Hadoop高可用搭建(二)
目录
解压Hadoop
改名
更改配置文件
workers
hdfs-site.xml
core-site.xml
hadoop-env.sh
mapred-site.xml
yarn-site.xml
设置环境变量
启动集群
启动zk集群
启动journalnode服务
格式化hfds namenode
启动namenode
同步namenode信息
查看namenode节点状态
查看启动情况
关闭所有dfs有关的服务
格式化zk
启动dfs
启动yarn
查看resourcemanager节点状态
测试集群wordcount
创建一个TXT文件
上传到hdfs上面
查看输出结果
解压Hadoop
[root@ant51 install]# tar -zxvf ./hadoop-3.1.3.tar.gz -C ../soft/
改名
[root@ant151 install]# cd /opt/soft
[root@ant151 soft]# mv hadoop-3.1.3/ hadoop313
更改配置文件
workers
[root@ant151 ~] # cd /opt/soft/hadoop313/etc/hadoop
[root@ant151 hadoop] # vim workers
把所有的虚拟机加上去

hdfs-site.xml
[root@ant151 hadoop] # vim hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value><description>hadoop中每一个block文件的备份数量</description></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value><description>namenode上存储hdfs名字空间元数据的目录</description></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value><description>datanode上数据块的物理存储位置目录</description></property><property><name>dfs.namenode.secondary.http-address</name><value>ant151:9869</value><description></description></property><property><name>dfs.nameservices</name><value>gky</value><description>指定hdfs的nameservice,需要和core-site.xml中的保持一致</description></property><property><name>dfs.ha.namenodes.gky</name><value>nn1,nn2</value><description>gky为集群的逻辑名称,映射两个namenode逻辑名</description></property><property><name>dfs.namenode.rpc-address.gky.nn1</name><value>ant151:9000</value><description>namenode1的rpc通信地址</description></property>
<property><name>dfs.namenode.http-address.gky.nn1</name><value>ant151:9870</value><description>namenode1的http通信地址</description></property><property><name>dfs.namenode.rpc-address.gky.nn2</name><value>ant152:9000</value><description>namenode2的rpc通信地址</description></property>
<property><name>dfs.namenode.http-address.gky.nn2</name><value>ant152:9870</value><description>namenode2的http通信地址</description></property>
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://ant151:8485;ant152:8485;ant153:8485/gky</value><description>指定namenode的edits元数据的共享存储位置(JournalNode列表)</description></property>
<property><name>dfs.journalnode.edits.dir</name><value>/opt/soft/hadoop313/data/journaldata</value><description>指定JournalNode在本地磁盘存放数据的位置</description></property>
<!-- 容错 -->
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>开启NameNode故障自动切换</description></property>
<property><name>dfs.client.failover.proxy.provider.gky</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value><description>如果失败后自动切换的实现的方式</description></property>
<property><name>dfs.ha.fencing.methods</name><value>sshfence</value><description>防止脑裂的处理</description></property>
<property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value><description>使用sshfence隔离机制时,需要用ssh免密登陆</description></property><property><name>dfs.permissions.enabled</name><value>false</value><description>关闭hdfs操作的权限验证</description></property><property><name>dfs.image.transfer.bandwidthPerSec</name><value>1048576</value><description></description></property><property><name>dfs.block.scanner.volume.bytes.per.second</name><value>1048576</value><description></description></property></configuration>core-site.xml
[root@ant151 hadoop] # vim core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://gky</value><description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservice值保持一致</description></property><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/tmpdata</value><description>namenode上本地的hadoop临时文件夹</description></property><property><name>hadoop.http.staticuser.user</name><value>root</value><description>默认用户</description></property><property><name>io.file.buffer.size</name><value>131072</value><description>读写队列缓存:128k;读写文件的buffer大小</description></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value><description>代理用户</description></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value><description>代理用户组</description></property><property><name>ha.zookeeper.quorum</name><value>ant151:2181,ant152:2181,ant153:2181</value><description>高可用用户连接</description></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value><description>hadoop连接zookeeper会话的超时时长为10s</description></property>
</configuration>
hadoop-env.sh
[root@ant151 hadoop] # vim hadoop-env.sh
大概54行左右JAVA_HOME
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
mapred-site.xml
[root@ant151 hadoop] # vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>job执行框架:local,classic or yarn</description><final>true</final></property><property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value></property><property><name>mapreduce.jobhistory.address</name><value>ant151:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>ant151:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>1024</value><description>map阶段task工作内存</description></property><property><name>mapreduce.reduce.memory.mb</name><value>1024</value><description>reduce阶段task工作内存</description></property></configuration>
yarn-site.xml
[root@ant151 hadoop] # vim yarn-site.xml
<configuration><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><description>开启resourcemanager高可用</description></property><property><name>yarn.resourcemanager.cluster-id</name><value>yrcabc</value><description>指定yarn集群中的id</description></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1</value><description>指定resourcemanager的名字</description></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>ant153</value><description>设置rm1的名字</description></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>ant153:8088</value><description></description></property> <property><name>yarn.resourcemanager.zk-address</name><value>ant151:2181,ant152:2181,ant153:2181</value><description>指定zk集群地址</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>运行mapreduce程序必须配置的附属服务</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/local</value><description>nodemanager本地存储目录</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/log</value><description>nodemanager本地日志目录</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>1024</value><description>resource进程的工作内存</description></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value><description>resource工作中所能使用机器的内核数</description></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>256</value><description></description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description></description></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value><description>日志保留多少秒</description></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description></description></property><property><name>yarn.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value><description></description></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value><description></description></property>
</configuration>
设置环境变量
[root@ant151 hadoop] # vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib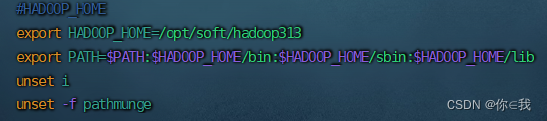
配置完成之后把hadoop313和配置文件拷贝到其余机器上面
hadoop
[root@ant151 shell]# scp -r ./hadoop313/ root@ant152:/opt/soft/
[root@ant151 shell]# scp -r ./hadoop313/ root@ant153:/opt/soft/环境变量
[root@ant151 shell]# scp /etc/profile root@ant152:/etc
[root@ant151 shell]# scp /etc/profile root@ant153:/etc
所有机器刷新资源[root@ant151 shell]# source /etc/profile
启动集群
启动zk集群
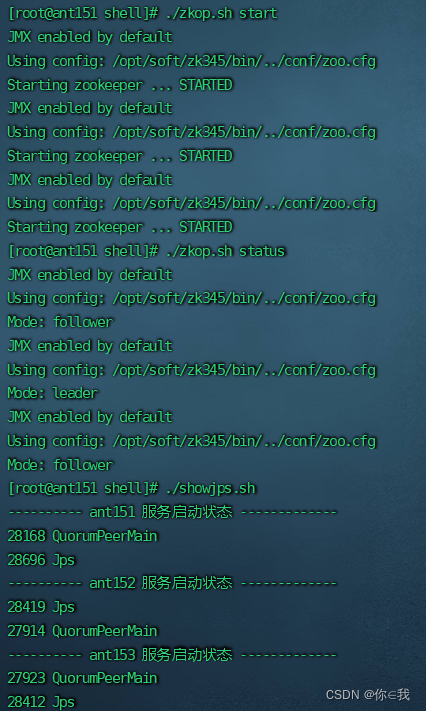
[root@ant151 shell]# ./zkop.sh start
[root@ant151 shell]# ./zkop.sh status
[root@ant151 shell]# ./showjps.sh
启动journalnode服务
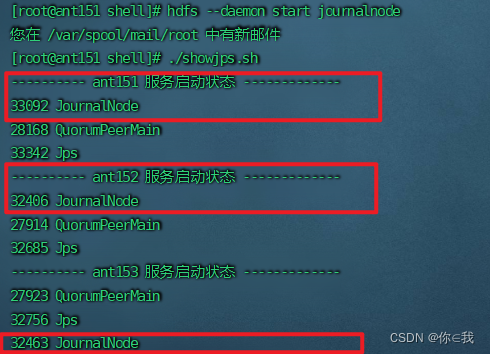
启动ant151,ant152,ant153的journalnode服务
[root@ant151 soft]# hdfs --daemon start journalnode
格式化hfds namenode
在ant151上面操作
[root@ant151 soft]# hdfs namenode -format
启动namenode
在ant151上面操作
[root@ant151 soft]# hdfs --daemon start namenode
同步namenode信息
在ant152上操作
[root@ant152 soft]# hdfs namenode -bootstrapStandby
启动namenode
[root@ant152 soft]# hdfs --daemon start namenode
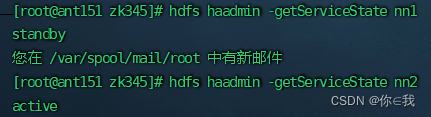
查看namenode节点状态
[root@ant151 zk345]# hdfs haadmin -getServiceState nn1
[root@ant151 zk345]# hdfs haadmin -getServiceState nn2
查看启动情况
[root@ant152 shell]# ./showjps.sh

