rust智能指针
智能指针
智能指针虽然也号称指针,但是它是一个复杂的家伙:通过比引用更复杂的数据结构,包含比引用更多的信息,例如元数据,当前长度,最大可用长度等。引用和智能指针的另一个不同在于前者仅仅是借用了数据,而后者往往可以拥有它们指向的数据,然后再为其它人提供服务。智能指针往往是基于结构体实现,它与我们自定义的结构体最大的区别在于它实现了 Deref 和 Drop 特征:
- Deref 可以让智能指针像引用那样工作,这样你就可以写出同时支持智能指针和引用的代码,例如 *T
- Drop 允许你指定智能指针超出作用域后自动执行的代码,例如做一些数据清除等收尾工作
Box<T> 堆对象分配
Box<T> 允许你将一个值分配到堆上,然后在栈上保留一个智能指针指向堆上的数据。Rust 堆上对象还有一个特殊之处,它们都拥有一个所有者,因此受所有权规则的限制:当赋值时,发生的是所有权的转移(只需浅拷贝栈上的引用或智能指针即可)。
堆栈的性能
很多人可能会觉得栈的性能肯定比堆高,其实未必。
- 小型数据,在栈上的分配性能和读取性能都要比堆上高
- 中型数据,栈上分配性能高,但是读取性能和堆上并无区别,因为无法利用寄存器或 CPU 高速缓存,最终还是要经过一次内存寻址
- 大型数据,只建议在堆上分配和使用
总之,栈的分配速度肯定比堆上快,但是读取速度往往取决于你的数据能不能放入寄存器或 CPU 高速缓存。 因此不要仅仅因为堆上性能不如栈这个印象,就总是优先选择栈,导致代码更复杂的实现。
Box的使用场景
由于 Box 是简单的封装,除了将值存储在堆上外,并没有其它性能上的损耗。而性能和功能往往是鱼和熊掌,因此 Box 相比其它智能指针,功能较为单一,可以在以下场景中使用它:
- 特意的将数据分配在堆上
- 数据较大时,又不想在转移所有权时进行数据拷贝
- 类型的大小在编译期无法确定,但是我们又需要固定大小的类型时
- 特征对象,用于说明对象实现了一个特征,而不是某个特定的类型(在特征对象的时候,我们已经见到过了Box)
使用 Box<T> 将数据存储在堆上
前面的文章,我们提到过,标量数据类型是被存储在栈上的。现在我们使用Box来将其存储在堆上。例如:
fn main() {let num = Box::new(1);println!("{}", num);let sum = *num + 1;println!("{sum}");
}
创建一个智能指针指向了存储在堆上的 1,并且 num 持有了该指针。
- println! 可以正常打印出 a 的值,是因为它隐式地调用了 Deref 对智能指针 a 进行了解引用;
let sum = *num + 1,需要手动解引用,这是因为在表达式中,rust无法自动隐式地执行 Deref 解引用操作,你需要使用 * 操作符来显式的进行解引用;- num持有的智能指针将在作用域结束(main 函数结束)时,被释放掉,这是因为
Box<T>实现了 Drop 特征
避免栈上数据的拷贝
当栈上数据转移所有权时,实际上是把数据拷贝了一份,最终新旧变量各自拥有不同的数据,因此所有权并未转移。而堆上则不然,底层数据并不会被拷贝,转移所有权仅仅是复制一份栈中的指针,再将新的指针赋予新的变量,然后让拥有旧指针的变量失效,最终完成了所有权的转移:
fn main() {// 在栈上创建一个长度为1000的数组let arr = [0;1000];// 将arr所有权转移arr1,由于 `arr` 分配在栈上,因此这里实际上是直接重新深拷贝了一份数据let arr1 = arr;// arr 和 arr1 都拥有各自的栈上数组,因此不会报错println!("{:?}", arr.len());println!("{:?}", arr1.len());// 在堆上创建一个长度为1000的数组,然后使用一个智能指针指向它let arr = Box::new([0;1000]);// 将堆上数组的所有权转移给 arr1,由于数据在堆上,因此仅仅拷贝了智能指针的结构体,底层数据并没有被拷贝// 所有权顺利转移给 arr1,arr 不再拥有所有权let arr1 = arr;println!("{:?}", arr1.len());// 由于 arr 不再拥有底层数组的所有权,因此下面代码将报错// println!("{:?}", arr.len());
}
在这种数据较大的时候,将数据保存在堆上。在转移所有权的时候,代价较小。
使用Box来构建链表节点
struct Node<T>
{value: Option<T>,next: Option<Box<Node<T>>>
}
链表的节点可能类似于上面,和我们在C++中使用指针定义链表节点的方式非常类似,不过在rust里,我们实现一个链表是相当困难的,因为我们受到所有权和声明周期的约束。
特征对象
回归一下之前的特征对象,他帮助我们实现了某种意义上的鸭子类型。
trait Draw {fn draw(&self);
}struct Button {id: u32,
}
impl Draw for Button {fn draw(&self) {println!("这是屏幕上第{}号按钮", self.id)}
}struct Select {id: u32,
}impl Draw for Select {fn draw(&self) {println!("这个选择框贼难用{}", self.id)}
}fn main() {let elems: Vec<Box<dyn Draw>> = vec![Box::new(Button { id: 1 }), Box::new(Select { id: 2 })];for e in elems {e.draw()}
}
以上代码将不同类型的 Button 和 Select 包装成 Draw 特征的特征对象,放入一个数组中,Box<dyn Draw> 就是特征对象。其实,特征也是动态大小类型,而特征对象在做的就是将动态大小类型转换为固定大小类型。
Box 内存布局
直接参考Rust语言圣经中的讲解。
Box::leak
Box 中还提供了一个非常有用的关联函数:Box::leak,它可以消费掉 Box 并且强制目标值从内存中泄漏。其实还真有点用,例如,你可以把一个 String 类型,变成一个 'static 生命周期的 &str 类型:
fn main() {let s = gen_static_str();println!("{}", s);
}fn gen_static_str() -> &'static str{let mut s = String::new();s.push_str("hello, world");Box::leak(s.into_boxed_str())
}
在之前的代码中,如果 String 创建于函数中,那么返回它的唯一方法就是转移所有权给调用者 fn move_str() -> String,而通过 Box::leak 我们不仅返回了一个 &str 字符串切片,它还是 'static 生命周期的!
