反爬虫技术
预计更新
一、 爬虫技术概述
1.1 什么是爬虫技术
1.2 爬虫技术的应用领域
1.3 爬虫技术的工作原理
二、 网络协议和HTTP协议
2.1 网络协议概述
2.2 HTTP协议介绍
2.3 HTTP请求和响应
三、 Python基础
3.1 Python语言概述
3.2 Python的基本数据类型
3.3 Python的流程控制语句
3.4 Python的函数和模块
3.5 Python的面向对象编程
四、 爬虫工具介绍
4.1 Requests库
4.2 BeautifulSoup库
4.3 Scrapy框架
五、 数据存储和处理
5.1 数据存储格式介绍
5.2 数据库介绍
5.3 数据处理和分析
六、 动态网页爬取
6.1 动态网页概述
6.2 Selenium工具介绍
6.3 PhantomJS工具介绍
七、 反爬虫技术
7.1 反爬虫技术概述
7.2 User-Agent伪装
7.3 IP代理池
八、 数据清洗和预处理
8.1 数据清洗和去重
8.2 数据预处理和分析
九、 分布式爬虫和高并发
9.1 分布式爬虫概述
9.2 分布式爬虫框架介绍
9.3 高并发爬虫实现
十、 爬虫实战
10.1 爬取豆瓣电影排行榜
10.2 爬取天气数据
10.3 爬取新闻网站数据
七、 反爬虫技术
7.1 反爬虫技术概述
7.2 User-Agent伪装
7.3 IP代理池
反爬虫技术概述
一、前言
随着互联网的普及,网络爬虫技术越来越受到广泛关注和应用。然而,网络爬虫的过度使用也给网站带来了一定的负担和风险,为了保护网站的安全和稳定,很多网站采取了反爬虫技术,阻止网络爬虫对网站的访问和抓取。本文将介绍常见的反爬虫技术,并详细介绍其原理和应对方法。
二、常见的反爬虫技术
- IP限制
IP限制是最基本的反爬虫技术之一,通过检查访问请求的IP地址,判断是否是爬虫,如果是,则禁止其访问。IP限制的实现方式包括黑名单和白名单,黑名单是指禁止特定的IP地址访问,白名单是指只允许特定的IP地址访问。
应对方法:
-
使用代理IP:使用代理IP可以绕过IP限制,但需要注意代理IP的质量和稳定性,否则会影响抓取效果。
-
分布式抓取:使用多个IP地址进行分布式抓取,避免单个IP被限制。
-
更换IP地址:在被限制之后,更换IP地址重新进行抓取。
- User-Agent识别
User-Agent是HTTP请求头中的一个字段,用于标识客户端的类型和版本信息。很多网站通过User-Agent识别来判断访问请求是否来自于爬虫。
应对方法:
-
修改User-Agent:使用不同的User-Agent,欺骗网站判断,使其认为是正常的浏览器请求。
-
使用随机的User-Agent:使用随机生成的User-Agent,避免被网站识别出来。
- 验证码
验证码是一种防止机器人程序的技术,通过让用户输入验证码来表明其是人类而不是机器人。验证码的实现方式包括图片验证码、语音验证码、滑动验证码等。
应对方法:
-
识别验证码:使用OCR技术或者机器学习算法来自动识别验证码。
-
手动输入验证码:需要人工输入验证码来通过验证。
- Referer识别
Referer是HTTP请求头中的一个字段,用于标识请求来源页面的URL地址。有些网站会检查Referer字段,如果不是从合法的页面跳转过来,则认为是爬虫。
应对方法:
-
修改Referer:使用正确的Referer,使网站认为是正常的请求。
-
不使用Referer:在请求头中不包含Referer字段。
- 动态数据加载
很多网站使用JavaScript等技术动态加载数据,使得抓取工具无法获取完整的数据。动态数据加载的实现方式包括AJAX、JSON等。
应对方法:
-
使用Selenium等工具:使用Selenium等工具来模拟浏览器操作,获取动态加载的数据。
-
分析API接口:分析网站的API接口,直接获取数据。
- 频率限制
频率限制是指限制访问请求的频率,防止爬虫过度访问网站。频率限制的实现方式包括IP限制、账号限制、访问时间限制等。
应对方法:
-
降低抓取频率:降低抓取频率,减少对网站的访问压力。
-
使用多个账号:使用多个账号进行抓取,避免单个账号被限制。
- 页面内容加密
页面内容加密是指对网页内容进行加密处理,使得爬虫无法直接获取内容。页面内容加密的实现方式包括JavaScript加密、AES加密等。
应对方法:
-
破解加密算法:分析网页的加密算法,破解加密算法获取内容。
-
模拟浏览器行为:使用模拟浏览器行为的工具,获取解密后的内容。
- 混淆技术
混淆技术是指对网页代码进行混淆处理,使得爬虫无法直接解析网页代码。混淆技术的实现方式包括代码压缩、代码加密、代码打乱等。
应对方法:
-
解析混淆代码:使用工具解析混淆代码,获取可读性强的代码。
-
手动分析代码:手动分析混淆代码,还原出原始代码。
三、绕过反爬虫技术的原则
在应对反爬虫技术时,需要遵循以下原则:
-
尊重网站的规则和协议:不要使用反爬虫技术去违反网站的规则和协议,尊重网站的知识产权和合法权益。
-
遵循抓取规则:遵循网站的抓取规则,不要过度抓取和频繁访问。
-
分析网站的反爬虫技术:分析网站的反爬虫技术,选择合适的应对方法。
-
不断更新和学习:不断更新和学习反爬虫技术,提高应对能力和技术水平。
四、总结
反爬虫技术是网站保护安全和稳定的重要手段,但也给数据采集带来了一定的挑战。在应对反爬虫技术时,需要遵循原则,选择合适的应对方法,提高技术水平和应对能力。同时,也需要注意法律法规和道德规范,遵循网站的规则和协议,保护网站的知识产权和合法权益。
