【RabbitMQ】安装及六种模式
文章目录
- 安装rabbitmq镜像
- 访问容器内部15672端口映射到外面的端口地址
- RabbitMQ六种模式
- Hello world模式
- Work queues模式
- Publish/Subscribe模式
- 交换机
- fanout类型
- Routing模式
- Topics模式
- RPC模式
rabbitmq:0->1的学习
学习文档:https://www.cnblogs.com/guyuyun/p/14970592.html
安装rabbitmq镜像
cd /home/rabbitmqdocker run -d \
-v ./data:/var/lib/rabbitmq \
-p 5672:5672 -p 5673:15672 --name rabbitmq --restart=always \
--hostname myRabbit rabbitmq:3.9.12-management

访问容器内部15672端口映射到外面的端口地址
这里是127.0.0.1:5673
默认账号密码:账号 guest , 密码 guest

RabbitMQ六种模式
Hello world模式

Hello world模式是最简单的一种模式,一个producer发送message,另一个consumer接收message。
-
producer示例
send.py:producer端发送message会涉及最简单的5个步骤,具体见代码注释。import pika# 1. 创建一个到RabbitMQ server的连接,如果连接的不是本机, # 则在pika.ConnectionParameters中传入具体的ip和port即可,默认端口开放为5672,可以不传 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', port)) # 2. 创建一个channel channel = connection.channel() # 3. 创建队列,queue_declare可以使用任意次数, # 如果指定的queue不存在,则会创建一个queue,如果已经存在, # 则不会做其他动作,官方推荐,每次使用时都可以加上这句 channel.queue_declare(queue='hello') # 4. 发布消息 channel.basic_publish(exchange='', # RabbitMQ中所有的消息都要先通过交换机,空字符串表示使用默认的交换机routing_key='hello', # 指定消息要发送到哪个queuebody='Hello world!') # 消息的内容 # 5. 关闭连接 connection.close() -
consumer示例
receive.py:consumer端接收message会涉及最简单的6个步骤,具体见代码注释。import pikadef main():# 1. 创建一个到RabbitMQ server的连接,如果连接的不是本机,# 则在pika.ConnectionParameters中传入具体的ip和port即可connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))# 2. 创建一个channelchannel = connection.channel()# 3. 创建队列,queue_declare可以使用任意次数,# 如果指定的queue不存在,则会创建一个queue,如果已经存在,# 则不会做其他动作,官方推荐,每次使用时都可以加上这句channel.queue_declare(queue='hello')# 4. 定义消息处理程序def callback(ch, method, properties, body):print('[x] Received %r' % body)# 5. 接收来自指定queue的消息channel.basic_consume(queue='hello', # 接收指定queue的消息on_message_callback=callback, # 接收到消息后的处理程序auto_ack=True) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息print('[*] Waiting for message.')# 6. 开始循环等待,一直处于等待接收消息的状态channel.start_consuming()if __name__ == '__main__':main()
Work queues模式
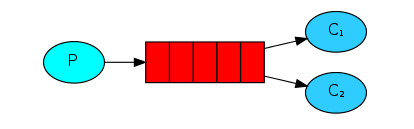
Work queues模式即工作队列模式,也称为Task queues模式(任务队列模式),这个模式的特点在于,同一个queue可以允许多个consumer从中获取massage,RabbitMQ默认会从queue中依次循环的给不同的consumer发送message。与Hello world模式相比,工作队列模式在示例代码中有些许不同
- hello world模式中指定了
auto_ack=True,表示consumer接收到message之后自动发送确认标识,告诉RabbitMQ可以从队列中移除该条message了。工作队列模式下,使用了默认值,即需要手动确认ch.basic_ack(delivery_tag=method.delivery_tag)。- hello world模式中只有一个consumer去处理queue中的message,工作队列模式中可以有多个consumer去处理queue中的message。
- 工作队列模式中可以使message持久化,保证RabbitMQ服务挂掉之后message依然不被丢失。
- 工作队列模式中可以手动标记message已接收并处理完成(这一步在编程时千万别忘了,否则RabbitMQ会认为该条message没有被处理,会一直保留在队列中,并适时发送到别的consumer中)。
-
producer示例
new_task.py:注意如果声明queue时参数不一样,则建议换一个名称,因为RabbitMQ中不允许同名但实际上是不同的两个queue存在,比如指定了durable=True参数。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 声明durable=True可以保证RabbitMQ服务挂掉之后队列中的消息也不丢失,原理是因为 # RabbitMQ会将queue中的消息保存到磁盘中 channel.queue_declare(queue='task_queue')message = 'Hello World! 555' channel.basic_publish(exchange='',routing_key='task_queue',body=message,# delivery_mode=2可以指定此条消息持久化,防止RabbitMQ服务挂掉之后消息丢失# 但是此属性设置并不能百分百保证消息真的被持久化,因为RabbitMQ挂掉的时候# 它可能还保存在缓存中,没来得及同步到磁盘中# properties=pika.BasicProperties(delivery_mode=2) ) print(" [x] Sent %r" % message) connection.close() -
consumer示例
worker.py:RabbitMQ会将queue中的消息依次发送给不同的consumer,所以这里的示例可以用同样的代码多开几个客户端进行测试。import pika import timeconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 声明durable=True可以保证RabbitMQ服务挂掉之后队列中的消息也不丢失,原理是因为 # RabbitMQ会将queue中的消息保存到磁盘中 channel.queue_declare(queue='task_queue') print(' [*] Waiting for messages.')def callback(ch, method, properties, body):print(" [x] Received %r" % body.decode())# 此处以消息中的“.”的数量作为sleep的值,是为了模拟不同消息处理的耗时time.sleep(body.count(b'.'))print(" [x] Done")# 手动标记消息已接收并处理完毕,RabbitMQ可以从queue中移除该条消息ch.basic_ack(delivery_tag=method.delivery_tag)# prefetch_count表示接收的消息数量,当我接收的消息没有处理完(用basic_ack # 标记消息已处理完毕)之前不会再接收新的消息了 channel.basic_qos(prefetch_count=1) channel.basic_consume(queue='task_queue', on_message_callback=callback)channel.start_consuming()
Publish/Subscribe模式

