滴滴一面:order by 调优10倍,思路是啥?
背景说明:
Mysql调优,是大家日常常见的调优工作。
所以,Mysql调优是一个非常、非常核心的面试知识点。
在40岁老架构师 尼恩的读者交流群(50+)中,其相关面试题是一个非常、非常高频的交流话题。
近段时间,有小伙伴面试滴滴,说遇到一个order by 调优的面试题:
order by 线上的查询速度太慢, 需要优化10倍以上, 说说你的思路?
社群中,还遇到过大概的变种:
形式1:order by 是怎么实现排序的?
形式2:order by 是怎么实现优化的?
形式3: 后面的变种,应该有很多变种…,会收入 《尼恩Java面试宝典》。
这里尼恩给大家order by 调优,做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个 题目以及参考答案,收入咱们的《尼恩Java面试宝典》,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
回答这个order by的优化之前,首先要给面试官介绍一下order by的底层原理。
首先、什么是Order by 工作原理?
假设,有一个用户表为例,表结构如下:
create table `user` (`id` int(11) not null auto_increment COMMENT 'id',`city` varchar(16) not null COMMENT '城市',`name` varchar(16) not null COMMENT '姓名',`age` int(11) not null COMMENT '年龄',`sex` int(1) default 1 COMMENT '性别',primary key (`id`),key `city` (`city`)
) engine = InnoDB comment '用户表';
表数据示例如下:

现在假定有个需求:查询前 5 个来自北京的用户姓名、年龄、城市,并且按照年龄升序排序。
那么相应的 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;
这条 SQL 语句逻辑简单清晰,要点有3个:
- city = ‘北京’ :有where 查询条件
- order by age :根据 age 排序,默认是asc
- limit 5 :取得 top5
那么 mysql 底层是如何执行的呢?
首先,给大家介绍一下宏观的思路。
Order by 执行的两步
总体来说,Order by 执行流程,分为两步,具体如下:

第1步:索引的查找
根据where 后面的字段,进行 二级索引的查找,找到后再回表 聚集索引,拿到需要的字段
第2步:原始数据的排序
原始数据的数据, 并不是按照 order by 有序的。
所以,需要按照 order by 字段,进行排序。
接下来,排序的地点在哪里呢?
- 优先选择内存。因为内存的性能高。
- 如果原始的数据实在规模太大,就借助磁盘进行排序。
用于排序的内存,称为 sort_buffer。其实 MySQL 会给每个线程分配一块内存用于排序的 sort_buffer。
了解了整个步骤后,开始来看看执行计划。
然后再看怎么优化。
Explain查看执行计划
我们先用Explain关键字查看一下执行计划。
那么相应的 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;

可以看到:
- key 字段表示使用到 city 索引,
- Extra 字段中的
Using index condition表示用到了索引条件, Using filesort表示用到了文件排序 。
用到文件排序,说明第一次查出来的 原始数据,在内存放不下, 需要借助 磁盘空间进行排序,
磁盘IO的性能比较低的,所以,需要进行调优。
再调优之前,首先图解一下order
图解一下Order by 执行的两步
第1步:索引的查找
根据where 后面的字段,进行 二级索引的查找,找到后再回表 聚集索引,拿到需要的字段
回顾 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;
首先从 二级索引city 索引树 的查找 city = ‘北京’ 的索引叶子。
在 city 索引树中是非聚簇索引树,叶子节点存储的是主键 ID。city 索引树 如下:

聚簇索引树的叶子节点则存放的是每行数据,如下图:
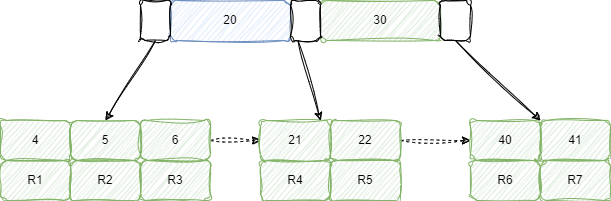
查询语句的执行流程就是先通过 city 索引树,找到对应的主键 ID,然后再搜索主键索引树,找到对应的行数据。
这些数据是原始数据,放在内存 sort_buffer 中。

第2步:原始数据的排序
原始数据的数据, 并不是按照 order by 有序的。 所以,需要按照 order by 字段,进行排序。
加上order by排序之后,整体的执行流程就是:

Order by 执行完整流程,如下:
- 当前线程首先初始化 sort_buffer 块,
- 然后从 city 索引树从查询一条满足
city='北京'的主键 ID, 比如图中的id=2, - 接着在聚簇索引树中查询
id=2的一行数据,将name、age、city三个字段的值,存到sort_buffer, - 继续重复前两个步骤,直到 city 索引树中找不到
city='北京'的主键 ID。 - 最后在sort_buffer中,将所有数据根据
age进行排序,取前 5 行返回给客户端。
全字段排序就是将查询所需的字段,如name、age、city三个字段数据全部存到 sort_buffer 中。
3个核心概念
接下来开始给面试官介绍如何调优。
不过不急,调优涉及到3个核心概念
- 全字段排序
- 外部排序
- rowid 排序
全字段排序
sort_buffer是 MySQL 为每个任务线程维护的一块内存区域,用于进行排序。
sort_buffer 的大小可以通过 sort_buffer_size 来设置。
那这种处理方式会存在一个问题, sort_buffer 是一块固定大小的内存,如果数据量太大,sort_buffer 放不下怎么办呢?
sort_buffer_size 是一个用于控制sort_buffer内存大小的参数。
外部排序
如果要排序的数据小于 sort_buffer_size,那在 sort_buffer 内存中就可以完成排序,如果要排序的数据大于 sort_buffer_size,则需要外部排序,借助磁盘文件来进行排序。
通过执行一下命令,可以查看 SQL 语句执行中是否采用了磁盘文件辅助排序。
set optimizer_trace = "enabled=on";select name,age,city from user where city = '北京' order by age limit 5;select * from information_schema.optimizer_trace;
可以从number_of_tmp_files中看出,是否使用了临时文件。
{"join_execution": {"select#": 1,"steps": [{"filesort_information": [{"direction": "asc","table": "`user`","field": "age"}],"filesort_priority_queue_optimization": {"limit": 5,"rows_estimate": 992,"row_size": 112,"memory_available": 262144,"chosen": true},"filesort_execution": [],"filesort_summary": {"rows": 3,"examined_rows": 28,"number_of_tmp_files": 0,"sort_buffer_size": 720,"sort_mode": "<sort_key, additional_fields>"}}]}
}
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果 number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件后,当 sort_buffer 内存不足时,先进行排序,将排序后的数据存放到一个小磁盘文件中,清空 sort_buffer。
然后继续存放数据到 sort_buffer,重复以上步骤。最后将多个磁盘小文件合并成一个有序的大文件。
Tips: 磁盘小文件合并排序,使用的是归并排序算法
这样依然会存在问题,数据存放到临时磁盘小文件,然后还需要归并排序为大文件,再读入到内存中,返回结果集,整体排序效率低下。
rowid 排序
要解决上述问题,可以将只需要用于排序的字段和主键 ID 放入 sort_buffer 中,也就是 rowid 排序,这样就可以在 sort_buffer 中完成排序。
max_length_for_sort_data 是一个用于表示 Mysql 用于排序行数据长度的一个参数,如果单行数据的长度超过了这个值,那么可能会导致采用临时文件排序,mysql 会换用 rowid 排序。
可以通过命令看下这个参数取值。
show variables like 'max_length_for_sort_data';

max_length_for_sort_data 默认值是 1024。本文中name,age,city 长度=64+4+64=132<1024, 所以走的是全字段排序。
我们执行以下命令,改下参数值,再重新执行 SQL。
set max_length_for_sort_data = 32;select name,age,city from user where city = '北京' order by age limit 5;
使用 rowid 排序的后,执行示意图如下:

对比全字段排序,rowid 排序最后需要根据主键 ID 获取对应字段数据即多了回表查询。
当需要查询的数据在索引树中不存在的时候,需要再次到聚集索引中去获取,这个过程叫做回表
我们通过执行以下命令,可以看到是否使用了 rowid 排序的:
set optimizer_trace = "enabled=on";select name,age,city from user where city = '北京' order by age limit 5;select * from information_schema.optimizer_trace;
{"join_execution": {"select#": 1,"steps": [{"filesort_information": [{"direction": "asc","table": "`user`","field": "age"}],"filesort_priority_queue_optimization": {"limit": 5,"rows_estimate": 992,"row_size": 8,"memory_available": 262144,"chosen": true},"filesort_execution": [],"filesort_summary": {"rows": 3,"examined_rows": 28,"number_of_tmp_files": 0,"sort_buffer_size": 96,"sort_mode": "<sort_key, rowid>"}}]}
}
sort_mode表示排序模式为 rowid 排序。
order by 的优化思路
重点来了
如何调优呢?两大措施:
-
联合索引优化
如果数据本身是有序的,那就不需要排序,而索引数据本身是有序的,所以,我们可以通过建立联合索引,跳过排序步骤。
-
参数优化
可以通过调整max_length_for_sort_data等参数优化排序算法;
联合索引
基于查询条件和排序条件,给表加个联合索引idx_city_age。然后再查看执行计划:
alter table user add index idx_city_age(city,age);explain select name,age,city from user where city = '北京' order by age limit 5;