你需要一个在运行期初始化的值,但是可以全局有效,也就是和整个程序活得一样久,那么就可以使用 Box::leak
Deref 解引用
智能指针的名称来源,主要就在于它实现了 Deref 和 Drop 特征,这两个特征可以智能地帮助我们节省使用上的负担:Deref 可以让智能指针像引用那样工作,这样你就可以写出同时支持智能指针和引用的代码,例如 *T。
常规引用是一个指针类型,包含了目标数据存储的内存地址。对常规引用使用 * 操作符,就可以通过解引用的方式获取到内存地址对应的数据值:
fn main() {let x = 5;let y = &x;assert_eq!(5, x);assert_eq!(5, *y);
}
这里 y 就是一个常规引用,包含了值 5 所在的内存地址,然后通过解引用 *y,我们获取到了值 5。如果你试图执行 assert_eq!(5, y);,代码就会无情报错,因为你无法将一个引用与一个数值做比较。
考虑一下智能指针,*它是一个结构体类型,如果你直接对它进行 myStruct,显然编译器不知道该如何办,因此我们可以为智能指针结构体实现 Deref 特征。
实现 Deref 后的智能指针结构体,就可以像普通引用一样,通过 * 进行解引用,例如 Box<T> 智能指针:
fn main() {let x = Box::new(1);let sum = *x + 1;
}
智能指针 x 被 * 解引用为 i32 类型的值 1,然后再进行求和。
*背后的原理
当我们对智能指针 Box 进行解引用时,实际上 Rust 为我们调用了以下方法:
*(y.deref())
首先调用 deref 方法返回值的常规引用,然后通过 * 对常规引用进行解引用,最终获取到目标值。
至于 Rust 为何要使用这个有点啰嗦的方式实现,原因在于所有权系统的存在。如果 deref 方法直接返回一个值,而不是引用,那么该值的所有权将被转移给调用者,而我们不希望调用者仅仅只是 *T 一下,就拿走了智能指针中包含的值。
需要注意的是,* 不会无限递归替换,从 *y 到 *(y.deref()) 只会发生一次,而不会继续进行替换然后产生形如 *((y.deref()).deref()) 的怪物。
函数和方法中的隐式 Deref 转换
对于函数和方法的传参,Rust 提供了一个极其有用的隐式转换:Deref 转换。若一个类型实现了 Deref 特征,那它的引用在传给函数或方法时,会根据参数签名来决定是否进行隐式的 Deref 转换,例如:
fn main() {let s = String::from("hello world");display(&s)
}fn display(s: &str) {println!("{}",s);
}
- String 实现了 Deref 特征,可以在需要时自动被转换为 &str 类型
- &s 是一个 &String 类型,当它被传给 display 函数时,自动通过 Deref 转换成了 &str
- 必须使用 &s 的方式来触发 Deref(仅引用类型的实参才会触发自动解引用)
连续的隐式 Deref 转换
如果你以为 Deref 仅仅这点作用,那就大错特错了。Deref 可以支持连续的隐式转换,直到找到适合的形式为止:
fn main() {let s = MyBox::new(String::from("hello world"));display(&s)
}fn display(s: &str) {println!("{}",s);
}
这里我们使用了之前自定义的智能指针 MyBox,并将其通过连续的隐式转换变成 &str 类型:首先 MyBox 被 Deref 成 String 类型,结果并不能满足 display 函数参数的要求,编译器发现 String 还可以继续 Deref 成 &str,最终成功的匹配了函数参数。
总之,当参与其中的类型定义了 Deref 特征时,Rust 会分析该类型并且连续使用 Deref 直到最终获得一个引用来匹配函数或者方法的参数类型,这种行为完全不会造成任何的性能损耗,因为完全是在编译期完成。
但是 Deref 并不是没有缺点,缺点就是:如果你不知道某个类型是否实现了 Deref 特征,那么在看到某段代码时,并不能在第一时间反应过来该代码发生了隐式的 Deref 转换。事实上,不仅仅是 Deref,在 Rust 中还有各种 From/Into 等等会给阅读代码带来一定负担的特征。还是那句话,一切选择都是权衡,有得必有失,得了代码的简洁性,往往就失去了可读性,Go 语言就是一个刚好相反的例子。
再来看一下在方法、赋值中自动应用 Deref 的例子:
fn main() {let s = MyBox::new(String::from("hello, world"));let s1: &str = &s;let s2: String = s.to_string();
}
对于 s1,我们通过两次 Deref 将 &str 类型的值赋给了它(在表达式中需要手动解引用);而对于 s2,我们在其上直接调用方法 to_string,实际上 MyBox 根本没有没有实现该方法,能调用 to_string,完全是因为编译器对 MyBox 应用了 Deref 的结果(方法调用会自动解引用)。
Deref 规则总结
一个类型为 T 的对象 foo,如果 T: Deref<Target=U>,那么,相关 foo 的引用 &foo 在应用的时候会自动转换为 &U。
三种 Deref 转换
在之前,我们讲的都是不可变的 Deref 转换,实际上 Rust 还支持将一个可变的引用转换成另一个可变的引用以及将一个可变引用转换成不可变的引用,规则如下:
- 当
T: Deref<Target=U>,可以将 &T 转换成 &U,也就是我们之前看到的例子 - 当
T: DerefMut<Target=U>,可以将 &mut T 转换成 &mut U - 当
T: Deref<Target=U>,可以将 &mut T 转换成 &U
来看一个关于 DerefMut 的例子:
struct MyBox<T> {v: T,
}impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox { v: x }}
}use std::ops::Deref;impl<T> Deref for MyBox<T> {type Target = T;fn deref(&self) -> &Self::Target {&self.v}
