数据结构(三):集合、字典、哈希表
数据结构(三)
- 一、集合(Set)
- 1.封装一个集合类
- 2.集合常见的操作
- (1)并集
- (2)交集
- (3)差集
- (4)子集
- 二、字典(Map)
- 三、哈希表
- 1.什么是哈希表?
- 2.哈希化之后的位置冲突解决
- (1)链地址法(拉链法)
- (2)开放地址法
- 3.优秀的哈希函数
- (1)快速的计算
- (2)均匀的分布
- 4.封装一个哈希表
- (1)基础结构的搭建
- (2)哈希函数的设计
- (3)put插入/修改的方法
- (4)get获取某个key对应的value
- (4)remove删除某个key对应的元组
- 5.哈希表的扩容
- (1)为什么需要扩容?
- (2)扩容的思路
- (3)扩容代码
- (4)如何判断一个数为质数?(我面试被问过)
- (5)实现扩容时,容量为质数
- 6.完整的封装代码
一、集合(Set)
1.封装一个集合类
集合通常是由一组无序的、不能重复的元素构成。
不能重复意味着不能通过下标值进行访问,而且相同的对象在集合中只会存在一份。
在ES6中的Set类就是一个集合类,这里我们重新封装一个Set类,了解集合的底层实现。
JavaScript中的Object类中的key就是一个集合,可以使用它来封装集合类Set。
class Set {constructor() {//集合使用对象存储,因为元素不能重复(对象中属性不能重复)this.items = {};}//向集合添加一个新的项add(value) {//先判断有没有这个属性,有的话就不添加if(this.has(value)) return false;//使用[]的方式添加属性,这样属性名就和value一样this.items[value] = value;return true;}//检测集合(对象)中是否有这个属性has(value) {return this.items.hasOwnProperty(value);}//删除某个元素remove(value) {if(!this.has(value)) return false;delete this.items[value];}//移除集合中所有项clear() {this.items = {};}//返回集合的长度size() {return Object.keys(this.items).length;}//获取集合中所有的值getValues() {return Object.values(this.items);}
}
测试代码:
let set = new Set();
set.add('zzy');
set.add('努力的但丁');
set.add('DantinZhang');
console.log(set.items);
set.remove('zzy');
console.log(set.items);
set.clear();
console.log(set.items);
2.集合常见的操作
先准备好测试代码段:
//集合1
let set = new Set();
set.add('zzy');
set.add('努力的但丁');
set.add('DantinZhang');
console.log(set.getValues()); //['zzy', '努力的但丁', 'DantinZhang']//集合2
let newSet = new Set();
newSet.add('元素1');
newSet.add('元素2');
newSet.add('努力的但丁');
console.log(newSet.getValues()); //['元素1', '元素2', '努力的但丁']
(1)并集
主要思路就是先创建一个新的集合,把集合1元素都放进去
然后遍历集合2,如果集合2中的元素没有在新集合中,就add进去。
当然啊,遍历集合2也可以直接将所有元素add进去,因为我们封装的add做了去重判断
//并集union(otherSet) {//集合对象1:this//集合对象2:otherSet//1.创建一个新的集合let unionSet = new Set();//2.先把集合对象1中的元素全部放到新集合中let values = this.getValues();values.forEach(el => {unionSet.add(el);})//3.遍历集合对象2,判断其中的元素在新集合中有没有values = otherSet.getValues();for(let i = 0; i < values.length; i++) {//这里其实不写判断也可以,因为add方法做了判断if(!unionSet.has(values[i])) {unionSet.add(values[i]);}}//4.返回合并之后的结果return unionSet;}
测试代码:
//并集
let union = set.union(newSet);
console.log(union.getValues()); //['zzy', '努力的但丁', 'DantinZhang', '元素1', '元素2']
(2)交集
主要思路就是遍历集合1,看看每个元素是否在集合2中存在,如果存在就添加到新的集合中,最后返回新的集合。
//交集
intersection(otherSet) {//1.定义一个交集集合let intersectionSet = new Set();//2.拿集合1中的元素和集合2中元素相比较let values1 = this.getValues();values1.forEach(el => {//集合1有集合2也有的收起来if(otherSet.has(el)) {intersectionSet.add(el);}})//3.返回交集集合return intersectionSet;
}
测试代码:
//交集
let intersection = set.intersection(newSet);
console.log(intersection.getValues()); //['努力的但丁']
(3)差集
