超全、超详细的Redis学习笔记总结
❤ 作者主页:欢迎来到我的技术博客😎
❀ 个人介绍:大家好,本人热衷于Java后端开发,欢迎来交流学习哦!( ̄▽ ̄)~*
🍊 如果文章对您有帮助,记得关注、点赞、收藏、评论⭐️⭐️⭐️
📣 您的支持将是我创作的动力,让我们一起加油进步吧!!!🎉🎉
一、Redis简单介绍
Redis是一种键值型的NoSql数据库,这里有两个关键字:
- 键值型
- NoSql
其中键值型,是指Redis中存储的数据都是以key.value对的形式存储,而value的形式多种多样,可以是字符串.数值.甚至json:
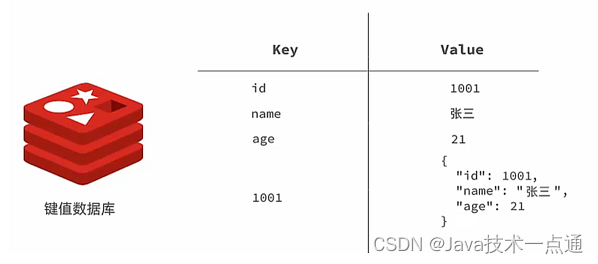
而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
对于存储的数据,没有类似Mysql那么严格的约束,比如唯一性,是否可以为null等等,所以我们把这种松散结构的数据库,称之为NoSQL数据库。
二、初始Redis
2.1 认识NoSQL
NoSql可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
2.1.1 结构化与非结构化
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,插入的数据必须遵守这些约束:
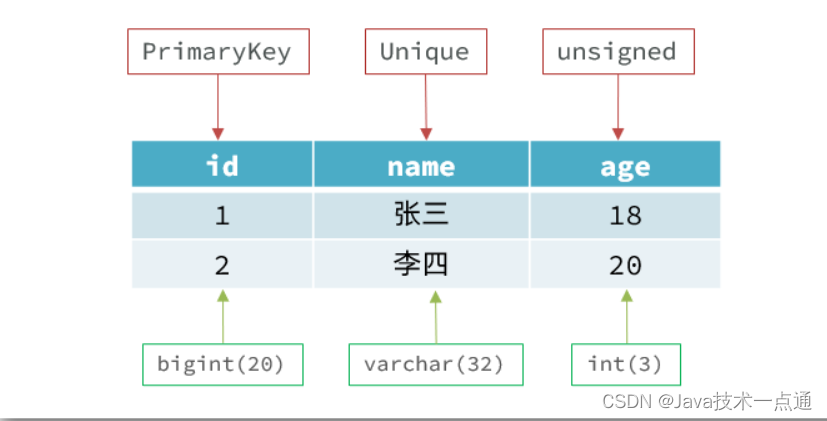
而NoSql则对数据库格式没有严格约束,往往形式松散,自由。
- 可以是键值型:
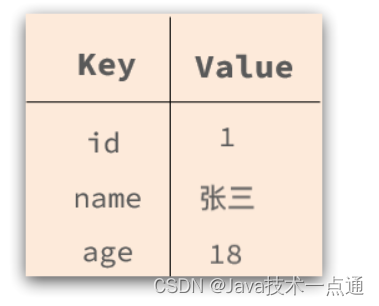
-
也可以是文档型

-
甚至可以是图格式
2.1.2 关联和非关联
传统数据库的表与表之间往往存在关联,例如外键:

而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
{id: 1,name: "张三",orders: [{id: 1,item: {id: 10, title: "荣耀6", price: 4999}},{id: 2,item: {id: 20, title: "小米11", price: 3999}}]
}
此处要维护“张三”的订单与商品“荣耀”和“小米11”的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
2.1.3 查询方式
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。
2.1.4 事务
传统关系型数据库能满足事务ACID的原则。
而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
2.1.5 总结
除了上述四点以外,在存储方式、扩展性和查询性能上关系型与非关系型也都有着显著差异,总结如下:
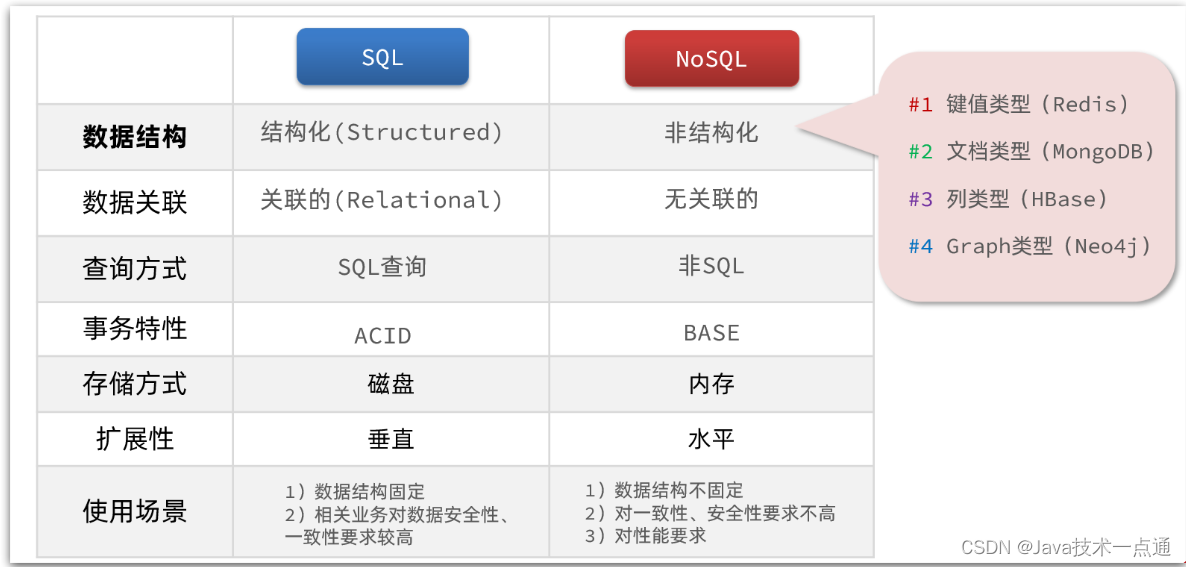
- 存储方式
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响。
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些。
- 扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦。
2.2 认识Redis
Redis诞生于2009年全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存.IO多路复用.良好的编码)。
- 支持数据持久化
- 支持主从集群.分片集群
- 支持多语言客户端
Redis的官方网站地址:https://redis.io/
2.3 安装Redis
大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包。因此课程中我们会基于Linux系统来安装Redis。
此处选择的Linux版本为CentOS 7。
2.4 Redis桌面客户端
安装完成Redis,我们就可以操作Redis,实现数据的CRUD了。这需要用到Redis客户端,包括:
- 命令行客户端
- 图形化桌面客户端
- 编程客户端
2.4.1 Redis命令行客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
redis-cli [options] [commonds]
其中常见的options有:
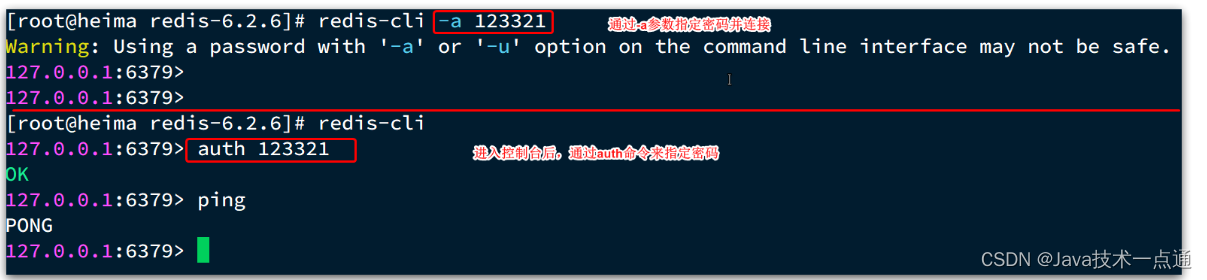
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123321:指定redis的访问密码
其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong
不指定commond时,会进入redis-cli的交互控制台:
2.4.2 图形化桌面客户端
GitHub上的大神编写了Redis的图形化桌面客户端,地址:https://github.com/uglide/RedisDesktopManager
不过该仓库提供的是RedisDesktopManager的源码,并未提供windows安装包。
在下面这个仓库可以找到安装包:https://github.com/lework/RedisDesktopManager-Windows/releases
2.4.3 安装
对压缩包进行解压安装即可。
2.4.4 建立连接
点击左上角的连接到Redis服务器按钮:

在弹出的窗口中填写Redis服务信息:

点击确定后,在左侧菜单会出现这个链接:

点击即可建立连接了。

Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库:
# 选择 0号库
select 0
三、Redis 5 种基本数据结构详解
3.1 Redis
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样:

Redis为了方便我们学习,将操作不同数据类型的命令也做了分组,在官网 https://redis.io/commands 可以查看到不同的命令:
当然我们也可以通过Help命令来帮助我们去查看命令:
3.2 Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
- KEYS:查看符合模板的所有key
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
通过help [command] 可以查看一个命令的具体用法,例如:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YXngkfyo-1677123284850)(assets/1652887865189.png)]](https://img-blog.csdnimg.cn/2da1caafca864635bef169b94e1fc41c.png)
- KEYS
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379># 查询以a开头的key
127.0.0.1:6379> keys a*
1) "age"
127.0.0.1:6379>
贴心小提示:在生产环境下,不推荐使用keys 命令,因为这个命令在key过多的情况下,效率不高
- DEL
127.0.0.1:6379> help delDEL key [key ...]summary: Delete a keysince: 1.0.0group: generic127.0.0.1:6379> del name #删除单个
(integer) 1 #成功删除1个127.0.0.1:6379> keys *
1) "age"127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3 #批量添加数据
OK127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
4) "age"127.0.0.1:6379> del k1 k2 k3 k4
(integer) 3 #此处返回的是成功删除的key,由于redis中只有k1,k2,k3 所以只成功删除3个,最终返回
127.0.0.1:6379>127.0.0.1:6379> keys * #再查询全部的key
1) "age" #只剩下一个了
127.0.0.1:6379>
- EXISTS
127.0.0.1:6379> help EXISTSEXISTS key [key ...]summary: Determine if a key existssince: 1.0.0group: generic127.0.0.1:6379> exists age
(integer) 1127.0.0.1:6379> exists name
(integer) 0
- EXPIRE
贴心小提示:内存非常宝贵,对于一些数据,我们应当给他一些过期时间,当过期时间到了之后,他就会自动被删除。
127.0.0.1:6379> expire age 10
(integer) 1127.0.0.1:6379> ttl age
(integer) 8127.0.0.1:6379> ttl age
(integer) 6127.0.0.1:6379> ttl age
(integer) -2127.0.0.1:6379> ttl age
(integer) -2 #当这个key过期了,那么此时查询出来就是-2 127.0.0.1:6379> keys *
(empty list or set)127.0.0.1:6379> set age 10 #如果没有设置过期时间
OK127.0.0.1:6379> ttl age
(integer) -1 # ttl的返回值就是-1
3.3 String(字符串)
3.3.1 介绍
String 是 Redis 中最简单同时也是最常用的一个数据结构。
String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
3.3.2 常用命令
| 命令 | 说明 |
|---|---|
| SET key value | 设置指定 key 的值 |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| GET key | 获取指定 key 的值 |
| MSET key1 value1 key2 value2 … | 设置一个或多个指定 key 的值 |
| MGET key1 key2 … | 获取一个或多个指定 key 的值 |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
| INCR key | 将 key 中储存的数字值增一 |
| DECR key | 将 key 中储存的数字值减一 |
| EXISTS key | 判断指定 key 是否存在 |
| DEL key(通用) | 删除指定的 key |
| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=string
- LPUSH和RPUSH
127.0.0.1:6379> LPUSH users 1 2 3
(integer) 3
127.0.0.1:6379> RPUSH users 4 5 6
(integer) 6
- LPOP和RPOP
127.0.0.1:6379> LPOP users
"3"
127.0.0.1:6379> RPOP users
"6"
- LRANGE
127.0.0.1:6379> LRANGE users 1 2
1) "1"
2) "4"
3.3.3 应用场景
-
需要存储常规数据的场景
- 举例 :缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
- 相关命令 : SET、GET。
-
需要计数的场景
- 举例 :用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
- 相关命令 :SET、GET、 INCR、DECR 。
-
分布式锁
利用SETNX key value命令可以实现一个最简易的分布式锁(存在一些缺陷,通常不建议这样实现分布式锁)。
3.4 List(列表)
3.4.1 介绍
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
3.4.2 常用命令
| 命令 | 介绍 |
|---|---|
| RPUSH key value1 value2 … | 在指定列表的尾部(右边)添加一个或多个元素 |
| LPUSH key value1 value2 … | 在指定列表的头部(左边)添加一个或多个元素 |
| LSET key index value | 将指定列表索引 index 位置的值设置为 value |
| LPOP key | 移除并获取指定列表的第一个元素(最左边) |
| RPOP key | 移除并获取指定列表的最后一个元素(最右边) |
| LLEN key | 获取列表元素数量 |
| LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
画了一个图方便大家理解 RPUSH , LPOP , lpush , RPOP 命令:

更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=list
- LPUSH和RPUSH
127.0.0.1:6379> LPUSH users 1 2 3
(integer) 3
127.0.0.1:6379> RPUSH users 4 5 6
(integer) 6
- LPOP和RPOP
127.0.0.1:6379> LPOP users
"3"
127.0.0.1:6379> RPOP users
"6"
- LRANGE
127.0.0.1:6379> LRANGE users 1 2
1) "1"
2) "4"
3.4.3 应用场景
-
信息流展示
- 举例 :最新文章、最新动态。
- 相关命令 : LPUSH、LRANGE。
-
消息队列
- Redis List 数据结构可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
3.5 Hash(哈希)
3.5.1 介绍
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
3.5.2 常用命令
| 命令 | 介绍 |
|---|---|
| HSET key field value | 设置指定哈希表中指定字段的值 |
| HSETNX key field value | 只有指定字段不存在时设置指定字段的值 |
| HMSET key field1 value1 field2 value2 … | 同时将一个或多个 field-value (域-值)对设置到指定哈希表中 |
| HGET key field | 获取指定哈希表中指定字段的值 |
| HMGET key field1 field2 … | 获取指定哈希表中一个或者多个指定字段的值 |
| HGETALL key | 获取指定哈希表中所有的键值对 |
| HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
| HDEL key field1 field2 … | 删除一个或多个哈希表字段 |
| HLEN key | 获取指定哈希表中字段的数量 |
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=hash
- HSET和HGET
127.0.0.1:6379> HSET heima:user:3 name Lucy//大key是 heima:user:3 小key是name,小value是Lucy
(integer) 1
127.0.0.1:6379> HSET heima:user:3 age 21// 如果操作不存在的数据,则是新增
(integer) 1
127.0.0.1:6379> HSET heima:user:3 age 17 //如果操作存在的数据,则是修改
(integer) 0
127.0.0.1:6379> HGET heima:user:3 name
"Lucy"
127.0.0.1:6379> HGET heima:user:3 age
"17"
- HMSET和HMGET
127.0.0.1:6379> HMSET heima:user:4 name HanMeiMei
OK
127.0.0.1:6379> HMSET heima:user:4 name LiLei age 20 sex man
OK
127.0.0.1:6379> HMGET heima:user:4 name age sex
1) "LiLei"
2) "20"
3) "man"
- HGETALL
127.0.0.1:6379> HGETALL heima:user:4
1) "name"
2) "LiLei"
3) "age"
4) "20"
5) "sex"
6) "man"
- HKEYS和HVALS
127.0.0.1:6379> HKEYS heima:user:4
1) "name"
2) "age"
3) "sex"
127.0.0.1:6379> HVALS heima:user:4
1) "LiLei"
2) "20"
3) "man"
- HINCRBY
127.0.0.1:6379> HINCRBY heima:user:4 age 2
(integer) 22
127.0.0.1:6379> HVALS heima:user:4
1) "LiLei"
2) "22"
3) "man"
127.0.0.1:6379> HINCRBY heima:user:4 age -2
(integer) 20
- HSETNX
127.0.0.1:6379> HSETNX heima:user4 sex woman
(integer) 1
127.0.0.1:6379> HGETALL heima:user:3
1) "name"
2) "Lucy"
3) "age"
4) "17"
127.0.0.1:6379> HSETNX heima:user:3 sex woman
(integer) 1
127.0.0.1:6379> HGETALL heima:user:3
1) "name"
2) "Lucy"
3) "age"
4) "17"
5) "sex"
6) "woman"
3.5.3 应用场景
- 对象数据存储场景
- 举例 :用户信息、商品信息、文章信息、购物车信息。
- 相关命令 :HSET (设置单个字段的值)、HMSET(设置多个字段的值)、HGET(获取单个字段的值)、HMGET(获取多个字段的值)。
3.6 Set(集合)
3.6.1 介绍
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
你可以基于 Set 轻易实现 交集、并集、差集 的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
3.6.2 常见命令
| 命令 | 介绍 |
|---|---|
| SADD key member1 member2 … | 向指定集合添加一个或多个元素 |
| SMEMBERS key | 获取指定集合中的所有元素 |
| SCARD key | 获取指定集合的元素数量 |
| SISMEMBER key member | 判断指定元素是否在指定集合中 |
| SINTER key1 key2 … | 获取给定所有集合的交集 |
| SINTERSTORE destination key1 key2 … | 将给定所有集合的交集存储在 destination 中 |
| SUNION key1 key2 … | 获取给定所有集合的并集 |
| SUNIONSTORE destination key1 key2 … | 将给定所有集合的并集存储在 destination 中 |
| SDIFF key1 key2 … | 获取给定所有集合的差集 |
| SDIFFSTORE destination key1 key2 … | 将给定所有集合的差集存储在 destination 中 |
| SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=set
127.0.0.1:6379> sadd s1 a b c
(integer) 3
127.0.0.1:6379> smembers s1
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> srem s1 a
(integer) 1127.0.0.1:6379> SISMEMBER s1 a
(integer) 0127.0.0.1:6379> SISMEMBER s1 b
(integer) 1127.0.0.1:6379> SCARD s1
(integer) 2
案例
- 将下列数据用Redis的Set集合来存储:
- 张三的好友有:李四.王五.赵六
- 李四的好友有:王五.麻子.二狗
- 利用Set的命令实现下列功能:
- 计算张三的好友有几人
- 计算张三和李四有哪些共同好友
- 查询哪些人是张三的好友却不是李四的好友
- 查询张三和李四的好友总共有哪些人
- 判断李四是否是张三的好友
- 判断张三是否是李四的好友
- 将李四从张三的好友列表中移除
127.0.0.1:6379> SADD zs lisi wangwu zhaoliu
(integer) 3127.0.0.1:6379> SADD ls wangwu mazi ergou
(integer) 3127.0.0.1:6379> SCARD zs
(integer) 3127.0.0.1:6379> SINTER zs ls
1) "wangwu"127.0.0.1:6379> SDIFF zs ls
1) "zhaoliu"
2) "lisi"127.0.0.1:6379> SUNION zs ls
1) "wangwu"
2) "zhaoliu"
3) "lisi"
4) "mazi"
5) "ergou"127.0.0.1:6379> SISMEMBER zs lisi
(integer) 1127.0.0.1:6379> SISMEMBER ls zhangsan
(integer) 0127.0.0.1:6379> SREM zs lisi
(integer) 1127.0.0.1:6379> SMEMBERS zs
1) "zhaoliu"
2) "wangwu"
3.6.3 应用场景
-
需要存放的数据不能重复的场景
- 举例:网站 UV 统计(数据量巨大的场景还是 HyperLogLog更适合一些)、文章点赞、动态点赞等场景。
- 相关命令:SCARD(获取集合数量) 。
-
需要获取多个数据源交集、并集和差集的场景
- 举例 :共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集) 、订阅号推荐(差集+交集) 等场景。
- 相关命令:SINTER(交集)、SINTERSTORE (交集)、SUNION (并集)、SUNIONSTORE(并集)、SDIFF(差集)、SDIFFSTORE (差集)。
-
需要随机获取数据源中的元素的场景
- 举例 :抽奖系统、随机。
- 相关命令:SPOP(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、SRANDMEMBER(随机获取集合中的元素,适合允许重复中奖的场景)。
3. 7 Sorted Set(有序集合)
3.7.1 介绍
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
3.7.2 常用命令
| 命令 | 介绍 |
|---|---|
| ZADD key score1 member1 score2 member2 … | 向指定有序集合添加一个或多个元素 |
| ZCARD KEY | 获取指定有序集合的元素数量 |
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
| ZINTERSTORE destination numkeys key1 key2 … | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
| ZUNIONSTORE destination numkeys key1 key2 … | 求并集,其它和 ZINTERSTORE 类似 |
| ZDIFF destination numkeys key1 key2 … | 求差集,其它和 ZINTERSTORE 类似 |
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set
3.7.3 应用场景
-
需要随机获取数据源中的元素根据某个权重进行排序的场景
- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
- 相关命令 :ZRANGE (从小到大排序) 、 ZREVRANGE (从大到小排序)、ZREVRANK (指定元素排名)。
-
需要存储的数据有优先级或者重要程度的场景 比如优先级任务队列。
- 举例 :优先级任务队列。
- 相关命令 :ZRANGE (从小到大排序) 、 ZREVRANGE (从大到小排序)、ZREVRANK (指定元素排名)。
四、Redis 3 种特殊数据结构详解
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构 :Bitmap、HyperLogLog、GEO。
4.1 Bitmap
4.1.1 介绍
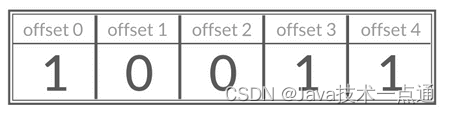
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
4.1.2 常用命令
| 命令 | 说明 |
|---|---|
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 … | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
SETBIT mykey 7 1
(integer) 0
SETBIT mykey 7 0
(integer) 1
GETBIT mykey 7
(integer) 0
SETBIT mykey 6 1
(integer) 0
SETBIT mykey 8 1
(integer) 0
# 通过 bitcount 统计被被设置为 1 的位的数量。
BITCOUNT mykey
(integer) 2
4.1.3 应用场景
-
需要保存状态信息(0/1 即可表示)的场景
- 举例 :用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令 :SETBIT、GETBIT、BITCOUNT、BITOP。
4.2 HyperLogLog
4.2.1 介绍
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 2 64 2^{64} 264个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵 :计数较少的时候,占用空间很小。
- 稠密矩阵 :计数达到某个阈值的时候,占用 12k 的空间。
基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 0.81% 。)。
4.2.2 常见命令
| 命令 | 说明 |
|---|---|
| PFADD key element1 element2 … | 添加一个或多个元素到 |
| HyperLogLog 中PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 … | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
PFADD hll foo bar zap
(integer) 1
PFADD hll zap zap zap
(integer) 0
PFADD hll foo bar
(integer) 0
PFCOUNT hll
(integer) 3
PFADD some-other-hll 1 2 3
(integer) 1
PFCOUNT hll some-other-hll
(integer) 6
PFMERGE desthll hll some-other-hll
"OK"
PFCOUNT desthll
(integer) 6
4.2.3 应用场景
-
数量量巨大(百万、千万级别以上)的计数场景
- 举例 :热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
- 相关命令 :PFADD、PFCOUNT 。
4.3 Geospatial index
4.3.1 介绍
Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。
4.3.2 常用命令
| 命令 | 说明 |
|---|---|
| GEOADD key longitude1 latitude1 member1 … | 添加一个或多个元素对应的经纬度信息到 |
| GEO 中GEOPOS key member1 member2 … | 返回给定元素的经纬度信息 |
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
3
GEOPOS personLocation user1
116.3299986720085144
39.89000061669732844
GEODIST personLocation user1 user2 km
1.4018
4.3.3 应用场景
-
需要管理使用地理空间数据的场景
- 举例:附近的人。
- 相关命令: GEOADD、GEORADIUS、GEORADIUSBYMEMBER 。
五、Redis的Java客户端-Jedis
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:

标记为星号的就是推荐使用的Java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map.Queue等,而且支持跨进程的同步机制:Lock.Semaphore等待,比较适合用来实现特殊的功能需求。
5.1 Jedis快速入门
- 创建maven工程
- 引入依赖
<!--jedis-->
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version>
</dependency>
<!--单元测试-->
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.0</version><scope>test</scope>
</dependency>
- 建立连接
private Jedis jedis;@BeforeEach
void setUp() {// 1.建立连接jedis = new Jedis("192.168.150.101", 6379);// 2.设置密码jedis.auth("123321");// 3.选择库jedis.select(0);
}
- 测试
@Test
void testString() {// 存入数据String result = jedis.set("name", "虎哥");System.out.println("result = " + result);// 获取数据String name = jedis.get("name");System.out.println("name = " + name);
}@Test
void testHash() {// 插入hash数据jedis.hset("user:1", "name", "Jack");jedis.hset("user:1", "age", "21");// 获取Map<String, String> map = jedis.hgetAll("user:1");System.out.println(map);
}
- 释放资源
@AfterEach
void tearDown() {if (jedis != null) {jedis.close();}
}
5.2 Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
有关池化思想,并不仅仅是这里会使用,很多地方都有,比如说我们的数据库连接池,比如我们tomcat中的线程池,这些都是池化思想的体现。
5.2.1 创建Jedis连接池
public class JedisConnectionFacotry {private static final JedisPool jedisPool;static {//配置连接池JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);poolConfig.setMaxIdle(8);poolConfig.setMinIdle(0);poolConfig.setMaxWaitMillis(1000);//创建连接池对象jedisPool = new JedisPool(poolConfig,"192.168.150.101",6379,1000,"123321");}public static Jedis getJedis(){return jedisPool.getResource();}
}
代码说明:
-
(1) JedisConnectionFacotry:工厂设计模式是实际开发中非常常用的一种设计模式,我们可以使用工厂,去降低代的耦合,比如Spring中的Bean的创建,就用到了工厂设计模式。
-
(2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对 连接池的初始化。
-
(3)最后提供返回连接池中连接的方法。
5.2.2 改造原始代码
-
在我们完成了使用工厂设计模式来完成代码的编写之后,我们在获得连接时,就可以通过工厂来获得。而不用直接去new对象,降低耦合,并且使用的还是连接池对象。
-
当我们使用了连接池后,当我们关闭连接其实并不是关闭,而是将Jedis还回连接池的。
@BeforeEachvoid setUp(){//建立连接/*jedis = new Jedis("127.0.0.1",6379);*/jedis = JedisConnectionFacotry.getJedis();//选择库jedis.select(0);}@AfterEachvoid tearDown() {if (jedis != null) {jedis.close();}}
六、Redis的Java客户端-SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
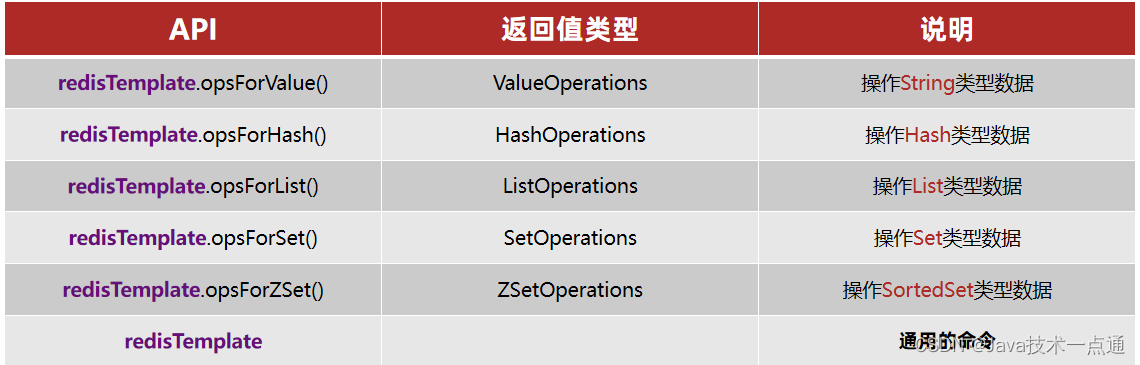
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:
6.1 快速入门
- 创建一个springboot工程
- 引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.7</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.heima</groupId><artifactId>redis-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>redis-demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><!--redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--common-pool--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency><!--Jackson依赖--><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
- 配置文件
spring:redis:host: 192.168.150.101port: 6379password: 123321lettuce:pool:max-active: 8 #最大连接max-idle: 8 #最大空闲连接min-idle: 0 #最小空闲连接max-wait: 100ms #连接等待时间
- 测试
@SpringBootTest
class RedisDemoApplicationTests {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Testvoid testString() {// 写入一条String数据redisTemplate.opsForValue().set("name", "虎哥");// 获取string数据Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}
}
贴心小提示:SpringDataJpa使用起来非常简单,记住如下几个步骤即可
SpringDataRedis的使用步骤:
- 引入spring-boot-starter-data-redis依赖
- 在application.yml配置Redis信息
- 注入RedisTemplate
6.2 数据序列化器
RedisTemplate可以接收任意Object作为值写入Redis:
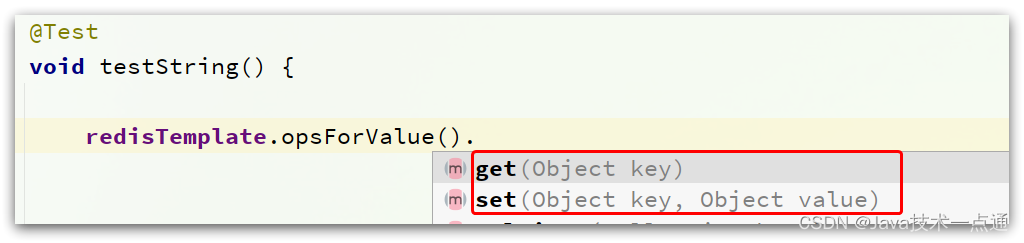
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
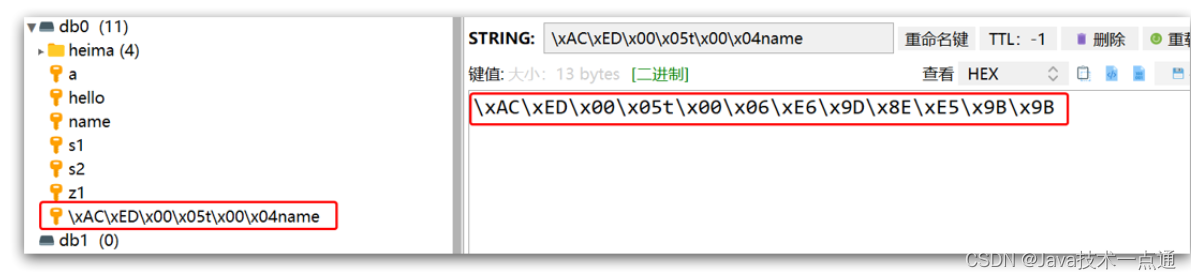
缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){// 创建RedisTemplate对象RedisTemplate<String, Object> template = new RedisTemplate<>();// 设置连接工厂template.setConnectionFactory(connectionFactory);// 创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 设置Key的序列化template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());// 设置Value的序列化template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);// 返回return template;}
}
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:

整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
6.3 StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4BYEW5n7-1677136696795)(.\Redis.assets\1653054602930.png)]](https://img-blog.csdnimg.cn/0601ecce18a742e0a81d99d3a3da8568.png)
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样,在存储value时,我们就不需要在内存中就不用多存储数据,从而节约我们的内存空间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TTSwKca3-1677136696796)(.\Redis.assets\1653054744832.png)]](https://img-blog.csdnimg.cn/33ac68ce16be439e8eb8d2861b76654b.png)
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FklZ4KB8-1677136699000)(null)]](https://img-blog.csdnimg.cn/0adba542c77f46eebbad0fe10fe748db.png)
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@SpringBootTest
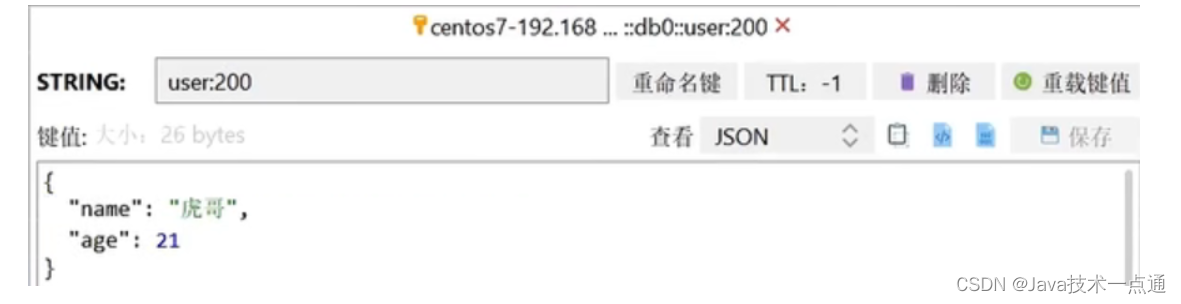
class RedisStringTests {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testvoid testString() {// 写入一条String数据stringRedisTemplate.opsForValue().set("verify:phone:13600527634", "124143");// 获取string数据Object name = stringRedisTemplate.opsForValue().get("name");System.out.println("name = " + name);}private static final ObjectMapper mapper = new ObjectMapper();@Testvoid testSaveUser() throws JsonProcessingException {// 创建对象User user = new User("虎哥", 21);// 手动序列化String json = mapper.writeValueAsString(user);// 写入数据stringRedisTemplate.opsForValue().set("user:200", json);// 获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:200");// 手动反序列化User user1 = mapper.readValue(jsonUser, User.class);System.out.println("user1 = " + user1);}}
此时我们再来看一看存储的数据,小伙伴们就会发现那个class数据已经不在了,节约了我们的空间。
最后小总结:
RedisTemplate的两种序列化实践方案:
-
方案一:
- 自定义RedisTemplate
- 修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer
-
方案二:
- 使用StringRedisTemplate
- 写入Redis时,手动把对象序列化为JSON
- 读取Redis时,手动把读取到的JSON反序列化为对象
6.4 Hash结构操作
这里简单对Hash结构操作一下:
@SpringBootTest
class RedisStringTests {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testvoid testHash() {stringRedisTemplate.opsForHash().put("user:400", "name", "虎哥");stringRedisTemplate.opsForHash().put("user:400", "age", "21");Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");System.out.println("entries = " + entries);}
}
非常感谢您阅读到这里,如果这篇文章对您有帮助,希望能留下您的点赞👍 关注💖 分享👥 留言💬thanks!!!
相关文章:
超全、超详细的Redis学习笔记总结
❤ 作者主页:欢迎来到我的技术博客😎 ❀ 个人介绍:大家好,本人热衷于Java后端开发,欢迎来交流学习哦!( ̄▽ ̄)~* 🍊 如果文章对您有帮助,记得关注、点赞、收藏、…...

