Mysql 学习(八)单表查询方法二
复杂查询
- 上一节说了5种访问类型的查询,这一节就来说说关于这些比较复杂的查询
情况一:多个二级索引查询
- sql:
SELECT * FROM index_value_table WHERE value1 = 'abc' AND value2 > 1000; - 搜索条件:
- value1 等于 abc
- value2 大于 1000
- 我们知道一般情况下,搜索条件会根据单个二级索引进行查询,所以优化器一般会根据 表的统计数据来判断使用哪个搜索条件来进行二级索引。上面这个例子,我们正常情况下会选择 value1 = abc ,因为获取到列最少,在回表的时候可以遍历更少的列来判断另一个搜索条件,步骤可以分为下面两步:
- 使用二级索引定位记录的阶段,也就是根据条件value1 = 'abc’从idx_key1索引代表的B+树中找到对应的二级索引记录。
- 回表阶段,也就是根据上一步骤中找到的记录的主键值进行回表操作,也就是到聚簇索引中找到对应的完整的用户记录,再根据条件value2 > 1000到完整的用户记录继续过滤。将最终符合过滤条件的记录返回给用户。
情况二:多个range访问
- 这个情况有很多种复杂场景,这个时候我们需要了解一下 range访问方法的使用范围区间
- 对于B+树索引来说,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以写成<>)或者LIKE操作符连接起来,就可以产生一个所谓的区间。
- 对于复杂查询来说,一个查询的where子句有多个小的搜索条件,这些搜索条件都是使用 and 或者 or 连接起来的,而我们想要使用range访问方法执行的话,就需要找出该查询可用的索引中正确的范围区间
- 这里需要普及一个小知识:
- 条件1 AND 条件2:只有当 条件1 和 条件2 都为TRUE时整个表达式才为TRUE
- 条件1 OR 条件2:只要 条件1 或者 条件2 中有一个为TRUE整个表达式就为TRUE
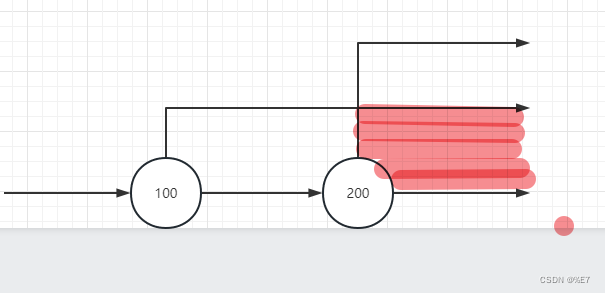
多个range访问 一:所有搜索条件都可以使用某个索引的情况
- sql:
SELECT * FROM index_value_table WHERE value2 > 100 AND value2 > 200; - 搜索条件:
- value2 大于 100
- value2 大于 200
- 因为是and 所以两个查询条件需要取交集,刚好两个查询条件都可以用到 value2 这个索引列,所以我们的查询条件就可以变成 value2 >= 200
- sql:
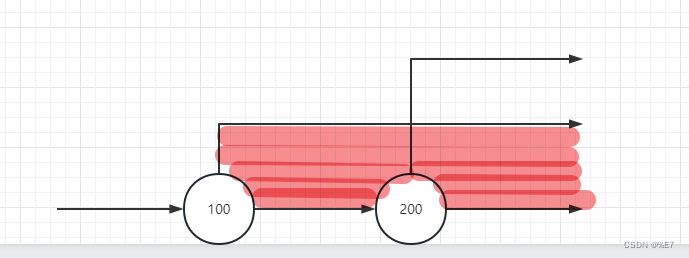
SELECT * FROM index_value_table WHERE value2 > 100 OR value2 > 200; - 搜索条件:
- value2 大于 100
- value2 大于 200
- 因为是OR所以两个查询条件需要取并集,刚好两个查询条件都可以用到 value2 这个索引列,所以我们的查询条件就可以变成 value2 >100
多个range访问 二:有的搜索条件无法使用索引的情况
-
sql:
SELECT * FROM index_value_table WHERE value2 > 100 AND common_field = 'abc'; -
搜索条件:
- value2 大于 100
- common_field 等于 abc
-
因为 能用索引的搜索条件是 value2 ,但是 在二级索引树里面没有 common_field 这个字段,所以我们只能先更具 value2 大于 100的条件从二级索引树中找出来,回表的时候再判断 common_field 是否是 abc 。所以我们在确定范围区间的时候不需要考虑没有相关索引的搜索条件,把这个条件替换成true就可以了,变化如下:
SELECT * FROM index_value_table WHERE value2 > 100 AND true,化简一下:SELECT * FROM index_value_table WHERE value2 > 100 -
sql :
SELECT * FROM index_value_table WHERE value2 > 100 ORcommon_field = 'abc'; -
搜索条件:
- value2 大于 100
- common_field 等于 abc
-
这个跟上面一个例子的区别就是 and和or的区别,这里如果把 common_field 查询条件变成true 的话 ,查询条件就会变成
value2 > 100 OR TRUE,化简一下就变成 ture了,所以直接变成扫描全表的,所以如果一个使用到索引的搜索条件和没有使用该索引的搜索条件使用OR连接起来后是无法使用该索引的。
多个range访问 三:复杂搜索条件下找出范围匹配的区间
- sql:
SELECT * FROM index_value_table WHERE (value1 > 'xyz' AND value2 = 748 ) OR (value1 < 'abc' AND value1 > 'lmn') OR (value1 LIKE '%suf' AND value1 > 'zzz' AND (value2 < 8000 OR common_field = 'abc')) ; - 查询条件:
- value1 大于 xyz 且 value2 等于 748
- value1 小于 abc 且 value2 大于 lmn
- value1 类似 后缀为 suf 且 value1 大于 zzz 且 ( value2 小于 8000 或者 common_field 等于 abc )
- 这个查询真的,很复杂,优化器会怎么优化这种查询呢,我们先来看看有几个索引列,value1 对应的 idx_key1,value2 对应的 idx_key2,一般都会采用单个二级索引,所以我们把 idx_key1 和 idx_key2 分开看
- 先看 idx_key1 执行查询,把二级索引用不到字段查询替换成true 进行化简
- 替换之后:
(value1 > 'xyz' AND true ) OR (value1 < 'abc' AND value1 > 'lmn') OR (true AND value1 > 'zzz' AND (true OR true)) ;- 化简之后:
value1 > 'xyz' OR (value1 < 'abc' AND value1 > 'lmn') OR value1 > 'zzz'; - 因为 value1 < ‘abc’ and value1 > ‘lmn’ 按照字符集比较规则,这个条件根本不可能生效,所以 继续化简:
value1 > 'xyz' OR value1 > 'zzz'; - 剩下因为 OR 操作符,需要取并集,最终化简:
value1 > 'xyz' - 化简完之后,我们根据这个进行二级索引查询,然后在回表的时候进行其他非这个索引的查询
- 化简之后:
- 替换之后:
- 我们再来看 idx_key2 执行查询
- 我们需要把那些用不到该索引的搜索条件暂时使用TRUE条件替换掉,其中有关value1和common_field的搜索条件都需要被替换掉,替换结果就是:
(true AND value2 = 748 ) OR (true AND value2 = 748) OR (true AND true AND (value2 < 8000 OR true)) ; - 在化简就变成
value2 = 748 OR TRUE - 然后再化简就变成
true - 意思就是如果要使用idx_key2索引查询语句的话,就需要扫描所有记录
- 我们需要把那些用不到该索引的搜索条件暂时使用TRUE条件替换掉,其中有关value1和common_field的搜索条件都需要被替换掉,替换结果就是:
情况三:索引合并
- 一般情况下,mysql执行一个查询的时候只会用到单个二级索引或者聚簇索引,但还是有特殊情况,可能会用到多个二级索引,而这种用到多个二级索引的查询叫做索引合并。
- 索引合并的算法主要有三种:
- Intersection合并:交集合并
- Union合并
- Sort-Union合并
Intersection合并:交集合并
- 什么是Intersection合并?
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' AND value3 = 'b'; - 执行过程是这样的:
- 从idx_key1二级索引对应的B+树中取出value1 = 'a’的相关记录
- 从idx_key3二级索引对应的B+树中取出value3 = 'b’的相关记录
- 计算得出两个结果集中的主键值交集
- 通过得到的结果集进行回表找到对应的记录
- Intersection 合并 就是 某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取交集
- 举个例子:
- 为什么会有Intersection合并?
- 从上面的例子可以看出来,我们完全可以选择其中一个二级索引查找,然后通过回表的时候过滤掉另一个条件,为什么不这么做呢?
- 这里就需要分析一下 两种方式所对应的成本代价
- 只读一个二级索引的成本:
- 按照某个搜索条件读取一个二级索引
- 回表 过滤
- 读取多个二级索引之后取交集成本:
- 按照不同的搜索条件分别读取不同的二级索引
- 将从多个二级索引得到的主键值取交集,然后进行回表操作
- 只读一个二级索引的成本:
- 虽然读取多个二级索引比读取一个二级索引消耗性能,但是读取二级索引的操作是顺序I/O,而回表操作是随机I/O,所以如果只读取一个二级索引时需要回表的记录数特别多,而读取多个二级索引之后取交集的记录数非常少,当节省的因为回表而造成的性能损耗比访问多个二级索引带来的性能损耗更高时,读取多个二级索引后取交集比只读取一个二级索引的成本更低。
- 所以 MySQL只会在某些特定的情况下才可能使用到 Intersection索引合并
- 什么情况会使用Intersection合并?
