【大数据】第三章:详解HDFS(送尚硅谷笔记和源码)
什么是HDFS
HDFS是(Hadoop Distributed File System)的缩写,也即Hadoop分布式文件系统。它通过目录树定位在分布式场景下 在不同服务器主机上的文件。它适用于一次写入,多次读出的场景。
HDFS的优缺点
优点
1,高容错性,一份文件在多台服务器上都有备份,不存在因为一台服务器宕机而造成文件丢失的情况。
2,存储量大,数据规模:接近TB。数量规模:接近百万。
3,可搭建在廉价的电脑上,不需要专门的服务器。
缺点
1,读取速度慢。
2,无法高效的存储大量的细小文件,大量的小文件,HDFS的查找时间远大于读取时间,违反了HDFS的设计初衷。
3,不支持并发写入,不支持随机修改了。要修改的数据只能追加在文件的末尾。
HDFS的组成
NameNode
HDFS的老大,只操作小弟,不操作具体的数据。
DataNode
HDFS的小弟,负责操作具体的数据。
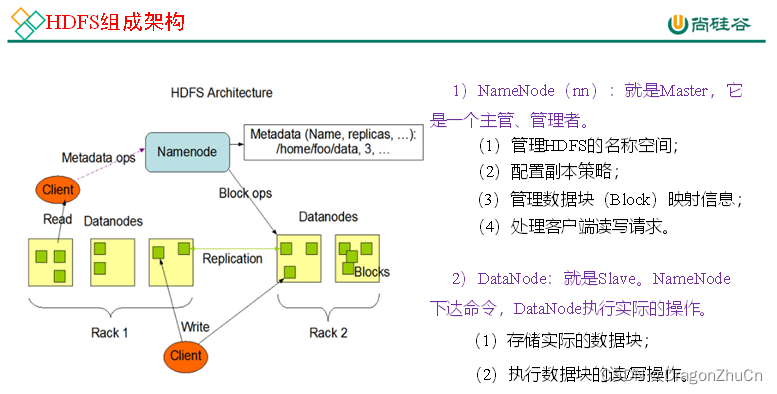
Client
客户端,直接打开的hadoop页面是客户端,写的HDFS命令是客户端,后端写的代码也是客户端。
SecondaryNameNode
大哥的秘书,分担老大的工作,比如定时备份数据:操作Fsimage和Edits

HDFS中的块大小
HDFS文件在物理上采用分块存储,在Hadoop1.x版本中是64M,在Hadoop2.x和3.x版本中采用128M。
其大小可以修改配置 dfs.blocksize来决定。
为什么要采用128M作为大小?
寻址时间为0.01s,按照HDFS的设计思路,数据在传输的时间应为寻址时间的0.01,那么传输时间就为1s,机械硬盘的读写速度为100M/s。所以一个块选择其大小为128M。
总结:块大小取决于服务器硬盘的传输效率。
HDFS的Shell操作
这些百度就有
尚硅谷Hadoop3.x官方文档大全免费下载。
https://pan.baidu.com/share/init?surl=P5JAtWlGDKMAPWmHAAcbyA 提取码:5h60
HDFS的JavaApi操作
源码在GitHub
HDFS的读写流程
HDFS的写数据流程
文件写入流程
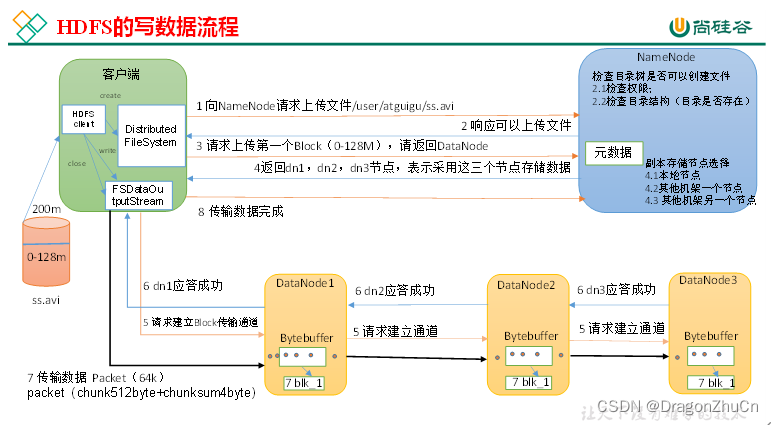
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block(128M)上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。是第一个应答后传给第二个,再传给第三个
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
节点距离计算
HDFS在写入数据时,NameNode会选择距离最近的DataNode,写入数据,那么他是如何计算距离的呢?
