实验六 调度器-实验部分
目录
一、知识点
1.进程调度器设计的目标
1.1.进程的生命周期
1.2.用户进程创建与内核进程创建
1.3.进程调度器的设计目标
2.ucore 调度器框架
2.1.调度初始化
2.2.调度过程
2.2.1.调度整体流程
2.2.2.设计考虑要点
2.2.3.数据结构
2.2.4.调度框架应与调度算法无关
2.3.进程状态
2.4.内核抢占点
2.5.进程切换过程
3.Round-Robin 调度算法
4.Stride调度算法
4.1.基本思路
4.2.使用优先级队列实现Stride Scheduling
4.3.斜堆实现优先级队列举例
二、练习解答
1.练习1(使用Round-Robin调度算法)
1.1.分析sched_calss中各个函数指针的用法
1.2.描述Round Robin调度算法在ucore执行过程
2.练习2(实现Stride Scheding调度算法)
2.1.初始化队列
2.2.入队和出列
2.3.选择调度的进程
一、知识点
1.进程调度器设计的目标
本章介绍调度器涉及的核心知识点以及进程调度器设计的目标进程的生命周期的角度看,、切换、退出属于操作系统课程的第5个实验的重要内容。本章继续从进程的生命周期角度出发,对进程调度进行设计与分析。
1.1.进程的生命周期
一个进程存在5个状态,这5个状态分别是创建、退出、就绪、运行、等待。进入这5中状态,由不同的情况触发,并且做不同的事情,见图1-1。
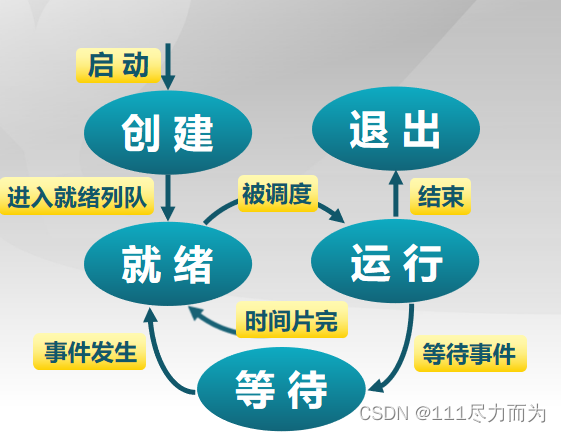
图1-1 进程的5个状态
进程创建(创建-->就绪)。进程的创建分别由三种情况触发,1)系统初始化时,这时候内核会创建0号进程和1号进程,这些是在进入内核初始化函数的时候创建的。2)用户请求一个进程,典型的方式是用户在shell终端启动一个进程。3)正在运行的进程执行了一个创建进程的系统调用。进程被创建成功后,就会将该进程放在就绪队列中,并且它的状态就是就绪状态。
进程执行(就绪-->运行)。内核会根据进程调度器的调度算法,选择一个进程占用处理机并执行。
进程退出(运行-->退出)。进程退出有4种情况:1)正常退出(自愿的)。2)错误退出(自愿的)。3)致命错误(强制性的)。4)被其他进程所杀(强制性的)。退出的过程中会将进程所拥有的内存资源和CPU资源释放,其中内存包括进程控制块,堆栈,虚拟内存管理器等。
进程等待(运行-->等待)。进程进入等待(阻塞)的情况:1)请求并等待系统服务,无法马上完成。2)启动某种操作,无法马上完成。3)需要的数据没有到达。进程等待是只有进程本身知道何时需要等待何种事件发生。
进程抢占(运行-->就绪)。进程会发生抢占的情况有:1)高优先级进程就绪。2)进程执行当前时间用完。
进程唤醒(等待-->就绪)。唤醒进程的情况:1)被阻塞进程需要的资源可被满足。2)被阻塞进程等待的事件到达。进程只能被别的进程或操作系统唤醒。
1.2.用户进程创建与内核进程创建
操作系统课程第5个实验,已经详细的说明了进程创建的过程,本章复用第5个实验的重要成果,即假设读者已经掌握了创建独立的用户进程和内核进程,见图1-2。
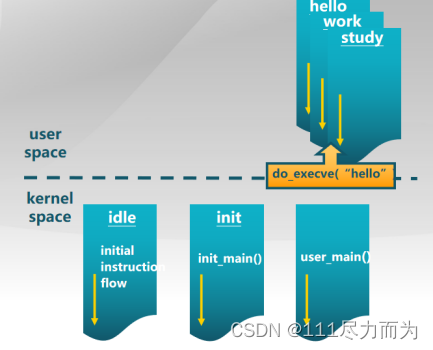
图1-2 创建独立的用户进程和内核进程
1.3.进程调度器的设计目标
进程调度器的设计目标是当操作系统中存在多个进程的时候,什么时候,选择什么进程进程执行。为了实现这个目标,我们需要完成以下4个小目标:
1)熟悉 ucore 调度器框架
2)理解Round-Robin 调度算法
3)理解并实现Stride调度算法
2.ucore 调度器框架
在这个章节对调度器的调度框架进行简单的介绍,它主要由两部分的内容构成:1)调度初始化。2)调度的过程。调度初始化主要在init.c/kern_init()/sched_init()中进行完成的。而调度过程主要由调度点触发、进程选择、进程切换等一些列活动构成。
2.1.调度初始化
首先需要实现一个调度算法类,这个类对外提供的接口如下:
// The introduction of scheduling classes is borrrowed from Linux, and makes the
// core scheduler quite extensible. These classes (the scheduler modules) encapsulate
// the scheduling policies.