差集的思路和交集是相反的,遍历集合1,看看每个元素是否在集合2中存在,如果不存在就add到新集合里,最后返回新集合。
//差集,刚好和交集相反
difference(otherSet) {//1.定义一个差集集合let diffSet = new Set();//2.集合1中的元素去集合2中查找let values1 = this.getValues();values1.forEach(el => {//集合1有集合2没有的收起来if(!otherSet.has(el)) {diffSet.add(el);}})//3.返回结果return diffSet;
}
测试代码:
//差集
let difference = set.difference(newSet);
console.log(difference.getValues()); //['zzy', 'DantinZhang']
(4)子集
主要思路是遍历集合1,看每个元素是否在集合2中存在,如果存在就return,不存在就继续查找,如果所有元素都在集合2中存在,那么久返回true。
这里有一个大坑,就是forEach中写return是无效的,只能跳出当前循环继续下一轮循环,并不能跳出整个循环,更不能跳出整个函数。所以这里要用for循环比较好。
//子集的判断
isSubset(otherSet) {//判断集合1是否是集合2的子集let values = this.getValues();//forEach的坑:return无法终止循环,无法跳出函数// values.forEach(el => {// if(!otherSet.has(el)) return false;// }) for(let i = 0; i < values.length; i++) {if(!otherSet.has(values[i])) return false;}return true;
}
测试代码:
let set = new Set();
set.add('zzy');
set.add('努力的但丁');
set.add('DantinZhang');
console.log(set.getValues());
//子集的判断
let subset = new Set();
subset.add('zzy');
subset.add('努力的但丁');
subset.add('DantinZhang');
subset.add('ht');
console.log(subset.getValues());
let isSubset = set.isSubset(subset);
console.log(isSubset); //true
二、字典(Map)
数组、集合、字典是任何语言都有的数据结构。其中集合和字典比较像,集合可以理解为只有值,字典可以理解为键值对。
这里要注意,对象和ES6的Map数据结构是不一样的,对象的键可以是String可以是Symbol,而Map数据结构的键可以是任意数据类型。
对字典的封装简单写一下,和集合基本一样。
//字典和集合差不多,都可以基于对象封装
class Map {constructor() {this.items = {};}add(key, value) {if(this.has(key)) return false;this.items[key] = value;}has(key) {return this.items.hasOwnProperty(key);}remove(key) {if(!this.has(key)) return false;delete this.items[key];}get(key) {if(!this.has(key)) return undefined;return this.items[key]}keys() {return Object.keys(this.items);}size() {return this.keys.length;}clear() {this.items = {};}
}
三、哈希表
从这里开始就上难度了tmd,看看大佬的博客
1.什么是哈希表?
哈希表是基于数组实现的,但是相对于数组和链表来说,它的查找效率更高,因为它通常会对插入元素的下标值进行变换。这种变换称为哈希函数,通过哈希函数获取hashCode,并通过取余操作获取元素在数组中的下标。
哈希表的一些概念:
1、哈希化:将大数字转化成数组范围内下标的过程,称之为哈希化;
2、哈希函数:我们通常会将单词转化成大数字,把大数字进行哈希化的代码实现放在一个函数中,该函数就称为哈希函数;
3、哈希表:对最终数据插入的数组进行整个结构的封装,得到的就是哈希表。
综上所述,哈希表简单理解,就是把单词通过幂的连乘(可以唯一标识一个玩意儿,例如6543=6 * 103 + 5 * 102 + 4 * 10 + 3,还有cats = 3 * 273 + 1 * 272 + 20 * 27 + 17 =60337;)唯一标识出来,然后放入一个长度为n的数组中,放入时通过取余来判断放入的位置(比如数组长度是12,那么余数的范围是0-11,正好对应数组的12个下标)
2.哈希化之后的位置冲突解决
此时问题来了,取余后产生的下标,可能会产生冲突(虽然概率小,但还是会有)。那么如何解决冲突呢?
(1)链地址法(拉链法)
我们以长度为10的数组举例,什么是链地址法?
如下图所示,我们将每一个数字都对10进行取余操作,则余数的范围0~9作为数组的下标值。并且,数组每一个下标值对应的位置存储的不再是一个数字了,而是存储由经过取余操作后得到相同余数的数字组成的数组或链表。
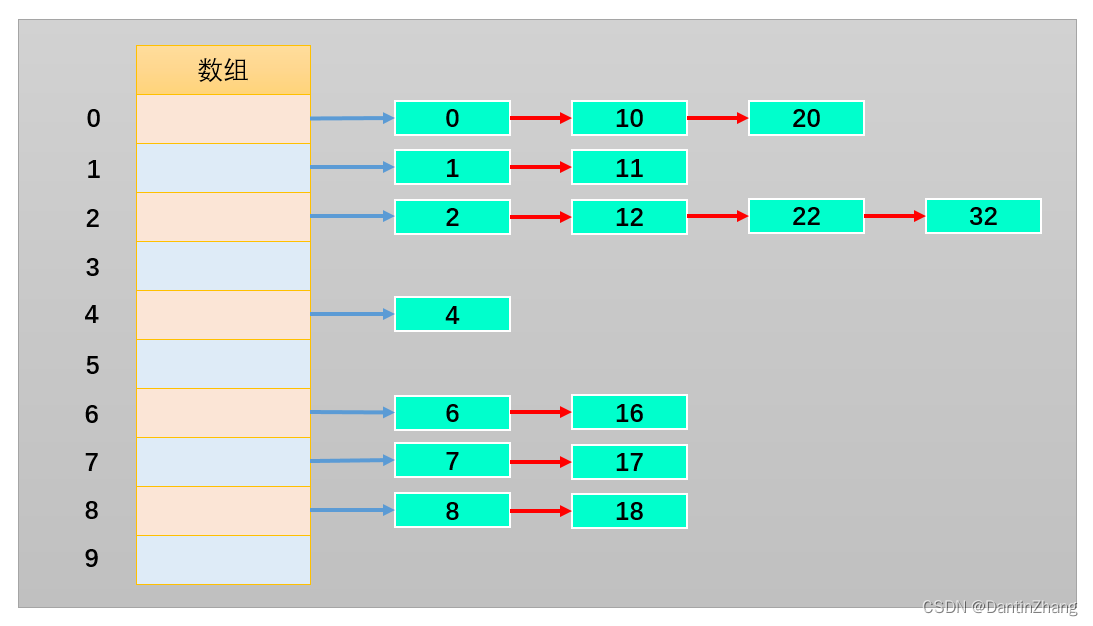
这样可以根据下标值获取到整个数组或链表,之后继续在数组或链表中查找就可以了。而且,产生冲突的元素一般不会太多。
总结:链地址法解决冲突的办法是每个数组单元中存储的不再是单个数据,而是一条链条,这条链条常使用的数据结构为数组或链表,两种数据结构查找的效率相当(因为链条的元素一般不会太多)。
(2)开放地址法
开放地址法的主要工作方式是寻找空白的单元格来放置冲突的数据项。