关闭所有dfs有关的服务
[root@ant151 soft]# stop-dfs.sh
格式化zk
[root@ant151 soft]# hdfs zkfc -formatZK
启动dfs
[root@ant151 soft]# start-dfs.sh

启动yarn
[root@ant151 soft]# start-yarn.sh
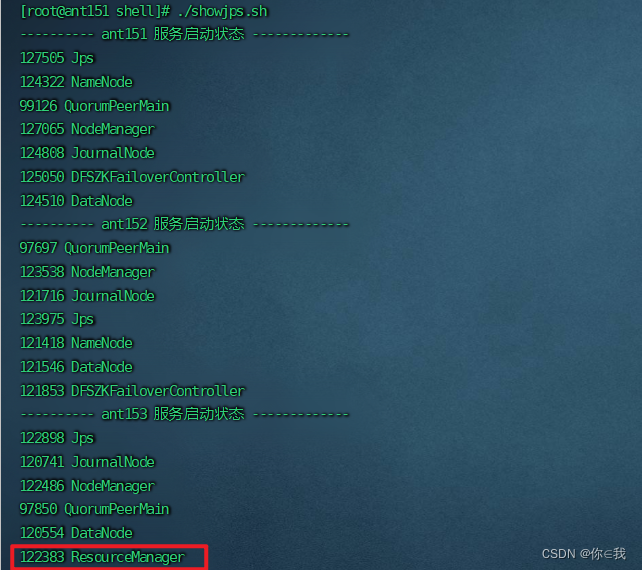
查看resourcemanager节点状态
[root@ant151 zk345]# yarn rmadmin -getServiceState rm1