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' AND value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c'; - 为什么这种情况可以?
- 答案是因为,二级索引树,你通过等值查找的时候,会获取很多条记录,只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的,所以你得到两个主键的结果集都是由小到大进行排序的,然后通过一定的算法可以将对应的交集算出来,这种速度是很快的。
- 求交集的方法:
- 假设 从idx_key1中获取到已经排好序的主键值:1、3、5
- 假设从idx_key2中获取到已经排好序的主键值:2、3、4
- 那么求交集的过程就是这样:逐个取出这两个结果集中最小的主键值,如果两个值相等,则加入最后的交集结果中,否则丢弃当前较小的主键值,再取该丢弃的主键值所在结果集的后一个主键值来比较,直到某个结果集中的主键值用完了,过程如下:
* 先取出这两个结果集中较小的主键值做比较,因为1 < 2,所以把idx_key1的结果集的主键值1丢弃,取出后边的3来比较。
* 因为3 > 2,所以把idx_key2的结果集的主键值2丢弃,取出后边的3来比较。
* 因为3 = 3,所以把3加入到最后的交集结果中,继续两个结果集后边的主键值来比较。
* 后边的主键值也不相等,所以最后的交集结果中只包含主键值3。
- 求交集的方法:
- 答案是因为,二级索引树,你通过等值查找的时候,会获取很多条记录,只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的,所以你得到两个主键的结果集都是由小到大进行排序的,然后通过一定的算法可以将对应的交集算出来,这种速度是很快的。
- 举个例子:
- 情况二:主键列可以是范围匹配
- 举个例子:
SELECT * FROM index_value_table WHERE id > 100 AND value1 = 'a'; - 为什么这种情况可以?
- 答案还是因为二级索引树,当你通过索引找到对应的主键id时,就已经可以过滤掉不是这个范围的记录了
- 举个例子:
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
- 注意事项:即使情况一、情况二成立,也不一定发生Intersection索引合并,这得看优化器的心情。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数太多,导致回表开销太大,而通过Intersection索引合并后需要回表的记录数大大减少时才会使用Intersection索引合并。
Union合并
- 什么是Union合并?
- Union合并 就是 某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取并集
- 什么情况下会有Union合并?
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' OR ( value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c');
- 举个例子:
- 情况二:主键列可以是范围匹配
- 情况三:使用Intersection索引合并的搜索条件
- 举个例子:
SELECT * FROM index_value_table WHERE value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c' OR (value1 = 'a' AND value3 = 'b');
- 举个例子:
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
- 注意事项:查询条件符合了这些情况也不一定就会采用Union索引合并,也得看优化器的心情。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数比较少,通过Union索引合并后进行访问的代价比全表扫描更小时才会使用Union索引合并。
总结一下
- 索引合并的使用场景:
- 当查询条件中包含多个列时,每个列都有单独的索引,但是MySQL无法使用这些索引进行有效的查询优化。这时,MySQL可以将多个索引合并使用,以便提高查询性能。
- 当查询条件中包含多个列时,每个列都有单独的索引,并且MySQL可以使用这些索引进行有效的查询优化。这时,MySQL可以选择使用索引合并来进一步优化查询性能。
相关文章:
Mysql 学习(八)单表查询方法二
复杂查询 上一节说了5种访问类型的查询,这一节就来说说关于这些比较复杂的查询 情况一:多个二级索引查询 sql:SELECT * FROM index_value_table WHERE value1 abc AND value2 > 1000;搜索条件: value1 等于 abcvalue2 大于…...
安卓系统下的截屏和录屏
可以抓取手机屏幕画面(屏幕截图),也可以录制屏幕画面视频。拍摄屏幕后,可以查看、编辑和分享所拍的图片或视频。 抓取屏幕截图 打开要抓取的屏幕。视手机情况执行下列一个操作,3种方法看你手机有效的: 同…...

行为型模式-中介者模式
中介者模式 概述 一般来说,同事类之间的关系是比较复杂的,多个同事类之间互相关联时,他们之间的关系会呈现为复杂的网状结构,这是一种过度耦合的架构,即不利于类的复用,也不稳定。例如在下左图中…...
-2-领航辅助系统NAP-功能ODD定义)
辅助驾驶功能开发-功能规范篇(16)-2-领航辅助系统NAP-功能ODD定义
1.系统定义 智能驾驶系统包含行车场景功能和泊车场景功能,行车场景功能包括安全ADAS功能、基础ADAS功能和高阶ADAS功能三大类,本文档定义高阶ADAS功能中的导航辅助驾驶功能用例。 1.1.高阶ADAS功能列表 功能需求ID 功能分类 功能名称...
