神经网络的建立-TensorFlow2.x
要学习深度强化学习,就要学会使用神经网络,建立神经网络可以使用TensorFlow和pytorch,今天先学习以TensorFlow建立网络。
直接上代码
import tensorflow as tf# 定义神经网络模型
model = tf.keras.models.Sequential([tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 加载数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
model.evaluate(x_test, y_test)然后解释一下代码里的具体步骤
定义神经网络模型
当使用 tf.keras.models.Sequential 创建神经网络时,可以按顺序添加多个层,每个层都会顺序连接在一起,构成整个神经网络模型。在这个例子中,我们添加了两个全连接层(Dense层)和一个Dropout层。这个模型的结构如下所示:
输入层:由 tf.keras.layers.Dense(128, activation=‘relu’, input_shape=(784,)) 创建,包含128个神经元。输入数据的形状是 (None, 784),其中 None 表示任意的批次大小。激活函数为 ReLU。
Dropout层:由 tf.keras.layers.Dropout(0.2) 创建,其作用是随机断开一定比例的输入神经元,以防止过拟合。
输出层:由 tf.keras.layers.Dense(10) 创建,包含10个神经元,对应于10个分类。激活函数为空,因为我们将使用 logits 值来进行计算,而不是经过 softmax 转换后的概率。
因为我们没有指定激活函数的名称,所以默认情况下 Dense 层使用线性激活函数。由于我们需要 logits 值来计算交叉熵损失函数,因此输出层没有指定激活函数。
总的来说,这个模型是一个具有 1 个输入层,1 个输出层和 1 个 Dropout 层的简单全连接神经网络。
编译模型
在 TensorFlow 中,使用 compile() 方法来配置模型的训练过程,其中包括选择优化器、损失函数和评估指标等。
optimizer=‘adam’:指定使用 Adam 优化器进行模型训练。Adam 是一种常用的自适应学习率优化算法,可以更快地收敛和更好地处理不同的学习率。
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True):指定使用交叉熵损失函数来计算模型在训练期间的误差。在这里我们使用的是 SparseCategoricalCrossentropy,它适用于多分类问题且标签为整数编码的情况。由于输出层没有使用 softmax 激活函数,所以设置参数 from_logits=True,表示我们将使用 logits 值来计算交叉熵损失函数。
metrics=[‘accuracy’]:指定使用准确率作为模型的评估指标,以在训练期间监视模型的性能。我们可以指定多个评估指标,例如 metrics=[‘accuracy’, ‘mse’],以同时监视模型的准确率和均方误差。
这些配置将应用于后续的模型训练中。
然后直接从Keras这个高级API加载数据集,这里讲一下x_train和x_test
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
这两行代码是将输入的训练数据 x_train 和测试数据 x_test 进行预处理,使它们具有相同的数据形状和数据类型,并进行了归一化处理。
x_train.reshape(60000, 784):将训练数据的形状从原来的 (60000, 28, 28) 重塑为 (60000, 784),其中 784 表示每个图像的像素数量,也就是将每个图像转换为一个长度为 784 的一维数组。
.astype(‘float32’):将数据类型转换为浮点型,因为在后续的归一化处理中需要进行除法操作。
/ 255:将像素值的范围从原来的 0 到 255 之间的整数转换为 0 到 1 之间的浮点数。这是一种常见的归一化方法,它可以使得输入数据的数值范围更加稳定,更容易被神经网络学习。
这样处理后,训练数据 x_train 和测试数据 x_test 都变成了形状为 (60000, 784) 和 (10000, 784) 的浮点数数组。这样的数据可以作为神经网络的输入,并可以更好地被模型学习。60000和10000分别表示训练和测试的数据量。
最后训练模型
model.fit(x_train, y_train, epochs=5) 是用来训练模型的代码。它将训练数据集 x_train 和训练标签 y_train 作为输入,并对模型进行多轮(5 轮)的训练。
具体来说,fit() 方法将对模型进行以下操作:
按照指定的轮数(即 epochs=5)对整个数据集进行多次迭代训练。
在每一轮训练中,将数据集划分为多个小批量数据,每个小批量包含一定数量的样本(默认情况下是 32 个样本)。
使用优化器(在 model.compile() 中指定)对模型进行优化,即更新模型的权重和偏置以最小化损失函数。
计算在每个小批量数据上的损失值和评估指标值,并在屏幕上输出模型的训练进度信息。
在每一轮训练结束后,使用测试数据集进行模型评估(在 model.evaluate() 中指定)。
通过反复迭代训练,模型的权重和偏置将不断被更新,以使得模型能够更好地适应数据集,并获得更好的性能。
评估模型model.evaluate(x_test, y_test)
相关文章:

神经网络的建立-TensorFlow2.x
要学习深度强化学习,就要学会使用神经网络,建立神经网络可以使用TensorFlow和pytorch,今天先学习以TensorFlow建立网络。 直接上代码 import tensorflow as tf# 定义神经网络模型 model tf.keras.models.Sequential([tf.keras.layers.Dense…...

python基于卷积神经网络实现自定义数据集训练与测试
注意: 如何更改图像尺寸在这篇文章中,修改完之后你就可以把你自己的数据集应用到网络。如果你的训练集与测试集也分别为30和5,并且样本类别也为3类,那么你只需要更改图像标签文件地址以及标签内容(如下面两图所示&…...
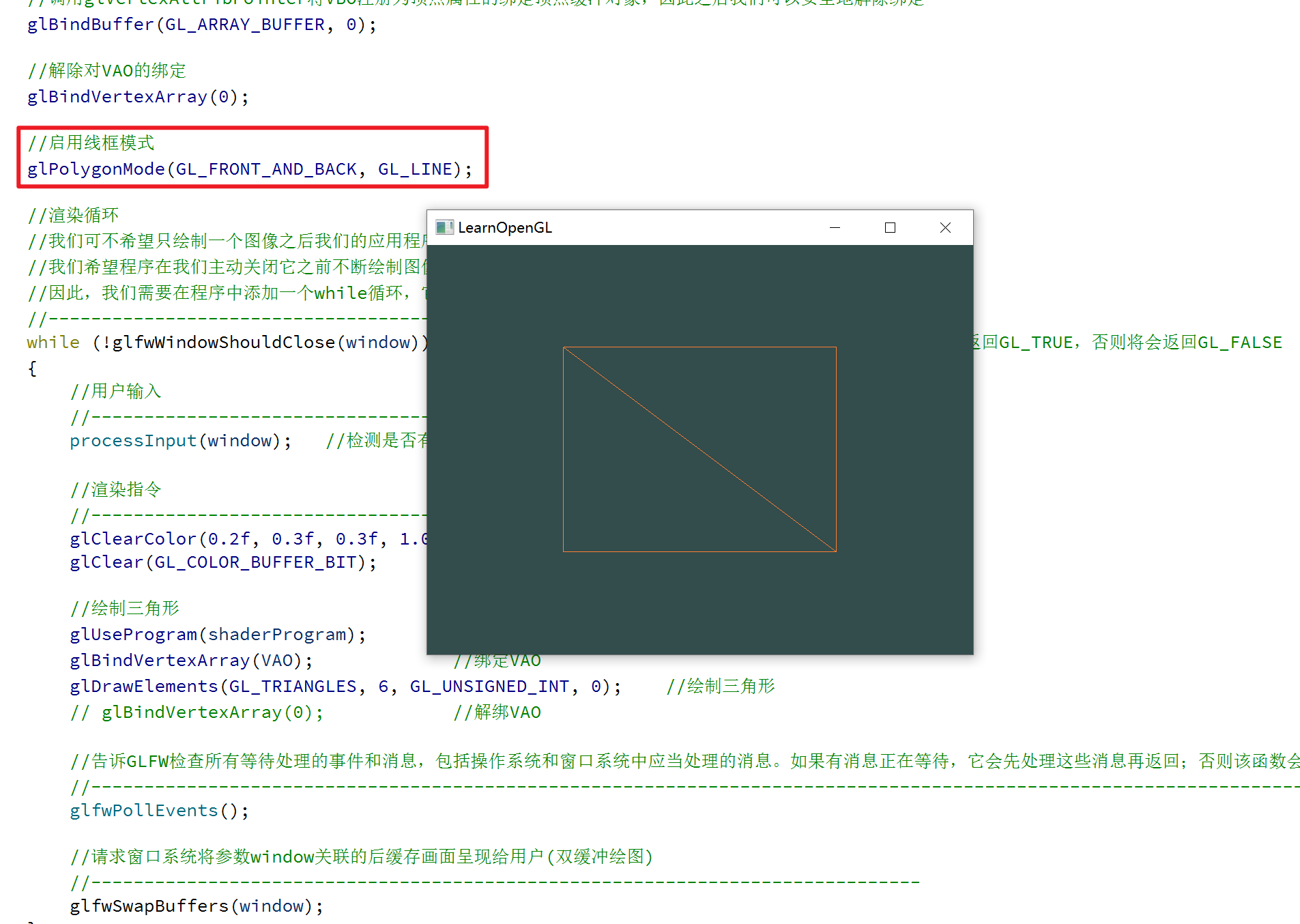
跟着LearnOpenGL学习3--四边形绘制
文章目录 一、前言二、元素缓冲对象三、完整代码四、绘制模式 一、前言 通过跟着LearnOpenGL学习2–三角形绘制一文,我们已经知道了怎么配置渲染管线,来绘制三角形; OpenGL主要处理三角形,当我们需要绘制别的图形时,…...

