Java容器-集合
目录
1.Java容器概述
2.集合框架
3.Collection接口中的方法使用
4.iterator()
5.List接口
2.ArrayList、LinkedList、Vector相同点
3.不同点
1.ArrayList
2.LinkedList
3.Vector
4.Vector源码分析
5.ArrayList源码分析
6.LinkedList源码分析
6.List中的常用方法
7.区分remove删除的是元素还是索引
8.Set接口存在三个主要的实现类
1.HashSet
2.LinkedHashSet
3.TreeSet
4.如何理解Set的无序、不可重复特性(以HashSet为例)
5.set中添加元素的过程(以HashSet为例)
6.HashSet底层
7.要求
9.LinkedHashSet的使用
10.TreeSet()的使用
11.Map接口
1.HashMap
2.LinkedHashMap
3.TreeMap
4.Hashtable
5.Properties
12.Map的键与值
13.HashMap的底层实现原理
1.以jdk7说明
2.jdk8和jdk7的不同
3.HashMap的默认值
14.Map接口中常用的方法
15.遍历Map的方法
16.TreeMap
17.Collections工具类
19.Collection和Collections的区别
1.Java容器概述
1.集合、数组都是对多个数据进行存储的结构,简称java容器。
此时的存储:主要是内存层面的存储,不涉及到持久化(硬盘方面)的存储
2.数组在存储多个数据方面的特点:
一旦初始化后,长度就确定了,元素的类型也确定了;
3.数组存储多个数据方面的缺点:
1.初始化后,其长度无法修改;
2.数组中提供的方法极其有限,对于增删改查操作不方便,效率不高;
3.获取数组中实际元素个数的需求,没有现成的方法可用;
4.数组存储数据的特点:有序、可重复;对于无序、不可重复的需求,不能满足。
2.集合框架
1.Collection接口:单列集合,存储一个一个的对象;分为两大类
List接口:存储有序的、可重复的数据;主要实现类:ArrayList,LinkedList,Vector
Set接口:存储无序的、不可重复的数据;主要实现类:HashSet,LinkedHashSet,TreeSet
2.Map接口:双列集合,存储一对(key-value)的数据
主要实现类:HashMap,LinkedHashMap,TreeMap,Hashtable,Properties
3.Collection接口中的方法使用
1.使用多态造实现类对象赋给Collection集合对象;
2.add(E e):将元素添加到集合中
3.size():获取添加元素的个数
4.addAll(Collection coll):添加一个集合;
5.isEmpty():判断当前集合是否为空
6.clear():清空集合元素
7.contains(O o):判断当前集合中是否包含o
8.containsAll(Collection coll):判断形参coll中所有元素是否都存在于当前集合中
9.remove(Object o):删除obj数据
10.removeAll(Collection c):删除c中包含的所有元素;获取与c集合之间的差集
11.retainAll(Collection c):获取与c集合之间的交集
12.equals(Object o):判断两个集合所有的元素是否相同,是返回true
13.hashCode():调用集合的哈希值
14.toArray():集合转化为数组
15.将数组转换为集合:Arrays.asList(String[])
注意:包装类数组与基本数据类型数组的区别
若写为一个基本数据类型的数组则为一个元素,而不是识别为数组;写成包装类就会识别为数组中的多个元素。
Iterator iterator = c.iterator();//hasNext():判断是否还有下一个元素while (iterator.hasNext()) {//next():两个作用:指针下移;返回下移以后的集合位置上的元素System.out.println(iterator.next());}重要:add和contains方法调用的是obj对象所在类的equals()方法;若未重写即为false;因此向Collection的接口实现类的对象中添加数据obj时,要求obj所在类要重写equals()方法。
4.iterator()
返回Iterator接口的实例,用于遍历集合元素;
1.使用hasNext()+next()方法。使用next()时指针下移,并将下移后对应的集合元素返回。
2.集合对象每次调用hasNext()都会得到一个全新的迭代器对象,默认游标都在集合第一个元素之上。
Iterator iterator = c.iterator();//hasNext():判断是否还有下一个元素while (iterator.hasNext()) {//next():两个作用:指针下移;返回下移以后的集合位置上的元素System.out.println(iterator.next());}3.内部定义了remove()方法;删除遍历后集合中的元素,此方法不同于集合中调用的remove;
4.jdk5.0后使用foreach,用于遍历集合、数组;也叫做增强for循环
ArrayList a = new ArrayList();
//增强for循环
for(Object obj : a){System.out.println(obj);
}//for遍历
for (int i = 0; i < a.size(); i++) {System.out.println(a.get(i));
}//iterator迭代器
Iterator iterator = a.iterator();