struct sched_class {// the name of sched_classconst char *name;// Init the run queuevoid (*init)(struct run_queue *rq);// put the proc into runqueue, and this function must be called with rq_lockvoid (*enqueue)(struct run_queue *rq, struct proc_struct *proc);// get the proc out runqueue, and this function must be called with rq_lockvoid (*dequeue)(struct run_queue *rq, struct proc_struct *proc);// choose the next runnable taskstruct proc_struct *(*pick_next)(struct run_queue *rq);// dealer of the time-tickvoid (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);/* for SMP support in the future* load_balance* void (*load_balance)(struct rq* rq);* get some proc from this rq, used in load_balance,* return value is the num of gotten proc* int (*get_proc)(struct rq* rq, struct proc* procs_moved[]);*/
};然后在kern_init()函数中,需要对调度算法类进行初始化,这个初始化函数是sched.c/sched_init()函数。它的具体实现如下:
sched_init(void) {list_init(&timer_list);sched_class = &default_sched_class;rq = &__rq;rq->max_time_slice = MAX_TIME_SLICE;sched_class->init(rq);cprintf("sched class: %s\n", sched_class->name);
}其中sched_class是一个全局调度算法类指针,它记录的是现在的操作系统中使用的调度算法。其中rq 是一个全局的调度队列指针,它记录的是现在的操作系统中使用的调度队列。
以上的程序完成了调度器框架的初始化,但是关于进程被调度的时候,需要设置调度点。举个例子,当程序退出的时候,调用do_exit()函数,在这个函数中,会调用schedule()来设置调度点。设置了调度点,当程序被调用的时候,就会进行调度。
2.2.调度过程
2.2.1.调度整体流程
对于进程的调度过程是固定的,它的流程如下:
1)触发:trigger scheduling
2)入队:‘enqueue’
3)选取:pick up
4)出队:‘dequeue’
5)切换:process switch2.2.2.设计考虑要点
数据结构组织方式。实行一个进程调度策略,到底需要实现哪些基本功能对应的数据结构?首先考虑到一个无论哪种调度算法都需要选择一个就绪进程来占用CPU运行。为此我们可把就绪进程组织起来,可用队列(双向链表)、二叉树、红黑树、数组…等不同的组织方式。
操作方式。在操作方面,如果需要选择一个就绪进程,就可以从基于某种组织方式的就绪进程集合中选择出一个进程执行。需要注意,这里“选择”和“出”是两个操作,选择是在集合中挑选一个“合适”的进程,“出”意味着离开就绪进程集合。另外考虑到一个处于运行态的进程还会由于某种原因(比如时间片用完了)回到就绪态而不能继续占用CPU执行,这就会重新进入到就绪进程集合中。这两种情况就形成了调度器相关的三个基本操作:在就绪进程集合中选择、进入就绪进程集合和离开就绪进程集合。这三个操作属于调度器的基本操作。
选择进程。在进程的执行过程中,就绪进程的等待时间和执行进程的执行时间是影响调度选择的重要因素,这两个因素随着时间的流逝和各种事件的发生在不停地变化,比如处于就绪态的进程等待调度的时间在增长,处于运行态的进程所消耗的时间片在减少等。这些进程状态变化的情况需要及时让进程调度器知道,便于选择更合适的进程执行。所以这种进程变化的情况就形成了调度器相关的一个变化感知操作:timer时间事件感知操作。这样在进程运行或等待的过程中,调度器可以调整进程控制块中与进程调度相关的属性值(比如消耗的时间片、进程优先级等),并可能导致对进程组织形式的调整(比如以时间片大小的顺序来重排双向链表等),并最终可能导致调选择新的进程占用CPU运行。这个操作属于调度器的进程调度属性调整操作。
2.2.3.数据结构
在理解框架之前,需要先了解一下调度器框架所需要的数据结构。
通常的操作系统中,进程池是很大的(虽然在ucore中,MAX_PROCESS很小)。在ucore中,调度器引入run-queue(简称rq,即运行队列)的概念,通过链表结构管理进程。
由于目前ucore设计运行在单CPU上,其内部只有一个全局的运行队列,用来管理系统内全部的进程。
