【论文笔记】图像修复Learning Joint Spatial-Temporal Transformations for Video Inpainting
论文地址:https://arxiv.org/abs/2007.10247
源码地址:GitHub - researchmm/STTN: [ECCV'2020] STTN: Learning Joint Spatial-Temporal Transformations for Video Inpainting
一、项目介绍
当下SITA的方法大多采用注意模型,通过搜索参考帧中缺失的内容来完成一帧,并进一步逐帧完成整个视频。然而,这些方法在空间和时间维度上的注意结果可能会不一致,这往往会导致视频中的模糊和时间伪影。
本文提出时空转换网络STTN(Spatial-Temporal Transformer Network)。具体来说,是通过自注意机制同时填补所有输入帧中的缺失区域,并提出通过时空对抗性损失来优化STTN。为了展示该模型的优越性,我们使用标准的静止掩模和更真实的运动物体掩模进行了定量和定性的评价。
二、STTN
模型输入是图像帧序列和masks序列,图像帧序列经过Encoder、Mask经过scale变化成原来的1/4,然后一起送入Spatial-Temporal Transformer模块;Spatial-Temporal Transformer模块由8个TransformerBlock组成;最后Decoder模块负责将特征还原成图像帧序列。STTN的整体结构图如下:
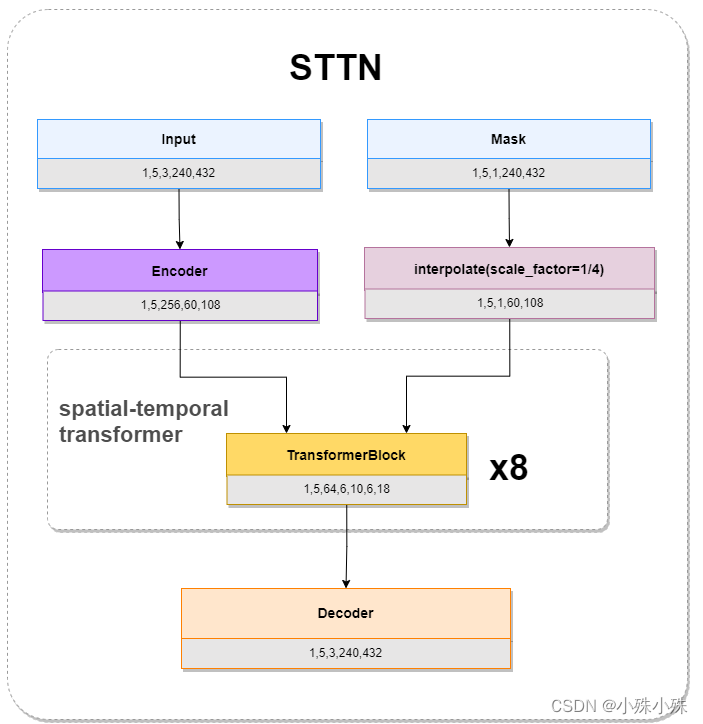
图1
1.Encoder
Frame-Level Encoder帧级编码器,通过叠加二维卷积层来构建的,目的是为每一帧的低级别像素的深度特征,就是四个卷积层提取单帧图像特征,要素不多,结构图如下:

图2
代码如下:
# 位置model/sttn.py
self.encoder = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, channel, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),)2.Spatial-Temporal Transformer Network
这是STTN的核心部分,通过一个多头 patch-based attention模块沿着空间和时间维度进行搜索。transformer的不同头部计算不同尺度上对空间patch的注意力。这样的设计允许我们处理由复杂的运动引起的外观变化。例如,对大尺寸的patch(例如,帧大小H×W)旨在修复固定的背景;对小尺寸的patch(如H/10×W/10)有助于在视频的任意位置捕捉移动的前景信息。
(1)TranformerBlock
TransformerBlock由Embedding、Matching和Attending组成,代码中Matching和Attending被放在一起合成了MultiHeadedAttention。输入是帧序列特征和masks。
帧序列的特征平分成四部分,每个部分经过Embedding映射为四种尺度的Key、Query、Value,从而对应不同尺度的patch。masks经过变换也变成四个尺度。将四个尺度的Key、Query、Value和四个尺度masks分别送入MultiHeadedAttention,然后将结果Concat到一起,经过FeedForward层进一步分特征融合,得到融合了时间维度上不同尺度空间patch的特征。结构图如下:

图3
代码如下:
# 位置model/sttn.py
class TransformerBlock(nn.Module):"""Transformer = MultiHead_Attention + Feed_Forward with sublayer connection"""def __init__(self, patchsize, hidden=128):super().__init__()self.attention = MultiHeadedAttention(patchsize, d_model=hidden)self.feed_forward = FeedForward(hidden)def forward(self, x):x, m, b, c = x['x'], x['m'], x['b'], x['c']x = x + self.attention(x, m, b, c)x = x + self.feed_forward(x)return {'x': x, 'm': m, 'b': b, 'c': c}(2)KQV Formatting
图3中的KQV Formatting结构如下图:
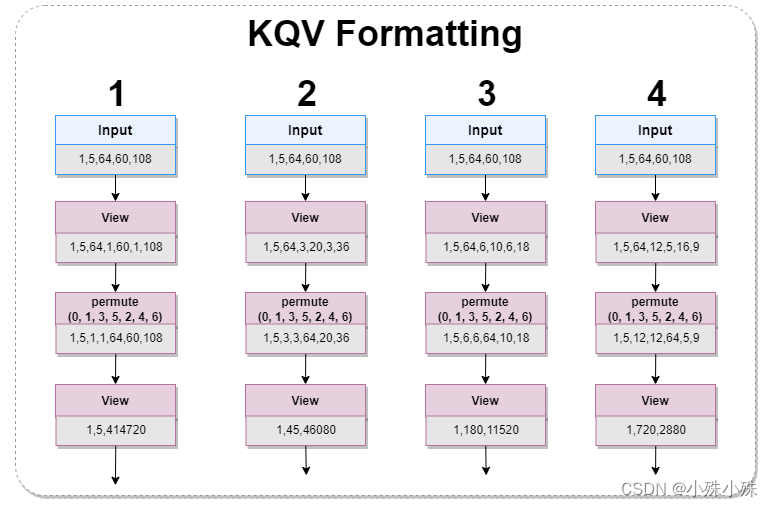
图4
TranformerBlock输入的帧序列特征,被平分成四个部分,每个部分经过变换,变成四种尺度patch的特征。
代码如下:
# 位置model/sttn.py
query = query.view(b, t, d_k, out_h, height, out_w, width)
query = query.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)
key = key.view(b, t, d_k, out_h, height, out_w, width)
key = key.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)
value = value.view(b, t, d_k, out_h, height, out_w, width)
value = value.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)(3)Mask Formatting
KQV Formatting将帧序列变成四种尺度,masks也需要对应的变成四种尺度,结构如下:
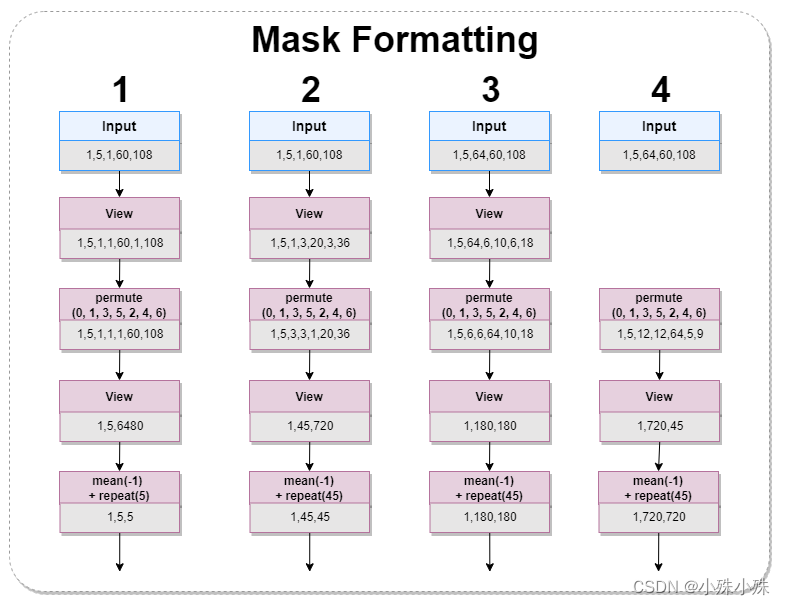
图5
代码如下:
# 位置model/sttn.py
mm = m.view(b, t, 1, out_h, height, out_w, width)
mm = mm.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, height*width)
mm = (mm.mean(-1) > 0.5).unsqueeze(1).repeat(1, t*out_h*out_w, 1)(4)Attention
图3中的Attention层其实包括了论文中的Matching和Attending,结构图如下:
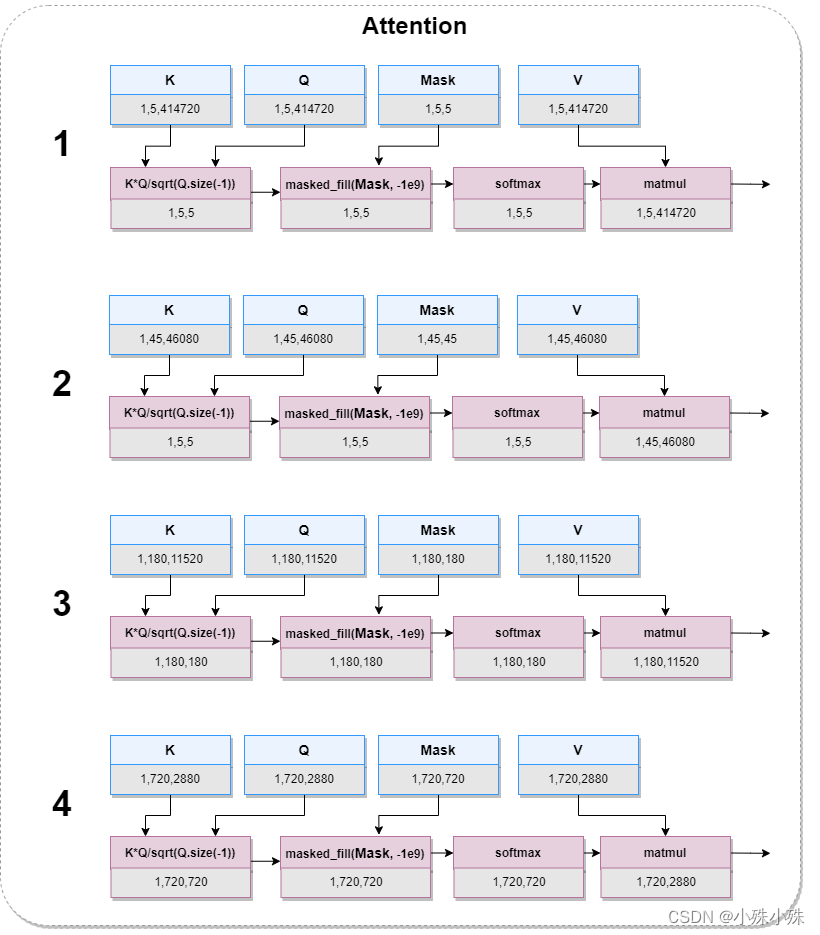
图6
图6中的K*Q/sqrt(Q.size(-1))是在计算各个patch的相似性,对应论文中公式,第i个斑块与第j个patch的相似性记为::

