Java面试知识点
工作也有好些年了,从刚毕业到前几年看过无数的面试题,总想着自己写一个面试总结,随着自我认识的变化,一些知识点的理解也越来越不一样了。写下来温故而知新。很多问题可能别人也总结过,但是答案不尽相同,如有问题欢迎指正以备完善。
现在的问题还不是很全面,会持续更新,大家有遇到一些面试题的话,也可以评论出来,一起完善。
1. JDK与JRE的区别
- JDK(Java development kit)Java开发工具包,JRE(Java runtime environment)Java运行环境。JDK中包含JRE,JDK中有一个名为jre的目录,里面包含两个文件夹bin和lib,bin就是JVM,lib就是JVM工作所需要的类库。
- JRE包含了java虚拟机、java基础类库。是使用java语言编写的程序运行所需要的软件环境,是提供给想运行java程序的用户使用的。JDK是程序员使用java语言编写java程序所需的开发工具包,是提供给程序员使用的。运行java程序只需安装JRE。如果需要编写java程序,需要安装JDK。
2. final修饰符的作用:
(1)修饰一个引用
如果引用为基本数据类型,则该引用为常量,该值无法修改;
如果引用为引用数据类型,比如对象、数组,则该对象、数组本身可以修改,但指向该对象或数组的地址的引用不能修改。
如果引用是类的成员变量,则必须当场赋值,否则编译会报错。
(2)用来修饰一个方法
当使用final修饰方法时,这个方法将成为最终方法,无法被子类重写。但是,该方法仍然可以被继承。
(3)用来修饰类
当用final修改类时,该类成为最终类,无法被继承。比如常用的String类就是最终类。
3. Math相关方法:
Math.ceil向上取整,Math.floor向上取整,Math.round数值加0.5后向下取整。
Math.ceil(11.3) = 12;
Math.ceil(-11.3) = 11;
Math.floor(11.3) = 11;
Math.floor(-11.3) = -12;
Math.round(11.3) = 11;
Math.round(11.8) = 12;
Math.round(-11.3) = -11;
Math.round(-11.8) = -12;
4. String str="i"与 String str=new String(“i”)
不一样,String str="i"会将其分配到常量池中,常量池中没有重复的元素,如果常量池中有i,就将i的地址赋给变量,如果没有就创建一个再赋给变量。String str=new String(“i”)会将对象分配到堆中,即使内存一样,还是会重新创建一个新的对象。
5. 如何将字符串翻转?
这儿提供两种方式:stringbuilder.reverse及char[]。
public static void main(String[] args) {String abc = "hello world";StringBuilder stringBuilder = new StringBuilder(abc);String reverse = stringBuilder.reverse().toString();System.out.println(reverse);
}
public static void main(String[] args) {String abc = "hello world";char[] chars = abc.toCharArray();char[] newd = new char[abc.length()];for (int i = 0; i < chars.length; i++) {char aChar = chars[chars.length - i - 1];newd[i]=aChar;}String s = String.valueOf(newd);System.out.println(s);
}
6. 普通类和抽象类的区别
- 抽象类的存在是为了被继承,不能实例化,而普通类存在是为了实例化一个对象。
- 抽象类的子类必须重写抽象类中的抽象方法,而普通类可以选择重写父类的方法,也可以直接调用父类的方法。
- 抽象类必须用abstract来修饰,普通类则不用。
- 普通类和抽象类都可以含有普通成员属性和普通方法。
- 普通类和抽象类都可以继承别的类或者被别的类继承。
- 普通类和抽象类的属性和方法都可以通过子类对象来调用。
7. 接口与抽象类的区别
- 抽象类和接口都不能直接实例化。如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
- 抽象类要被子类继承,接口要被类实现。
- 接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现。
- 接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
- 抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
- 抽象方法只能申明,不能实现。
- 抽象类里可以没有抽象方法
- 如果—个类里有抽象方法,那么这个类只能是抽象类
- 抽象方法要被实现,所以不能是静态的,也不能是私有的。
8. JAVA中IO流分类及区别
按照数据的流向:输入流:读数据。输出流:写数据
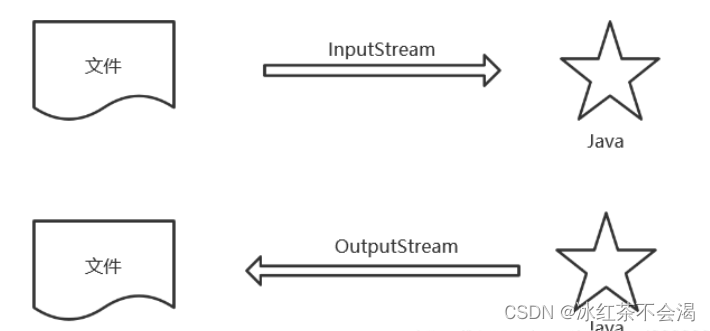
按照数据类型来分:
字节流:字节输入流(Inputstream),字节输出流(Outputstream)
字符流:字符输入流(Reader),字符输出流(Writer)
- 字符流和字节流是根据处理数据的类型的不同来区分的。
- 字节流按照8位传输,字节流是最基本的,所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。
- 字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串;
- 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
- 理论上任何文件都能够用字节流读取,但当读取的是文本数据时,为了能还原成文本你必须再经过一个转换的工序,相对来说字符流就省了这个麻烦,可以有方法直接读取。所以,如果是处理纯文本数据,就要优先考虑字符流,除此之外都是用字节流。
9. 什么是反射?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法,所以先要获取到每一个字节码文件对应的Class类型的对象。
反射就是把java类中的各种成分映射成一个个的Java对象。
反射这儿比较重要,再次不详细展开,可查看相关链接:
Java基础-反射
10. 什么是,为什么要,怎么实现序列化?