根据探测空白单元格位置方式的不同,可分为三种方法:
线性探测、二次探测、再哈希法。这里太复杂了,先跳过,想了解点链接。
装填因子:当前哈希表中已经包含的数据项和整个哈希表长度的比值
装填因子 = 总数据项 / 哈希表长度
开放地址法的装填因子最大为1,因为只有空白的单元才能放入元素;
链地址法的装填因子可以大于1,因为只要愿意,拉链法可以无限延伸下去(到无穷);
3.优秀的哈希函数
哈希表的优势在于它的速度,所以哈希函数不能采用消耗性能较高的复杂算法。提高速度的一个方法是在哈希函数中尽量减少乘法和除法。
性能高的哈希函数应具备以下两个优点:
1、快速的计算:减少乘法;
2、均匀的分布:数组长度为质数;
(1)快速的计算
霍纳法则:在中国霍纳法则也叫做秦久韶算法,具体算法为:

求多项式的值时,首先计算最内层括号内一次多项式的值,然后由内向外逐层计算一次多项式的值。这种算法把求n次多项式f(x)的值就转化为求n个一次多项式的值。
变换之前:
乘法次数:n(n+1)/2次;
加法次数:n次;
变换之后:
乘法次数:n次;
加法次数:n次;
如果使用大O表示时间复杂度的话,直接从变换前的O(N²)降到了O(N)。
(2)均匀的分布
这个不太懂为什么,但是为了保证数据在哈希表中均匀分布,当我们需要使用常量的地方,尽量使用质数;比如:哈希表的长度、N次幂的底数等。
4.封装一个哈希表
本次封装,所有的冲突解决方案以:链地址法(拉链法)为主。
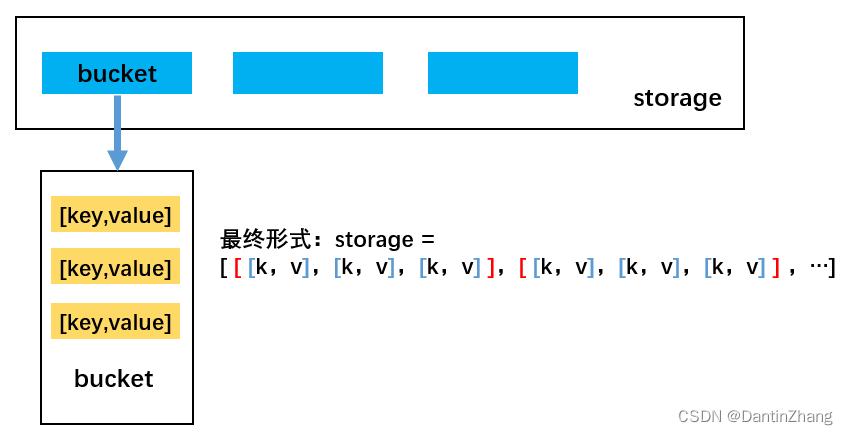
(1)基础结构的搭建
这里需要初始化三个属性,一个是用来存储元素的数组storage,一个是用来计算装载因子的变量:元素个数count,一个是数组长度limit。
其中装载因子是要用于判断数组是否需要扩容,如果装载因子>0.75,那么就要扩容,装载因子<0.25就要缩容。
//封装哈希表(基于链地址法解决冲突情况)
class HashTable {constructor() {//1.定义一个数组来存储元素this.storage = [];//2.count:已经存储的总长度,用来计算装载因子//装载因子(已经存储的/数组总长)用来判断是否扩容this.count = 0;//3.数组的长度this.limit = 7;}
}
(2)哈希函数的设计
通过前面部分的分析,我们的哈希函数要分为两步:
1、把字符串转换成较大的hashCode(这里幂的底数选择37)
2、hashCode和哈希表的长度取余,返回位置
//设计哈希函数
//1>将字符串转换成比较大的数字:hashCode
//2>把hashCode压缩到数组范围(size)内
hashFun(str, size) {//1.定义hashCode变量let hashCode = 0;//2.霍纳算法O(N),计算hashCode的值// cats => 获取Unicode编码for (let i = 0; i < str.length; i++) {//这里的理论比较不好理解,代码先记住吧。hashCode = 37 * hashCode + str.charCodeAt(i);}//3.取余数let index = hashCode % size;//4.返回位置索引return index;
}
(3)put插入/修改的方法
主要思路:
1、先通过哈希函数计算出key要插入的位置index
2、定义一个bucket来存储该位置的值(初始没有值是undefined)
3、判断插入的位置是否有bucket,如果没有就创建一个空数组
4、如果有了bucket,就遍历它,对比每个key,看是否已经添加,如果已经添加那么就要修改当前key对应的value值,修改完return出去
5、如果遍历完没有return,说明需要添加,直接push添加就行了。
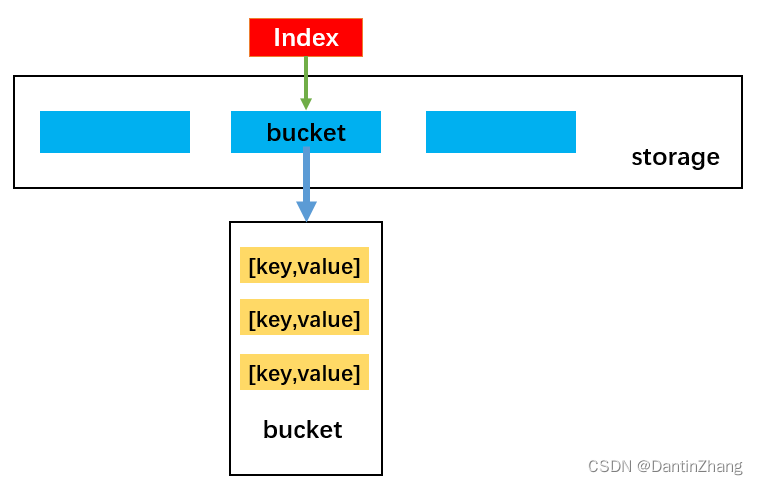
函数代码:
//插入/修改方法
put(key, value) {//1.获取位置let index = this.hashFun(key, this.limit);let bucket = this.storage[index];console.log('当前桶:', index, bucket);//2.判断插入的位置是否已经创建数组(桶)if (bucket == undefined) {bucket = []; //创建桶然后放到索引位置this.storage[index] = bucket;}//3.如果已经有了桶,那么就遍历看是否已经添加for (let i = 0; i < bucket.length; i++) {let tuple = bucket[i];if (tuple[0] == key) {//3.1如果添加了,就修改valuetuple[1] = value;return true;}}//4.循环结束如果没有返回,那么就要新增bucket.push([key, value]);//5.装载因子增加this.count++; return true;
}
测试代码:
let hashTable = new HashTable();
hashTable.put('name', 'zzy'); //5位置
hashTable.put('age', 18); //2位置
console.log(hashTable.storage);
结果:[null, null, [['age',18]], null, null, [['name','zzy']], null]