Day05 04-MySQL分库分表介绍
文章目录 第十七章 MySQL分库分表17.1 什么是分库分表17.2 为什么要分库分表17.3 垂直切分17.3.1 垂直分库17.3.2 垂直分表 17.4 水平切分17.4.1 水平分库17.4.2 水平分表17.4.3 常见的水平切分规则 第十七章 MySQL分库分表 17.1 什么是分库分表 MySQL数据库常见的优化方案中…...

基于SpringBoot+vue的毕业生信息招聘平台设计和实现
博主介绍: 大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。 我擅长在JavaWeb、SSH、SSM、SpringBoot等框架下…...

git一定要学会,加油
gitgit文档http://file:///F:/%E8%B5%84%E6%96%99%E5%A4%8D%E4%B9%A0/Git%E4%BC%98%E7%A7%80%E5%BC%80%E6%BA%90%E4%B9%A6%E7%B1%8D/Git%E5%BC%80%E6%BA%90%E4%B9%A6%E7%B1%8D/Pro%20Git%E4%B8%AD%E6%96%87PDF%E7%89%88.pdf init 初始化仓库 这个命令在当前目录下初始化一个 G…...

TVM面试题
1、TVM中的调度器(Scheduler)是什么?请简要解释TVM调度器的作用和工作原理。 TVM中的调度器(Scheduler)是负责将计算图映射到特定硬件目标上的组件。调度器在TVM中起着关键的作用,它决定了计算图的执行方式、并行化策略以及内存布局等,以优化…...

CSS相关面试题
1、标准盒子模型和IE怪异盒子模型? 标准盒子模型就是指的元素的宽度和高度仅包括的内容区域,不包括边框和内边距,也就是说,元素的实际宽度和高度等于内容区域的宽度和高度IE怪异盒子是指元素的高度和宽度,包括内容区域…...

6.11总结
这周准备了蓝桥杯,主要看了一些以前学过的东西,看了二分,树状数组,树状数组二分,复习了利用倍增相关的算法。 周六去打的蓝桥杯,总体来说也就一般吧,出了考场突然想起来我b题中间的称号写成了加…...
Hazel游戏引擎(008-009)事件系统
文中若有代码、术语等错误,欢迎指正 文章目录 008、事件系统-设计009、事件系统-自定义事件前言自定义事件类与使用声明与定义类代码包含头文件使用事件 事件调度器代码 C知识:FunctionBind用法function基本使用 012、事件系统-DemoLayer用EventDispache…...
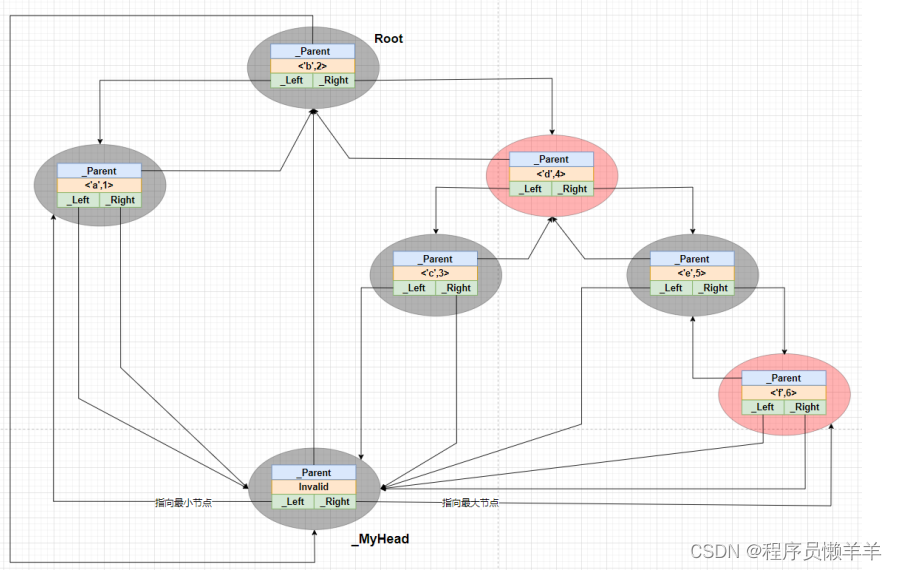
【C++】 STL(上)STL简述、STL容器
文章目录 简述STL容器list链表vector向量deque双端队列map映射表set集合hash_map哈希表 简述 STL是“Standard Template Library”的缩写,中文译为“标准模板库”。STL是C标准库的一部分,位与各个C的头文件中,即他并非以二进制代码的形式提供…...

【002 基础知识】什么是原子操作?
一、原子操作 原子操作就是指不能再进一步分割的操作。 二、为了实现一个互斥,自己定义一个变量作为标记来作为一个资源只有一个使用者行不行? 不行。如果在一个线程正持有锁时(2处),线程上下文发生切换,…...

English Learning - L3 作业打卡 Lesson5 Day32 2023.6.5 周一
English Learning - L3 作业打卡 Lesson5 Day32 2023.6.5 周一 引言🍉句1: What do you read when you are travelling by train or bus?成分划分弱读爆破语调 🍉句2: What are other passengers reading?成分划分弱读连读语调 🍉句3: Perh…...