}use std::ops::DerefMut;impl<T> DerefMut for MyBox<T> {fn deref_mut(&mut self) -> &mut Self::Target {&mut self.v}
}fn main() {let mut s = MyBox::new(String::from("hello, "));display(&mut s)
}fn display(s: &mut String) {s.push_str("world");println!("{}", s);
}
以上代码有几点值得注意:
要实现 DerefMut 必须要先实现 Deref 特征:pub trait DerefMut: Deref
T: DerefMut<Target=U> 解读:将 &mut T 类型通过 DerefMut 特征的方法转换为 &mut U 类型,对应上例中,就是将 &mut MyBox<String> 转换为 &mut String
对于上述三条规则中的第三条,它比另外两条稍微复杂了点:Rust 可以把可变引用隐式的转换成不可变引用,但反之则不行。
如果从 Rust 的所有权和借用规则的角度考虑,当你拥有一个可变的引用,那该引用肯定是对应数据的唯一借用,那么此时将可变引用变成不可变引用并不会破坏借用规则;但是如果你拥有一个不可变引用,那同时可能还存在其它几个不可变的引用,如果此时将其中一个不可变引用转换成可变引用,就变成了可变引用与不可变引用的共存,最终破坏了借用规则。
Drop 释放资源
指定在值离开作用域时应该执行的代码的方式是实现 Drop trait。Drop trait 要求实现一个叫做 drop 的方法,它获取一个 self 的可变引用。
struct HasDrop1;
struct HasDrop2;
impl Drop for HasDrop1 {fn drop(&mut self) {println!("Dropping HasDrop1!");}
}
impl Drop for HasDrop2 {fn drop(&mut self) {println!("Dropping HasDrop2!");}
}
#[allow(unused)]
struct HasTwoDrops {one: HasDrop1,two: HasDrop2,
}
impl Drop for HasTwoDrops {fn drop(&mut self) {println!("Dropping HasTwoDrops!");}
}struct Foo;impl Drop for Foo {fn drop(&mut self) {println!("Dropping Foo!")}
}fn main() {let _x = HasTwoDrops {one: HasDrop1,two: HasDrop2,};let _foo = Foo;println!("Running!");
}
这段程序的执行结果如下所示:
Running!
Dropping Foo!
Dropping HasTwoDrops!
Dropping HasDrop1!
Dropping HasDrop2!
这段代码中:
- Drop 特征中的 drop 方法借用了目标的可变引用,而不是拿走了所有权。
- 结构体中每个字段都有自己的 Drop
Drop 的顺序
观察以上输出,我们可以得出以下关于 Drop 顺序的结论
- 变量级别,按照逆序的方式(入栈,出栈),_x 在 _foo 之前创建,因此 _x 在 _foo 之后被 drop
- 结构体内部,按照字段定义顺序的方式,结构体 _x 中的字段按照定义中的顺序依次 drop
没有实现 Drop 的结构体
实际上,就算你不为 _x 结构体实现 Drop 特征,它内部的两个字段依然会调用 drop,我们可以移除HasTwoDrops的Drop trait。原因在于,Rust 自动为几乎所有类型都实现了 Drop 特征,因此就算你不手动为结构体实现 Drop,它依然会调用默认实现的 drop 函数,同时再调用每个字段的 drop 方法。输出结果如下所示:
Running!
Dropping Foo!
Dropping HasDrop1!
Dropping HasDrop2!
Drop 使用场景
对于 Drop 而言,主要有两个功能:
- 回收内存资源
- 执行一些收尾工作
对于第二点,在之前我们已经详细介绍过,因此这里主要对第一点进行下简单说明。
在绝大多数情况下,我们都无需手动去 drop 以回收内存资源,因为 Rust 会自动帮我们完成这些工作,它甚至会对复杂类型的每个字段都单独的调用 drop 进行回收!但是确实有极少数情况,需要你自己来回收资源的,例如文件描述符、网络 socket 等,当这些值超出作用域不再使用时,就需要进行关闭以释放相关的资源,在这些情况下,就需要使用者自己来解决 Drop 的问题。
互斥的 Copy 和 Drop
我们无法为一个类型同时实现 Copy 和 Drop 特征。因为实现了 Copy 的特征会被编译器隐式的复制,因此非常难以预测析构函数执行。因此这些实现了 Copy 的类型无法拥有析构函数。
#[derive(Copy)]
struct Foo;impl Drop for Foo {fn drop(&mut self) {println!("Dropping Foo!")}
}
这段代码会报错,告诉我们在具有析构函数的结构体上,无法实现Copy trait。
the trait `Copy` may not be implemented for this type; the type has a destructor
自定义智能指针
如前所述,我们需要实现智能指针,那么只需要实现Deref trait和Drop trait即可。
use std::ops::Deref;struct MyBox<T> (T);impl<T> MyBox<T>
{fn new(v: T) -> Self {MyBox(v)}
}impl<T> Deref for MyBox<T>{type Target = T;fn deref(&self) -> &Self::Target {&self.0}
}impl<T> Drop for MyBox<T>{fn drop(&mut self) {println!("Drop")}