测试集群wordcount
创建一个TXT文件
[root@ant151 soft]# vim ./aa.txt
上传到hdfs上面
[root@ant151 soft]# hdfs dfs -put ./aa.txt /
查看
[root@ant151 soft]# hdfs dfs -ls /

mapreduce里面的jar包运行wordcount
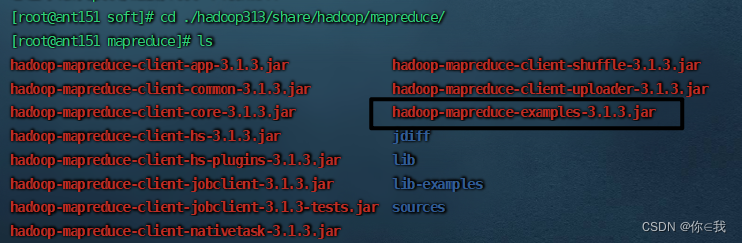
运行
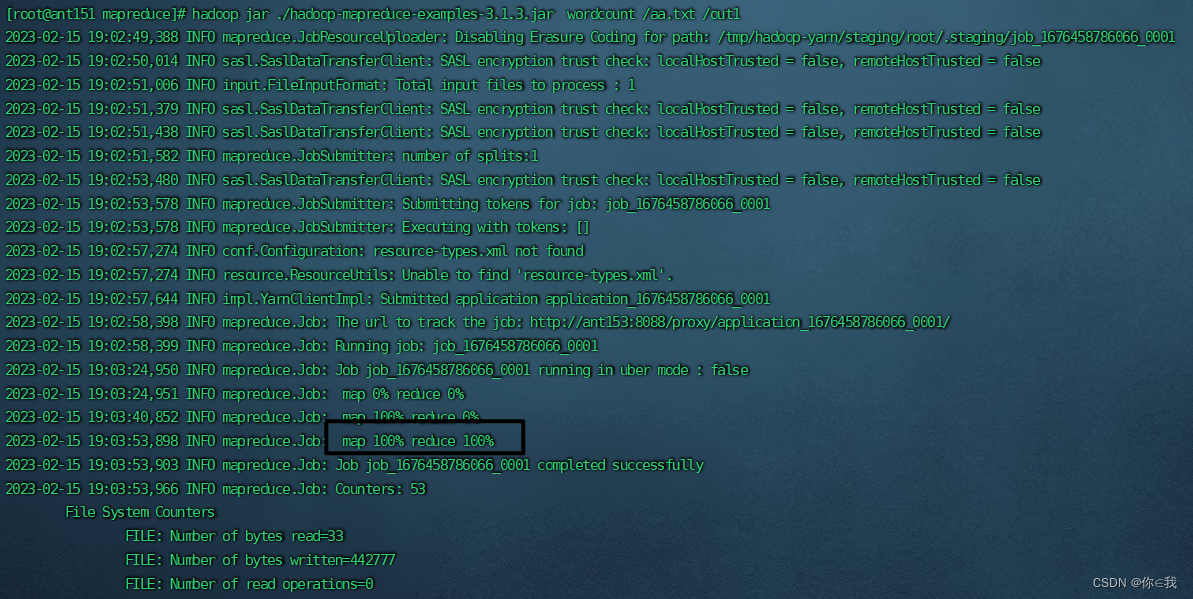
[root@ant151 mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /aa.txt /out1
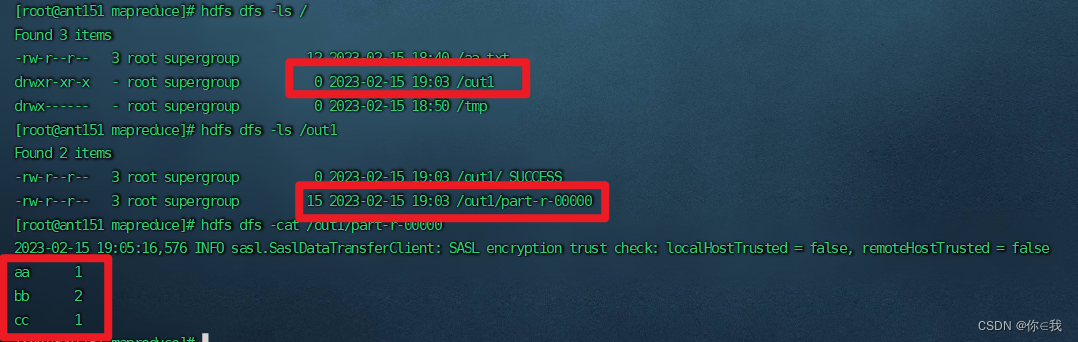
查看输出结果
[root@ant151 mapreduce]# hdfs dfs -ls /
[root@ant151 mapreduce]# hdfs dfs -ls /out1
[root@ant151 mapreduce]# hdfs dfs -cat /out1/part-r-00000出现
aa 1
bb 2
cc 3
则成功
相关文章:
Hadoop高可用搭建(二)
目录 解压Hadoop 改名 更改配置文件 workers hdfs-site.xml core-site.xml hadoop-env.sh mapred-site.xml yarn-site.xml 设置环境变量 启动集群 启动zk集群 启动journalnode服务 格式化hfds namenode 启动namenode 同步namenode信息 查看namenode节点状态 …...

