Early Stopping中基于测试集(而非验证集)上的表现选取模型的讨论
论文中一般都是用在验证集上效果最好的模型去预测测试集,多次预测的结果取平均计算准确率或者mAP值,而不是单纯的取一次验证集最好的结果作为论文的结果。如果你在写论文的过程中,把测试集当做验证集去验证的话,这其实是作假的,建议不要这样,一旦有人举报或者复现出来你的结果和你论文中的结果相差很大的话,是会受到很大处分的。
我之前曾遇到过这种情况,我在图像分类的过程中曾经用过CutMix增强方式,CutMix其实就是将两张图片放在一起,如下图所示,这种结果会造成验证集上准确率很大的波动,可能一会儿变成99%,一会儿变成88%,那我总不能拿99%作为我论文中的结果啊,所以还是要以最终的测试集的准确率为主,因为这个才是我们需要关注的。
如果只是单纯的取提高准确率的话可以看看文中下面的一些方式,这些方式的提升一定会比单纯取最好的模型的效果要好的。
首先我们需要理解一下概念,什么是训练集?什么是验证集?什么是测试集?大家很容易将“验证集”与“测试集”,“交叉验证”混淆。
首先我们来了解一下基本的概念哈,然后在分析如何解决分类问题,提高模型的准确率和泛化能力。
训练集、验证集、测试集:
训练集(train set) —— 用于模型拟合的数据样本。
验证集(development set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数(包括EarlyStopping的epoch)和用于对模型的能力进行初步评估。
测试集 —— 用来评估模最终模型的泛化能力,也就是计算论文里最后各个评价指标的值。但不能作为调参、选择特征等算法相关的选择的依据。
一个形象的比喻:
训练集:学生的课本;学生 根据课本里的内容来掌握知识。
验证集:作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集:考试,考的题是平常都没有见过,考察学生举一反三的能力。
为什么验证数据集和测试数据集两者都需要?
因为验证数据集(Validation Set)用来调整模型参数从而选择最优模型,模型本身已经同时知道了输入和输出,所以从验证数据集上得出的误差(Error)会有偏差(Bias)。
但是我们只用测试数据集(Test Set) 去评估模型的表现,并不会去调整优化模型。
传统上,一般三者切分的比例是:6:2:2,验证集并不是必须的,即验证集可有可无(可以选择不用验证集调整超参数)。
所以,很多人口中的测试集应该是验证集的意思,测试集不能作为调参、选择特征等算法相关的选择的依据。
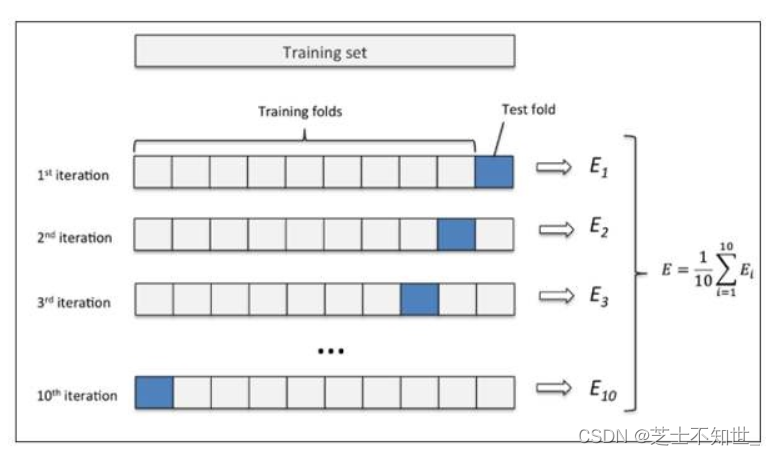
K-折交叉验证(K-fold Cross Validation,记为K-CV)
就按照作者说的10折交叉来说,算法步骤是(图如1):
- 将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率。
- 10次的结果的正确率的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
 在数据缺乏的情况下使用,如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,故LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数,作为此下LOO-CV分类器的性能指标。
在数据缺乏的情况下使用,如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,故LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数,作为此下LOO-CV分类器的性能指标。
优点:(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
缺点:计算成本高,需要建立的模型数量与原始数据样本数量相同。当数据集较大时几乎不能使用。
关于EarlyStopping保存最优的模型
Pytroch保存最优的训练模型
min_loss = 100000#随便设置一个比较大的数for epoch in range(epochs):train()val_loss = val()if val_loss < min_loss:min_loss = val_lossprint("save model")torch.save(net.state_dict(),'model.pth')
图像分类
当我们拿到数据集的第一步就是对数据进行分析:
- 各个种类的样本是否平衡,如果数据不平衡的话对模型准确性的影响是非常大的。举个栗子:如果有100个样本,其中99个是正样本,1个是负样本。那么就算我们把所有的样本都预测成正样本,准确率也有99%,显然这是不对的,因为这个模型只能识别正样本了,泛化能力非常差。这个时候,可以考虑改动损失函数,增加难样本(负样本)的权重,减少简单样本(正样本)的权重。
- 数据集中是否含有大量噪声。
- 数据量是否充足等等.