}fn my_print(v: &i32) {println!("{}", v);
}fn main() {let x = MyBox::new(123);my_print(&x); // 当引用在传给函数或方法时,自动进行隐式deref调用。
}
我们为MyBox实现了Drop trait和 Deref trait,从而让MyBox变为智能指针。我们的drop接口方法实际上什么都没干,只是打印了Drop。在实际自定义智能指针的时候,几乎是不需要实现Drop trait的,因为rust 自动为几乎所有类型都实现了 Drop 特征。
Rc与Arc
Rust 所有权机制要求一个值只能有一个所有者,在大多数情况下,都没有问题,但是考虑以下情况:
- 在图数据结构中,多个边可能会拥有同一个节点,该节点直到没有边指向它时,才应该被释放清理
- 在多线程中,多个线程可能会持有同一个数据,但是你受限于 Rust 的安全机制,无法同时获取该数据的可变引用
以上场景不是很常见,但是一旦遇到,就非常棘手,为了解决此类问题,Rust 在所有权机制之外又引入了额外的措施来简化相应的实现:通过引用计数的方式,允许一个数据资源在同一时刻拥有多个所有者。
这种实现机制就是 Rc 和 Arc,前者适用于单线程,后者适用于多线程。
Rc<T>
引用计数(reference counting),顾名思义,通过记录一个数据被引用的次数来确定该数据是否正在被使用。当引用次数归零时,就代表该数据不再被使用,因此可以被清理释放。
当我们希望在堆上分配一个对象供程序的多个部分使用且无法确定哪个部分最后一个结束时,就可以使用 Rc 成为数据值的所有者。
下面是经典的所有权被转移导致报错的例子:
fn main() {let s = String::from("hello, world");// s在这里被转移给alet a = Box::new(s);// 报错!此处继续尝试将 s 转移给 blet b = Box::new(s);
}
使用 Rc 就可以轻易解决:
use std::rc::Rc;
fn main() {let a = Rc::new(String::from("hello, world"));let b = Rc::clone(&a);assert_eq!(2, Rc::strong_count(&a));assert_eq!(Rc::strong_count(&a), Rc::strong_count(&b))
}
以上代码我们使用 Rc::new 创建了一个新的 Rc<String> 智能指针并赋给变量 a,该指针指向底层的字符串数据。智能指针 Rc<T> 在创建时,还会将引用计数加 1,此时获取引用计数的关联函数 Rc::strong_count 返回的值将是 1。
接着,我们又使用 Rc::clone 克隆了一份智能指针 Rc<String>,并将该智能指针的引用计数增加到 2。由于 a 和 b 是同一个智能指针的两个副本,因此通过它们两个获取引用计数的结果都是 2。
这里的 clone 仅仅复制了智能指针并增加了引用计数,并没有克隆底层数据,因此 a 和 b 是共享了底层的字符串 s,不是所有的clone都会进行深拷贝。下面的例子展示了引用计数的变化。
use std::rc::Rc;
fn main() {let a = Rc::new(String::from("test ref counting"));println!("count_a = {}", Rc::strong_count(&a));let b = Rc::clone(&a);println!("count_a = {}, count_b = {}", Rc::strong_count(&a), Rc::strong_count(&b));{let c = Rc::clone(&a);println!("count_a = {}, count_b = {}, count_c = {}", Rc::strong_count(&a), Rc::strong_count(&b), Rc::strong_count(&c));}println!("After:");println!("count_a = {}, count_b = {}", Rc::strong_count(&a), Rc::strong_count(&b));
}
由于变量 c 在语句块内部声明,当离开语句块时它会因为超出作用域而被释放,所以引用计数会减少 1,事实上这个得益于 Rc<T> 实现了 Drop 特征。a、b、c 三个智能指针引用计数都是同样的,并且共享底层的数据,因此打印计数时用哪个都行,这里选择全部打印是为了直观展示效果。当 a、b 超出作用域后,引用计数会变成 0,最终智能指针和它指向的底层字符串都会被清理释放。
事实上,Rc<T> 是指向底层数据的不可变的引用,因此你无法通过它来修改数据,这也符合 Rust 的借用规则:要么存在多个不可变借用,要么只能存在一个可变借用。如果需要修改数据,那么在rust中使用Arc 跟 Mutex 锁的组合非常常见,它们既可以让我们在不同的线程中共享数据,又允许在各个线程中对其进行修改。
在多线程中使用 Rc<T>
use std::rc::Rc;
use std::thread;fn main() {let s = Rc::new(String::from("多线程漫游者"));for _ in 0..10 {let s = Rc::clone(&s);let handle = thread::spawn(move || { // ERROR, `Rc<String>` cannot be sent between threads safelyprintln!("{}", s)});}
}
spawn的参数是一个闭包,并且使用move将s的所有权转移到闭包中。而spawn会开启一个线程,那么意味着s的所有权转移到一个新的线程中。但是上述代码会报错,原因是 Rc<T> 不能在线程间安全的传递,实际上是因为它没有实现 Send 特征,而该特征是恰恰是多线程间传递数据的关键,我们会在多线程章节中进行讲解。当然,还有更深层的原因:由于 Rc<T> 需要管理引用计数,但是该计数器并没有使用任何并发原语,因此无法实现原子化的计数操作,最终会导致计数错误。
Arc
Arc 是 Atomic Rc 的缩写,顾名思义:原子化的 Rc<T> 智能指针。它能保证我们的数据能够安全的在线程间共享.
