powerjob的worker启动,研究完了这块代码之后我发现了,代码就是现实中我们码农的真实写照
这是一篇让你受益匪浅的文章,代码即使人生。

worker启动比server启动要复杂一些,毕竟worker是要实际干活的,工欲善其事必先利其器,所以需要准备的工具还是不能少的,server对于powerjob来说,只是一个调度用的,说白了就是管理worker做什么工作的,只需要给他一个流程,让他按照流程上的内容,一次告诉worker去工作,至于怎么做,只有worker知道,server当然不会知道的,也没有必要知道。
worker的启动大概分为以下这么几个步骤:
-
判断是否重复初始化
-
获取默认配置
-
校验appName
-
获取IP地址和端口(这一步和server端是一样的,在这里就不赘述了)
-
初始化定时线程
-
连接server
-
初始化Akka
-
初始化日志系统
-
初始化存储
-
初始化定时任务
步骤是蛮多的,但是其实都不是非常的复杂
由于worker的启动源码过于多了,就不全贴出来了。
开胃菜
首先因为该worker包是需要被依赖的,所以并没有spring的启动类,但是却有启动spring时添加其配置的内容,在worker包里面的PowerJobWorker类,是实现了ApplicationContextAware, InitializingBean, DisposableBean这三个类,这三个类默认有三个方法,分别是
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException
public void afterPropertiesSet() throws Exception
public void destroy() throws Exception
99.9%的初始化工作都是在afterPropertiesSet这个方法里完成的,看名字大概也能猜出这个方法的意思,就是字面意思。
判断是否重复初始化
if (!initialized.compareAndSet(false, true)) {log.warn("[PowerJobWorker] please do not repeat the initialization");return;
}这段代码意思就是一个initialized的变量,代表的意思是是否初始化,一开始的时候是false,因为还没有开始初始化,然后compareAndSet后面跟着两个参数,第一个参数是预期值,如果预期值和当前的变量值一样,则将当前变量更新为第二个参数的值。
如果initialized的值是false ,和预期值一样,则compareAndSet方法返回的是true,跳出if条件语句,并且initialized值变成了true。
如果initialized的·值是true,和预期值不一样,则compareAndSet返回的是false,进入条件语句,打印告警日志,并且不再有后续的初始化操作,此时initialized的值不变,依旧是true。
获取默认配置
PowerJobWorkerConfig config = workerRuntime.getWorkerConfig();//下面这些代码都是在之后的初始化操作中进行赋值的
workerRuntime.setWorkerAddress(workerAddress);workerRuntime.setServerDiscoveryService(serverDiscoveryService);workerRuntime.setActorSystem(actorSystem);workerRuntime.setOmsLogHandler(omsLogHandler);workerRuntime.setTaskPersistenceService(taskPersistenceService);这个WorkerRuntime类是worker.common包里面的一个Bean类,记录了一些worker运行时的参数和环境,里面有的有默认值,有的没有默认值,需要在初始化的时候进行赋值。比如上面代码中,后面set的值
校验appName
我将里面有关打印日志的部分全部拿掉了,通过appName,去server请求appId,如果请求不到,则说明配置文件里面的“powerjob.worker.app-name”配置的有问题,所有appName都是需要注册的,所以名字是不会重复的。
private void assertAppName() {//获取到appNamePowerJobWorkerConfig config = workerRuntime.getWorkerConfig();String appName = config.getAppName();Objects.requireNonNull(appName, "appName can't be empty!");//调用server端的服务String url = "http://%s/server/assert?appName=%s";for (String server : config.getServerAddress()) {
//获取到server的请求地址String realUrl = String.format(url, server, appName);try {
//请求服务,返回结果String resultDTOStr = CommonUtils.executeWithRetry0(() -> HttpUtils.get(realUrl));
//解析返回结果ResultDTO resultDTO = JsonUtils.parseObject(resultDTOStr, ResultDTO.class);if (resultDTO.isSuccess()) {
//将appId设置到运行环境里Long appId = Long.valueOf(resultDTO.getData().toString());workerRuntime.setAppId(appId);return;}else {throw new PowerJobException(resultDTO.getMessage());}}catch (PowerJobException oe) {throw oe;}catch (Exception ignore) {}}throw new PowerJobException("no server available!");
}连接Server

