NLP实践——知识图谱问答模型FiD
NLP实践——知识图谱问答模型FiD
- 0. 简介
- 1. 模型结构
- 2. 召回
- 3. 问答
- 4. 结合知识的问答
0. 简介
好久没有更新了,今天介绍一个知识图谱问答(KBQA)模型,在此之前我一直在用huggingface的Pipeline中提供的QA模型,非常方便但是准确性不是特别好。今天介绍的这个模型是Facebook在2021年就已经提出来的FiD(Fusion-in-Decoder),发表在ACL上。
论文地址: https://aclanthology.org/2021.eacl-main.74.pdf
项目地址:https://github.com/facebookresearch/FiD
其实我原本是想看EMNLP2022中的一篇文章,也已经开源。这个项目叫Grape,其基本思想实在FiD的基础上,采用两个T5 Encoder,并且在解码之前利用query和候选文本中的实体,构建GNN,在节点上做了Attention以增强Encoder的表征。
论文地址: https://arxiv.org/pdf/2210.02933.pdf
但是grape的这个项目我在实验的时候,遇到了一点环境配置上的问题,作者采用了一个比较冷门的dgl版本,这个版本在Linux_x86_64系统上没有官方编译过,于是我尝试自己编译,又遇到了一堆cmake和gcc版本的问题,于是放弃尝试。但顺着Grape的论文,找到了FiD这一项目。
1. 模型结构
所谓KBQA,也就是在问答模型的基础上,除了给定原文的信息之外,还考虑知识库中其他的预料信息。这个模型的原理很简单,就是一个生成模型,加上召回任务。
也就是先利用一个召回模型,在知识库中召回若干与给定的原文相关的文本,然后再将问题分别与原文以及相关文本进行拼接,拼接后的结果分别进行编码,再将编码的结果进行concat,最终把concat的结果给到Decoder,由Decoder生成答案。

