深入探究HDFS:高可靠、高可扩展、高吞吐量的分布式文件系统【上进小菜猪大数据系列】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。
引言
在当今数据时代,数据的存储和处理已经成为了各行各业的一个关键问题。尤其是在大数据领域,海量数据的存储和处理已经成为了一个不可避免的问题。为了应对这个问题,分布式文件系统应运而生。Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)就是其中一个开源的分布式文件系统。本文将介绍HDFS的概念、架构、数据读写流程,并给出相关代码实例。
一、HDFS的概念
HDFS是Apache Hadoop的一个核心模块,是一个开源的分布式文件系统,它可以在集群中存储和管理大型数据集。HDFS被设计用来运行在廉价的硬件上,它提供了高可靠性和高可用性,能够自动处理故障,具有自我修复的能力。
HDFS的核心理念是将大型数据集划分成小的块(通常是128 MB),并在集群中的多个节点之间进行分布式存储。每个块都会被复制到多个节点上,以提高数据的可靠性和可用性。HDFS还提供了高效的数据读写接口,可以支持各种不同类型的应用程序对数据的读写操作。
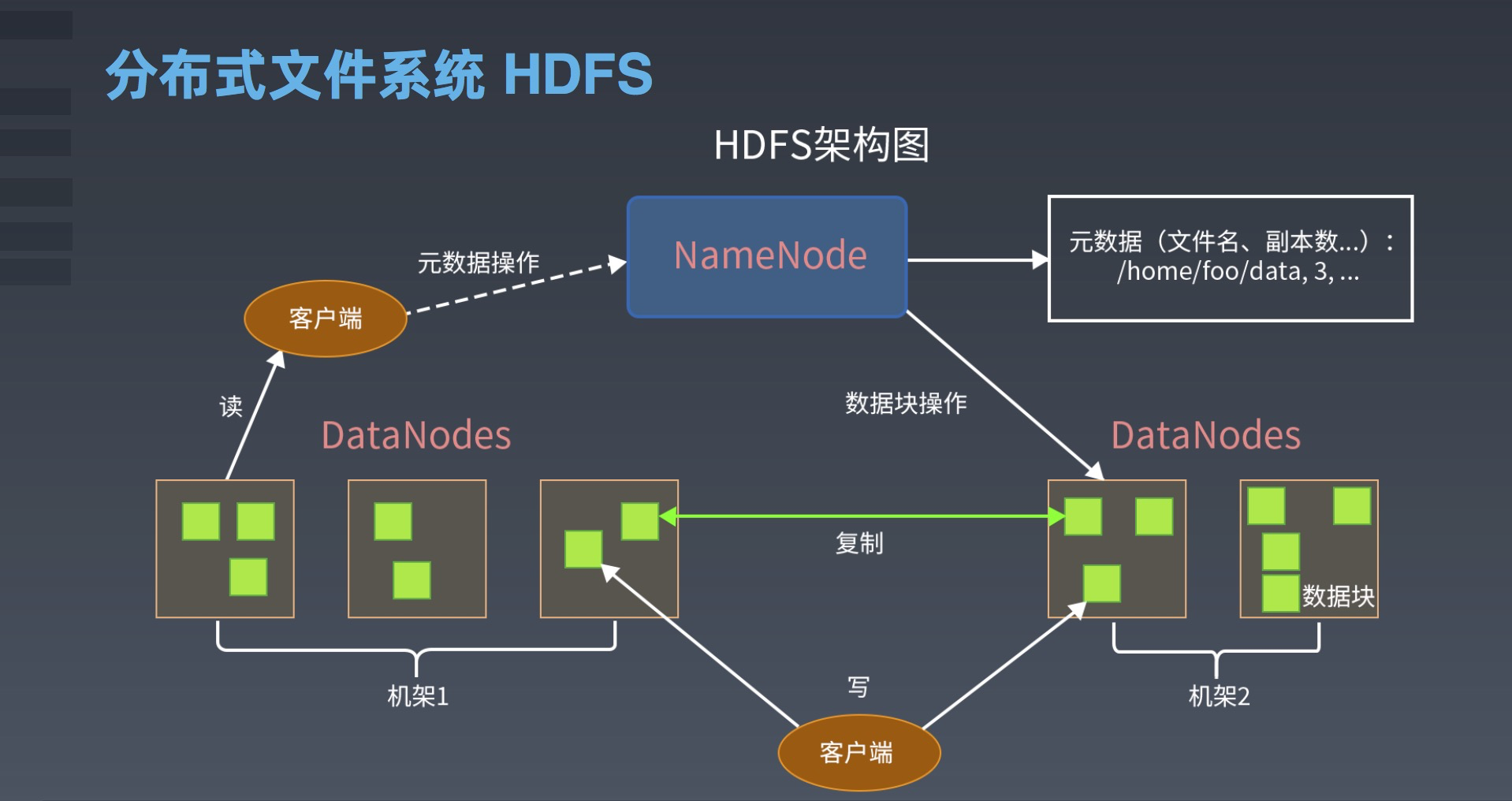
二、HDFS的架构
HDFS的架构包括NameNode、DataNode和客户端三个组件。
1.NameNode
NameNode是HDFS的核心组件,它是集群中的中心节点,用于管理文件系统的命名空间和客户端访问文件的元数据。NameNode维护了整个文件系统的命名空间和文件的层次结构,它还维护了每个文件的块列表、块所在的DataNode列表以及每个块的副本数量。当客户端请求访问文件时,它首先向NameNode发送请求,NameNode根据元数据信息返回给客户端请求的数据块的位置信息。
2.DataNode
DataNode是HDFS的工作节点,它负责存储实际的数据块,并提供数据读写服务。当客户端需要读取或写入数据块时,它会与DataNode通信,DataNode返回请求的数据块,并执行相应的读写操作。
3.客户端
客户端是使用HDFS的应用程序,它通过HDFS提供的API来访问HDFS中存储的数据。客户端向NameNode发送文件系统的元数据请求,并与DataNode进行数据交互。HDFS提供了Java和其他编程语言的API,使得开发者可以方便地使用HDFS的功能。
三、HDFS的数据读写流程
HDFS的数据读写流程包括文件写入和文件读取两个过程
1.文件写入
在HDFS中,文件的写入过程可以分为以下几个步骤:
(1)客户端向NameNode发送文件写入请求。
(2)NameNode检查请求的文件是否存在,如果不存在,则创建新的文件,并返回文件的元数据信息给客户端。如果文件已经存在,则返回文件的元数据信息给客户端。
(3)客户端根据元数据信息将文件分割成一个个数据块,并将每个数据块复制到多个DataNode上。
(4)客户端向NameNode发送数据块信息,包括块的编号和块所在的DataNode列表。
(5)NameNode将块的信息存储在内存中,并返回给客户端写入成功的信息。
(6)客户端开始向DataNode写入数据块,如果一个DataNode写入失败,则重新选择另一个DataNode进行数据复制。