运行队列通过链表的形式进行组织。链表的每一个节点是一个list_entry_t,每个list_entry_t又对应到了structproc_struct*,这其间的转换是通过宏le2proc来完成的。具体来说,我们知道在structproc_struct中有一个叫run_link的list_entry_t,因此可以通过偏移量逆向找到对因某个run_list的structproc_struct。即进程结构指针proc=le2proc(链表节点指针,run_link)。
为了保证调度器接口的通用性,ucore调度框架定义了如下接口,该接口中,几乎全部成员变量均为函数指针。具体的功能会在后面的框架说明中介绍。
struct sched_class {// the name of sched_classconst char *name;// Init the run queuevoid (*init)(struct run_queue *rq);// put the proc into runqueue, and this function must be called with rq_lockvoid (*enqueue)(struct run_queue *rq, struct proc_struct *proc);// get the proc out runqueue, and this function must be called with rq_lockvoid (*dequeue)(struct run_queue *rq, struct proc_struct *proc);// choose the next runnable taskstruct proc_struct *(*pick_next)(struct run_queue *rq);// dealer of the time-tickvoid (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);/* for SMP support in the future* load_balance* void (*load_balance)(struct rq* rq);* get some proc from this rq, used in load_balance,* return value is the num of gotten proc* int (*get_proc)(struct rq* rq, struct proc* procs_moved[]);*/
};此外,proc.h中的structproc_struct中也记录了一些调度相关的参数信息:
struct proc_struct {// . . .// 该进程是否需要调度, 只对当前进程有效volatile bool need_resched;// 该进程的调度链表结构, 该结构内部的连接组成了 运行队列 列表list_entry_t run_link;// 该进程剩余的时间片, 只对当前进程有效int time_slice;// round-robin 调度器并不会用到以下成员// 该进程在优先队列中的节点, 仅在 LAB6 使用skew_heap_entry_t lab6_run_pool;// 该进程的调度优先级, 仅在 LAB6 使用uint32_t lab6_priority;// 该进程的调度步进值, 仅在 LAB6 使用uint32_t lab6_stride;
};在此次实验中,你需要了解default_sched.c中的实现RR调度算法的函数。在该文件中,你可以看到ucore已经为RR调度算法创建好了一个名为RR_sched_class的调度策略类。
通过数据结构 struct run_queue 来描述完整的 run_queue(运行队列)。它的主要结构如下:
struct run_queue {//其运行队列的哨兵结构, 可以看作是队列头和尾list_entry_t run_list;//优先队列形式的进程容器, 只在 LAB6 中使用skew_heap_entry_t *lab6_run_pool;//表示其内部的进程总数unsigned int proc_num;//每个进程一轮占用的最多时间片int max_time_slice;
};在ucore框架中,运行队列存储的是当前可以调度的进程,所以,只有状态为runnable的进程才能够进入运行队列。当前正在运行的进程并不会在运行队列中,这一点需要注意。
2.2.4.调度框架应与调度算法无关
虽然进程各种状态变化的原因和导致的调度处理各异,但其实仔细观察各个流程的共性部分,会发现其中只涉及了三个关键调度相关函数:wakup_proc、shedule、run_timer_list。如果我们能够让这三个调度相关函数的实现与具体调度算法无关,那么就可以认为ucore实现了一个与调度算法无关的调度框架。
wakeup_proc函数其实完成了把一个就绪进程放入到就绪进程队列中的工作,为此还调用了一个调度类接口函数sched_class_enqueue,这使得wakeup_proc的实现与具体调度算法无关。
void