c#笔记-结构
装箱 结构是值类型。值类型不能继承其他类型,也不能被其他类型继承。 所以它的方法都是确定的,没有虚方法需要在运行时进行动态绑定。 值类型没有对象头,方法调用由编译器直接确定。 但是,如果使用引用类型变量(如接…...

Es分布式搜索引擎
目录 一、什么是ES? 二、什么是elk? 三、什么是倒排索引? 四、正向索引和倒排索引的优缺点对比 五、mysql数据库和es的区别? 六、索引库(es中的数据库表)操作有哪些? 八、ES分片存储原理 …...
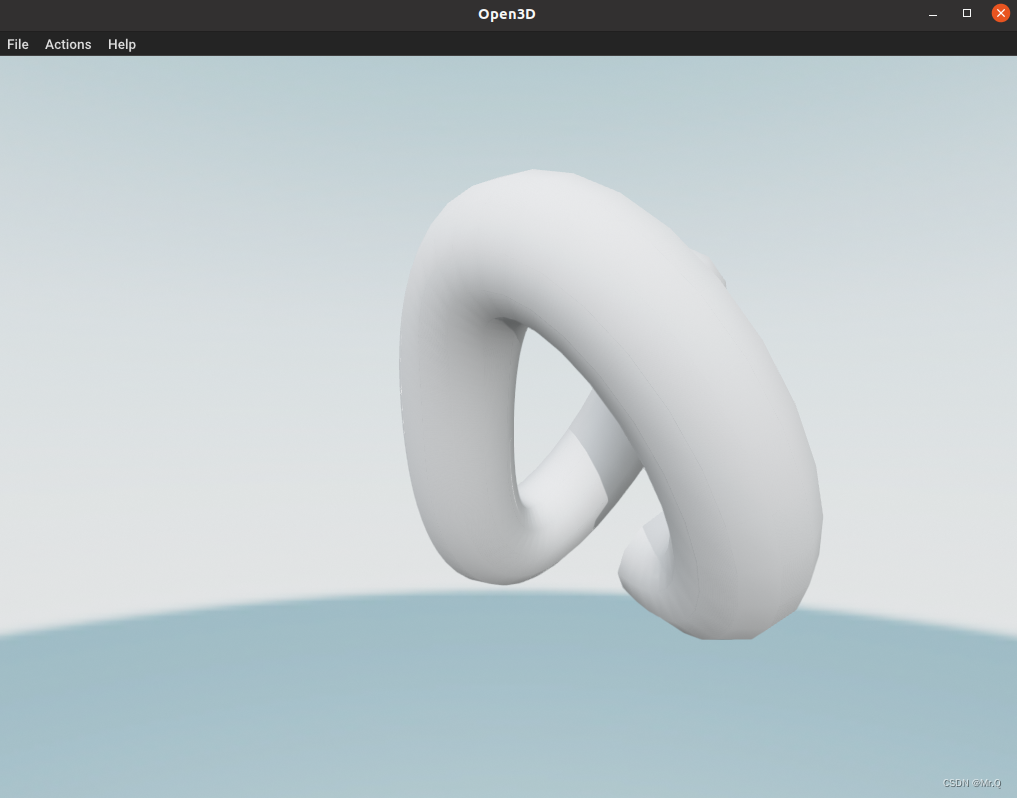
open3d 裁剪点云
目录 1. crop_point_cloud 2. crop 3. crop_mesh 1. crop_point_cloud 关键函数 chair vol.crop_point_cloud(pcd) # vol: SelectionPolygonVolume import open3d as o3dif __name__ "__main__":# 1. read pcdprint("Load a ply point cloud, crop it…...