User-Agent伪装
一、前言
User-Agent是HTTP请求头中的一个字段,用于标识客户端的类型和版本信息。很多网站通过User-Agent识别来判断访问请求是否来自于爬虫。因此,User-Agent伪装是常见的反爬虫技术,本文将详细介绍User-Agent伪装的原理和应对方法。
二、User-Agent的原理
User-Agent是HTTP请求头中的一个字段,用于标识客户端的类型和版本信息。User-Agent的格式通常为“产品名称/产品版本号+操作系统名称/操作系统版本号”,例如“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36”。
网站通过检查User-Agent字段来判断访问请求是否来自于爬虫,如果User-Agent中包含爬虫相关的关键词,或者User-Agent与常见的浏览器不一致,就会被认为是爬虫。因此,User-Agent伪装是常见的反爬虫技术。
三、User-Agent伪装的方法
- 修改User-Agent字段
最直接的方法就是修改User-Agent字段,将其设置为常见的浏览器的User-Agent。这样,网站就无法通过User-Agent判断访问请求是否来自于爬虫。
Python中可以使用requests库来发送HTTP请求,并通过headers参数来设置HTTP请求头中的User-Agent字段。例如:
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}response = requests.get('http://www.example.com', headers=headers)
- 随机生成User-Agent字段
为了更好地伪装User-Agent,可以使用随机生成User-Agent的方法。Python中可以使用fake_useragent库来随机生成User-Agent。例如:
from fake_useragent import UserAgent
import requestsua = UserAgent()
headers = {'User-Agent': ua.random}response = requests.get('http://www.example.com', headers=headers)
这样每次发送请求时都会随机生成一个不同的User-Agent,增加了反爬虫的难度。
- 使用浏览器插件或工具
可以使用浏览器插件或工具来模拟浏览器发起请求,从而伪装User-Agent。例如,可以使用Chrome浏览器的User-Agent Switcher插件来切换User-Agent,或者使用Selenium工具来模拟浏览器行为,并设置浏览器的User-Agent。例如:
from selenium import webdriveroptions = webdriver.ChromeOptions()
options.add_argument('--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"')driver = webdriver.Chrome(options=options)
driver.get('http://www.example.com')
这样就可以使用Chrome浏览器的User-Agent来访问网站了。
- 使用代理服务器
使用代理服务器可以隐藏爬虫的真实IP地址和User-Agent,从而绕过反爬虫的限制。代理服务器会将请求转发给目标网站,目标网站只能看到代理服务器的IP地址和User-Agent,无法识别出请求的真实来源。
Python中可以使用requests库来设置代理服务器。例如:
import requestsproxies = {'http': 'http://127.0.0.1:8888', 'https': 'https://127.0.0.1:8888'}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}response = requests.get('http://www.example.com', proxies=proxies, headers=headers)
这样将会通过代理服务器发起请求,并使用指定的User-Agent伪装,从而避免被网站识别为爬虫。
- 使用HTTP代理池
使用HTTP代理池可以动态获取可用的代理服务器列表,并自动切换代理服务器,从而避免被网站封禁IP地址。Python中可以使用requests库结合requests-ProxyPool库来实现HTTP代理池。例如:
import requests
from requests.exceptions import ProxyError
from requests.packages.urllib3.exceptions import MaxRetryError
from requests.packages.urllib3.exceptions import NewConnectionError
from requests.packages.urllib3.exceptions import ConnectTimeoutError
from requests.packages.urllib3.exceptions import ReadTimeoutError
from requests.packages.urllib3.exceptions import SSLError