图6中的masked_fill(Mask, -1e9)是将图像中的损坏部分mask掉,意思是只学习图像中完整的部分,坏的就不要学习了。
论文中的Attention对应图6中的matmul,负责计算相关patches的value加权和得到输出patch的query。公式如下:

代码如下:
# 位置model/sttn.py
class Attention(nn.Module):"""Compute 'Scaled Dot Product Attention"""def forward(self, query, key, value, m):scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))scores.masked_fill(m, -1e9)p_attn = F.softmax(scores, dim=-1)p_val = torch.matmul(p_attn, value)return p_val, p_attn3.Decoder
frame-level decoder: 帧级解码器,把特征解码成帧。期间特征图经过了两次的膨胀,中间穿插几个2d卷积,整体过程有点像Encoder倒过来,结构图如下:
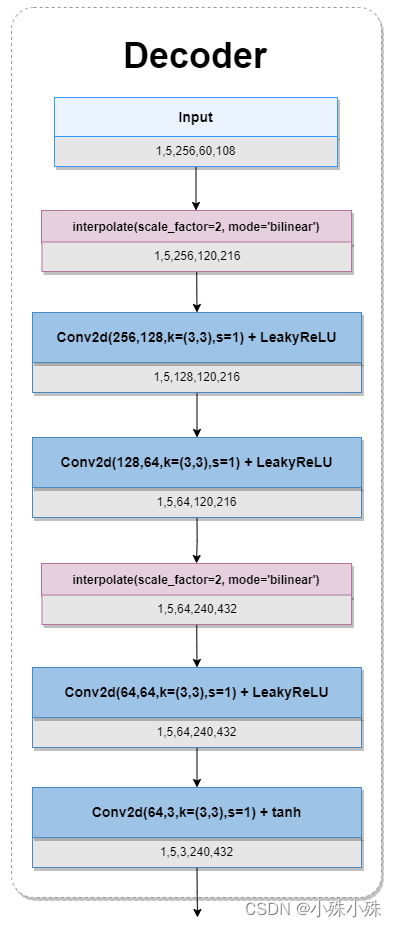
图7
代码如下:
# 位置model/sttn.py
self.decoder = nn.Sequential(deconv(channel, 128, kernel_size=3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),deconv(64, 64, kernel_size=3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1))三、损失函数
本文使用GAN来对模型进行优化,G模型选择了一个像素级的重建损失即L1Loss,D网络使用T-PatchGAN来优化。
1.G模型损失函数
G模型图像破坏区域的L1Loss:

G模型图像有效区域的L1Loss:

STTN的对抗性损失:

上式看上去很复杂,其实就是将恢复的图像送入D模型,然后送入损失函数(可选nsgan、lsgan、hinge)
总结上面三个式子,得出G模型的损失函数,其中三个权重官方推荐
![]()
2.D网络的损失函数
对抗性的损失在提高视频绘制的感知质量和时空一致性方面显示出了良好的效果。公式如下:

看山去还是很复杂,其实就是将原图和复原图分别送入损失函数(可选nsgan、lsgan、hinge),然后求和,代码中是取均值,不过应该影响不大。
三、训练流程
下面是我根据官方代码梳理的整个训练过程:
1.从数据集选取数据,同时为选取的数据随机带有破坏图案的masks
2.根据masks将原图的破坏部分变成0,得到masked_frame
3.将masked_frame和masks送入G模型(生成模型,即STTN),得出估计pred_img
4.根据pred_img修复图像,得到comp_img
5.将原图和comp_img分别送入D模型,分别得到输出的特征 real_vid_feat和fake_vid_feat
6.使用real_vid_feat和fake_vid_feat对D模型进行优化(损失函数可选nsgan、lsgan、hinge)
7.使用原图、comp_img和gen_vid_feat对G模型进行优化(L1Loss)
代码如下:
# 位置core/trainer.pydef _train_epoch(self, pbar):device = self.config['device']for frames, masks in self.train_loader:self.adjust_learning_rate()self.iteration += 1frames, masks = frames.to(device), masks.to(device)b, t, c, h, w = frames.size()masked_frame = (frames * (1 - masks).float())# 将masked_frame和masks送入G模型(生成模型,即STTN),得出估计pred_imgpred_img = self.netG(masked_frame, masks)frames = frames.view(b*t, c, h, w)masks = masks.view(b*t, 1, h, w)# 根据pred_img修复图像,得到comp_imgcomp_img = frames*(1.-masks) + masks*pred_imggen_loss = 0dis_loss = 0# 将原图和comp_img分别送入D模型,分别得到输出的特征 real_vid_feat和fake_vid_featreal_vid_feat = self.netD(frames)fake_vid_feat = self.netD(comp_img.detach())# 计算D网络的损失dis_real_loss = self.adversarial_loss(real_vid_feat, True, True)dis_fake_loss = self.adversarial_loss(fake_vid_feat, False, True)dis_loss += (dis_real_loss + dis_fake_loss) / 2self.add_summary(self.dis_writer, 'loss/dis_vid_fake', dis_fake_loss.item())self.add_summary(self.dis_writer, 'loss/dis_vid_real', dis_real_loss.item())self.optimD.zero_grad()dis_loss.backward()# 使用real_vid_feat和fake_vid_feat对D模型进行优化self.optimD.step()# G模型的对抗性损失gen_vid_feat = self.netD(comp_img)gan_loss = self.adversarial_loss(gen_vid_feat, True, False)gan_loss = gan_loss * self.config['losses']['adversarial_weight']gen_loss += gan_lossself.add_summary(self.gen_writer, 'loss/gan_loss', gan_loss.item())# G模型图像破坏区域的L1Losshole_loss = self.l1_loss(pred_img*masks, frames*masks)hole_loss = hole_loss / torch.mean(masks) * self.config['losses']['hole_weight']gen_loss += hole_loss self.add_summary(self.gen_writer, 'loss/hole_loss', hole_loss.item())# G模型图像有效区域的L1Lossvalid_loss = self.l1_loss(pred_img*(1-masks), frames*(1-masks))valid_loss = valid_loss / torch.mean(1-masks) * self.config['losses']['valid_weight']gen_loss += valid_loss self.add_summary(self.gen_writer, 'loss/valid_loss', valid_loss.item())self.optimG.zero_grad()gen_loss.backward()# 使用原图、comp_img和gen_vid_feat对G模型进行优化self.optimG.step()# 日志if self.config['global_rank'] == 0:pbar.update(1)pbar.set_description((f"d: {dis_loss.item():.3f}; g: {gan_loss.item():.3f};"f"hole: {hole_loss.item():.3f}; valid: {valid_loss.item():.3f}"))# saving modelsif self.iteration % self.train_args['save_freq'] == 0:self.save(int(self.iteration//self.train_args['save_freq']))if self.iteration > self.train_args['iterations']:break接下来代码中有些重点,需要简单说明一下:
1.准备数据集
项目中用到Davis或youtube-vos数据集,两个数据集其实都是为segmentation任务设计的,代码中都只使用图像数据,不使用标注数据。我们以davis数据集为例,davis数据集由90个视频组成,每个视频已经拆帧成图片,数据集下载完每个视频一个文件夹,但是程序需要每个视频这图片打成zip文件,下面的程序可以用来完成这个工作:
import os
import zipfiledef zipDir(dirpath, out_full_name):zipname = zipfile.ZipFile(out_full_name, 'w', zipfile.ZIP_DEFLATED)for path, dirnames, filenames in os.walk(dirpath):fpath= path.replace(dirpath, '')for filename in filenames:zipname.write(os.path.join(path, filename), os.path.join(fpath, filename))zipname.close()if __name__=="__main__":org_dir = r'datasets/davis/JPEGImages_org'zip_dir = r'datasets/davis/JPEGImages'g = os.walk(org_dir)for path, dir_list, file_list in g:for dir_name in dir_list:input_path = os.path.join(path, dir_name)output_path = os.path.join(zip_dir, dir_name+'.zip')print(input_path, '\n', output_path)zipDir(input_path, output_path)2.数据选取策略
数据是从90个视频中随机挑一个,然后在这个视频中选取sample_length张图片,最终每个视频都会选取一个图片组,在论文中提到有两种数据选取策略,就是下面这个公式:

其中代表以t为中心n为半径的连续帧序列,代码实现是50%概率用一个长度为sample_length的框随机滑动选取;
表示从以s采样率的视频
中均匀采样的远处帧,代码中并未使用这种方式,而是50%概率随机选取帧,这样也许是为了解决缓解数据不够多的问题。
选图片组的代码如下:
# 位置:core/dataset.py
def get_ref_index(length, sample_length):# 50%概率随机选取帧if random.uniform(0, 1) > 0.5:ref_index = random.sample(range(length), sample_length)ref_index.sort()else:# 50%概率用一个长度为sample_length的框随机滑动选取pivot = random.randint(0, length-sample_length)ref_index = [pivot+i for i in range(sample_length)]return ref_index3.生成随机masks
有了图片组,还需要为每个图片组随机生成masks。其中0代表背景,1代表破坏部分。代码如下,注释已经很清楚:
# 位置:core/utils.py
def create_random_shape_with_random_motion(video_length, imageHeight=240, imageWidth=432):# 生成的破坏图案宽高占原图的1/3到100%height = random.randint(imageHeight//3, imageHeight-1)width = random.randint(imageWidth//3, imageWidth-1)# 生成不规则的破坏图案edge_num = random.randint(6, 8)ratio = random.randint(6, 8)/10region = get_random_shape(edge_num=edge_num, ratio=ratio, height=height, width=width)region_width, region_height = region.size# 随机放置破坏图案x, y = random.randint(0, imageHeight-region_height), random.randint(0, imageWidth-region_width)velocity = get_random_velocity(max_speed=3)m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))m.paste(region, (y, x, y+region.size[0], x+region.size[1]))masks = [m.convert('L')]# 50%概率所有的mask一样if random.uniform(0, 1) > 0.5:return masks*video_length# 50%概率mask中的破坏图案会移动for _ in range(video_length-1):x, y, velocity = random_move_control_points(x, y, imageHeight, imageWidth, velocity, region.size, maxLineAcceleration=(3, 0.5), maxInitSpeed=3)m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))m.paste(region, (y, x, y+region.size[0], x+region.size[1]))masks.append(m.convert('L'))return masks相关文章:
【论文笔记】图像修复Learning Joint Spatial-Temporal Transformations for Video Inpainting
论文地址:https://arxiv.org/abs/2007.10247 源码地址:GitHub - researchmm/STTN: [ECCV2020] STTN: Learning Joint Spatial-Temporal Transformations for Video Inpainting 一、项目介绍 当下SITA的方法大多采用注意模型,通过搜索参考帧…...
代码随想录算法训练营第二天 | 977.有序数组的平方 、209.长度最小的子数组 、59.螺旋矩阵II、总结
打卡第二天,认真做了两道题目,顶不住了好困,明天早上练完车回来再重新看看。 今日任务 第一章数组 977.有序数组的平方209.长度最小的子数组59.螺旋矩阵II 977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每…...

Python pickle模块:实现Python对象的持久化存储
Python 中有个序列化过程叫作 pickle,它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。值得一提的是,pickle 是 python 语言的一个标准模…...
【C++】C/C++内存管理
文章目录1. C/C内存分布2. C语言当中的动态内存管理3. C 内存管理方式3.1 new/delete操作内置类型3.2 new和delete操作自定义类型4. operator new 和operator delete 函数5. new和delete的实现原理5.1 内置类型5.2 自定义类型6. 定位new表达式(placement-new)7. 常见面试题7.1 …...

【测试】自动化测试02
努力经营当下,直至未来明朗! 文章目录前言 回顾 预告一、常见的元素操作1. 输入文本sendKeys()2. 点击click3. 提交submit(通过回车键提交)4. 清除clear5. 获取文本getText()6. 获取属性对应的值getAttribute()7. 查看title和ur…...
Python空间分析| 02 利用Python计算空间局部自相关(LISA)
局部空间自相关 import esda import numpy as np import pandas as pd import libpysal as lps import geopandas as gpd import contextily as ctx import matplotlib.pyplot as plt from geopandas import GeoDataFrame from shapely.geometry import Point from pylab im…...

idea快捷编码:生成for循环、主函数、判空非空、生成单例方法、输出;自定义快捷表达式
前言 idea可根据输入的简单表达式进行识别,快速生成语句 常用的快捷编码:生成for循环、主函数、判空非空、生成单例方法、输出 自定义快捷表达式 博客地址:芒果橙的个人博客 【http://mangocheng.com】 一、idea默认的快捷表达式查看 Editor…...

【Spring】@Value注入配置文件 application.yml 中的值失败怎么办
本期目录一、 问题背景二、 问题原因三、 解决方法一、 问题背景 今天碰到的问题是用 Value 注解无法注入配置文件 application.yml 中的配置值。 检查过该类已经交给 Spring 容器管理了,即已经在类上加了 Configuration 和 ConfigurationProperties(prefix &quo…...
CleanMyMac清理工具软件功能优势介绍
CleanMyMac更新最新版本x4.12,完美适配新版系统macOS10.14,拥有全新的界面。CleanMyMac可以让您安全、智能地扫描和清理整个系统,删除大型未使用的文件,减少iPod库的大小,最精确的应用程序卸载,卸载不必要的…...

【面试题】对JS中的事件冒泡、事件捕获、事件委托的理解
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库DOM事件流(event flow )存在三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。Dom标准事件流的触发的先…...

SAP 理解合并会计报表
随着企业集团的发展,集团内部会出现越来越多的公司;复杂的公司结构和复杂的集团内业务,使得集团内部管理困难重重,信息渠道严重失灵。除了内部管理的需要,企业还有义务向相关方提供详细的和及时的信息。ERP中的合并会计…...

Ubuntu 命令常用命令——定时启动程序
crontab -e 语法 crontab[ -u user ] file或 crontab[ -u user ] { -l | -r | -e }说明: crontab是用来让使用者在固定时间或固定间隔执行程序之用,换句话说,也就是类似使用者的时程表。 -U Lser 是指设定指定user的时程表,这个前提是你必…...
:走迷宫)
笔试题(十三):走迷宫
# 描述 # 定义一个二维数组 N*M ,如 5 5 数组下所示: # int maze[5][5] { # 0, 1, 0, 0, 0, # 0, 1, 1, 1, 0, # 0, 0, 0, 0, 0, # 0, 1, 1, 1, 0, # 0, 0, 0, 1, 0,}; # 它表示一个迷宫,其中的1表示墙壁,0表示可以走的路&#…...