while(iterator.hasNext()){System.out.println(iterator.next());
}5.List接口
看作是数组的替换,动态数组
1.存储有序的、可重复的数据;有三个实现类ArrayList、LinkedList、Vector
2.ArrayList、LinkedList、Vector相同点
三个类都实现了List接口;存储数据都有序可重复。
3.不同点
1.ArrayList
作为List接口的主要实现类;线程不安全,执行效率比较高;底层使用object[ ]存储。适合查找元素,复杂度较低;不适合插入、删除操作。
2.LinkedList
对于频繁的插入、删除操作,使用此类效率比ArrayList高,底层使用双向链表存储;不适合查找元素,复杂度较高。
3.Vector
作为List接口中的古老实现类,线程安全,效率比较低;底层使用object[ ]存储。
4.Vector源码分析
jdk7和idk8中都是通过Vector()构造器创建对象,底层都创建了长度为10的数组;
在数组容量不够需要扩容方面,默认扩容为原来的数组长度的2倍。
//源码public Vector() {this(10);}5.ArrayList源码分析
1.jdk 7情况下
ArrayList List = new ArrayList();//源码
private static final int DEFAULT_CAPACITY = 10;此时:底层创建了长度是10的object[ ]数组elementData
List.add(123);//elementDatale[0] = new Integer(123); 此时:elementDatale[0] = new Integer(123);
若:List.add()添加到第十一次:
List.add(11); 此时:若此次的添加导致底层eLlementData数组容量不够,则扩容。默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中
结论:建议开发中使用带参的构造器:
ArrayList list = new ArrayList(int capacity)
2.jdk 8中ArrayList的变化:
ArrayList List = new ArrayList();
//源码transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
此时:底层创建了bject[ ]数组,而elementData初始化为{},说明此时的elementData并没有创建
若调用
List.add(123);//elementDatale[0] = new Integer(123); //源码public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;}private static final int DEFAULT_CAPACITY = 10; 此时:第一次调用add(),add()调用底层ensureCapacityInternal()方法,底层传入的最小数组容量为:calculateCapacity(elementData, minCapacity),calculateCapacity()方法返回的是DEFAULT_CAPACITY = 10(没有扩容的情况下);之后将并将数据123添加到elementData
后续的添加和扩容操作与idk 7 一样。
2.3小结:
jdk7中的ArrayList的对象的创建类似于单例模式中的饿汉式,而idk8中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
6.LinkedList源码分析
LinkedList list = new LinkedList();此时:内部声明了Node类型的first和last性,默认值为null
transient Node<E> first;//null
transient Node<E> last;//null向list中封装数据:
List.add(123); 此时:直到往list中封装数据后,开始创建Node对象,将123封装到Node中。
其中,Node定义为:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
LinkedList 对数据的封装,就是说把数据封装成Node 对象;当往list封装数据后,创建Node对象,并根据此时的具体情况创建prev和next属性;
prev属性表示previous-上一个:若此时的元素不是第一个元素,则指向上一个节点
next属性表示下一个:指向下一个节点
item属性:保存了当前节点的值
这几个属性体现了LinkedList的双向链表的说法
6.List中的常用方法
加入了调用索引的方法
1.add(int index,Object o);在index插入o
2.addAll():在index加入一个集合中的所有元素
3.get():获取索引处元素
4.indexOf(Object o):返回o在集合中首次出现位置(若找不到就返回-1)
5.lastIndexOf(Object o):返回o在集合中末次出现位置(不存在就返回-1)
6.remove(int index):删除指定索引处元素
7.set(inded,o):设置指定索引位置元素
8.subList(from,toIndex):返回指定位置集合
7.区分remove删除的是元素还是索引
在List方法中提供了重载的remove删除该索引处元素;
而Collection中删除的是该元素(若Collection无序就不存在索引)
8.Set接口存在三个主要的实现类
set接口中没有额外定义新的方法,使用的都是Collection中声明过的方法。
1.HashSet
set接口的主要实现类;是线程不安全的;可以存储null值;