深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)【上篇】
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…...
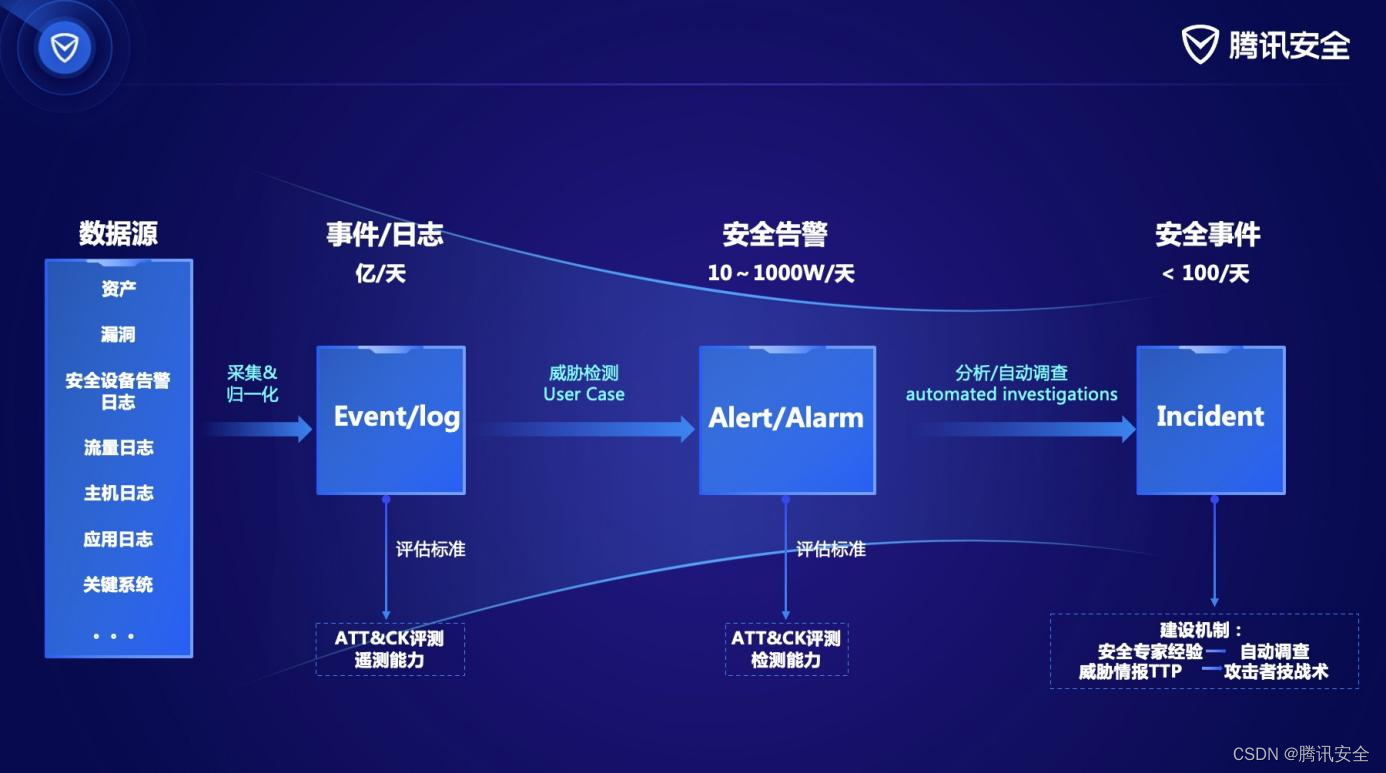
腾讯安全SOC+荣获“鑫智奖”,助力金融业数智化转型
近日,由金科创新社主办,全球金融专业人士协会支持的“2023鑫智奖第五届金融数据智能优秀解决方案评选”榜单正式发布。腾讯安全申报的“SOC基于新一代安全日志大数据平台架构的高级威胁安全治理解决方案”获评“鑫智奖网络信息安全创新优秀解决方案”。 …...

Python绘制气泡图示例
部分数据来源:ChatGPT 引言 在数据可视化领域中,气泡图是一种能够同时展示三维信息的图表类型,常用于表示数据集中的两个变量之间的关系。Python中提供了许多用于绘制气泡图的可视化库,比如pyecharts。在本篇文章中,我们将介绍如何使用pyecharts库绘制一个简单的气泡图,…...

数学建模经历-程序人生
引言 即将大四毕业(现在大三末),闲来无事(为了冲粽子)就写一篇记录数学建模经历的博客吧。其实经常看到一些大佬的博客里会有什么"程序人生"、"人生感想"之类的专栏,但是由于我只是一个小趴菜没什么阅历因此也就没有写过类似的博客…...

数字电子电路绪论
博主介绍:一个爱打游戏的计算机专业学生 博主主页:夏驰和徐策 所属专栏:程序猿之数字电路 1.科技革命促生互联网时代 科技革命对互联网时代的兴起产生了巨大的推动作用。以下是一些科技革命对互联网时代的促进因素: 1. 计算机技…...

电脑丢失dll文件一键修复需要什么软件?快速修复dll文件的方法
在使用电脑的过程中,我们经常会遇到程序无法正常运行的情况,提示“XXX.dll文件丢失”的错误。这时候,很多人会感到困惑,不知道该如何解决。本文将详细介绍dll文件丢失的各种原因、如何使用dll修复工具进行一键修复dll丢失问题以及…...
你知道微信的转账是可以退回的吗
微信作为当今最受欢迎的即时通讯软件之一,其转账功能得到了广泛的应用。在使用微信转账时,我们可能会遇到一些问题,例如误操作、支付失败或者需要退款等等。 首先需要注意的是,微信转账退回的操作只能在“一天内未确认”时进行。如…...
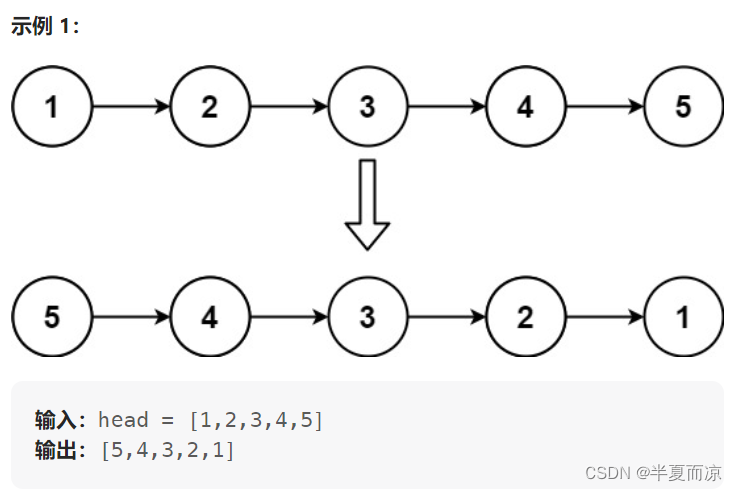
【链表Part01】| 203.移除链表元素、707.设计链表、206.反转链表
目录 ✿LeetCode203.移除链表元素❀ ✿LeetCode707.设计链表❀ ✿LeetCode206.反转链表❀ ✿LeetCode203.移除链表元素❀ 链接:203.移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点ÿ…...

