4.2 Spark SQL数据源 - 基本操作
一、默认数据源
案例演示读取Parquet文件
查看Spark的样例数据文件users.parquet
1、在Spark Shell中演示
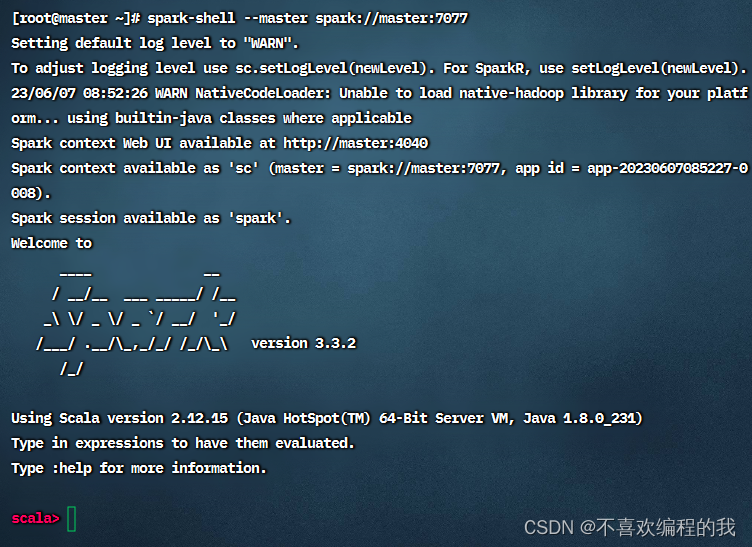
启动Spark Shell

查看数据帧内容

查看数据帧模式

对数据帧指定列进行查询,查询结果依然是数据帧,然后通过write成员的save()方法写入HDFS指定目录

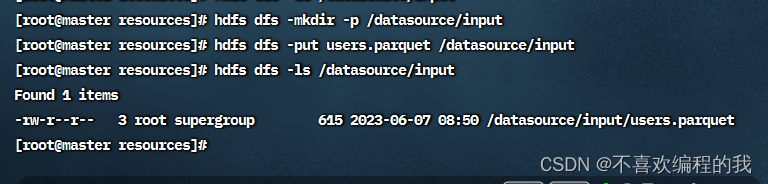
查看HDFS上的输出结果
执行SQL查询

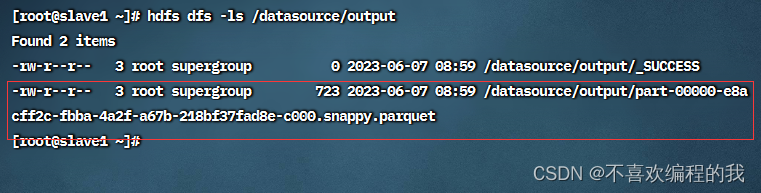
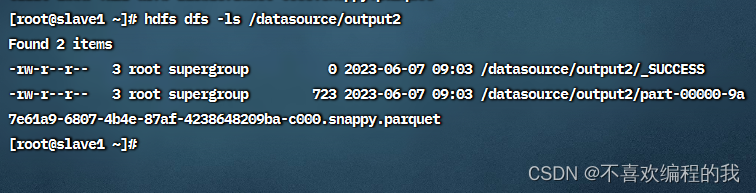
查看HDFS上的输出结果
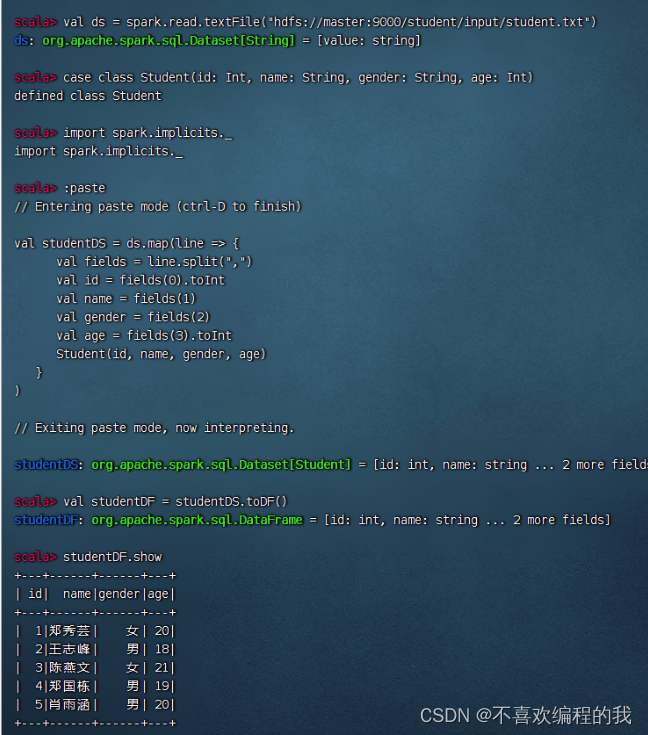
课堂练习1、将4.1节的student.txt文件转换成student.parquet
得到学生数据帧 - studentDF
将学生数据帧保存为parquet文件