from proxypool import ProxyPoolpool = ProxyPool()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}while True:try:proxy = pool.get_proxy()response = requests.get('http://www.example.com', proxies={'http': 'http://' + proxy, 'https': 'https://' + proxy}, headers=headers)print(response.text)except (ProxyError, MaxRetryError, NewConnectionError, ConnectTimeoutError, ReadTimeoutError, SSLError):pool.remove_proxy(proxy)
这样就可以使用HTTP代理池来动态获取可用的代理服务器,并自动切换代理服务器,从而避免被网站封禁IP地址和User-Agent。
四、应对User-Agent伪装的方法
网站可以通过以下方法来应对User-Agent伪装:
- 限制User-Agent
网站可以限制User-Agent,只允许常见的浏览器的User-Agent,或者只允许特定的User-Agent。这样就可以防止使用非法的User-Agent来访问网站。
- 检测User-Agent的格式和内容
网站可以检测User-Agent的格式和内容,判断是否与常见的浏览器的User-Agent一致,或者是否包含爬虫相关的关键词。如果检测到异常的User-Agent,就可以判定为爬虫并进行反爬虫处理。
- 使用Cookie和Session
网站可以使用Cookie和Session来识别请求的来源,从而防止使用不同的User-Agent来伪装访问请求。使用Cookie和Session可以将访问请求绑定到特定的用户或会话,从而防止爬虫绕过User-Agent的限制。
- 使用验证码
网站可以使用验证码来识别访问请求是否来自于人类用户,从而防止爬虫绕过User-Agent和Cookie的限制。使用验证码可以增加反爬虫的难度,但也会增加人类用户的访问成本。
总之,User-Agent伪装是常见的反爬虫技术之一,可以通过修改User-Agent字段、随机生成User-Agent、使用浏览器插件或工具、使用代理服务器和HTTP代理池等方法来绕过反爬虫限制。网站可以通过限制User-Agent、检测User-Agent的格式和内容、使用Cookie和Session和使用验证码等方法来应对User-Agent伪装。
IP代理池
一、前言
随着互联网技术的不断发展,爬虫技术也越来越成熟。对于一些网站来说,爬虫的存在可能会给其带来很大的损失,因此,网站会采取一些技术手段来防御爬虫。其中,IP代理池是一种常用的反爬虫技术,本文将详细介绍IP代理池的原理和应对方法。
二、IP代理池的原理
IP代理池是一种通过动态获取可用的代理服务器列表,并自动切换代理服务器来避免被网站封禁IP地址的反爬虫技术。在使用IP代理池时,爬虫并不是直接从自己的IP地址向目标网站发起请求,而是通过代理服务器转发请求,代理服务器会将请求转发给目标网站,目标网站只能看到代理服务器的IP地址,无法识别出请求的真实来源。
IP代理池的核心就是代理服务器,代理服务器可以分为以下几类:
- HTTP代理服务器
HTTP代理服务器主要用于HTTP协议的代理,它可以代理HTTP请求和响应,但不能代理其他协议的请求和响应。
- HTTPS代理服务器
HTTPS代理服务器主要用于HTTPS协议的代理,它可以代理HTTPS请求和响应,但需要注意的是,HTTPS代理服务器必须支持SSL/TLS协议,并且需要提供有效的证书,否则无法正常代理HTTPS请求和响应。
- SOCKS代理服务器
SOCKS代理服务器可以代理所有协议的请求和响应,包括HTTP、HTTPS、FTP等。与HTTP代理服务器和HTTPS代理服务器不同,SOCKS代理服务器支持TCP和UDP协议,并且能够与远程主机建立直接连接,不需要经过代理服务器。
在使用IP代理池时,需要通过一些手段来动态获取可用的代理服务器列表,并自动切换代理服务器。常用的方法包括:
- 免费代理网站
免费代理网站是最常用的获取代理服务器列表的方法之一。通过爬取免费代理网站上的代理服务器列表,可以获取大量的代理服务器,但是需要注意的是,免费代理服务器的质量和稳定性通常比较差,容易出现连接超时、访问速度慢等问题,甚至可能会被网站识别为爬虫并进行反爬虫处理。
- 付费代理服务商
付费代理服务商通常提供质量比较好的代理服务器,可以保证代理服务器的稳定性和速度。通过购买付费代理服务,可以获取可靠的代理服务器列表,并获得更好的服务质量和客户支持。
- 自建代理服务器
自建代理服务器可以确保代理服务器的质量和稳定性,但需要投入一定的成本和精力来维护和管理代理服务器。自建代理服务器可以使用开源的代理软件,如Squid、Shadowsocks等。
- 公共代理API
一些代理服务商提供公共的代理API,可以通过API接口获取可用的代理服务器列表,并自动切换代理服务器。使用公共代理API可以避免手动获取代理服务器列表的麻烦,并且可以获得更好的服务质量和客户支持。
三、如何使用IP代理池
使用IP代理池可以避免被网站封禁IP地址,提高爬取效率和成功率。在使用IP代理池时,需要注意以下几个问题:
- 如何获取可用的代理服务器列表?