相对于工作/任务模式中的一个message只能发送给一个consumer使用,发布订阅模式会将一个message同时发送给多个consumer使用,其实就是producer将message广播给所有的consumer。
交换机
这个模式中会引入交换机(exchange)的概念,其实在RabbitMQ中,所有的producer都不会直接把message发送到queue中,甚至producer都不知道message在发出后有没有发送到queue中,事实上,producer只能将message发送给exchange,由exchange来决定发送到哪个queue中。
exchange的一端用来从producer中接收message,另一端用来发送message到queue,exchange的类型规定了怎么处理接收到的message,发布订阅模式使用到的exchange类型为
fanout,这种exchange类型非常简单,就是将接收到的message广播给已知的(即绑定到此exchange的)所有consumer。
当然,如果不想使用特定的exchange,可以使用
exchange=''表示使用默认的exchange,默认的exchange会将消息发送到routing_key指定的queue,可以参考工作(任务)队列模式和Hello world模式。
fanout类型
在使用fanout类型的exchange时,并不是只有一个queue,然后将queue中的message每个consumer都发一份,而是会为每个已知(绑定)的consumer创建一个queue,然后广播message到对应queue中,fanout类型的exchange会将从生产者接收到的message广播到所有的绑定到自己的queue中,这个queue通常是由consumer端指定的专属于consumer自己的、由RabbitMQ随机命名的queue,由此,consumer广播message后,每个consumer都能收到同样的一条message了。
consumer端需要为自己生成一个专属于自己的由RabbitMQ随机命名的queue,然后绑定到fanout类型的exchange上,由此,exchange才知道将message广播给哪些已经绑定到自己的queue。
-
示例
emit_log.py:用于生成一条日志信息,然后广播给所有consumer。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 创建一个指定名称的交换机,并指定类型为fanout,用于将接收到的消息广播到所有queue中 channel.exchange_declare(exchange='logs', exchange_type='fanout')message = "info: Hello World!" # 将消息发送给指定的交换机,在fanout类型中,routing_key=''表示不用发送到指定queue中, # 而是将发送到绑定到此交换机的所有queue channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close() -
示例
receive_logs.py:这个程序可以多运行几个,表示有多个consumer需要使用producer发送的消息。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 指定交换机 channel.exchange_declare(exchange='logs', exchange_type='fanout')# 使用RabbitMQ给自己生成一个专有的queue result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue# 将queue绑定到指定交换机 channel.queue_bind(exchange='logs', queue=queue_name)print(' [*] Waiting for logs.')def callback(ch, method, properties, body):print(" [x] %r" % body)channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)channel.start_consuming()
Routing模式
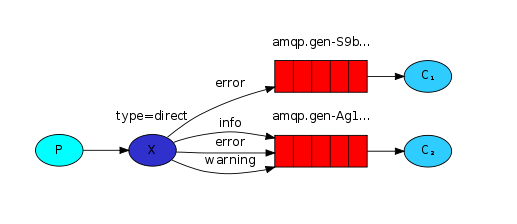
路由模式中,exchange类型为direct,与发布订阅模式相似,但是不同之处在于,发布订阅模式将message不加区分广播给所有的绑定queue,但是路由模式中,允许queue在绑定exchange时,同时指定 routing_key ,exchange就只会发送message到与 routing_key 匹配的queue中,其他的所有message都将被丢弃。当然,也允许多个queue指定相同的 routing_key ,此时效果就相当于fanout类型的发布订阅模式了。
producer端:从代码上看,路由模式和订阅模式非常相似,唯一不同的是,exchange类型为direct,且发送message时多了一个routing_key参数,exchange会根据routing_key将message发送到对应的queue中。
-
示例
emit_log_direct.py:发送不同级别的日志消息到queue中,不同的consumer根据自己指定的routing_key接收message。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 指定交换机名称和类型 channel.exchange_declare(exchange='direct_logs', exchange_type='direct')# severity = 'info' # severity = 'warning' severity = 'error' message = 'Hello World!'# 与fanout类型的发布订阅模式相比,只是多了一个routing_key参数 # 交换机会根据routing_key将消息发送到对应的queue中 channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
consumer端:在路由模式中,不同的queue可以指定相同的routing_key,同一个queue也可以指定多个routing_key,从exchange角度看,它知道所有绑定到自己的queue,也知道每个queue指定的routing_key,发送消息时,只需要根据queue的routing_key进行发送即可。
-
示例
receive_logs_direct.py:这个程序可以多运行几个,每个程序指定接收不同日志级别的消息。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 指定交换机名称和类型 channel.exchange_declare(exchange='direct_logs', exchange_type='direct')# 使用RabbitMQ给自己生成一个专属于自己的queue result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue# 绑定queue到交换机,并指定自己只接受哪些routing_key # 可以都接收,也可以只接收一种 # for severity in ['error', 'warning', 'info']: for severity in ['error']:channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)channel.start_consuming()
Topics模式