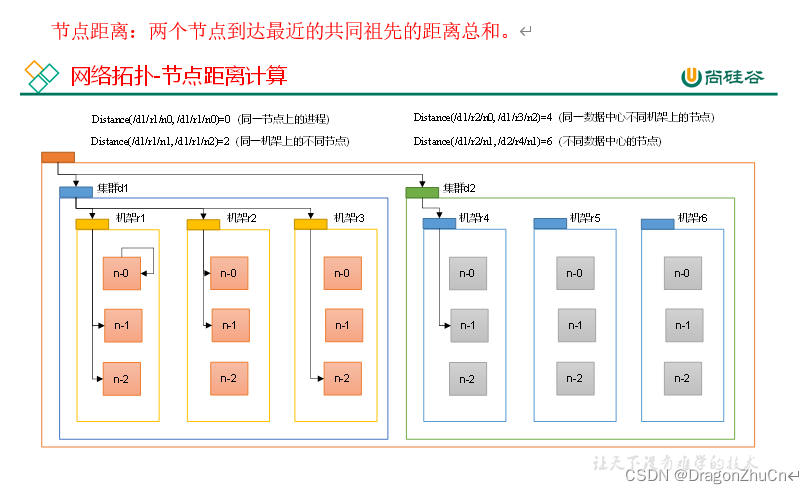
机架感知(副本存储节点选择)
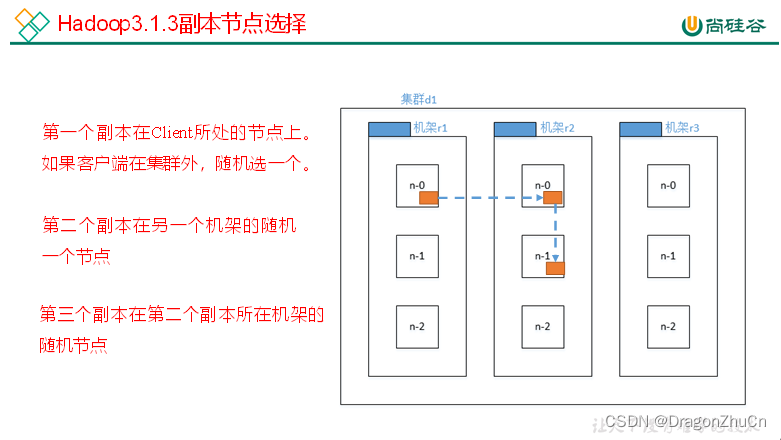
在“文件写入流程”中d1是数据存储的位置,d2,d3都是d1文件副本(冗余)存储的DataNode。那么HDFS他是如何选择冗余副本应该放在哪的呢?
