Python-第六天 Python数据容器
Python-第六天 Python数据容器
- 一、数据容器入门
- 1.数据容器
- 二、数据容器:list(列表)
- 1.列表的定义
- 2.列表的下标(索引)
- 3.列表的常用操作(方法)
- 4.练习案例:常用功能练习
- 5.list(列表)的遍历
- 5.1 列表的遍历 - while循环
- 5.2 列表的遍历 - for 循环
- 5.3 while循环和for循环的对比
- 5.4 练习
- 三、数据容器:tuple(元组)
- 1.元祖的定义
- 2.元祖的操作
- 3.元祖的特点
- 4.练习案例:元组的基本操作
- 四、数据容器:str(字符串)
- 1.再识字符串
- 2.字符串的下标(索引)
- 3.字符串常用操作汇总
- 4.字符串的遍历
- 5.字符串的特点
- 6.练习案例:分割字符串
- 五、数据容器的切片
- 1.序列
- 2.序列的常用操作 - 切片
- 3.练习案例:序列的切片实践
- 六、数据容器:set(集合)
- 1.定义和基本语法
- 2.常用方法
- 3.集合的特点
- 4.练习案例:信息去重
- 七、数据容器:dict(字典、映射)
- 1.定义和基本语法
- 2.常用方法
- 3.字典的嵌套
- 3.字典的特点
- 4.案例:升职加薪
- 八、数据容器的通用操作
- 1.数据容器对比总结
- 2.通用操作
- 3.字符串比较大小
- 九、综合案例
一、数据容器入门
1.数据容器
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
- 是否支持重复元素
- 是否可以修改
- 是否有序,等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
我们将一一学习它们
二、数据容器:list(列表)
1.列表的定义
基本语法:
# 字面量
[元素1,元素2,元素3,元素4,...]# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,...]# 定义空列表
变量名称 = []
变量名称 = list()
列表内的每一个数据,称之为元素
- 以
[]作为标识 - 列表内每一个元素之间用
,逗号隔开 - 注意:列表可以一次存储多个数据,
且可以为不同的数据类型,支持嵌套
示例:
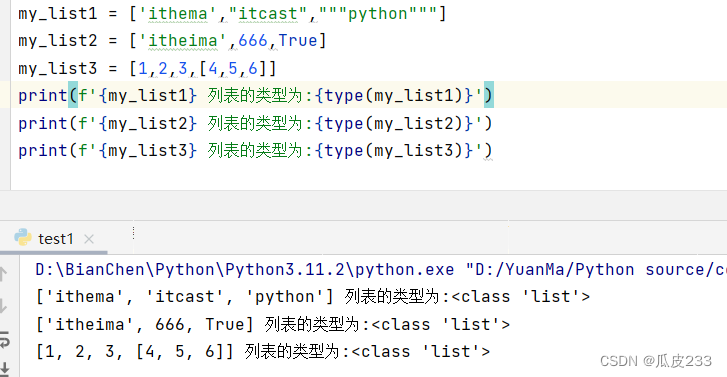
my_list1 = ['ithema',"itcast","""python"""]
my_list2 = ['itheima',666,True]
my_list3 = [1,2,3,[4,5,6]]
print(f'{my_list1} 列表的类型为:{type(my_list1)}')
print(f'{my_list2} 列表的类型为:{type(my_list2)}')
print(f'{my_list3} 列表的类型为:{type(my_list3)}')
2.列表的下标(索引)
我们可以使用下标索引从列表中取出特定位置的数据

如图,列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增
我们只需要按照下标索引,即可取得对应位置的元素。
基本语法
# 语法: 列表[下标索引]name_list = ['Tom','zs','ls']
print(name_list[0]) # 结果 :Tom
print(name_list[1]) # 结果 :zs
print(name_list[2]) # 结果 :ls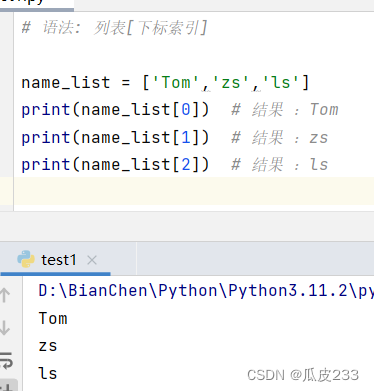
或者,可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3......)

如图,从后向前,下标索引为:-1、-2、-3,依次递减。
如果列表是嵌套的列表,同样支持下标索引
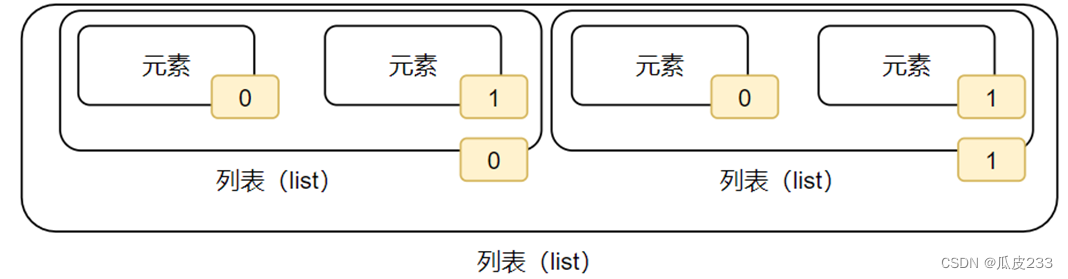
如图,下标就有2个层级了。
要注意下标索引的取值范围,超出范围无法取出元素,并且会报错
3.列表的常用操作(方法)
列表除了可以:
- 定义
- 使用下标索引获取值
以外,列表也提供了一系列功能:
- 插入元素
- 删除元素
- 清空列表
- 修改元素
- 统计元素个数
等等功能,这些功能我们都称之为:列表的方法
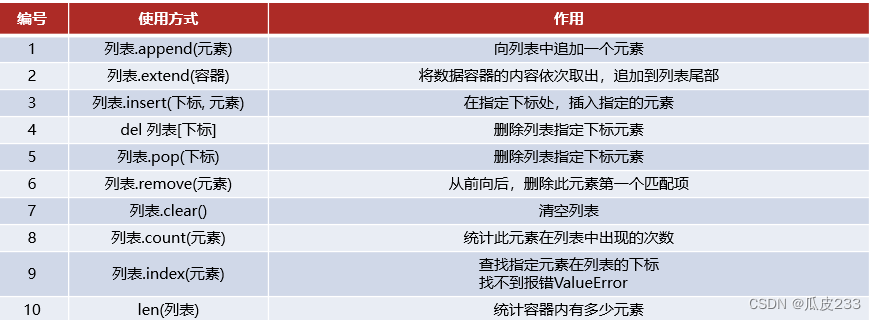
示例:
# 查询功能 列表.index(元素)
my_list =['itheima','itcast','python']
print(my_list.index('itcast')) #结果 :1# 修改功能# 1.修改特定位置元素的值 列表[下标] = 值 正向、反向下标均可
# 1.1正向下标
my_list = [1,2,3]
my_list[0] = 5
print(my_list) # 结果:[5,2,3]
# 1.2.反向下标
my_list = [1,2,3]
my_list[-3] = 5
print(my_list) # 结果:[5,2,3]# 2.插入元素 列表.insert(下标,元素) 在指定的下标位置,插入指定的元素
my_list = [1,2,3]
my_list.insert(1,'itheima')
print(my_list) # 结果:[1,'itheima',2,3]# 3.追加元素
# 3.1 列表.append(元素) 将指定元素,追加到列表尾部
my_list = [1,2,3]
my_list.append([4,5,6])
print(my_list) # 结果:[1,2,3,[4,5,6]]
# 3.2 列表.extend(其他数据容器) 将其他数据容器的内容取出,依次追加到列表尾部
my_list = [1,2,3]
my_list.extend([4,5,6])
print(my_list) # 结果:[1,2,3,4,5,6]# 4.删除元素
# 4.1 del 列表[下标]
my_list = [1,2,3]
del my_list[0]
print(my_list) # 结果:[2,3]
# 4.2 列表.pop(下标)
my_list = [1,2,3]
my_list.pop(0)
print(my_list) # 结果:[2,3]
# 4.3 列表.remove(元素) 删除某元素在列表中的第一个匹配项
my_list = [1,2,3,2,3]
my_list.remove(2)
print(my_list) # 结果:[1,3,2,3]
# 4.4 列表.clear() 清空列表
my_list = [1,2,3,2,3]
my_list.clear()
print(my_list) # 结果:[]# 列表.count(元素) 统计某元素在列表中的数量
my_list = [1,1,3,1,3]
print(my_list.count(1)) # 结果:3# len(列表) 统计列表内的元素个数
my_list = [1,1,3,1,3]
print(len(my_list)) # 结果:5
经过上述对列表的学习,可以总结出列表有如下特点:
- 可以容纳多个元素(上限为2**63-1、9223372036854775807个)
- 可以容纳不同类型的元素(混装)
- 数据是有序存储的(有下标序号)
- 允许重复数据存在
- 可以修改(增加或删除元素等)
4.练习案例:常用功能练习
有一个列表,内容是:[21, 25, 21, 23, 22, 20],记录的是一批学生的年龄
请通过列表的功能(方法),对其进行
- 定义这个列表,并用变量接收它
- 追加一个数字31,到列表的尾部
- 追加一个新列表[29, 33, 30],到列表的尾部
- 取出第一个元素(应是:21)
- 取出最后一个元素(应是:30)
- 查找元素31,在列表中的下标位置
# 定义这个列表,并用变量接收它
age_list = [21, 25, 21, 23, 22, 20]
print(age_list)
# 追加一个数字31,到列表的尾部
age_list.append(31)
print(age_list)
# 追加一个新列表[29, 33, 30],到列表的尾部
age_list.extend([29,33,30])
print(age_list)
# 取出第一个元素(应是:21)
print(age_list[0])
# 取出最后一个元素(应是:30)
print(age_list[-1])
# 查找元素31,在列表中的下标位置
print(age_list.index(31))