serverDiscoveryService.start(timingPool);
最主要的就是上面这一行代码,这个代码里面主要流程如下:
-
将配置文件里面的服务器地址存入内存。
-
当前服务地址如果不为空,调用server端的/acquire服务获取结果。
-
如果经过第二步没有结果返回,则遍历配置文件中所有的server地址来获取结果。
-
如果依旧没有结果,说明连接不到server,需要将所有的本地任务停止。
-
如果得到结果,则将结果返回。
private String discovery() { //1.将配置文件里面的服务器地址存入内存。if (ip2Address.isEmpty()) {config.getServerAddress().forEach(x -> ip2Address.put(x.split(":")[0], x));}String result = null; //2.当前服务地址如果不为空,调用server端的/acquire服务获取结果。String currentServer = currentServerAddress;if (!StringUtils.isEmpty(currentServer)) {String ip = currentServer.split(":")[0];String firstServerAddress = ip2Address.get(ip);if (firstServerAddress != null) {result = acquire(firstServerAddress);}} //3.如果经过第二步没有结果返回,则遍历配置文件中所有的server地址来获取结果。for (String httpServerAddress : config.getServerAddress()) {if (StringUtils.isEmpty(result)) {result = acquire(httpServerAddress);}else {break;}}if (StringUtils.isEmpty(result)) { //4.如果依旧没有结果,说明连接不到server,需要将所有的本地任务停止。if (FAILED_COUNT++ > MAX_FAILED_COUNT) {List<Long> frequentInstanceIds = TaskTrackerPool.getAllFrequentTaskTrackerKeys();if (!CollectionUtils.isEmpty(frequentInstanceIds)) {frequentInstanceIds.forEach(instanceId -> {TaskTracker taskTracker = TaskTrackerPool.remove(instanceId);taskTracker.destroy();});}FAILED_COUNT = 0;}return null;} else { //5.如果得到结果,则将结果返回。FAILED_COUNT = 0;return result;} }初始化日志系统
OmsLogHandler omsLogHandler = new OmsLogHandler(workerAddress, actorSystem, serverDiscoveryService);
这个日志系统的主要作用,就是将本地的日志上报的server上,从传进的参数就能看出,都是和通讯相关的内容。
这个日志系统的提交也是异步单独占用一个线程,在之前开启的线程中,其中就有一个线程是用来提交日志的,该线程会在worker启动的最后开启,代码段如下:
timingPool.scheduleWithFixedDelay(omsLogHandler.logSubmitter, 0, 5, TimeUnit.SECONDS);
固定每5秒提交一次日志。
初始化存储
worker使用的是本地的H2数据库,持久化的策略分为磁盘和内存,在worker停止的时候,会将本地的数据文件全部销毁。其主要的初始化代码在worker.persistence包里面的ConnectionFactory类中,源代码如下:
-
private final String DISK_JDBC_URL = String.format("jdbc:h2:file:%spowerjob_worker_db;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=false", H2_PATH); private final String MEMORY_JDBC_URL = String.format("jdbc:h2:mem:%spowerjob_worker_db;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=false", H2_PATH);public synchronized void initDatasource(StoreStrategy strategy) {strategy = strategy == null ? StoreStrategy.DISK : strategy;HikariConfig config = new HikariConfig();config.setDriverClassName(Driver.class.getName());config.setJdbcUrl(strategy == StoreStrategy.DISK ? DISK_JDBC_URL : MEMORY_JDBC_URL);config.setAutoCommit(true);// 池中最小空闲连接数量config.setMinimumIdle(2);// 池中最大连接数量config.setMaximumPoolSize(32);dataSource = new HikariDataSource(config);try {FileUtils.forceDeleteOnExit(new File(H2_PATH));}catch (Exception ignore) {} }HikariCP 是一个高性能的 JDBC 连接池组件,HikariConfig 就是其相关的配置类。
总结
-
 worker工作起来确实不是很容易,需要找到自己的上级,还需要记录自己工作的日志,需要一个人干好多任务,还需要再不耽误正常任务的同时,向自己的上级汇报工作,汇报自己的身体状态。简直就是我们底层程序员的真实写照啊。里面使用了很多经典的技术,也有比较新的技术,对于日志系统,做的还是让我学到了很多。
worker工作起来确实不是很容易,需要找到自己的上级,还需要记录自己工作的日志,需要一个人干好多任务,还需要再不耽误正常任务的同时,向自己的上级汇报工作,汇报自己的身体状态。简直就是我们底层程序员的真实写照啊。里面使用了很多经典的技术,也有比较新的技术,对于日志系统,做的还是让我学到了很多。
相关文章:
powerjob的worker启动,研究完了这块代码之后我发现了,代码就是现实中我们码农的真实写照
这是一篇让你受益匪浅的文章,代码即使人生。 worker启动比server启动要复杂一些,毕竟worker是要实际干活的,工欲善其事必先利其器,所以需要准备的工具还是不能少的,server对于powerjob来说,只是一个调度用的…...
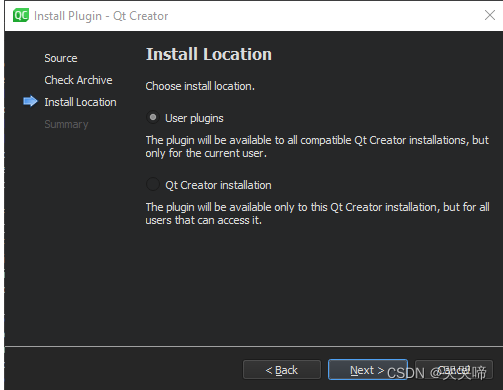
配置Qt Creator
前言 为了使Qt Creator更像您最喜欢的代码编辑器或IDE,您可以更改键盘快捷键、配色方案、通用高亮显示、代码片段和版本控制系统的设置。 检查生成和运行设置 Qt Creator是一个集成开发环境(IDE),可以用来开发Qt应用程序。虽然您可以使用Qt Installer…...
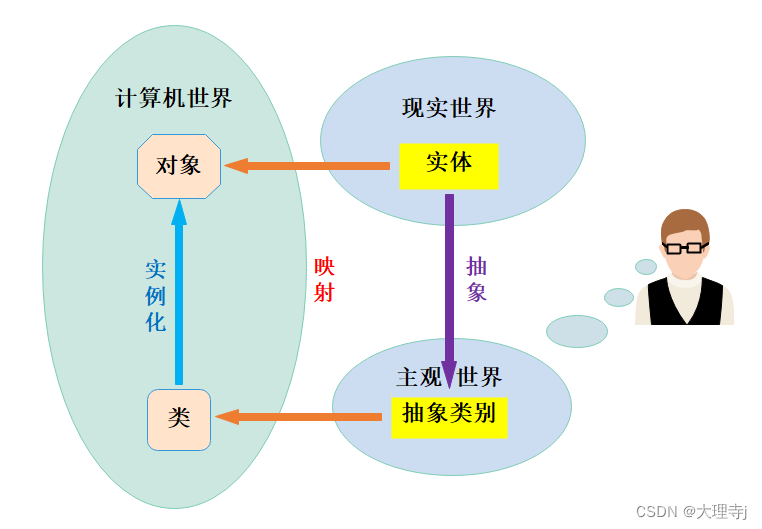
C++-类和对象(下)
C-类和对象(下)一,const成员函数二,再谈构造函数1,初始化列表2,explicit关键字三,static成员四,友元(friend)1,全局函数做友元2,类做友…...