如何用企微SCRM管理系统发掘老客户的新增长点?
如何用企微SCRM管理系统发掘老客户的新增长点? 一直做投放拉新,很快营销成本会难以支撑,如果在私域运营中始终留不下老用户,那么运营也是失败的。 开发老客户的成本只需新客户成本的1/6,但很多企业对老客户都忽视了&…...

我用python疯狂爬取公司数据
我是半路从一个纯小白学过来的,学习途中也掉过许多坑,在这里建议新手要先把基础打扎实,然后再去学习自己需要的内容,不要想着全部学完再用,那样你是永远学不完的,用哪方面就学习哪方面的内容,不…...

EMR集群运行TPC-DS在云盘和OSS中的对比
1.简介 TPC-DS是大数据领域最为知名的Benchmark标准。本文介绍使用阿里云EMR集群运行TPC-DS在云盘和OSS中的表现对比。 2.环境准备 1.创建EEMR-5.10.1集群 1个master,2个core,3台机器都s是4c16g。 2.安装Git和Maven sudo yum install -y git maven3.下载TPC-DS Benchmark工…...
菜鸟在 windows 下 python 中安装 jupyter 踩坑要点 、被神化的 VsCode
我平时用不到 python ,更没用过 jupyter ,因此我的 python知识仅限于知道有 python 这么个编程语言,会写个 print("Hello World!!!") 而已,完全没听过 jupyter ,因为某些原因今天需要安装下 jupyter 看看&am…...

k8s简单搭建
前言 最近学习k8s,跟着网上各种教程搭建了简单的版本,一个master节点,两个node节点,这里记录下防止以后忘记。 具体步骤 准备环境 用Oracle VM VirtualBox虚拟机软件安装3台虚拟机,一台master节点,两台…...

计算机SCI期刊审稿人,一般关注论文的那些问题? - 易智编译EaseEditing
编辑主要关心: (1)文章内容是否具有足够的创新性? (2)文章主题是否符合期刊的受众读者? (3)文章方法学是否合理,数据处理是否充分? (…...

Docker迁移以及环境变量问题
问题一描述将docker容器通过docker export命令打包,传输到另外的服务器,再通过docker import命令导入后,发现原来docker容器中的环境变量失效了。解决方案1. 【无效方案】直接在docker容器中通过export命令设置环境变量。export LD_LIBRARY_P…...
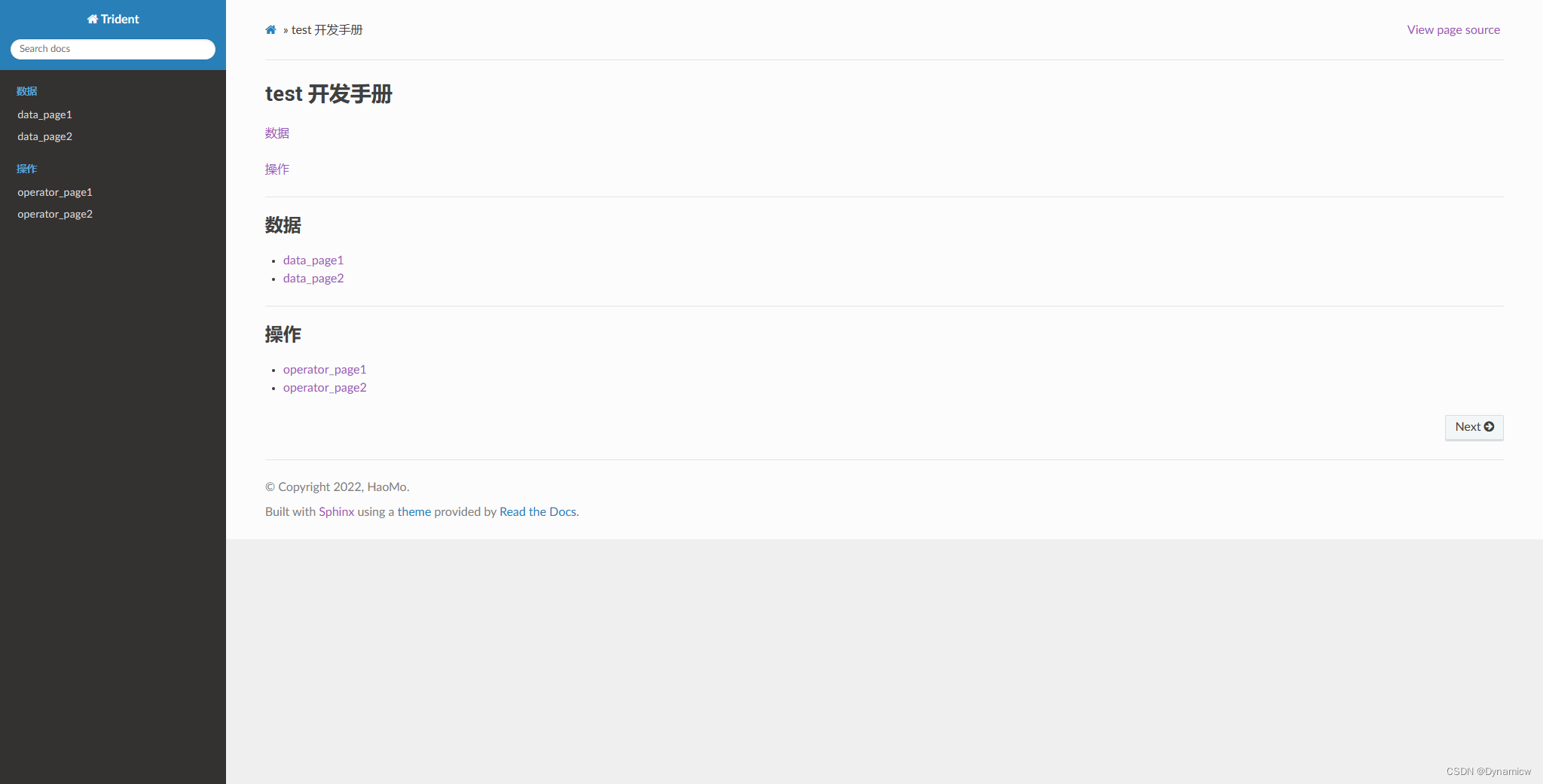
Sphinx文档生成工具(二)
rst语法 官方的语法手册 行内的样式: #斜体 *message* #粗体 **message** #等宽 不能有换行 message标题 一级标题 ^^^^^^^^ 二级标题 --------- 三级标题 >>>>>>>>> 四级标题 ::::::::: 五级标题六级标题 """"…...