获取可用的代理服务器列表可以通过以上提到的方法,包括免费代理网站、付费代理服务商、自建代理服务器和公共代理API等。需要注意的是,获取代理服务器列表的质量和稳定性对于IP代理池的使用效果有很大的影响,建议选择可靠的代理服务商或自建代理服务器。
- 如何验证代理服务器的可用性?
获取代理服务器列表后,需要验证代理服务器的可用性,通常使用的方式是发送HTTP请求并检查响应状态码。常见的响应状态码包括200、404、500等,其中200表示请求成功,404表示请求的资源不存在,500表示服务器内部错误。如果代理服务器无法正常响应或响应状态码不符合要求,需要将其从可用代理服务器列表中移除。
- 如何实现代理服务器的自动切换?
代理服务器的自动切换可以通过设置代理池的大小和代理服务器的使用次数来实现。代理池的大小可以根据实际情况进行调整,一般建议保持在100个左右。代理服务器的使用次数可以根据代理服务器的稳定性和速度进行调整,一般建议不超过10次。当某个代理服务器的使用次数达到上限或无法正常响应时,需要将其从可用代理服务器列表中移除,并从代理池中选择另一个可用的代理服务器。
- 如何防止代理服务器被封禁?
为了避免代理服务器被网站封禁,需要注意以下几点:
- 使用高质量、稳定的代理服务器,并定期验证和更新代理服务器列表;
- 设置代理池的大小和代理服务器的使用次数,避免过度使用某个代理服务器;
- 避免在短时间内频繁访问同一个网站,可以设置访问间隔或使用多个代理服务器轮流访问;
- 避免使用代理服务器爬取敏感信息或进行非法活动,以免引起网站的注意并被封禁。
- 如何处理代理服务器的异常情况?
在使用代理服务器时,可能会遇到一些异常情况,比如代理服务器无法连接、响应时间过长、返回错误的响应等。针对这些异常情况,可以采取以下措施:
- 尝试重新连接代理服务器,如果多次尝试仍无法连接,需要将其从可用代理服务器列表中移除;
- 设置超时时间,避免因代理服务器响应时间过长导致程序卡顿或超时;
- 对返回错误响应的代理服务器进行标记或移除,并通过日志记录异常情况,以便后续分析和处理。
- 如何处理代理服务器的速度问题?
代理服务器的速度对于爬虫的效率和稳定性有很大的影响。为了提高代理服务器的速度,可以采取以下措施:
- 选择速度较快的代理服务器,建议选择距离本地较近的代理服务器;
- 设置超时时间,避免因代理服务器响应时间过长导致程序卡顿或超时;
- 对代理服务器的响应时间进行监控和统计,并定期更新代理服务器列表。
- 如何处理代理服务器的安全问题?
代理服务器存在一定的安全风险,可能会被黑客攻击、被滥用进行非法活动等。为了保障代理服务器的安全性,需要注意以下几点:
- 选择可靠的代理服务商或自建代理服务器,并对其进行安全配置和加固;
- 避免在代理服务器上存储敏感信息,比如密码、账号等;
- 定期更新代理服务器列表,避免使用已被黑客攻击或滥用的代理服务器;
- 监控代理服务器的使用情况,发现异常情况及时处理。
总之,IP代理池是爬虫中常用的一种技术手段,可以提高爬虫的稳定性和效率。在使用IP代理池时,需要注意代理服务器的质量、稳定性、速度和安全性,以及代理服务器的验证、自动切换和异常情况处理等问题。
相关文章:

反爬虫技术
预计更新 一、 爬虫技术概述 1.1 什么是爬虫技术 1.2 爬虫技术的应用领域 1.3 爬虫技术的工作原理 二、 网络协议和HTTP协议 2.1 网络协议概述 2.2 HTTP协议介绍 2.3 HTTP请求和响应 三、 Python基础 3.1 Python语言概述 3.2 Python的基本数据类型 3.3 Python的流程控制语句 …...
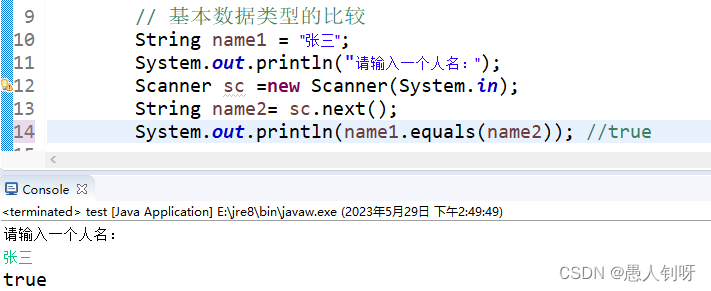
JAVA中.equals()与 ==的区别
1. “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。 2..equals() equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重写之后比…...

