JVM学习笔记(上)
1、总体路线
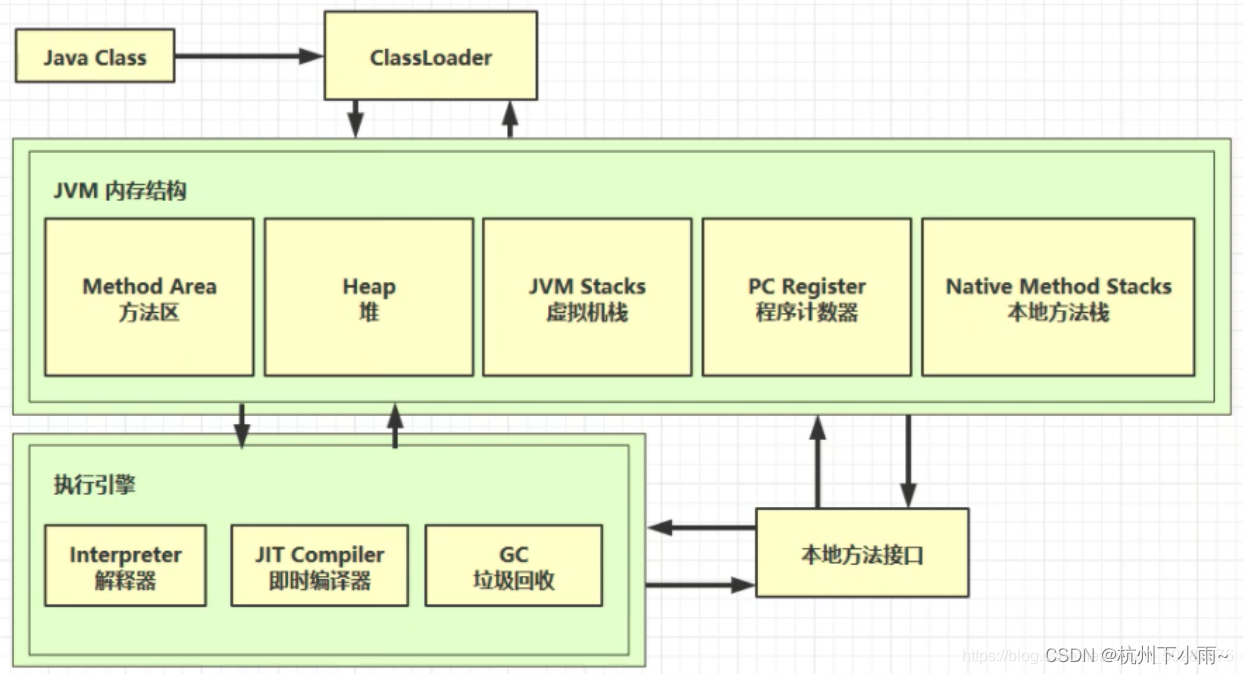
2、程序计数器
Program Counter Register 程序计数器(寄存器)
作用:是记录下一条 jvm 指令的执行地址行号。
特点:
- 是线程私有的
- 不会存在内存溢出
解释器会解释指令为机器码交给 cpu 执行,程序计数器会记录下一条指令的地址行号,这样下一次解释器会从程序计数器拿到指令然后进行解释执行。
多线程的环境下,如果两个线程发生了上下文切换,那么程序计数器会记录线程下一行指令的地址行号,以便于接着往下执行。
3、栈
定义
每个线程运行需要的内存空间,称为虚拟机栈
每个栈由多个栈帧(Frame)组成,对应着每次调用方法时所占用的内存
每个线程只能有一个活动栈帧,对应着当前正在执行的方法
问题辨析:
- 垃圾回收是否涉及栈内存?
不会。栈内存是方法调用产生的,方法调用结束后会弹出栈。
- 栈内存分配越大越好吗?
不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
- 方法内的局部变量是否线程安全
如果方法内部的变量没有逃离方法的作用范围,它是线程安全的
如果是局部变量引用了对象,并逃离了方法的作用范围,那就要考虑线程安全问题。