如何对第三方相同请求进行筛选过滤
文章目录 问题背景处理思路注意事项代码实现 问题背景 公司内部多个系统共用一套用户体系库,对外(钉钉)我们是两个客户身份(这里是根据系统来的),例如当第三方服务向我们发起用户同步请求:是一个更新用户操作,它会同时发送一个 d…...

Go RPC
目录 文章目录 Go RPCHTTP RPCTCP RPCJSON RPC Go RPC Go 标准包中已经提供了对 RPC 的支持,而且支持三个级别的 RPC:TCP、HTTP、JSONRPC。但 Go 的 RPC 包是独一无二的 RPC,它和传统的 RPC 系统不同,它只支持 Go 开发的服务器与…...

真正的智能不仅仅是一个技术问题
智能并不是单一的技术问题,而是一个包括技术、人类智慧、社会制度和文化等多个方面的综合体,常常涉及技术变革、系统演变、运行方式创新、组织适应。智能是指人类的思考、判断、决策和创造等高级认知能力,可以通过技术手段来实现增强和扩展。…...

【数据结构】复杂度包装泛型
目录 1.时间和空间复杂度 1.1时间复杂度 1.2空间复杂度 2.包装类 2.1基本数据类型和对应的包装类 2.2装箱和拆箱 //阿里巴巴面试题 3.泛型 3.1擦除机制 3.2泛型的上界 1.时间和空间复杂度 1.1时间复杂度 定义:一个算法所花费的时间与其语句的执行次数成…...