华为OD机试之羊、狼、农夫过河(Java源码)
羊、狼、农夫过河 题目描述 羊、狼、农夫都在岸边,当羊的数量小于狼的数量时,狼会攻击羊,农夫则会损失羊。农夫有一艘容量固定的船,能够承载固定数量的动物。 要求求出不损失羊情况下将全部羊和狼运到对岸需要的最小次数。只计算…...

C++ string的简单应用
C语言的字符串 C的字符串 头文件: #include<string.h> //c #include<string> //C #include<cstring> //C 比较string的大小 两个string对象相加 使用字符串对象来存放字符串 两个string对象相加 string str "Hello,"; st…...

Java中的阻塞队列
阻塞队列的基本概念 1、生产者、消费者的概念 他俩是设计模式的一种,提出这两种概念,通过一个容器的方式能解决强耦合问题 生产者、消费者之间不会直接通讯。通过一个第三方容器、队列的方式进行通讯 生产者生产完数据放入容器之后,不用等待消…...

PriorityBlockingQueue无界阻塞优先级队列
PriorityBlockingQueue无界阻塞优先级队列 PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实 现,研究过数组方式存放最小堆节点的都知道,直接遍历队列元素是无序的。 如图 P…...

「HTML和CSS入门指南」p 标签详解
<p> 标签是什么? HTML5 中的 <p> 标签是用于定义段落的标签。它可以用来标记文章、新闻等长篇内容中的段落,并且可以与其他 HTML 元素配合使用。 <p> 标签的语法和属性 <p> 标签的语法非常简单,只需要在 HTML 文件中插入 <p> 和 </p>…...
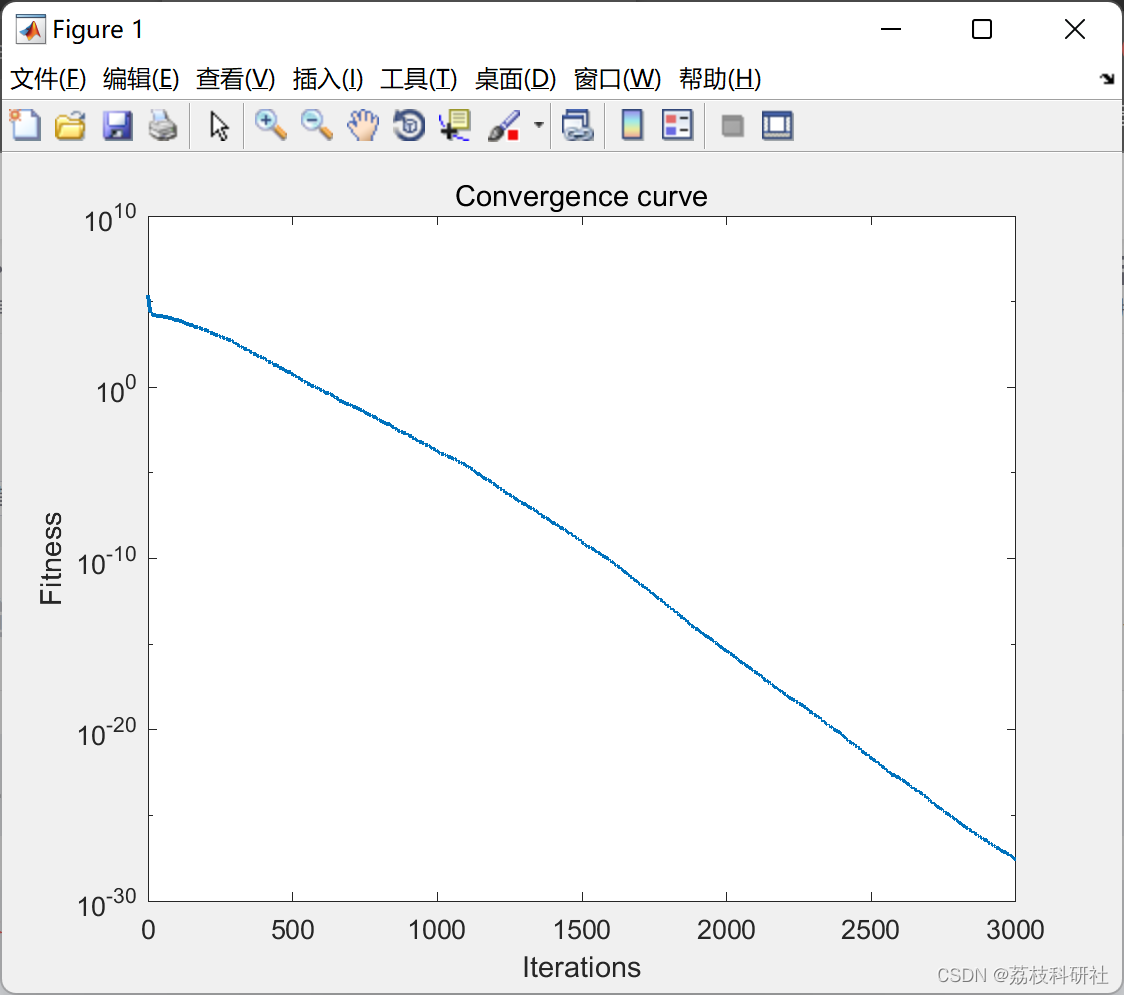
【单目标优化算法】孔雀优化算法(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

chatgpt赋能python:Python同一行多个语句:如何提高你的编程效率?