2.LinkedHashSet
作为HashSet的子类,遍历内部数据时,可以按照添加的顺序遍历
3.TreeSet
可以按照添加的对象指定属性,进行排序。
4.如何理解Set的无序、不可重复特性(以HashSet为例)
无序性:不等于随机性;存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定.添加时是无序的
不可重复性:保证添加的元素按照equals()判断时,不能返回true;即相同的元素只能添加一个。
5.set中添加元素的过程(以HashSet为例)
向HashSet中添加元素a,首先调用a所在类的hashCode方法,计算a的哈希值,此哈希值接着通过某种算法计算出a在HashSet底层数组中的存放位置(即索引位置),判断数组位置上是否已经有元素,如果此位置没有其他元素,则a添加成功;若此位置有其他元素b(或以链表形式存在的多个元素),则比较a与b的hash值,若哈希值不同,则a添加成功,若哈希值相同,则调用a所在类的equals()方法,若equals返回true,则a添加失败,若返回false,则a添加成功。
6.HashSet底层
数组+链表形式。
7.要求
向Set中添加的数据,其所在的类一定要重写hashCode()和equals();重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码(即哈希值)
9.LinkedHashSet的使用
1.LinkedHashSet的使用作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
2.优点:对于频繁的遍历操作,效率高于HashSet()
10.TreeSet()的使用
1.向TreeSet中添加的数据,要求是相同类的对象,不能添加不同类的对象。
2.两种排序方式:自然排序(实现Comparable接口)、定制排序(comparator)
3.自然排序中,比较两个对象是否相同的标准为compareTo()方法返回0;不再是equals()方法
4.定制排序中,比较两个对象是否相同的标准是compare()返回0,不再是equals()方法
//Comparable 自然排序
public class Person implements Comparable {@Overridepublic int compareTo(Object o) {if (o instanceof Person){Person oo = (Person)o;return this.age - (oo.getAge());}else {throw new RuntimeException("输入的类型不一致");}}
}//comparator:定制排序Set set3 = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if (o1 instanceof Person && o2 instanceof Person){Person oo1 = (Person)o1;Person oo2 = (Person)o2;return oo1.getName().compareTo(oo2.getName());}else{throw new RuntimeException("输入的类型不一致。");}}});11.Map接口
1.HashMap
Map的主要实现类;线程不安全的,效率高;可以存储null的key和value。
底层:jdk7之前:数组+链表
jdk8:数组+链表+红黑树
2.LinkedHashMap
保证在遍历map元素时,可以按照添加的顺序实现遍历。
原因:在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,效率高于HashMap
3.TreeMap
可以按照添加的key- value进行排序,实现排序遍历。此时考虑key的自然排序或定制排序。底层使用红黑树。
4.Hashtable
作为古老的实现类;线程安全的,效率低;不能存储null的key和value
5.Properties
常用来处理配置文件。key和value都是String类型。
12.Map的键与值
1.Map当中的key是无序的不可重复的,是使用Set存储的;values也是无序的,但是可以重复,使用Collection存储;而实际上使用put(key,value)时向Map中存储的是一个Entry对象,该对象有两个属性,一个是key,另一个是value,且Entry也是使用Set存储的,无序不可重复。
2.以HashMap为例,key所在的类必须重写equals()和hashCode()方法;values所在的类要重写equals()方法。
3.hashCode方法主要是存的时候效率高一点,在查找值时方便一点。
13.HashMap的底层实现原理
1.以jdk7说明
HashMap被实例化后,底层创建长度为16的一维数组Entry[ ] table。
调用put(key1,value1)后,会先调用key1所在类的hashCode()方法计算key1的哈希值,此哈希值经过计算后得到Entry数组在底层的存放位置:
若此位置为空,则key1-value1添加成功
若此位置不为空,则比较key1和该位置元素(假设为key2-value2)的哈希值:
若key1的哈希值和该元素key2哈希值都不相同,则key1-value1添加成功
若key1的哈希值和该元素key2哈希值相同,则比较key1所在类的equals(key2)方法
若equals()返回false,则key1-value1添加成功
若equals返回true,则value1将value2进行替换
2.jdk8和jdk7的不同
1.new HashMap()后不会创建长度为16的数组Entry[ ] table