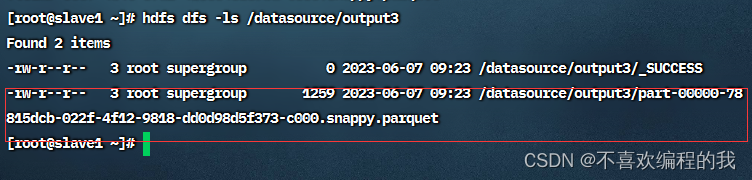
查看生成的parquet文件
复制parquet文件到/datasource/input目录
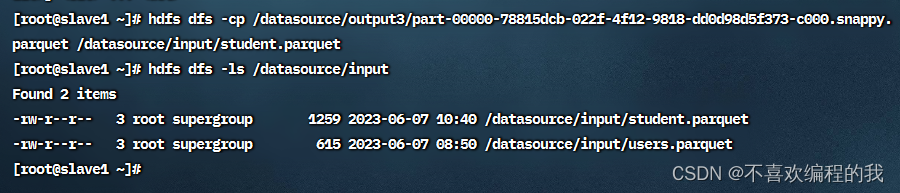
课堂练习2、读取student.parquet文件得到学生数据帧,并显示数据帧内容
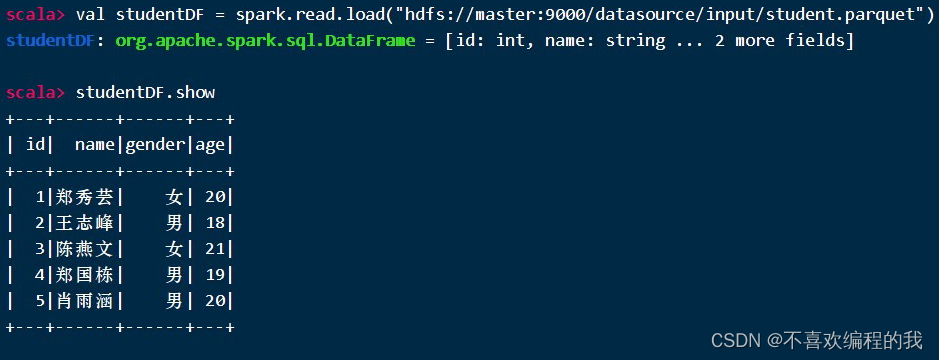
2、在IntelliJ IDEA里演示
在这里插入图片描述
将java目录改成scala目录
在pom.xml文件里添加相关依赖,设置源程序文件夹
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>net.cxf.sql</groupId><artifactId>SparkSQLDemo</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.15</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.3</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory></build>
</project>
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
<?xml version="1.0" encoding="UTF-8"?>
<configuration><property><description>only config in clients</description><name>dfs.client.use.datanode.hostname</name><value>true</value></property>
</configuration>创建net.cxf.sql.day01包,在包里创建ReadParquetFile对象
package net.cxf.sql.day01
import org.apache.spark.sql.SparkSession
/*** 功能:读取Parquet文件* 作者:cxf* 日期:2023年06月07日*/object ReadParquetFile {def main(args: Array[String]): Unit = {// 创建或得到Spark会话对象val spark = SparkSession.builder().appName("ReadParquetFile").master("local[*]").getOrCreate()// 加载student.parquet文件,得到数据帧val studentDF = spark.read.load("hdfs://master:9000/datasource/input/student.parquet")// 显示学生数据帧内容studentDF.show// 查询20岁以上的女生val girlDF = studentDF.filter("gender = '女' and age > 20")// 显示女生数据帧内容girlDF.show// 保存查询结果到HDFS(保证输出目录不存在)girlDF.write.save("hdfs://master:9000/datasource/output")}
}运行程序,查看控制台结果