采用的基础模型是T5,分别在两个数据集NaturalQuestions和TriviaQA上进行了训练,数据和训练好的模型均可在git上找到。
2. 召回
召回这部分其实没有什么东西,在官方的git中,就是采用bert-base做了一下编码,我没有跟着它的做法,感兴趣的同学可以自行阅读retrieval相关的py文件。
这里我是觉得自己编码更方便一些,可以直接采用Sentence transformer的预训练模型,或者你自己训练的什么编码模型,另外做成faiss或者milvus索引的话,效率还会高不少。关于Sentence transformer,在好久之前的这篇博客中也介绍过。
3. 问答
虽然这个模型是KBQA模型,但是git上似乎也没有直接给出Fusion的那部分代码。这里我们不妨自己先写一个预测方法,利用它训练好的模型来实现QA的功能。
由于它本身其实就是一个T5模型,所以只要你对transformers模块比较熟悉的话,可以很轻易的写出预测方法。
首先我们加载一下模型和tokenizer:
from transformers import AutoTokenizer
from src.model import FiDT5 # 注意引用时的目录,引不进来就直接把这个类复制过来# 从git上下载你想要尝试的模型,比如nq,把文件都放在一个目录里,然后用from_pretrained读取它
model = FiDT5.from_pretrained('your_path_to_Fid_model/nq_reader_base/')
tokenizer = AutoTokenizer.from_pretrained('t5-large') # 联网下载,或提前下载好放在本地目录# 然后eval一下,关掉dropout和BN,如果你比较叛逆,不关也是可以的
model.eval()
接下来我们写一个简单的预测方法,就可以实现QA了。
def predict(model, tokenizer, question, title, context, device='cpu'):"""预测:param model: T5模型:param tokenizer: 分词器:param question: 问题:param title: 标题,没有的话可以给空字符:param context: 正文:param device: 在cpu还是cuda上执行---------------ver: 2023-01-12by: changhongyu"""if device.startswith('cuda'):model.to(device)combined_text = "question: " + question + "title: " + title + "context: " + contextinputs = tokenizer(combined_text, max_length=1024, return_tensors='pt')test_outputs = model.generate(input_ids=inputs['input_ids'].unsqueeze(0).to(device),attention_mask=inputs['attention_mask'].unsqueeze(0).to(device),max_length=50,)answer = tokenizer.decode(test_outputs[0])return answer
来测试一下效果:
predict(model, tokenizer,"Who is Russia's new commander","Russia Ukraine War Live Updates: Russia changes commanders again in Ukraine","""09:20 (IST) Jan 12 Ukrainian military analyst Oleh Zhdanov said the situation in Soledar was "approaching that of critical" "The Ukrainian armed forces are holding their positions. About one half of the town is under our control. Fierce fighting is going on near the town centre," he said on YouTube.However, Zhdanov told Ukrainian television that if Russian forces seized Soledar or nearby Bakhmut it would be more a political victory than military. 09:18 (IST) Jan 12 Russian private military firm Wagner Group said its capture of the salt mining town Soledar in eastern Ukraine was complete- a claim denied by Ukraine 09:08 (IST) Jan 12 Russia changes commanders again in Ukraine Moscow named a new commander for its invasion of Ukraine. Russian Defence Minister Sergei Shoigu on Wednesday appointed Chief of the General Staff Valery Gerasimov as overall commander for what Moscow calls its "special military operation" in Ukraine, now in its 11th month.The change effectively demoted General Sergei Surovikin, who was appointed only in October to lead the invasion and oversaw heavy attacks on Ukraine's energy infrastructure. 06:40 (IST) Jan 12 Russia, Ukraine agree new prisoner swap in Turkey Russia and Ukraine on Wednesday agreed a new prisoner swap during rare talks in Turkey during which they also discussed the creation of a "humanitarian corridor" in the war zone. Ukraine's human rights ombudsman Dmytro Lubinets met his Russian counterpart Tatyana Moskalkova on the sidelines of an international conference in Ankara attended by Turkish President Recep Tayyip Erdogan. 06:39 (IST) Jan 12 President Volodymyr Zelenskyy urged NATO on Wednesday to do more than just promise Ukraine its door is open at a July summit, saying Kyiv needs "powerful steps" as it tries to join the military alliance. 06:39 (IST) Jan 12 Russian forces shelled 13 settlements in and around Kharkiv region largely returned to Ukrainian hands in September and October, the Ukrainian military said. 06:38 (IST) Jan 12 Russia's war on Ukraine latest: Russia puts top general in charge of invasion Russia ordered its top general on Wednesday to take charge of its faltering invasion of Ukraine in the biggest shake-up yet of its malfunctioning military command structure after months of battlefield setbacks. 