5.list(列表)的遍历
5.1 列表的遍历 - while循环
语法
index = 0
while index < len(列表):元素 = 列表[index]对元素处理index +=1
5.2 列表的遍历 - for 循环
语法
for 临时变量 in 数据容器:对临时变量处理
5.3 while循环和for循环的对比
while循环和for循环,都是循环语句,但细节不同:
在循环控制上:
- while循环可以自定循环条件,并自行控制
- for循环不可以自定循环条件,只可以一个个从容器内取出数据
在无限循环上:
- while循环可以通过条件控制做到无限循环
- for循环理论上不可以,因为被遍历的容器容量不是无限的
在使用场景上:
- while循环适用于任何想要循环的场景
- for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
5.4 练习
定义一个列表,内容是:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
遍历列表,取出列表内的偶数,并存入一个新的列表对象中
使用while循环和for循环各操作一次

提示:
- 通过if判断来确认偶数
- 通过列表的append方法,来增加元素
"""
定义一个列表,内容是:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
遍历列表,取出列表内的偶数,并存入一个新的列表对象中
使用while循环和for循环各操作一次提示:
通过if判断来确认偶数
通过列表的append方法,来增加元素"""
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_list = []
index = 0
#while
while index < len(my_list):if my_list[index] % 2 == 0:even_list.append(my_list[index])index+=1
print(f'通过while循环,从列表:{my_list}中取出偶数,组成新列表:{even_list}')# for
even_list = []
for el in my_list:if el % 2 == 0:even_list.append(el)
print(f'通过for循环,从列表:{my_list}中取出偶数,组成新列表:{even_list}')
三、数据容器:tuple(元组)
1.元祖的定义
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
语法
# 定义元祖字面量
(元素1,元素2,元素3,元素4,....)
# 定义元祖变量
变量名称 = (元素1,元素2,元素3,元素4,....)
# 定义空元祖
变量名称 = ()
变量名称 = tuple()
# 元祖也支持嵌套
t1 = ((1,2,3),(4,5,6))
注意:
- 元组一旦定义完成,就不可修改.所以,当我们需要在程序内封装数据,又不希望封装的数据被篡改,那么元组就非常合适
- 元祖只有一个数据,这个数据后面要加逗号 (元素1,)
2.元祖的操作

示例:
t = (1,2,'hello',3,4,'hello',1)
# 根据下标取出数据
print(t[2]) # 结果为 hello
# index() 查找某个数据,如果数据存在返回对应的下标,否则报错
print(t.index('hello')) # 结果为 2
# count() 统计某个数据在当前元组出现的次数
print(t.count(1)) # 结果为 2
# len(元组) 统计元组内的元素个数
print(len(t)) # 结果为 7
3.元祖的特点
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是有序存储的(下标索引)
- 允许重复数据存在
不可以修改(增加或删除元素等)- 支持for循环
多数特性和list一致,不同点在于不可修改的特性。
4.练习案例:元组的基本操作
定义一个元组,内容是:(‘周杰轮’, 11, [‘football’, ‘music’]),记录的是一个学生的信息(姓名、年龄、爱好)
请通过元组的功能(方法),对其进行
- 查询其年龄所在的下标位置
- 查询学生的姓名
- 删除学生爱好中的football
- 增加爱好:coding到爱好list内
t =('周杰轮', 11, ['football', 'music'])
print(t.index(11))
print(t[0])
t[-1].remove('football')
print(t)
t[-1].append('coding')
print(t)
四、数据容器:str(字符串)
1.再识字符串
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器。
但不可否认的是,字符串同样也是数据容器的一员。

字符串是字符的容器,一个字符串可以存放任意数量的字符。
如,字符串:“itheima”
2.字符串的下标(索引)
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
- 从前向后,下标从0开始
- 从后向前,下标从-1开始
同元组一样,字符串是一个:无法修改的数据容器。
所以:
- 修改指定下标的字符 (如:字符串[0] = “a”)
- 移除特定下标的字符 (如:del 字符串[0]、字符串.remove()、字符串.pop()等)
- 追加字符等 (如:字符串.append())
均无法完成。如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改
3.字符串常用操作汇总

4.字符串的遍历
同列表、元组一样,字符串也支持while循环和for循环进行遍历
5.字符串的特点
作为数据容器,字符串有如下特点:
只可以存储字符串- 长度任意(取决于内存大小)
- 支持下标索引
- 允许重复字符串存在
不可以修改(增加或删除元素等)- 支持for循环
基本和列表、元组相同
不同与列表和元组的在于:字符串容器可以容纳的类型是单一的,只能是字符串类型。
不同于列表,相同于元组的在于:字符串不可修改
6.练习案例:分割字符串
给定一个字符串:“itheima itcast boxuegu”
- 统计字符串内有多少个"it"字符
- 将字符串内的空格,全部替换为字符:“|”
- 并按照"|"进行字符串分割,得到列表