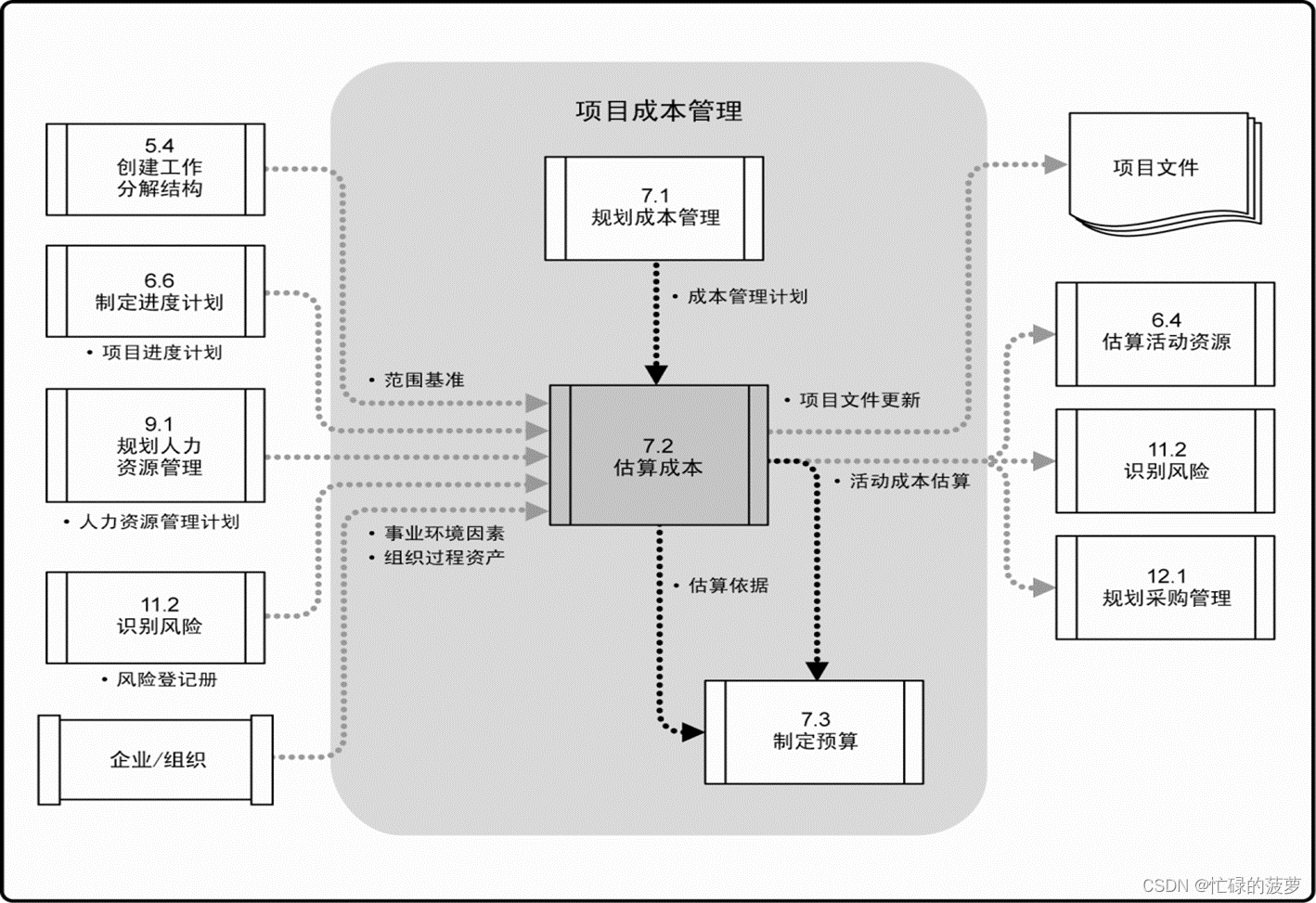
PMP/高项 06-项目成本管理
项目成本管理 概念 项目成本管理 项目成本管理又被称为项目造价管理,是有关项目成本和项目价值两个方面的管理,是为保障以最小的成本实现最大的项目价值而开展的项目专项管理工作。 确保在批准的项目预算内完成项目 成本管理内容 规划成本管理 制定项目…...