m1是线程安全的,m2,m3都不算线程安全的。
栈内存溢出
栈帧过大、过多、或者第三方类库操作,都有可能造成栈内存溢出 java.lang.stackOverflowError ,使用 -Xss256k 指定栈内存大小!
public class Demo1_19 {public static void main(String[] args) throws JsonProcessingException {Dept d = new Dept();d.setName("Market");Emp e1 = new Emp();e1.setName("zhang");e1.setDept(d);Emp e2 = new Emp();e2.setName("li");e2.setDept(d);d.setEmps(Arrays.asList(e1, e2));// { name: 'Market', emps: [{ name:'zhang', dept:{ name:'', emps: [ {}]} },] }ObjectMapper mapper = new ObjectMapper();System.out.println(mapper.writeValueAsString(d));}
}class Emp {private String name;@JsonIgnoreprivate Dept dept;public String getName() {return name;}public void setName(String name) {this.name = name;}public Dept getDept() {return dept;}public void setDept(Dept dept) {this.dept = dept;}
}
class Dept {private String name;private List<Emp> emps;public String getName() {return name;}public void setName(String name) {this.name = name;}public List<Emp> getEmps() {return emps;}public void setEmps(List<Emp> emps) {this.emps = emps;}
}
线程运行诊断
案例一:cpu 占用过多
解决方法:Linux 环境下运行某些程序的时候,可能导致 CPU 的占用过高,这时需要定位占用 CPU 过高的线程
- top 命令,查看是哪个进程占用 CPU 过高
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过 top 查到的进程号 通过 ps 命令进一步查看是哪个线程占用 CPU 过高
- jstack 进程 id 通过查看进程中的线程的 nid ,刚才通过 ps 命令看到的 tid 来对比定位,注意 jstack 查找出的线程 id 是 16 进制的,需要转换。
本地方法栈
一些带有 native 关键字的方法就是需要 JAVA 去调用本地的C或者C++方法,因为 JAVA 有时候没法直接和操作系统底层交互,所以需要用到本地方法栈,服务于带 native 关键字的方法。
4、堆
定义
Heap 堆
- 通过new关键字创建的对象都会被放在堆内存
特点
- 它是线程共享,堆内存中的对象都需要考虑线程安全问题
- 有垃圾回收机制
堆内存溢出
java.lang.OutofMemoryError :java heap space. 堆内存溢出
可以使用 -Xmx8m 来指定堆内存大小。
堆内存诊断
jps 工具
查看当前系统中有哪些 java 进程
jmap 工具
查看堆内存占用情况 jmap - heap 进程id
jconsole 工具
图形界面的,多功能的监测工具,可以连续监测
5、方法区
定义
Java 虚拟机有一个在所有 Java 虚拟机线程之间共享的方法区域。方法区域类似于用于传统语言的编译代码的存储区域,或者类似于操作系统进程中的“文本”段。它存储每个类的结构,例如运行时常量池、字段和方法数据,以及方法和构造函数的代码,包括特殊方法,用于类和实例初始化以及接口初始化方法区域是在虚拟机启动时创建的。
组成
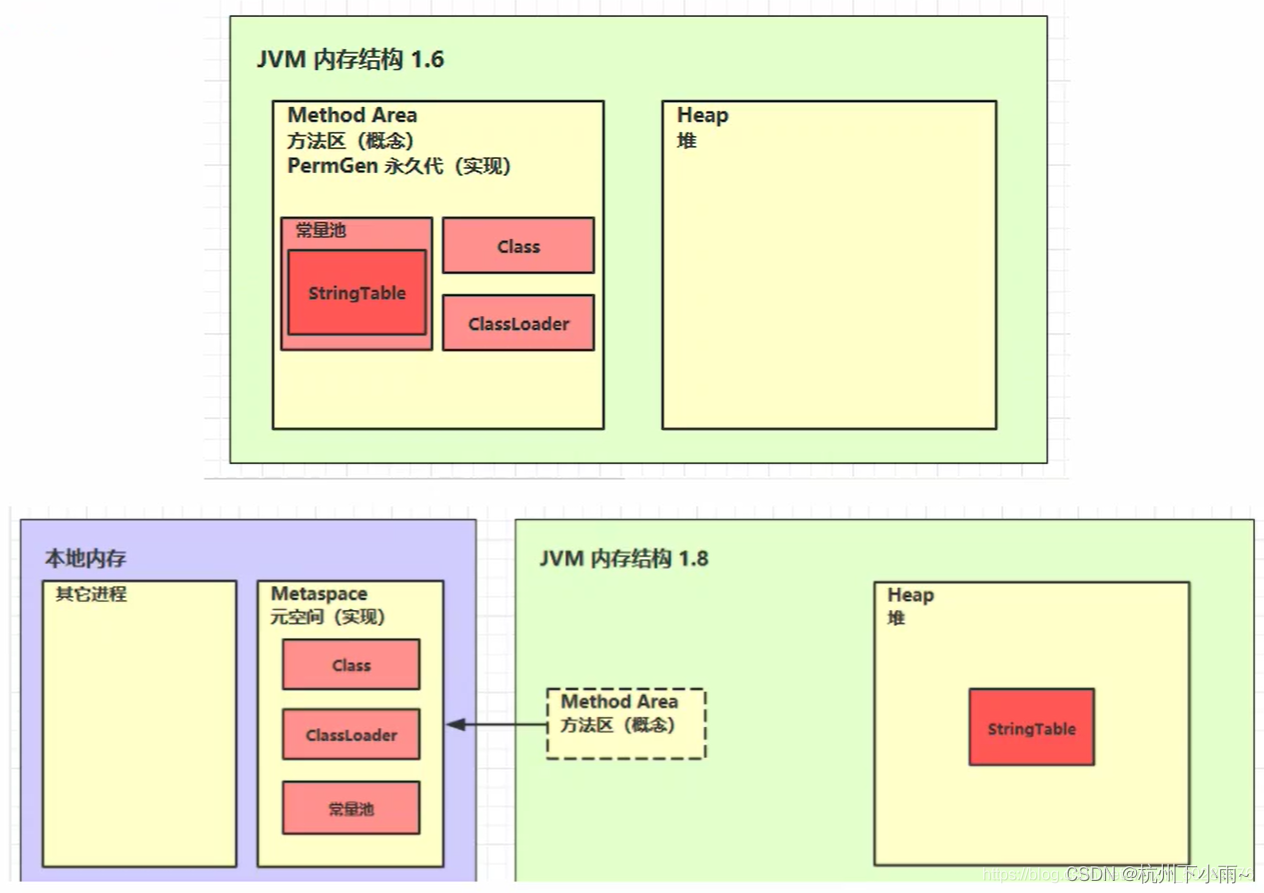
方法区内存溢出
1.8 之前会导致永久代内存溢出
使用 -XX:MaxPermSize=8m 指定永久代内存大小
1.8 之后会导致元空间内存溢出
使用 -XX:MaxMetaspaceSize=8m 指定元空间大小
运行时常量池
二进制字节码包含(类的基本信息,常量池,类方法定义,包含了虚拟机的指令)
首先看看常量池是什么,编译如下代码:
public class Test {public static void main(String[] args) {System.out.println("Hello World!");}}然后使用 javap -v Test.class 命令反编译查看结果。
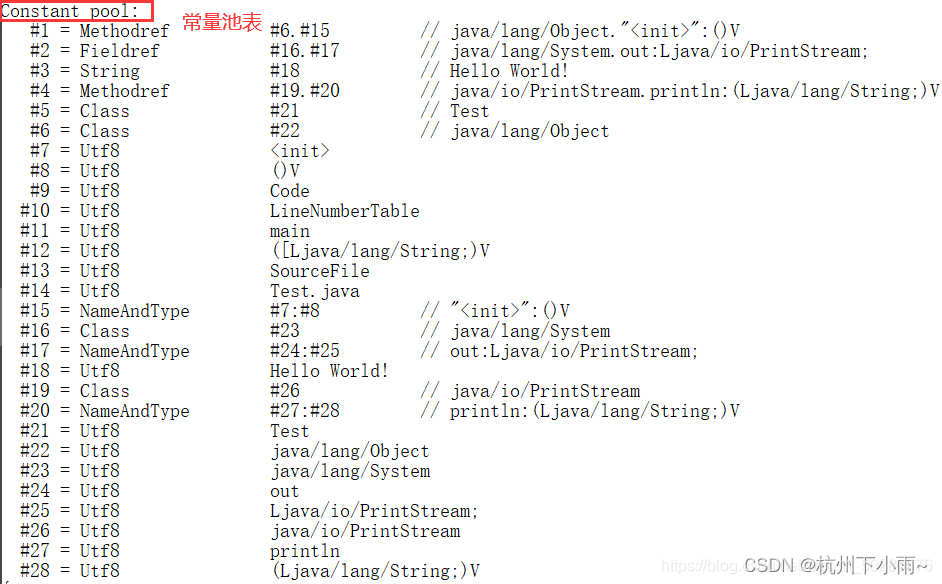
常量池:
就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息
运行时常量池:
常量池是 *.class 文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