提示:
count、replace、split
str = "itheima itcast boxuegu"
print(f'字符串{str}中有:{str.count("it")}个it字符')
str1 = str.replace(' ','|')
print(f'字符串{str},被替换空格后,结果:{str1}')
list = str1.split('|')
print(f'字符串{str1},按照|分隔后,结果:{list}')
五、数据容器的切片
1.序列
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。


如图,序列的典型特征就是:有序并可用下标索引,字符串、元组、列表均满足这个要求
2.序列的常用操作 - 切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:
序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
示例:
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4] # 下标1开始,下标4(不含)结束,步长1
print(new_list) # 结果:[2, 3, 4]my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:] # 从头开始,到最后结束,步长1
print(new_tuple) # 结果:(1, 2, 3, 4, 5)my_list = [1, 2, 3, 4, 5]
new_list = my_list[::2] # 从头开始,到最后结束,步长2
print(new_list) # 结果:[1, 3, 5]my_str = "12345"
new_str = my_str[:4:2] # 从头开始,到下标4(不含)结束,步长2
print(new_str) # 结果:"13"my_str = "12345"
new_str = my_str[::-1] # 从头(最后)开始,到尾结束,步长-1(倒序)
print(new_str) # 结果:"54321"my_list = [1, 2, 3, 4, 5]
new_list = my_list[3:1:-1] # 从下标3开始,到下标1(不含)结束,步长-1(倒序)
print(new_list) # 结果:[4, 3]my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:1:-2] # 从头(最后)开始,到下标1(不含)结束,步长-2(倒序)
print(new_tuple) # 结果:(5, 3)
3.练习案例:序列的切片实践
有字符串:“万过薪月,员序程马黑来,nohtyP学”
请使用学过的任何方式,得到"黑马程序员"
可用方式参考:
倒序字符串,切片取出或切片取出,然后倒序
split分隔"," replace替换"来"为空,倒序字符串
str = "万过薪月,员序程马黑来,nohtyP学"
print(str[9:4:-1])
print(str[::-1][9:14])
print(str[5:10][::-1])
print(str.split(',')[1].replace("来","")[::-1])
六、数据容器:set(集合)
1.定义和基本语法
# 定义集合字面量
{元素,元素,...,元素}
# 定义集合变量
变量名称 = {元素,元素,...,元素}
# 定义空集合
变量名称 = set()
和列表、元组、字符串等定义基本相同:
- 列表使用:[]
- 元组使用:()
- 字符串使用:“”
- 集合使用:{}
首先,因为集合是无序的,所以集合不支持:下标索引访问
但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法。
2.常用方法

-
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素 -
移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素 -
从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除 -
清空集合
语法:集合.clear(),功能,清空集合
结果:集合本身被清空 -
取出2个集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变 -
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变 -
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变 -
查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果 -
集合同样支持使用for循环遍历
-
要注意:集合不支持下标索引,所以也就不支持使用while循环。
my_set = {'Hello','World'}
my_set.add('itheima')
print(my_set) # 结果{'Hello','World','itheima'}my_set = {'Hello','World','itheima'}
my_set.remove('Hello')
print(my_set) # 结果{'World','itheima'}my_set = {'Hello', 'World', 'itheima'}
my_set.clear()
print(my_set) # 结果{}my_set = {'Hello', 'World', 'itheima'}
element = my_set.pop()
print(my_set) # 结果{'itheima','World'}
print(element) # 结果 'Hello'set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2) # 得到新集合
print(set3) # 结果 {2,3}
print(set1) # 结果 {1,2,3} 不变
print(set2) # 结果 {1,5,6} 不变set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2)
print(set1) # 结果 {2,3}
print(set2) # 结果 {1,5,6} 不变set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2) # 得到新集合
print(set3) # 结果 {1,2,3,5,6}
print(set1) # 结果 {1,2,3} 不变
print(set2) # 结果 {1,5,6} 不变set1 = {1, 2, 3}
print(len(set1)) # 结果 3set1 = {1, 2, 3}
for i in set1:print(i)# 结果# 1# 2# 3
3.集合的特点
经过上述对集合的学习,可以总结出集合有如下特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是无序存储的(不支持下标索引)
- 不允许重复数据存在
- 可以修改(增加或删除元素等)
- 支持for循环
4.练习案例:信息去重
有如下列表对象:
my_list = [‘黑马程序员’, ‘传智播客’, ‘黑马程序员’, ‘传智播客’, ‘itheima’, ‘itcast’, ‘itheima’, ‘itcast’, ‘best’]
请:
- 定义一个空集合
- 通过for循环遍历列表
- 在for循环中将列表的元素添加至集合
- 最终得到元素去重后的集合对象,并打印输出

my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客','itheima', 'itcast', 'itheima', 'itcast', 'best']
# 方法1
# set1 = set(my_list)# 方法2
set1 = set()
for i in my_list:set1.add(i)
print(set1)
七、数据容器:dict(字典、映射)
1.定义和基本语法
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
# 定义字典字面量
{key: value, key: value, ..., key: value}
# 定义字典变量
my_dict = {key: value, key: value, ..., key: value}
# 定义空自定空字典
my_dict = {}
my_dict = dict()
- 使用{}存储原始,每一个元素是一个键值对
- 每一个键值对包含Key和Value(用冒号分隔)
- 键值对之间使用逗号分隔
- Key和Value可以是任意类型的数据(key不可为字典)
- Key不可重复,重复会对原有数据覆盖
2.常用方法

-
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value 字典[Key] -
新增元素
语法:字典[Key] = Value,结果:字典被修改,新增了元素 -
更新元素
语法:字典[Key] = Value,结果:字典被修改,元素被更新
注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值 -
删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除 -
清空字典
语法:字典.clear(),结果:字典被修改,元素被清空 -
获取全部的key
语法:字典.keys(),结果:得到字典中的全部Key -
遍历字典
语法:for key in 字典.keys()
注意:字典不支持下标索引,所以同样不可以用while循环遍历
- 计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
# 语法 :字典[key] 可以取到对应的value
stu_soure = {"王力宏":99,"周杰伦":88,"林俊杰":77}
print(stu_soure["王力宏"]) # 结果99
print(stu_soure["周杰伦"]) # 结果88
print(stu_soure["林俊杰"]) # 结果77# 新增元素
# 语法:字典[Key] = Value,结果:字典被修改,新增了元素
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
stu_score['张学友'] = 66
print(stu_score) # 结果 {'王力宏': 77, '周杰伦': 88, '林俊杰': 99, '张学友': 66}# 更新元素
# 语法:字典[Key] = Value,结果:字典被修改,元素被更新
# 注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
stu_score['王力宏'] = 100
print(stu_score) # 结果 {'王力宏': 100, '周杰伦': 88, '林俊杰': 99}# 删除元素
# 语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
value = stu_score.pop('王力宏')
print(value) # 结果 77
print(stu_score) # 结果 {'周杰伦': 88, '林俊杰': 99}# 清空字典
# 语法:字典.clear(),结果:字典被修改,元素被清空
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
value = stu_score.clear()
print(stu_score) # 结果 {}# 获取全部的key
# 语法:字典.keys(),结果:得到字典中的全部Key
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
keys = stu_score.keys()
print(keys) # 结果 dict_keys(['王力宏', '周杰伦', '林俊杰'])# 遍历字典
# 语法:for key in 字典.keys()
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
for key in stu_score.keys():print(stu_score[key]) # 结果 77 88 99# 注意:字典不支持下标索引,所以同样不可以用while循环遍历# 计算字典内的全部元素(键值对)数量
# 语法:len(字典)
# 结果:得到一个整数,表示字典内元素(键值对)的数量
stu_score = {'王力宏': 77,'周杰伦': 88,'林俊杰': 99,
}
print(len(stu_score)) # 结果 3
3.字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)
字典是可以嵌套的
需求如下:记录学生各科的考试信息