如何使用Postman生成curl?
生成在Lunix系统调接口的curl 直接看图操作 点击</>即可!...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...
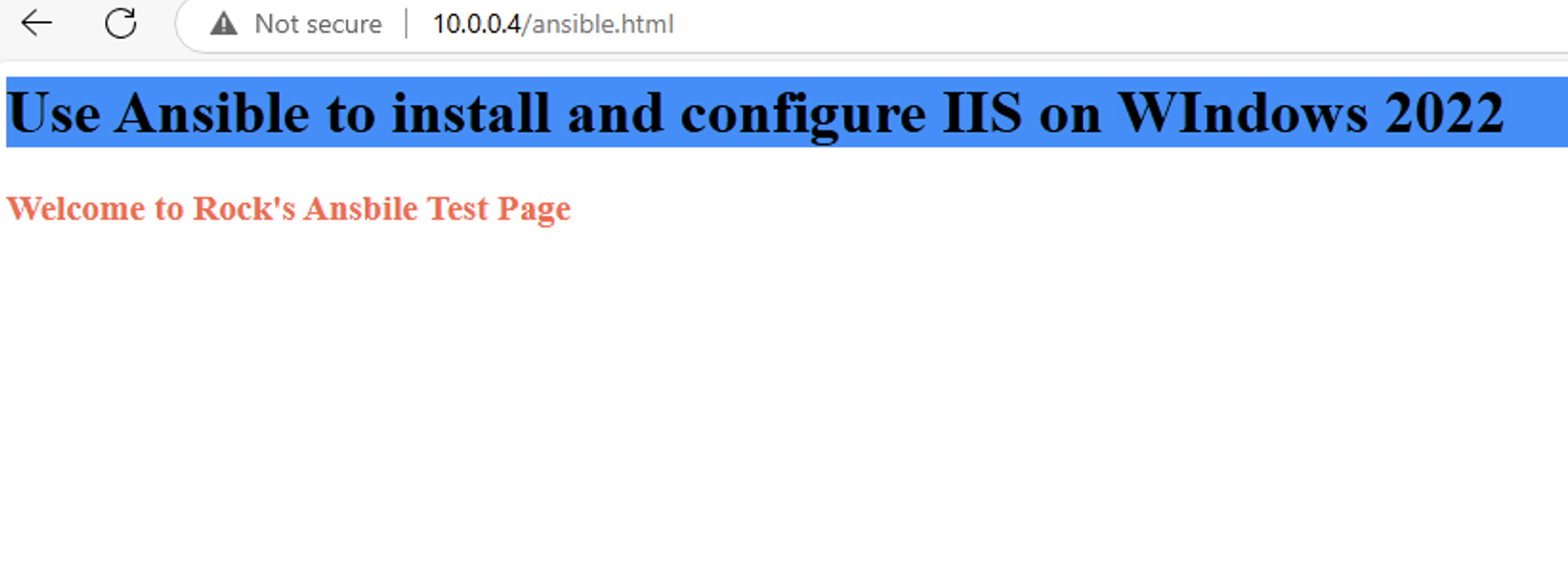
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...
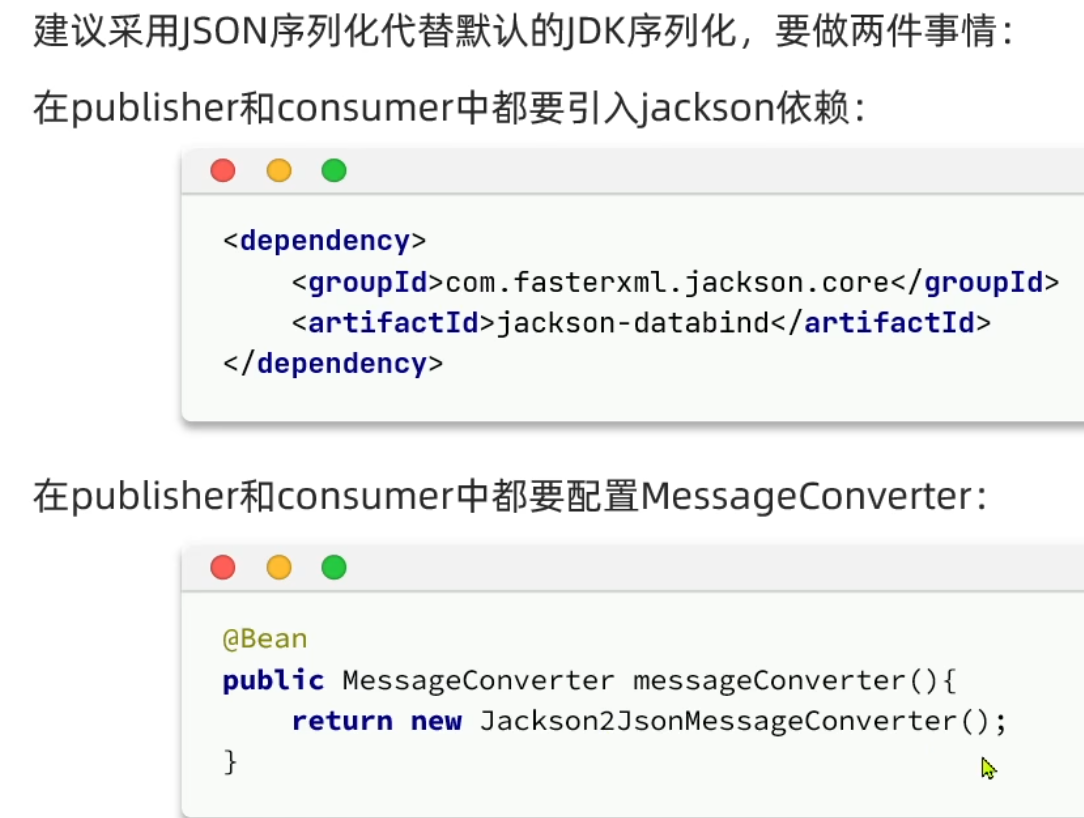
RabbitMQ 各类交换机
为什么要用交换机? 交换机用来路由消息。如果直发队列,这个消息就被处理消失了,那别的队列也需要这个消息怎么办?那就要用到交换机 交换机类型 1,fanout:广播 特点 广播所有消息:将消息…...