06:37 (IST) Jan 12 Zelenskyy says Russian war won't become WWIII Ukraine will stop Russian aggression and the conflict won't turn into World War III, President Volodymyr Zelenskiy said as his forces battled to keep control of Soledar and Bakhmut in the eastern Donetsk region. The Kremlin had positioned the most experienced units from the Wagner military-contracting company near Soledar, according to Ukrainian operational command spokesman Serhiy Cherevatyi."""
)
模型给出的回答符合预期:
Valery Gerasimov
4. 结合知识的问答
官方的代码中好像没有给出这部分内容,所以我根据论文的思路简单实现了一下,简而言之就是在召回之后,将目标文档的编码结果与召回的参考文档的编码结果进行拼接,然后再统一进行解码即可。
def predict_with_reference(model, tokenizer, question, title, context, reference_title, reference_context, device='cpu'):"""预测:param model: T5模型:param tokenizer: 分词器:param question: 问题:param title: 标题,没有的话可以给空字符:param context: 正文:param reference_title: 召回文本的标题:param reference_context: 召回文本的正文:param device: 在cpu还是cuda上执行---------------ver: 2023-01-12by: changhongyu"""if device.startswith('cuda'):model.to(device)combined_text = "question: " + question + "title: " + title + "context: " + contextcombined_refer = "question: " + question + "title: " + reference_title + "context: " + reference_contextquery_inputs = tokenizer(combined_text, max_length=1024, return_tensors='pt')refer_inputs = tokenizer(combined_refer, max_length=1024, return_tensors='pt')test_outputs = model.generate(input_ids=torch.cat([query_inputs['input_ids'].unsqueeze(0), refer_inputs['input_ids'].unsqueeze(0)], dim=2).to(device),attention_mask=torch.cat([query_inputs['attention_mask'].unsqueeze(0), refer_inputs['attention_mask'].unsqueeze(0)], dim=2).to(device),max_length=50,)answer = tokenizer.decode(test_outputs[0])return answer
然后来测试一下效果:
假设我们有一篇地震相关的新闻:
text = """The death toll in Syria and Turkey from the earthquake has passed 12,000, with the number of injured exceeding 100,000, while hundreds of thousands have been displaced. In Turkey, at least 9,000 have been killed and nearly 60,000 people have been injured, authorities said on Wednesday. The death toll in Syria stands at more than 3,000, according to the Syrian Observatory for Human Rights, while Syrian state media reported more than 298,000 people have been displaced."""
以及在知识库里召回的一篇叙相关的介绍:
reference = """Syria (Arabic: سوريا, romanized: Sūriyā), officially the Syrian Arab Republic (Arabic: الجمهورية العربية السورية, romanized: al-Jumhūrīyah al-ʻArabīyah as-Sūrīyah), is a country in Western Asia, bordering Lebanon to the southwest, the Mediterranean Sea to the west, Turkey to the north, Iraq to the east, Jordan to the south, and Israel to the southwest. A country of fertile plains, high mountains, and deserts, Syria is home to diverse ethnic and religious groups, including Syrian Arabs, Kurds, Turkemens, Assyrians, Armenians, Circassians, Mandeans and Greeks. Religious groups include Sunnis, Christians, Alawites, Druze, Isma'ilis, Mandeans, Shiites, Salafis, Yazidis, and Jews. Arabs are the largest ethnic group, and Sunnis the largest religious group."""
然后进行问答:
predict_with_reference(model, tokenizer,question="where is Syria.",title="Earthquake death toll exceeds 12,000 as Turkey, Syria seek help.",context=text,reference_title="Syria",reference_context=reference,
)
模型给出的回答是:
'Western Asia'
答案也是符合预期的。
如果是召回多篇文档,理论上将predict_with_reference这个方法的reference都改成list,然后再拼接的时候把结果组合起来就可以了,感兴趣的同学可以自己尝试一下。
以上就是本文的全部内容了,在ChatGPT时代下,KBQA这个话题似乎有点“过时”了,但是这对于练习NLP基础任务和理解attention的运作还是很有帮助的。如果这篇文章对你有帮助,欢迎一键三连加关注,也欢迎评论区或私信交流,我们下期再见。
相关文章:
NLP实践——知识图谱问答模型FiD
NLP实践——知识图谱问答模型FiD0. 简介1. 模型结构2. 召回3. 问答4. 结合知识的问答0. 简介 好久没有更新了,今天介绍一个知识图谱问答(KBQA)模型,在此之前我一直在用huggingface的Pipeline中提供的QA模型,非常方便但…...