(4)get获取某个key对应的value
主要思路:
1、获取该key对应的位置index
2、获取该位置对应的桶bucket
3、如果bucket里是空的,说明肯定没有该元素,返回null
4、bucket不为空,就遍历它,依次对比key,如果有就返回
5、没有说明没有插入过,那么就返回null
//获取某个key对应的value
get(key) {//1.先找到位置let index = this.hashFun(key, this.limit);//2.找到该位置的桶let bucket = this.storage[index];//3.判断桶是否为空,为空说明肯定没有keyif(bucket == undefined) return null;//4.如果不为空,那么就遍历桶for(let i = 0; i < bucket.length; i++) {let tuple = bucket[i]; //存储每一轮的元组//5.如果找到key,就返回它对应的valueif(tuple[0] == key) {return tuple[1];}}//6.如果遍历完没有return,说明没找到return null;
}
测试代码:
let hashTable = new HashTable();hashTable.put('name', 'zzy');hashTable.put('age', 18);console.log(hashTable.storage);console.log(hashTable.get('age')); //18console.log(hashTable.get('www')); //null
(4)remove删除某个key对应的元组
主要思路和前边差不多:
1、获取该key对应的位置index
2、获取该位置对应的桶bucket
3、如果bucket里是空的,说明不用删除了,返回null
4、bucket不为空,就遍历它,依次对比key,如果有就删除并返回value(count-1)
5、没有说明没有插入过,那么就返回null
//删除某个key对应的元组
remove(key) {//1.先找到位置let index = this.hashFun(key, this.limit);//2.找到该位置对应的桶let bucket = this.storage[index];//3.如果桶是空的,那么直接返回trueif(bucket == undefined) return null;//4.如果桶不为空,就遍历寻找key所对应的元组for(let i = 0; i < bucket.length; i++) {let tuple = bucket[i];if(tuple[0] == key) {bucket.splice(i,1);this.count --; //别忘了插入个数-1return tuple[1];}}//5.如果走到这里,说明没有这个元素return null;
}
测试代码:
let hashTable = new HashTable();
hashTable.put('name', 'zzy');//位置5
hashTable.put('age', 18); //位置2
console.log(hashTable.storage);//结果:[null, null, [['age',18]], null, null, [['name','zzy']], null]
//测试获取元素
console.log(hashTable.get('age')); //18
console.log(hashTable.get('www')); //null
//测试删除
console.log(hashTable.remove('age'));//18
console.log(hashTable.storage);//[null,[],null,null,null,[['name','zzy']],null]
5.哈希表的扩容
(1)为什么需要扩容?
前面我们在哈希表中使用的是长度为7的数组,由于使用的是链地址法,装填因子(loadFactor)可以大于1,所以这个哈希表可以无限制地插入新数据。
但是,随着数据量的增多,storage中每一个index对应的bucket数组(链表)就会越来越长,这就会造成哈希表效率的降低。
(2)扩容的思路
loadFactor > 0.75时就扩容,loadFactor < 0.25时就缩容,扩容可以直接扩大两倍(扩容成质数后面再说),扩容之后所有数据都要同步修改,那么扩容的思路是什么呢?
1、首先,定义一个变量oldStorage把扩容前的旧数组存储起来
2、把当前数组变成一个容量更大的数组(重置属性)
3、把旧数组oldStorage中的每个bucket中的每个元素都取出来依次添加到新数组中
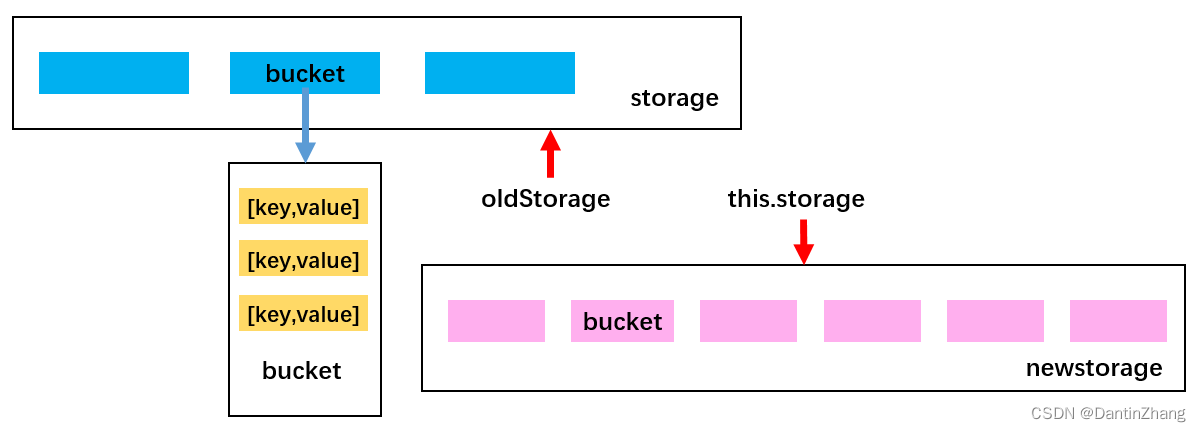
(3)扩容代码
//哈希表的扩容,传入新的数组长度