接下来我们讲解一下图像分类中的一些trick:
1.数据清洗
借助弱监督方式引入外部数据集中的高质量数据——解决了自行扩展数据集带来的测试偏移。步骤如下:
- 使用训练数据建立模型
- 预测爬取的数据的标签,对外部数据进行伪标签标注。
- 结合样本分布和混淆矩阵的结果,设置了多级阈值,选择可信度高的数据,组合成新的数据集
- 重复1,2,3。
2.数据增强
①几何变换——只进行水平翻转和平移0.05
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomHorizontalFlip()
②CutMix
3.数据不均衡
在数据层面和算法层面同时测试选取—— 上采样和class_wight相结合
①上采样——通过混淆矩阵和验证集的随机化设置,提取模型预测错误的数据,然后按照一定的权重进行数据复制扩充,为了减少上采样可能带来的过拟合问题,我们对扩充的数据进行了区域裁剪,使数据更倾向于需要关注的部分。
②class_weight——将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。
4.数据标签平滑
目的:减小过拟合问题
平滑过后的样本交叉熵损失就不仅考虑到了训练样本中正确的标签位置的损失,也稍微考虑到其他错误标签位置的损失,导致最后的损失增大,导致模型的学习能力提高,即要下降到原来的损失,就得学习的更好,也就是迫使模型往增大正确分类概率并且同时减小错误分类概率的方向前进。
#!/usr/bin/python
# -*- encoding: utf-8 -*-import torch
import torch.nn as nnclass LabelSmoothSoftmaxCE(nn.Module):def __init__(self,lb_pos=0.9,lb_neg=0.005,reduction='mean',lb_ignore=255,):super(LabelSmoothSoftmaxCE, self).__init__()self.lb_pos = lb_posself.lb_neg = lb_negself.reduction = reductionself.lb_ignore = lb_ignoreself.log_softmax = nn.LogSoftmax(1)def forward(self, logits, label):logs = self.log_softmax(logits)ignore = label.data.cpu() == self.lb_ignoren_valid = (ignore == 0).sum()label = label.clone()label[ignore] = 0lb_one_hot = logits.data.clone().zero_().scatter_(1, label.unsqueeze(1), 1)label = self.lb_pos * lb_one_hot + self.lb_neg * (1-lb_one_hot)ignore = ignore.nonzero()_, M = ignore.size()a, *b = ignore.chunk(M, dim=1)label[[a, torch.arange(label.size(1)), *b]] = 0if self.reduction == 'mean':loss = -torch.sum(torch.sum(logs*label, dim=1)) / n_validelif self.reduction == 'none':loss = -torch.sum(logs*label, dim=1)return lossif __name__ == '__main__':torch.manual_seed(15)criteria = LabelSmoothSoftmaxCE(lb_pos=0.9, lb_neg=5e-3)net1 = nn.Sequential(nn.Conv2d(3, 3, kernel_size=3, stride=2, padding=1),)net1.cuda()net1.train()net2 = nn.Sequential(nn.Conv2d(3, 