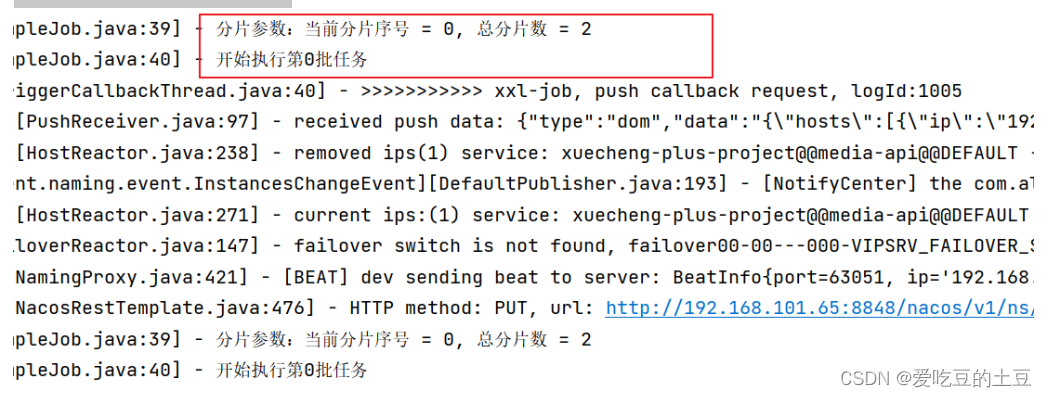
XXL-JOB中间件【实现分布式任务调度】
目录 1:XXL-JOB介绍 2:搭建XXL-JOB 2.1:调度中心 2.2:执行器 2.3:执行任务 3:分片广播 1:XXL-JOB介绍 XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学…...
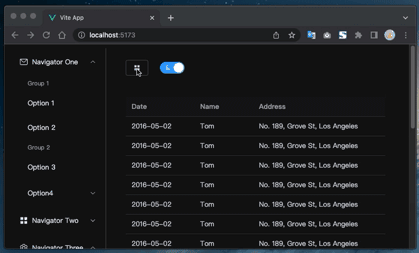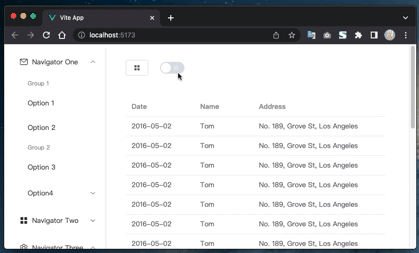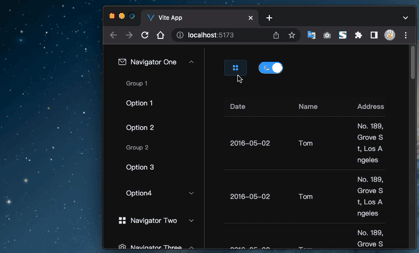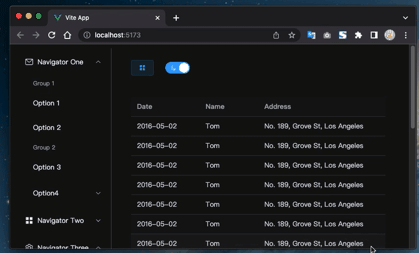
Vue3+Element Plus环境搭建和一键切换明暗主题的配置
Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。而Element Plus是一款基于Vue3面向设计师和开发者的组件库。 最终效果: 环境搭建 已安装 16.0 或更高版本的 Node.js,终端: npm init vuelatest这一…...
Leetcode326. 3 的幂
Every day a leetcode 题目来源:326. 3 的幂 相似题目:342. 4的幂 解法1:递归 代码: /** lc appleetcode.cn id326 langcpp** [326] 3 的幂*/// lc codestart class Solution { public:bool isPowerOfThree(int n){if (n <…...

【运动规划算法项目实战】如何在栅格地图中实现Dijkstra算法
文章目录 简介一、算法介绍1.1 Dijkstra算法流程1.2 Dijkstra算法伪代码二、代码实现2.1 ROS实现2.2 RVIZ演示三、总结简介 Dijkstra算法是一种用于图中单源最短路径的贪心算法。在计算机科学和网络设计中广泛应用。该算法从起点开始,通过优先选择距离起点最近的未标记节点来…...