如果我们需要持久化Java对象比如将Java对象保存在文件中,或者在网络传输Java对象,这些场景都需要用到序列化。简单来说:
序列化: 将数据结构或对象转换成二进制字节流的过程。
反序列化:将在序列化过程中所生成的二进制字节流的过程转换成数据结构或者对象的过程。
常见的序列化实现方式为:JDK 自带的序列化,只需实现 java.io.Serializable接口即可。
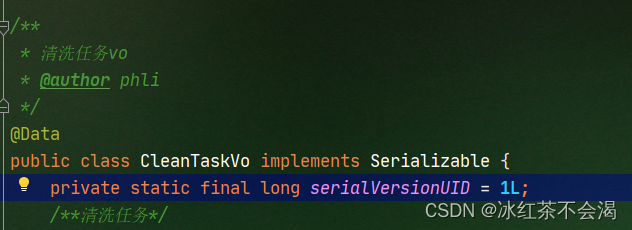 序列化号 serialVersionUID 属于版本控制的作用。序列化的时候serialVersionUID也会被写入二级制序列,当反序列化时会检查serialVersionUID是否和当前类的serialVersionUID一致。如果serialVersionUID不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的序列化号。日常使用指定为1L即可。
序列化号 serialVersionUID 属于版本控制的作用。序列化的时候serialVersionUID也会被写入二级制序列,当反序列化时会检查serialVersionUID是否和当前类的serialVersionUID一致。如果serialVersionUID不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的序列化号。日常使用指定为1L即可。
11. throw与throws的异同
较为基础的问题,日常开发过程中会较多用到的异常处理方式。
- 不同点:
位置不同。throws用在函数上,后边跟的是异常类,可以跟多个异常类。throw用在函数内,后面跟的是异常对象。
功能不同。①throws用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先得处理方式。throw抛出具体的问题对象,执行到throw。功能就已经结束了跳转到调用者,并将具体的问题对象抛给调用者,也就是说throw语句独立存在时,下面不要定义其他语句,因为执行不到。②throws表示出现异常的一种可能性,并不一定会发生这些异常,throw则是抛出了异常,执行throw则一定抛出了某种异常对象。 - 相同点:
两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
12. try-catch-finally-return的执行顺序
public static void main(String[] args) {System.out.println(test());
}public static int test() {try {int abc = 1/0;System.out.println("try");return 0;} catch (Exception e) {System.out.println(e.getMessage());return 1;} finally {System.out.println("finally");}
}
/ by zero
finally
1
13. 什么是,为什么要有hashcode,hashcode与equals关系
- hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义 在 JDK 的 Object.java 中,这就意味着Java 中的任何类都包含有 hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象) - 为什么要有hashcode
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。
如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。 - Object 类中的 equals 方法用于检测一个对象是否等于另外一个对象。在 Object类中,这个方法将判断两个对象是否具有相同的引用。如果两个对象具有相同的引用,它们一定是相等的。当我们对比两个对象是否相等时,我们就可以先使用 hashCode 进行比较,如果比较的结果是 true,那么就可以使用 equals再次确认两个对象是否相等,如果比较的结果是true,那么这两个对象就是相等的,否则其他情况就认为两个对象不相等。这样就大大的提升了对象比较的效率,这也是为什么 Java 设计使用hashCode 和 equals 协同的方式,来确认两个对象是否相等的原因。
- 如果equals为true,hashcode一定相等(没有重写equals的情况下);
如果equals为false,hashcode不一定不相等;
如果hashcode值相等,equals不一定相等;
如果hashcode值不等,equals一定不等(没有重写equals的情况下);
14. 在 Java 中,为什么不允许从静态方法中访问非静态变量?