(7)当所有数据块都写入完成后,客户端向NameNode发送完成写入请求,NameNode更新文件的元数据信息,并返回写入完成的信息给客户端。
2.文件读取
在HDFS中,文件的读取过程可以分为以下几个步骤:
(1)客户端向NameNode发送文件读取请求。
(2)NameNode根据文件的元数据信息,返回数据块的位置信息。
(3)客户端根据块的位置信息,向DataNode请求读取数据块。
(4)DataNode返回数据块的内容给客户端。
(5)如果需要读取多个数据块,则客户端继续向相应的DataNode请求读取数据块。
3.HDFS的优势
HDFS具有以下优势:
(1)可靠性:HDFS采用了数据复制机制,每个数据块都会复制到多个DataNode上,即使某个DataNode出现故障,也不会影响文件的完整性和可用性。
(2)高可扩展性:HDFS的设计理念就是高可扩展性,通过添加更多的DataNode,可以轻松地扩展文件系统的容量和性能。
(3)高吞吐量:HDFS的设计目标是针对大数据量的处理,因此具有高吞吐量的特性,能够快速地读写大文件。
(4)适用于批处理:HDFS适用于大规模的批处理任务,例如MapReduce等。
4.HDFS的缺点
HDFS也有以下几个缺点:
(1)不适合小文件存储:由于HDFS采用了数据块的方式存储文件,每个数据块的大小通常为64MB或128MB,因此如果存储小文件,会浪费大量的存储空间。
(2)不适合实时读写:由于HDFS的设计目标是针对大数据量的处理,因此不适合实时读写操作。
(3)复制带来的负载和成本:HDFS采用了数据复制机制,每个数据块都会复制到多个DataNode上,这会增加系统的负载和成本。
5.HDFS的应用
HDFS已经被广泛地应用于大数据处理、数据分析等领域,例如:
(1)Hadoop:Hadoop是一个分布式计算平台,基于MapReduce和HDFS实现了大规模数据处理。
(2)Spark:Spark是一个快速、通用、可扩展的大数据处理引擎,可以与HDFS集成,实现大规模数据处理。
(3)HBase:HBase是一个面向列存储的NoSQL数据库,也是基于HDFS实现的。
(4)Hive:Hive是一个基于Hadoop的数据仓库,可以将结构化数据映射为HDFS上的文件系统。
6.HDFS的代码实例
以下是一个简单的Java程序,用于向HDFS中写入一个文件:
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class HDFSWriter {public static void main(String[] args) throws Exception {String localFilePath = "/home/user/data.txt";String hdfsFilePath = "/user/hadoop/data.txt";Configuration conf = new Configuration();FileSystem fs = FileSystem.get(conf);InputStream in = new FileInputStream(localFilePath);fs.copyFromLocalFile(new Path(localFilePath), new Path(hdfsFilePath));IOUtils.closeStream(in);}
}