3, kernel_size=3, stride=2, padding=1),)net2.cuda()net2.train()with torch.no_grad():inten = torch.randn(2, 3, 5, 5).cuda()lbs = torch.randint(0, 3, [2, 5, 5]).cuda()lbs[1, 3, 4] = 255lbs[1, 2, 3] = 255print(lbs)import torch.nn.functional as Flogits1 = net1(inten)logits1 = F.interpolate(logits1, inten.size()[2:], mode='bilinear')logits2 = net2(inten)logits2 = F.interpolate(logits2, inten.size()[2:], mode='bilinear')# loss1 = criteria1(logits1, lbs)loss = criteria(logits1, lbs)# print(loss.detach().cpu())loss.backward()
5.双损失函数
categorical_crossentropy 和 Label Smoothing Regularization :在对原始标签进行平滑的过程中,可能存在某些数据对标签变化特别敏感,导致损失函数的异常增大,使模型变得不稳定,为了增加模型的稳定性所以使用双损失函数——categorical_crossentropy 和 Label Smoothing Regularization,即保证了模型的泛化能力,又保证了数据不会对标签过于敏感,增加了模型的稳定性。
criterion = L.JointLoss(first=nn.crossentropyloss(), second=LabelSmoothSoftmaxCE(),first_weight=0.5, second_weight=0.5)
6.优化器
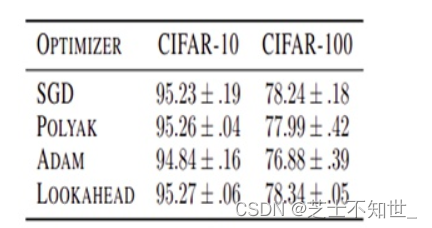
RAdam LookAhead:兼具Adam和SGD两者的优化器RAdam,收敛速度快,鲁棒性好LookAhead对SGD进行改进,在各种深度学习任务上实现了更快的收敛 。
将RAdam和LookAhead结合在了一起,形成名为Ranger的新优化器。在ImageNet上进行了测试,在128px,20epoch的测试中,Ranger的训练精度达到了93%,比目前FastAI排行榜榜首提高了1%。
7.选择的模型
ResNeXt101系列,EfficientNet系列。
resnext101_32x16d_wsl
resnext101_32x8d_wsl
efficientnet-b4
efficientnet-b5
8.注意力机制
在模型中加入SE&CBAM注意力机制——提升网络模型的特征提取能力。
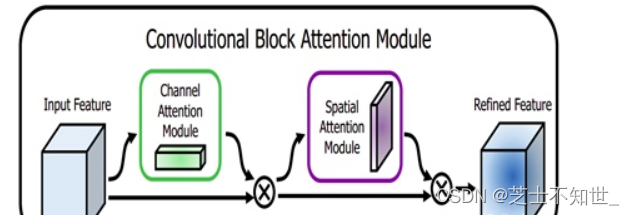
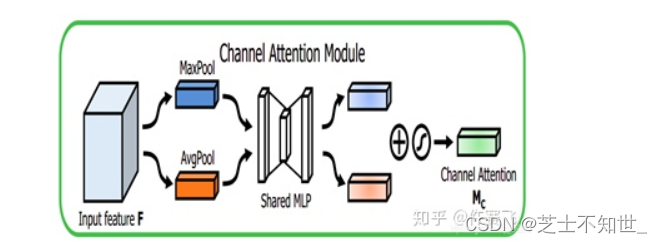
- channel attention的过程。比SE多了一个 global max pooling(池化本身是提取高层次特征,不同的池化意味着提取的高层次特征更加丰富)。其第2个池化之后的处理过程和SE一样,都是先降维再升维,不同的是将2个池化后相加再sigmod和原 feature map。
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)self.relu1 = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)
② spatial attention 的过程。将做完 channel attention 的feature map 作为输入,之后作2个大小为列通道的维度池化,每一次池化得到的 feature map 大小就为 h * w * 1 ,再将两次池化的 feature map 作基于通道的连接变成了大小为 h * w * 2 的 feature map ,再对这个feature map 进行核大小为 7*7 ,卷积核个数为1的卷积操作(通道压缩)再sigmod,最后就是熟悉的矩阵全乘。