主题模式的exchange类型为topic,相较于路由模式,主题模式更加灵活,区别就在于它的routing_key可以带通配符 * (匹配一个单词)和 # (匹配0个或多个单词),每个单词以点号分隔,但注意,routing_key的总大小不能超过255个字节。
如果一个message同时匹配了多个queue中的routing_key,那这几个queue都会收到这个message,如果一个message同时匹配了一个queue中的多个routing_key,那这个queue也只会接收一次这条message,如果一个message没有匹配上任何routing_key,那么这个message将被丢弃。
如果routing_key定义为 # (就只有这一个通配符),那么这个queue将接收所有message,就像exchange类型为fanout的发布订阅模式一样,如果routing_key两个通配符都没有使用,那么这个queue将会接收固定routing_key的message,就像exchange类型为direct的路由模式一样。
producer端:从代码上讲,producer的代码与路由模式没什么区别,只不过在routing_key的传值上需要注意与想要发送到的queue进行匹配。
-
示例
emit_log_topic.py:还是发送日志消息的示例,不过消息类型不再只有级别这一种类型,还添加了发送者的信息,级别与发送者之间以点号分隔。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 指定交换机名称和类型 channel.exchange_declare(exchange='topic_logs', exchange_type='topic')# 以点号分隔每个单词 routing_key = 'anonymous.error' message = 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
consumer端:consumer根据需要,使用星号
*和井号#两个通配符对routing_key进行特定主题的匹配,其余部分与路由模式则是一致的。
-
示例
receive_logs_topic.py: 这个程序可以多运行几个,每个程序使用通配符指定不同的主题。import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel()# 指定交换机名称和类型 channel.exchange_declare(exchange='topic_logs', exchange_type='topic')# 使用RabbitMQ给自己生成一个专属于自己的queue result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue# 可以绑定多个routing_key,routing_key以点号分隔每个单词 # *可匹配一个单词,#可以匹配0个或多个单词 for binding_key in ['anonymous.*']:channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)channel.start_consuming()
RPC模式