MyBatis 多表关联查询
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

《NFL橄榄球》:克利夫兰布朗·橄榄1号位
克利夫兰布朗(英语:Cleveland Browns)是一支职业美式橄榄球球队,位于俄亥俄州克利夫兰。 布朗隶属于美国全国橄榄球联盟(NFL)的北区,主场位于第一能源体育场。球队在1946年与AAFC联盟一同成立,并在1946年到…...
InstructGPT笔记
一、InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调 二、该论文展示了怎么样对语言模型和人类意图之间进行匹配,方法是在人类的反馈上进行微调。 **三、方法简介:**收集很多问题,使用标注工具将问题的答案写出来࿰…...

【uniapp】getOpenerEventChannel().once 接收参数无效的解决方案
uniapp项目开发跨平台应用常会遇到接收参数无效的问题,无法判断是哪里出错了,这里是讲替代的方案,现有三种方案可选。 原因 一般我们是这样处理向另一个页面传参,代码是这样写的 //... let { title, type, rank } args; uni.n…...
ELK分布式日志收集快速入门-(二)kafka进阶-快速安装可视化管理界面-(单节点部署)
目录安装前准备安装中安装成功安装前准备 安装kafka-参考博客 (10条消息) ELK分布式日志收集快速入门-(一)-kafka单体篇_康世行的博客-CSDN博客 安装zk 参考博客 (10条消息) 快速搭建-分布式远程调用框架搭建-dubbozookperspringboot demo 演示_康世行的…...

线程的创建
1. 多线程常用函数 1.1 创建一条新线程pthread_create 对此函数使用注意以下几点: 线程例程指的是:如果线程创建成功,则该线程会立即执行的函数。POSIX线程库的所有API对返回值的处理原则一致:成功返回0,失败返回错误…...

分布式之Paxos共识算法分析
写在前面 分布式共识是分布式系统中的重要内容,本文来一起看下,一种历史悠久(1998由兰伯特提出,并助其获得2003年图灵奖)的实现分布式共识的算法Paxos。Paxos主要分为两部分,Basic Paxos和Multi-Paxos,其中…...

35岁测试工程师,面临中年危机,我该如何自救...
被辞的原因 最近因故来了上海,联系上了一位许久不见的老朋友,老王;老王和我是大学同学,毕业之后他去了上海,我来到广州。因为我们大学专业关系,从12年毕业以后我们从事着相同的职业,软件自动化…...
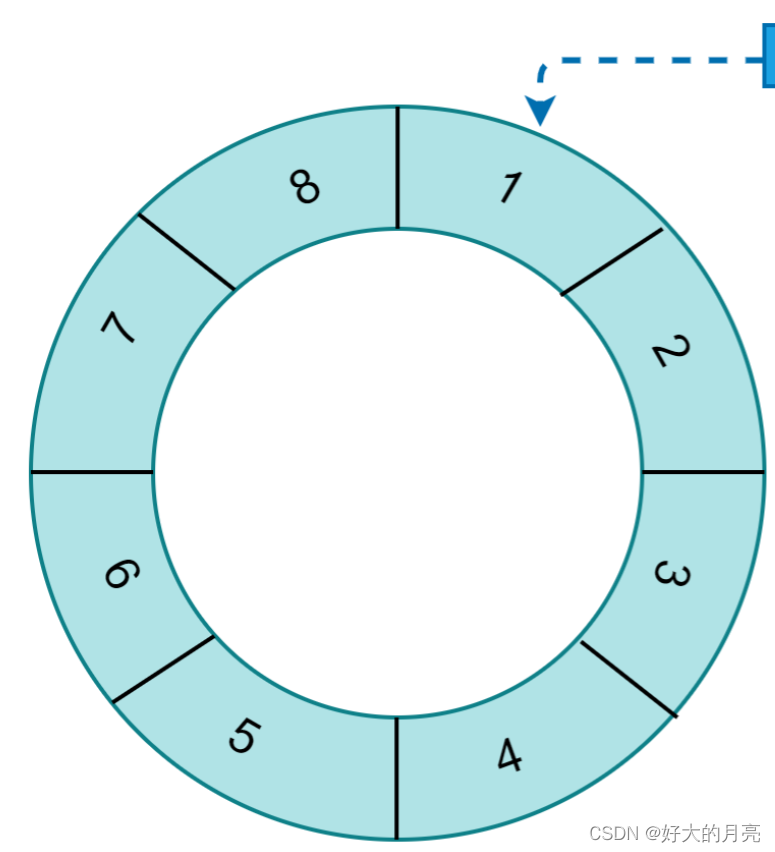
时间轮算法概念
概述 在一些中间件中我们经常见到时间轮控制并发和熔断。 那么这个时间轮具体是什么呢,又是怎么使用的呢。 简介 其实时间轮可以简单的理解成我们日常生活中的时钟。 时钟里的指针一直在不停的转动,利用这个我们可以实现定时任务,目前lin…...
[SCTF2019]babyre 题解
对未来的真正慷慨,是把一切献给现在。 ——加缪 目录 1.查壳 2.处理花指令,找到main函数 这一操作过程可以参考下面的视频: 3.静态分析第一部分,psword1 4.静态分析第二部分,psword2 5.静态分析第五部分,psword3 6.根据ps…...