(1)官方说明
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication For the common case, when the replication factor is three, HDFS’splacement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; thi policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
(2)Hadoop3.1.3副本节点选择
HDFS的读数据流程
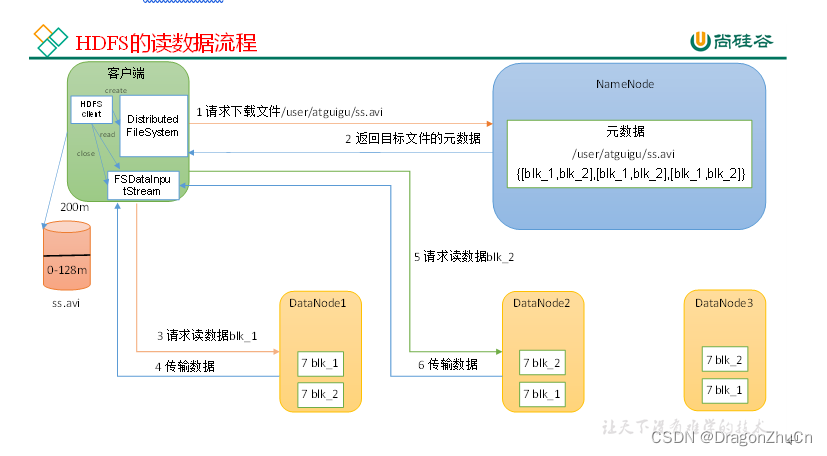
(1)Client通过对象:分布式文件系统向NameNode请求下载文件,NameNode进行权限和文件校验。并返回具体的DataNode地址。
(2)挑选一台DataNode(就近原则+负载原则)穿行读数据。!非并行!
(3)DataNode开始传输数据给客户端(以Packet为单位来做校验)。Packet = 64K
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
NameNode和2NameNode
NN和2NN工作机制
DataNode中数据又备份,那NameNode中的数据没有备份吗?
当然有,NameNode数据备份类似Redis的AOF和RDB技术,采用FsImage和Edits的合并,合成元数据。并把这个备份程序,交由2NN进行运行。
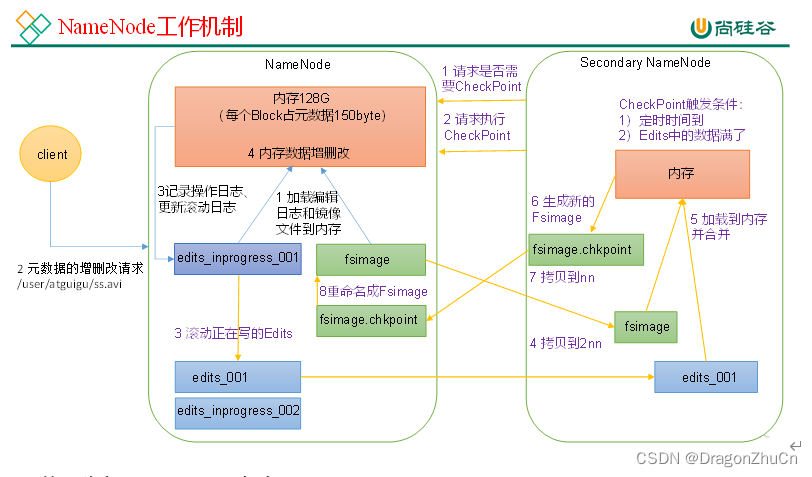
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
要备份数据,就将fsimage和最新的edits_inprogress进行合并。
每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
DataNode
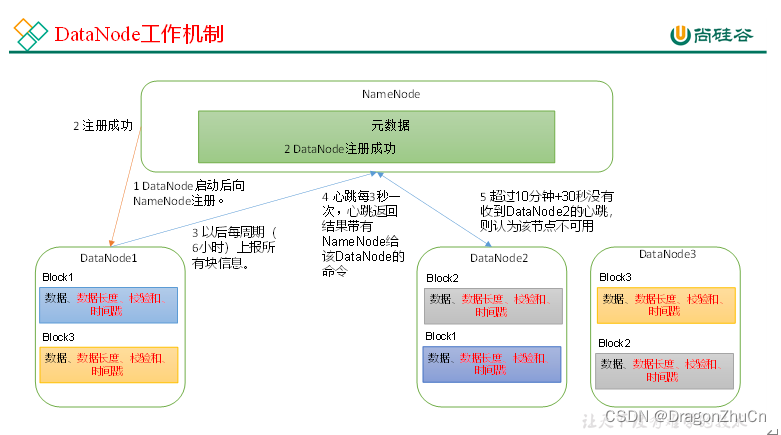
DataNode的工作机制
1,DataNode检查是否在正常,
1>DataNode每3秒向NameNode发送心跳,如果在10分钟+20秒NameNode还是没有接收到DataNode的心跳就默认为DataNode挂掉了。
2>一个DataNode中有很多块,NameNode周期性校验节点块的时间为6H,周期性向NameNode汇报节点情况的时间也为6H。
2,数据具体在DataNode中的块中有。数据+数据长度+校验和+时间戳
校验数据的完整性
在获取数据的API操作中,方法最后一个参数是True或者False。也就是是否要采用CRC校验数据的完整性。
相关文章:
【大数据】第三章:详解HDFS(送尚硅谷笔记和源码)
什么是HDFS HDFS是(Hadoop Distributed File System)的缩写,也即Hadoop分布式文件系统。它通过目录树定位在分布式场景下 在不同服务器主机上的文件。它适用于一次写入,多次读出的场景。 HDFS的优缺点 优点 1,高容…...

27岁想转行IT,还来得及吗?
来不来得及不还是看你自身的意愿和条件,这个问题要问你自己吧! 每个人的能力、看法都不同。面对类似的问题,很多人会把侧重点放在IT上,或者27岁上面。那么我们试着换一个方式来问呢:什么时候适合转行,有哪些…...

Web前端CSS清除浮动的5种方法
在移动端清除浮动布局,常用的5种方法: 使用清除浮动的类;使用overflow属性;使用 flex 布局;使用grid 布局;使用 table 布局。 根据实际情况选择适合的方法,需要注意兼容性和语义性问题。在移动…...

Java:博客系统,实现加盐加密,分页,草稿箱,定时发布
文章目录1. 项目概述2. 准备工作2.1 数据库表格代码2.2 前端代码2.3 配置文件3. 准备项目结构3.1 拷贝前端模板3.2 定义实体类3.3 定义mapper接口和 xml 文件3.4 创建其他包4. 统一数据返回4.1 Result 类4.2 统一数据格式5. 注册5.1 逻辑5.2 验证数据规范性5.3 实现注册5.4 前端…...

JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算、网络、存储、安全、智能为核心能力的新一代分布式云计算解决方案。边缘存储主要面向适配边缘计算的典型业务场景&#…...

实验06 二叉树遍历及应用2022
A. 【程序填空】二叉树三种遍历题目描述给定一颗二叉树的特定先序遍历结果,空树用字符‘0’表示,例如AB0C00D00表示如下图请完成以下程序填空,建立该二叉树的二叉链式存储结构,并输出该二叉树的先序遍历、中序遍历和后序遍历结果输…...

基于蜣螂算法改进的LSTM分类算法-附代码
基于蜣螂算法改进的LSTM分类算法 文章目录基于蜣螂算法改进的LSTM分类算法1.数据集2.LSTM模型3.基于蜣螂算法优化的RF4.测试结果5.Matlab代码摘要:为了提高LSTM数据的分类预测准确率,对LSTM中的参数利用蜣螂搜索算法进行优化。1.数据集 数据的来源是 UC…...

如何正确应用GNU GPLv3 和 LGPLv3 协议
文章目录前言GNU GPLv3.0Permissions(许可)Conditions(条件)Limitations(限制)GNU LGPLv3.0应用GPLv3.0应用LGPLv3.0建议的内容:添加文件头声明附录GNU GPLv3.0原文GNU LGPLv3.0 原文前言 对于了解开源的朋友们,GNU GPL系列协议可谓是老朋友了。原来我基…...