从执行计划Extra字段中可以发现没有再使用Using filesort排序,keys使用了idx_city_age索引。
idx_city_age联合索引示意图,如下:

整个 SQL 执行流程图如下所示:

任务线程从idx_city_age索引树中可以有序的获取满足条件的主键 ID, 然后根据主键 ID 查询对应字段数据,不需要在 sort_buffer 中排序了。
从示意图看来,还是有一次回表操作,那可以通过覆盖索引来解决,给city,name,age 组成一个联合索引,省去回表操作。
覆盖索引是 select 的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
参数优化
通过调整参数,也可以优化order by的执行。
- 调整 sort_buffer_size 参数的值。如果 sort_buffer 值太小而数据量大的话,MySQL 会采用磁盘临时文件辅助排序。MySQL 服务器配置高的情况下,可以将参数调大些。
- 调整 max_length_for_sort_data 的值,值太小的话 MySQL 会采用 rowid 排序,会多一次回表操作导致查询性能降低。同样可以适当调大些。
推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》## 推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》
相关文章:
滴滴一面:order by 调优10倍,思路是啥?
背景说明: Mysql调优,是大家日常常见的调优工作。 所以,Mysql调优是一个非常、非常核心的面试知识点。 在40岁老架构师 尼恩的读者交流群(50)中,其相关面试题是一个非常、非常高频的交流话题。 近段时间,有小伙伴面…...

Vue框架学习篇(五)
Vue框架学习篇(五) 1 组件 1.1 组件的基本使用 1.1.1 基本流程 a 引入外部vue组件必须要的js文件 <script src"../js/httpVueLoader.js"></script>b 创建.vue文件 <template><!--公共模板内容--></template><script><!…...
(蓝桥杯 刷题全集)【备战(蓝桥杯)算法竞赛-第1天(基础算法-上 专题)】( 从头开始重新做题,记录备战竞赛路上的每一道题 )距离蓝桥杯还有75天
🏆🏆🏆🏆🏆🏆🏆 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录&a…...
C++——继承那些事儿你真的知道吗?
目录1.继承的概念及定义1.1继承的概念1.2 继承定义1.2.1定义格式1.2.2继承关系和访问限定符1.2.3继承基类成员访问方式的变化2.父类和子类对象赋值转换3.继承中的作用域4.派生类的默认成员函数5.继承与友元6. 继承与静态成员7.复杂的菱形继承及菱形虚拟继承如何解决数据冗余和二…...
leetcode 困难 —— N 皇后(简单递归)
(不知道为啥总是给这种简单的递归设为困难题,虽然优化部分很不错,但是题目太好过了) 题目: 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个…...
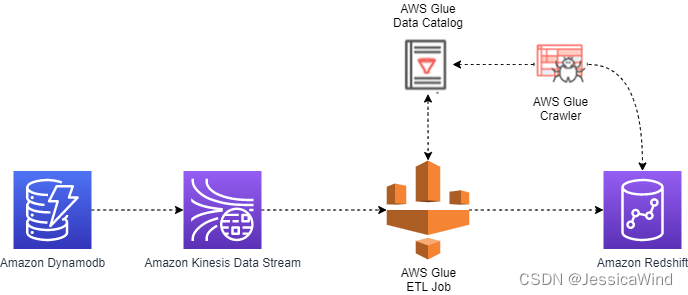
AWS实战:Dynamodb到Redshift数据同步
AWS Dynamodb简介 Amazon DynamoDB 是一种完全托管式、无服务器的 NoSQL 键值数据库,旨在运行任何规模的高性能应用程序。DynamoDB能在任何规模下实现不到10毫秒级的一致响应,并且它的存储空间无限,可在任何规模提供可靠的性能。DynamoDB 提…...
机器学习评估指标的十个常见面试问题
评估指标是用于评估机器学习模型性能的定量指标。它们提供了一种系统和客观的方法来比较不同的模型并衡量它们在解决特定问题方面的成功程度。通过比较不同模型的结果并评估其性能可以对使用哪些模型、如何改进现有模型以及如何优化给定任务的性能做出正确的决定,所…...