全志H3系统移植 | 移植主线最新uboot 2023.04和kernel 6.1.11到Nanopi NEO开发板
文章目录 环境说明uboot移植kernel移植rootfs移植测试环境说明 OS:Ubuntu 20.04.5 LTSGCC:arm-none-linux-gnueabihf-gcc 10.3.0编译器下载地址:Downloads | GNU-A Downloads – Arm Developer uboot移植 当前最新版本v2023.04-rc2下载地址:https://github.com/u-boot/u-…...

vue项目第四天
使用elementui tabplane组件实现历史访问记录组件的二次封装<el-tabs type"border-card"><el-tab-pane label"用户管理">用户管理</el-tab-pane><el-tab-pane label"配置管理">配置管理</el-tab-pane><el-tab-…...
「C语言进阶」数据内存的存储
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 🐰数据类型的介绍 🐰类型的意义 🐰数据类型的基本归类…...

面试必问:进程和线程的区别(从操作系统层次理解)
1.什么是进程?为什么要有进程? 进程有一个相当精简的解释:进程是对操作系统上正在运行程序的一个抽象。 这个概念确实挺抽象,仔细想想却也挺精准。 我们平常使用计算机,都会在同一时间做许多事,比如边看…...

ModuleNotFoundError: No module named ‘apex‘与 error: legacy-install-failure
ModuleNotFoundError: No module named ‘apex’ ModuleNotFoundError: No module named apex 表示 Python 在搜索模块时无法找到名为 apex 的模块。这通常是因为您没有安装 apex 模块或安装不正确。 apex 是一个针对混合精度训练和优化的 PyTorch 扩展库,您可以通过…...
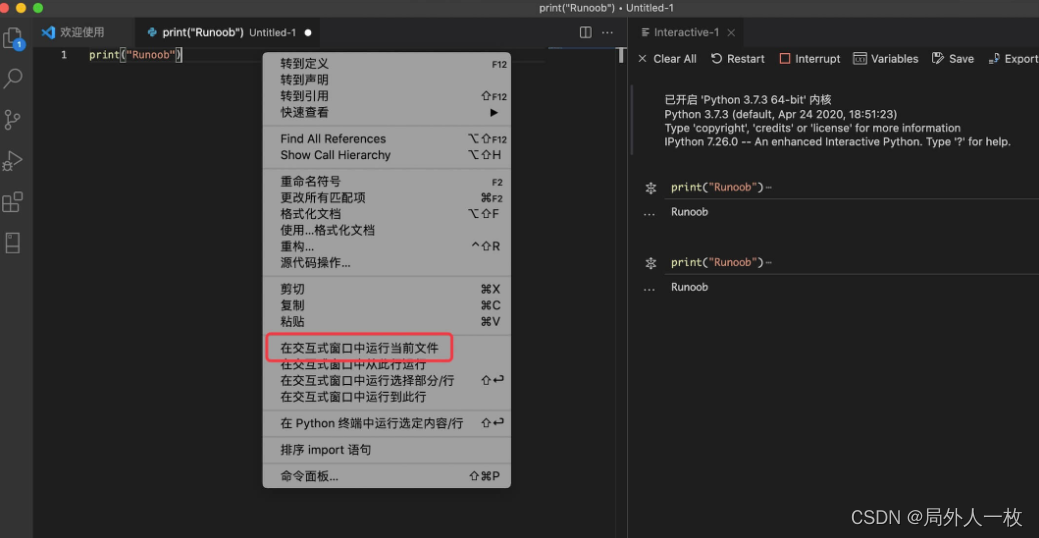
Python3 VScode 配置
Python3 VScode 配置 在上一章节中我们已经安装了 Python 的环境,本章节我们将介绍 Python VScode 的配置。 准备工作: 安装 VS Code 安装 VS Code Python 扩展 安装 Python 3 安装 VS Code VSCode(全称:Visual Studio Code&…...