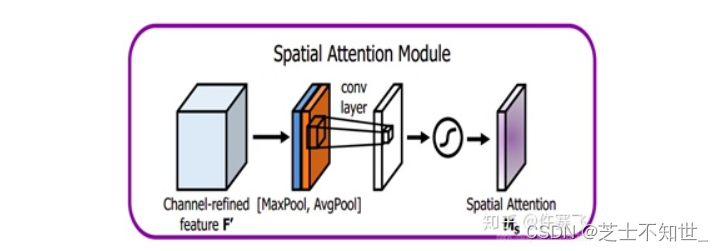
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)
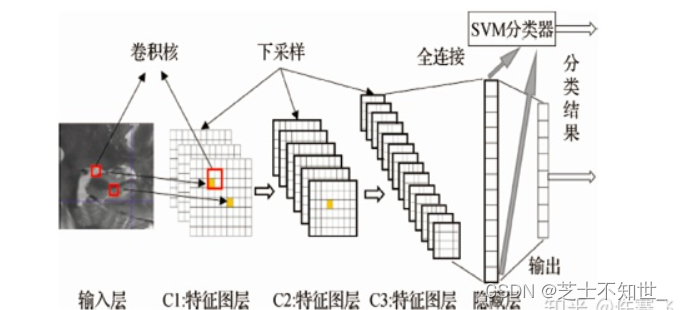
9.SVM替换softmax层
抽取出模型的最后一层,将其接入SVM,用训练数据动态训练SVM分类器,再使用训练好的SVM分类器进行预测。
深度学习模型有支持向量机无法比拟的非线性函数逼近能力,能够很好地提取并表达数据的特征,深度学习模型的本质是特征学习器。然而,深度模型往往在独立处理分类、回归等问题上难以取得理想的效果。对于 SVM 来说,可以利用核函数的思想将非线性样本映射到高维空间,使其线性可分,再通过使数据集之间的分类间隔最大化来寻找最优分割超平面,在分类问题上表现出许多特有优势。但实质上,SVM 只含有一个隐层,数据表征能力并不理想。因此将深度学习方法与 SVM 相结合,构造用于分类的深层模型。利用深度学习的无监督方式分层提取样本高级特征,然后将这些高级特征输入 SVM 模型进行分类,从而达到最优分类精度。
10.模型融合
多模型融合的策略,Stacking,VotingClassifier—— 提升分类准确率Stacking方法: Stacking 先从初始数据集训练出初级学习器,然后”生成”一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。stacking使用交叉验证的方式,初始训练集 D 被随机划分为 k 个大小相似的集合 D1 , D2 , … , Dk,每次用k-1 个部分训练 T 个模型,对另个一个部分产生 T 个预测值作为特征,遍历每一折后,也就得到了新的特征集合,标记还是源数据的标记,用新的特征集合训练一个集合模型。
11.TTA:测试时数据增强(保证数据增强的几何变换和tta一致)
可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA)。这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。
tta_model = tta.TTAWrapper(model,tta.fliplr_image2label)
作者:初识CV
链接:https://www.zhihu.com/question/408153243/answer/1490901503
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
相关文章:
Early Stopping中基于测试集(而非验证集)上的表现选取模型的讨论
论文中一般都是用在验证集上效果最好的模型去预测测试集,多次预测的结果取平均计算准确率或者mAP值,而不是单纯的取一次验证集最好的结果作为论文的结果。如果你在写论文的过程中,把测试集当做验证集去验证的话,这其实是作假的&am…...

appium ios真机自动化环境搭建运行(送源码)
appium ios真机自动化环境搭建&运行(送源码) 目录:导读 (1)安装JDK,并配置环境变量,方法如下: (2)安装Xcode、Xcode commandline tools和iOS模拟器 &…...
米尔基于ARM嵌入式核心板的电池管理系统(BMS)
BMS全称是Battery Management System,电池管理系统。它是配合监控储能电池状态的设备,主要就是为了智能化管理及维护各个电池单元,防止电池出现过充电和过放电,延长电池的使用寿命,监控电池的状态。 图片摘自网络 电池…...
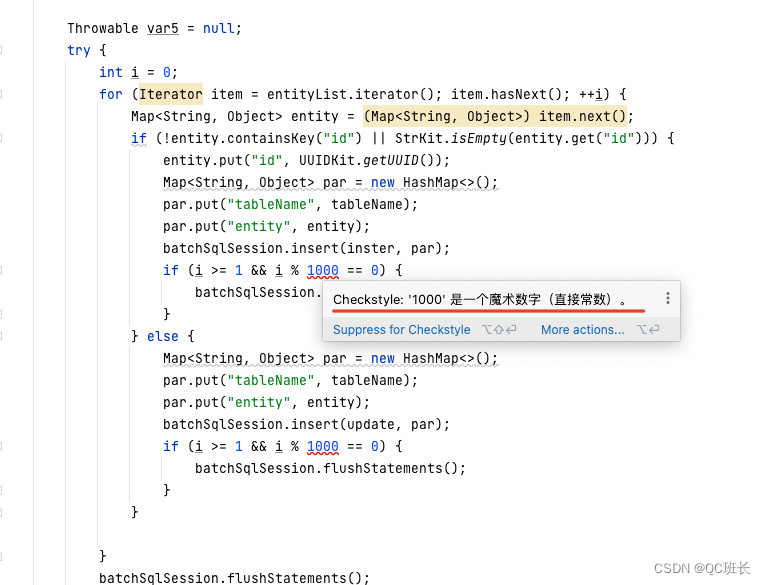
Java后端项目IDEA配置代码规范检查,使用checkStyle实现
最近的Java后端项目想实现代码的规范检查,调研了一圈,终于找到了简单的方式实现:以下是常见的几种方案: 1、在客户端做 git hook,主要是用 pre-commit 这个钩子。前端项目中常见的 husky 就是基于此实现的。但缺点也很…...