)
Python局部函数及用法(包含nonlocal关键字)
Python 函数内部可以定义变量,这样就产生了局部变量,可能有人会问,Python 函数内部能定义函数吗?答案是肯定的。Python 支持在函数内部定义函数,此类函数又称为局部函数。 那么,局部函数有哪些特征&#x…...

关于BMS的介绍及应用领域
电池管理系统(Battery Management System,BMS)是一种集成电路系统,它用于监测和控制电池系统状态,以确保电池的正常运行和安全使用。BMS的应用涵盖了电动汽车、储能系统、无人机、电动工具等各个领域,可以提…...

2月datawhale组队学习:大数据
文章目录一、大数据概述二、 Hadoop2.1 Hadoop概述2.2 su:Authentication failure2.3 使用sudo命令报错xxx is not in the sudoers file. This incident will be reported.2.4 创建用户datawhale,安装java8:2.5 安装单机版Hadoop2.5.1 安装Hadoop2.5.2 修…...

在Spring框架中创建Bean实例的几种方法
我们希望Spring框架帮忙管理Bean实例,以便得到框架所带来的种种功能,例如依赖注入等。将一个类纳入Spring容器管理的方式有几种,它们可以解决在不同场景下创建实例的需求。 XML配置文件声明 <?xml version"1.0" encoding"…...
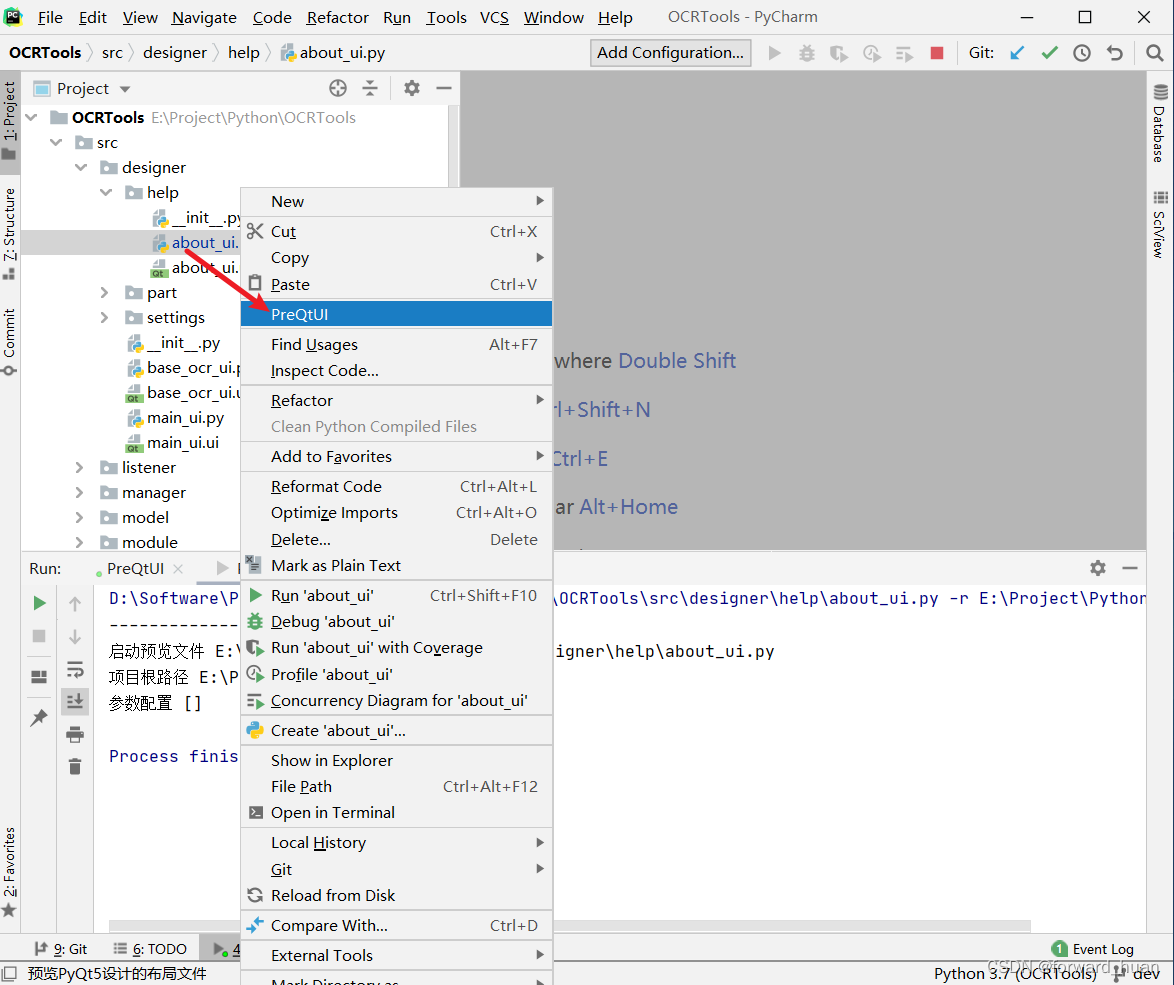
PyQt5 界面预览工具
简介 一款为了预览PyQt5设计的UI界面而开发的工具,使用时需要结合PyCharm同时使用。 下载 PyQt5界面预览工具 参数说明 使用配置 启动PyCharm,找到File -> Settings,打开 找到Tools -> External Tools点击打开,在新界面…...

day44【代码随想录】动态规划之零钱兑换II、组合总和 Ⅳ、零钱兑换