wakeup_proc(struct proc_struct *proc) {assert(proc->state != PROC_ZOMBIE);bool intr_flag;local_intr_save(intr_flag);{if (proc->state != PROC_RUNNABLE) {proc->state = PROC_RUNNABLE;proc->wait_state = 0;if (proc != current) {sched_class_enqueue(proc);}}else {warn("wakeup runnable process.\n");}}local_intr_restore(intr_flag);
}schedule函数完成了与调度框架和调度算法相关三件事情:把当前继续占用CPU执行的运行进程放放入到就绪进程队列中,从就绪进程队列中选择一个“合适”就绪进程,把这个“合适”的就绪进程从就绪进程队列中摘除。
void
schedule(void) {bool intr_flag;struct proc_struct *next;local_intr_save(intr_flag);{current->need_resched = 0;if (current->state == PROC_RUNNABLE) {sched_class_enqueue(current);}if ((next = sched_class_pick_next()) != NULL) {sched_class_dequeue(next);}if (next == NULL) {next = idleproc;}next->runs ++;cprintf("current process name=%s\n",current->name);cprintf("next process name=%s\n",next->name);if (next != current) {proc_run(next);}}local_intr_restore(intr_flag);
}在每次timer中断处理过程中被调用,从而可用来调用调度算法所需的timer时间事件感知操作,调整相关进程的进程调度相关的属性值。通过调用调度类接口函数sched_class_proc_tick使得此操作与具体调度算法无关。
static void
trap_dispatch(struct trapframe *tf)
{//...case IRQ_OFFSET + IRQ_TIMER://LAB5ticks++;//0.01s is one clock interrupt,update LAB5 CODE//LAB6sched_class_proc_tick(current);break;//...
}2.3.进程状态
在此次实验中,进程的状态之间的转换需要有一个更为清晰的表述,在ucore中,runnable的进程会被放在运行队列中。值得注意的是,在具体实现中,ucore定义的进程控制块struct proc_struct包含了成员变量state,用于描述进程的运行状态,而running和runnable共享同一个状态(state)值(PROC_RUNNABLE。ucore的进程控制块的代码如下:
struct proc_struct {enum proc_state state; // Process stateint pid; // Process IDint runs; // the running times of Procesuintptr_t kstack; // Process kernel stackvolatile bool need_resched; // bool value: need to be rescheduled to release CPU?struct proc_struct *parent; // the parent processstruct mm_struct *mm; // Process's memory management fieldstruct context context; // Switch here to run processstruct trapframe *tf; // Trap frame for current interruptuintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)uint32_t flags; // Process flagchar name[PROC_NAME_LEN + 1]; // Process namelist_entry_t list_link; // Process link list list_entry_t hash_link; // Process hash listint exit_code; // exit code (be sent to parent proc)uint32_t wait_state; // waiting statestruct proc_struct *cptr, *yptr, *optr; // relations between processesstruct run_queue *rq; // running queue contains Processlist_entry_t run_link; // the entry linked in run queueint time_slice; // time slice for occupying the CPUskew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pooluint32_t lab6_stride; // FOR LAB6 ONLY: the current stride of the process uint32_t lab6_priority; // FOR LAB6 ONLY: the priority of process, set by lab6_set_priority(uint32_t)