Arc 的性能损耗
原子化或者其它锁虽然可以带来的线程安全,但是都会伴随着性能损耗,而且这种性能损耗还不小。因此 Rust 把这种选择权交给我们自己。对比Python语言,它的标准实现CPython是线程安全的,Python使用全局解释器锁(GIL)来确保同一时刻只有一个线程在执行Python字节码。
Arc 和 Rc 拥有完全一样的 API,将上面报错的代码从Rc改成Arc。
use core::time;
use std::sync::Arc;
use std::thread::{self, sleep};#[allow(unused)]
fn main() {let s = Arc::new(String::from("多线程漫游者"));for _ in 0..10 {let s = Arc::clone(&s);let handle = thread::spawn(move || {println!("{}", s)});}sleep(time::Duration::from_secs(3)); // 加了三秒等待所有线程执行完毕。否则输出几个“多线程漫游者是不确定的”。
}
Arc 和 Rc 并没有定义在同一个模块,前者通过 use std::sync::Arc 来引入,后者通过 use std::rc::Rc。大家可以去掉最后一行,多次执行代码,看看效果。
Rc和Arc简单总结
- Rc/Arc 是不可变引用,你无法修改它指向的值,只能进行读取。
- 一旦最后一个拥有者消失,则资源会自动被回收,这个生命周期是在编译期就确定下来的
- Rc 只能用于同一线程内部,想要用于线程之间的对象共享,你需要使用 Arc
Rc<T>/Arc<T>是一个智能指针,实现了 Deref 特征,因此你无需先解开 Rc/Arc 指针,再使用里面的 T,而是可以直接使用 T
Rc 和 Arc 的区别在于,后者是原子化实现的引用计数,因此是线程安全的,可以用于多线程中共享数据。这两者都是只读的,如果想要实现内部数据可修改,必须配合内部可变性 RefCell 或者互斥锁 Mutex 来一起使用。
Cell 和 RefCell
OK,我们终于来到了可以在拥有不可变引用的同时修改目标数据。之前的Rc只是让我们在同一线程内通过引用计数的方式,允许一个数据资源在同一时刻拥有多个所有者;而Arc也只不过是在Rc的基础上扩展到了多线程。我们仍旧无法修改数据,只能传递数据。
为此, Rust 提供了 Cell 和 RefCell 用于内部可变性。
内部可变性的实现是因为 Rust 使用了 unsafe 来做到这一点,但是对于使用者来说,这些都是透明的,因为这些不安全代码都被封装到了安全的 API 中。
Cell
Cell 和 RefCell 在功能上没有区别,区别在于 Cell<T> 适用于 T 实现 Copy 的情况。例如:
use std::cell::Cell;
fn main() {let c = Cell::new("123");let one = c.get();c.set("456");let two = c.get();println!("{}, {}", one, two);
}
- “123” 是 &str 类型,它实现了 Copy 特征
- c.get 用来取值,c.set 用来设置新值
取到值保存在 one 变量后,还能同时进行修改,这个违背了 Rust 的借用规则,但是由于 Cell 的存在,我们很优雅地做到了这一点,但是如果你尝试在 Cell 中存放String:编译器会立刻报错,因为 String 没有实现 Copy 特征
RefCell
由于 Cell 类型针对的是实现了 Copy 特征的值类型,因此在实际开发中,Cell 使用的并不多,因为我们要解决的往往是可变、不可变引用共存导致的问题,此时就需要借助于 RefCell 来达成目的。
use std::cell::RefCell;fn main() {let s = RefCell::new(String::from("hello, world"));let s1 = s.borrow(); // 不可变引用let s2 = s.borrow_mut(); // 可变引用println!("{},{}", s1, s2);
}
这段代码在编译的时候,不会报错;但是在运行时会报错。RefCell可以使用.borrow()方法来获取引用,并使用.borrow_mut()方法来获取可变引用。当RefCell离开其作用域时,会自动检查是否存在任何悬空引用,如果存在,则会引发panic。RefCell不适合多线程并发访问,因为它不是线程安全的。对于多线程访问,Rust的std::sync::Mutex和std::sync::RwLock提供了更好的选择。
RefCell 实际上并没有解决可变引用和引用可以共存的问题,只是将报错从编译期推迟到运行时,从编译器错误变成了 panic 异常。
RefCell 为何存在
Rust 编译期的宁可错杀,绝不放过的原则,当编译器不能确定你的代码是否正确时,就统统会判定为错误,因此难免会导致一些误报。而 RefCell 正是用于你确信代码是正确的,而编译器却发生了误判时。
有时候,你可能很难管理可变和不可变,因此你确实需要RefCell帮你通过编译。总之,当你确信编译器误报但不知道该如何解决时,或者你有一个引用类型,需要被四处使用和修改然后导致借用关系难以管理时,都可以优先考虑使用 RefCell。
RefCell 简单总结
- 与 Cell 用于可 Copy 的值不同,RefCell 用于引用
- RefCell 只是将借用规则从编译期推迟到程序运行期,并不能帮你绕过这个规则
- RefCell 适用于编译期误报或者一个引用被在多处代码使用、修改以至于难于管理借用关系时
- 使用 RefCell 时,违背借用规则会导致运行期的 panic
选择 Cell 还是 RefCell
根据本文的内容,我们可以大概总结下两者的区别:
- Cell 只适用于 Copy 类型,用于提供值,而 RefCell 用于提供引用
- Cell 不会 panic,而 RefCell 会
性能比较
Cell 没有额外的性能损耗,例如以下两段代码的性能其实是一致的:
// code snipet 1
let x = Cell::new(1);
let y = &x;
let z = &x;
x.set(2);
y.set(3);
z.set(4);
println!("{}", x.get());// code snipet 2
let mut x = 1;
let y = &mut x;
let z = &mut x;
x = 2;
*y = 3;
*z = 4;
println!("{}", x);
虽然性能一致,但代码 1 拥有代码 2 不具有的优势:它能编译成功
而RefCell使用了运行时借用检查,每次使用.borrow()或.borrow_mut()方法时都会进行借用检查,这会影响性能。总之,当非要使用内部可变性时,首选 Cell,只有你的类型没有实现 Copy 时,才去选择 RefCell。
内部可变性
之前我们提到 RefCell 具有内部可变性,何为内部可变性?简单来说,对一个不可变的值进行可变借用就是内部可变性。阅读下面的代码。
use std::cell::RefCell;
pub trait Messenger {fn send(&self, msg: String);
}pub struct MsgQueue {msg_cache: RefCell<Vec<String>>,
}impl Messenger for MsgQueue {fn send(&self, msg: String) {self.msg_cache.borrow_mut().push(msg)}
}fn main() {let mq = MsgQueue {msg_cache: RefCell::new(Vec::new()),};mq.send("hello, world".to_string());
}
mq是MsgQueue的不可变实例,因此我们无法通过常规手段修改mq中的msg_cache字段。此时在确保代码正确的情况下,我们可以使用RefCell来改变不可变的mq中的msg_cache。
结构体中的字段可变性取决于结构体对象本身是否是可变的,上述例子中的mq是不可变的,因此msg_cache字段也是不可变的。而我们通过使用RefCell来改变了msg_cache字段。这种内部可变性提供给了我们这种可能。
参考资料
- Rust语言圣经(Rust Course)
- Rust 程序设计语言
相关文章:

rust智能指针
智能指针 智能指针虽然也号称指针,但是它是一个复杂的家伙:通过比引用更复杂的数据结构,包含比引用更多的信息,例如元数据,当前长度,最大可用长度等。引用和智能指针的另一个不同在于前者仅仅是借用了数据…...