在HDFS查看输出结果

二、手动指定数据源
(一)案例演示读取不同数据源
1、读取csv文件
查看Spark的样例数据文件people.csv
将people.csv文件上传到HDFS的/datasource/input目录,然后查看文件内
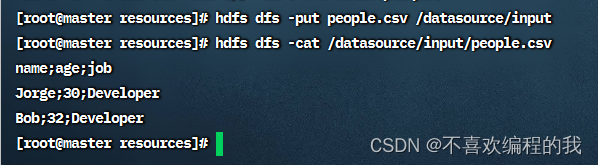
读取人员csv文件,得到人员数据帧

查看人员数据帧内容


查看人员数据帧内容


2、读取json,保存为parquet
查看people.json文件
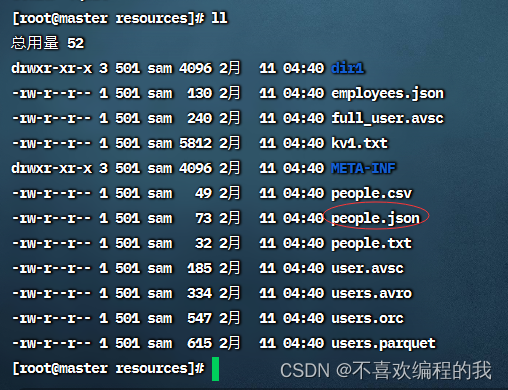
将people.json上传到HDFS的/datasource/input目录,并查看其内容



查看生成的parquet文件
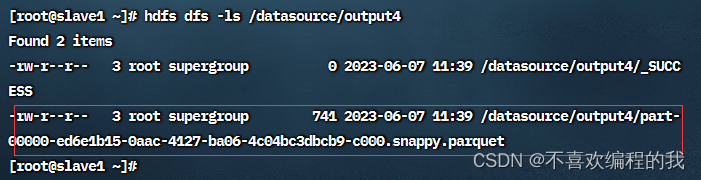

现在读取/datasource/input/people.parquet文件得到人员数据帧
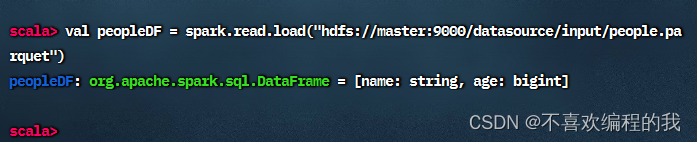
查看人员数据帧内容