6、StringTable
- 常量池中的字符串仅是符号,只有在被用到时才会转化为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder
- 字符串常量拼接的原理是编译器优化
- 可以使用
intern方法,主动将串池中还没有的字符串对象放入串池中
例1:
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象// ldc #2 会把 a 符号变为 "a" 字符串对象// ldc #3 会把 b 符号变为 "b" 字符串对象// ldc #4 会把 ab 符号变为 "ab" 字符串对象public static void main(String[] args) {String s1 = "a"; // 懒惰的String s2 = "b";String s3 = "ab";String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为abSystem.out.println(s3 == s5);//trueSystem.out.println(s3 == s4);//flase}
}
intern方法 1.8
调用字符串对象的 intern 方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,则放入成功
如果有该字符串对象,则放入失败 - 无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用 intern 方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象
public class Demo1_23 {// ["ab", "a", "b"]public static void main(String[] args) {String x = "ab";String s = new String("a") + new String("b");// 堆 new String("a") new String("b") new String("ab")String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回System.out.println( s2 == x);//trueSystem.out.println( s == x );//false}}
面试题
/*** 演示字符串相关面试题*/
public class Demo1_21 {public static void main(String[] args) {String s1 = "a";String s2 = "b";String s3 = "a" + "b"; // abString s4 = s1 + s2; // new String("ab")String s5 = "ab";String s6 = s4.intern();// 问System.out.println(s3 == s4); // falseSystem.out.println(s3 == s5); // trueSystem.out.println(s3 == s6); // trueString x2 = new String("c") + new String("d"); // new String("cd")
// x2.intern();String x1 = "cd";x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢System.out.println(x1 == x2);//false}
}
理解intern方法:intern是将字符串放到常量池里,常量池如果没有,就把自己的地址放到常量池,如果有,就返回常量池里面的对象地址。
StringTable位置
jdk1.6 StringTable 位置是在永久代中,1.8 StringTable 位置是在堆中。
StringTable 垃圾回收
-Xmx10m 指定堆内存大小
-XX:+PrintStringTableStatistics 打印字符串常量池信息
-XX:+PrintGCDetails
-verbose:gc 打印 gc 的次数,耗费时间等信息
/*** 演示 StringTable 垃圾回收* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc*/
public class Code_05_StringTableTest {public static void main(String[] args) {int i = 0;try {for(int j = 0; j < 10000; j++) { // j = 100, j = 10000String.valueOf(j).intern();i++;}}catch (Exception e) {e.printStackTrace();}finally {System.out.println(i);}}}StringTable调优
在介绍性能调优之前不得不说一说StringTable的底层实现,前面已经提到了StringTable底层是一个HashTable,HashTable长什么样呢?其实就是数组+链表,每个元素是一个key-value。当存入一个元素的时候,就会将其key通过hash函数计算得出数组的下标并存放在对应的位置。