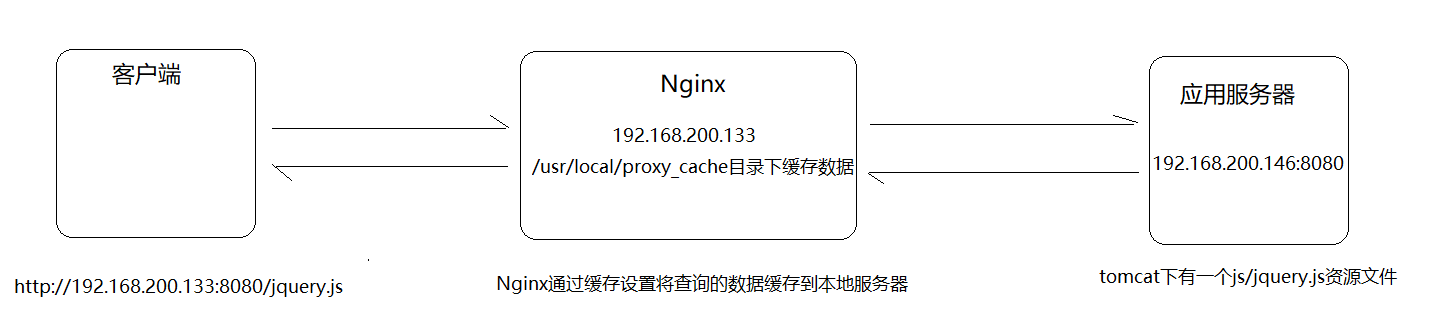
Nginx_4
Nginx负载均衡 负载均衡概述 早期的网站流量和业务功能都比较简单,单台服务器足以满足基本的需求,但是随着互联网的发展,业务流量越来越大并且业务逻辑也跟着越来越复杂,单台服务器的性能及单点故障问题就凸显出来了,…...
linux Ubuntu KUbuntu 系统安装相关
系统安装 本来想快到中午的时候调试一下服务器上的http请求接收代码。我的电脑上装的是kali的U盘系统,然后我的U盘居然找不到了(然后之前安装的系统不知道是否是写入软件的原因,没办法解析DNS,我都用的转发的,这让我体验非常差。kali的系统工具很多&…...

个人信息保护认证
个人信息保护认证是证明个人信息处理者在认证范围内开展的个人信息收集、存储、使用、加工、传输、提供、公开、删除以及跨境等处理活动符合认证依据标准要求。适用范围 本规则依据《中华人民共和国认证认可条例》制定,规定了对个人信息处理者开展个人信息收集、存储…...

Negative Prompt in Stable Diffusion
必读链接:https://www.reddit.com/r/StableDiffusion/comments/z7salo/with_the_right_prompt_stable_diffusion_20_can_do/ A lot of people have noticed that Negative Prompt works wonders in 2.0, and works even better in 2.1. Negative hints are the op…...

MLX90316KGO-BDG-100-RE传感器 旋转位置 角度测量
介绍MLX90316是Tria⊗is旋转位置传感器,提供在设备表面旋转的小偶极磁铁(轴端磁铁)的绝对角位置。得益于其表面的集成磁集中器(IMC),单片设备以非接触式方式感知应用磁通量密度的水平分量。这种独特的传感原理应用于旋转位置传感器,可在机械(…...