3、读取jdbc数据源,保存为json文件
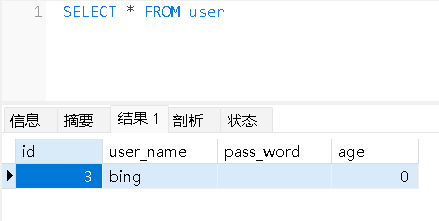
查看student数据库里的t_user表
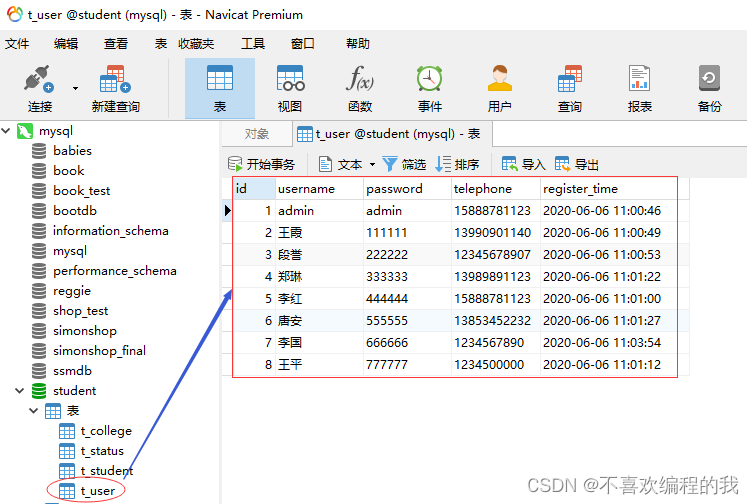
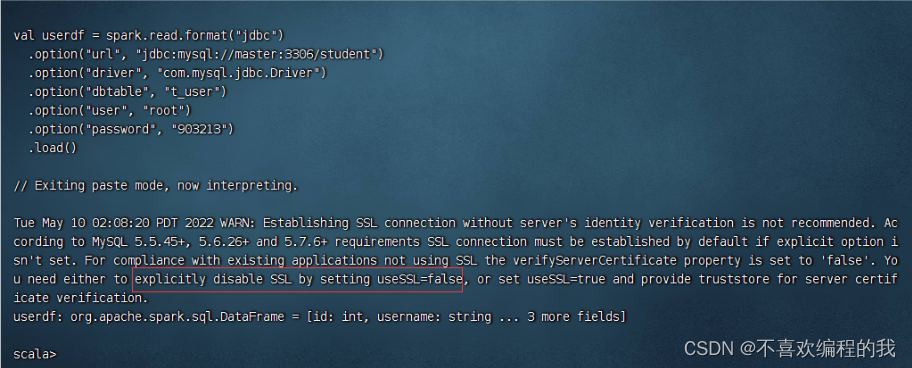
报错,找不到数据库驱动程序com.mysql.jdbc.Driver
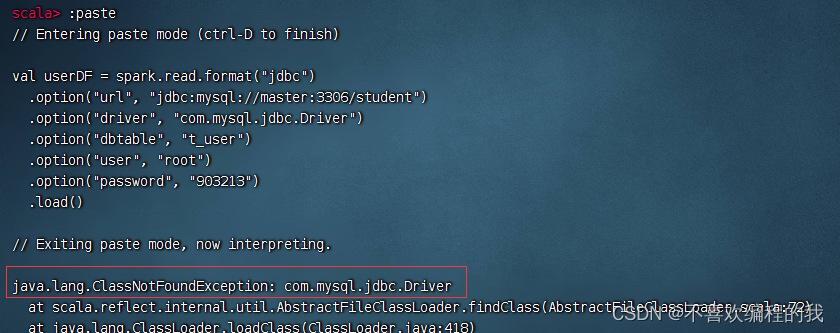
将数据库驱动程序上传到master虚拟机的/opt目录
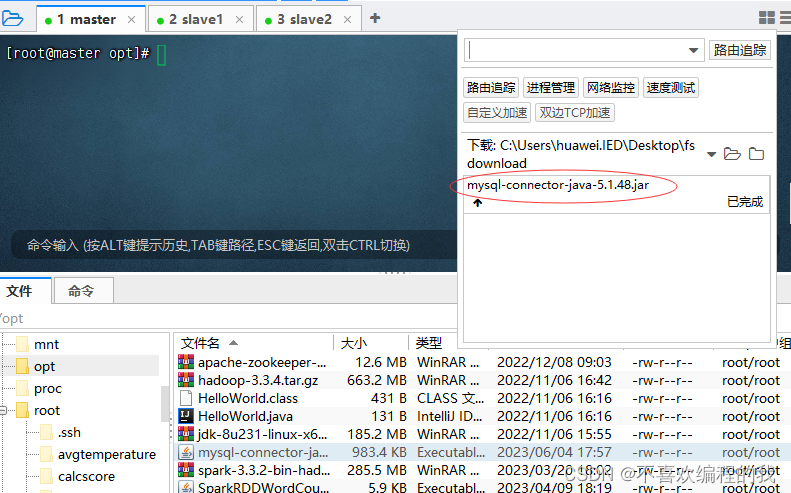
将数据库驱动程序拷贝到$SPARK_HOME/jars目录,