};进程的正常生命周期如下:
- 进程首先在 cpu 初始化或者 sys_fork 的时候被创建, 当为该进程分配了一个进程控制块之后, 该进程进入 uninit态(在proc.c 中 alloc_proc)。
- 当进程完全完成初始化之后, 该进程转为runnable态。
- 当到达调度点时, 由调度器 sched_class 根据运行队列rq的内容来判断一个进程是否应该被运行, 即把处于runnable态的进程转换成running状态, 从而占用CPU执行。
- running态的进程通过wait等系统调用被阻塞, 进入sleeping态。
- sleeping态的进程被wakeup变成runnable态的进程。
- running态的进程主动 exit 变成zombie态, 然后由其父进程完成对其资源的最后释放, 子进程的进程控制块成为unused。
- 所有从runnable态变成其他状态的进程都要出运行队列, 反之, 被放入某个运行队列中
2.4.内核抢占点
调度的本质是CPU的抢占。对于用户进程而言,由于中断的产生,可以随时打断用户进程的执行,转到内核内部执行,从而给了操作系统调度的权利。操作系统依据调度策略选择一个进程,对当前的进程进行切换,切换到下一个进程进行执行。这体现了程序的可抢占性(preemptive),其实就是有没有一个进程/线程切换到另外一个进程/线程的情况。但是如果把ucore操作系统也看做是一种特殊的内核进程和多个内核线程的集合,那么ucore是否也是可以抢占的呢?其实ucore内核执行是不可以抢占的(non-preemptive),理由是内核进程使用一个内核栈,当内核进程的代码正在执行的时候,有了中断,此时不会切换栈,即不会切换内核栈到用户栈,也不会进行调度,即调用schedule()函数。因此CPU的控制权还在内核状态的内核进程空间中。这里需要注意的是,不是所有的情况下ucore内核执行都不是不可抢占的,有以下的几种固定情况除外。
1)进行同步互斥操作, 比如争抢一个信号量、 锁( lab7中会详细分析) ;
2) 进行磁盘读写等耗时的异步操作, 由于等待完成的耗时太长, ucore会调用shcedule让其他就绪进程执行。
这几种情况其实是由于当前的进程所需的某个资源(也称事件)无法得到满足,无法继续执行下去,从而不得不主动放弃对CPU的控制权。如果参考用户进程任何位置都可以被内核打断并放弃CPU的控制权,这些在内核中放弃CPU控制权的执行地点是“固定”的而不是“任意”的,这并不能体现内核任意位置都可以抢占性特点。我们搜寻一下实验五的代码,可以发现有如下几个地方调用了schedule函数:
表1 调用进程调度函数schedule的位置和原因
| 编号 | 位置 | 原因 |
| 1 | proc.c::do_exit | 用户进程执行结束,主动放弃CPU |
| 2 | proc.c::do_wait | 用户进程等待子进程结束,主动放弃CPU控制权 |
| 3 | proc.c::init_mian | 1、initproc内核线程等待所有用户进程结束,如果没有结束,就主动放弃CPU的控制权;2、initproc内核线程在所有用户进程结束后,用户进程会调用sys_exit系统调用,在这个系统调用中会释放空闲的资源。 |
| 4 | proc.c::cpu_idle | idleproc内核线程的主要工作是等待有处于就绪态的进程或线程,如果有就调用schedule函数 |
| 5 | sync.h::lock | 在获取锁的过程中,如果无法满足得到锁,则主动放弃CPU的控制权。 |
| 6 | trap.c::trap | 如果当前进程在用户态被打断去,且当前进程控制块的成员变量need_resched设置成1,则当前进程会放弃CPU的控制权。 |
仔细分析上述的位置,第1、2、5处的执行位置体现了由于获取某种资源一时得不到满足、进程要退出、进程要休眠等原因而不得不主动放弃CPU。第3、4处的执行位置比较特殊,initproc内核线程等待用户进程结束而执行schedule函数;idle内核线程在没有进程处于就绪状态时才执行,一旦有了就绪状态进程,它将执行schedule函数完成进程调度。这里只有第6处的位置比较特殊:
void
trap(struct trapframe *tf) {// dispatch based on what type of trap occurred// used for previous projectsif (current == NULL) {trap_dispatch(tf);}else {// keep a trapframe chain in stackstruct trapframe *otf = current->tf;current->tf = tf;bool in_kernel = trap_in_kernel(tf);trap_dispatch(tf);current->tf = otf;if (!in_kernel) {if (current->flags & PF_EXITING) {do_exit(-E_KILLED);}if (current->need_resched) {schedule();}}}