2.jdk8 底层使用Node[ ],而不是Entry[ ]
3.调用put方法时,底层创建长度为16的数组
4.jdk7底层结构为数组+链表;
jdk8中的底层结构为数组+链表+红黑树;当数组的某一个索引位置元素以链表形式存在的数据个数大于8且当前数组长度大于64,则将该索引位置上的所有数据改为使用红黑树存储。
3.HashMap的默认值
HashMap的默认容量:16
HashMap的加载因子:0.75
扩容的临界值:容量*加载因子:16*0.75=12
链表形式存在的数据大于8:转化为红黑树
Node被树化时最小的hash表容量:64
14.Map接口中常用的方法
1.put():添加key- value的Node对象
2.putAll(Map m):将m中所有Node添加
3.remove(key):删除指定key的键值对
4.clear():清空当前map
5.get(key):获取key的value
6.containsKey(key):是否包含kry
7.contains Value()
8.size():Node个数
9.isEmpty()
10.equals():两个Map是否相同
15.遍历Map的方法
1.遍历所有的key:keySet()
2.遍历所有的value:values()
3.遍历所有的key-value():entrySet()
代码示例:
@Testpublic void test(){//1.遍历keyMap map = new HashMap();map.put("Tom",12);map.put("Jerry",45);map.put("Mary","AA");System.out.println(map);Set set = map.keySet();Iterator iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}//2.遍历valueCollection c = map.values();System.out.println(c);for (Object o : c){System.out.println(o);}System.out.println("-------------------------------");//3.遍历NodeSet s1 = map.entrySet();Iterator iterator1 = s1.iterator();while(iterator1.hasNext()){Object obj = iterator1.next();Map.Entry entry = (Map.Entry)obj;System.out.println(entry.getKey() + " === " + entry.getValue());}}16.TreeMap
1.向TreeMap中添加key-value,要求key必须由同一个类创建的对象
2.因为要按照key进行排序:自然排序、定制排序
17.Collections工具类
操作Collection和Map的工具类
1.Collections类中提供了synchronizeXxx():该方法可以使指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
2.reverse(List):反转list中元素顺序
3.shuffle():对集合元素随机排序
4.sort():根据自然顺序对指定list元素升序
5.swap():将制定list中的i元素交换为j元素
6.frequency():返回指定集合元素出现次数
7.copy(i,j):将j复制到i
19.Collection和Collections的区别
Collection是单列集合的接口,子接口有List和Set;
Collections是操作Collection和Map的工具类。
相关文章:

Java容器-集合
目录 1.Java容器概述 2.集合框架 3.Collection接口中的方法使用 4.iterator() 5.List接口 2.ArrayList、LinkedList、Vector相同点 3.不同点 1.ArrayList 2.LinkedList 3.Vector 4.Vector源码分析 5.ArrayList源码分析 6.LinkedList源码分析 6.List中的常用方法 …...
总结890
学习目标: 月目标:6月(线性代数强化9讲2遍,背诵15篇短文,考研核心词过三遍) 周目标:线性代数强化3讲,英语背3篇文章并回诵,检测 每日必复习(5分钟ÿ…...

2023年5月青少年机器人技术等级考试理论综合试卷(二级)
青少年机器人技术等级考试理论综合试卷(二级)2023.6 分数: 100 题数: 45 一、 单选题(共 30 题, 共 60 分) 1.下图中的凸轮机构使用了摆动型从动件的是? ( ) A.a B.b C.c D.d 试题类…...

2023CCPC河南省赛 VP记录
感觉现在的xcpc,风格越来越像CF,不是很喜欢,还是更喜欢多点算法题的比赛 VP银了,VP银也是银 感觉省赛都是思维题,几乎没有算法题,感觉像打了场大型的CF B题很简单没开出来,一直搞到最后&…...
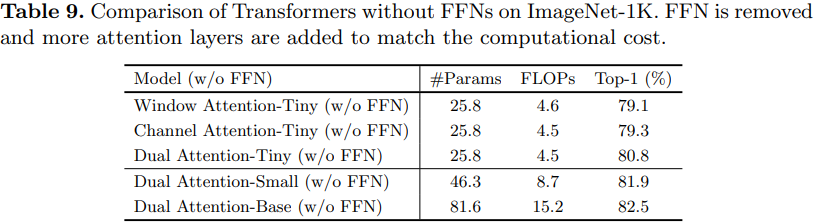
【ECCV2022】DaViT: Dual Attention Vision Transformers
DaViT: Dual Attention Vision Transformers, ECCV2022 解读:【ECCV2022】DaViT: Dual Attention Vision Transformers - 高峰OUC - 博客园 (cnblogs.com) DaViT:双注意力Vision Transformer - 知乎 (zhihu.com) DaViT: Dual Attention Vision Trans…...