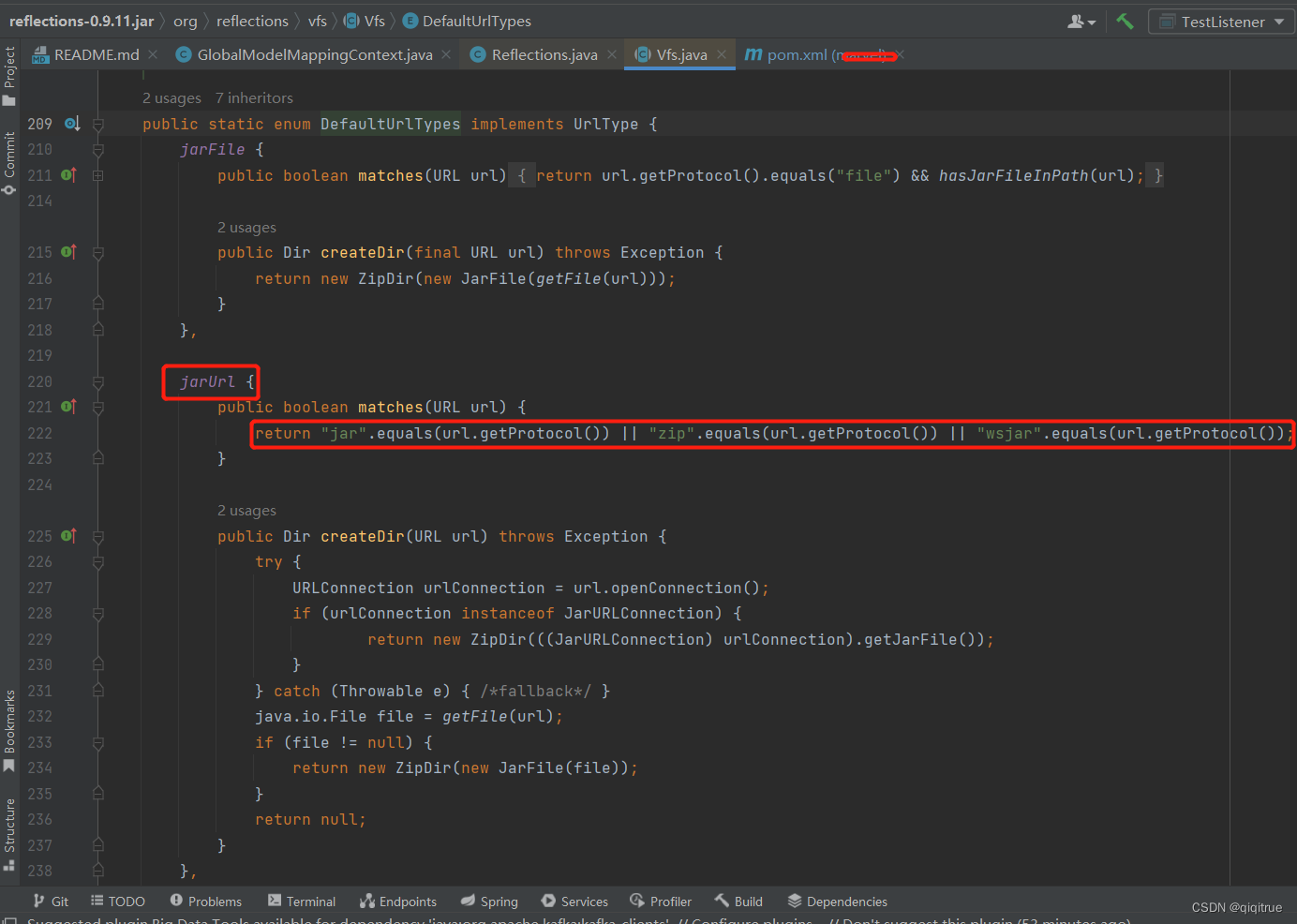
Reflections反射包在springboot jar环境下扫描不到class排查过程
需求: 要实现指定pkg(如com.qiqitrue.test.pojo)扫描包下所有class类信息:使用代码如下 使用的版本:0.10.2(截至目前是最新版)发现只能在idea编译期间可以获取得到(也就是在开发阶段…...
黑马】后台项目171集
将近一个月没有练习了,找到之后果然打不开出了问题【问题】运行代码打开网页后,发现不能正常登录,一开始还以为是密码记错了,后来发现是数据库没有正常启动,phpstudy中的数据库一直是启动状态,关闭不了。【…...
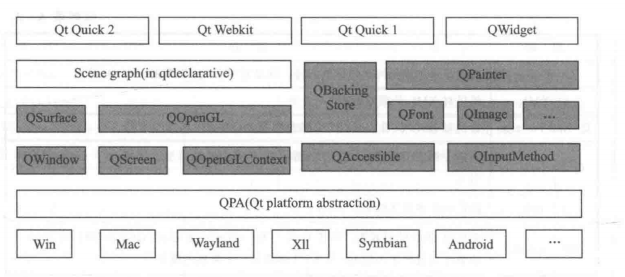
Qt 5 架构和特点
Qt 5 模块构架: 模块:功能:Qt CoreQt 5 的核心类库,每个模块都建立在Core上Qt GUI图形用户界面开发的最基础的类库Qt Widgets提供c用户界面部件(是对Qt GUI的拓展)Qt SQL对数据库进行操作Qt Multimedia、…...