Gradle相关的知识学习
这里有一套博客文章写的比较通俗易懂:https://www.jianshu.com/p/8e1ddd19083a...
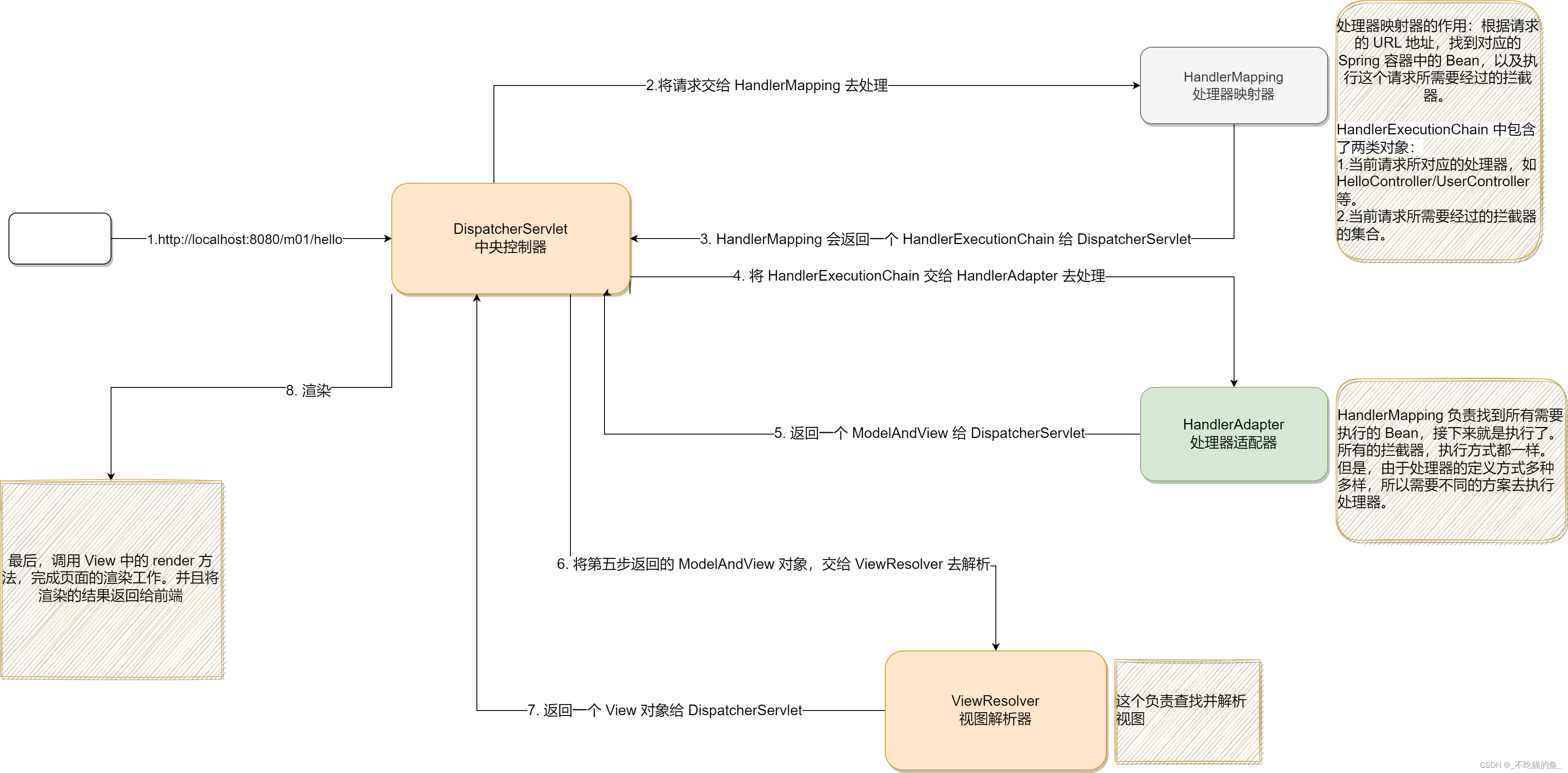
SpringMVC的工作原理
SpringMVC的工作原理流程图 SpringMVC流程 1、 用户发送请求至前端控制器DispatcherServlet。 2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。 3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截…...
问卷数据分析流程
文章目录一、数据合并1. 读取数据2. 数据预览二、数据清洗1. 检验ID是否重复,剔除ID重复项2. 剔除填写时间小于xx分钟的值3.处理 量表题 一直选一个选项的问题三、数据清洗1.1 将问卷单选题的选项code解码,还原成原来的选项1.2 自动获取单选题旧的选项列…...