}这里表明了只有当进程在用户态执行“任意”某处用户代码位置时才能发生中断,且当前进程控制块成员变量need_resched为1(表示需要调度了)时,才会执行shedule函数。这实际上体现了用户进程的可抢占性。如果没有第一个if语句,那么就可以体现内核代码的可抢占性。但是如果把第一个if语句去掉,我们就不得不实现对ucore中的所有全局变量的互斥访问操作,以防止所有的竞争状态,这样的ucore实现复杂度会增加不少。
2.5.进程切换过程
进程调度函数schedule选择了下一个将占用CPU执行的进程后,将调用进程切换,从而让新的进程得到执行。通过实验四和实验五的理解,应该已经对进程调度和上下文切换有了初步的认识。在实验五中,结合调度器框架的设计,可对ucore中的进程切换一级堆栈的维护和使用等更加深刻的认识。假定有两个用户进程,在二者进行进程切换的过程中,具体的步骤如下:
首先在执行某进程A的用户代码时,出现了一个trap(例如是一个外设产生的中断),这个时候就会从进程A的用户态切换到内核态(过程(1)),并且保存好进程A的trapframe;当内核态处理中断时发现需要进行进程切换时,ucore要通过schedule函数选择下一个将占用CPU执行的进程(即进程B),然后会调用proc_run函数,proc_run函数进一步调用switch_to函数,切换到进程B的内核状态(过程(2)),继续进程B上一次在内核态的操作,并通过iret指令,最终将执行权转交给进程B的用户空间(过程(3))。
当进程B由于某种原因发生中断之后(过程(4)),会从进程B的用户态切换到内核态,并且保存好进程B的trapframe;当内核态处理中断时发现需要进行进程切换时,即需要切换到进程A,ucore再次切换到进程A(过程(5)),会执行进程A上一次在内核调用schedule(具体还要跟踪到switch_to函数)函数返回后的下一行代码,这行代码当然还是在进程A的上一次中断处理流程中。最后当进程A的中断处理完毕后,执行权又会反交给进程A的用户代码(过程(6))。 这就是在只有两个进程的情况下, 进程切换间的大体流程。
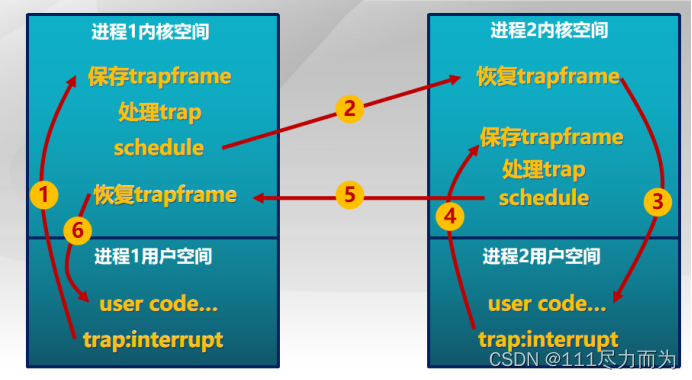
图2-1 两个进程之间的切换
其中进程切换schedule()函数,会在内核地址空间中对进程1的trapframe进行保存,并且对进程2的trapframe进行恢复,switch_to()函数的关键代码如下:
.text
.globl switch_to
switch_to: # switch_to(from, to)# save from's registersmovl 4(%esp), %eax # eax points to frompopl 0(%eax) # save eip !poplmovl %esp, 4(%eax)movl %ebx, 8(%eax)movl %ecx, 12(%eax)movl %edx, 16(%eax)movl %esi, 20(%eax)movl %edi, 24(%eax)movl %ebp, 28(%eax)# restore to's registersmovl 4(%esp), %eax # not 8(%esp): popped return address already# eax now points to tomovl 28(%eax), %ebpmovl 24(%eax), %edimovl 20(%eax), %esimovl 16(%eax), %edxmovl 12(%eax), %ecxmovl 8(%eax), %ebxmovl 4(%eax), %esppushl 0(%eax) # push eipret几点需要强调的是:
a)需要透彻理解在进程切换以后,程序是从哪里开始执行的?需要注意到虽然指令还是同一个cpu上执行,但是此时已经是另外一个进程在执行了,且使用的资源已经完全不同了。这一点参考switch_to()函数的实现。
b)内核在第一个程序运行的时候,需要进行哪些操作?有了实验四和实验五的经验,可以确定,内核启动第一个用户进程user_main的过程,实际上是从进程启动时的内核状态切换到该用户进程的内核状态的过程,而且该用户进程在用户态的起始入口应该是forkret()。这一点在实验五中还有待进一步理解,在此不在说明。
3.Round-Robin 调度算法
RR调度算法的调度思想是想让所有runnable态的进程分时轮流使用CPU的时间。RR调度器维护当前runnable进程的有序运行队列。当前进程的时间片用完之后,调度器将当前进程放置运行队列的尾部,再从其头部取出一个进程调度。RR调度算法的就绪队列在组织结构上是一个双向的链表,只是增加了一个成员变量,表明在此就绪队列中的最大执行时间片。而且在进程控制块proc_struct中增加了一个成员变量time_slice,用于记录进程当前可运行时间片段。这是由于RR调度算法需要考虑执行进程的运行时间不能太长。在每个timer到来的时候,操作系统会递减当前执行进程的time_slice,当time_slice为0时,这意味着这个进程运行了一段时间(这个时间片段称为进程的时间片),需要把CPU让给其他的进程执行,于是操作系统就需要让此进程重新回到rq的队列尾部,且重置此进程的时间片为就绪队列的成员变量最大时间片max_time_slice值,然后再从rq的队列头取出一个新的进程执行。接下来分析其调度算法的实现。