该程序首先需要指定要写入的本地文件路径和HDFS文件路径,然后创建一个Configuration对象和FileSystem对象,以便与HDFS进行交互。接下来,使用copyFromLocalFile()方法将本地文件复制到HDFS中,并使用closeStream()方法关闭输入流。
以下是一个简单的Java程序,用于从HDFS中读取一个文件:
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class HDFSReader {public static void main(String[] args) throws Exception {String localFilePath = "/home/user/data.txt";String hdfsFilePath = "/user/hadoop/data.txt";Configuration conf = new Configuration();FileSystem fs = FileSystem.get(conf);OutputStream out = new FileOutputStream(localFilePath);IOUtils.copyBytes(fs.open(new Path(hdfsFilePath)), out, conf);IOUtils.closeStream(out);}
}
该程序首先需要指定要读取的本地文件路径和HDFS文件路径,然后创建一个Configuration对象和FileSystem对象,以便与HDFS进行交互。接下来,使用open()方法打开HDFS中的文件,使用copyBytes()方法将文件的内容复制到本地文件中,并使用closeStream()方法关闭输出流。
四.总结
HDFS是一个高可靠、高可扩展、高吞吐量的分布式文件系统,适用于大规模的数据处理和批处理任务。它的设计理念就是针对大数据量的处理,因此不适合小文件存储和实时读写操作。HDFS已经被广泛地应用于大数据处理、数据分析等领域,例如Hadoop、Spark、HBase、Hive等。通过上述的代码实例,可以初步了解HDFS的基本操作方式。
当然,HDFS还有很多其他的高级特性,例如快照、权限控制、Federation等,这些特性在大规模集群中是非常有用的。如果您想要深入了解HDFS,可以继续学习Hadoop生态系统中的其他组件,例如YARN、MapReduce、Hive、Pig、Spark等。
在实际应用中,为了更好地管理和操作HDFS,还需要使用一些工具。例如,Hadoop自带的命令行工具hadoop fs,可以方便地操作HDFS中的文件和目录,例如创建目录、上传文件、下载文件等。此外,还有一些第三方的图形界面工具,例如Apache Ambari、Cloudera Manager、Hue等,可以更加直观地管理HDFS集群。
总之,HDFS是一个非常重要的分布式文件系统,是Hadoop生态系统的核心组件之一。了解和掌握HDFS的基本概念和操作方式,对于从事大数据处理和数据分析的工程师来说是非常必要的。
相关文章:
深入探究HDFS:高可靠、高可扩展、高吞吐量的分布式文件系统【上进小菜猪大数据系列】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。 引言 在当今数据时代,数据的存储和处理已经成为了各行各业的一个关键问题。尤其是在大数据领域,海量数据的存储和处理已经成为了一个不可避免的问题。为了应…...