resize(newLimit) {//1.定义一个变量存储旧数组let oldStorage = this.storage;//2.初始化数组长度this.storage = [];this.count = 0;this.limit = newLimit;//3.把旧数组中存放的东西依次拿出来添加到新数组for(let i = 0; i < oldStorage.length; i++) {let bucket = oldStorage[i];//如果当前桶里没东西,就继续下一轮循环if(bucket == undefined) continue;//如果桶里有东西,就遍历它for(let i = 0; i < bucket.length; i++) {//调用put方法依次把元组放进新的数组中//注意put方法接收两个参数(key,value)let tuple = bucket[i];this.put(tuple[0],tuple[1]);}}//4.直到所有的桶里的元素都迁移完毕,那么扩容就欧了
}
上面这个方法应该什么时候调用呢?
在我们插入元素且count改变后,应该对count进行一个判断,如果装载因子loadFactor > 0.75就进行扩容(这里先两倍)
//判断是否需要扩容操作
count++;
if(this.count > this.limit * 0.75){this.resize(this.limit * 2)
}
在我们删除元素且count改变后,进行判断,如果装载因子loadFactor< 0.25就缩容。(这里先两倍)。
this.count --; //别忘了插入个数-1
if(this.limit > 7 && this.count < this.limit * 0.25) {this.resize(Math.floor(this.limit / 2));
}
(4)如何判断一个数为质数?(我面试被问过)
所谓质数,就是只能被1和它本身整除的数,那么有了这个思路,我们可以这样去判断一个数是否为质数:
//判断一个数是否为质数
function isPrime(num) {if(num <= 1) return false;for (let i = 2; i < num; i++) {if (num % i == 0) return false;}return true;
}
但是实际上还有更高效的判断方法,想象一下,一个数字如果要找两个因数,那么这两个因数一定是一个a在平方根的左侧,另一个b在平方根的右侧,如果我们把循环条件设置为开平方根的数字,那么如果左侧的a中没有可以整除的结果,右侧的b就不用再找了。
//判断一个数是否为质数更高效的方法
function isPrimeNb(num) {if(num <= 1) return false;let sqrtNum = Math.sqrt(num);for (let i = 2; i < sqrtNum; i++) {if (num % i == 0) return false;}return true;
}
(5)实现扩容时,容量为质数
先把上一步写的方法加进去:
//判断一个数是否为质数
isPrime(num) {if(num <= 1) return false;let sqrtNum = Math.sqrt(num);for (let i = 2; i < sqrtNum; i++) {if (num % i == 0) return false;}return true;
}
把当前数变成质数:
扩容/缩容之后,通过循环调用isPrime判断得到的容量是否为质数,不是则+1,直到是为止。比如原长度:7,2倍扩容后长度为14,14不是质数,14 + 1 = 15不是质数,15 + 1 = 16不是质数,16 + 1 = 17是质数,停止循环,由此得到质数17。
//把当前数变成质数
getPrime(num) {while(!isPrime(num)) {num++;}return num;
}
然后在插入方法中:
//6.判断是否需要扩容
if(this.count > this.limit * 0.75) {let newLimit = this.getPrime(this.limit * 2);this.resize(newLimit);
}
在删除方法中:
if(this.limit > 7 && this.count < this.limit * 0.25) {let newLimit = Math.floor(this.limit / 2);let newPrimeLimit = this.getPrime(newLimit);this.resize(newPrimeLimit);
}
测试代码:
let hashTable = new HashTable();hashTable.put('name', 'zzy');hashTable.put('age', 18); hashTable.put('class1','Tom')hashTable.put('class2','Mary')hashTable.put('class3','Gogo')hashTable.put('class4','Tony')hashTable.put('class5','5')hashTable.put('class6','6')hashTable.put('class7','7')hashTable.put('class8','8')console.log(hashTable.limit); //17
6.完整的封装代码
请见github:https://github.com/DantinZhang/js-data-structures-algorithms
相关文章:
数据结构(三):集合、字典、哈希表
数据结构(三)一、集合(Set)1.封装一个集合类2.集合常见的操作(1)并集(2)交集(3)差集(4)子集二、字典(Map)三、…...