【观察】Solidigm P44 Pro SSD评测:原厂品质+软硬兼施=性能怪兽
众所周知,目前SSD(固态硬盘)已取代HDD(机械硬盘)成为电脑中常见的存储设备,特别是在技术创新的持续推动下,如今SSD的速度和效率都在不断地提高,从SATA2 3GB发展到SATA3 6GBÿ…...
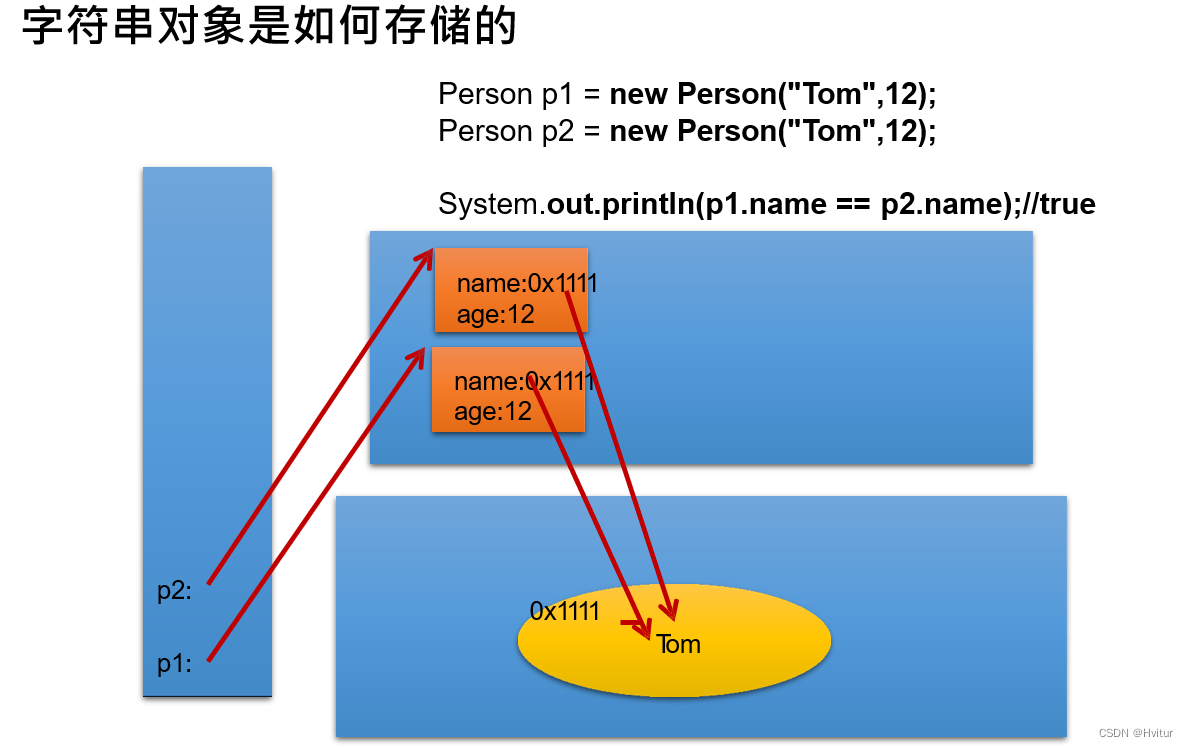
String对象的创建和比较
String类的概述 String类:代表字符串。 Java 程序中的所有字符串字面值(如 “abc” )都作 为此类的实例实现。 String是JDK中内置的一个类:java.lang.string 。 String表示字符串类型,属于引用数据类型,不…...
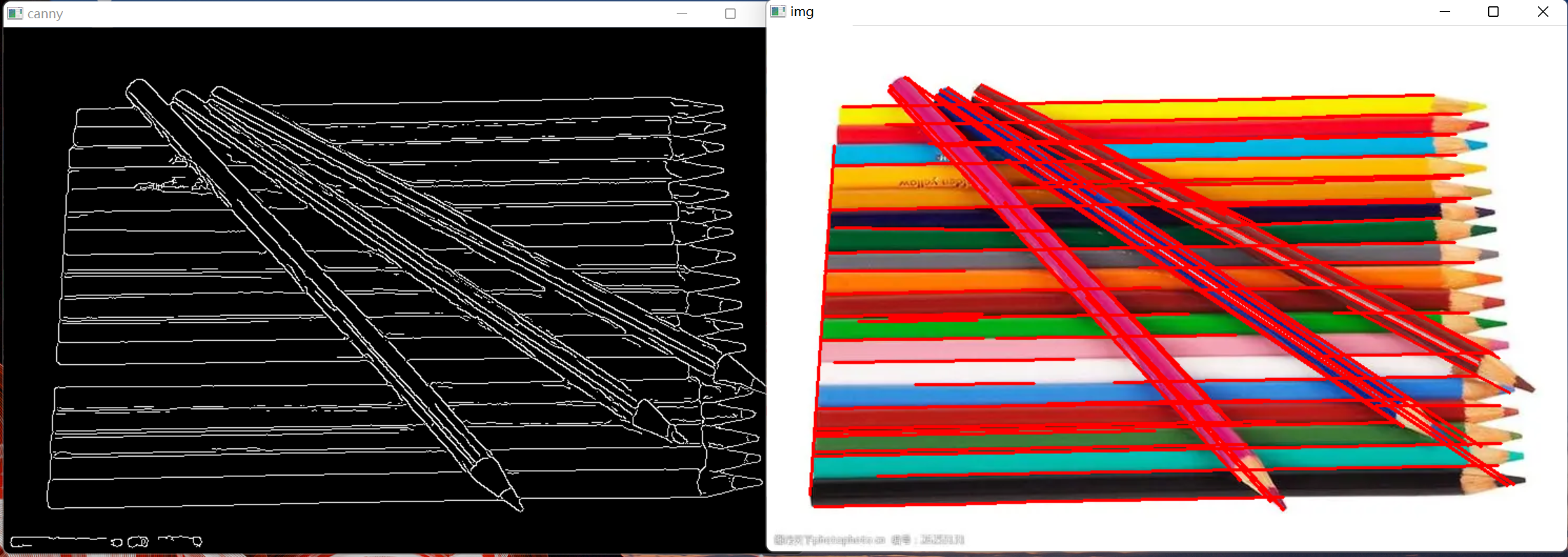
09 OpenCV图形检测
1 轮廓描边 cv2.findContours() 函数是OpenCV中用于寻找轮廓的函数之一。它可以用于在二值图像中查找并检测出所有的物体轮廓,以及计算出这些轮廓的各种属性,例如面积、周长、质心等。 cv2.findContours() 函数的语法如下: contours, hiera…...
解密Teradata与中国市场“分手”背后的原因!国产数据库能填补空白吗?
2月15日,西方的情人节刚刚过去一天,国内IT行业就爆出一个大瓜。 继Adobe、甲骨文、Tableau、Salesforce之后,又一个IT巨头要撤离中国市场。 Teradata天睿公司官宣与中国市场“分手”,结束在中国的直接运营。目前,多家…...