RPC远程调用(Remote Procedure Call)模式其实就是使用消息队列处理请求的一种方式,通常请求接收到后会立即执行且多个请求是并行执行的,如果一次性来了太多请求,达到了服务端处理请求的瓶颈就会影响性能,但是如果使用消息队列的方式,最大的一点好处是可以不用立即处理请求,而是将请求放入消息队列,服务端只需要根据自己的状态从消息队列中获取并处理请求即可。
producer端:RPC模式的客户端(producer)需要使用到两个queue,一个用于发送request消息(此queue通常在服务端声明和创建),一个用于接收response消息。另外需要特别注意的一点是,需要为每个request消息指定一个uuid(correlation_id属性,类似请求id),用于识别返回的response消息是否属于对应的request。
-
示例
rpc_client.pyimport pika import uuidclass FibonacciRpcClient(object):def __init__(self):self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))self.channel = self.connection.channel()# 创建一个此客户端专用的queue,用于接收服务端发过来的消息result = self.channel.queue_declare(queue='', exclusive=True)self.callback_queue = result.method.queueself.channel.basic_consume(queue=self.callback_queue,on_message_callback=self.on_response,auto_ack=True)def on_response(self, ch, method, props, body):# 判断接收到的response是否属于对应requestif self.corr_id == props.correlation_id:self.response = bodydef call(self, n):self.response = Noneself.corr_id = str(uuid.uuid4()) # 为该消息指定uuid,类似于请求idself.channel.basic_publish(exchange='',routing_key='rpc_queue', # 将消息发送到该queueproperties=pika.BasicProperties(reply_to=self.callback_queue, # 从该queue中取消息correlation_id=self.corr_id, # 为此次消息指定uuid),body=str(n))while self.response is None:self.connection.process_data_events()return int(self.response)fibonacci_rpc = FibonacciRpcClient()print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(30) print(" [.] Got %r" % response)
consumer端:服务端也需要使用到两个queue,一个接收request消息(通常由服务端创建),一个发送response消息(通常由客户端创建),需要特别注意,发送response消息时需要将对应request的uuid(correlation_id属性)赋上。
-
示例
rpc_server.pyimport pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()# 指定接收消息的queue channel.queue_declare(queue='rpc_queue')def fib(n):if n == 0:return 0elif n == 1:return 1else:return fib(n - 1) + fib(n - 2)def on_request(ch, method, props, body):n = int(body)print(" [.] fib(%s)" % n)response = fib(n)ch.basic_publish(exchange='', # 使用默认交换机routing_key=props.reply_to, # response发送到该queueproperties=pika.BasicProperties(correlation_id=props.correlation_id), # 使用correlation_id让此response与请求消息对应起来body=str(response))ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1) # 从rpc_queue中取消息,然后使用on_request进行处理 channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)print(" [x] Awaiting RPC requests") channel.start_consuming()
相关文章:
【RabbitMQ】安装及六种模式
文章目录 安装rabbitmq镜像访问容器内部15672端口映射到外面的端口地址RabbitMQ六种模式Hello world模式Work queues模式Publish/Subscribe模式交换机fanout类型 Routing模式Topics模式RPC模式 rabbitmq:0->1的学习 学习文档:https://www.cnblogs.com…...