Ae:绘画面板
Ae菜单:窗口/绘画 Paint 快捷键:Ctrl 8 绘画工具(画笔工具、仿制图章工具及橡皮擦工具)仅能工作在图层面板上。在使用绘画工具之前,建议先在绘画 Paint面板中查看或进行相关设置。 说明: 如果要在绘画描边…...
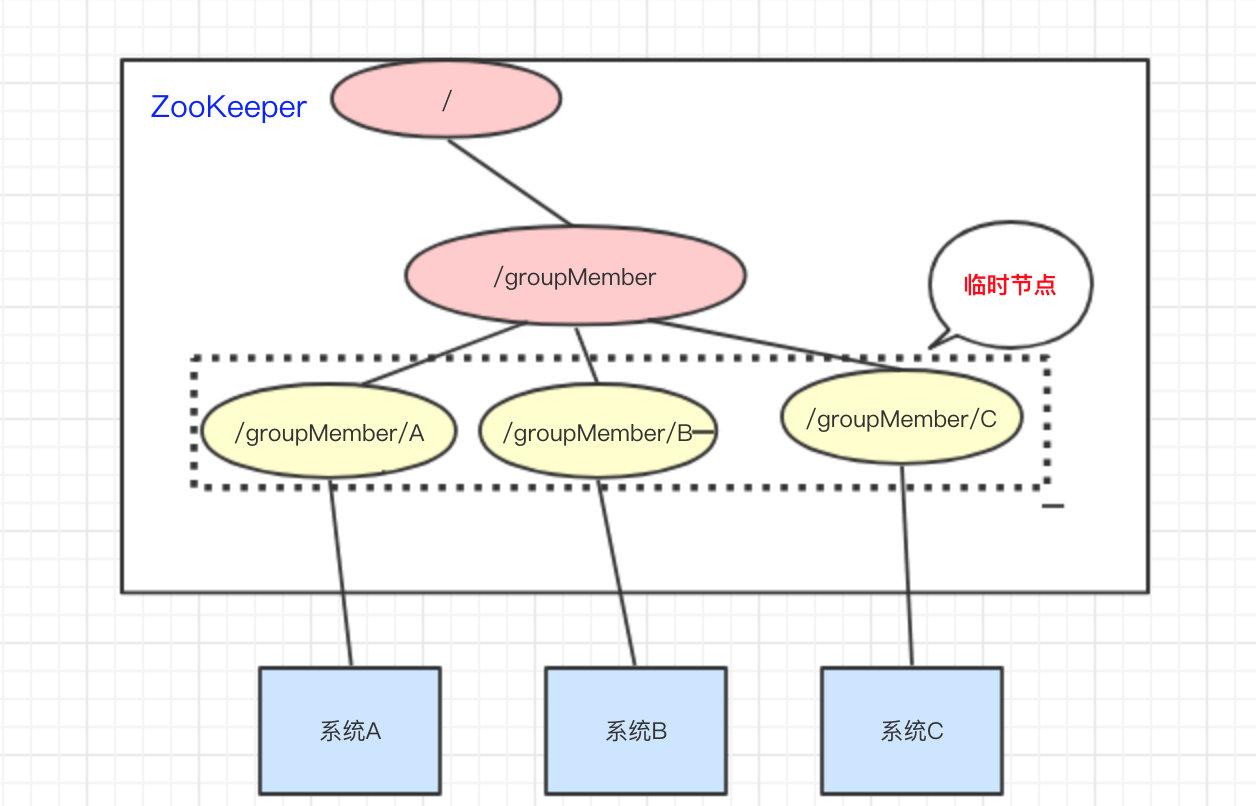
常见的锁和zookeeper
zookeeper 本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com 前言 只有光头才能变强。 文本已收录至我的 GitHub 仓库,欢迎 Star:https://github.com/ZhongFuCheng3y/3y 上次写了一篇 什么是消息队列?以后,本来…...
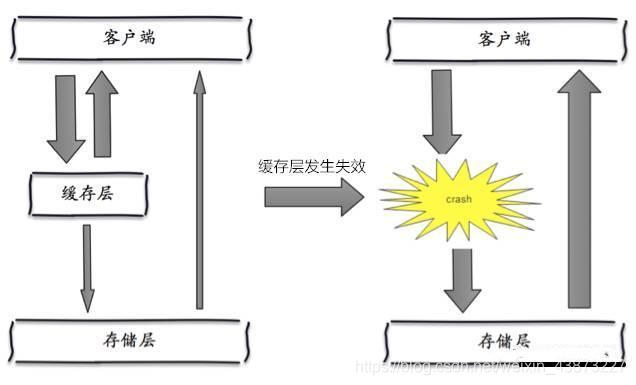
经验总结:(Redis NoSQL数据库快速入门)