)
转换符说明使用方法(在printf函数中)
目录 一些常见的转换说明及打印结果: printf()的转换说明修饰符 printf()函数打印数据指令时要与代打印数据的类型相匹配才行。 如%d %c %ld......这些符号叫做转换说明。代表着数据转化成显示的形式。 一些常见的…...

针灸-基本任脉督脉
这里写自定义目录标题 丈量 同身丈下针深浅一般入穴的方法成人 幼儿 不同入穴方式现代常用针概念十二经 纳天干**天干**地支表里关系筋络任脉中脘穴:梅花灸巨阙穴廉泉穴督脉长强腰俞命门阳关悬枢脊中筋缩眼诊 癫痫至阳消渴...

信息系统与信息化
1.1 信息系统与信息化 1.1.1 信息的基本概念 信息质量属性(掌握)信息传输模型 1.1.2 信息系统的基本概念1.1.3 信息化的基本概念 信息化的五个层次信息化基本内涵信息化的基本概念(了解)六要素关系图(掌握) 1.1.4 信息系统生命周…...
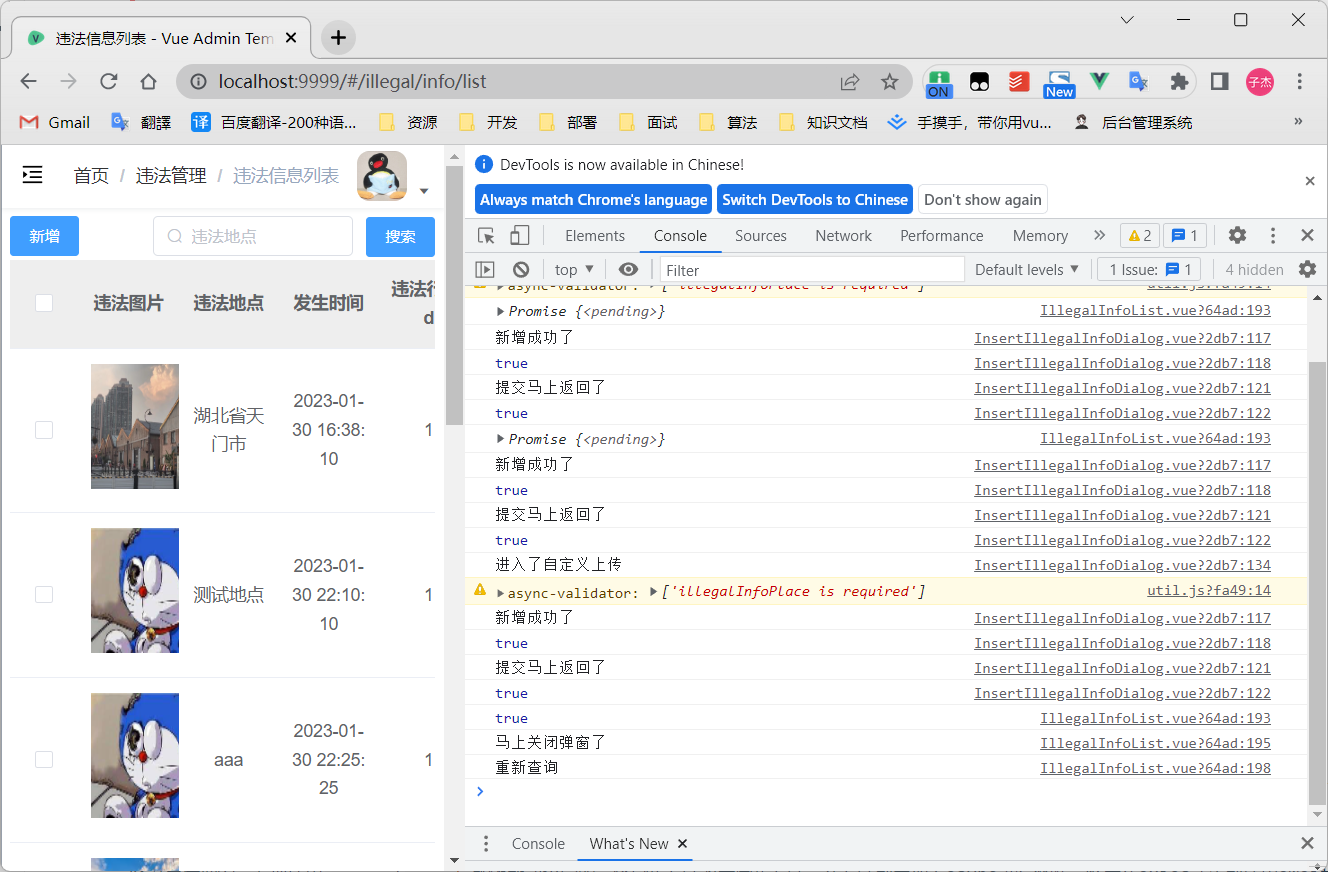
解决axios异步请求问题(异步变为同步)
遇到的问题 在目前一个需求中,我需要等待axios请求完成后,判断请求是否出现异常,然后来判断是否关闭弹窗 修改后大概代码如下: async submitForm() {let flag false//表单验证,默认通过let formValidation truethis…...