比如现在有一个key-value,这个key通过hash函数计算结果为2,那么就把value存放在数组下标为2的位置。但是如果现在又有一个key通过hash函数计算出了相同的结果,比如也是2,但2的位置已经有值了,这种现象就叫做哈希冲突,怎么解决呢?这里采用了链表法:
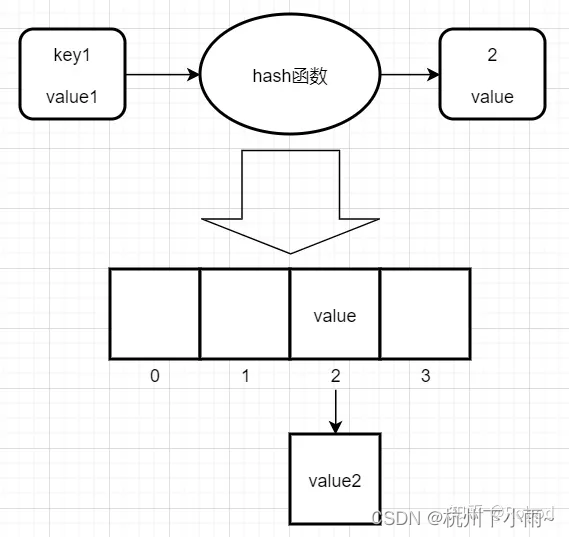
链表法就是将下标一样的元素通过链表的形式串起来,如果数组容量很小但是元素很多,那么发生哈希冲突的概率就会提高。大家都知道,链表的效率远没有数组那么高,哈希冲突过多会影响性能。所以为了减少哈希冲突的概率,所以可以适当的增加数组的大小。数组的每一格在StringTable中叫做bucket,我们可以增加bucket的数量来提高性能,默认的数量为60013个,来看一个对比:
long startTime = System.nanoTime();
String str = "hello";
for(int i = 0;i < 500000;i++) {String s = str + i;s.intern();
}
long endTime = System.nanoTime();
System.out.println("花费的时间为:"+(endTime-startTime)/1000000 + "毫秒");
先通过一个虚拟机参数将bucket指定的小一点,来个2000吧:
-XX:StringTableSize=2000
运行一下:

一共花费了1.2秒。再来将bucket的数量增加一点,来个20000个:
-XX:StringTableSize=20000
运行一下:

可以看到,这次只花了0.19秒,性能有了明显的提升,说明这样确实可以优化StringTable。
7、直接内存
定义
Direct Memory
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
使用直接内存的好处
文件读写流程:

因为 java 不能直接操作文件管理,需要切换到内核态,使用本地方法进行操作,然后读取磁盘文件,会在系统内存中创建一个缓冲区,将数据读到系统缓冲区, 然后在将系统缓冲区数据,复制到 java 堆内存中。缺点是数据存储了两份,在系统内存中有一份,java 堆中有一份,造成了不必要的复制。
使用了 DirectBuffer 文件读取流程

直接内存是操作系统和 Java 代码都可以访问的一块区域,无需将代码从系统内存复制到 Java 堆内存,从而提高了效率。
使用ByteBuffer.allocateDirect
/*** IO:阻塞式 NIO (New IO / Non-Blocking IO):非阻塞式* byte[] / char[] Buffer* Stream Channel** 查看直接内存的占用与释放*/
public class BufferTest {private static final int BUFFER = 1024 * 1024 * 1024; //1GBpublic static void main(String[] args){//直接分配本地内存空间ByteBuffer byteBuffer = ByteBuffer.allocateDirect(BUFFER);System.out.println("直接内存分配完毕,请求指示!");Scanner scanner = new Scanner(System.in);scanner.next();System.out.println("直接内存开始释放!");byteBuffer = null;System.gc();scanner.next();}}
使用unsafe类
/*** 直接内存分配的底层原理:Unsafe*/
public class Demo1_27 {static int _1Gb = 1024 * 1024 * 1024;public static void main(String[] args) throws IOException {Unsafe unsafe = getUnsafe();// 分配内存long base = unsafe.allocateMemory(_1Gb);unsafe.setMemory(base, _1Gb, (byte) 0);System.in.read();// 释放内存unsafe.freeMemory(base);System.in.read();}public static Unsafe getUnsafe() {try {Field f = Unsafe.class.getDeclaredField("theUnsafe");f.setAccessible(true);Unsafe unsafe = (Unsafe) f.get(null);return unsafe;} catch (NoSuchFieldException | IllegalAccessException e) {throw new RuntimeException(e);}}
}
8、垃圾回收
如何判断对象可以回收
引用计数法
当一个对象被引用时,引用对象的值加一,当一个对象不被引用时,引用对象的值减一,当值为 0 时,就表示该对象不被引用,可以被垃圾收集器回收。
这个引用计数法听起来不错,但是有一个弊端,如下图所示,循环引用时,两个对象的计数都为1,导致两个对象都无法被释放,造成内存泄露。

可达性分析算法
- JVM 中的垃圾回收器通过可达性分析来探索所有存活的对象
- 扫描堆中的对象,看能否沿着 GC Root 对象为起点的引用链找到该对象,如果找不到,则表示可以回收
- 可以作为 GC Root 的对象
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI(即一般说的Native方法)引用的对象
- 已启动且未停止的 Java 线程
public static void main(String[] args) throws IOException {ArrayList<Object> list = new ArrayList<>();list.add("a");list.add("b");list.add(1);System.out.println(1);System.in.read();list = null;System.out.println(2);System.in.read();System.out.println("end");}对于以上代码,可以使用如下命令将堆内存信息转储成一个文件,然后使用
Eclipse Memory Analyzer 工具进行分析。
第一步:
使用 jps 命令,查看程序的进程

第二步

使用 jmap -dump:format=b,live,file=1.bin 16104 命令转储文件
dump:转储文件
format=b:二进制文件
file:文件名
16104:进程的id
第三步:打开 Eclipse Memory Analyzer 对 1.bin 文件进行分析。

分析的 gc root,找到了 ArrayList 对象,然后将 list 置为null,再次转储,那么 list 对象就会被回收。
java定义常量是在方法区还是堆区
在Java中,常量通常被定义为静态final字段,它们被存储在方法区中的运行时常量池中。这意味着它们在程序运行期间只被分配一次,并且可以被所有对象共享。堆区是用于存储对象实例的区域,而不是常量。
四种引用

强引用
只有所有 GC Roots 对象都不通过【强引用】引用该对象,该对象才能被垃圾回收
软引用(SoftReference)
仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次出发垃圾回收,回收软引用对象可以配合引用队列来释放软引用自身
弱引用(WeakReference)
仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象
可以配合引用队列来释放弱引用自身
虚引用(PhantomReference)
必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队,由 Reference Handler 线程调用虚引用相关方法释放直接内存
终结器引用(FinalReference)
无需手动编码,但其内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize 方法,第二次 GC 时才能回收被引用对象。
演示软引用
/*** 演示 软引用* -Xmx20m -XX:+PrintGCDetails -verbose:gc*/
public class Code_08_SoftReferenceTest {public static int _4MB = 4 * 1024 * 1024;public static void main(String[] args) throws IOException {method2();}// 设置 -Xmx20m , 演示堆内存不足,public static void method1() throws IOException {ArrayList<byte[]> list = new ArrayList<>();for(int i = 0; i < 5; i++) {list.add(new byte[_4MB]);}System.in.read();}// 演示 软引用public static void method2() throws IOException {ArrayList<SoftReference<byte[]>> list = new ArrayList<>();for(int i = 0; i < 5; i++) {SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB]);System.out.println(ref.get());list.add(ref);System.out.println(list.size());}System.out.println("循环结束:" + list.size());for(SoftReference<byte[]> ref : list) {System.out.println(ref.get());}}
}method1 方法解析:
首先会设置一个堆内存的大小为 20m,然后运行 mehtod1 方法,会抛异常,堆内存不足,因为 mehtod1 中的 list 都是强引用。

method2 方法解析:
在 list 集合中存放了 软引用对象,当内存不足时,会触发 full gc,将软引用的对象回收。细节如图:

上面的代码中,当软引用引用的对象被回收了,但是软引用还存在,所以,一般软引用需要搭配一个引用队列一起使用。
修改 method2 如下:
// 演示 软引用 搭配引用队列
public static void method3() throws IOException {ArrayList<SoftReference<byte[]>> list = new ArrayList<>();// 引用队列ReferenceQueue<byte[]> queue = new ReferenceQueue<>();for(int i = 0; i < 5; i++) {// 关联了引用队列,当软引用所关联的 byte[] 被回收时,软引用自己会加入到 queue 中去SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);System.out.println(ref.get());list.add(ref);System.out.println(list.size());}// 从队列中获取无用的 软引用对象,并移除Reference<? extends byte[]> poll = queue.poll();while(poll != null) {list.remove(poll);poll = queue.poll();}System.out.println("=====================");for(SoftReference<byte[]> ref : list) {System.out.println(ref.get());}}
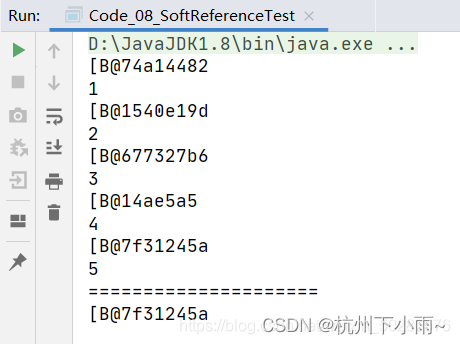
弱引用
/*** 演示弱引用* -Xmx20m -XX:+PrintGCDetails -verbose:gc*/
public class Demo2_5 {private static final int _4MB = 4 * 1024 * 1024;public static void main(String[] args) {// list --> WeakReference --> byte[]List<WeakReference<byte[]>> list = new ArrayList<>();for (int i = 0; i < 10; i++) {WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);list.add(ref);for (WeakReference<byte[]> w : list) {System.out.print(w.get()+" ");}System.out.println();}System.out.println("循环结束:" + list.size());}
}
相关文章:
JVM学习笔记(上)
1、总体路线 2、程序计数器 Program Counter Register 程序计数器(寄存器) 作用:是记录下一条 jvm 指令的执行地址行号。 特点: 是线程私有的不会存在内存溢出 解释器会解释指令为机器码交给 cpu 执行,程序计数器会…...

反爬虫技术
预计更新 一、 爬虫技术概述 1.1 什么是爬虫技术 1.2 爬虫技术的应用领域 1.3 爬虫技术的工作原理 二、 网络协议和HTTP协议 2.1 网络协议概述 2.2 HTTP协议介绍 2.3 HTTP请求和响应 三、 Python基础 3.1 Python语言概述 3.2 Python的基本数据类型 3.3 Python的流程控制语句 …...
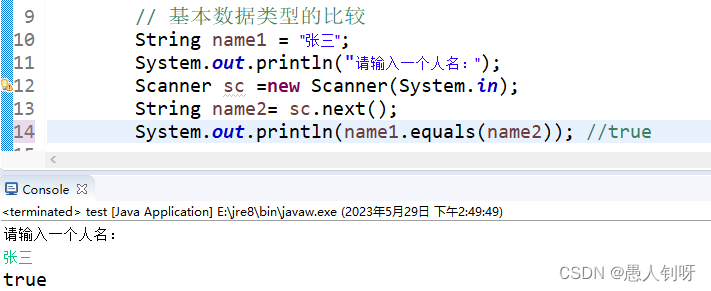
JAVA中.equals()与 ==的区别
1. “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。 2..equals() equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重写之后比…...

华为OD机试之羊、狼、农夫过河(Java源码)
羊、狼、农夫过河 题目描述 羊、狼、农夫都在岸边,当羊的数量小于狼的数量时,狼会攻击羊,农夫则会损失羊。农夫有一艘容量固定的船,能够承载固定数量的动物。 要求求出不损失羊情况下将全部羊和狼运到对岸需要的最小次数。只计算…...

C++ string的简单应用
C语言的字符串 C的字符串 头文件: #include<string.h> //c #include<string> //C #include<cstring> //C 比较string的大小 两个string对象相加 使用字符串对象来存放字符串 两个string对象相加 string str "Hello,"; st…...