stu_score = {'王力宏': {'语文': 77, '数学': 66, '英语': 33, }, '周杰伦': {'语文': 88, '数学': 86, '英语': 55, }, '林俊杰': {'语文': 99, '数学': 96, '英语': 66, }, }# 优化一下可读性,可以写成:
stu_score = {'王力宏': {'语文': 77, '数学': 66, '英语': 33, },'周杰伦': {'语文': 88, '数学': 86, '英语': 55, },'林俊杰': {'语文': 99, '数学': 96, '英语': 66, },
}
嵌套字典的内容获取
嵌套字典的内容获取,如下所示:
stu_score = {'王力宏': {'语文': 77, '数学': 66, '英语': 33, },'周杰伦': {'语文': 88, '数学': 86, '英语': 55, },'林俊杰': {'语文': 99, '数学': 96, '英语': 66, },
}
print(stu_score['王力宏']) # 结果 {'语文': 77, '数学': 66, '英语': 33 }
print(stu_score['王力宏']['语文']) # 结果 77
print(stu_score['周杰伦']['数学']) # 结果 863.字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据
- 每一份数据是KeyValue键值对
- 可以通过Key获取到Value,Key不可重复(重复会覆盖)
- 不支持下标索引
- 可以修改(增加或删除更新元素等)
- 支持for循环,不支持while循环
4.案例:升职加薪
有如下员工信息,请使用字典完成数据的记录。
并通过for循环,对所有级别为1级的员工,级别上升1级,薪水增加1000元

运行后,输出如下信息:

employee_info = {'王力宏': {'部门': '科技部', '工资': 3000, '级别': 1},'周杰轮': {'部门': '市场部', '工资': 5000, '级别': 2},'林俊节': {'部门': '市场部', '工资': 7000, '级别': 3},'张学油': {'部门': '科技部', '工资': 4000, '级别': 1},'刘德滑': {'部门': '市场部', '工资': 6000, '级别': 2},
}
print(f'全体员工当前信息如下:\n{employee_info}')
for names in employee_info:if employee_info[names]['级别'] == 1:employee_info[names]['级别'] += 1employee_info[names]['工资'] += 1000
print(f'全体员工级别为1的员工完成升职加薪操作,操作后:\n{employee_info}')
八、数据容器的通用操作
1.数据容器对比总结
数据容器可以从以下视角进行简单的分类:
-
是否支持下标索引
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
-
是否支持重复元素:
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
-
是否可以修改
- 支持:列表、集合、字典
- 不支持:元组、字符串

基于各类数据容器的特点,它们的应用场景如下:
- 列表:一批数据,可修改、可重复的存储场景
- 元组:一批数据,不可修改、可重复的存储场景
- 字符串:一串字符串的存储场景
- 集合:一批数据,去重存储场景
- 字典:一批数据,可用Key检索Value的存储场景
2.通用操作

数据容器的通用操作 - 遍历
- 5类数据容器都支持for循环遍历
- 列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
数据容器的通用统计功能
- len(容器) 统计容器的元素个数
- max(容器) 统计容器的最大元素
- min(容器) 统计容器的最小元素
# len(容器)
# 统计容器的元素个数
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"print(len(my_list)) # 结果3
print(len(my_tuple)) # 结果5
print(len(my_str)) # 结果8# max(容器)
# 统计容器的最大元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"print(max(my_list)) # 结果3
print(max(my_tuple)) # 结果5
print(max(my_str)) # 结果t# min(容器)
# 统计容器的最小元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"print(min(my_list)) # 结果1
print(min(my_tuple)) # 结果1
print(min(my_str)) # 结果a
数据容器转换功能
- list(容器) 将给定容器转换为列表
- str(容器) 将给定容器转换为字符串
- tuple(容器) 将给定容器转换为元组
- set(容器) 将给定容器转换为集合
# 数据容器转换功能
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = 'abcdefg'
my_set = {1, 2, 3, 4, 5}
my_dict = {'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4, 'key5': 5, }
# list(容器)
# 将给定容器转换为列表
print(f'列表转换列表的结果是{list(my_list)}') # [1, 2, 3, 4, 5]
print(f'元祖转换列表的结果是{list(my_tuple)}') # [1, 2, 3, 4, 5]
print(f'字符串转换列表的结果是{list(my_str)}') # ['a', 'b', 'c', 'd', 'e', 'f', 'g']
print(f'集合转换列表的结果是{list(my_set)}') # [1, 2, 3, 4, 5]
# ['key1', 'key2', 'key3', 'key4', 'key5']
print(f'字典转换列表的结果过是{list(my_dict)}')# str(容器)
# 将给定容器转换为字符串
print('----------------------')
print(f'列表转换字符串的结果是{str(my_list)}') # '[1, 2, 3, 4, 5]'
print(f'元祖转换字符串的结果是{str(my_tuple)}') # '(1, 2, 3, 4, 5)'
print(f'字符串转换字符串的结果是{str(my_str)}') # 'abcdefg'
print(f'集合转换字符串的结果是{str(my_set)}') # '{1, 2, 3, 4, 5}'
# '{'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4, 'key5': 5, }'
print(f'字典转换字符串的结果是{str(my_dict)}')# tuple(容器)
# 将给定容器转换为元组
print('----------------------')
print(f'列表转换元祖的结果是{tuple(my_list)}') # (1, 2, 3, 4, 5)
print(f'元祖转换元祖的结果是{tuple(my_tuple)}') # (1, 2, 3, 4, 5)
print(f'字符串转换元祖的结果是{tuple(my_str)}') # ('a', 'b', 'c', 'd', 'e', 'f', 'g')
print(f'集合转换元祖的结果是{tuple(my_set)}') # (1, 2, 3, 4, 5)
# ('key1', 'key2', 'key3', 'key4', 'key5')
print(f'字典转换元祖的结果是{tuple(my_dict)}')# set(容器)
# 将给定容器转换为集合
print('----------------------')
print(f'列表转换集合的结果是{set(my_list)}') # {1, 2, 3, 4, 5}
print(f'元祖转换集合的结果是{set(my_tuple)}') # {1, 2, 3, 4, 5}
print(f'字符串转换集合的结果是{set(my_str)}') # {1, 2, 3, 4, 5}
print(f'集合转换集合的结果是{set(my_set)}') # {1, 2, 3, 4, 5}
# {'key1', 'key4', 'key5', 'key2', 'key3'}
print(f'字典转换集合的结果是{set(my_dict)}')
容器排序功能
sorted(容器, [reverse=True])
注意,排序后都会得到列表(list)对象。
# 容器通用排序功能
# sorted(容器, [reverse=True])
# 将给定容器进行排序
# 数据容器转换功能
my_list = [1, 5, 3, 4, 2]
my_tuple = (1, 5, 3, 2, 4)
my_str = 'gbdecfa'
my_set = {1, 5, 2, 4, 3}
my_dict = {'key1': 1, 'key3': 3, 'key4': 4, 'key2': 2, 'key5': 5, }print(f'列表排序的结果是{sorted(my_list)}') # [1, 2, 3, 4, 5]
print(f'元祖排序的结果是{sorted(my_tuple)}') # [1, 2, 3, 4, 5]
print(f'字符排序的结果是{sorted(my_str)}') # ['a', 'b', 'c', 'd', 'e', 'f', 'g']
print(f'集合排序的结果是{sorted(my_set)}') # [1, 2, 3, 4, 5]
# ['key1', 'key2', 'key3', 'key4', 'key5']
print(f'字典排序的结果过是{sorted(my_dict)}')
3.字符串比较大小
在程序中,字符串所用的所有字符如:
- 大小写英文单词
- 数字
- 特殊符号(!、\、|、@、#、空格等)
都有其对应的ASCII码表值
每一个字符都能对应上一个:数字的码值
字符串进行比较就是基于数字的码值大小进行比较的。