加载jdbc数据源成功,但是有个警告,需要通过设置useSSL=false来消除
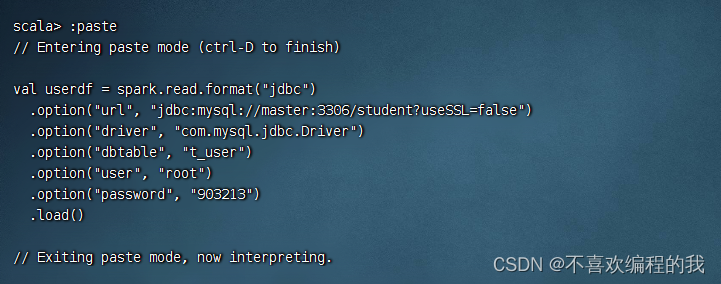
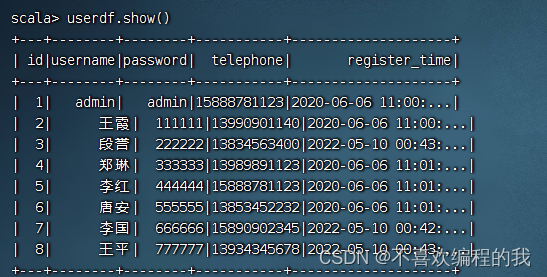
执行命令:userdf.show()

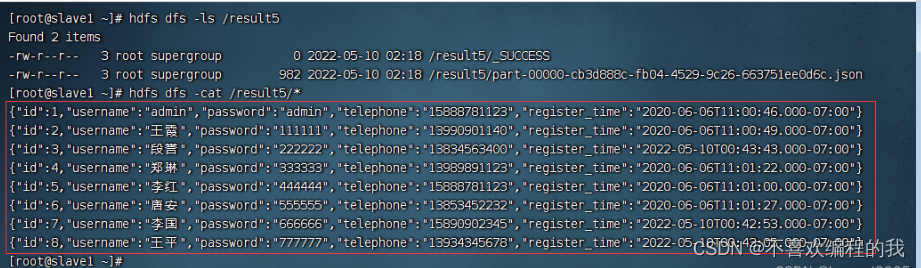
在虚拟机slave1查看生成的json文件
三、数据写入模式
案例演示不同写入模式
查看数据源
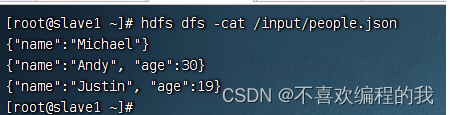
查询该文件name里,采用覆盖模式写入/result,/result目录里本来有东西的


导入SaveMode类

在slave1虚拟机上查看生成的json文件

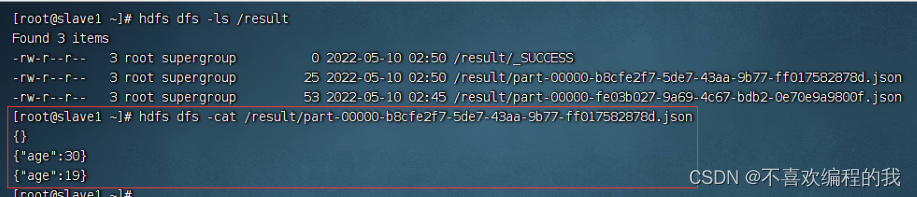
查询age列

在slave1虚拟机上查看追加生成的json文件
四、分区自动推断
(一)分区自动推断概述
以people作为表名,gender和country作为分区列,给出存储数据的目录结构

(二)分区自动推断演示
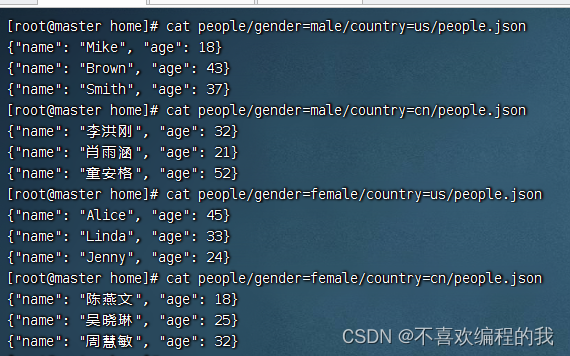
1、建四个文件
在master虚拟机上/home里创建如下目录及文件,其中目录people代表表名,gender和country代表分区列,people.json存储实际人口数据
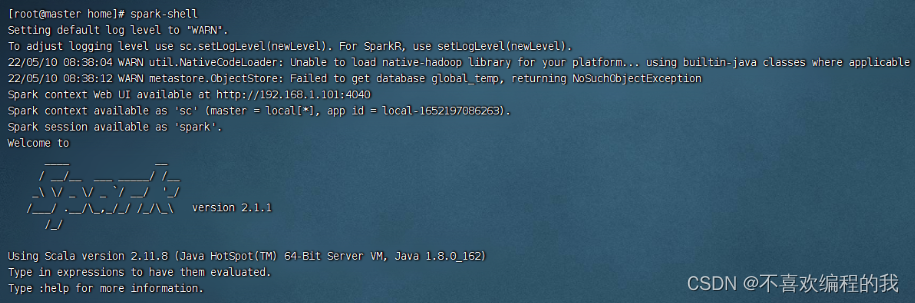
2、读取表数据
启动Spark Shell

