ShardingSphere系列四(Sharding-JDBC内核原理及核心源码解析)
文章目录
- 1. ShardingSphere内核解析
- 1.1 解析引擎
- 1.2 路由引擎
- 1.3 改写引擎
- 1.4 执行引擎
- 1.5 归并引擎
- 2. ShardingSphere的SPI扩展点
- 2.1 SPI机制
- 2.2 ShardingSphere中的SPI扩展点
- 2.3 实现自定义主键生成策略
- 3. ShardingSphere源码
1. ShardingSphere内核解析
ShardingSphere虽然有多个产品,但是他们的数据分片主要流程是完全一致的。
1.1 解析引擎

解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树(简称AST,Abstract Syntax Tree)。
SQL解析是整个分库分表产品的核心,其性能和兼容性是最重要的衡量指标。ShardingSphere在1.4.x之前采用的是性能较快的Druid作为SQL解析器。1.5.x版本后,采用自研的SQL解析器,针对分库分表场景,采取对SQL半理解的方式,提高SQL解析的性能和兼容性。然后从3.0.x版本后,开始使用ANLTR作为SQL解析引擎。这是个开源的SQL解析引擎,ShardingSphere在使用ANLTR时,还增加了一些AST的缓存功能。针对ANLTR4的特性,官网建议尽量采用PreparedStatement的预编译方式来提高SQL执行的性能。
1.2 路由引擎
根据解析上下文匹配数据库和表的分片策略,生成路由路径。
ShardingSphere的分片路由策略主要分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是Between)。不携带分片键的SQL则是广播路由。
分片策略通常可以由数据库内置也可以由用户方配置。内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。 由用户方配置的分片策略则更加灵活,可以根据使用方需求定制复合分片策略。
实际使用时,应尽量使用分片路由,明确路由策略。因为广播路由影响过大,不利于集群管理及扩展。

- 全库表路由:对于不带分片键的DQL、DML以及DDL语句,会遍历所有的库表,逐一执行。例如 select * from course 或者 select * from course where ustatus=‘1’(不带分片键)
- 全库路由:对数据库的操作都会遍历所有真实库。 例如 set autocommit=0
- 全实例路由:对于DCL语句,每个数据库实例只执行一次,例如CREATE USER customer@127.0.0.1 identified BY ‘123’;
- 单播路由:仅需要从任意库中获取数据即可。 例如 DESCRIBE course
- 阻断路由:屏蔽SQL对数据库的操作。例如 USE coursedb。就不会在真实库中执行,因为针对虚拟表操作,不需要切换数据库。
1.3 改写引擎
用户只需要面向逻辑库和逻辑表来写SQL,最终由ShardigSphere的改写引擎将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。

1.4 执行引擎
ShardingSphere并不是简单的将改写完的SQL提交到数据库执行。执行引擎的目标是自动化的平衡资源控制和执行效率。例如他的连接模式分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。内存限制模式只关注一个数据库连接的处理数量,通常一张真实表一个数据库连接。而连接限制模式则只关注数据库连接的数量,较大的查询会进行串行操作。

ShardingSphere引入了连接模式的概念,分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。
这两个模式的区分涉及到一个参数spring.shardingsphere.props.max.connections.size.per.query=50(默认值1,配置参见源码中ConfigurationPropertyKey类)。ShardingSphere会根据 路由到某一个数据源的路由结果 计算出 所有需在数据库上执行的SQL数量,用这个数量除以 用户的配置项,得到每个数据库连接需执行的SQL数量。数量>1就会选择连接限制模式,数量<=1就会选择内存限制模式。
内存限制模式不限制连接数,也就是说会建立多个数据连接,然后并发控制每个连接只去读取一个数据分片的数据。这样可以最快速度的把所有需要的数据读出来。并且在后面的归并阶段,会选择以每一条数据为单位进行归并,就是后面提到的流式归并。这种归并方式归并完一批数据后,可以释放内存了,可以很好的提高数据归并的效率,并且防止出现内存溢出或垃圾回收频繁的情况。他的吞吐量比较大,比较适合OLAP场景。
连接限制模式会对连接数进行限制,也即是说至少有一个数据库连接会要去读取多个数据分片的数据。这样他会对这个数据库连接采用串行的方式依次读取多个数据分片的数据。而这种方式下,会将数据全部读入到内存,进行统一的数据归并,也就是后面提到的内存归并。这种方式归并效率会比较高,例如一个MAX归并,直接就能拿到最大值,而流式归并就需要一条条的比较。比较适合OLTP场景。