常见的安全问题汇总 学习记录
声明 本文是学习2017中国网站安全形势分析报告. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 2017年重大网站安全漏洞 CVE-2017-3248 :WebLogic 远程代码执行 2017年1月27日,WebLogic官方发布了一个编号为CVE-2017-3248 的…...

元宵晚会节目预告没有岳云鹏,是不敢透露还是另有隐情
在刚刚结束的元宵节晚会上,德云社的岳云鹏,再一次参加并引起轰动,并获得了观众朋友们的一致好评。 不过有细心的网友发现,早前央视元宵晚会节目预告,并没有看到小岳岳,难道是不敢提前透露,怕公布…...
计算机视觉 吴恩达 week 10 卷积
文章目录一、边缘检测二、填充 padding1、valid convolution2、same convolution三、卷积步长 strided convolution四、三维卷积五、池化层 pooling六、 为什么要使用卷积神经网络一、边缘检测 可以通过卷积操作来进行 原图像 n✖n 卷积核 f✖f 则输出的图像为 n-f1 二、填充…...

JavaScript 函数定义
JavaScript 函数定义 函数是 JavaScript 中的基本组件之一。一个函数是 JavaScript 过程 — 一组执行任务或计算值的语句。要使用一个函数,你必须将其定义在你希望调用它的作用域内。 一个 JavaScript 函数用function关键字定义,后面跟着函数名和圆括号…...
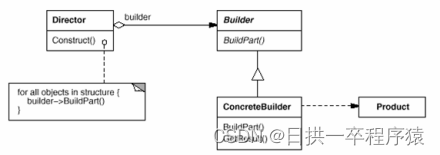
设计模式:建造者模式教你创建复杂对象
一、问题场景 当我们需要创建资源池配置对象的时候,资源池配置类里面有以下成员变量: 如果我们使用new关键字调用构造函数,构造函数参数列表就会太长。 如果我们使用set方法设置字段值,那minIdle<maxIdle<maxTotal的约束逻辑就没地方…...

在C++中将引用转换为指针表示
在C中将引用转换为指针表示 有没有办法在c 中"转换"对指针的引用?在下面的例子,func2已经定义了原型和我不能改变它,但func是我的API,我想为pass两个参数,或一(组和第二组,以NULL)或既不(均设置为NULL): void func2(some1 *p1, some2 *p2); func(some1…...

PS快速入门系列
01-界面构成 1菜单栏 2工具箱 3工县属性栏 4悬浮面板 5画布 ctr1N新建对话框(针对画布进行设置) 打开对话框:ctrl0(字母) 画布三种显示方式切换:F 隐藏工具箱,工具属性栏,悬浮面板…...

ASP.NET CORE 3.1 MVC“指定的网络名不再可用\企图在不存在的网络连接上进行操作”的问题解决过程
ASP.NET CORE 3.1 MVC“指定的网络名不再可用\企图在不存在的网络连接上进行操作”的问题解决过程 我家里的MAC没这个问题。这个是在windows上发生的。 起因很简单我用ASP.NET CORE 3.1 MVC做个项目做登录将数据从VIEW post到Controller上结果意外的报了错误。 各种百度都说…...
JVM从看懂到看开Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

服务器常用的41个状态码及其对应的含义
服务器常用的状态码及其对应的含义如下: 100——客户必须继续发出请求 101——客户要求服务器根据请求转换HTTP协议版本 200——交易成功 201——提示知道新文件的URL 202——接受和处理、但处理未完成 203——返回信息不确定或不完整 204——请求收到&#…...

万里数据库加入龙蜥社区,打造基于“龙蜥+GreatSQL”的开源技术底座
近日,北京万里开源软件有限公司(以下简称“万里数据库”)及 GreatSQL 开源社区签署了 CLA(Contributor License Agreement,贡献者许可协议),正式加入龙蜥社区(OpenAnolis)…...

为什么不推荐使用CSDN?
CSDN粪坑 94%的讲得乱七八糟前言不搭后语互相矛盾的垃圾(还包含直接复制粘贴其他源的内容)3%的纯搬运(偷窃)2%个人日记 (以上99%中还夹杂着很多明明都是盗版资源还要上传卖钱的 ) 1%黄金程序员时间有限&am…...
apisix 初体验
文章目录前言一、参考资料二、安装1.安装依赖2.安装apisix 2.53.apisix dashboard三、小试牛刀3.1 上游(upstream)3.2 路由(route)四、遇到的问题前言 APISIX 是一个微服务API网关,具有高性能、可扩展性等优点。它基于…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...