VMware 修复了三个身份认证绕过漏洞
Bleeping Computer 网站披露,VMware 近期发布了安全更新,以解决 Workspace ONE Assist 解决方案中的三个严重漏洞,分别追踪为 CVE-2022-31685(认证绕过)、CVE-2022-31686 (认证方法失败)和 CVE-…...

实现一个简单的Database10(译文)
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。作者: 花家舍文章来源:GreatSQL社区原创 前文回顾 实现一个简单的Database系列 译注:csta…...
CTF-取证题目解析-提供环境
一、安装 官网下载:Volatility 2.6 Release 1、将windows下载的volatility上传到 kali/home 文件夹里面 3、将home/kali/vol刚刚上传的 移动到use/sbin目录里面 mv volatility usr/local/sbin/ 切换到里面 cd /usr/local/sbin/volatility 输入配置环境echo $PAT…...

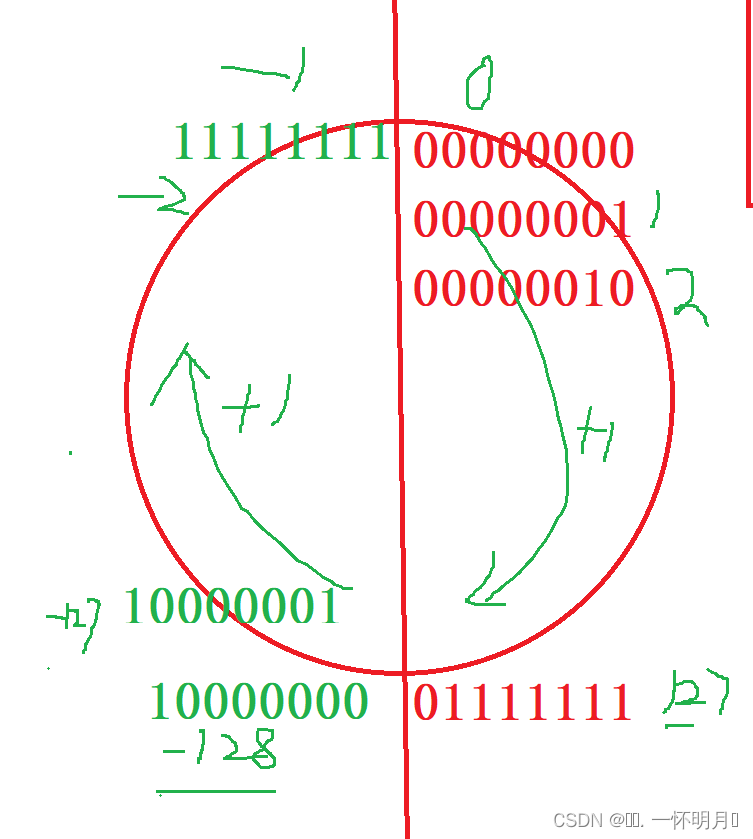
国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...