数据结构刷题(三十一):1049. 最后一块石头的重量 II、完全背包理论、518零钱兑换II
一、1049. 最后一块石头的重量 II 1.思路:01背包问题,其中dp[j]表示容量为j的背包,最多可以背最大重量为dp[j]。 2.注意:递推公式dp[j] max(dp[j], dp[j - stones[i]] stones[i]);本题中的重量就是价值,所以第二个…...

opencv_c++学习(四)
图像在opencv中的存储方式 在上图中可以看出,在opencv中采用的是像素值来代表每一个像素三通道颜色的深浅。 Mat对象 Mat对象是在OpenCV2.0之后引进的图像数据结构、自动分配内存、不存在内存泄漏的问题,是面向对象的数据结构。分了两个部分࿰…...

基于AT89C51单片机的篮球计时记分设计
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/87771065 源码获取 主要内容: 基于51单片机设计篮球计时计分器,结合单片机串行接口原理,用AT89C51设计一个篮球比赛计分计时器,能够通过数码管显示分数和比赛时间(并设有…...

并发编程-Day2
并发编程 1.共享模型-内存 共享变量在多线程间的<可见性>问题与多条指令执行时的<有序性>问题 1.1Java内存模型 JMM它定义了主存、工作内存抽象概念,底层对应着CPU寄存器、缓存、硬件内存CPU指令优化等. JMM体现在: 原子性-保证指令不会受到线程上…...

第1章 Nginx简介
基于 Nginx版本 1.14.2 ,Tomcat版本 9.0.0 演示 第1章 Nginx简介 1.1 Nginx发展介绍 Nginx (engine x) 是一个高性能的Web服务器和反向代理服务器,也可以作为邮件代理服务器。 Nginx 特点是占有内存少,并发处理能力…...
一个.Net功能强大、易于使用、跨平台开源可视化图表
可视化图表运用是非常广泛的,比如BI系统、报表统计等。但是针对桌面应用的应用,很多报表都是收费的,今天给大家推荐一个免费.Net可视化开源的项目! 项目简介 基于C#开发的功能强大、易于使用、跨平台高质量的可视化图表库&#…...

浅谈 ext2 文件系统的特点、优缺点以及使用场景
ext2(Extended File System 2)是 Linux 中最早的一种文件系统,它是 Linux 文件系统的基础,也被广泛用于其他类 Unix 系统中。下面是 ext2 文件系统的特点、优缺点以及使用场景: 特点: ext2 文件系统可以支…...

Map和Set数据结构和ES6模块化语法
Map和Set数据结构 ●ES6 新增的两种数据结构 ●共同的特点: 不接受重复数据 Set数据结构 ●是一个 类似于 数组的数据结构 ●按照索引排列的数据结构 创建 Set 数据结构 语法: var s new Set([ 数据1, 数据2, 数据3, ... ]) Set 数据结构的属性和方法 ●size 属性 ○语法: 数…...

10_Uboot启动流程_2
目录 _main函数详解 board_init_f函数详解 relocate_code函数详解 relocate_vectors函数详解 board_init_r 函数详解 _main函数详解 在上一章得知会执行_main函数_main函数定义在文件arch/arm/lib/crt0.S 中,函数内容如下: 第76行,设置sp指针为CONFIG_SYS_INIT_SP_ADDR,也…...
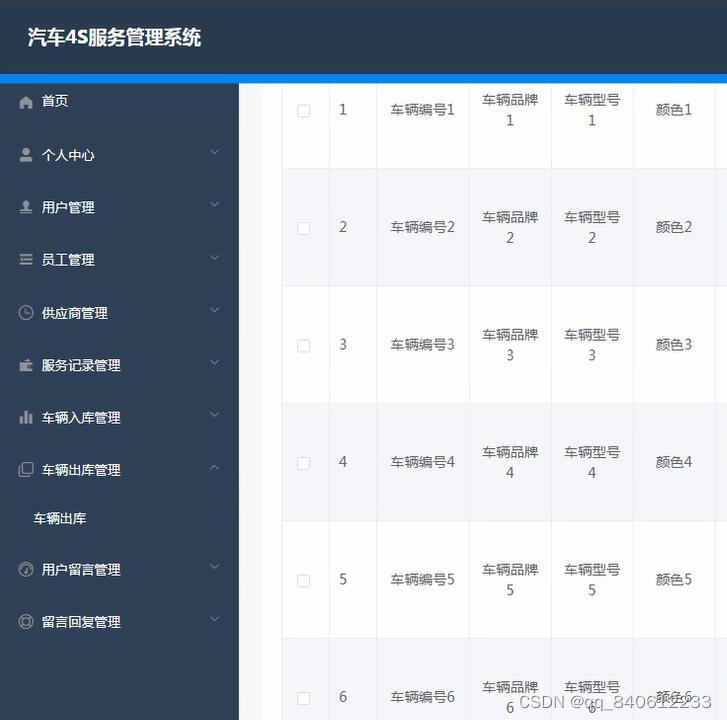
python+django汽车4S店零配件保养服务管理系统
汽车4S服务管理系统包括三种用户。管理员、普通员工、客户。 开发语言:Python 框架:django/flask Python版本:python3.7.7 数据库:mysql 数据库工具:Navicat 开发软件:PyCharm django 应用目录结构管…...