字符串是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大。

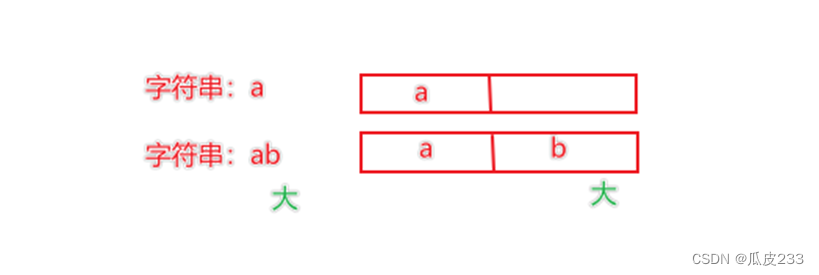
九、综合案例
1 . 幸运数字6:输入任意数字,如数字8,生成nums列表,元素值为1~8,从中选取幸运数字(能够被6整除)移动到新列表lucky,打印nums与lucky。
num = int(input('请输入数字:'))
nums = range(1, num+1)
nums = list(nums)
lucky = []
for i in nums:if i % 6 == 0:lucky.append(i)
print(f'产生的列表nums为:{nums}\n幸运数字列表lucky为:{lucky}')
2 列表嵌套:有3个教室[[],[],[]],8名讲师[‘A’,‘B’,‘C’,‘D’,‘E’,‘F’,‘G’,‘H’],将8名讲师随机分配到3个教室中
import randomrooms = [[], [], []]
teachers = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']for teacher in teachers:index = random.randint(0, 2)rooms[index].append(teacher)print(rooms)i = 1
for room in rooms:print(f'第{i}个教室中的讲师:{room}')i += 1
相关文章:
Python-第六天 Python数据容器
Python-第六天 Python数据容器一、数据容器入门1.数据容器二、数据容器:list(列表)1.列表的定义2.列表的下标(索引)3.列表的常用操作(方法)4.练习案例:常用功能练习5.list(列表)的遍历5.1 列表的…...

【C/C++基础练习题】复习题三,易错点知识点笔记
C复习题知识点记录: 在定义结构体类型时,不可以为成员设置默认值。 在公用一个共用体变量时。系统为其分配存储空间的原则是按成员中占内存空间最大者分配 a ,La, "a", L"a" 字符 长字符 字符串 长字符串 布尔类型只有两个值 fal…...

Mysql sql优化
插入优化 1️⃣ 用批量插入代替单条插入 insert into 表明 values(1, xxx) insert into 表明 values(2, xxx) ... 改为使用👇 insert into 表名 values(1, xxx), (2, xxx)...2️⃣ 手动提交事务 start tranaction; insert into 表名 values(1, xxx), (2, xxx)... in…...

vnode 在 Vue 中的作用
vnode就是 Vue 中的 虚拟 dom 。 vnode 是怎么来的? 就是把 template 中的结构内容,通过 vue template complier 中的 render 函数(使用了 JS 中的 with 语法),来生成 template 中对应的 js 数据结构,举个例…...
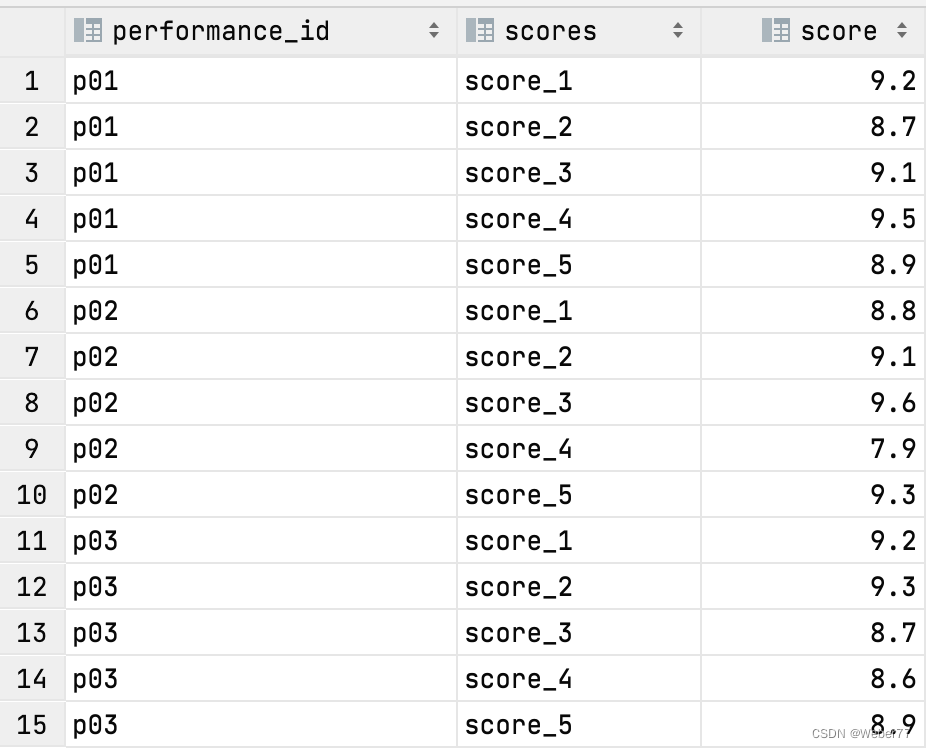
SQL语句实现找到一行中数据最大值(greatest)/最小值(least);mysql行转列
今日我在刷题时遇到这样一个题,它提到了以下需求: 有一场节目表演,五名裁判会对节目提供1-10分的打分,节目最终得分为去掉一个最高分和一个最低分后的平均分。 存在以下一张表performence_detail,包含字段有performa…...
记一次以小勃大,紧张刺激的渗透测试(2017年老文)
一、起因 emmm,炎炎夏日到来,这么个桑拿天干什么好呢? 没错,一定要坐在家里,吹着空调,吃着西瓜,然后静静地挖洞。挖洞完叫个外卖,喝着啤酒,撸着烧烤,岂不美…...

LeetCode 61. 旋转链表
原题链接 难度:middle\color{orange}{middle}middle 题目描述 给你一个链表的头节点 headheadhead ,旋转链表,将链表每个节点向右移动 kkk 个位置。 示例 1: 输入:head [1,2,3,4,5], k 2 输出:[4,5,1…...