GIMP制作艺术字技巧
GIMP下载官网 https://www.gimp.org/downloads/ 我使用的版本 2.10.32 字体下载 https://ziyouziti.com/index-index-all.html 下载解压之后会有otf、ttf等字体文件,需要拷贝到gimp当前用户目录 C:\Users\用户名\AppData\Roaming\GIMP\2.10\fonts GIMP绘制字…...
Redis 布隆过滤器总结
Redis 布隆过滤器总结 适用场景 大数据判断是否存在来实现去重:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1) 的级别,但是…...

云基础设施安全:7个保护敏感数据的最佳实践
导语:云端安全防护进行时! 您的组织可能会利用云计算的实际优势:灵活性、快速部署、成本效益、可扩展性和存储容量。但是,您是否投入了足够的精力来确保云基础设施的网络安全? 您应该这样做,因为数据泄露、…...

centos7安装nginx
1.配置环境 1).gcc yum install -y gcc2).安装第三方库 pcre-devel yum install -y pcre pcre-devel3).安装第三方库 zlib yum install -y zlib zlib-devel2.下载安装包并解压 nginx官网下载:http://nginx.org/en/download.html 或者 使用wget命令进行下载 wg…...
PyQt5 基础篇(一)-- 安装与环境配置
1 PyQt5 图形界面开发工具 Qt 库是跨平台的 C 库的集合,是最强大的 GUI 库之一,可以实现高级 API 来访问桌面和移动系统的各种服务。PyQt5 是一套 Python 绑定 Digia QT5 应用的框架。PyQt5 实现了一个 Python模块集,有 620 个类,…...
Java—JDK8新特性—函数式接口【内含思维导图】
目录 3.函数式接口 思维导图 3.1 什么是函数式接口 3.2 functionalinterface注解 源码分析 3.3 Lambda表达式和函数式接口关系 3.4 使用函数式接口 3.5 内置函数式接口 四大核的函数式接口区别 3.5.1 Supplier 函数式接口源码分析 3.5.2 Supplier 函数式接口使用 3.…...
【MySQL】外键约束和外键策略
一、什么是外键约束? 外键约束(FOREIGN KEY,缩写FK)是用来实现数据库表的参照完整性的。外键约束可以使两张表紧密的结合起来,特别是针对修改或者删除的级联操作时,会保证数据的完整性。 外键是指表…...
3. SQL底层执行原理详解
一条SQL在MySQL中是如何执行的 1. MySQL的内部组件结构1.1 Server层1.2 Store层 2. 连接器3. 分析器4. 优化器5. 执行器6. bin-log归档 本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。 1. MySQL的内部组件结…...