RR_enqueue的函数实现如下表所示。即把某进程的进程控制块指针放入到rq队列末尾,且如果进程控制块的时间片为0,则需要把它重置为rq成员变量max_time_slice。这表示如果进程在当前的执行时间片已经用完,需要等到下一次有机会运行时,才能再执行一段时间。
static void
RR_enqueue(struct run_queue *rq, struct proc_struct *proc) {assert(list_empty(&(proc->run_link)));list_add_before(&(rq->run_list), &(proc->run_link));if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {proc->time_slice = rq->max_time_slice;}proc->rq = rq;rq->proc_num ++;
}RR_pick_next的函数实现如下表所示。即选取就绪进程队列rq中的队头队列元素,并把队列元素转换成进程控制块指针。
static struct proc_struct *
RR_pick_next(struct run_queue *rq) {list_entry_t *le = list_next(&(rq->run_list));if (le != &(rq->run_list)) {return le2proc(le, run_link);}return NULL;
}RR_dequeue的函数实现如下表所示。即把就绪进程队列rq的进程控制块指针的队列元素删除,并把表示就绪进程个数的proc_num减一。
static void
RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {assert(!list_empty(&(proc->run_link)) && proc->rq == rq);list_del_init(&(proc->run_link));rq->proc_num --;
}RR_proc_tick的函数实现如下表所示。即每次timer到时后,trap函数将会间接调用此函数来把当前执行进程的时间片time_slice减一。如果time_slice降到零,则设置此进程成员变量need_resched标识为1,这样在下一次中断来后执行trap函数时,会由于当前进程程成员变量need_resched标识为1而执行schedule函数,从而把当前执行进程放回就绪队列末尾,而从就绪队列头取出在就绪队列上等待时间最久的那个就绪进程执行。
static void
RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {if (proc->time_slice > 0) {proc->time_slice --;}if (proc->time_slice == 0) {proc->need_resched = 1;}
}4.Stride调度算法
4.1.基本思路
考察round-robin调度器,在假设所有进程都充分使用了其拥有的CPU时间资源的情况下,所有的进程得到的CPU时间应该是相等的。但是有时候我们希望调度器能够更加智能的为每个进程分配合理的CPU资源。假设我们为不同的进程分配不同的优先级,则我们有可能希望每一个进程得到的时间资源与他们优先级成正比。Stride调度是基于这种想法的一种较为典型和简单的算法。除了简单易于实现之外,它还有如下的特点:
可控性:正如我们希望的那样子了,可以证明Stride Scheduling对进程的调度次数正比与其优先级。
确定性:在不考虑计时器事件的情况下,整个调度机制都是可以预知和重现的。
该算法的基本思想可以考虑如下:
- 为每一个runnable的进程设置一个当前状态stride,表示该进程当前的调度权。另外其对应的pass值,表示对应进程在调度后,stride需要进行的累加值。
- 每次需要调度时,从当前的runnable态的进程中选择stride最小的进程调度。
- 对于获得调度的进程P,将对应的stride加上其对应的步长pass(只与进程的优先权有关系)。
- 在一段固定的时间之后,回到2.步骤,重新调度当前的stride 最小的进程。可以证明,如果令P.pass=BigStride/P.priority其中P.priority表示进程的优先权(>=1),而BigStride表示一个预先定义的大常数,则该调度方案为每个进程分配的时间将与其优先级成正比。
这里采用一段程序进行简单的说明
假设进行a,b,c都是16位的数字,他们进行计算的程序如下:
void main(){
uint16_t a = 98;uint16_t b = 65534;int16_t c = a-b;int16_t d = 0;if(c>0){//答案是c=100,走该分支d = 8;}else if(c==0){d = 0;}else{d = -8;}
}为什么a的数值小于b,计算的c却大于0?