数据库(4)--视图的定义和使用
一、学习目的 加深对视图的理解,熟练视图的定义、查看、修改等操作 二、实验环境 Windows 11 Sql server2019 三、实验内容 学生(学号,年龄,性别,系名) 课程(课号,课名,…...
pandas表格并表(累加合并)
今天需求是用pandas的两张表格合并起来,其中重复的部分将数据进行相加。 用到的是combine()这个函数。 函数详细的使用可以看这个大佬的文章: https://www.cnblogs.com/traditional/p/12727997.html (这个文章使用的测…...
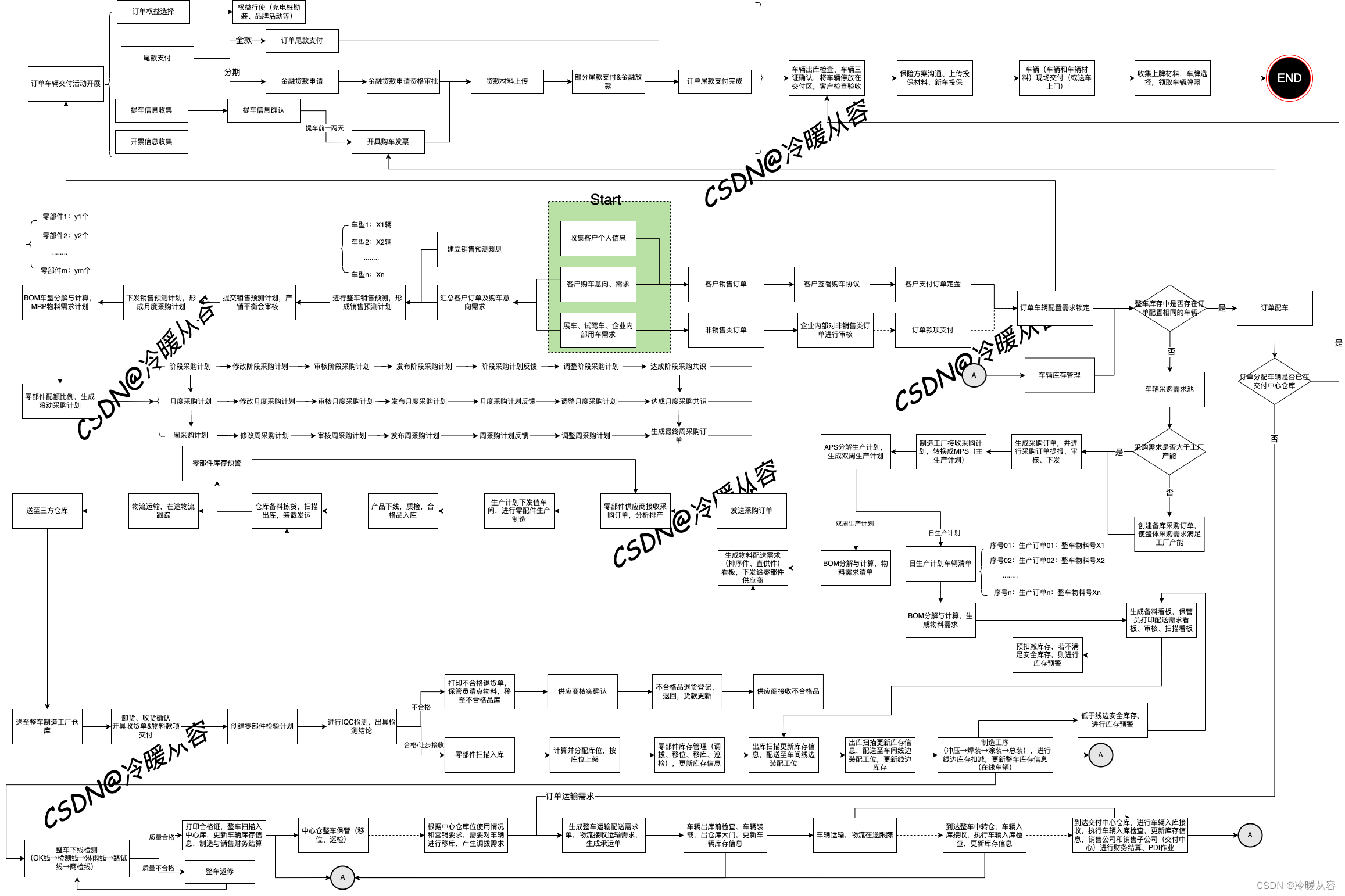
汽车直营模式下OTD全流程
概述 随着新能源汽车的蓬勃发展,造车新势力的涌入,许多新能源车企想通过直营的营销模式来解决新能源汽车市场推广速度缓慢问题,而直营模式下OTD(Order-To-Delivery,订单-交付)全流程的改革创新在这过程中无…...

如何在 Canvas 上实现图形拾取?
图形拾取,指的是用户通过鼠标或手指在图形界面上能选中图形的能力。图形拾取技术是之后的高亮图形、拖拽图形、点击触发事件的基础。 canvas 作为一个过于朴实无华的绘制工具,我们想知道如何让 canvas 能像 HTML 一样,知道鼠标点中了哪个 “…...

适用于媒体行业的管理数据解决方案—— StorageGRID Webscale
主要优势 1、降低媒体存储库的复杂性 • 借助真正的全局命名空间在全球范围内存储数据并在本地进行访问。 • 实施纠删编码和远程复制策略。 • 通过单一管理平台管理策略和监控存储。 2、优化媒体工作流 • 确认内容在合适的时间处于合适的位置。 • 支持应用程序直接通过 A…...