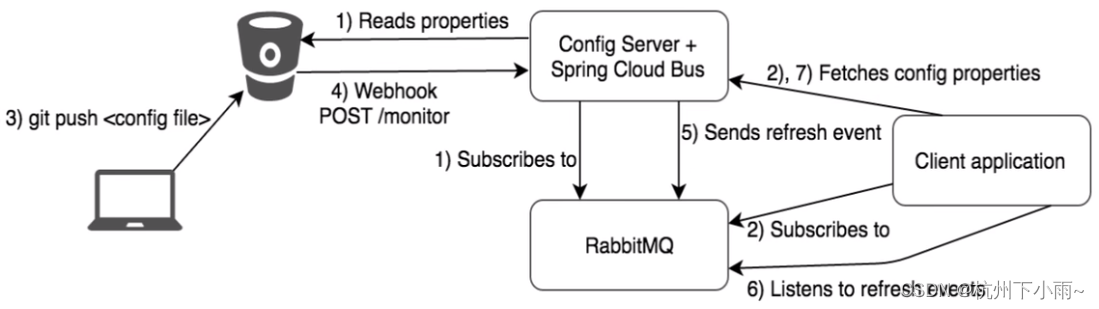
Bus动态刷新
Bus动态刷新全局广播配置实现 启动 EurekaMain7001ConfigcenterMain3344ConfigclientMain3355ConfigclicntMain3366 运维工程师 修改Gitee上配置文件内容,增加版本号发送POST请求curl -X POST "http://localhost:3344/actuator/bus-refresh" —次发送…...

逆波兰式的写法
一、什么是波兰式,逆波兰式和中缀表达式 6 *(37) -2 将运算数放在数值中间的运算式叫做中缀表达式 - * 6 3 7 2 将运算数放在数值前间的运算式叫做前缀表达式 6 3 7 * 2 - 将运算数放在数值后间的运算式叫做后缀表达式 二、生成逆波兰表达式 6 *(37) -2 生成…...

Linux系统日志介绍