Git、Gitee、Github、Gitlab区别与联系
Git:本地软件,无需联网即可使用,实现本地代码的管理。 分布式版本控制系统,是一种工具,用于代码的存储和版本控制。 将本地文件通过一定的操作将其同步上传到Github或Gitee Gitee:是一家中…...

接口优化的策略
1.批处理 批量思想:批量操作数据库,这个很好理解,我们在循环插入场景的接口中,可以在批处理执行完成后一次性插入或更新数据库,避免多次IO。 //批量入库 batchInsert();List的安全操作有以下几种方式: 使…...

android 隐藏底部虚拟按键
方法一 滑动屏幕 可重新显示出来 protected void hideBottomUIMenu() { //隐藏虚拟按键,并且全屏 if (Build.VERSION.SDK_INT <11 && Build.VERSION.SDK_INT < 19) { // lower api View v this.getWindow().getDecorView(); v.setSyst…...
基于电流控制的并网逆变器(Simulink)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
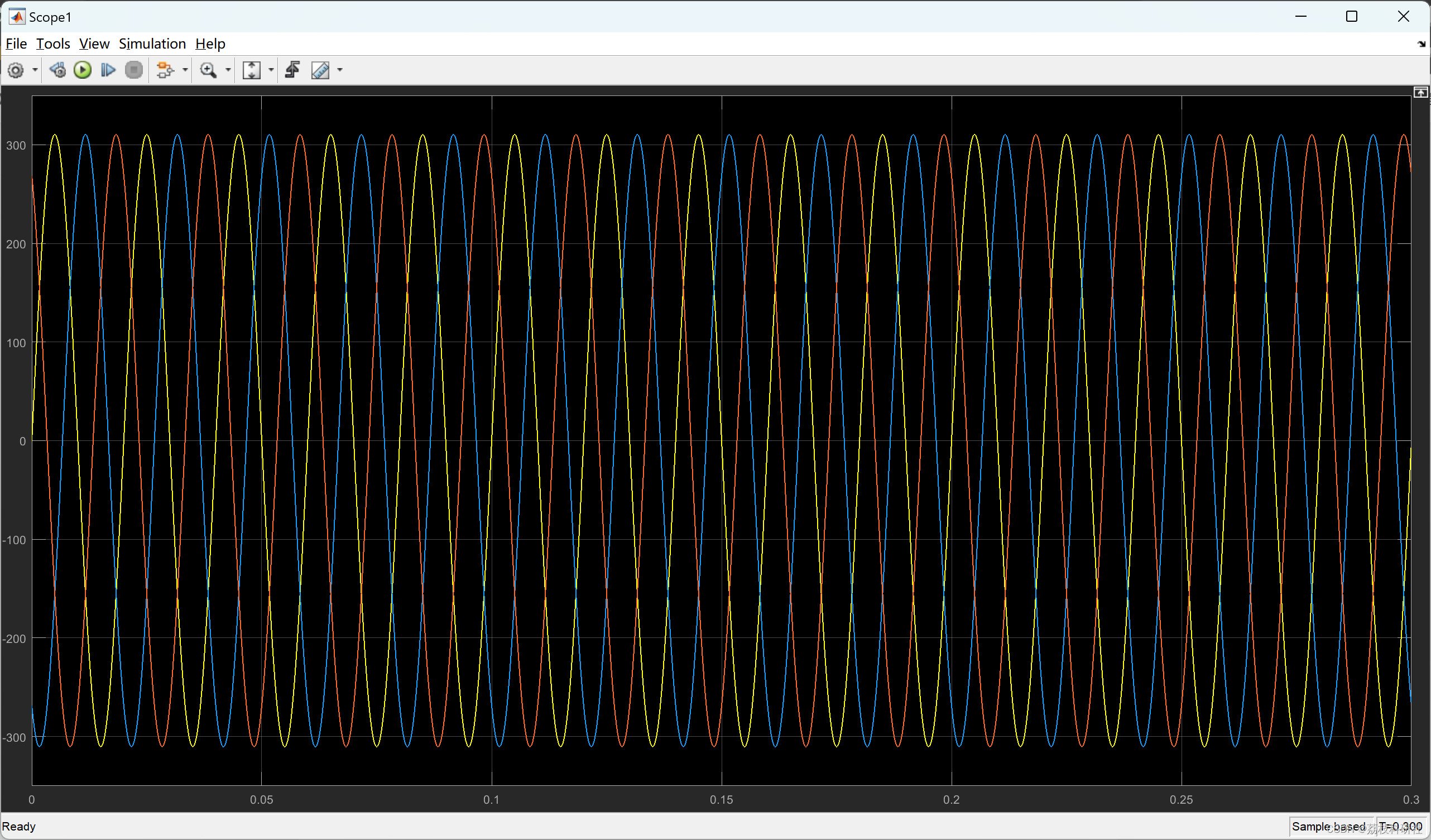
learn_C_deep_9 (汇编角度理解return的含义、const 的各种应用场景)
return 关键字 不知道我们大家是否有一个疑惑:我们下载一个大型游戏软件(王者荣耀),都要花几个小时去下载,但是一旦我们游戏连输,想要删除这个软件的时候,它仅仅只需要十几秒,这是为…...