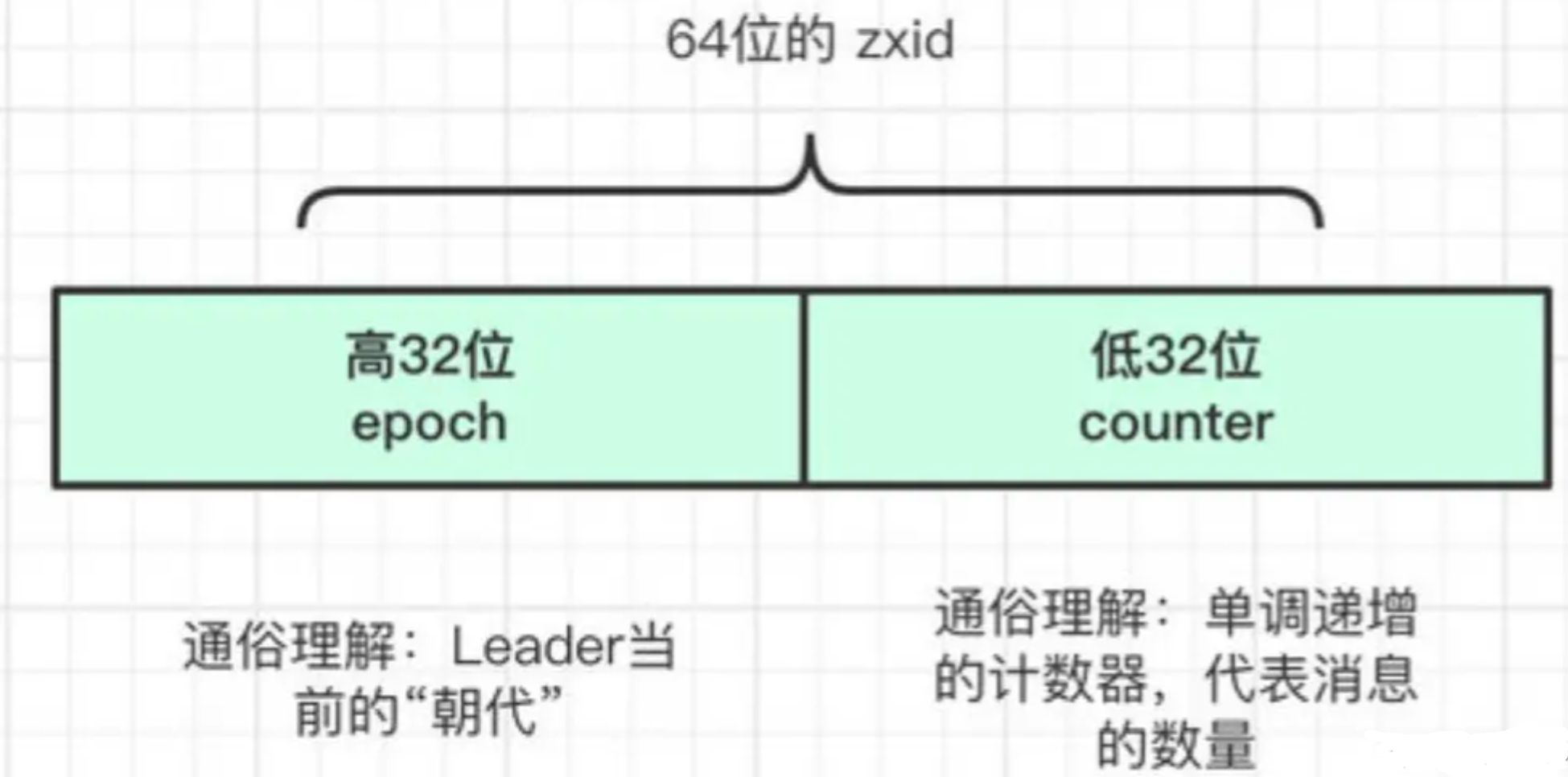
【算法】一文彻底搞懂ZAB算法
文章目录 什么是ZAB 算法?深入ZAB算法1. 消息广播两阶段提交ZAB消息广播过程 2. 崩溃恢复选举参数选举流程 ZAB算法需要解决的两大问题1. 已经被处理的消息不能丢2. 被丢弃的消息不能再次出现 最近需要设计一个分布式系统,需要一个中间件来存储共享的信息…...
【软考高级】2022年系统分析师综合知识
1.( )是从系统的应用领域而不是从系统用户的特定需要中得出的,它们可以是新的功能性需求,或者是对已有功能性需求的约束,或者是陈述特定的计算必须遵守的要求。 A.功能性需求 B. 用户需求 C.产品需求 D.领域需求 2.对于安全关键系…...

关于AI未来的思考和应用场景
关于AI未来的思考和应用场景 AI(人工智能)是当今最热门的技术领域之一,它已经在多个领域产生了深远的影响,如医疗、金融、制造业等。未来,AI将继续发展,并在更多领域产生重要的影响。 AI的未来发展方向有…...
智慧城市规划数字化管理:数字孪生技术的创新应用
随着智能城市的不断发展,数字孪生技术也开始在智慧城市的建设中得到了广泛应用。数字孪生作为一种数字化的复制技术,它可以模拟真实世界中的实体和过程。 在城市规划方面,数字孪生可以帮助城市规划师更加直观地了解城市的整体规划和发展趋势&…...

开心档之C++ 指针
C 指针 学习 C 的指针既简单又有趣。通过指针,可以简化一些 C 编程任务的执行,还有一些任务,如动态内存分配,没有指针是无法执行的。所以,想要成为一名优秀的 C 程序员,学习指针是很有必要的。 正如您所知…...