文章目录前言一、零钱兑换II(力扣518)二、组合总和 Ⅳ(力扣377)三、零钱兑换(力扣322)总结前言 1、零钱兑换II 2、组合总和 Ⅳ 3、零钱兑换 一、零钱兑换II(力扣518) 给你一个整数…...
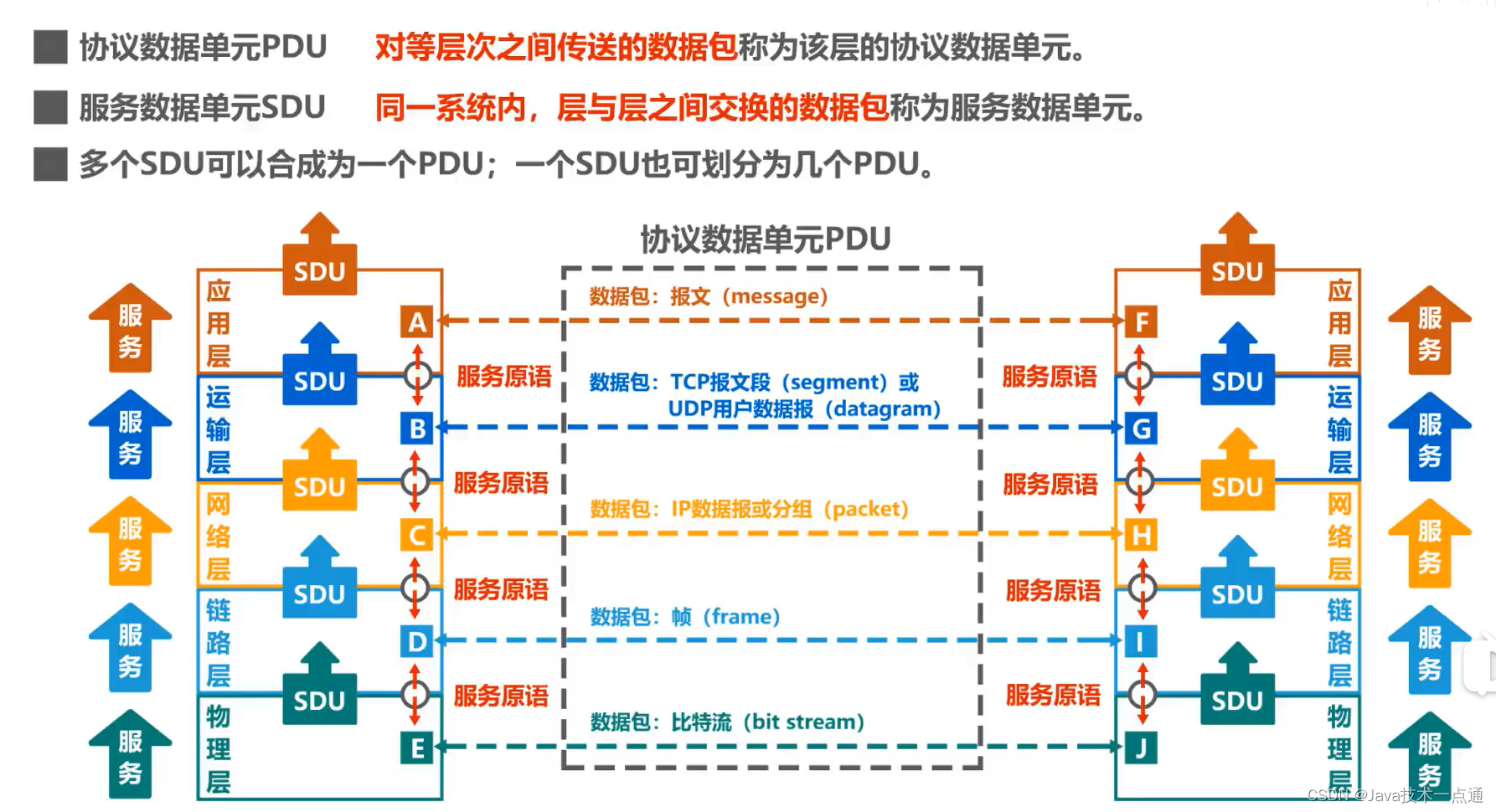
计算机网络第1章(概述)学习笔记
❤ 作者主页:欢迎来到我的技术博客😎 ❀ 个人介绍:大家好,本人热衷于Java后端开发,欢迎来交流学习哦!( ̄▽ ̄)~* 🍊 如果文章对您有帮助,记得关注、点赞、收藏、…...
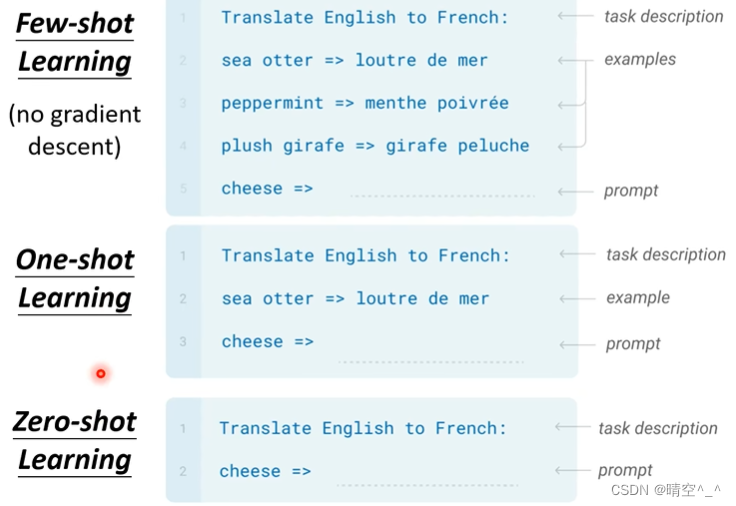
GPT-3(Language Models are Few-shot Learners)简介
GPT-3(Language Models are Few-shot Learners) 一、GPT-2 1. 网络架构: GPT系列的网络架构是Transformer的Decoder,有关Transformer的Decoder的内容可以看我之前的文章。 简单来说,就是利用Masked multi-head attention来提取文本信息&a…...