什么是仓库管理?
仓库管理包括仓库日常运营所触及的准绳和流程。从较高的层次上讲,这包括接纳和组织仓库空间、布置劳动力、管理库存和完成订单。放大来看,你会发现有效的仓库管理触及到优化和集成这些过程中的每一个,以确保仓库操作的一切方面协同工作&#…...
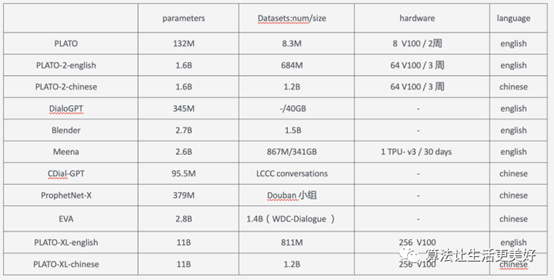
对话系统学习概述(仅够参考)
对话系统(仅够参考) 目录对话系统(仅够参考)背景类人对话系统的关键特征1、知识运用2、个性体现3、情感识别与表达数据集评价方式评价的一些指标训练模型需要的资源任务型对话系统预训练最新研究进展参考文献背景 对话系统一般包括…...

免费CRM客户管理系统真的存在吗?不仅有,还有5个!
免费CRM客户管理系统真的存在吗?当然有! 说到CRM客户管理系统,相信很多企业并不陌生,是因为CRM客户管理系统已经成为大多数企业最不可或缺的工具。但是对于很多小微企业和个人用户来说,购买和实施CRM的成本仍然难以承…...

