几个数据包 5.常用的linux命令 6.进程与线程的区别 7.数据库查询如何去重 8.MySql怎么连接两张表,有什么区别 9.说说索引 10.cookie 和 session 的区别 (会话管…...

微服务 Spring Boot 整合Redis 实现优惠卷秒杀 一人一单
文章目录 一、什么是全局唯一ID ⛅全局唯一ID ⚡Redis实现全局唯一ID 二、环境准备 三、实现秒杀下单 四、库存超卖问题 ⏳问题分析 ⌚ 乐观锁解决库存超卖 ✅Jmeter 测试 五、优惠卷秒杀 实现一人一单 ⛵小结 一、什么是全局唯一ID ⛅全局唯一ID 在分布式系统中,经常需要使用…...
构建OVS网络
构建OVS网络 1. 配置虚拟机环境 (1)配置虚拟机交换机 1 创建一个名为br-xd的虚拟交换机。 # ovs-vsctl add-br br-xd 2 查询虚拟交换机。 # ovs-vsctl show 5a1cd870-fc31-4820-a7f4-b75c19450582 Bridge br-xd Port br-xd …...

【Python】万能之王 Lambda 函数详解
Python 提供了非常多的库和内置函数。有不同的方法可以执行相同的任务,而在 Python 中,有个万能之王函数:lambda 函数,它可以以不同的方式在任何地方使用。今天云朵君将和大家一起研究下这个万能之王! Lambda 函数简介…...