Linux内核驱动开发(一)
Linux内核初探 linux操作系统历史 开发模式 git 分布式管理git clone 获取git push 提交git pull 更新 邮件组 mailing list patch 内核代码组成 Makfile arch 体系系统架构相关 block 块设备 crypto 加密算法 drivers 驱动(85%) atm 通信bluet…...

TCP/IP协议二十问
TCP/IP协议二十问 1. 什么是TCP网络分层? TCP网络分层一般分为五层: 应用层(HTTP):组装数据包传输层(TCP):增加TCP头部,包含端口号等信息网络互联层(IP&am…...

常用Array数组操作方法
定义一个测试数组constplayers[{name:科比,num:24},{name:詹姆斯,num:23},{name:保罗,num:3},{name:威少,num:0},{name:杜兰特,num:35}]复制代码1、forEach参数代表含义item:遍历项index:遍历项的索引arr:数组本身Array.prototype.sx_forEach…...
【C++】set/multiset、map/multimap的使用
目录 一、关联式容器 二、set的介绍 1、接口count与容器multiset 2、接口lower_bound和upper_bound 三、map的介绍 1、接口insert 2、接口insert和operator[]和at 3、容器multimap 四、map和set相关OJ 1、前K个高频单词 2、两个数组的交集 一、关联式容器 vector、…...
vue3语法
vue3教程 //ps 这里是基本写法 一般项目不需要ref 因为需要一直return 这里是根据在不使用ts后缀 来在.vue里面写setup 如下图所示:setup setup是启动页面会自动执行的一个函数 项目里定义的所有变量,都要在setup当中 在setup定义的变量和方法,都需要r…...
对象之间的关系
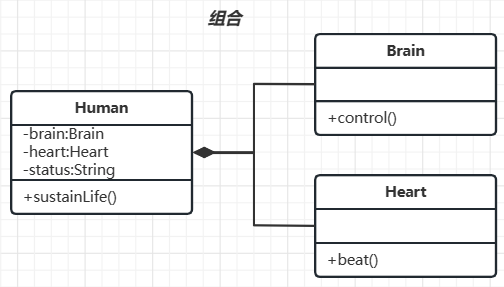
目录1. 依赖2. 关联3. 聚合4. 组合Java的对象/类之间有四种关系:依赖、关联、组合、聚合。 1. 依赖 依赖(Dependency): 一个对象的功能依赖于另一个对象。 类比:人类生存依赖食物和空气 体现:被依赖者体…...
云原生时代顶流消息中间件Apache Pulsar部署实操-上
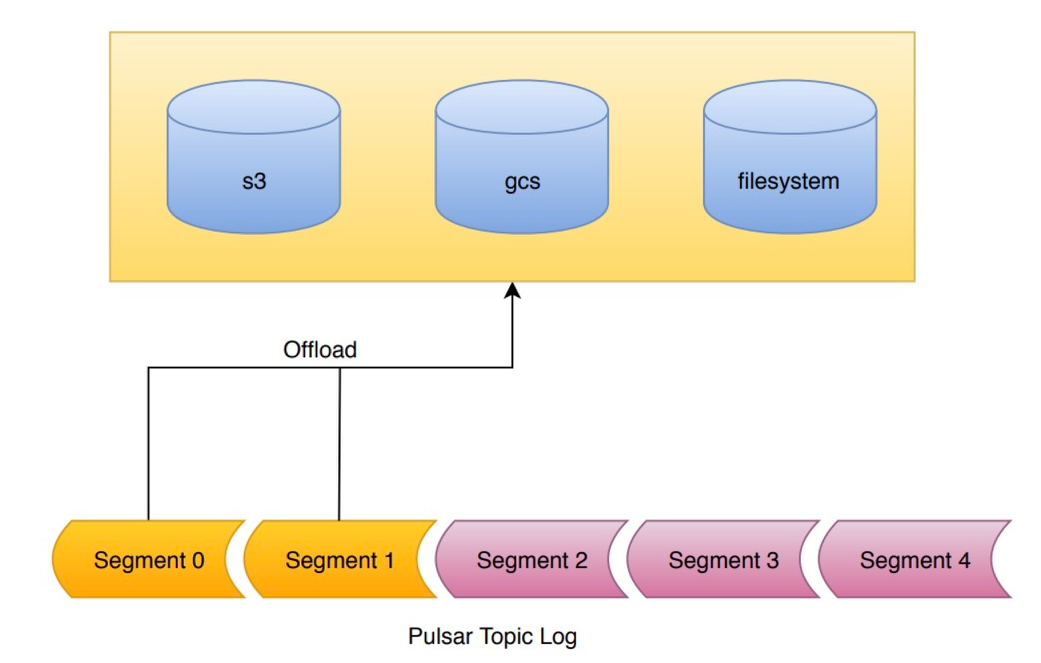
文章目录安装运行时Java版本推荐Locally Standalone集群启动验证部署分布式集群部署说明初始化集群元数据部署BookKeeper部署BrokerAdmin客户端和验证Tiered Storage(层级存储)概述支持分级存储何时使用工作原理安装 运行时Java版本推荐 Locally Standalone集群 启动 # 下载…...

Python实现基于openCV+百度智能云平台实现《1:N人脸考勤机》文章最后附带源码!
目录 一、 项目介绍 1.1 项目名称 1.2 项目简介 1.3 项目物料 1.4 技术栈 二、 项目架构 三、项目细节 3.1 环境搭建 3.2 利用opencv实现摄像头调取及相关图像的采集 3.3 利用aips上传图像和结果返回 3.4 结果优化和处理 3.5 可扩展性 3.6 遗留问题和…...