容器安全风险and容器逃逸漏洞实践
本文博客地址:https://security.blog.csdn.net/article/details/128966455 一、Docker存在的安全风险 1.1、Docker镜像存在的风险 不安全的第三方组件:用户自己的代码依赖若干开源组件,这些开源组件本身又有着复杂的依赖树,甚至…...

2023年美赛B题-重新想象马赛马拉
背景 肯尼亚的野生动物保护区最初主要是为了保护野生动物和其他自然资源资源。肯尼亚议会于2013年通过了《野生动物保护和管理法》提供更公平的资源共享,并允许替代的、以社区为基础的管理工作[1]。此后,肯尼亚增加了修正案,以解决立法中的空…...
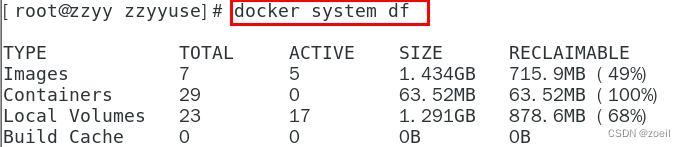
Docker常用命令总结
目录 一、帮助启动类命令 (1)启动docker (2)停止docker (3)重启docker (4)查看docker (5)设置开机自启 (6)查看docker概要信息…...
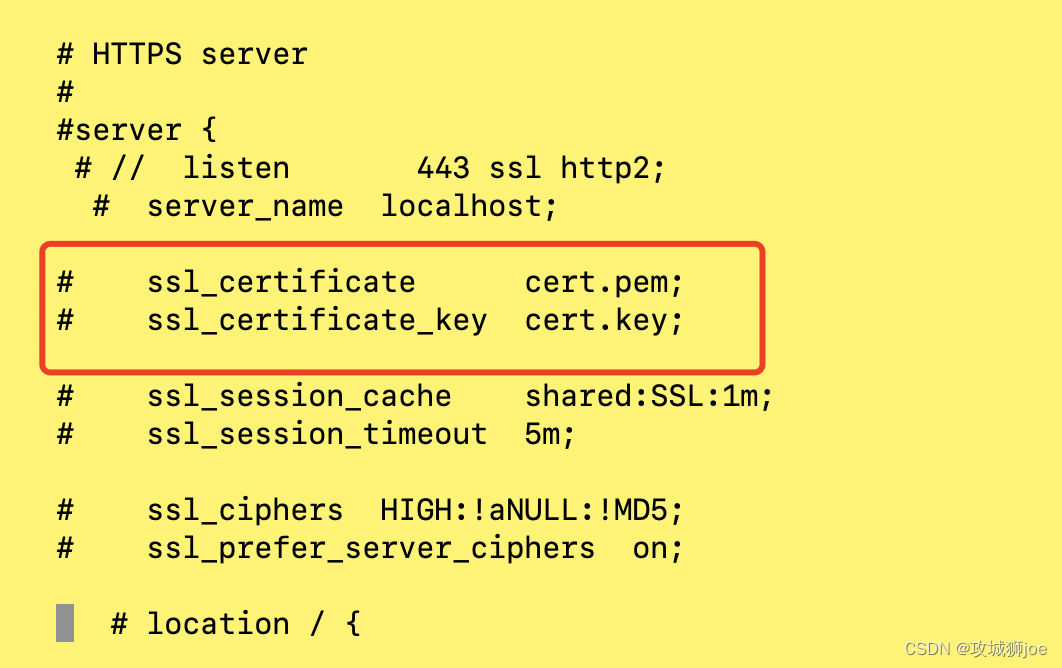
mac环境,安装NMP遇到的问题
一 背景 项目开发中,公司项目需要使用本地的环境运行,主要是php这块的业务。没有使用docker来处理,重新手动撸了一遍。记录下其中遇到的问题; 二 遇到的问题 2.1 Nginx的问题 brew install nginx后,启动nginx,报错如下:nginx: [emerg] no "ssl_certificate" …...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...