Python同一行多个语句:如何提高你的编程效率? Python是一种优雅的编程语言,拥有简洁易懂的语法,可以帮助你快速编写可以在各种领域使用的高级代码。其中,Python同一行多个语句,是一种可以大大提高编程效率…...
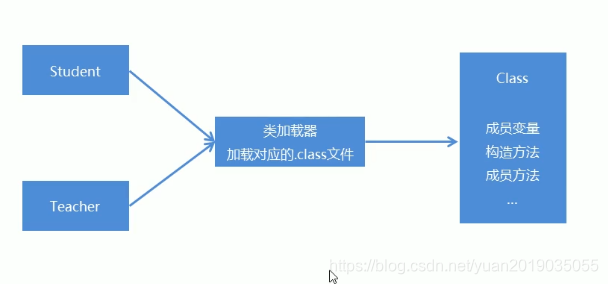
Java反射概述
2 反射 2.1 反射概述 Java反射机制:是指在运行时去获取一个类的变量和方法信息。然后通过获取到的信息来创建对象,调用方法的一种机制。由于这种动态性,可以极大的增强程序的灵活性,程序不用在编译期就完成确定,在运行期仍然可以扩展2.2 反射获取Class类的对象 我们要想通过反…...
)
《网络是怎样连接的》(一)
第一章web浏览器 简介 首先输入网址URL,浏览器进行解析,将我们需要哪些数据告诉服务器。浏览器向服务器发送消息,必须告诉操作系统的接收方的IP地址,所以浏览器先查出web服务器的IP地址,向DNS服务器查询域名对应的IP…...

Flink on yarn任务日志怎么看
1、jobmanager日志 在yarn上可以直接看 2、taskmanager日志 在flink的webui中可以看,但是flink任务失败后,webui就不存在了,那怎么看? 这是jobmanager的地址 hadoop02:19888/jobhistory/logs/hadoop02:45454/container_e03_16844…...
二次元的登录界面
今天还是继续坚持写博客,然后今天给大家带来比较具有二次元风格的登录界面,也只是用html和css来写的,大家可以来看看! 个人名片: 😊作者简介:一名大一在校生,web前端开发专业 &…...
2. 量化多因子数据清洗——去极值、标准化、正交化、中性化
一、去极值 1. MAD MAD(mean absolute deviation)又称为绝对值差中位数法,是一种先需计算所有因子与平均值之间的距离总和来检测离群值的方法. def extreme_MAD(rawdata, n): median rawdata.quantile(0.5) # 找出中位数 new_median (abs(…...

皮卡丘反射型XSS
1.反射型xss(get) 进入反射型xss(get)的关卡,我们可以看到如下页面 先输入合法数据查看情况,例如输入“kobe” 再随便输入一个,比如我舍友的外号“xunlei”,“666”,嘿嘿嘿 F12查看源代码,发现你输入的数…...