Python快速上手系列--JSON--入门篇
本章我们来看看json的一些应用。简单易懂还实用。一起来看看数据类型以及一些语法规则吧1、数字(整数或浮点数) 如:{"age":18, "score":70.5} 注意,数字直接写,不需要带任何符号2、字符串…...
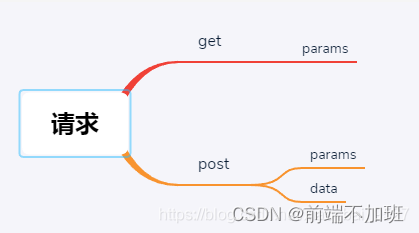
axios中的GET POST PUT PATCH,发送请求时params和data的区别
axios 中 get/post请求方式 1. 前言 最近突然发现post请求可以使用params方式传值,然后想总结一下其中的用法。 2.1 分类 经过查阅资料,get请求是可以通过body传输数据的,但是许多工具类并不支持此功能。 在postman中,选择get请…...

hume项目k8s的改造
hume项目k8s的改造 一、修改构建目录结构 1、在根目录下添加build-work文件夹 目录结构如下 [rootk8s-worker-01 build-work]# tree . . ├── Dockerfile ├── hume │ └── start.sh └── Jenkinsfile2、每个文件内容如下 Dockerfile FROM ccr.ccs.tencentyun…...
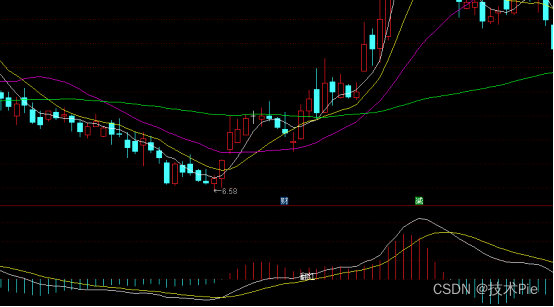
MACD红二波选股公式,选出MACD二次翻红的标的
经过一段上涨行情之后,市场出现了时间稍长或者幅度稍大的调整,MACD指标的DIF、DEA会出现死叉,柱线由红色转变为绿色。 而调整时间较短或者幅度较小,MACD红柱会缩短,但不出现绿柱,之后红柱开始变长ÿ…...
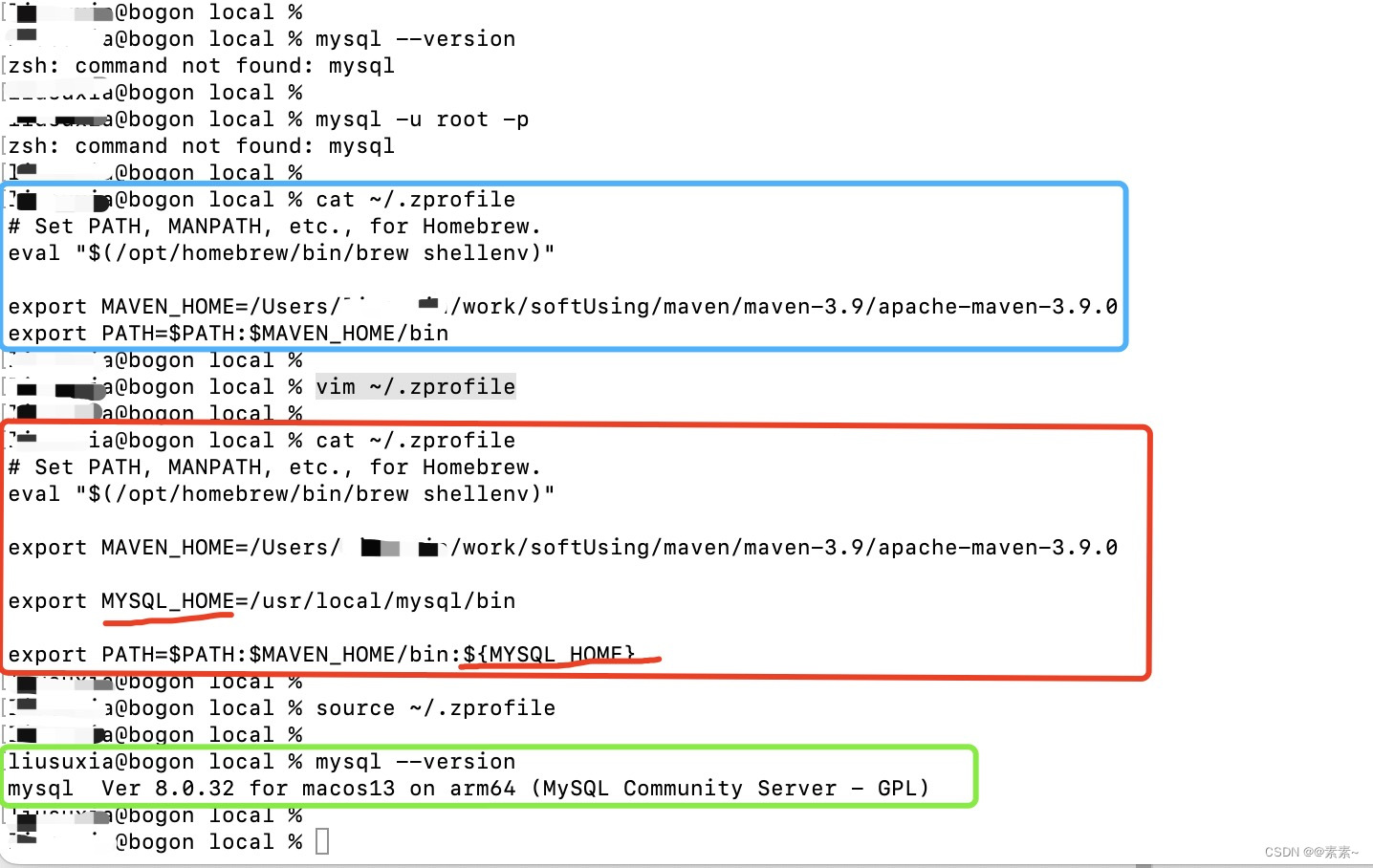
mac上安装mysql
mac上安装mysql1. 关于Linux上安装mysql2. 下载安装2.1 下载2.2 安装3. 客户端连接mysql3.1 先查看mysql服务3.2 连接mysql客户端3.2.1 终端使用命令连接3.2.2 可视化工具连接3.3 其他简单操作(启动服务等)3.3.1 可视化界面操作4. 配置环境变量4.1 配置环…...