1.5 归并引擎
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
其中,流式归并是指以一条一条数据的方式进行归并,而内存归并是将所有结果集都查询到内存中,进行统一归并。
分布式主键:内置生成器支持:UUID、SNOWFLAKE,并抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
- UUID:采用UUID.randomUUID()的方式产生唯一且不重复的分布式主键。最终生成一个字符串类型的主键。缺点是生成的主键无序。
- SNOWFLAKE:雪花算法,能够保证不同进程主键的不重复性,相同进程主键的有序性。二进制形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
- 符号位(1bit): 预留的符号位,恒为零。
- 时间戳位(41bit):41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000 Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L) =69.73年不重复;
- 工作进程位(10bit):该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过属性设置。
- 序列号位(12bit):该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。

优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖第三方组件,稳定性高,生成ID的性能也非常高。
- 可以根据自身业务特性分配bit位,非常灵活
缺点: - 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复。
2. ShardingSphere的SPI扩展点
ShardingSphere为了兼容更多的应用场景,在源码中保留了大量的SPI扩展点。所以在看源码之前,需要对JAVA的SPI机制有足够的了解。
2.1 SPI机制
SPI的全名为:Service Provider Interface。在java.util.ServiceLoader的文档里有比较详细的介绍。简单的总结下 Java SPI 机制的思想。我们系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块的方案,xml解析模块、jdbc模块的方案等。面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。
一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI 就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要Java SPI 的具体约定为:当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。jdk提供服务实现查找的一个工具类:java.util.ServiceLoader。
2.2 ShardingSphere中的SPI扩展点
ShardingSphere的开发思想是对源码中主体流程封闭,而对SPI开放。在配套的官方文档《shardingsphere_docs_cn.pdf》的开发者手册部分详细列出了ShardingSphere的所有SPI扩展点。
2.3 实现自定义主键生成策略
使用ShardingSphere提供的SPI扩展点,实现自定义分布式主键生成策略。
3. ShardingSphere源码
ShardingSphere 5.2.0源码下载

相关文章:
ShardingSphere系列四(Sharding-JDBC内核原理及核心源码解析)
文章目录 1. ShardingSphere内核解析1.1 解析引擎1.2 路由引擎1.3 改写引擎1.4 执行引擎1.5 归并引擎 2. ShardingSphere的SPI扩展点2.1 SPI机制2.2 ShardingSphere中的SPI扩展点2.3 实现自定义主键生成策略 3. ShardingSphere源码 1. ShardingSphere内核解析 ShardingSphere虽…...

【2023】华为OD机试真题全语言-题目0234-字符串重新排列
题目0234-字符串重新排列 题目描述 给定一个字符串s,s包括以空格分隔的若干个单词,请对s进行如下处理后输出: 单词内部调整:对每个单词字母重新按字典序排序单词间顺序调整: 统计每个单词出现的次数,并按次数降序排列次数相同,按单词长度升序排列次数和单词长度均相同…...
Springboot +Flowable,三种常见网关的使用(排他、并行、包容网关)(一)
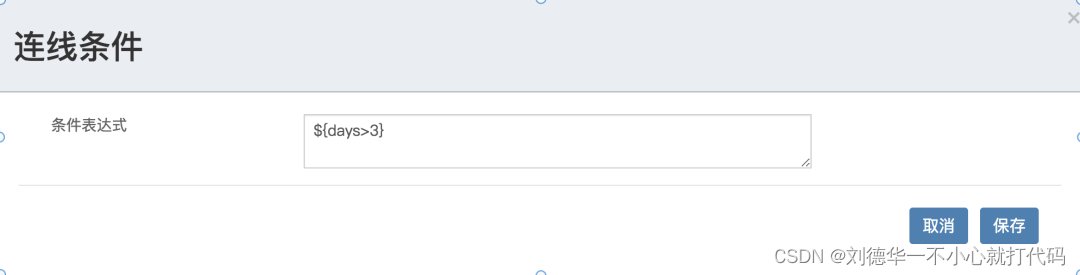
一.简介 Flowable 中常用的网关主要有三种类型,分别是: 排他网关并行网关包容网关 下面来说下这三种的网关的概念和用法。 二.排他网关 排他网关,也叫互斥网关,截图如下: 排他网关有一个入口,多个有效…...