巧计口诀-软件测试的生命周期,黑盒测试设计方法
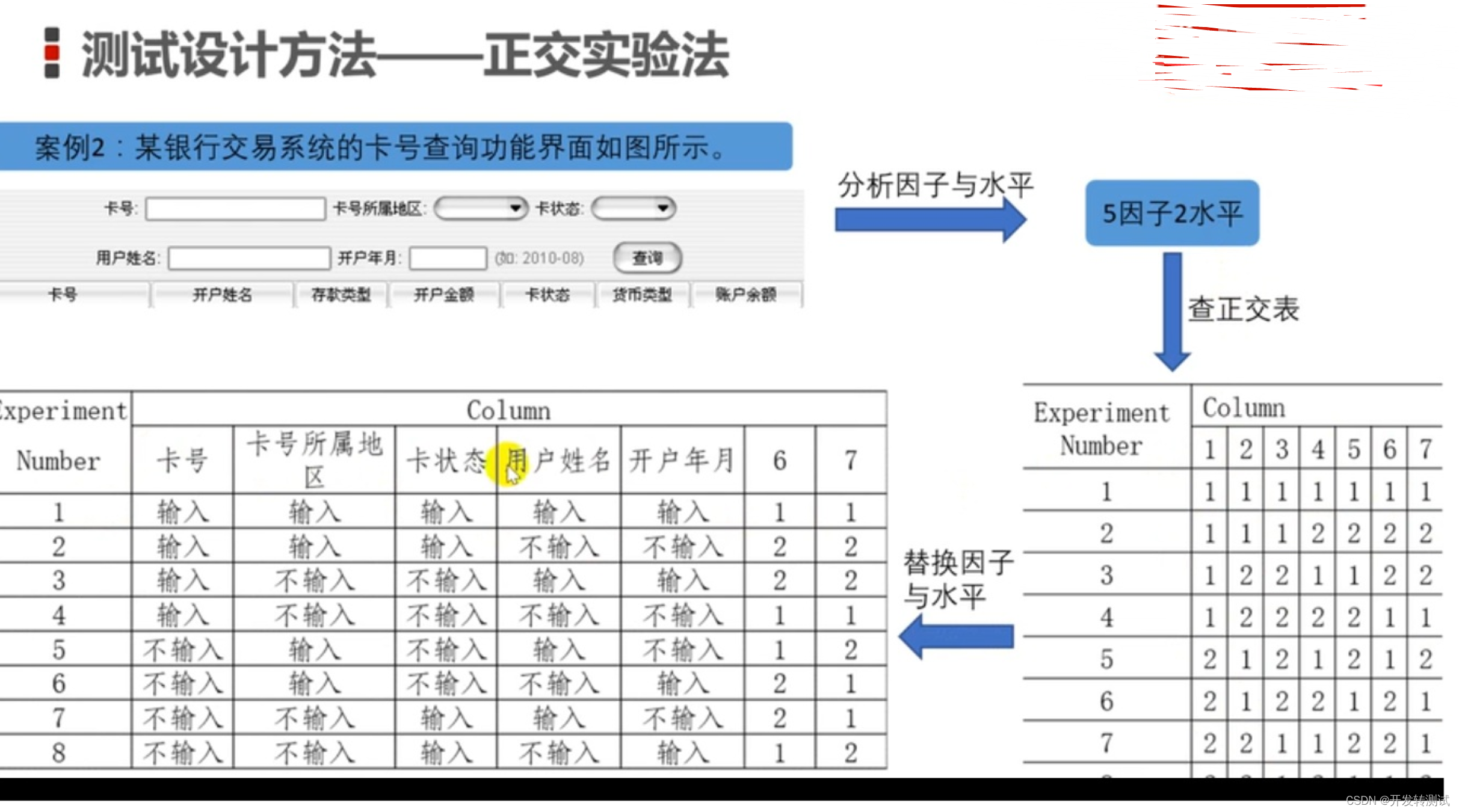
目录 1。口诀 2。黑盒设计方法适用场合 3。黑盒设计方法详解 3.1。等价类法 3.2。 边界值法 3.3。判定表法 3.4。因果表 3.5。状态迁移图 3.6。场景法 3.7。正交实验法 3.8。错误推断法 1。口诀 又到了找工作的日子,背诵这些基本知识和概念又开始了。我找…...
- Ashmem驱动)
Android系统的Ashmem匿名共享内存系统分析(1)- Ashmem驱动
声明 其实对于Android系统的Ashmem匿名共享内存系统早就有分析的想法,记得2019年6、7月份Mr.Deng离职期间约定一起对其进行研究的,但因为我个人问题没能实施这个计划,留下些许遗憾…文中参考了很多书籍及博客内容,可能涉及的比较…...

Redis 事务详细介绍
事务 注意:Redis单条命令是保证原子性的;但是事务不保证原子性! Redis事务没有隔离级别的概念,所有的命令在事务中,并没有直接被执行,只有发起执行命令时才执行 Redis事务本质:一组命令的集合&…...

2023-5-29第二十九天
consult咨询,查阅,商讨 specialize专门从事,专攻 inspect检查 pattern图案,方式 optimize使最优化 ensemble整体,全体 subscript下标 subscribe签名 sector行业,部门 precedence优先,优…...
【第三方库】PHP实现创建PDF文件和编辑PDF文件
目录 引入Setasign/fpdf、Setasign/fpdi 解决写入中文时乱码问题 1.下载并放置中文语言包(他人封装):https://github.com/DCgithub21/cd_FPDF 2.编写并运行生成字体文件的程序文件(addFont.php) 中文字体举例&…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
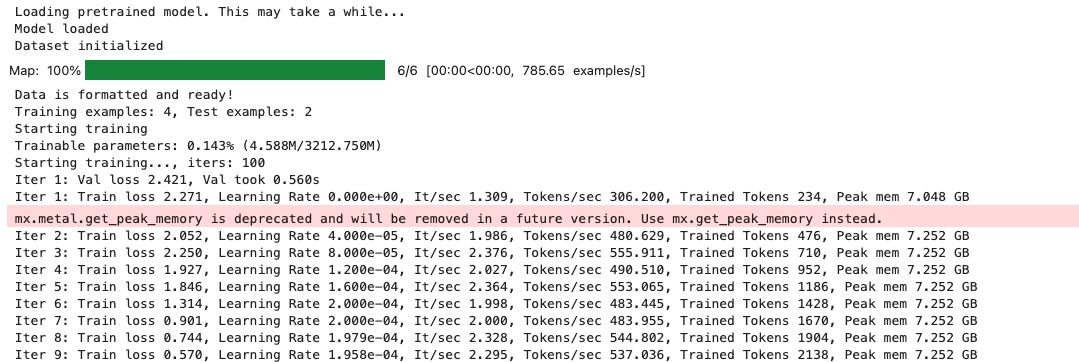
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...