3、输出Schema信息
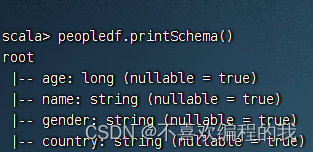
4、显示数据帧内容
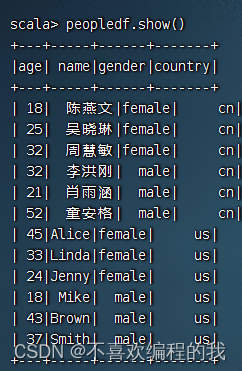
相关文章:
4.2 Spark SQL数据源 - 基本操作
一、默认数据源 案例演示读取Parquet文件 查看Spark的样例数据文件users.parquet 1、在Spark Shell中演示 启动Spark Shell 查看数据帧内容 查看数据帧模式 对数据帧指定列进行查询,查询结果依然是数据帧,然后通过write成员的save()方法写入HDF…...

事件相关功能磁共振波谱技术(fMRS)
导读 质子磁共振波谱(MRS)是一种非侵入性脑成像技术,用于测量不同神经化学物质的浓度。“单体素”MRS数据通常在几分钟内采集,然后对单个瞬态进行平均,从而测量神经化学物质浓度。然而,这种方法对更快速的神经化学物质的时间动态…...

跨境电商客户服务五步法
互联网技术的革新与升级对商务客服产生了巨大的影响,过去由在线客服与客户直接电联的单一服务形式被全渠道客服系统所替代。在电子商务时代,商家与客户之间的互动变得尤为重要:一方面,卖家通过分析客户喜好及消费趋向来针对性处理…...

hadoop环境配置及HDFS配置
环境与配置 ubuntu 20.04.6 /centos8hadoop 3.3.5 指令有部分不一样但是,配置是相同的 安装步骤 创建一个虚拟机,克隆三个虚拟机,master内存改大一点4G,salve内存1Gj修改主机名和配置静态ip(管理员模式下)) hostnamectl set-hostname node1 # 修改主机名 sudo passwd root …...

HTML中 meta的基本应用
meta 标签的定义 meta 标签是 head 部分的一个辅助性标签,提供关于 HTML 文档的元数据。它并不会显示在页面上,但对于机器是可读的。可用于浏览器(如何显示内容或重新加载页面),搜索引擎(SEO)或…...

docker compose 下 Redis 主备配置
1、准备两台虚拟机或者物理机 node1 IP:192.168.123.78 node2 IP:192.168.123.82 2、安装docker和docker compose 3、安装node1,配置docker-compose.yml version: 3services:redis-rs1:container_name: redis_node1image: redis:5.0.3rest…...

Tomcat ServletConfig和ServletContext接口概述
ServletConfig是一个接口,是Servlet规范中的一员 WEB服务器实现了ServletConfig接口,这里指的是Tomcat服务器 一个Servlet对象中有一个ServletConfig对象,Servlet和ServletConfig对象是一对一 ServletConfig对象是Tomcat服务器创建的…...