一、Nosql概述 为什么使用Nosql 1、单机Mysql时代 90年代,一个网站的访问量一般不会太大,单个数据库完全够用。随着用户增多,网站出现以下问题 数据量增加到一定程度,单机数据库就放不下了数据的索引(B Tree),一个机…...
form表单与模板引擎
文章目录 一、form表单的基本使用1、什么是表单2、表单的组成部分3、 <form>标签的属性4、表单的同步提交及缺点(1) 什么是表单的同步提交(2) 表单同步提交的缺点(3) 如何解决表单同步提交的缺点 二、…...
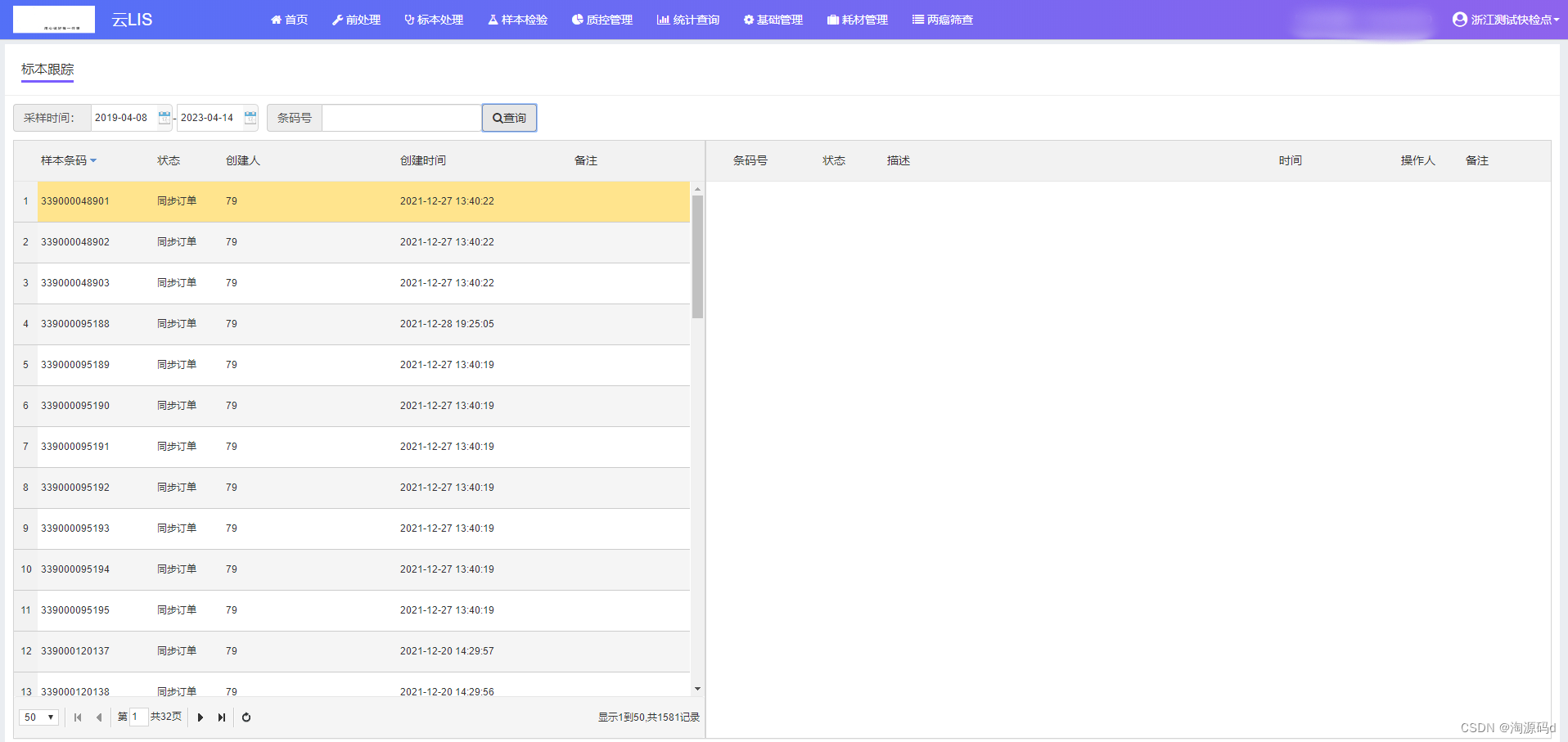
医院检验信息管理系统源码(云LIS系统源码)JQuery、EasyUI
云LIS系统是一种医疗实验室信息管理系统,提供全面的实验室信息管理解决方案。它的主要功能包括样本管理、检测流程管理、报告管理、质量控制、数据分析和仪器管理等。 云LIS源码技术说明: 技术架构:Asp.NET CORE 3.1 MVC SQLserver Redis等…...