【Django】云笔记项目
一、介绍 用户可在系统中记录自己的笔记,用户的数据被存储在云笔记平台;用户和用户之间的数据为隔离存储(登陆后才能使用相关笔记功能,且只能查阅自己的笔记) 二、功能拆解 1、用户模块 注册:成为平台…...

LeetCode——1797. 设计一个验证系统
一、题目 你需要设计一个包含验证码的验证系统。每一次验证中,用户会收到一个新的验证码,这个验证码在 currentTime 时刻之后 timeToLive 秒过期。如果验证码被更新了,那么它会在 currentTime (可能与之前的 currentTime 不同&am…...
java Resource
参看本文前 你要先了解 spring中的 Autowired和Qualifier 注解 如果之前没有接触过 可以查看我的文章 java spring 根据注解方式按(类型/名称)注入Bean 然后 创建一个java项目 引入spring注解方式 所需要的包 然后 在src下创建包 我们这里直接叫 Bean 在Bean下创建包 叫UserD…...
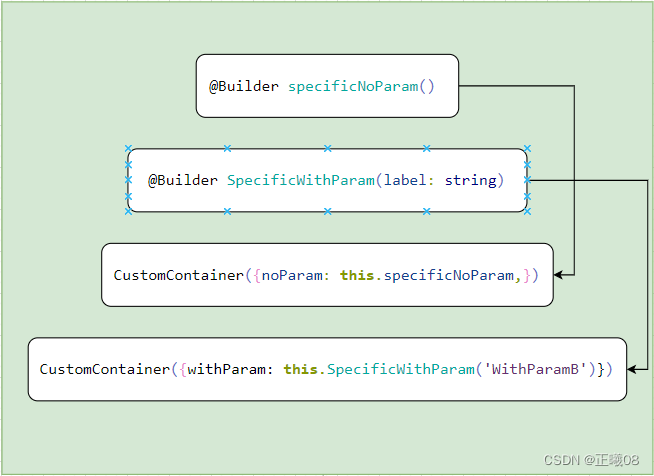
ArkTS语法(声明式UI)
页面级变量的状态管理 装饰器装饰内容说明State基本数据类型,类,数组修饰的状态数据被修改时会触发组件的build方法进行UI界面更新。Prop基本数据类型修改后的状态数据用于在父组件和子组件之间建立单向数据依赖关系。修改父组件关联数据时,…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
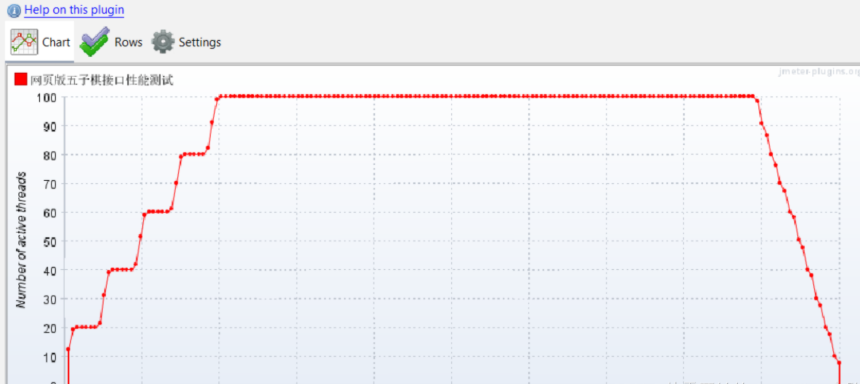
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
如何做好一份技术文档?从规划到实践的完整指南
如何做好一份技术文档?从规划到实践的完整指南 🌟 嗨,我是IRpickstars! 🌌 总有一行代码,能点亮万千星辰。 🔍 在技术的宇宙中,我愿做永不停歇的探索者。 ✨ 用代码丈量世界&…...