零基础搭建私人影音媒体平台【远程访问Jellyfin播放器】
文章目录 1. 前言2. Jellyfin服务网站搭建2.1. Jellyfin下载和安装2.2. Jellyfin网页测试 3.本地网页发布3.1 cpolar的安装和注册3.2 Cpolar云端设置3.3 Cpolar本地设置 4.公网访问测试5. 结语 转载自内网穿透工具的文章:零基础搭建私人影音媒体平台【远程访问Jelly…...

Abstract Expressionist
古董地图画集 10大最有名的抽象艺术家 抽象表现主义是现代许多不同艺术思想和表达流派中最奇特的艺术运动之一。这场运动开始从社会变革中涌现出来,恰逢第二次世界大战的最后几周和几个月。 这一次,来自世界各地的人们开始欢迎在经历了多年有史以来最致…...
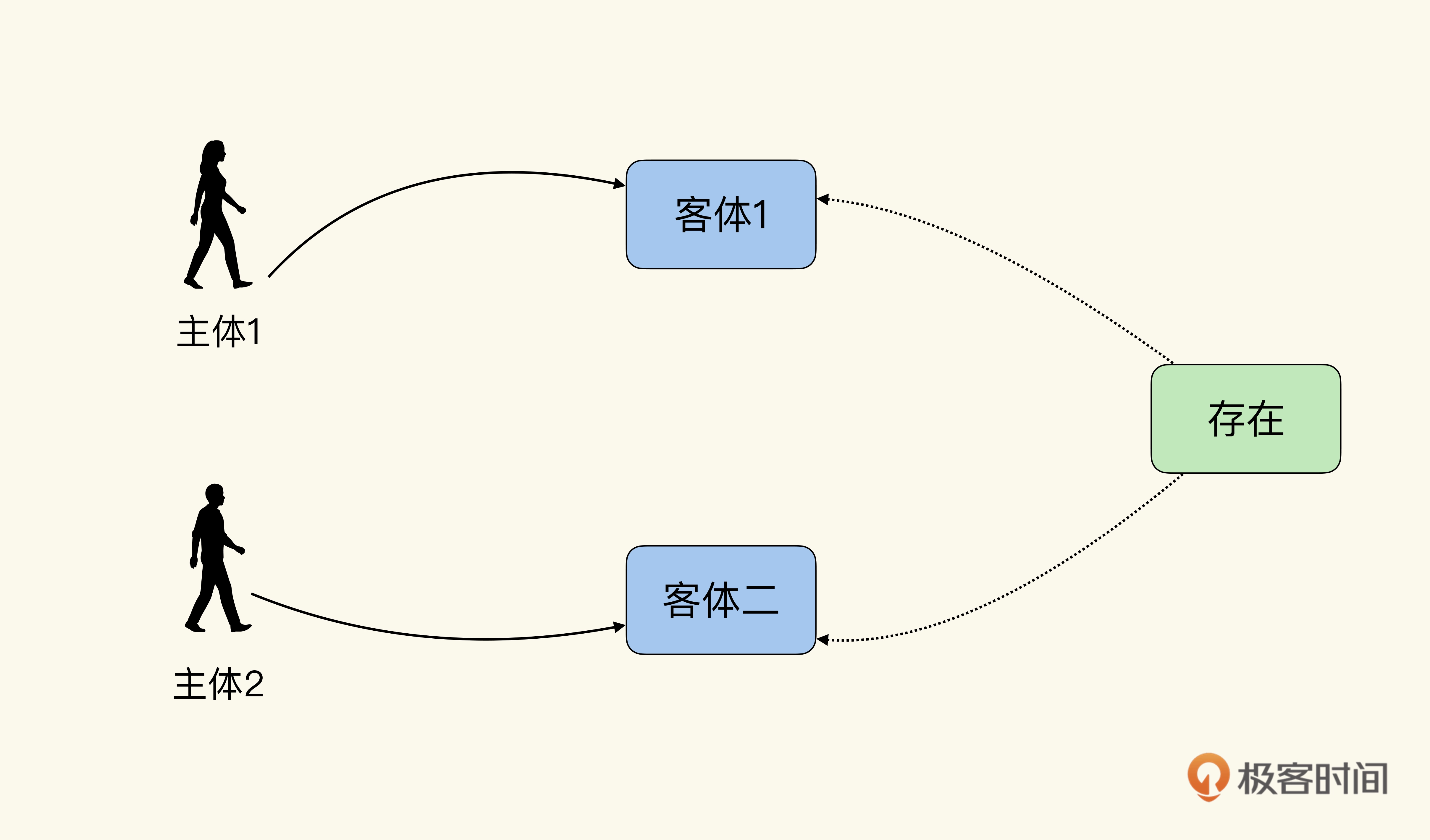
【郭东白架构课 模块二:创造价值】24|节点四:如何减少语义上的分歧?