- 静态变量属于类本身,在类加载的时候就会分配内存,可以通过类名直接访问;
- 非静态变量属于类的对象,只有在类的对象产生时,才会分配内存,通过类的实例去访问;
- 静态方法也属于类本身,但是此时没有类的实例,内存中没有非静态变量,所以无法调用非静态变量。
15. 实例化对象的方式
-
new
-
clone()
-
通过反射机制创建
用 Class.forName方法获取类,在调用类的newinstance()方法
Class<?> cls = Class.forName("com.dao.User");User u = (User)cls.newInstance();
- 序列化反序列化
将一个对象实例化后,进行序列化,再反序列化,也可以获得一个对象(远程通信的场景下使用
ObjectOutputStream out = new ObjectOutputStream (new FileOutputStream("D:/data.txt"));//序列化对象out.writeObject(user1); out.close();//反序列化对象ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:/data.txt"));User user2 = (User) in.readObject();System.out.println("反序列化user:" + user2);in.close();
16. Bean的生命周期
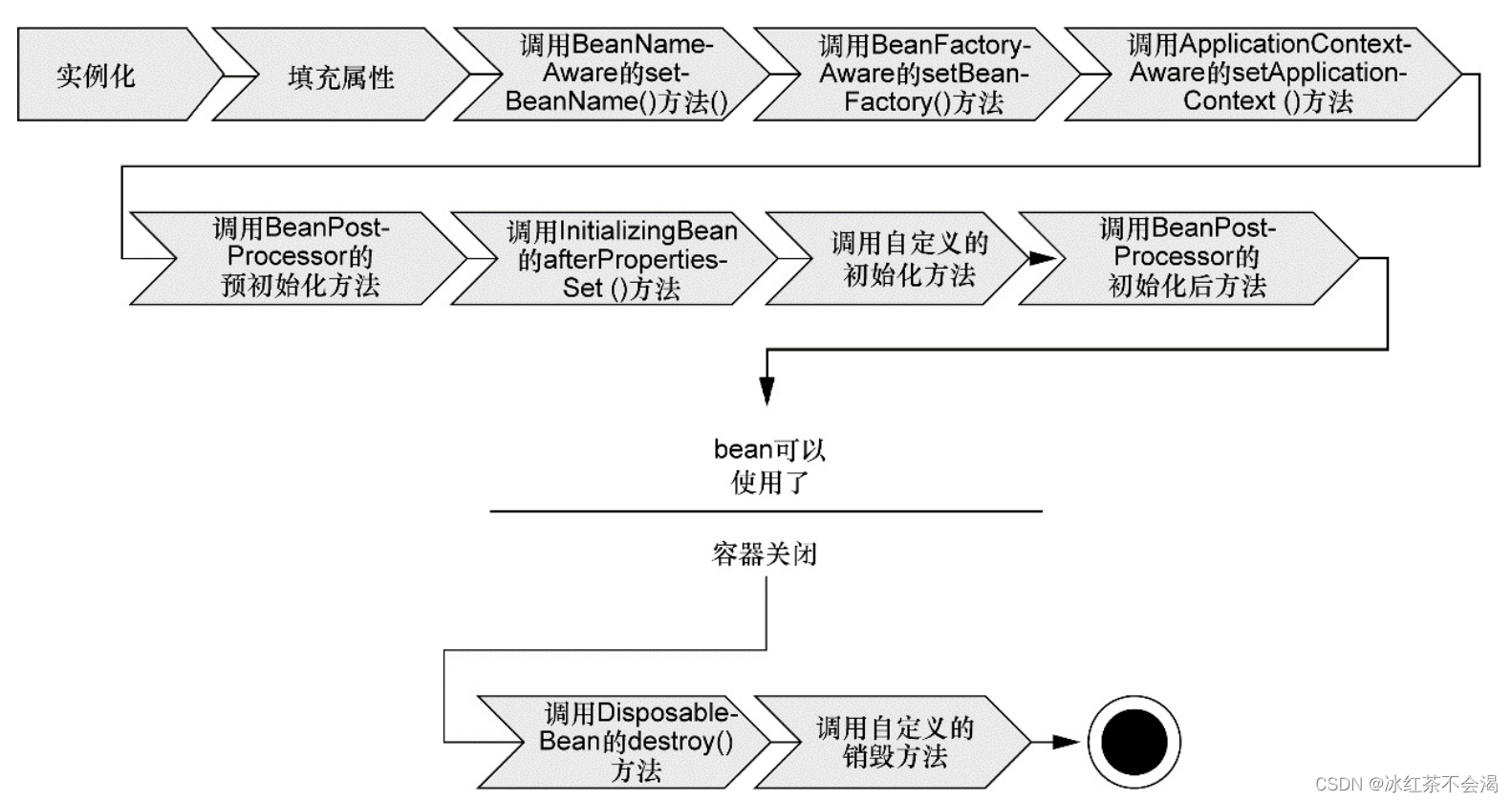
- Spring 对bean 进行实例化。
- Spring 将值和bean的引用注入到bean对应的属性中。
- 如果bean实现了BeanNameAware接口,Spring将bean的ID传递给setBean-Name() 方法。
- 如果bean 实现了BeanFactoryAware接口,Spring将调用setBeanFactory() 方法,将BeanFactory容器实例传入。
- 如果bean实现了ApplicationContextAware接口,Spring将调用setApplicationContext() 方法,将bean所在的应用上下文的引用传入进来。
- 如果bean实现了BeanPostProcessor接口,Spring将调用它们的post-ProcessBeforeInitialization() 方法
- 如果bean实现了InitializingBean接口,Spring将调用它们的after-PropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用。
- 如果bean实现了BeanPostProcessor接口,Spring将调用它们的post-ProcessAfterInitialization() 方法。
- 此时, bean 已经准备就绪,可以被应用程序使用了,它们将一直驻留在应用上下文中,直到该应用上下文被销毁。
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法。同样,如果bean使用destroy-method声明了销毁方法,该方法也会被调用。
17. bean初始化执行是顺序
可以参考我之前写的文章:初始化执行顺序
18. HashMap与HashTable的区别
这个知识点比较老旧,HashTable在工作中基本没用到过。但是还是写出来了,仅限于了解知道这个事儿即可,现在面试基本不会问。
- Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
- Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
- HashMap可以让你将空值作为一个表的条目的key或value。
- HashMap的默认容器是16,为2倍扩容,HashTable默认是11,为2倍+1扩容。
19. HashMap put及get的实现原理
- HashMap是基于哈希表的Map接口的非同步实现。元素以键值对的形式存放,并且允许null键和null值,因为key值唯一(不能重复),因此,null键只有一个。另外,hashmap不保证元素存储的顺序,是一种无序的,和放入的顺序并不相同(此类不保证映射的顺序,特别是它不保证该顺序恒久不变)。HashMap是线程不安全的。
- map.put(k,v)实现原理:
首先将k,v封装到Node对象当中(节点)。
然后它的底层会调用K的hashCode()方法得出hash值。