Apache 配置与应用
Apache 配置与应用 一、构建虚拟 Web 主机httpd服务支持的虚拟主机类型包括以下三种: 二、基于域名的虚拟主机1.为虚拟主机提供域名解析方法一:部署DNS域名解析服务器 来提供域名解析方法二:在/etc/hosts 文件中临时配置域名与IP地址的映射关…...
OpenGL 纹理
1.简介 纹理是一个2D图片(甚至也有1D和3D的纹理),它可以用来添加物体的细节;你可以想象纹理是一张绘有砖块的纸,无缝折叠贴合到你的3D的房子上,这样你的房子看起来就像有砖墙外表了。 为了能够把纹理映射(M…...

Jeston Orin Nnao 安装pytorch与torchvision环境
大家好,我是虎哥,Jeston Orin nano 8G模块,提供高达 40 TOPS 的 AI 算力,安装好了Jetpack5.1之后,我们需要配置一些支持环境,来为我们后续的深度学习开发提供支持。本章内容,我将主要围绕安装对…...

ROS:常用可视化工具的使用
目录 一、日志输出工具——rqt_console二、绘制数据曲线——rqt_plot三、图像渲染工具——rqt_image_view四、图形界面总接口——rqt五、Rviz六、Gazebo 一、日志输出工具——rqt_console 启动海龟键盘控制节点,打开日志输出工具 roscorerosrun turtlesim turtles…...
智能应用搭建平台——LCHub低代码表单 vs 流程表单 vs 仪表盘
1. LCHub低代码如何选择 「流程表单」:填报数据,并带有流程审批功能,适合报销、请假申请或其他工作流; 「表单」:填报数据,并带有数据协作功能,如修改、删除、导入、导出,并可以给不同的人不同的管理权限; 「仪表盘」:数据分析处理、结果展示功能,如数据汇总、趋…...
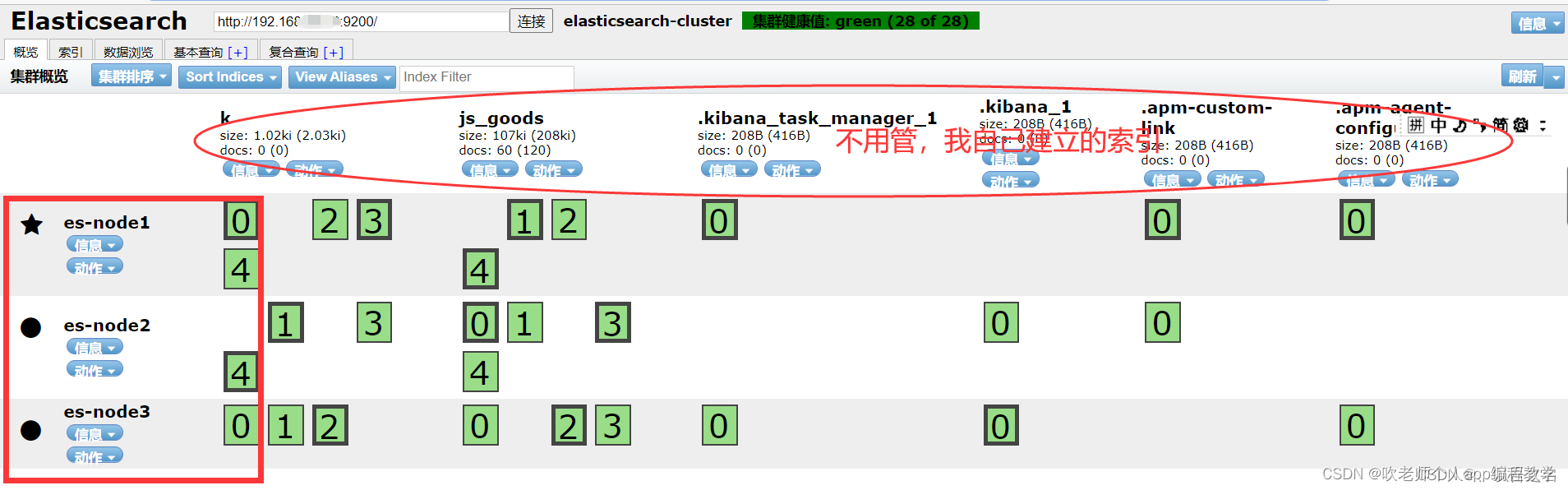
Mac下通过Docker安装ElasticSearch集群
1、安装ElasticSearch 使用docker直接获取es镜像,执行命令docker pull elasticsearch:7.7.0 执行完成后,执行docker images即可看到上一步拉取的镜像。 2、创建数据挂在目录,以及配置ElasticSearch集群配置文件 创建数据文件挂载目录 mkdir -…...