Springboot+ElasticSearch构建博客检索系统-学习笔记01
课程简介:从实际需求分析开始,打造个人博客检索系统。内容涵盖:ES安装、ES基本概念和数据类型、Mysql到ES数据同步、SpringBoot操作ES。通过本课,让学员对ES有一个初步认识,理解ES的一些适用场景,以及如何使…...
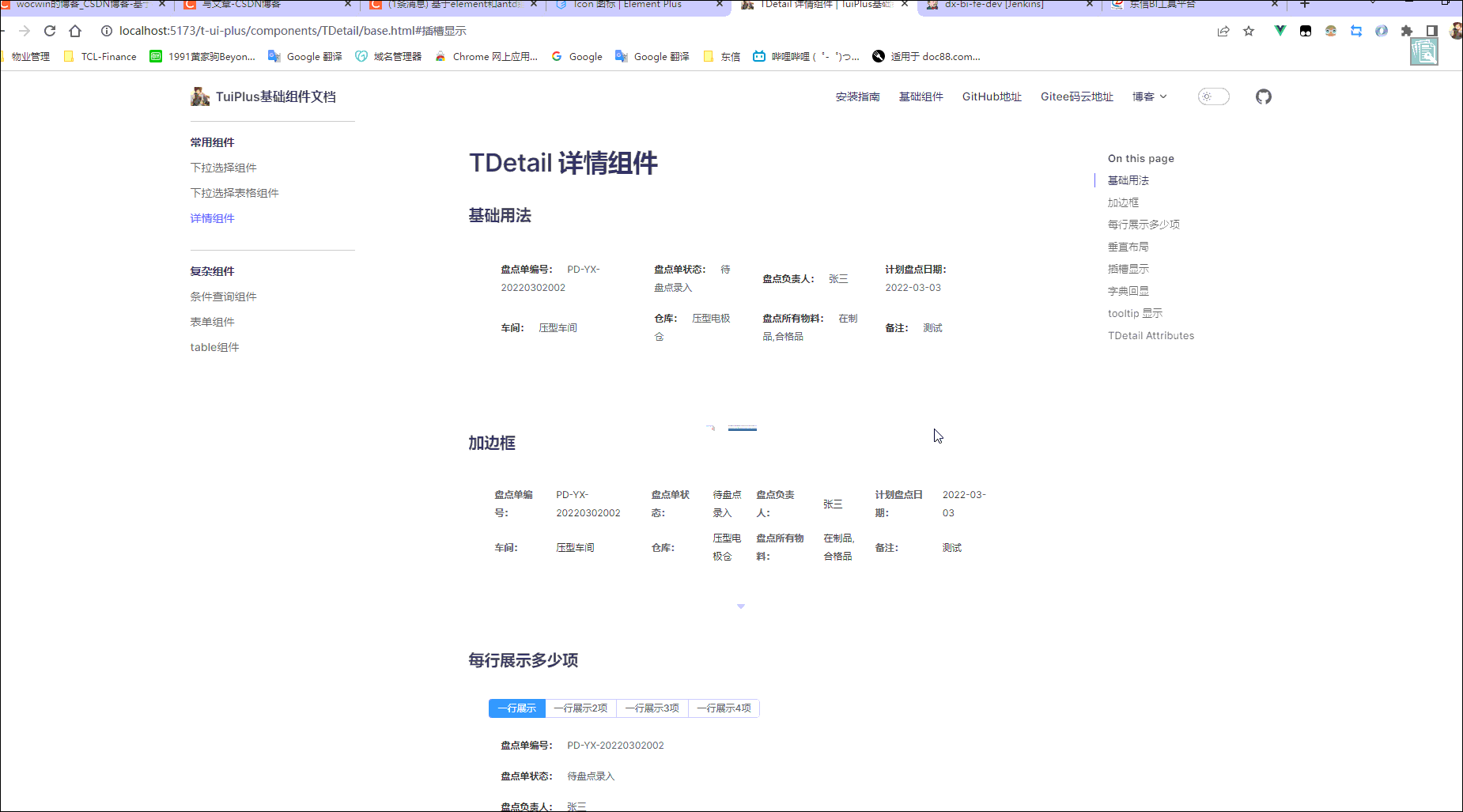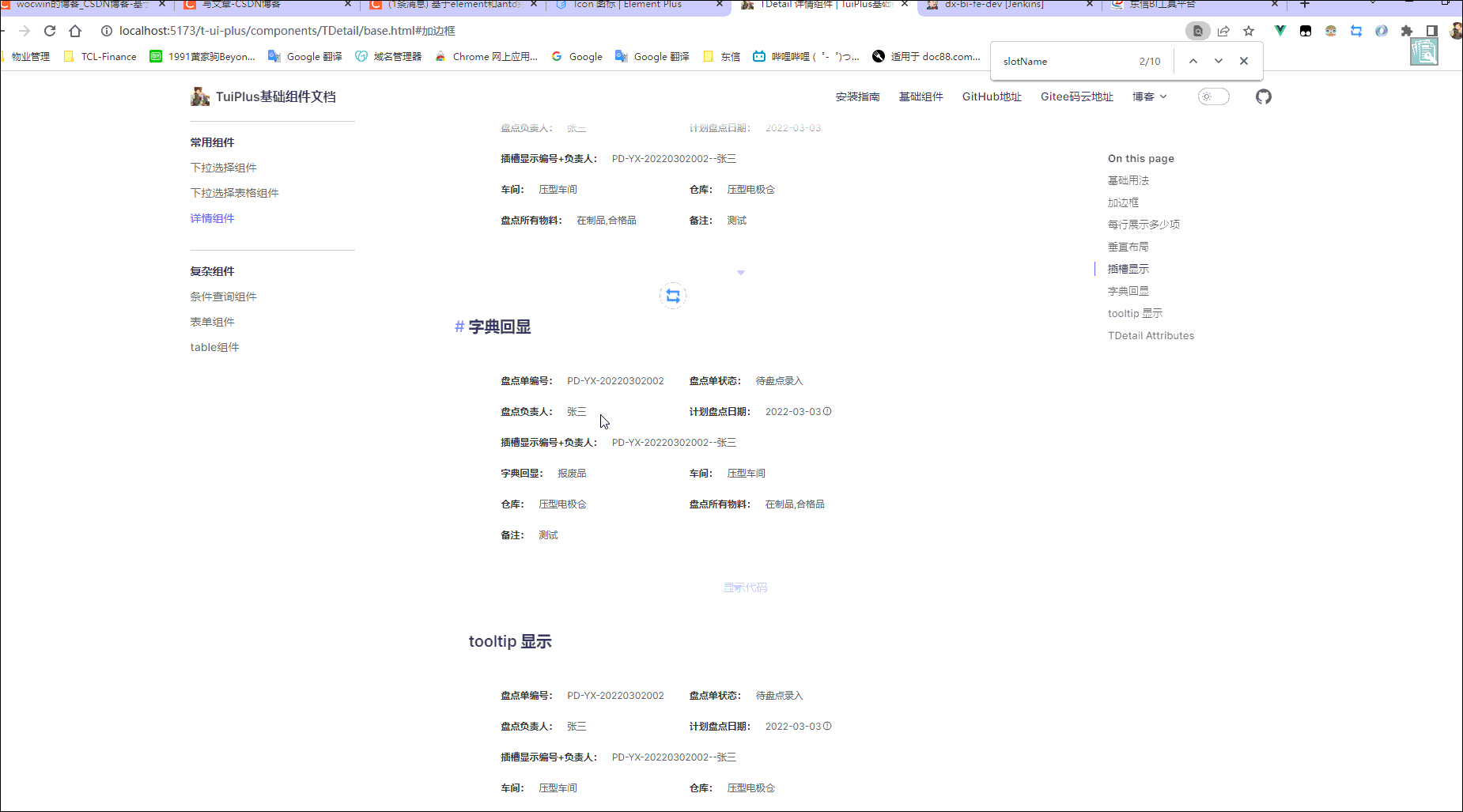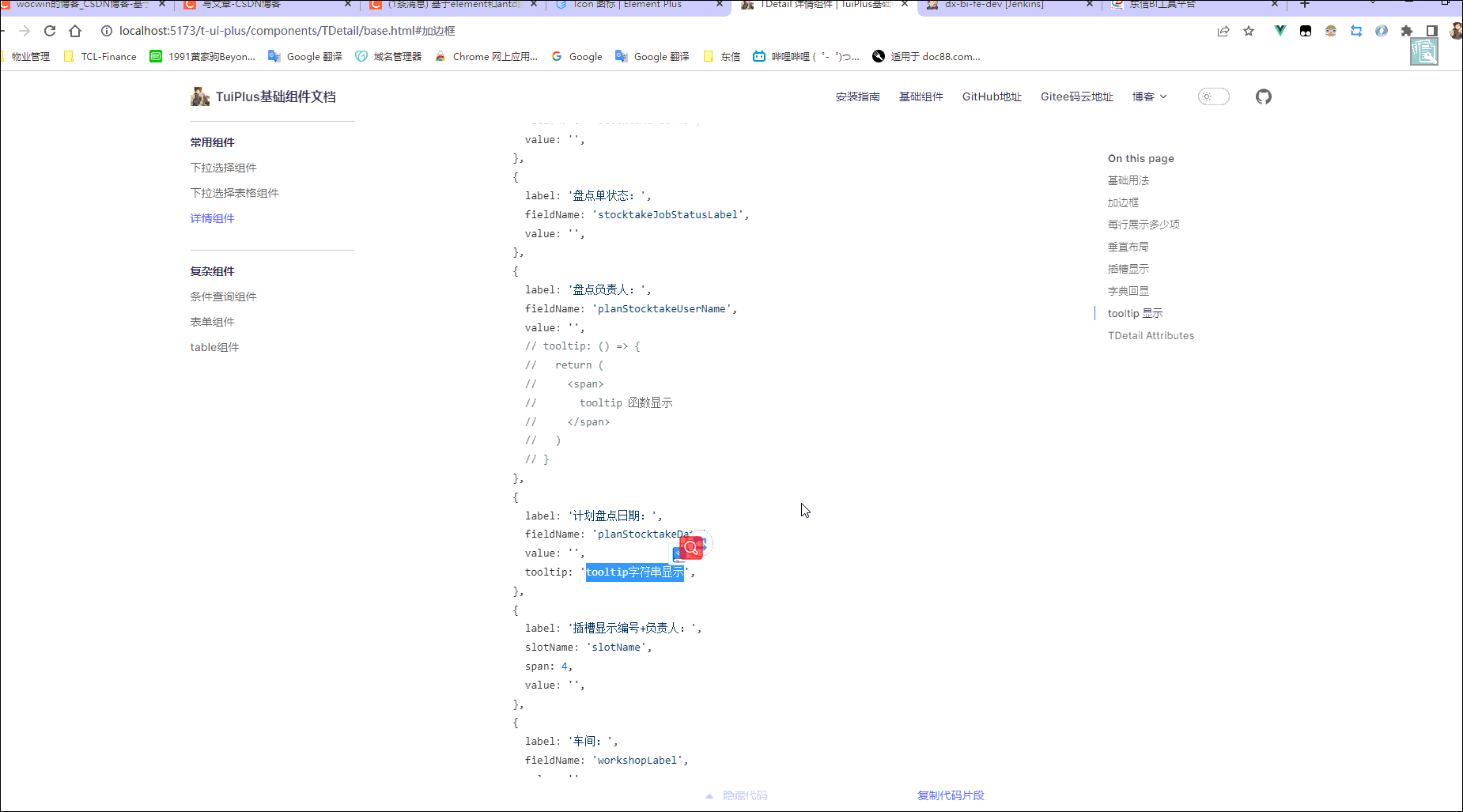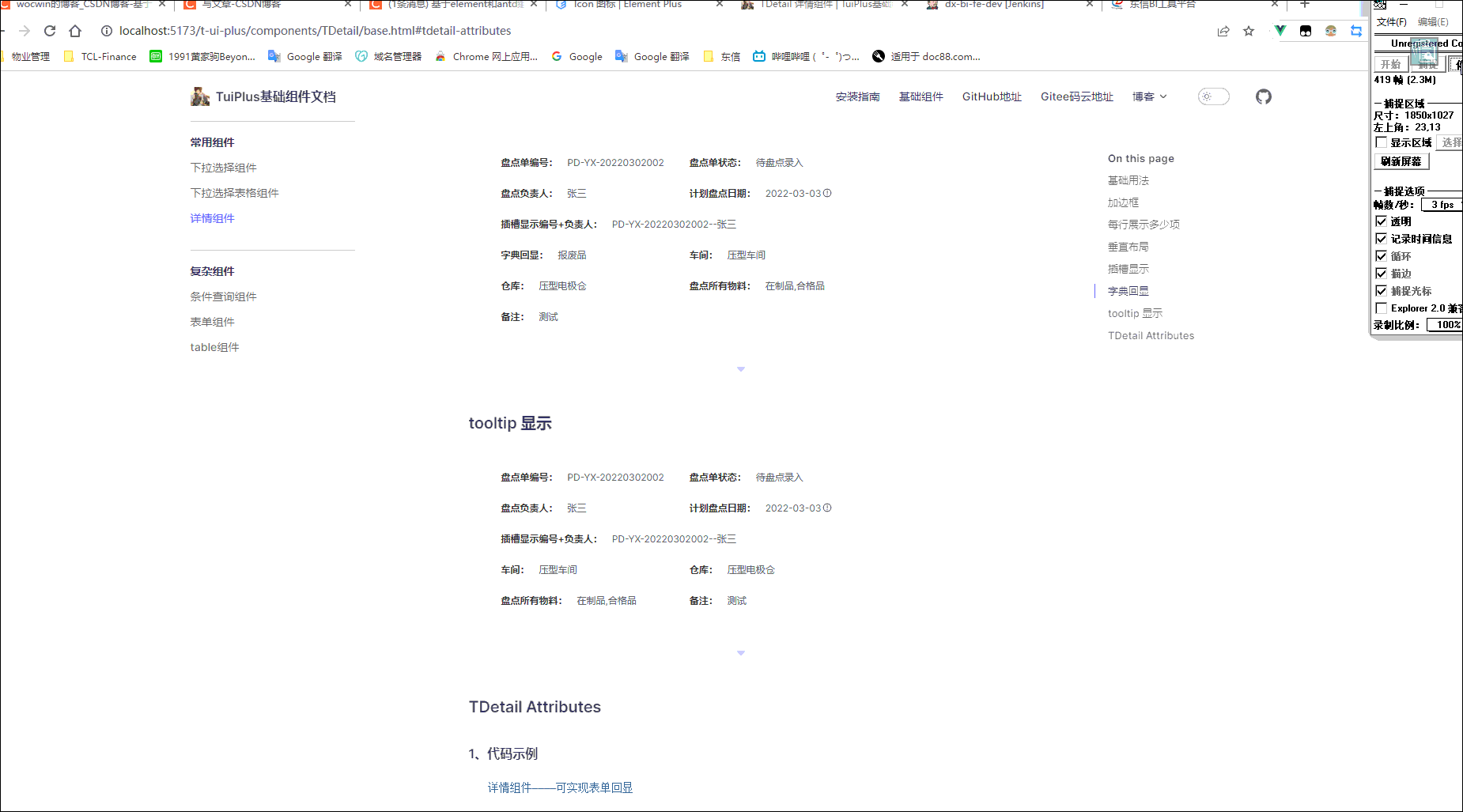
vue3+element-plus el-descriptions 详情组件二次封装(vue3项目)
最终效果 一、需求 一般后台管理系统,通常页面都有增删改查;而查不外乎就是渲染新增/修改的数据(由输入框变成输入框禁用),因为输入框禁用后颜色透明度会降低,显的颜色偏暗;为解决这个需求于是封…...