通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。 - map.get(k)实现原理:
先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
20. HashMap相关面试题
- HashMap内部的bucket数组长度为什么一直都是2的整数次幂答:这样做有两个好处,第一,可以通过(table.length - 1) & key.hash()这样的位运算快速寻址,第二,在HashMap扩容的时候可以保证同一个桶中的元素均匀地散列到新的桶中,具体一点就是同一个桶中的元素在扩容后一般留在原先的桶中,一般放到了新的桶中。
- HashMap默认的bucket数组是多大答:默认是16,即时指定的大小不是2的整数次幂,HashMap也会找到一个最近的2的整数次幂来初始化桶数组。
- HashMap什么时候开辟bucket数组占用内存答:在第一次put的时候调用resize方法。
- HashMap何时扩容?答:当HashMap中的元素熟练超过阈值时,阈值计算方式是capacity * loadFactor,在HashMap中loadFactor(负载因子)是0.75。
- 桶中的元素链表何时转换为红黑树,什么时候转回链表,为什么要这么设计?答:当同一个桶中的元素数量大于等于8的时候元素中的链表转换为红黑树,反之,当桶中的元素数量小于等于6的时候又会转为链表,这样做的原因是避免红黑树和链表之间频繁转换,引起性能损耗。
- Java 8中为什么要引进红黑树,是为了解决什么场景的问题?答:引入红黑树是为了避免hash性能急剧下降,引起HashMap的读写性能急剧下降的场景,正常情况下,一般是不会用到红黑树的,在一些极端场景下,假如客户端实现了一个性能拙劣的hashCode方法,可以保证HashMap的读写复杂度不会低于O(lgN)public int hashCode() {
return 1;
} - HashMap如何处理key为null的键值对?答:放置在桶数组中下标为0的桶中。
21. HashSet实现原理
HashSet是Set的实现,HashSet底层其实是一个HashMap实例,都是一个存放链表的数组。

HashSet是基于HashMap实现的,HashSet中所有的元素都存放在HashMap的key上,而value中的值都是统一的一个固定的对象:private static final Object PRESENT = new Object(); HashSet的add方法:
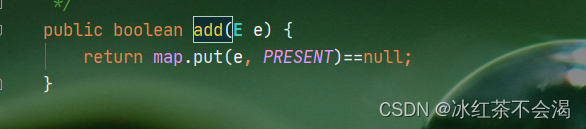
HashSet中add方法调用的是底层HashMap的put方法。如果是在HashMap中调用put方法,首先会去判断key是否已经存在,如果存在,则修改value的值,如果不存在,则插入这个k-v对。而在Set中,value是没有用的,所以也就不存在修改value的情况,故而,向HashSet中添加新的元素,首先判断元素是否存在,不存在则插入,存在则pass,这样HashSet中就不存在重复值了。
所以,判断key是否存在就需要去重写元素类的equals()和hashCode()方法。当向Set中添加元素的时候,先调用元素所在类的hashCode()方法,计算元素对象的哈希值,这个哈希值决定了这个元素在Set中存放的位置,如果这个位置是空的,没有存放其他元素,那么就直接把这个元素存放在这里;如果这个位置已经被别人占了,那么就调用元素所在类的equals()方法比较两个对象是否相同,相同就直接pass掉,保证了元素的不可重复性。
所以,在使用HashMap和HashSet的时候,如果Map的key或者Set中要存入自定义类的对象,必须重写hashCode和equals方法。
22. Java中如何确保一个集合不会被修改
我们很容易想到用final关键字进行修饰,我们都知道
final关键字可以修饰类,方法,成员变量,final修饰的类不能被继承,final修饰的方法不能被重写,final修饰的成员变量必须初始化值,如果这个成员变量是基本数据类型,表示这个变量的值是不可改变的,如果说这个成员变量是引用类型,则表示这个引用的地址值是不能改变的,但是这个引用所指向的对象里面的内容还是可以改变的。
那么,我们怎么确保一个集合不能被修改?首先我们要清楚,集合(map,set,list…)都是引用类型,所以我们如果用final修饰的话,集合里面的内容还是可以修改的。
那我们应该怎么做才能确保集合不被修改呢?