基于深度学习的OCR技术
随着数字化时代的到来,图片识别技术越来越受到人们的关注。其中,OCR技术作为图片处理的一个重要分支,可以将扫描的图片进行自动识别和分类,极大地提高了工作效率。本文将介绍有道实况OCR技术的相关内容,帮助读者更好地…...
『python爬虫』09. bs4实战之下载精美壁纸(保姆级图文)
目录 爬取思路代码思路1.拿到主页面的源代码. 然后提取到子页面的链接地址, href2.通过href拿到子页面的内容. 从子页面中找到图片的下载地址 img -> src3.下载图片 3. 完整实现代码总结 欢迎关注 『python爬虫』 专栏,持续更新中 欢迎关注 『python爬虫』 专栏&…...
【Linux学习】多线程——线程控制 | 线程TCB
🐱作者:一只大喵咪1201 🐱专栏:《Linux学习》 🔥格言:你只管努力,剩下的交给时间! 线程控制 | 线程TCB 🧰线程控制🎴线程创建🎴线程结束…...
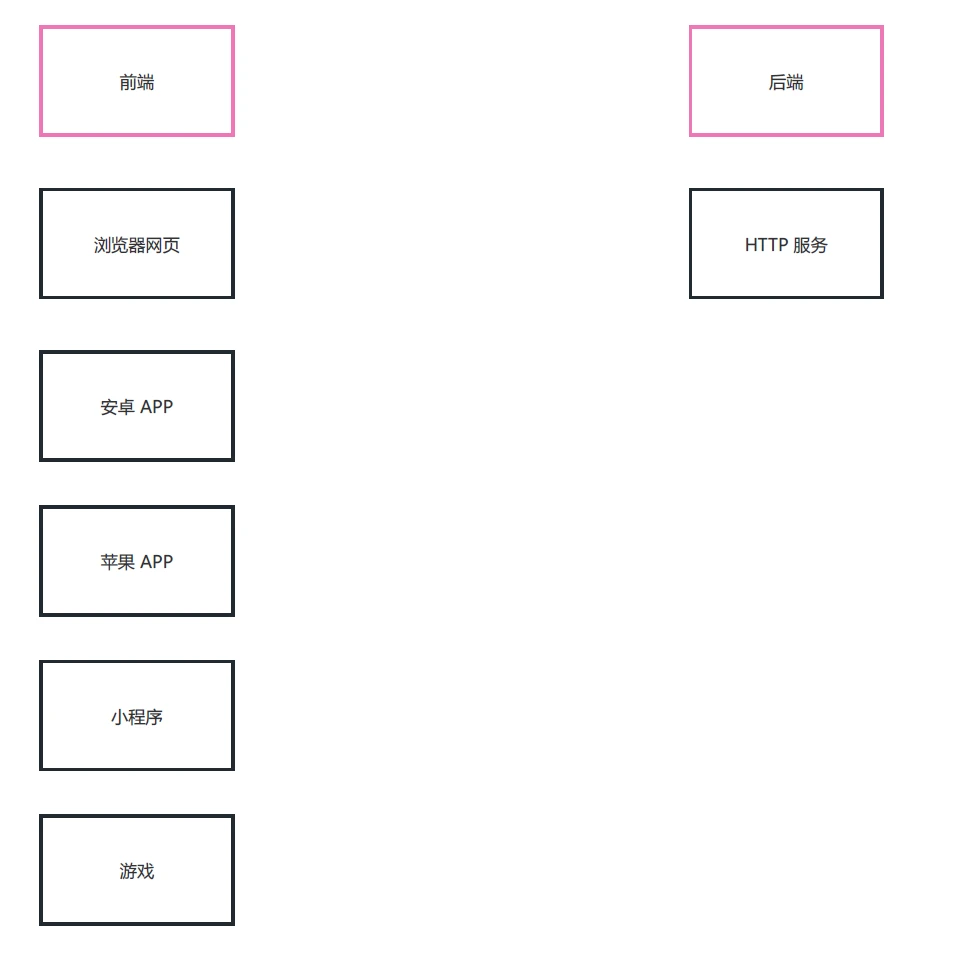
Node 10 接口
接口 简介 接口是什么 接口是 前后端通信的桥梁 简单理解:一个接口就是 服务中的一个路由规则 ,根据请求响应结果 接口的英文单词是 API (Application Program Interface),所以有时也称之为 API 接口 这里的接口指的是『数据接口』&#…...

大型互联网企业大流量高并发电商领域核心项目已上线(完整流程+项目白皮书)
说在前面的话 面对近年来网络的飞速发展,大家已经都习惯了网络购物,从而出现了一些衍生品例如:某宝/某东/拼夕夕等大型网站以及购物APP~ 并且从而导致很多大型互联网企业以及中小厂都需要有完整的项目经验,以及优秀处理超大流量…...

汇编语言学习笔记六
flag 寄存器 CF:进位标志位,产生进位CF1,否则为0 PF:奇偶位,如010101b,则该数的1有3个,则PF0,如果该数的1的个数为偶数,则PF1。0也是偶数 ZF:在相关指令执行后(运算和逻辑指令,传送指…...

多商户商城系统-v2.2.3版本发布
likeshop多商户商城系统-v2.2.3版本发布了!主要更新内容如下 新增 1.用户端退出账号功能 优化 1.平台添加营业执照保存异常问题 2.平台端分销商品优化-只显示参与分销的商品 3.优化订单详情显示营销价格标签 4.平台交易设置增加默认值 5.种草社区评论调整&a…...
科研人必看入门攻略(收藏版)
来源:投稿 作者:小灰灰 编辑:学姐 本文主要以如何做科研,日常内功修炼,常见科研误区,整理日常‘好论文’四个部分做以介绍,方便刚入门的科研者进行很好的规划。 1.如何做科研 1.1 选方向 当我…...