Java中的阻塞队列
阻塞队列的基本概念 1、生产者、消费者的概念 他俩是设计模式的一种,提出这两种概念,通过一个容器的方式能解决强耦合问题 生产者、消费者之间不会直接通讯。通过一个第三方容器、队列的方式进行通讯 生产者生产完数据放入容器之后,不用等待消…...

PriorityBlockingQueue无界阻塞优先级队列
PriorityBlockingQueue无界阻塞优先级队列 PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实 现,研究过数组方式存放最小堆节点的都知道,直接遍历队列元素是无序的。 如图 P…...

「HTML和CSS入门指南」p 标签详解
<p> 标签是什么? HTML5 中的 <p> 标签是用于定义段落的标签。它可以用来标记文章、新闻等长篇内容中的段落,并且可以与其他 HTML 元素配合使用。 <p> 标签的语法和属性 <p> 标签的语法非常简单,只需要在 HTML 文件中插入 <p> 和 </p>…...
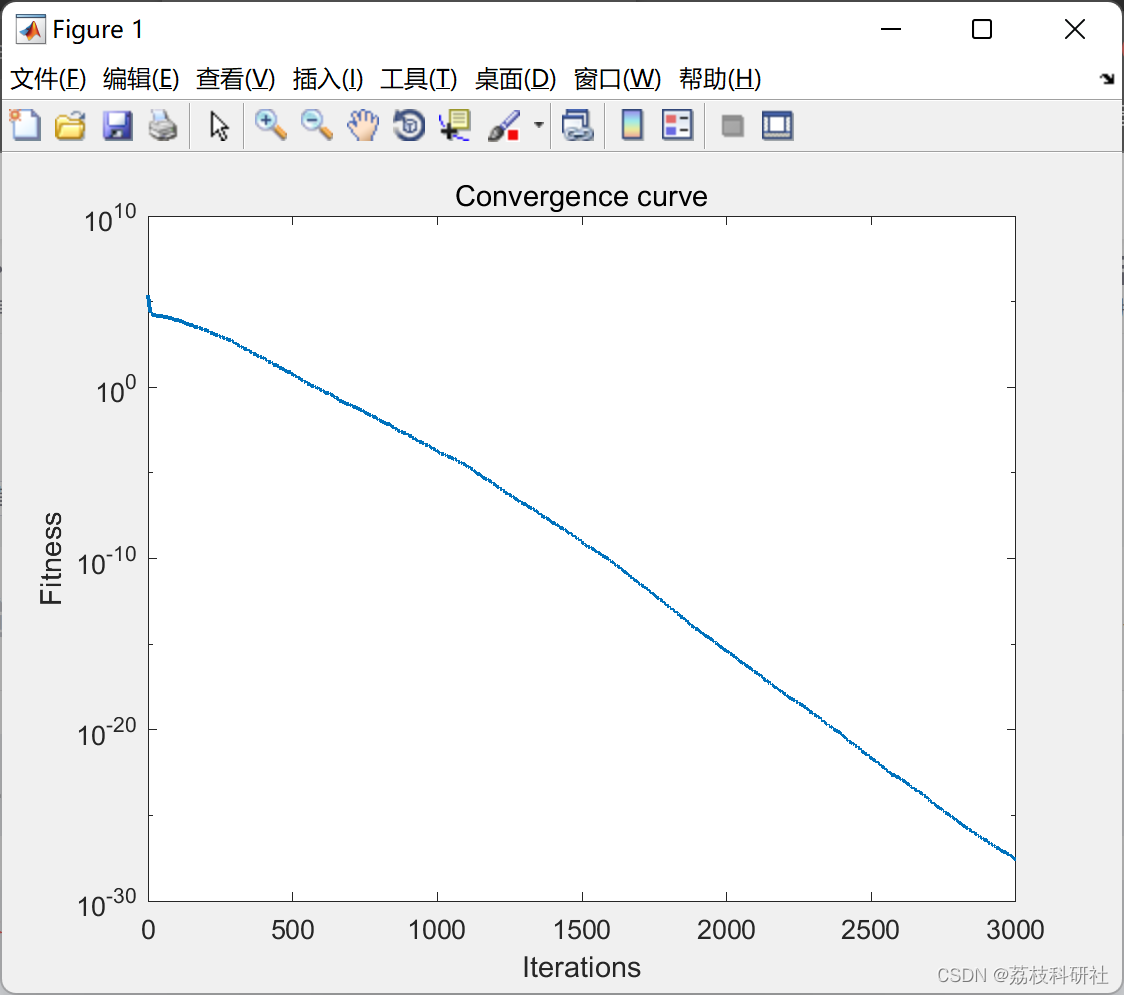
【单目标优化算法】孔雀优化算法(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