Django 模型继承问题
文章目录Django 模型继承问题继承出现的情况Meta 和多表继承Meta 和多表继承继承与反向关系指定父类连接字段代理模型QuerySet 仍会返回请求的模型基类约束代理模型管理器代理继承和未托管的模型间的区别多重继承不能用字段名 "hiding"在一个包中管理模型Django 模型…...
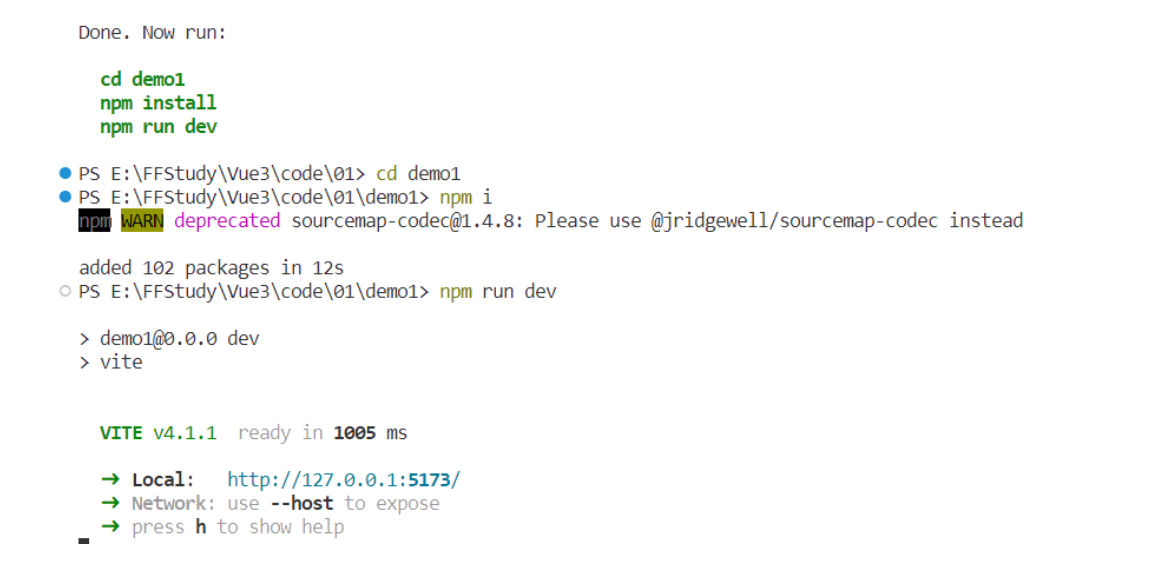
Vue3篇.01-简介及基本使用,项目创建方式, 模板语法, 事件监听, 修饰符
一.简介1.概念Vue 是一款用于构建用户界面的 JS框架, 基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型, 高效地开发用户界面。渐进式框架, 适应不同需求进行开发。两个核心功能:声明式…...

别学英语了,真的
文 / 王不留(微信公众号:王不留) 这两年,很多朋友加我微信后,第一句常是,学英语有什么用啊? 我会统一给出真诚答复:没用,真的。 看新闻,中文海量信息已经严重…...