C#开发的OpenRA使用自定义字典的比较函数
C#开发的OpenRA使用自定义字典的比较函数 字典是一个常用的数据结构, 因为它采用键值对的方式来保存数据, 这样非常方便程序里进行数据一对一的映射。 比如通过文件名称查找到文件对象,又者通过socket对象找到缓冲区对象。 由于字典是采用HASH算法,所以它的查找时间是非常快…...
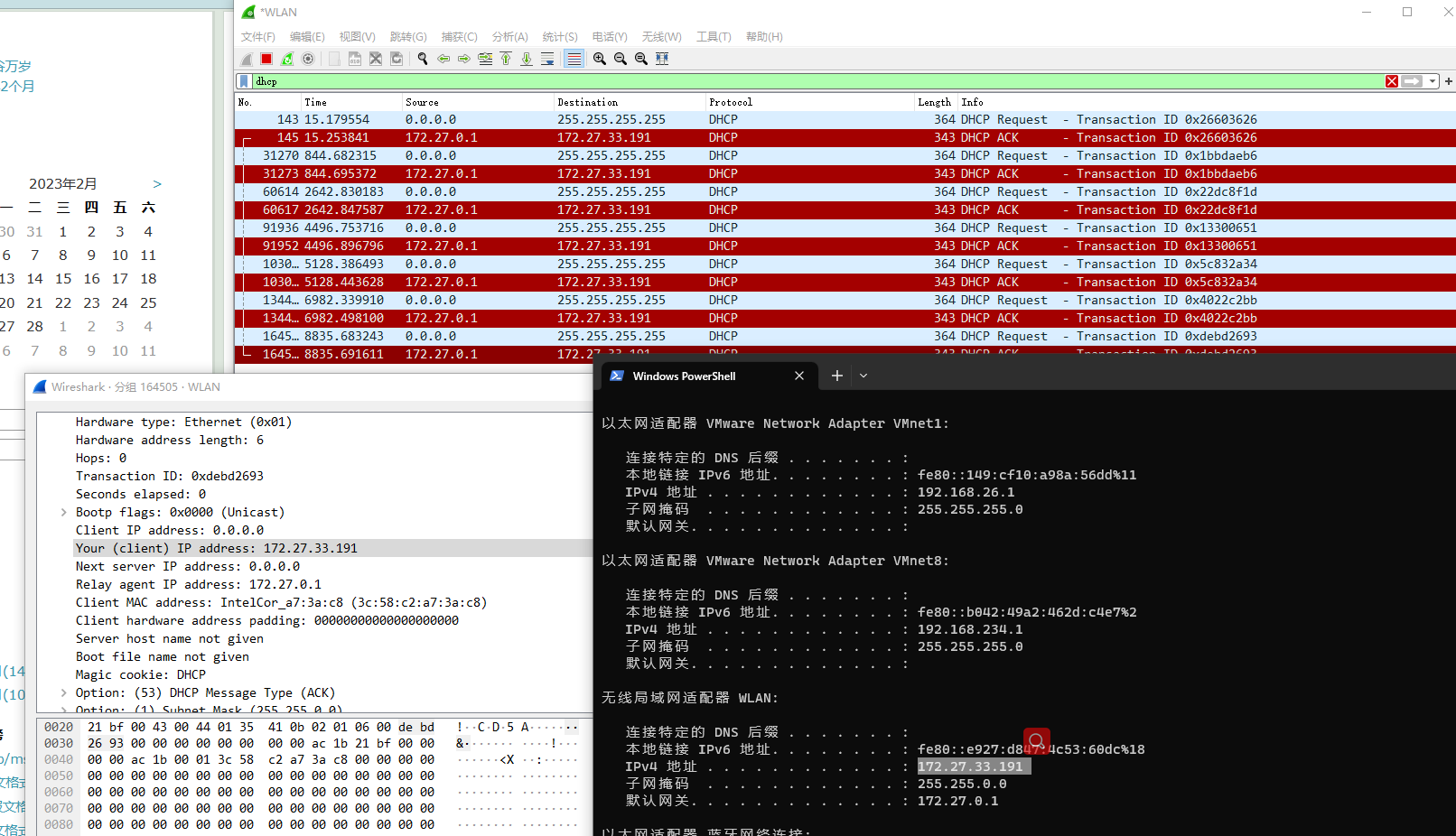
DHCP协议
DHCP协议 文章目录DHCP协议DHCP作用及特点DHCP服务IP分配的三种方式DHCP协议中的报文类型DHCP服务工作流程抓包参考动态主机配置协议 DHCP(Dynamic Host Configuration Protocol),提供了一种 插网即用的技术。DHCP是一个应用层协议。当我们将…...

C语言进阶——自定义类型:枚举、联合
🌇个人主页:_麦麦_ 📚今日名言:如果不去遍历世界,我们就不知道什么是我们精神和情感的寄托,但我们一旦遍历了世界,却发现我们再也无法回到那美好的地方去了。当我们开始寻求,我们就已…...

背景透明(opacity vs background)
最近在做项目的时候,遇到透明度的相关设置。 常用的背景透明设置可分为两种,分别是: 一是给background设置透明度。二是利用opacity属性。 在跳了一些坑之后,本人更推荐给background设置透明度,为什么呢?…...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 最小施肥机能效(Python)| 真题+思路+考点+代码+岗位
最小施肥机能效 题目 某农场主管理了一大片果园,fields[i]表示不同果林的面积,单位:( m 2 m^2 m2),现在要为所有的果林施肥且必须在 n 天之内完成,否则影响收成。 小布是果林的工作人员,他每次选择一片果林进行施肥,且一片果林施肥完...

vue2 使用 cesium 篇
vue2 使用 cesium 篇 今天好好写一篇哈,之前写的半死不活的。首先说明:这篇博文是我边做边写的,小白也是,实现效果会同时发布截图,如果没有实现也会说明,仅仅作为技术积累,选择性分享࿰…...