我们可以采用Collections包下的unmodifiableMap方法,通过这个方法返回的map,是不可以修改的。他会报 java.lang.UnsupportedOperationException错。
同理:Collections包也提供了对list和set集合的方法。Collections.unmodifiableList(List) Collections.unmodifiableSet(Set)
23. HashMap 在 JDK7 和 JDK8 有哪些区别?
- 数据结构:在 JDK7 及之前的版本,HashMap 的数据结构可以看成“数组+链表”,在 JDK8 及之后的版本,数据结构可以看成"数组+链表+红黑树",当链表的长度超过8时,链表就会转换成红黑树,从而降低时间复杂度(由O(n) 变成了 O(logN)),提高了效率
- 对数据重哈希:JDK8 及之后的版本,对 hash() 方法进行了优化,重新计算 hash 值时,让 hashCode 的高16位参与异或运算,目的是在 table 的 length较小的时候,在进行计算元素存储位置时,也让高位也参与运算。
- 在 JDK7 及之前的版本,在添加元素的时候,采用头插法,所以在扩容的时候,会导致之前元素相对位置倒置了,在多线程环境下扩容可能造成环形链表而导致死循环的问题。DK1.8之后使用的是尾插法,扩容是不会改变元素的相对位置
- 扩容时重新计算元素的存储位置的方式:JDK7 及之前的版本重新计算存储位置是直接使用 hash & (table.length-1);JDK8 使用节点的hash值与旧数组长度进行位与运算,如果运算结果为0,表示元素在新数组中的位置不变;否则,则在新数组中的位置下标=原位置+原数组长度。
- JDK7 是先扩容后插入,这就导致无论这次插入是否发生hash冲突都需要进行扩容,但如果这次插入并没有发生Hash冲突的话,那么就会造成一次无效扩容;JDK8是先插入再扩容的,优点是减少这一次无效的扩容,原因就是如果这次插入没有发生Hash冲突的话,那么其实就不会造成扩容
24. HashMap的线程不安全体现在哪儿,如何变成线程安全?
无论在JDK7还是JDK8的版本中,HashMap 都是线程不安全的,主要体现在以下两个方面:
- 在JDK7及以前的版本,表现为在多线程环境下进行扩容,由于采用头插法,位于同一索引位置的节点顺序会反掉,导致可能出现死循环的情况。
- 在JDK8及以后的版本,表现为在多线程环境下添加元素,可能会出现数据丢失的情况。
如果想使用线程安全的 Map 容器,可以使用以下几种方式:
- 使用线程安全的 Hashtable,它底层的每个方法都使用了 synchronized 保证线程同步,所以每次都锁住整张表,在性能方面会相对比较低。
- 使用Collections.synchronizedMap()方法来获取一个线程安全的集合,底层原理是使用synchronized来保证线程同步。
- 使用 ConcurrentHashMap 集合。
25. ConcurrentHashMap 在 JDK7 和 JDK8的区别?
- 数据结构:JDK7 的数据结构是 Segment数组 + HashEntry数组 + 链表,JDK8 的数据结构是 HashEntry数组 + 链表 + 红黑树,当链表的长度超过8时,链表就会转换成红黑树,从而降低时间复杂度(由O(n) 变成了 O(logN)),提高了效率
- 锁的实现:JDK7的锁是segment,是基于ReentronLock实现的,包含多个HashEntry;而JDK8 降低了锁的粒度,采用 table 数组元素作为锁,从而实现对每行数据进行加锁,进一步减少并发冲突的概率,并使用 synchronized 来代替 ReentrantLock,因为在低粒度的加锁方式中,synchronized 并不比 ReentrantLock 差,在粗粒度加锁中ReentrantLock 可以通过 Condition 来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了。
- 统计集合中元素个数 size 的方式:JDK7 是先尝试 2次通过不锁住 segment 的方式来统计各个 segment 大小,如果统计的过程中,容器的 count 发生了变化,则再采用加锁的方式来统计所有Segment的大小;在 JDK8 中,对于size的计算,在扩容和 addCount() 方法中就已经有处理了,等到调用 size() 时直接返回元素的个数
26. concurrentHashMap和HashTable有什么区别
concurrentHashMap融合了hashmap和hashtable的优势,hashmap是不同步的,但是单线程情况下效率高,hashtable是同步的同步情况下保证程序执行的正确性。
但hashtable每次同步执行的时候都要锁住整个结构,如下图:
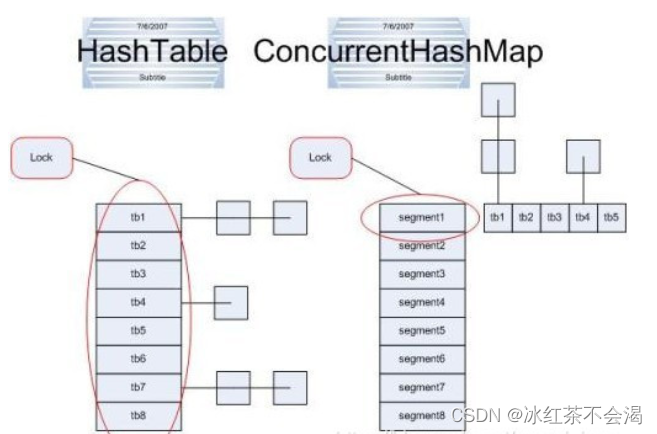
concurrentHashMap锁的方式是细粒度的。concurrentHashMap将hash分为16个桶(默认值),诸如get、put、remove等常用操作只锁住当前需要用到的桶。
concurrentHashMap的读取并发,因为读取的大多数时候都没有锁定,所以读取操作几乎是完全的并发操作,只是在求size时才需要锁定整个hash。
而且在迭代时,concurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,弱一致迭代器。在这种方式中,当iterator被创建后集合再发生改变就不会抛出ConcurrentModificationException,取而代之的是在改变时new新的数据而不是影响原来的数据,iterator完成后再讲头指针替代为新的数据,这样iterator时使用的是原来的数据。
27. ArrayList与LinkedList的区别
-
ArrayList 和 LinkedList 是 List 接口的两种不同实现,并且两者都不是线程安全的。
-
ArrayList 内部使用的动态数组来存储元素,LinkedList 内部使用的双向链表来存储元素,这也是 ArrayList 和 LinkedList 最本质的区别。由于内部使用的存储方式不同,导致它们的各种方法具有不同的时间复杂度。
-
ArrayList 和 LinkedList 在内存的使用上也有所不同。LinkedList 的每个元素都有更多开销,因为要存储上一个和下一个元素的地址。ArrayList 没有这样的开销。
-
ArrayList 占用的内存在声明的时候就已经确定了(默认大小为 10),不管实际上是否添加了元素,因为复杂对象的数组会通过 null 来填充。LinkedList 在声明的时候不需要指定大小,元素增加或者删除时大小随之改变(双向链表决定的)。LinkedList 允许内存进行动态分配,这就意味着内存分配是由编译器在运行时完成的,我们无需在 LinkedList 声明的时候指定大小。。
-
ArrayList 只能用作列表;LinkedList 可以用作列表或者队列,因为它还实现了 Deque 接口。
-
查询的时候,ArrayList 比 LinkedList 快。插入删除的时候LinkedList会更快些。
因为数组的元素需要连续的内存位置来存储其值。这就是 ArrayList 进行删除或者插入元素的时候成本很高的真正原因,因为我们必须移动某些元素为新的元素留出空间,比如说:现在有一个数组,10、12、15、20、4、5、100,如果需要在 12 的位置上插入一个值为 99 的元素,就必须得把 12 以后的元素往后移动,为 99 这个元素腾出位置。LinkedList 不需要在连续的位置上存储元素,因为节点可以通过引用指定下一个节点或者前一个节点。也就是说,LinkedList 在插入和删除元素的时候代价很低,因为不需要移动其他元素,只需要更新前一个节点和后一个节点的引用地址即可。。
个人看法:如果不知道该用 ArrayList 还是 LinkedList,就选择 ArrayList 。
28. HashMap与HashSet的区别
先贴一个众所周知的区别:
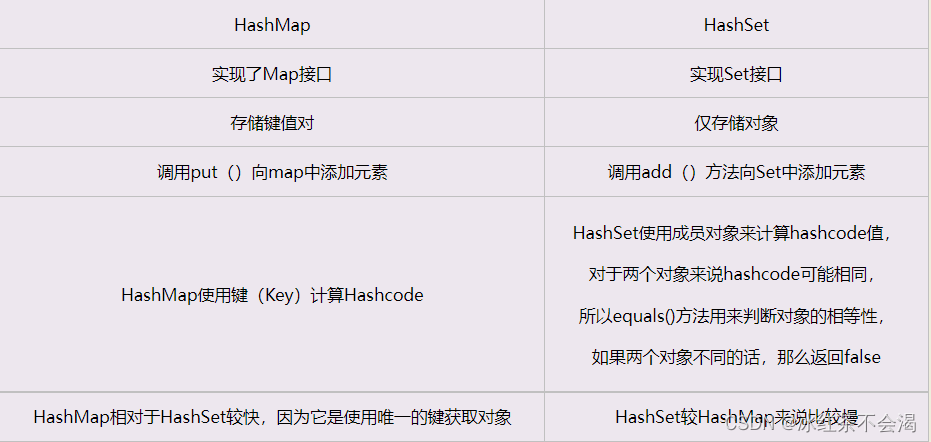
但其实从根本上来说,它俩本来就是同一个东西。再说的清楚明白一点, HashSet 就是个套了壳儿的 HashMap。虽然hashset是调用add()方法添加元素,但是其实HashSet的 add方法其实就是调用了HashMap的put方法,
相关文章:
Java面试知识点
工作也有好些年了,从刚毕业到前几年看过无数的面试题,总想着自己写一个面试总结,随着自我认识的变化,一些知识点的理解也越来越不一样了。写下来温故而知新。很多问题可能别人也总结过,但是答案不尽相同,如…...

PTA Advanced 1159 Structure of a Binary Tree C++
目录 题目 Input Specification: Output Specification: Sample Input: Sample Output: 思路 代码 题目 Suppose that all the keys in a binary tree are distinct positive integers. Given the postorder and inorder traversal sequences, a binary tree can be un…...
CDN绕过技术总汇
注 本文首发于合天网安实验室 首发链接:https://mp.weixin.qq.com/s/9oeUpFUZ_0FUu6YAhQGuAg 近日HVV培训以及面试,有人问了CDN该如何绕过找到目标真实IP,这向来是个老生常谈的问题,而且网上大多都有,但是有些不够全面…...