手把手教你怎么搭建自己的AI数字人直播间?帮你24小时不间断直播卖货
在搭建AI数字人直播间之前,您需要了解数字人技术。 一、什么是AI数字人、数字人直播间? 数字人是一种由人工智能技术构建的虚拟人物,其外貌、行为、语言等特征与真实人物相似,可以与人进行互动。数字人可以通过语音合成、人脸识…...
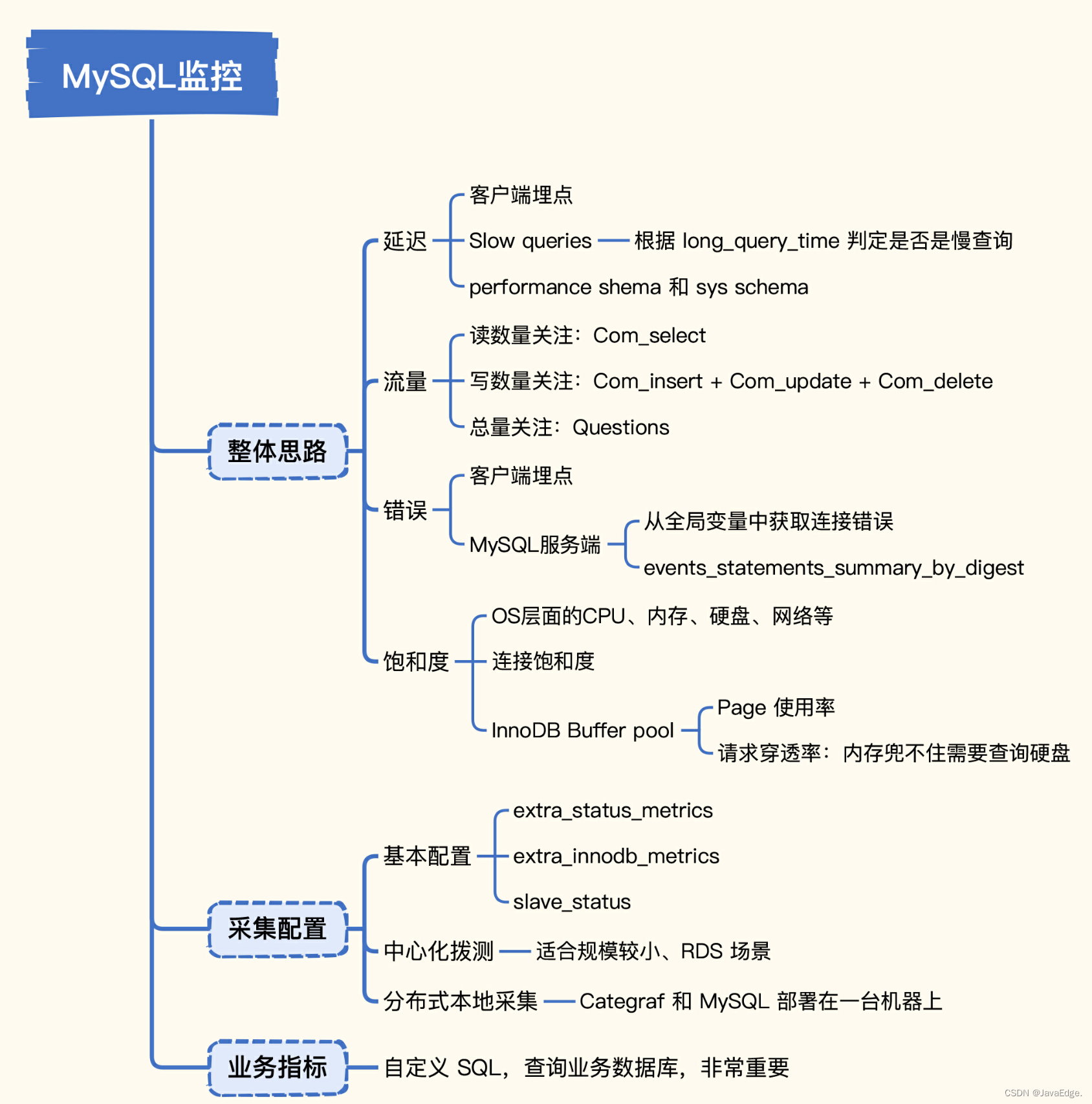
MySQL性能监控全掌握,快来get关键指标及采集方法!
数据库中间件监控实战,MySQL中哪些指标比较关键以及如何采集这些指标了。帮助提早发现问题,提升数据库可用性。 1 整体思路 监控哪类指标? 如何采集数据? 第10讲监控方法论如何落地? 这些就可以在MySQL中应用起来。…...
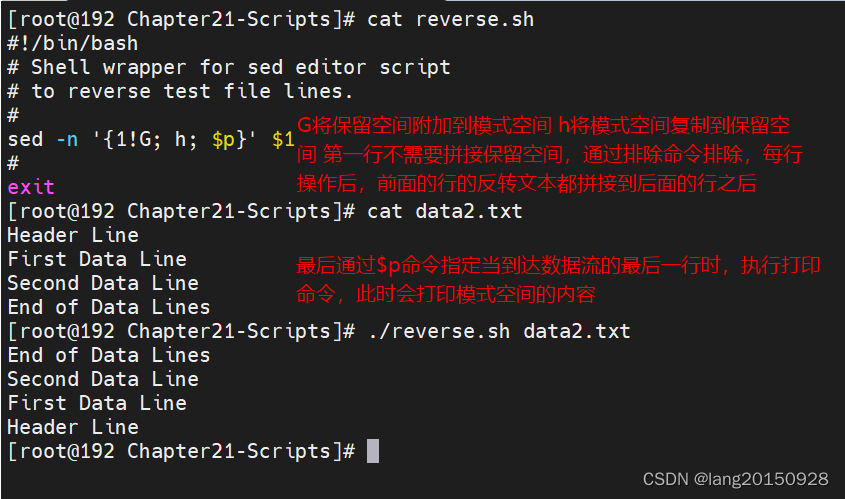
sed进阶之保留空间和排除命令
shell脚本编程系列 保留空间 模式空间(pattern space)是一块活跃的缓冲区,在sed编辑器执行命令时保存着待检查的文本,但它并不是sed编辑器保存文本的唯一空间。sed编辑器还有另一块称作保留空间(hold space࿰…...

21安徽练习
题目分为4部分 APK 集群 流量 exe 我尽量都做一下,逆向不是很会,就当提升自己。 [填空题]请获取app安装包的SHA256校验值(格式:不区分大小写)(10分) e15095d49efdccb0ca9b2ee125e4d8136cac5…...