信息化发展 ★重点集萃★)
软考高项(一)信息化发展 ★重点集萃★
1、信息是确定性的增加。信息不是物质,也不是能力。 2、信息的特征与质量,主要包括:客观性、普遍性、无限性、动态性、相对性、依附性、变换性、传递性、层次性、系统性和转化性等。 3、信息的质量属性,主要包括:精确…...
大项目准备(2)
目录 中国十大最具发展潜力城市 docker是什么?能介绍一下吗? 中国十大最具发展潜力城市 按照人随产业走、产业决定城市兴衰、规模经济和交通成本等区位因素决定产业布局的基本逻辑,我们在《中国城市发展潜力排名:2022》研究报告…...
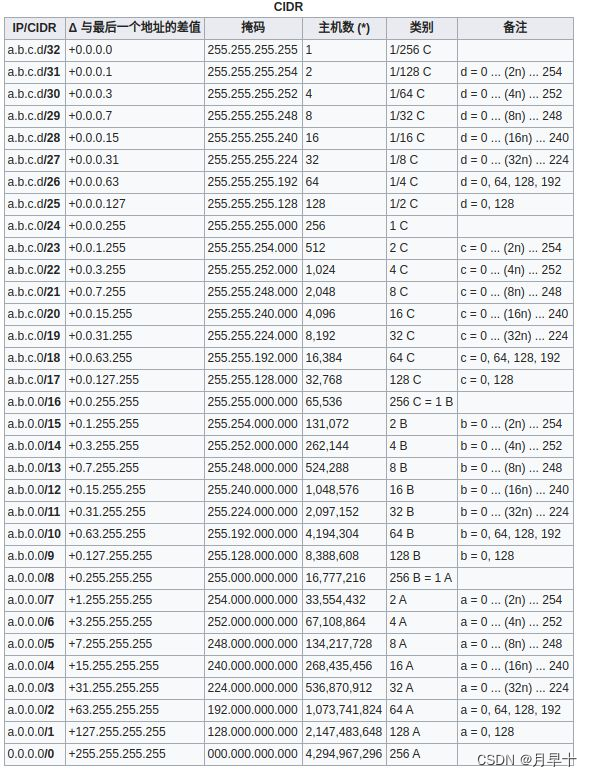
计算机网络【2】 子网掩码
学习大佬记下的笔记 https://zhuanlan.zhihu.com/p/163119376 "子网"掩码,顾名思义,它就是拿来划分子网的,更准确的说,划分子网的同时,还能通过它知道主机在子网里面的具体ip的具体地址。 子网掩码只有一个…...

linux发行家族和发行版及安装软件方式
在Linux平台下,软件包的类型可以划分为两类:源码包、二进制包; 一个软件要在Linux上执行,必须是二进制文件; 源码包:即程序软件的源代码(一般也叫Tarball,即将软件的源码以tar打包后…...

FE_Vue学习笔记 条件渲染[v-show v-if] 列表渲染[v-for] 列表过滤 列表排序
1 条件渲染 v-show v-if 使用template可以使其里面的内容在html的结构中不变。条件渲染: v-if 1)v-if“表达式” 2)v-else-if“表达式” 3)v-else {} 适用于:切换频率较低的场景。特点:不展示的DOM元素直…...
基于C++实现旅行线路设计
访问【WRITE-BUG数字空间】_[内附完整源码和文档] 系统根据风险评估,为旅客设计一条符合旅行策略的旅行线路并输出,系统能查询当前时刻旅客所处的地点和状态(停留城市/所在交通工具)。 实验内容和实验环境描述 1.1 实验内容 城…...