chatgpt赋能python:Python同一行多个语句:如何提高你的编程效率?
Python同一行多个语句:如何提高你的编程效率? Python是一种优雅的编程语言,拥有简洁易懂的语法,可以帮助你快速编写可以在各种领域使用的高级代码。其中,Python同一行多个语句,是一种可以大大提高编程效率…...
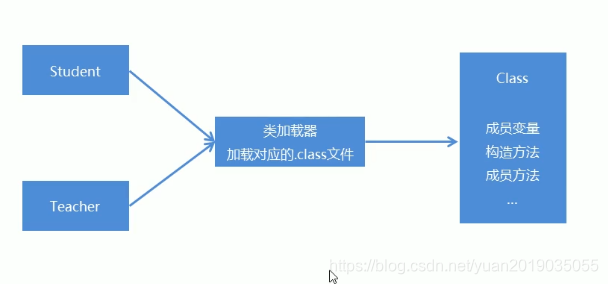
Java反射概述
2 反射 2.1 反射概述 Java反射机制:是指在运行时去获取一个类的变量和方法信息。然后通过获取到的信息来创建对象,调用方法的一种机制。由于这种动态性,可以极大的增强程序的灵活性,程序不用在编译期就完成确定,在运行期仍然可以扩展2.2 反射获取Class类的对象 我们要想通过反…...
)
《网络是怎样连接的》(一)
第一章web浏览器 简介 首先输入网址URL,浏览器进行解析,将我们需要哪些数据告诉服务器。浏览器向服务器发送消息,必须告诉操作系统的接收方的IP地址,所以浏览器先查出web服务器的IP地址,向DNS服务器查询域名对应的IP…...

Flink on yarn任务日志怎么看
1、jobmanager日志 在yarn上可以直接看 2、taskmanager日志 在flink的webui中可以看,但是flink任务失败后,webui就不存在了,那怎么看? 这是jobmanager的地址 hadoop02:19888/jobhistory/logs/hadoop02:45454/container_e03_16844…...
二次元的登录界面
今天还是继续坚持写博客,然后今天给大家带来比较具有二次元风格的登录界面,也只是用html和css来写的,大家可以来看看! 个人名片: 😊作者简介:一名大一在校生,web前端开发专业 &…...
2. 量化多因子数据清洗——去极值、标准化、正交化、中性化
一、去极值 1. MAD MAD(mean absolute deviation)又称为绝对值差中位数法,是一种先需计算所有因子与平均值之间的距离总和来检测离群值的方法. def extreme_MAD(rawdata, n): median rawdata.quantile(0.5) # 找出中位数 new_median (abs(…...

皮卡丘反射型XSS
1.反射型xss(get) 进入反射型xss(get)的关卡,我们可以看到如下页面 先输入合法数据查看情况,例如输入“kobe” 再随便输入一个,比如我舍友的外号“xunlei”,“666”,嘿嘿嘿 F12查看源代码,发现你输入的数…...
巧计口诀-软件测试的生命周期,黑盒测试设计方法
目录 1。口诀 2。黑盒设计方法适用场合 3。黑盒设计方法详解 3.1。等价类法 3.2。 边界值法 3.3。判定表法 3.4。因果表 3.5。状态迁移图 3.6。场景法 3.7。正交实验法 3.8。错误推断法 1。口诀 又到了找工作的日子,背诵这些基本知识和概念又开始了。我找…...
- Ashmem驱动)
Android系统的Ashmem匿名共享内存系统分析(1)- Ashmem驱动
声明 其实对于Android系统的Ashmem匿名共享内存系统早就有分析的想法,记得2019年6、7月份Mr.Deng离职期间约定一起对其进行研究的,但因为我个人问题没能实施这个计划,留下些许遗憾…文中参考了很多书籍及博客内容,可能涉及的比较…...

Redis 事务详细介绍
事务 注意:Redis单条命令是保证原子性的;但是事务不保证原子性! Redis事务没有隔离级别的概念,所有的命令在事务中,并没有直接被执行,只有发起执行命令时才执行 Redis事务本质:一组命令的集合&…...

2023-5-29第二十九天
consult咨询,查阅,商讨 specialize专门从事,专攻 inspect检查 pattern图案,方式 optimize使最优化 ensemble整体,全体 subscript下标 subscribe签名 sector行业,部门 precedence优先,优…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...

C/Python/Go示例 | Socket Programing与RPC
Socket Programming介绍 Computer networking这个领域围绕着两台电脑或者同一台电脑内的不同进程之间的数据传输和信息交流,会涉及到许多有意思的话题,诸如怎么确保对方能收到信息,怎么应对数据丢失、被污染或者顺序混乱,怎么提高…...