linux内核open文件流程
打开文件流程 本文基本Linux5.15 当应用层通过open api打开一个文件,内核中究竟如何处理? 本身用来描述内核中对应open 系统调用的处理流程。 数据结构 fdtable 一个进程可以打开很多文件, 内核用fdtable来管理这些文件。 include/linu…...
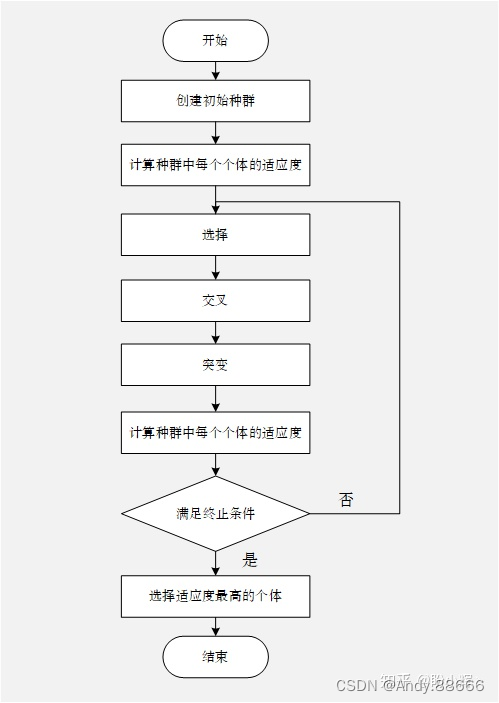
遗传算法讲解
遗传算法(Genetic Algorithm,GA) 是模拟生物在自然环境中的遗传和进化的过程而形成的自适应全局优化搜索算法。它借用了生物遗传学的观点,通过自然选择、遗传和变异等作用机制,实现各个个体适应性的提高。 基因型 (G…...
)
PostgreSQL修炼之道之高可用性方案设计(十六)
20 高可用性方案设计(一) 在一个生产系统中,通常都需要用高可用方案来保证系统的不间断运行。本章将详细介绍如何实现PostgreSQL数据库的高可用方案。 20.1 高可用架构基础 通常数据库的高可用方案都是让多个数据库服务器协同工作࿰…...

Bybit面经
缘起 V2EX有广告内推,看描述还挺不错 贴主5 年半工作经验,有两年大厂工作经历,20 年 11 月来到新加坡分公司开始工作 后来是猎头Jeff找的我 0318 主面 主要一个面试官是后端开发金融背景 某条金融线的负责人;其余是交叉面试。面…...
GORM---创建
目录 模型定义使用Create创建记录一次性创建多条数据批量插入数据时开启事务默认值问题 模型定义 定义一个PersonInfo结构体。 type PersonInfo struct {Id uint64 gorm:"column:id;primary_key;NOT NULL" json:"id"UserName string gorm:"co…...

高级查询 — 分组汇总
关于分组汇总 1.概述 将查询结果按某一列或者多列的值分组。 group by子句 分组后聚合函数将作用于每一个组,即每一组都有一个函数值。 语法 select 字段列表 from 表名 where 筛选条件 group by 分组的字段;select 字段列表 from 表名 group by 分组的字段 hav…...

【多线程】阻塞队列
1. 认识阻塞队列和消息队列 阻塞队列也是一个队列,也是一个特殊的队列,也遵守先进先出的原则,但是带有特殊的功能。 如果阻塞队列为空,执行出队列操作,就会阻塞等待,阻塞到另一个线程往阻塞队列中添加元素(…...

python2升级python3
查看当前版本 [roottest-01 node-v18.16.0]# python -V Python 2.7.5 安装依赖 [roottest-01 node-v18.16.0]# yum install -y gcc gcc-c zlib zlib-devel readline-devel 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base…...
(与spark的结合)--非bulk_insert模式)
Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景 之前讨论的都是’hoodie.datasource.write.operation’:bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件: /dt1/.hoodie_partition_metadata /dt1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_202305282…...
)
Java之旅(九)
Java 循环语句 Java 中的循环语句包括 for、while 和 do-while,它们都可以用于实现循环结构。 for 语句用于循环执行一段代码块,直到给定的条件表达式的布尔值为 false。 for 语句的一般格式如下: for (initialization; condition; update…...

6年测试经验之谈,为什么要做自动化测试?
一、自动化测试 自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。 个人认为,只要能服务于测试工作,能够帮助我们提升工作效率的,不管是所谓的自动化工具,还是简单的SQL 脚本、批处理脚本,还是自己编写…...

二分法的边界条件 2517. 礼盒的最大甜蜜度
2517. 礼盒的最大甜蜜度 给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。 商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两种糖果 价格 绝对差的最小值。 返回礼盒的 最大 甜蜜度。 记录一…...

java设计模式(十六)命令模式
目录 定义模式结构角色职责代码实现适用场景优缺点 定义 命令模式(Command Pattern) 又叫动作模式或事务模式。指的是将一个请求封装成一个对象,使发出请求的责任和执行请求的责任分割开,然后可以使用不同的请求把客户端参数化&a…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...