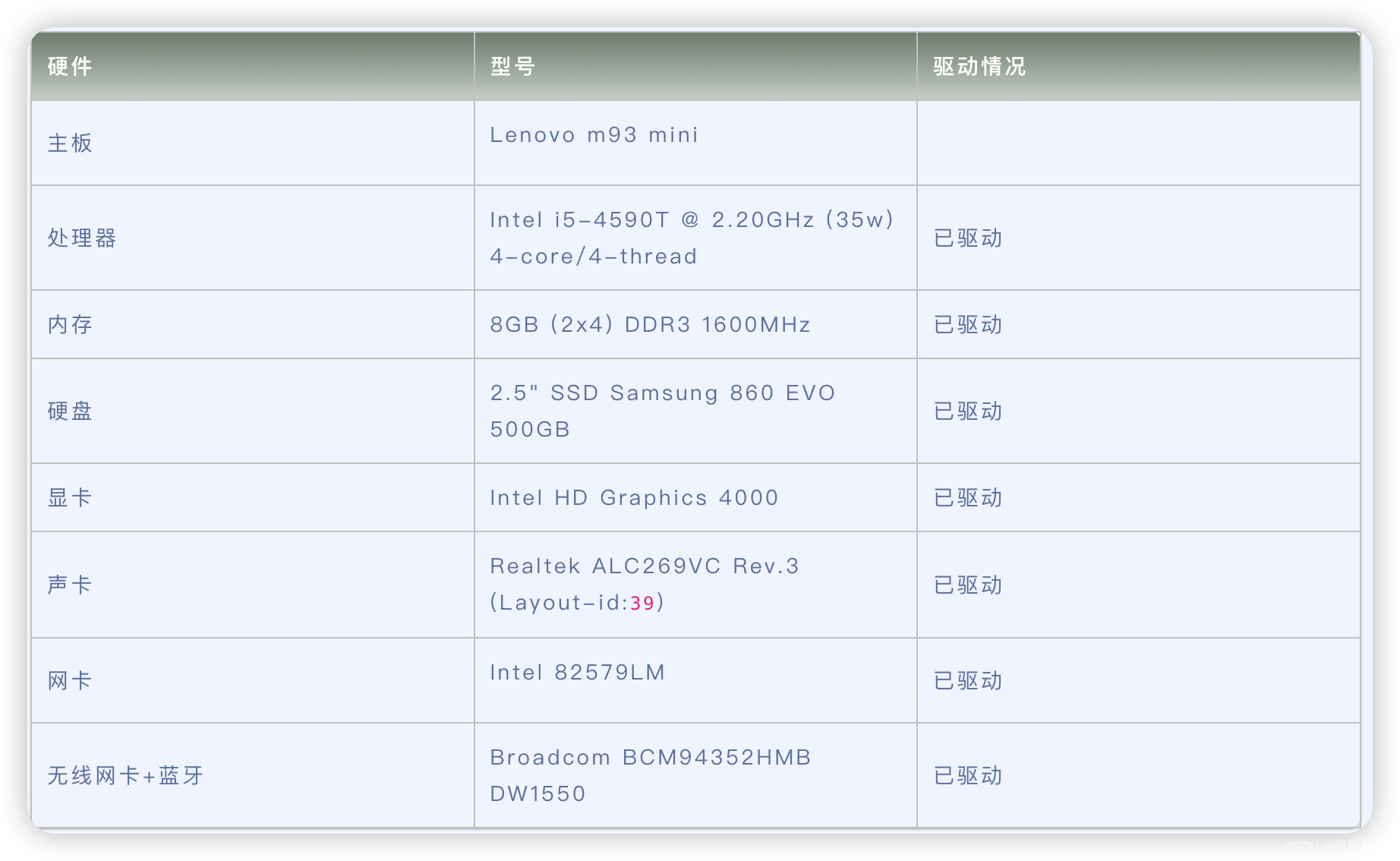
Lenovo m93 mini 电脑 Hackintosh 黑苹果efi引导文件
原文来源于黑果魏叔官网,转载需注明出处。(下载请直接百度黑果魏叔) 硬件型号驱动情况 主板Lenovo m93 mini 处理器Intel i5-4590T 2.20GHz (35w) 4-core/4-thread已驱动 内存8GB (2x4) DDR3 1600MHz已驱动 硬盘2.5" SSD Samsung 8…...