No.14新一代信息技术
新一代信息技术产业包括:加快建设宽带、泛在、融合、安全的信息忘了基础设施,推动新一代移动通信、下一代互联网核心设备和智能终端的研发及产业化,加快推进三网融合,促进物联网、云计算的研发和示范应用。 大数据、云计算、互联…...
微信小程序开发(五)小程序代码组成2
微信小程序开发(五)小程序代码组成2 为了进一步加深我们对小程序基础知识的了解和掌握,需要更进一步的了解小程序的代码组成以及一些简单的代码的编写。 参考小程序官方的的代码组成文档:https://developers.weixin.qq.com/ebook?…...
关于tensorboard --logdir=logs的报错解决办法记录
我在运行tensorboard --logdirlogs时,产生了如下的报错,找遍全网后,解决办法如下 先卸载 pip uninstall tensorboard再安装 pip install tensorboard最后出现如下报错 Traceback (most recent call last): File “d:\newanaconda\envs\imo…...

em,rem,px,rpx,vw,vh的区别与使用
在css中单位长度用的最多的是px、em、rem,这三个的区别是:一、px是固定的像素,一旦设置了就无法因为适应页面大小而改变。二、em和rem相对于px更具有灵活性,他们是相对长度单位,意思是长度不是定死了的,更适…...
Vue+node.js医院预约挂号信息管理系统vscode
网上预约挂号系统将会是今后医院发展的主要趋势。 前端技术:nodejsvueelementui,视图层其实质就是vue页面,通过编写vue页面从而展示在浏览器中,编写完成的vue页面要能够和控制器类进行交互,从而使得用户在点击网页进行操作时能够正…...

Java真的不难(五十四)RabbitMQ的入门及使用
RabbitMQ的入门及使用 一、什么是RabbitMQ? MQ全称为Message Queue,即消息队列。消息队列是在消息的传输过程中保存消息的容器。它是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...