Linux系统日志都是放在“/var/log”目录下面,各个日志文件的功能: /var/log/messages — 包括整体系统信息,其中也包含系统启动期间的日志。此外,mail,cron,daemon,kern和auth等内容也记录在va…...
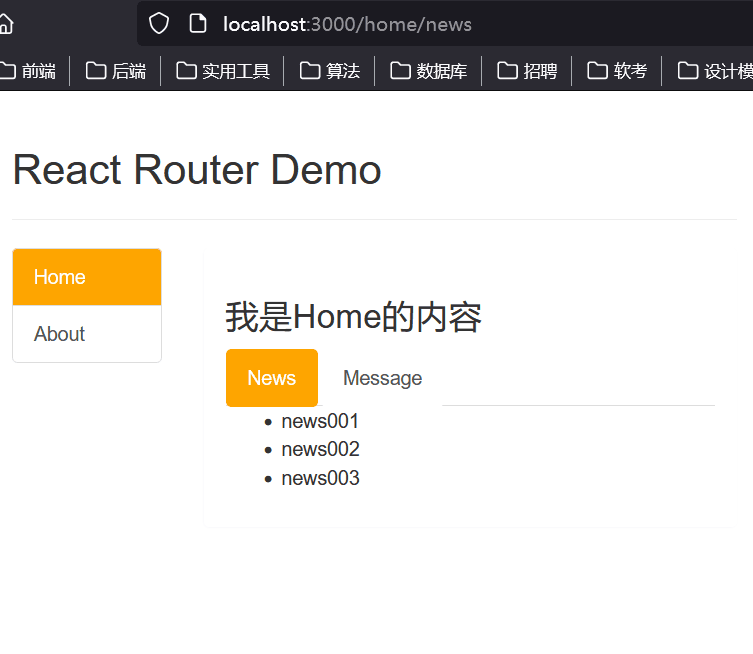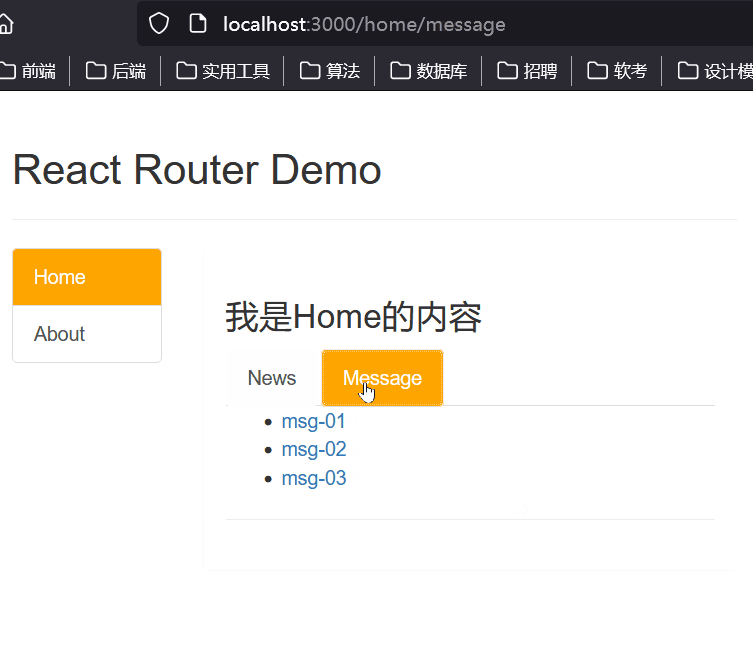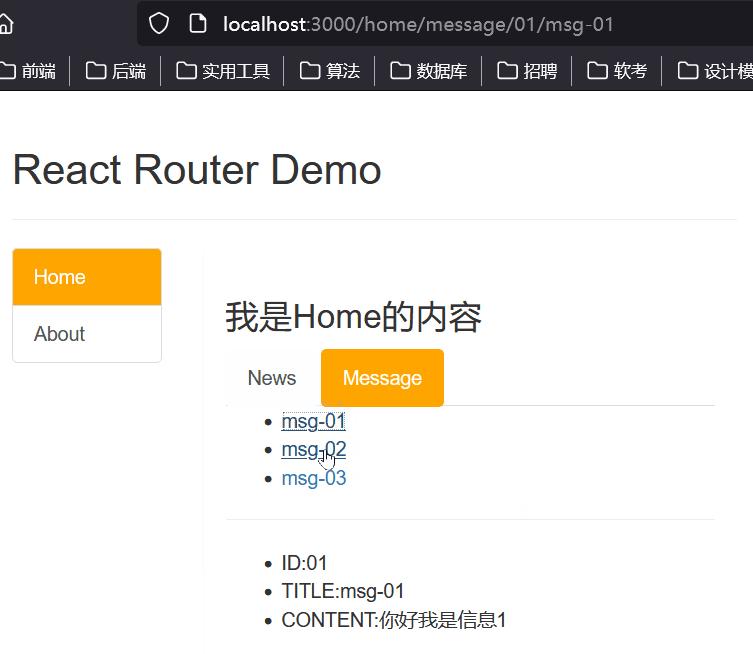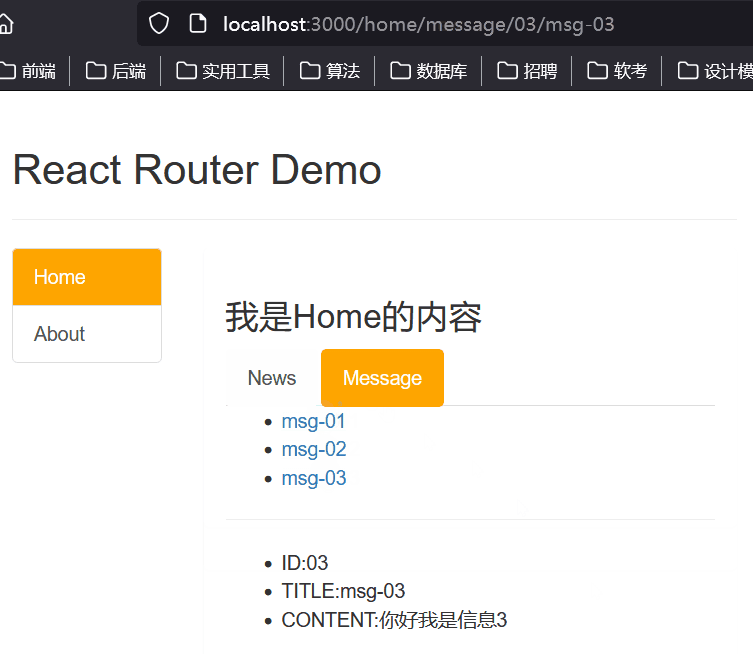
第三十二章 React路由组件的简单使用
1、NavLink的使用 一个特殊版本的 Link,当它与当前 URL 匹配时,为其渲染元素添加样式属性 <NavLink className"list-group-item" to"/home">Home</NavLink> <NavLink className"list-group-item" to&quo…...