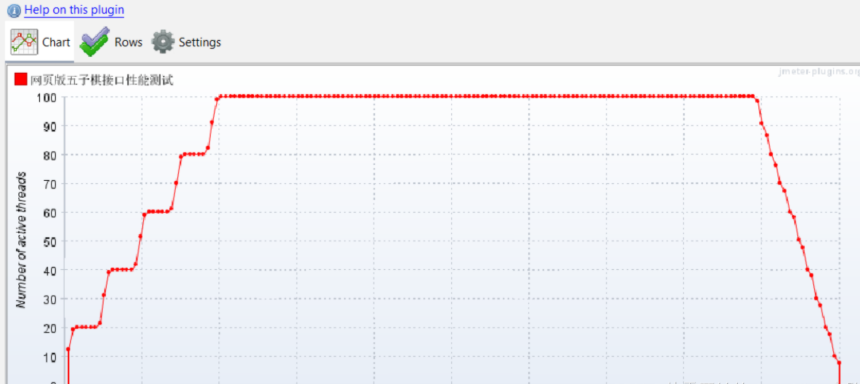
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
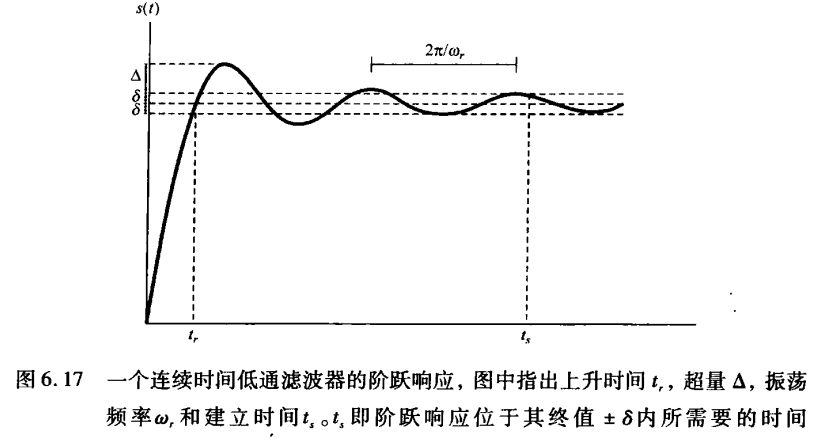
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...
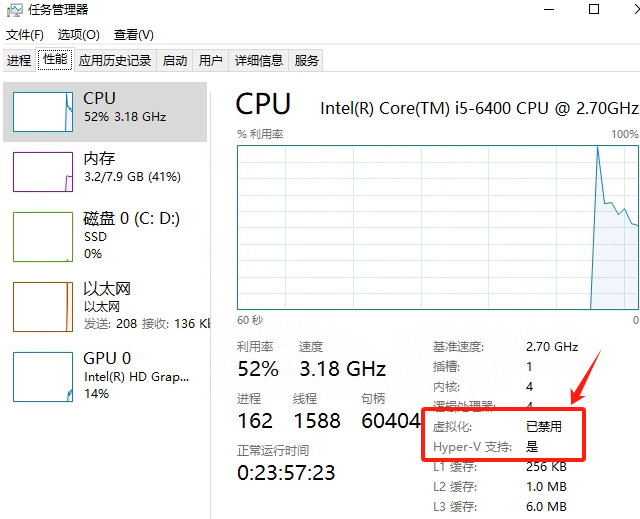
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...

Vue3 PC端 UI组件库我更推荐Naive UI
一、Vue3生态现状与UI库选择的重要性 随着Vue3的稳定发布和Composition API的广泛采用,前端开发者面临着UI组件库的重新选择。一个好的UI库不仅能提升开发效率,还能确保项目的长期可维护性。本文将对比三大主流Vue3 UI库(Naive UI、Element …...

Cursor AI 账号纯净度维护与高效注册指南
Cursor AI 账号纯净度维护与高效注册指南:解决限制问题的实战方案 风车无限免费邮箱系统网页端使用说明|快速获取邮箱|cursor|windsurf|augment 问题背景 在成功解决 Cursor 环境配置问题后,许多开发者仍面临账号纯净度不足导致的限制问题。无论使用 16…...