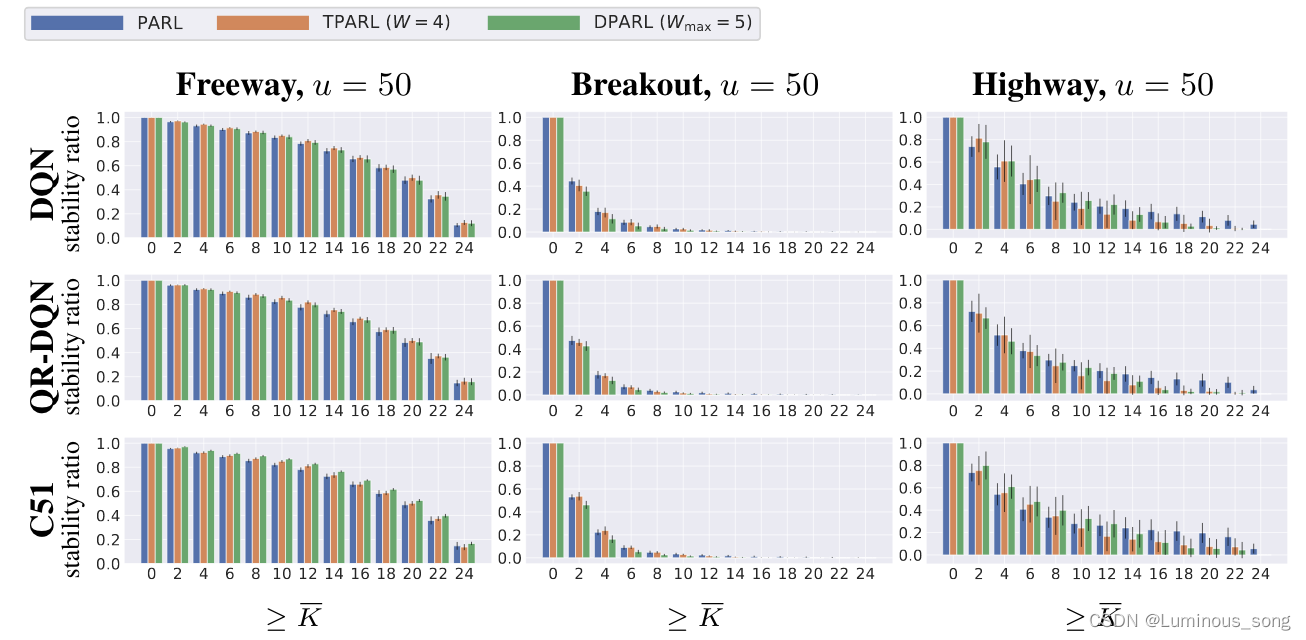
【论文阅读】COPA:验证针对中毒攻击的离线强化学习的稳健策略
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks 作者:Fan Wu, Linyi Li, Chejian Xu 发表会议:2022ICRL 摘要 目前强化学习完成任务的水平已经和人类相接近,因此研究人员的目光开始转向…...