【VAR | 时间序列】应用VAR模型时的15个注意点
一、前言 向量自回归(VAR,Vector Auto regression)常用于预测相互联系的时间序列系统以及分析随机扰动对变量系统的动态影响。 VAR方法通过把系统中每一个内生变量,作为系统中所有内生变量的滞后值的函数来构造模型,从而回避了结构化模型的…...

校招在线测评题目汇总
图形找规律题 https://blog.csdn.net/mxj1428295019/article/details/129627461https://blog.csdn.net/Yujian2563/article/details/124266574?spm1001.2101.3001.6650.2&utm_mediumdistribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-124266574-blo…...

『python爬虫』05. requests模块入门(保姆级图文)
目录 安装requests1. 抓取搜狗搜索内容 requests.get2. 抓取百度翻译数据 requests.post3. 豆瓣电影喜剧榜首爬取4. 关于请求头和关闭request连接总结 欢迎关注 『python爬虫』 专栏,持续更新中 欢迎关注 『python爬虫』 专栏,持续更新中 安装requests …...

WPF超好用的框架Prism入门使用,上位机赶紧学起来!
Prism简介 WPF框架Prism是一种用于开发模块化、可重用和可测试的WPF应用程序的框架。它提供了一种简单而强大的方式来管理复杂应用程序的代码和构建高度可扩展的应用程序。 如何学习Prism框架 如果您想使用Prism框架来开发WPF应用程序,需要学习以下几个方面&…...

十个机器学习应用实例
一、在Kaggle上举办的一个竞赛,名为“Tabular Playground Series - Aug 2021”。该竞赛旨在预测房屋销售价格,数据集包含了79个特征和一个目标变量。参赛者需要训练一个模型,能够预测测试集中房屋的销售价格。 该竞赛的获胜者使用了多个AI模型…...

【Redis17】Redis进阶:管道
Redis进阶:管道 管道是啥?我们做开发的同学们经常会在 Linux 环境中用到管道命令,比如 ps -ef | grep php 。在之前学习 Laravel框架时的 【Laravel6.4】管道过滤器https://mp.weixin.qq.com/s/CK-mcinYpWCIv9CsvUNR7w 这篇文章中,…...
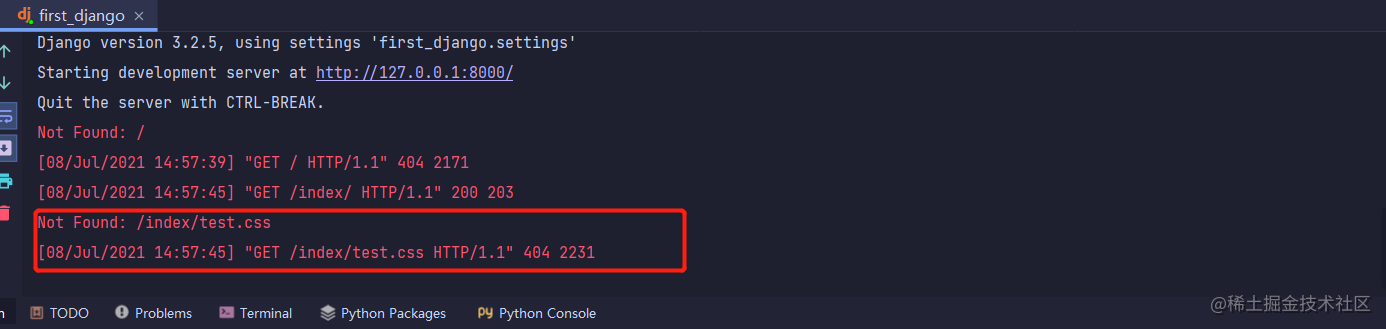
Django项目页面样式如何“传给”客户端浏览器
前言 django项目在视图函数中借助render函数可以返回HTML页面,但是HTML页面中如果引入了外部CSS文件或者JavaScript文件在浏览器页面无法加载,因此就必须有一种方式能够将HTML文档中引入的外部文件能够在客户端浏览器上加载,这种方式就是配置…...
)
二叉树(中南大学)
二叉树的先序序列 查看题解 查看答案 题目描述 Time Limit: 1000 ms Memory Limit: 256 mb 已知二叉树的中序和先序遍历可以唯一确定后序遍历、已知中序和后序遍历可以唯一确定先序遍历,但已知先序和后序,却不一定能唯一确定中序遍历。现要求根据输入…...