STM32F4的输出比较极性和PWM1,PWM2的关系
PWM 输出比较通道 在这里以通用定时器的通道1作为介绍。 如图,左边就是CNT计数器和CCR1第一路的捕获/比较寄存器,它俩进行比较,当CNT>CCR1, 或者CNTCCR1时,就会给输出模式控制器传送一个信号,然后输出模式控制器就…...

易优cms伪静态,EyouCms去除URL中的index.php
针对不同服务器、虚拟空间,运行PHP的环境也有所不同,目前主要分为:Nginx、apache、IIS以及其他服务器。下面分享如何去掉URL上的index.php字符,记得在管理后台清除缓存,对于一些ECS服务器可能要重启nginx等服务! 【Nginx服务器】 在原有的nginx重写文件里新增以下代码片…...
【自然语言处理】【大模型】CodeGeeX:用于代码生成的多语言预训练模型
CodeGeeX:用于代码生成的多语言预训练模型 《CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X》 论文地址:https://arxiv.org/pdf/2303.17568.pdf 相关博客 【自然语言处理】【大模型】CodeGen&#x…...

Open3D 非线性最小二乘拟合二维多项式曲线
目录 一、算法原理二、代码实现三、结果展示一、算法原理 多项式曲线表示为: p ( x ) = p 1 x n + p 2 x n...

kafka消息队列的两种模式
第一种模式: 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 1.消息生产者生产消息发送给队列,然后消费者从队列中取出并且消费消息 2.消息被消费以后,queue中不再有存储࿰…...
python语法复习
print:输出函数 print(520)效果:输出520. print(hello)效果:输出hello. print(1020)【效果:输出了:1020】注:“ ”在print里面是一个连接符。 print(1020)【效果:输出了30】注: 在此处…...
02-Java基础编程
Java基础编程 Java 基础语法Java 标识符变量变量的类型Java 基本数据类型基本数据类型转换 运算符常见运算符运算符的优先级 程序流程控制分支语句循环结构常用的循环结构循环的嵌套break 和 continue 关键字 数组一维数组多维数组的使用Arrays 工具类的使用数组中常见的异常 J…...
)
武忠祥老师每日一题||定积分基础训练(十)
已知f(x)连续 ∫ 0 x t f ( x − t ) d t 1 − cos x , 求 ∫ 0 π 2 f ( x ) d x 的值。 \int_{0}^{x}tf(x-t)\,{\rm d}t1-\cos x,求\int_{0}^{\frac{\pi}{2}}f(x)dx的值。 ∫0xtf(x−t)dt1−cosx,求∫02πf(x)dx的值。 已知一个关于f的变上限积分等式,&…...
)
C/C++趣味程序设计百例(41~50)
C/C语言经典、实用、趣味程序设计编程百例精解(5) 41.马克思手稿中的数学题 马克思手稿中有一道趣味数学问题:有30个人,其中有男人、女人和小孩,在一家饭馆吃饭花了50先令;每个男人花3先令,每个…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...