React 组件
文章目录 React 组件复合组件 React 组件 本节将讨论如何使用组件使得我们的应用更容易来管理。 接下来我们封装一个输出 “Hello World!” 的组件,组件名为 HelloMessage: React 实例 <!DOCTYPE html> <html> <head> &…...

硕士学位论文的几种常见节奏
摘要: 本文描述硕士学位论文的几种目录结构, 特别针对机器学习方向. 1. 基础版 XX算法及其在YY中的应用 针对情况: 只有一篇小论文支撑. 第 1 章: 引言 ( > 5页) 1.1 背景及意义 (应用背景、研究意义, 2 页) 1.2 研究进展及趋势 (算法方面, 2 页) 1.3 论文结构 (1 页) 第 …...

找兄弟单词
描述 定义一个单词的“兄弟单词”为:交换该单词字母顺序(注:可以交换任意次),而不添加、删除、修改原有的字母就能生成的单词。 兄弟单词要求和原来的单词不同。例如: ab 和 ba 是兄弟单词。 ab 和 ab 则不…...

python字典翻转教学
目录 第1关 创建大学英语四级单词字典 第2关 合并大学英语四六级词汇字典 第3关 查单词输出中文释义 第4关 删除字典中特定字母开头的单词 第5关 单词英汉记忆训练 第1关 创建大学英语四级单词字典 本关任务:编写一个能创建大学英语四级单词字典的小程序。 测…...
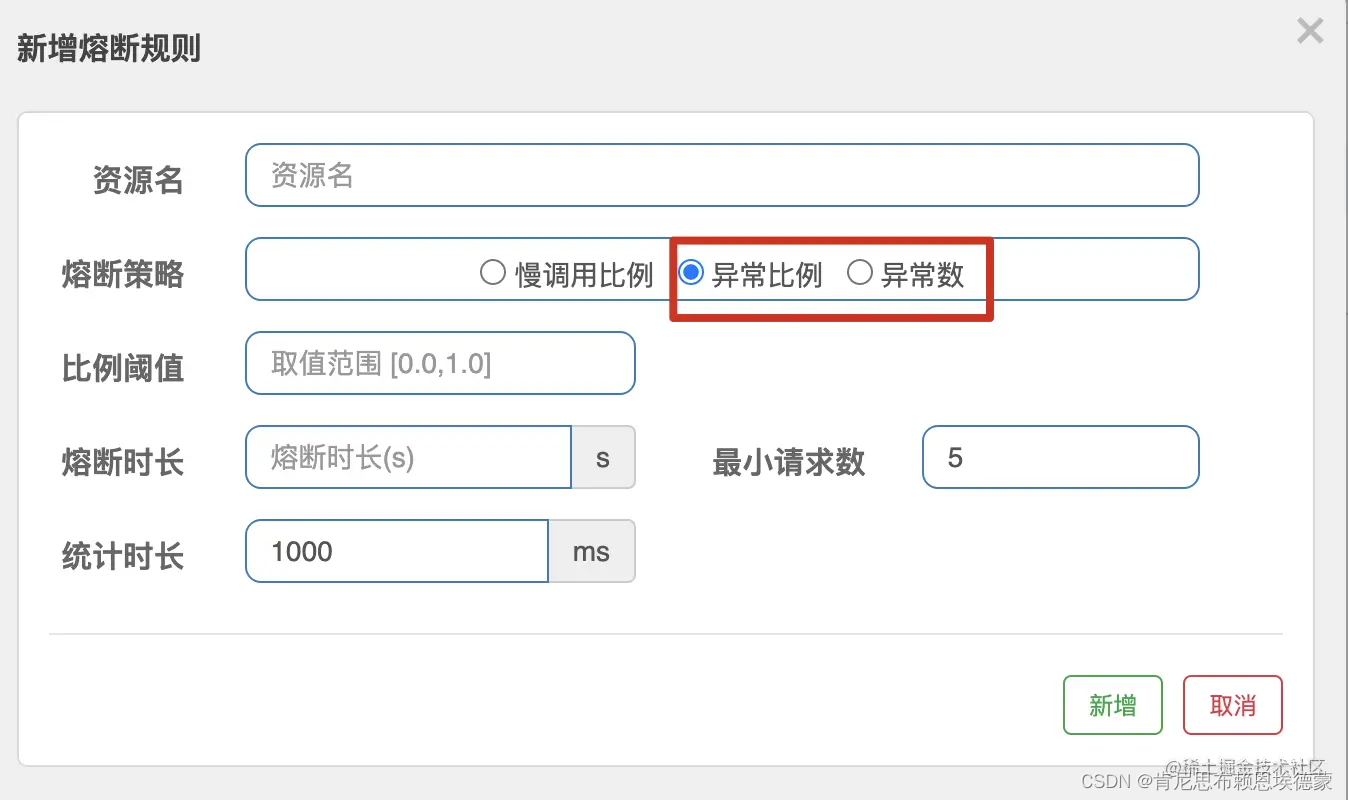
sentinel 随笔 3-降级处理
0. 像喝点东西,但不知道喝什么 先来段源码,看一下 我们在dashboard 录入的降级规则,都映射到哪些字段上 package com.alibaba.csp.sentinel.slots.block.degrade;public class DegradeRule extends AbstractRule {public DegradeRule(String…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...