MySQL redo log、undo log、binlog
MySQL是一个广泛使用的关系型数据库管理系统,它通过一系列的日志来保证数据的一致性和持久性。在MySQL中,有三个重要的日志组件,它们分别是redo log(重做日志)、undo log(回滚日志)和binlog&…...

文件包含漏洞
一、原理解析。 开发人员通常会把可重复使用的函数写到单个文件中,在使用到某些函数时,可直接调用此文件,而无须再次编写,这种调用文件的过程被称为包含。 注意:对于开发人员来讲,文件包含很有用…...

Python 中的 F-Test
文章目录 F 统计量和 P 值方差(ANOVA) 分析中的 F 值 本篇文章介绍 F 统计、F 分布以及如何使用 Python 对数据执行 F-Test 测试。 F 统计量是在方差分析检验或回归分析后获得的数字,以确定两个总体的平均值是否存在显着差异。 它类似于 T 检验的 T 统计量…...

Docker网络模式
一、docker网络概述 1、docker网络实现的原理 Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP, 同时Docker网桥是 每个容器的…...

百度离线资源治理
作者 | 百度MEG离线优化团队 导读 近些年移动互联网的高速发展驱动了数据爆发式的增长,各大公司之间都在通过竞争获得更大的增长空间,大数据计算的效果直接影响到公司的发展,而这背后其实依赖庞大的算力及数据作为支撑,因此在满足…...
C++进阶之继承
文章目录 前言一、继承的概念及定义1.继承概念2.继承格式与访问限定符3.继承基类与派生类的访问关系变化4.总结 二、基类和派生类对象赋值转换基本概念与规则 三、继承中的作用域四、派生类的默认成员函数五、继承与友元六、继承与静态成员六、复杂的菱形继承及菱形虚拟继承七、…...
在 Transformers 中使用约束波束搜索引导文本生成
引言 本文假设读者已经熟悉文本生成领域波束搜索相关的背景知识,具体可参见博文 如何生成文本: 通过 Transformers 用不同的解码方法生成文本。 与普通的波束搜索不同,约束 波束搜索允许我们控制所生成的文本。这很有用,因为有时我们确切地知…...

Centos7更换OpenSSL版本
OpenSSL 1.1.0 用户应升级至 1.1.0aOpenSSL 1.0.2 用户应升级至 1.0.2iOpenSSL 1.0.1 用户应升级至 1.0.1u 查看openssl版本 openssl version -v选择升级版本 我的版本是OpenSSL 1.0.2系列,所以要升级1.0.2i https://www.openssl.org/source/old/1.0.2/openssl-…...
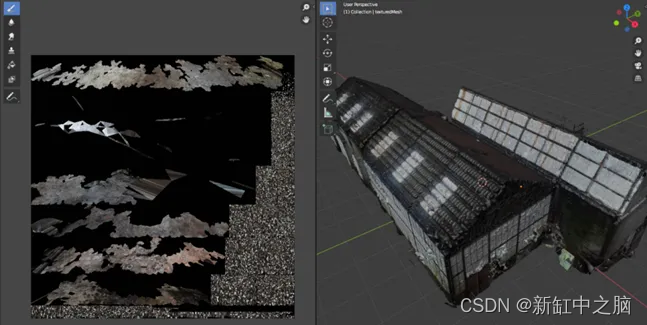
基于摄影测量的三维重建【终极指南】
我们生活的时代非常令人兴奋,如果你对 3D 东西感兴趣,更是如此。 我们有能力使用任何相机,从感兴趣的物体中捕捉一些图像数据,并在眨眼间将它们变成 3D 资产! 这种通过简单的数据采集阶段进行的 3D 重建过程是许多行业…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...