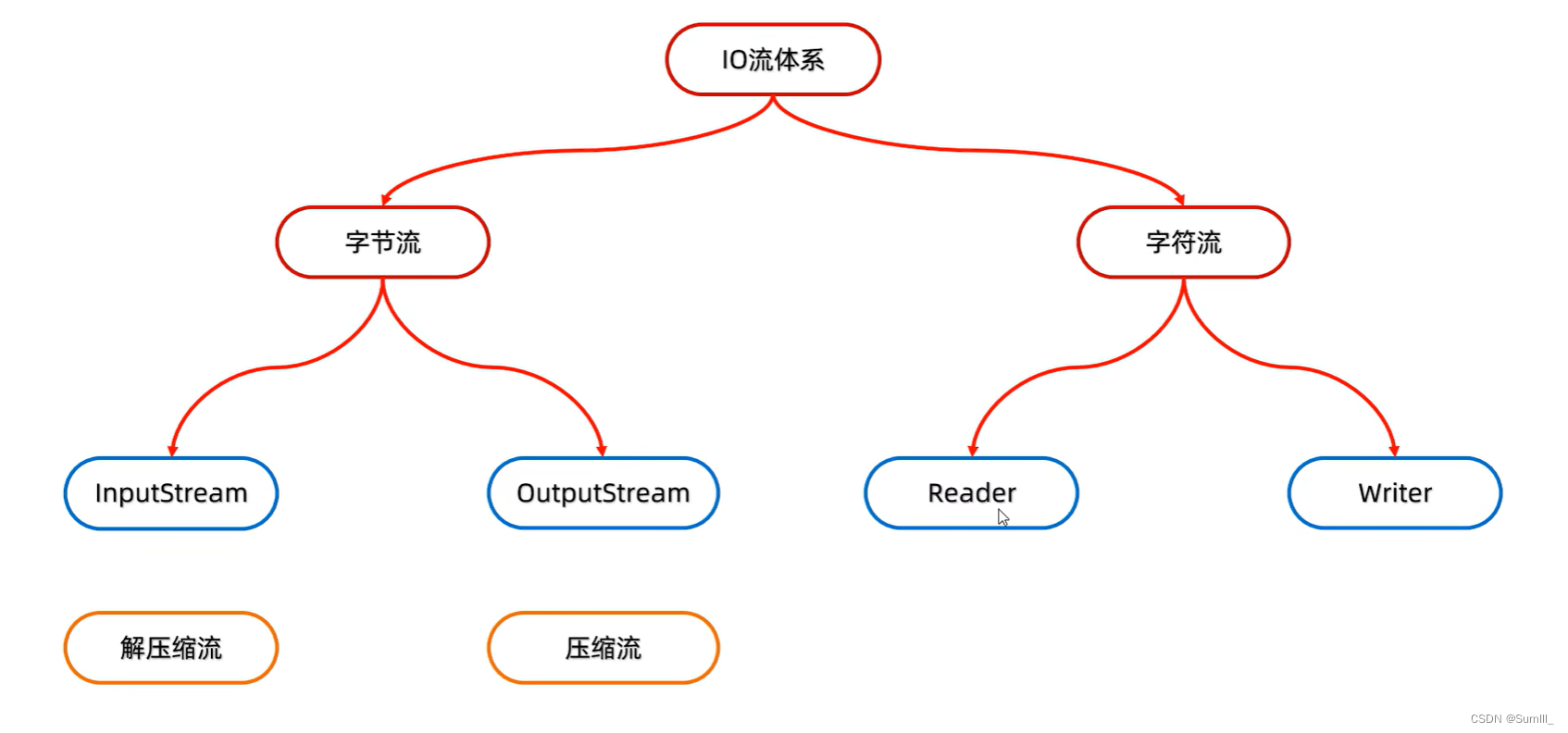
Java笔记_18(IO流)
Java笔记_18 一、IO流1.1、IO流的概述1.2、IO流的体系1.3、字节输出流基本用法1.4、字节输入流基本用法1.5、文件拷贝1.6、IO流中不同JDK版本捕获异常的方式 二、字符集2.1、GBK、ASCII字符集2.2、Unicode字符集2.3、为什么会有乱码2.4、Java中编码和解码的代码实现2.5、字符输…...