CRM系统五大技巧集成Excel为销售流程赋能
销售过程中有很多情况会降低团队的效率。通过正确的实施CRM客户管理系统,可以帮助您的企业自动执行手动任务、减少错误并专注于完成交易。这里有5个技巧,可以帮助您的销售人员通过CRM集成Excel为销售流程赋能并提高他们的整体效率。 技巧1:将…...
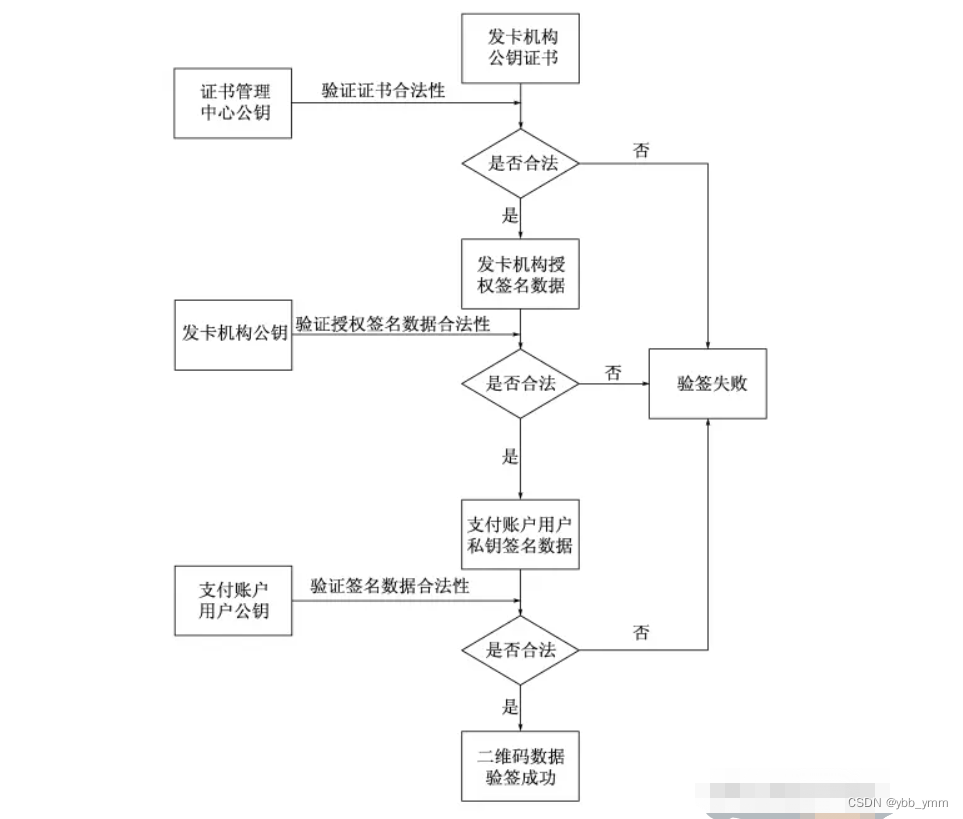
交通部互通互联码的根证书规则
引言 为了更好的服务交通互通互联码而更新这篇文章。 中金根证书其实是可以自己生成的。 代码内调整 中心公钥索引要保证自己的唯一性。 此处的唯一,是要保证在机具侧的唯一,因为他要根据这个索引去查找证书以及公钥。 提供根公钥给机具侧 生成的公钥…...
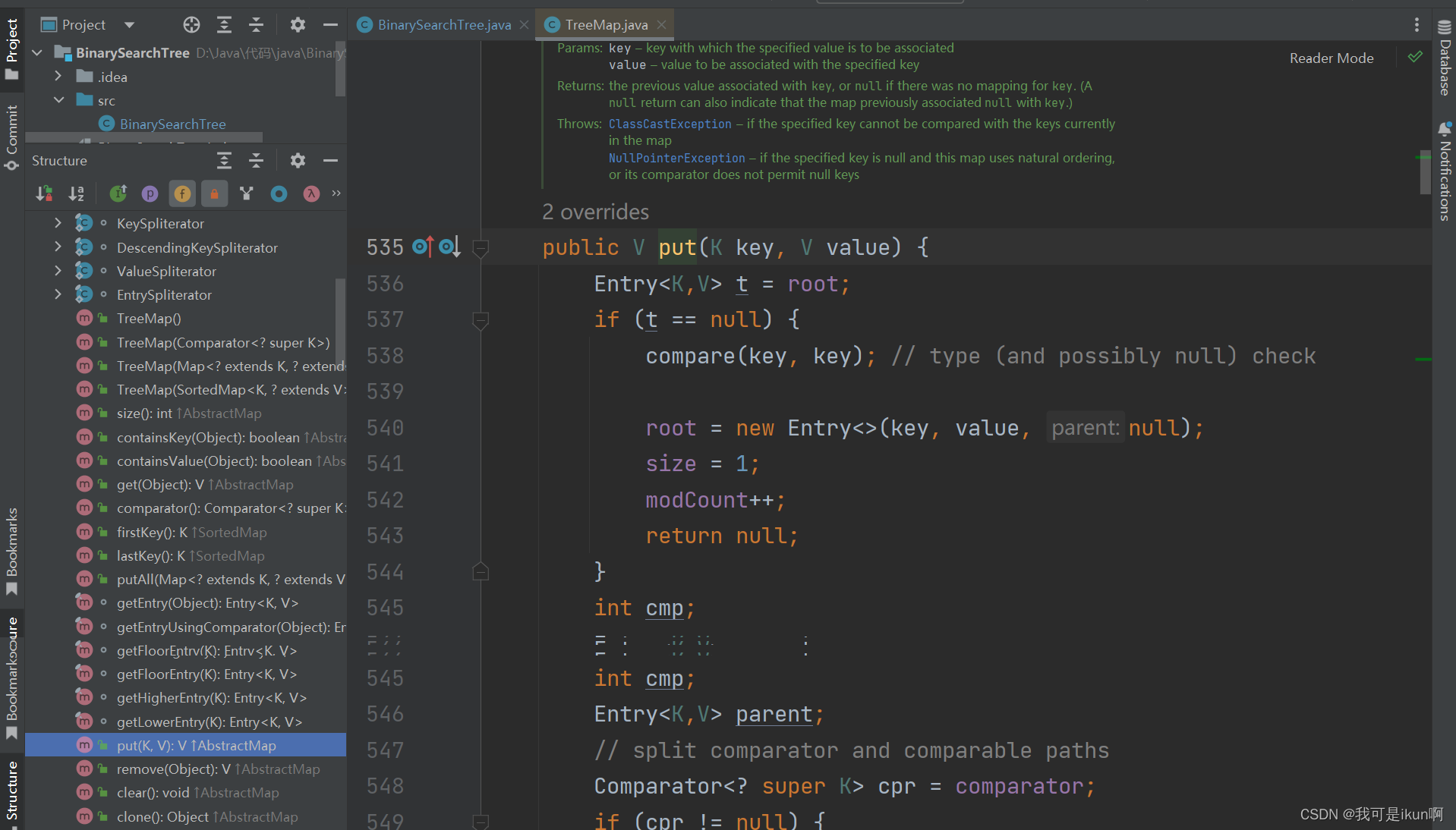
Map和Set(Java详解)
在开始详解之前,先来看看集合的框架: 可以看到Set实现了Collection接口,而Map又是一个单独存在的接口。 而最下面又分别各有两个类,分别是TreeSet(Map)和 HashSet(Map)。 TreeSet&…...