第5章 循环和关系表达式
1. strcmp()//比较字符串数组是否相等| string 可以直接用“”来判断 char word[5] "aaaa"; strcmp(word,"aaab");//相同输出0,不同输出1; 2. 延时函数 #include<ctime>float sec 2.3;long delay sec*CLOCKS_PER_SEC;long start c…...
中的svg、clipPath、mask元素)
Scalable Vector Graphics (SVG)中的svg、clipPath、mask元素
Scalable Vector Graphics (SVG)是一种用于描述二维向量图形的XML基础标记语言。使用SVG可以实现丰富的图形效果,而不需要像使用位图那样考虑分辨率和像素密度的问题,可以在不同设备上展示出相同的高质量图像。 在SVG中,除了基本形状如circl…...
Java基础(十五)集合框架
1. 集合框架概述 1.1 生活中的容器 1.2 数组的特点与弊端 一方面,面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象的操作,就要对对象进行存储。另一方面,使用数组存储对象方面具有一些弊端,而Java 集合…...

安装gitea
1、安装包(gitea-1.13.1-linux-amd64)上传到服务器,并添加执行权限 链接:https://pan.baidu.com/s/1SAxko0RhVmmD21Ev_m5JFg 提取码:ft07 chmod x gitea-1.13.1-linux-amd64 2、执行 ./gitea-1.13.1-linux-amd64 web…...

Java异常处理传递规范总结
java 异常分类 Thorwable类(表示可抛出)是所有异常和错误的超类,两个直接子类为Error和Exception,分别表示错误和异常。其中异常类Exception又分为运行时异常(RuntimeException)和非运行时异常, 这两种异常有很大的区别…...
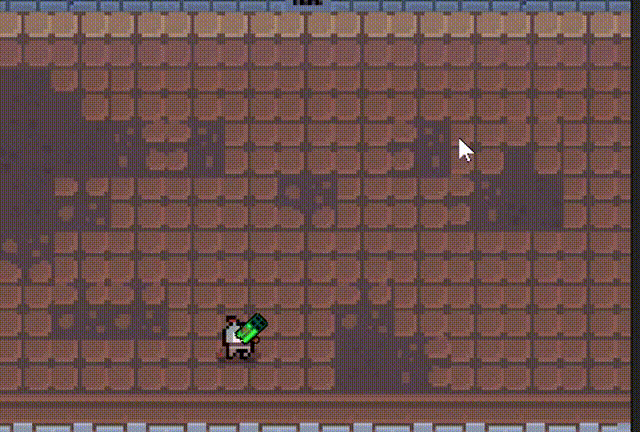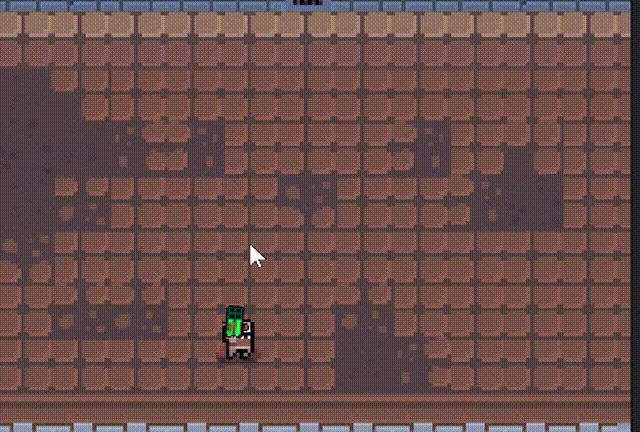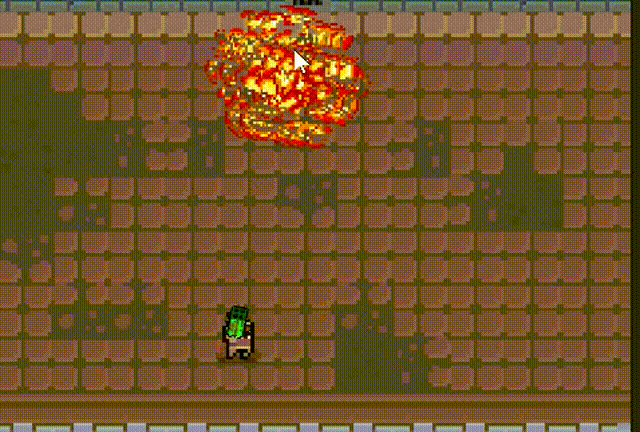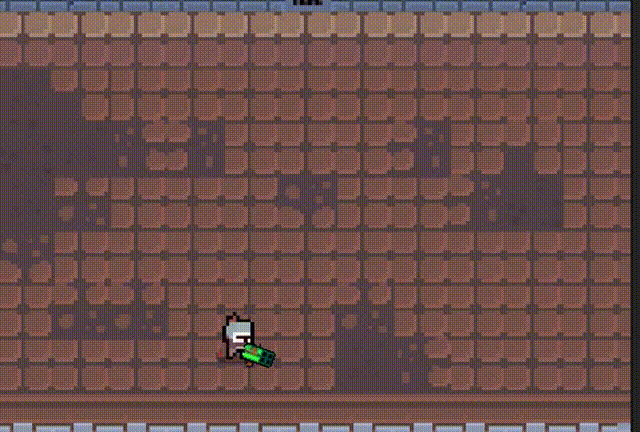
2d俯视视角游戏,可以切换多种枪械
文章目录 一、 介绍二、 人物移动、鼠标控制转向三、子弹脚本四、子弹随机抛壳五、 爆炸特效六、 发射子弹七、 子弹、弹壳对象池八、 散弹枪九、 火箭弹、发射火箭十、 下载工程文件 一、 介绍 2d俯视视角游戏。 人物视角跟随鼠标移动 多种枪械 抛壳效果 多种设计效果 对象池…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...