2023预测:PKI将受到企业重点关注
2023年,PKI作为关键业务将继续被主流企业关注,根据Keyfactor发布的报告显示,很多企业正努力实施PKI,而以下因素是影响企业决策的主要原因:1、66% 的企业正在其IT环境中部署更多的密钥和证书,而70%的企业表示…...

linux基本功系列之grep命令
文章目录前言一. grep命令介绍二. 语法格式及常用选项三. 参考案例3.1 搜索文件中以root开头的文件3.2 搜索文件中出现的root3.3 搜索除了匹配行之外的行3.4 匹配的部分使用颜色显示3.5 只输出文件中匹配到的地方3.6 输出包含匹配字符串的行,并显示所在的行数3.7 统…...

硬件设计——DDR
一、DDR简介 (1)DDRDouble Data Rate双倍速率同步动态随机存储器。严格的说DDR应该叫DDR SDRAM,人们习惯称为DDR,其中,SDRAM 是Synchronous Dynamic Random Access Memory的缩写,即同步动态随机存取存储器。…...

最近你提前还贷了吗
最近你有想过提前还贷吗?以前,欠别人的是大爷,借别人钱的是孙子。现在好像反过来了呀,想还钱成了孙子。现在,各种银行以各种方式增加你提前还贷的难度。比如第一步,关闭app线上还款入口第二步,需…...

关于STM32常用的8种GPIO输入输出模式的理解
目录 GPIO共有8中输入输出模式,分别是:上拉输入、下拉输入、浮空输入、模拟输入、开漏输出、推挽输出、开漏复用输出、推挽复用输出 ,下面我们详细介绍以下上面的八种输入输出模式。 一、输入模式 (1)上拉输入&#x…...
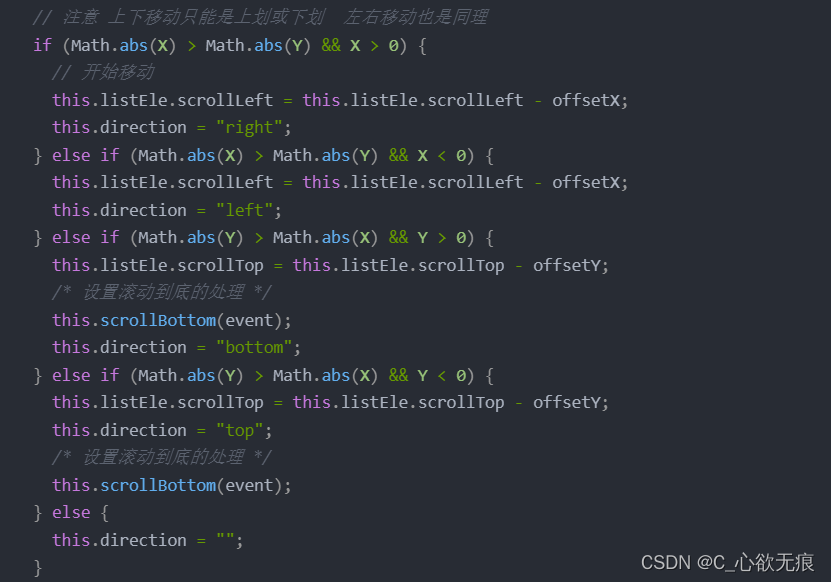
vue - vue项目中解决 IOS + H5 滑动边界橡皮筋弹性效果
问题: 最近遇到一个问题,我们在企业微信中的 H5 项目中需要用到table表格(支持懒加载 上划加载数据)。但是他们在锁头、锁列的情况下,依旧会出现边界橡皮筋效果。就会显示的很奇怪。 什么是ios橡皮筋效果: 我们知道元素…...
webpack(高级)--创建自己的loader 同步loader 异步loader loader参数校验
webpack 创建自己的loader loader是用于对模块的源代码进行转换(处理) 我们使用过很多loader 比如css-loader style-loader babel-loader 我么如果想要自己创建一个loader 首先创建webpack环境 pnpm add webpack webpack-cli -D 之后创建loader模块…...