“裸奔”时代下,我们该如何保护网络隐私?
当我们在互联网上进行各种活动时,我们的个人信息和数据可能会被攻击者窃取或盗用。为了保护我们的隐私和数据安全,以下是一些实用的技巧和工具,可以帮助您应对网络攻击、数据泄露和隐私侵犯的问题: 使用强密码:使用独特…...

c#笔记-方法
方法 方法定义 方法可以将一组复杂的代码进行打包。 声明方法的语法是返回类型 方法名 括号 方法体。 void Hello1() {for (int i 0; i < 10; i){Console.WriteLine("Hello");} }调用方法 方法的主要特征就是他的括号。 调用方法的语法是方法名括号。 He…...
)
054、牛客网算法面试必刷TOP101--堆/栈/队列(230509)
文章目录 前言堆/栈/队列1、BM42 用两个栈实现队列2、BM43 包含min函数的栈3、BM44 有效括号序列4、BM45 滑动窗口的最大值5、BM46 最小的K个数6、BM47 寻找第K大7、BM48 数据流中的中位数8、BM49 表达式求值 其它1、se基础 前言 提示:这里可以添加本文要记录的大概…...
怎么让chatGTP写论文-chatGTP写论文工具
chatGTP如何写论文 ChatGPT是一个使用深度学习技术训练的自然语言处理模型,可以用于生成自然语言文本,例如对话、摘要、文章等。作为一个人工智能技术,ChatGPT可以帮助你处理一些文字内容,但并不能代替人类的创造性思考和判断。以…...

springboot 断点上传、续传、秒传实现
文章目录 前言一、实现思路二、数据库表对象二、业务入参对象三、本地上传实现三、minio上传实现总结 前言 springboot 断点上传、续传、秒传实现。 保存方式提供本地上传(单机)和minio上传(可集群) 本文主要是后端实现方案&…...
2023河南省赛vp题解
目录 A题: B题 C题 D题 E题 F题 G题 H题 I题 J题 K题 L题 A题: 1.思路:考虑暴力枚举和双hash,可以在O(n)做完。 2.代码实现: #include<bits/stdc.h> #define sz(x) (int) x.size() #define rep(i,z,…...

港科夜闻|香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地。“港科资管通领航基金”28日在香港成立,将致力于推动高校科研成果转化,助力香港国际创科中心建设。…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...
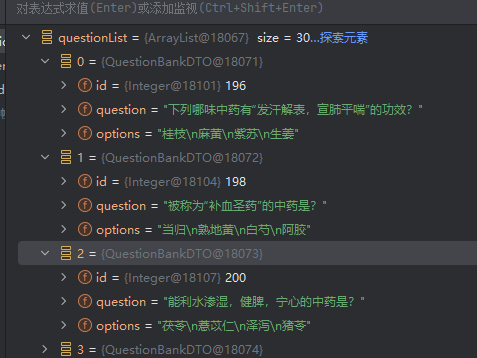
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...

Python 高级应用10:在python 大型项目中 FastAPI 和 Django 的相互配合
无论是python,或者java 的大型项目中,都会涉及到 自身平台微服务之间的相互调用,以及和第三发平台的 接口对接,那在python 中是怎么实现的呢? 在 Python Web 开发中,FastAPI 和 Django 是两个重要但定位不…...