算法训练营DAY51|300.最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
本期是求子序列的新的一期,题目前两道有一些相似之处,思路差不多,第三道有一点难度,但并不意味着第一道没有难度,没有做过该类型题的选手,并不容易解出题解。 300. 最长递增子序列 - 力扣(Leet…...
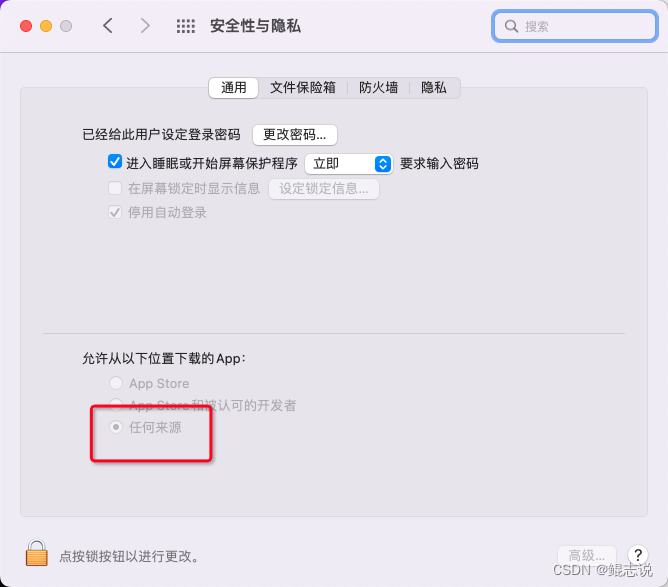
mac:彻底解决-安装应用后提示:无法打开“XXX”,因为无法验证开发者的问题;无法验证此App不包含恶意软件
mac从浏览器或其他电脑接收了应用,但是打开报错 目录报错解决办法一次性方法永久解决方法验证恢复应用验证报错 截图如下: 错误信息 无法打开“XXX”,因为无法验证开发者的问题;无法验证此App不包含恶意软件 解决办法 一次性方…...

CPU 指标 user/idle/system 说明
从图中看出,一共有五个关于CPU的指标。分别如下: User User表示:CPU一共花了多少比例的时间运行在用户态空间或者说是用户进程(running user space processes)。典型的用户态空间程序有:Shells、数据库、web服务器…… Nice N…...
Thinkphp大型进销存ERP源码/ 进销存APP源码/小程序ERP系统/含VUE源码支持二次开发
框架:ThinkPHP5.0.24 uniapp 包含:服务端php全套开源源码,uniapp前端全套开源源码(可发布H5/android/iod/微信小程序/抖音小程序/支付宝/百度小程序) 注:这个是全开源,随便你怎么开,怎么来&a…...
hgame2023 WebMisc
文章目录Webweek1Classic Childhood GameBecome A MemberGuess Who I AmShow Me Your BeautyWeek2Git Leakagev2boardSearch CommodityDesignerweek3Login To Get My GiftPing To The HostGopher Shopweek4Shared DiaryTell MeMiscweek1Where am I神秘的海报week2Tetris Master…...

67. Python的绝对路径
67. Python的绝对路径 文章目录67. Python的绝对路径1. 准备工作2. 路径3. 绝对路径3.1 概念3.2 查看绝对路径的方法4. 课堂练习5. 用绝对路径读取txt文件6. 加\改写绝对路径6.1 转义字符知识回顾6.2 转义字符改写7. 总结1. 准备工作 对照下图,新建文件夹和txt文件…...

VHDL语言基础-组合逻辑电路-加法器
目录 加法器的设计: 半加器: 全加器: 加法器的模块化: 四位串行进位全加器的设计: 四位并行进位全加器: 串行进位与并行进位加法器性能比较: 8位加法器的实现: 加法器的设计&…...

内存检测工具Dr.Memory在Windows上的使用
之前在https://blog.csdn.net/fengbingchun/article/details/51626705 中介绍过Dr.Memory,那时在Windows上还不支持x64,最新的版本对x64已有了支持,这里再总结下。 Dr.Memory源码地址https://github.com/DynamoRIO/drmemory,最新发…...

J6412四网口迷你主机折腾虚拟机教程
今天给大家做一个四网口迷你主机折腾虚拟机的安装教程,主机采用的是maxtang大唐NUC J6412 intel i226V四网口的迷你主机,这款主机它是不能直接装上NAS的,必须使用虚拟机系统,近期研究了下然后做了一个教程分享给大家。 首先需要做…...

电子招标采购系统—企业战略布局下的采购寻源
智慧寻源 多策略、多场景寻源,多种看板让寻源过程全程可监控,根据不同采购场景,采取不同寻源策略, 实现采购寻源线上化管控;同时支持公域和私域寻源。 询价比价 全程线上询比价,信息公开透明ÿ…...

elasticsearch 之 mapping 映射
当我们往 es 中插入数据时,若索引不存在则会自动创建,mapping 使用默认的;但是有时默认的映射关系不能满足我们的要求,我们可以自定义 mapping 映射关系。 mapping 即索引结构,可以看做是数据库中的表结构,…...
)
2023年rabbitMq面试题汇总2(5道)
一、如何确保消息接收⽅消费了消息?接收⽅消息确认机制:消费者接收每⼀条消息后都必须进⾏确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。这⾥并没有⽤到超时…...