Assignment写作各个部分怎么衔接完美?
Assignment格式很简单,就只有四个部分,按着通用的套路来,发现也没什么难度。不过这4个部分自己需要衔接完美,下面就给大家分享一下写Assignment最简单的方法。 如果没有目录可以放在第一页的开头,用“标题字体”加重显…...

告别眼部疲劳?Zotero Night护眼工具让文献阅读轻松升级
告别眼部疲劳?Zotero Night护眼工具让文献阅读轻松升级 【免费下载链接】zotero-night Night theme for Zotero UI and PDF 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-night 作为学术研究的得力助手,Zotero帮助无数用户管理海量文献。…...

AI辅助开发实战:基于CosyVoice和LeeZhao的智能代码生成优化
在AI辅助开发的浪潮中,我们这些开发者既兴奋又头疼。兴奋的是,动动嘴皮子或者写几句描述,AI就能帮我们生成代码框架,大大提升了效率。头疼的是,生成的代码常常“驴唇不对马嘴”,要么上下文理解跑偏…...

Magisk Root技术实践指南:从决策评估到风险管控的完整解决方案
Magisk Root技术实践指南:从决策评估到风险管控的完整解决方案 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk 一、决策评估:场景化应用与技术选型 1.1 设备Root需求分析矩阵 在…...

Java开发者晋升指南:集成Phi-3-vision构建AI面试题库与评估系统
Java开发者晋升指南:集成Phi-3-vision构建AI面试题库与评估系统 1. 技术招聘的痛点与AI解决方案 技术面试官每天面临重复性劳动:根据JD设计题目、评估代码、写反馈。传统方式存在三大痛点: 题库更新慢:技术栈迭代快,…...

FLUX小红书V2模型版本对比:V1与V2的核心改进与效果差异
FLUX小红书V2模型版本对比:V1与V2的核心改进与效果差异 1. 引言 如果你最近在玩AI图像生成,特别是想做出那种看起来特别真实、特别有小红书风格的照片,那你肯定听说过FLUX小红书模型。这个模型从V1版本开始就挺火的,主要是因为它…...

想为小说配图?试试圣女司幼幽-造相Z-Turbo,我的真实使用体验
想为小说配图?试试圣女司幼幽-造相Z-Turbo,我的真实使用体验 1. 为什么我需要这个AI绘画工具 作为一名网络小说作者,我经常遇到一个难题:如何在社交媒体上为我的小说章节配上吸引人的插图。找画师定制价格昂贵,自己学…...

为什么每次招人,企业HR和管理者心里都没底?招错人会带来哪些严重后果?
这是众多企业面临的招聘痛点。根据行业数据,企业招错一名员工的平均成本高达该员工年薪的30%-150%,不仅造成直接经济损失,更会导致团队效率下降、管理成本增加、项目延期等一系列连锁反应。许多企业陷入"招聘-试用-不合适-再招聘"的…...

Qwen3.5-4B-Claude-Opus入门必看:双RTX4090D GPU加速部署详解
Qwen3.5-4B-Claude-Opus入门必看:双RTX4090D GPU加速部署详解 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B的推理蒸馏模型,专门针对结构化分析、分步骤回答以及代码与逻辑类问题进行了优化。该版本采用GGUF量化…...

告别配对烦恼:用Auracast蓝牙广播,让手机、耳机和电视实现一拖多音频共享
告别配对烦恼:Auracast蓝牙广播重塑多设备音频共享体验 清晨七点的健身房,二十位健身爱好者同时戴上耳机,电视里的晨间新闻通过Auracast技术瞬间传入每个人的耳中;家庭影院里,父亲用电视播放电影,母亲通过降…...

《Essential Macleod中文手册》实战指南:从入门到精通的光学薄膜设计
1. 光学薄膜设计入门:为什么选择Essential Macleod? 第一次接触光学薄膜设计时,我和大多数人一样感到无从下手。市面上有那么多仿真软件,为什么专业工程师都推荐Essential Macleod?简单来说,它就像光学薄膜…...