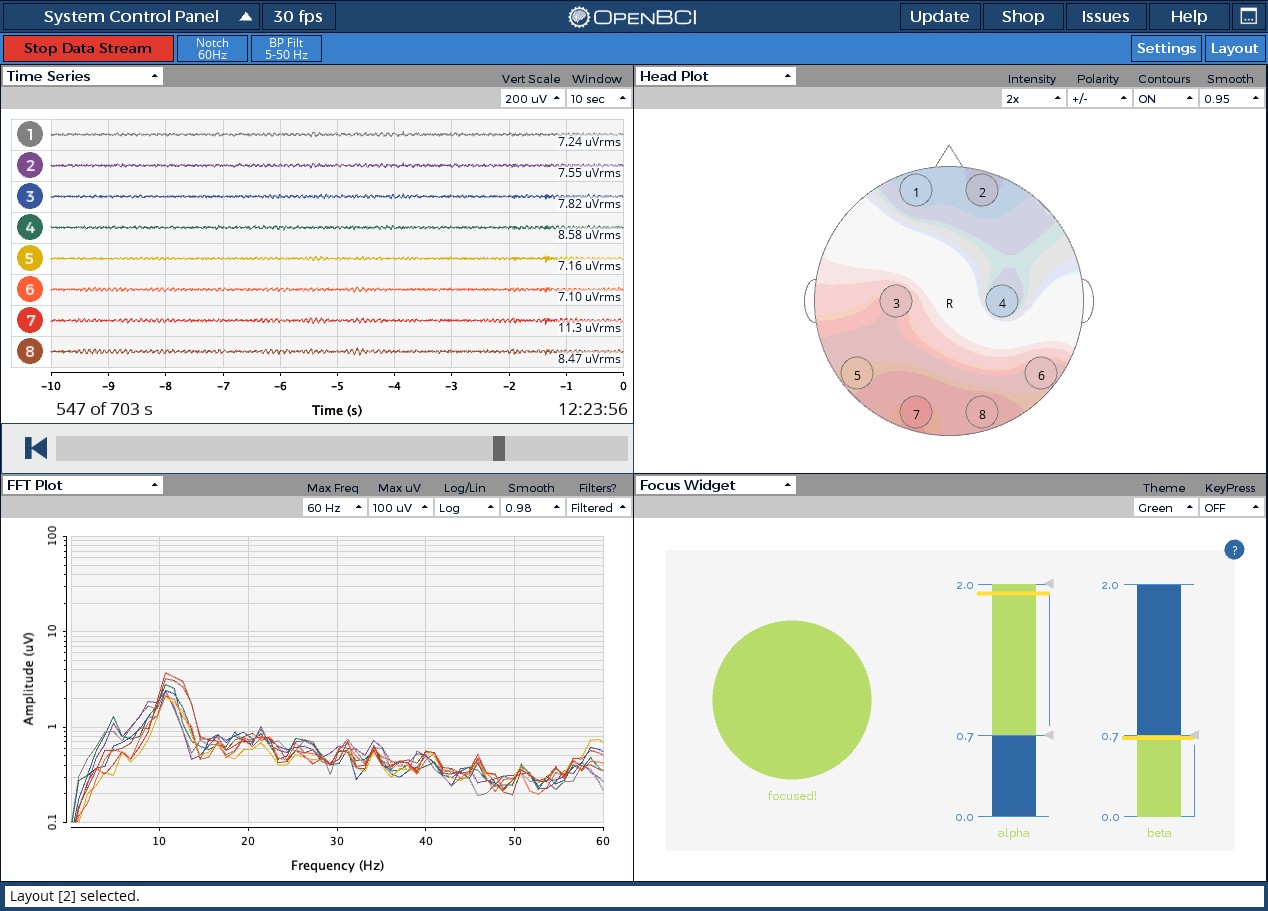
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...
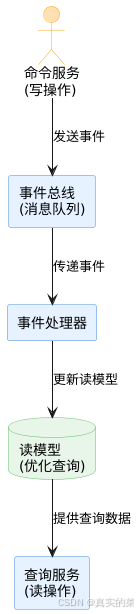
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...