Subfinder扩展开发终极指南:从零构建高级子域名发现模块
Subfinder扩展开发终极指南:从零构建高级子域名发现模块 【免费下载链接】subfinder 项目地址: https://gitcode.com/gh_mirrors/subf/subfinder Subfinder是一款功能强大的子域名发现工具,能够帮助安全研究人员和开发者快速枚举目标域名下的子域…...

pkgcloud存储服务实战:跨云平台文件上传下载最佳实践
pkgcloud存储服务实战:跨云平台文件上传下载最佳实践 【免费下载链接】pkgcloud pkgcloud is a standard library for node.js that abstracts away differences among multiple cloud providers. 项目地址: https://gitcode.com/gh_mirrors/pk/pkgcloud 在当…...

Citra模拟器终极指南:5个技巧让你的3DS游戏在电脑上飞起来
Citra模拟器终极指南:5个技巧让你的3DS游戏在电脑上飞起来 【免费下载链接】citra 项目地址: https://gitcode.com/GitHub_Trending/ci/citra Citra是一款强大的任天堂3DS模拟器,让玩家能够在电脑上流畅体验3DS游戏。本指南将分享5个实用技巧&am…...

单片机—STM32中:关于寄存器
首先需了解:计算机系统五大组成部分:运算器,控制器,存储器,输入设备,输出设备。其中存储器分为内存(ROM),外设(RAM)。寄存器是连接软件和硬件的桥梁;软件读写…...

COMSOL 数值模拟助力 N₂ 和 CO₂ 混合气体增强瓦斯抽采
COMSOL数值模拟,实现N2和CO2混合气体在THM热流固三场耦合情况下增强瓦斯(煤层气抽采)在煤层气抽采领域,如何高效地将瓦斯从煤层中抽采出来一直是研究的重点。近年来,利用 N₂ 和 CO₂ 混合气体在 THM(热 - …...

第3章 矩阵:系统、变换与结构的表达
底层数学四部曲第四部 线性代数:入门与全领域展开 第3章 矩阵:系统、变换与结构的表达 矩阵的本质,是线性关系的“容器”,是向量变换的“规则”,是复杂系统的“浓缩表达”。 上一章我们掌握了向量——线性世界的基本单…...

DeepChat一文详解:Ollama REST API与DeepChat前端通信的WebSocket心跳与流式响应机制
DeepChat一文详解:Ollama REST API与DeepChat前端通信的WebSocket心跳与流式响应机制 1. DeepChat是什么:一个真正私有的深度对话空间 你有没有想过,和AI聊天时,自己的问题、思考、甚至那些还没成型的想法,会不会悄悄…...

SenseVoice-Small ONNX模型部署:Ubuntu 20.04服务器环境保姆级教程
SenseVoice-Small ONNX模型部署:Ubuntu 20.04服务器环境保姆级教程 最近在折腾语音相关的AI应用,发现了一个挺有意思的模型叫SenseVoice-Small。它是个轻量级的语音识别模型,支持多种语言,而且推理速度挺快。最关键的是ÿ…...
)
从HippoRAG到MemOS:LLM记忆管理技术演进史(含开源工具对比表)
从HippoRAG到MemOS:LLM记忆管理技术演进史 当ChatGPT在2022年底掀起生成式AI的浪潮时,大多数用户惊叹于其流畅的对话能力,却很少人注意到一个关键问题:这些看似"聪明"的对话机器人,实际上患有严重的"健…...