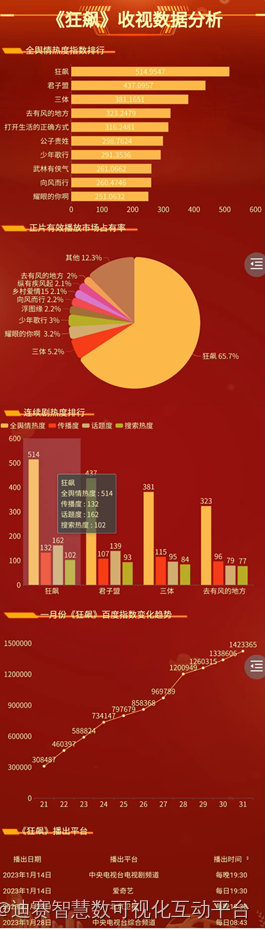
电视剧《狂飙》数据分析,正片有效播放市场占有率达65.7%
哈喽大家好,春节已经过去了,朋友们也都陆陆续续开工了,小编在这里祝大家开工大吉!春节期间,一大批电视剧和网剧上映播出,其中电视剧《狂飙》以不可阻挡之势成功成为“开年剧王”。这里小编整理了一些《狂飙…...

cas单点登录后重定向次数过多问题以及调试cas-dot-net-client
问题描述: web项目应用cas作为单点登录站点,登录后无法打开WEB项目的页面,报错,说重定向次数过多。 老实说,这种问题,以前遇到过不少,是我这种半桶水程序员的噩梦。解决这种问题,不…...
【监控】Prometheus(普罗米修斯)监控概述
文章目录一、监控系统概论二、基础资源监控2.1、网络监控2.2、存储监控2.3、服务器监控2.4、中间件监控2.5、应用程序监控(APM)三、Prometheus 简介3.1、什么是 Prometheus3.2、优点3.3、组件3.4、架构3.5、适用于什么场景3.6、不适合什么场景四、数据模…...
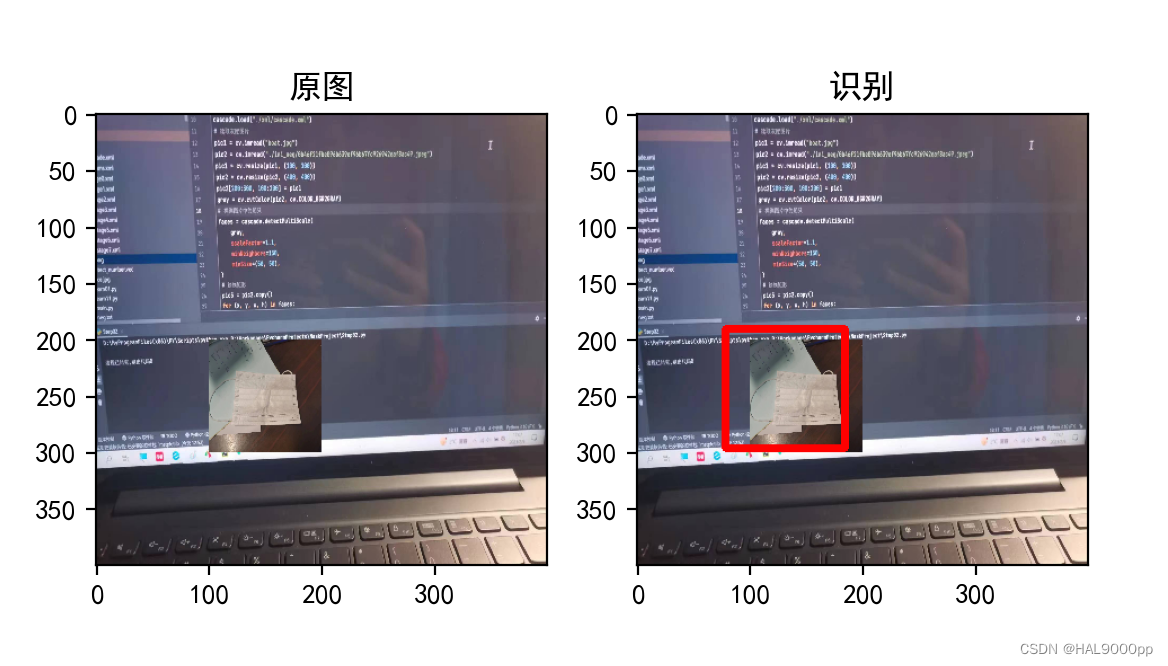
opencv+python物体检测【03-模仿学习】
仿照练习:原文链接 步骤一:准备图片 正样本集:正样本集为包含“识别物体”的灰度图,一般大于等于2000张,尺寸不能太大,尺寸太大会导致训练时间过长。 负样本集:负样本集为不含“识别物体”的…...

计算机科学基础知识第二节讲义
课程链接 运行环境:WSL Ubuntu OMZ终端 PS:看到老师终端具有高亮和自动补全功能,我连夜肝出oh-my-zsh安装教程,实现了此功能。 这节课主要讲变量的语法、控制流程、shell功能等内容。 修改终端用户名,输入密码后重启…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...