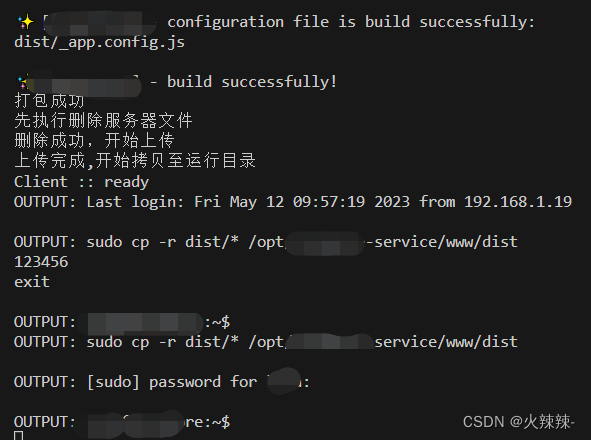
前端vue3一键打包发布
一键打包发布可以分为两种,一是本地代码,编译打包后发布至服务器,二是直接在服务器上拉去代码打包发布至指定目录中。 两种各有使用场景,第一种是前端开发自己调试发布用的比较多,第二种是测试或者其他人员用的多&…...
13 | visual studio与Qt的结合
1 前提 Qt 5.15.2 visual studio 2019 vsaddin 2.8 2 具体操作 2.1 visual studio tool 2.1.1 下载 https://visualstudio.microsoft.com/zh-hans/downloads/2.1.2 安装 开发...
纯手动搭建大数据集群架构_记录019_集群机器硬盘爆满了_从搭建虚拟机开始_做个200G的虚拟机---大数据之Hadoop3.x工作笔记0179
今天突然就发现,使用nifi的时候集群满了...气死了.. 而在vmware中给centos去扩容,给根目录扩容,做的时候,弄了一天...最后还是报错, 算了从头搭建一个200G的,希望这次够用吧.后面再研究一下扩容的问题. 2023-05-12 11:06:48 原来的集群的机器,硬盘太小了,扩容不知道怎么回事…...

变量大小:—揭开不同类型的字节数
变量大小:一一揭开不同类型的字节数 在编程中,我们会使用各种类型的变量来存储数据,但是你是否知道这些变量在内存中所占用的字节数是多少呢?随着不同编程语言和不同的操作系统,这些变量的字节数可能会有所不同。在本…...
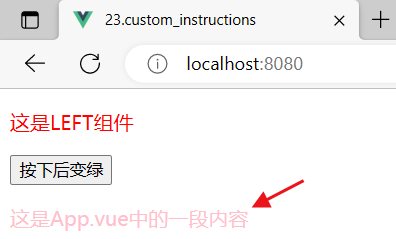
23.自定义指令
像是 v-if,v-for,v-model 这些是官方指令,vue允许开发者自定义指令 目录 1 mounted 1.1 基本使用 1.2 第一个形参 1.3 第二个形参 2 updated 3 函数简写 4 全局自定义指令 1 mounted 当指令绑定到元素身上的时候,就会自动触发mounted()…...

OPNET Modeler 例程——停等协议的建模和仿真
文章目录 一、概述二、链路模型和包格式创建三、进程模型1.src 进程模型2.sink 进程模型 四、节点模型五、网络模型六、仿真结果 一、概述 本例程是在 OPNET Modeler 中对停等协议的建模和仿真,其中停等协议的操作过程如下: (1)发…...
JavaScript - 基础+WebAPI(笔记)
前言: 求关注😭 本篇文章主要记录以下几部分: 基础: 输入输出语法;数据类型;运算符;流程控制 - 分支语句;流程控制 - 循环语句;数组 - 基础;函数 - 基础&…...

API调用的注意事项及好处!
API调用是指一个软件系统通过预定格式、协议和框架,向另一个软件系统发送请求并获得响应的过程。 在进行API调用时需要注意以下事项: 1. 认真阅读API文档:在调用API前,一定要认真仔细地阅读相关的API文档,了解API接口…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...

shell脚本质数判断
shell脚本质数判断 shell输入一个正整数,判断是否为质数(素数)shell求1-100内的质数shell求给定数组输出其中的质数 shell输入一个正整数,判断是否为质数(素数) 思路: 1:1 2:1 2 3:1 2 3 4:1 2 3 4 5:1 2 3 4 5-------> 3:2 4:2 3 5:2 3…...