OpenClaw语音交互:千问3.5-9B实现的自然语言控制
OpenClaw语音交互:千问3.5-9B实现的自然语言控制 1. 为什么需要语音交互的自动化助手 去年冬天的一个深夜,我正在赶制一份紧急报告。双手忙着整理数据,眼睛盯着屏幕,却突然需要打开另一个参考文档。那一刻我突然想:如…...

C++虚函数关键指南
虚函数 virtual 关键字 使用场景 在基类中声明虚函数,允许派生类重写该函数以实现多态。 行为特点 通过基类的指针或引用调用虚函数时,调用的是对象实际类型(派生类)的函数版本。 示例代码 class Base { public:virtual void func…...

PyTorch 2.8镜像企业实操:证券公司研报图表→财经解读短视频流水线
PyTorch 2.8镜像企业实操:证券公司研报图表→财经解读短视频流水线 1. 项目背景与需求分析 在证券行业,分析师每天需要处理大量研报数据,其中包含丰富的图表信息。传统的人工解读方式存在三个痛点: 时效性差:从图表…...

静态图分布式训练总失败?PyTorch 3.0官方未公开的3类隐式依赖、4个环境校验checklist,立即自查!
第一章:静态图分布式训练失败的典型现象与归因框架静态图分布式训练(如 TensorFlow 1.x Graph 模式或 MindSpore Graph 模式)在大规模模型训练中常因图构建期与执行期分离的特性,导致错误暴露滞后、定位困难。典型失败现象包括&am…...

OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析
OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析 1. 为什么需要图片自动分析助手 上周整理项目资料时,我发现自己电脑里堆满了会议白板照片、产品截图和手写笔记。手动整理这些图片不仅耗时,还经常漏掉关键信息。直到发现Open…...
)
【量子计算C++实战指南】:20年专家亲授,从零搭建Shor算法仿真器(含完整可运行代码)
第一章:量子计算与C编程的融合基础量子计算正从理论走向工程实践,而C凭借其零开销抽象、内存可控性与高性能特性,成为量子软件栈底层实现的关键语言。现代量子开发框架(如QPP、Q、XACC)普遍提供C原生API,使…...

手把手教你用思博伦GSS7000的SimReplayPlus模块:从硬件连接到功率调节的完整避坑指南
手把手教你用思博伦GSS7000的SimReplayPlus模块:从硬件连接到功率调节的完整避坑指南 第一次接触思博伦GSS7000卫星导航模拟器时,面对复杂的硬件接口和PosApp软件里密密麻麻的参数,不少工程师会感到无从下手。作为业内公认的高精度测试设备&a…...

IDC服务商快速上手命令合集
做idc服务商的,最主要就是对客户服务器进行维护,本篇文章主要就是将平常主要的维护操作,做一个合集,方便维护时快速调用。也方便欧云服务器的代理和各位同行朋友使用,降低难度。0、linux换源命令bash <(curl -sSL h…...

MySQL 索引特性与性能优化全解
🔥草莓熊Lotso:个人主页 ❄️个人专栏: 《C知识分享》 《Linux 入门到实践:零基础也能懂》 ✨生活是默默的坚持,毅力是永久的享受! 🎬 博主简介: 文章目录前言:一. 索引是什么1.1 初…...

seo在线分析技巧有哪些
SEO在线分析技巧有哪些? 在当今的数字化时代,搜索引擎优化(SEO)已经成为了每一个网站和在线业务的关键。特别是在百度这样的中文搜索引擎平台上,掌握SEO在线分析技巧对提升网站的可见度和流量至关重要。具体有哪些SEO…...