你好,我是郭东白。上节课我们通过一个篇幅比较长的电商案例,详细展示了为什么在架构活动中会出现语义分歧。同时也描述了,架构师在统一语义这个环节中所要创造的真正价值是什么。即,看到不同角色之间语境的差异,然后通…...

windows下免费本地部署类ChatGpt的国产ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 Chat…...

flask+opencv+实时滤镜(原图、黑白、怀旧、素描)
简介:滤镜,主要是用来实现图像的各种特殊效果。图像滤镜用于改变图像的视觉效果,使其具有特定的风格。下面是这三种滤镜的详细说明: 1、黑白(Grayscale):黑白滤镜将彩色图像转换为灰度图像&…...
计算机算法类SCI,数据库稳定检索19年)
【SCI征稿】极速送审,中科院2区(TOP)计算机算法类SCI,数据库稳定检索19年
算法类: 检索年份:数据库稳定检索19年 自引率:14.50% 国人占比:22.78% 期刊简介:IF:8.0-9.0,JCR1区,中科院2区(TOP) 检索情况:SCI&EI 双…...
)
STM32F407实战:手把手教你搞定永磁同步电机FOC电流环(附示波器调试避坑指南)
STM32F407实战:永磁同步电机FOC电流环深度优化与示波器调试全攻略 在电机控制领域,永磁同步电机(PMSM)的磁场定向控制(FOC)一直是工程师们关注的焦点。而电流环作为FOC控制中最核心的环节,其性能直接影响整个系统的响应速度和稳定性。本文将基…...

LeaguePrank终极指南:安全打造个性化英雄联盟游戏体验
LeaguePrank终极指南:安全打造个性化英雄联盟游戏体验 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款基于英雄联盟LCU API开发的个性化定制工具,让玩家能够在不违反游戏规则的前提下…...

GetQzonehistory完整指南:三步实现QQ空间历史说说一键备份
GetQzonehistory完整指南:三步实现QQ空间历史说说一键备份 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory GetQzonehistory是一款专为QQ空间用户设计的智能数据备份工具&…...
)
html+css+js创意小游戏~记忆卡片配对(附源码)
1. 从零开始打造记忆卡片配对游戏 最近在教家里小朋友认动物,突然想到可以用前端三件套做个记忆卡片小游戏。这个项目特别适合刚学完HTML/CSS基础,想练手JavaScript的朋友。我自己第一次写这个游戏时,只用了不到100行代码就实现了核心功能&am…...

国金证券QMT实盘连接指南:手把手教你配置交易环境与策略回测
国金证券QMT实盘连接实战:从环境搭建到策略部署全解析 引言 在量化交易的世界里,工具的选择往往决定了策略执行的效率与稳定性。国金证券QMT作为国内主流的量化交易平台之一,以其稳定的实盘连接能力和丰富的API接口受到众多量化交易者的青睐。…...

5G赋能下的车联网协同感知:自动驾驶感知盲区消除新思路
1. 为什么自动驾驶需要"组队开黑"模式? 想象一下你开车经过一个十字路口,左侧突然冲出一辆外卖电动车——这是典型的A柱盲区问题。传统自动驾驶就像闭着眼睛打游戏,全靠本车传感器"听声辨位"。而5G车联网协同感知&#x…...

leetcode 1504. Count Submatrices With All Ones 统计全 1 子矩形
Problem: 1504. Count Submatrices With All Ones 统计全 1 子矩形 计算矩阵的前缀和,然后遍历所有的子矩阵,看是否都是1也就是面积等于长乘以宽 都是1的矩阵,可以直接计算得到结果 Code class Solution { public:int numSubmat(vector<…...
)
【愚公系列】《剪映+DeepSeek+即梦:短视频制作》026-字幕:用文字来美化画面(美化字幕)
💎【行业认证权威头衔】 ✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家 ✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主 ✔ 技术生态共建先锋&am…...

FLUX小红书V2模型版本对比:V1与V2的核心改进与效果差异
FLUX小红书V2模型版本对比:V1与V2的核心改进与效果差异 1. 引言 如果你最近在玩AI图像生成,特别是想做出那种看起来特别真实、特别有小红书风格的照片,那你肯定听说过FLUX小红书模型。这个模型从V1版本开始就挺火的,主要是因为它…...

如何免费获取Microsoft Word APA第7版参考文献格式:完整安装指南
如何免费获取Microsoft Word APA第7版参考文献格式:完整安装指南 【免费下载链接】APA-7th-Edition Microsoft Word XSD for generating APA 7th edition references 项目地址: https://gitcode.com/gh_mirrors/ap/APA-7th-Edition 还在为学术论文的参考文献…...