因为锁的问题,我们被扣了1万
前言 春节放假期间,一个项目上的积分接口被刷,而且不止一个人在刷,并且东西也被兑走,放假晚上被人叫起来排查问题,通过这个人的积分明细观察,基本一秒就能获取一次,远远超过了积分规则限定的次…...
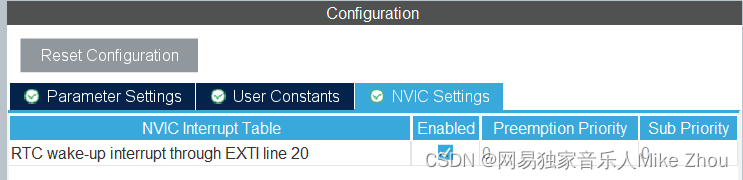
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER)
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER) 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置(ADC唤醒无法使用、低功耗模式无法烧录…...

浏览器渲染中的相关概念
渲染 渲染流水线 构建 DOM 树 输入:HTML 文档;处理:HTML 解析器解析;输出:DOM 数据解构。 样式计算 输入:CSS 文本;处理:属性值标准化,每个节点具体样式(…...

【MySQL】数据类型
1、数据类型描述 类型类型举例整数类型TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT浮点类型FLOAT、DOUBLE定点数类型DECIMAL位类型BIT日期时间类型YEAR、TIME、DATE、DATETIME、TIMESTAMP文本字符串类型CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT枚举类…...

L2-037 包装机
一种自动包装机的结构如图 1 所示。首先机器中有 N 条轨道,放置了一些物品。轨道下面有一个筐。当某条轨道的按钮被按下时,活塞向左推动,将轨道尽头的一件物品推落筐中。当 0 号按钮被按下时,机械手将抓取筐顶部的一件物品&#x…...
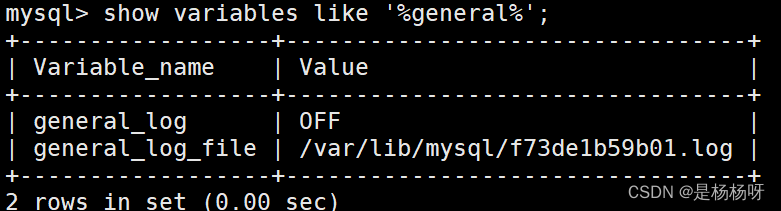
MySQL -查询日志、二进制日志、错误日志、慢查询日志
文章目录1.错误日志2.二进制日志3.查询日志4.慢查询日志1.错误日志 错误日志是 MySOL中最重要的日志之一,它记录了当 mvsald 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息当数据库出现任何故障导致无法正常使用时,建议…...

TCP实现可靠传输的实现
TCP实现可靠传输的实现 目录TCP实现可靠传输的实现ARQ协议停止等待协议(古老)连续ARQ协议累计重传(回退N帧的ARQ协议)缓存确认(选择重传ARQ协议)超时重传的时间选择TCP的流量控制零窗口探测报文段Nagle算法…...

2/14考试总结
时间安排 7:30–7:50 看题,T1可能是个数据结构之类的东西,T2是 dp ,T3 构造。 7:50–8:20 T3,仿照样例的构造,可以通过一部分测试点。 8:20–9:20 T1,发现题目实际上要求子树内各儿子的深度信息,可以 dsu ,对于不能暴…...

程序环境和预处理详解
文章目录一、程序环境1.1 - 翻译环境1.1.1 - 编译1.1.1.1 - 预编译(预处理)1.1.1.2 - 编译1.1.1.3 - 汇编1.1.2 - 链接1.2 - 执行环境二、预处理详解2.1 - 预定义符号2.2 - #define2.2.1 - #define 定义标识符2.2.1.1 - 语法2.2.1.2 - 建议2.2.2 - #defi…...