第8篇 | 逻辑回归
逻辑回归虽然名字中包含"回归",但实际上是一种分类算法。它通过sigmoid函数将线性输出转换为概率,广泛用于二分类问题。本篇将详细介绍逻辑回归的原理、实现和应用。一、逻辑回归概述逻辑回归用于处理二分类问题,输出为样本属于某一…...

Save Image as Type:终极Chrome图片格式转换指南,三步快速解决网页图片格式不兼容难题
Save Image as Type:终极Chrome图片格式转换指南,三步快速解决网页图片格式不兼容难题 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址:…...

深入剖析YOLOv8核心模块:从架构设计到实战应用全解析
1. YOLOv8架构设计揭秘 YOLOv8作为目标检测领域的标杆模型,其架构设计处处体现着工程师的巧思。我第一次拆解它的代码时,最惊艳的是它的模块化设计——就像搭积木一样,每个组件都能灵活替换。核心的Backbone部分采用CSPDarknet53结构…...

告别“人工智障”!OpenClaw + 大模型:打造真正能“看懂、想通、干成”的机械臂智能体
写在前面 在机器人圈子里,有个心照不宣的痛点:机械臂越来越便宜,但让它“听话”却越来越难。 传统的示教编程(Teaching Pendant)太慢,改个产品就得重教一遍;视觉定位(Vision Guided&…...

Qwen3-VL-8B数据库课程设计:构建一个多模态商品智能检索系统
Qwen3-VL-8B数据库课程设计:构建一个多模态商品智能检索系统 最近有个学弟跑来问我,说数据库课程设计不知道做什么好,想做个有技术含量又能拿高分的项目。我给他提了个建议,用现在很火的多模态大模型,结合传统的数据库…...

学习如何聚合零样本大型语言模型代理以进行企业披露分类
摘要本文研究一个轻量级训练聚合器是否能够将多样化的零样本大语言模型判断整合为更强的下游信号,用于公司披露分类。零样本大语言模型无需针对特定任务进行微调即可阅读披露文本,但其预测结果常因提示词、推理方式和模型家族的不同而存在差异。我采用一…...

SEO_避开这些常见误区,让你的SEO效果翻倍
<h2>避开这些常见误区,让你的SEO效果翻倍</h2> <p>在当今的互联网时代,搜索引擎优化(SEO)已经成为了每个网站和博客运营者必须掌握的技能之一。许多人在进行SEO时却会犯一些常见的错误,这些错误不仅…...

节能模式:OpenClaw+nanobot的间歇性任务调度技巧
节能模式:OpenClawnanobot的间歇性任务调度技巧 1. 为什么需要节能模式 去年夏天,我的电费账单突然飙升。排查后发现,那台24小时运行OpenClaw的工作站竟然是耗电大户——它持续调用着本地部署的Qwen大模型,GPU风扇昼夜不停地呼啸…...

UE4SS终极指南:解锁虚幻引擎4/5游戏Mod开发新境界
UE4SS终极指南:解锁虚幻引擎4/5游戏Mod开发新境界 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

F3D动画播放教程:如何轻松展示和播放3D模型动画
F3D动画播放教程:如何轻松展示和播放3D模型动画 【免费下载链接】f3d Fast and minimalist 3D viewer. 项目地址: https://gitcode.com/GitHub_Trending/f3/f3d 想要快速查看和播放3D模型动画吗?F3D(Fast and minimalist 3D viewer&am…...