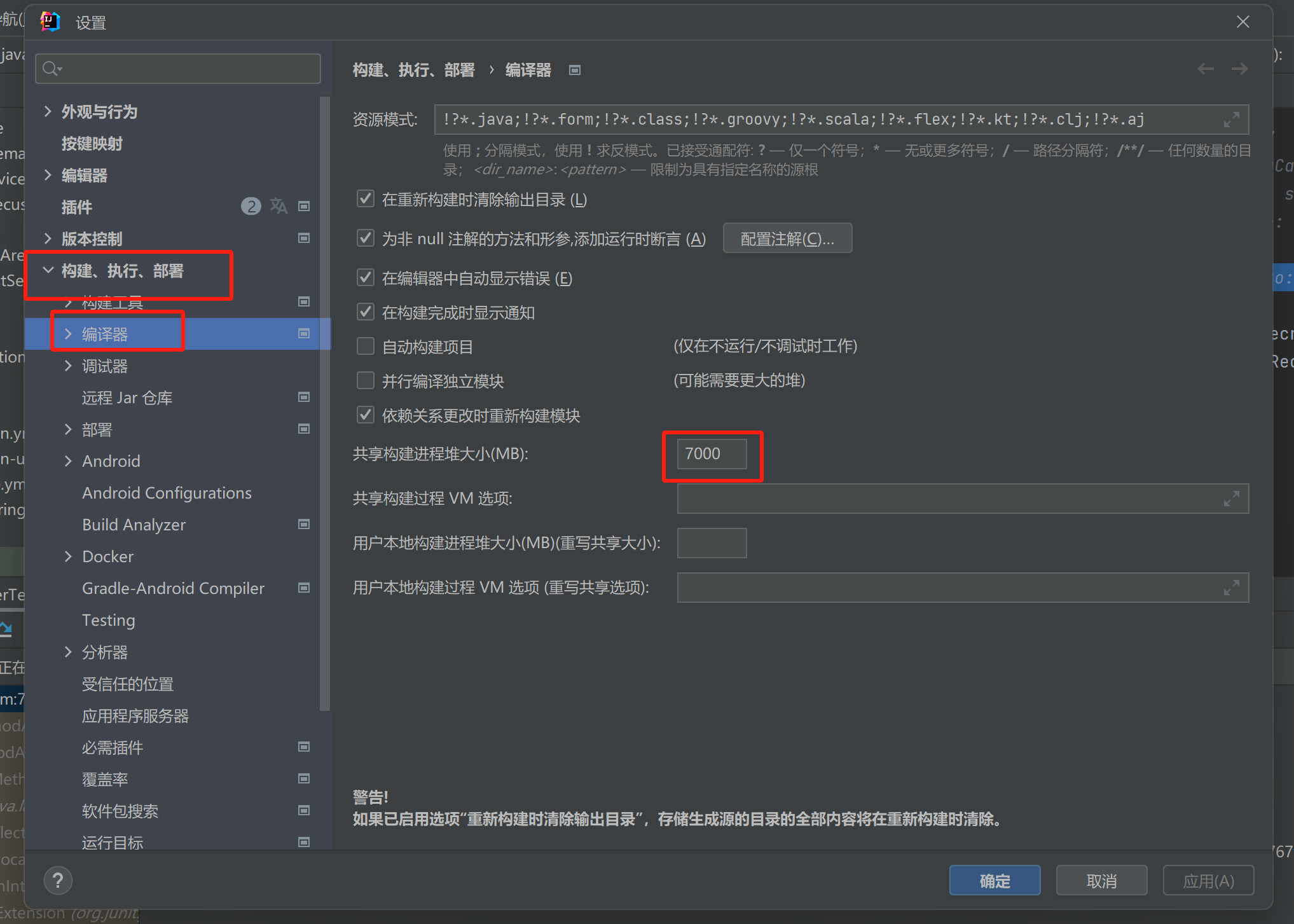
【记录坑点问题】IDEA运行:maven-resources-production:XX: OOM: Java heap space
问题:IDEA出现maven-resources-production:operation-service: java.lang.OutOfMemoryError: Java heap space 解决方案:将编译的堆内存增加一点 位置:设置setting-》构建菜单build-》编译器Complier...