The Social-Engineer Toolkit(社会工程学工具包)互联网第一篇全模块讲解
一、工具介绍 Social-Engineer Toolkit 是一个专为社会工程设计的开源渗透测试框架,可以帮助或辅助你完成二维码攻击、可插拔介质攻击、鱼叉攻击和水坑攻击等。SET 本身提供了大量攻击选项,可让您快速进行信任型攻击,也是一款高度自定义工具…...
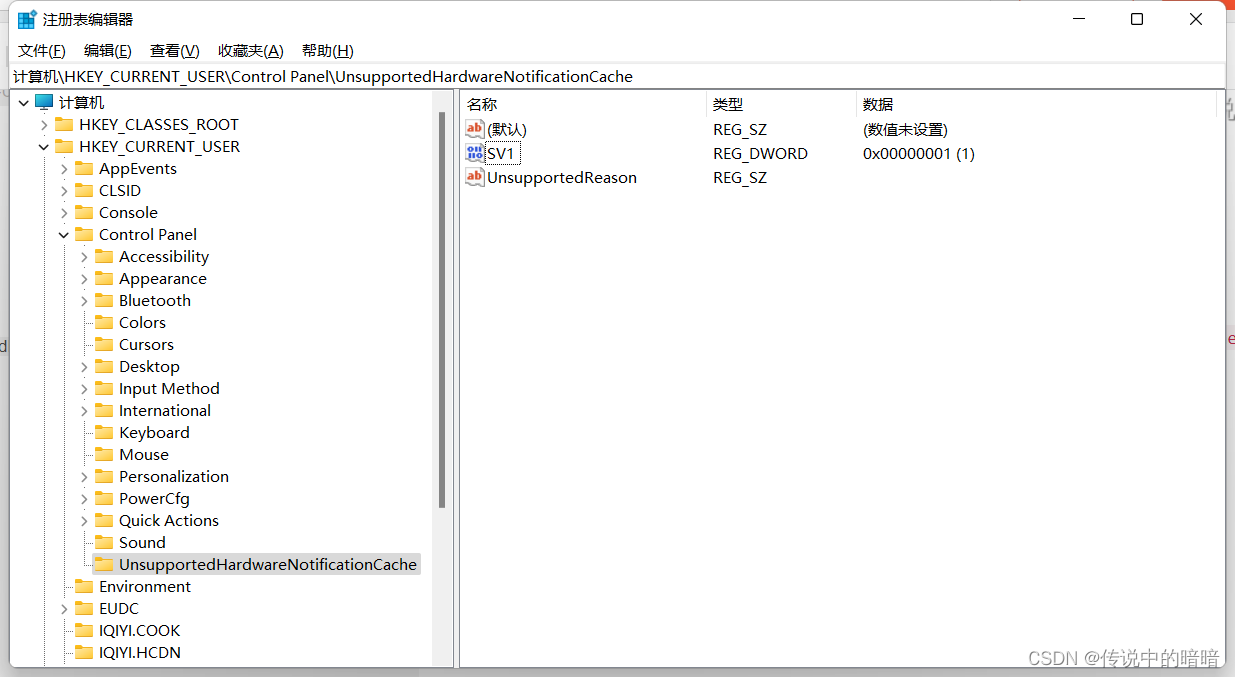
Windows11去掉不满足系统要求的提示水印
我的电脑是LEGION的拯救者R70002021,预装的是Windows 11 家庭中文版,没有折腾重装过系统,今天突然注意到右下角出现了这个提示:“不满足系统要求。转到’设置"了解详细信息”。 在进入设置 - 系统 面板中也提示不满足系统要…...

别再纠结选哪种了!用MATLAB机器人工具箱,5分钟搞定六轴机械臂的避障路径规划
六轴机械臂避障路径规划的MATLAB实战指南:5分钟决策与实现 在工业自动化实验室里,一位工程师正盯着屏幕上机械臂的异常抖动皱眉——这已经是本周第三次因为路径规划不当导致产线停摆了。类似的情景每天都在全球无数实验室和工厂上演,而问题的…...

RWKV7-1.5B-g1a部署教程:CSDN GPU平台外网访问全链路排障
RWKV7-1.5B-g1a部署教程:CSDN GPU平台外网访问全链路排障 1. 模型简介 rwkv7-1.5B-g1a是基于新一代RWKV-7架构的多语言文本生成模型,特别适合中文场景下的轻量级应用。这个1.5B参数的版本在保持高效推理的同时,能够处理基础问答、文案续写、…...

漫画收藏家的智能解决方案:Comics Downloader开源工具全解析
漫画收藏家的智能解决方案:Comics Downloader开源工具全解析 【免费下载链接】comics-downloader tool to download comics and manga in pdf/epub/cbr/cbz from a website 项目地址: https://gitcode.com/gh_mirrors/co/comics-downloader 在数字阅读时代&a…...

终极指南:3个简单技巧让你的终端颜值翻倍,告别混乱命令提示
终极指南:3个简单技巧让你的终端颜值翻倍,告别混乱命令提示 【免费下载链接】oh-my-posh JanDeDobbeleer/oh-my-posh: Oh My Posh 是一个跨平台的终端定制工具,用于增强 PowerShell、Zsh 和 Fish Shell 等终端的视觉效果,提供丰富…...

【实战】Python+Bluez BLE广播开发:从零构建可被发现的自定义设备
1. 为什么需要自定义BLE广播设备 想象一下这样的场景:你走进一家智能家居体验店,手机立刻自动弹出了当前房间所有智能设备的控制面板。这种"无感连接"的体验背后,核心就是BLE广播技术。作为开发者,我们经常需要让硬件设…...

解锁音乐自由:MusicFreeDesktop插件系统完全指南
解锁音乐自由:MusicFreeDesktop插件系统完全指南 【免费下载链接】MusicFreeDesktop 插件化、定制化、无广告的免费音乐播放器 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreeDesktop MusicFreeDesktop作为一款插件化、定制化的免费音乐播放器&…...

写作压力小了!2026 最新降AI率软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

Qwen3.5-4B-Claude-Opus入门指南:理解‘Opus-Reasoning-Distilled’命名含义
Qwen3.5-4B-Claude-Opus入门指南:理解Opus-Reasoning-Distilled命名含义 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。这个…...

YOLOv11n模型用Ultralytics官方工具转ncnn后,C++推理代码怎么改?附完整修改版
YOLOv11n模型Ultralytics转ncnn后的C推理代码改造指南 当你在移动端部署YOLOv11n模型时,如果采用Ultralytics官方工具导出ncnn格式,会遇到与ncnn官方示例代码不兼容的情况。这种差异主要源于模型输出结构的改变,需要针对性调整C推理代码的逻辑…...

告别微软商店:Win10企业版ThinkPad用户管理电池的终极方案——离线部署Lenovo Vantage全记录
ThinkPad企业级管理:Win10离线部署Lenovo Vantage的技术实践 当企业IT部门选择Windows 10企业版作为标准镜像时,往往会面临一个现实挑战——微软应用商店的缺失使得UWP应用部署变得复杂。作为ThinkPad设备管理的核心工具,Lenovo Vantage的离线…...