a=原码(0000,0000,0110,0010),b=原码(1111,1111,1111,1110),a-b=a+(-b),这样无符号之间的减法,变成了b有符号的加法了。b的补码是(1000,0000,0000,0010),则-b的补码是(0000,0000,0000,0010),符号位直接参与计算。计算的过程如下:
a-b=原码(0000,0000,0110,0010)-原码(1111,1111,1111,1110)
=a+(-b)
=补码(0000,0000,0110,0010)+补码(0000,0000,0000,0010)
=补码(0000,0000,0110,0100)
=原码(0000,0000,0110,0100)从上面的例子可以看出,计算两个数字相减,可以转换成补码的方式进行相加(变符号位),计算完成后的补码需要还原成原码,这就是最终的结果原码(0000,0000,0110,0100),它代表的是100。PS:计算机的减法运算采用补码计算,计算机的加法运算采用原码计算。
- init
初始化调度器类的信息(如果有的话)
初始化当前的运行队列为一个空的容器。(比如和RR调度算法一样,初始化为一个有序列表)
- enqueue
初始化刚进入运行队列的进程proc的stride属性
将proc插入运行队列中去(注意:这里并不要求放置在队列头部)
- dequeue
从运行队列中删除相应的元素
- pick next
扫描整个运行队列,返回其中stride值最小的对应进程
更新对应进程的stride值,即pass=BIG_STRIDE/P->priority;P->stride += pass。
- proc tick
检测当前进程是否用完已经分配的时间片。如果时间片用完,应该正确设置进程结构的相关标记来引起进程的切换。
一个process最多可以连续运行rq.max_time_slice个时间片。
在具体实现时,有一个需要注意的地方:strides属性的溢出问题,在之前的实现里面我们并没有考虑stride的数值范围,而这个值在理论上是不断增加的,在stride溢出以后,基于stride的比较可能会出现错误。比如假设当前存在两个进程A和B,stride属性采用16位无符号整数进行存储。当前的队列中元素如下:
| A.stride(实际值) | A.stride(理论值) | A.pass(=BigStride/A.prority) |
| 65534 | 65534 | 100 |
| B.stride(实际值) | B.stride(理论值) | B.pass(=BigStride/B.prority) |
| 65535 | 65535 | 50 |
此时应该选择A作为调度的进程,而在一轮调度后(调度A后),队列如下:
| A.stride(实际值) | A.stride(理论值) | A.pass(=BigStride/A.prority) |
| 98 | 65634 | 100 |
| B.stride(实际值) | B.stride(理论值) | B.pass(=BigStride/B.prority) |
| 65535 | 65535 | 50 |
可以看到由于溢出的出现,进程间stride的理论比较和实际比较结果出现了偏差。我们首先在理论上分析这个问题:令PASS_MAX为当前所有进程里最大的步进值。则我们可以证明如下结论:对每次Stride调度器的调度步骤中,有其最大的步进值STRIDE_MAX和最小的步进值STRIDE_MIN之差:STRIDE_MAX - STRIDE_MIN <= PASS_MAX
提示1:如何证明该结论?
为了理解这个问题,我们先举个stride调度器调度的例子。
| 调度次数 | 进程P1(pass=16) | 进程P2(pass=7) | 进程P2(pass=10) | stride_max -stride_min | pass_max | 结论成立么? |
| 初值 | stride=100 | stride=113 | stride=102 | 13 | 16 | 成立 |
| 1 | stride=116 | stride=113 | stride=102 | 14 | 16 | 成立 |
| 2 | stride=116 | stride=113 | stride=112 | 4 | 16 | 成立 |
| 3 | stride=116 | stride=113 | stride=122 | 9 | 16 | 成立 |
| 4 | stride=116 | stride=120 | stride=122 | 6 | 16 | 成立 |
从上面的例子中看上去,结论是成立的。把上面的过程公式化,使得例子更加具有普遍性。
| 调度次数 | 进程P1(P1_pass) | 进程P2(P2_pass) | 进程P3(P3_pass) | 进程P4(P4_pass) | stride_max -stride_min | 结论成立么? |
| 初值 | 0 | 0 | 0 | 0 | 0 | 成立 |
| 1 | P1_pass | P2_pass | P3_pass | P4_pass | Pi_pass -Pj_pass | 成立 |
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| ... | ||||||
| k | P1_stride_k | P2_stride_k | P3_stride_k(假设最大) | P4_stride_k(假设最小) | 成立 | |
| k+1 | P1_stride_k | P2_stride_k | P3_stride_k | P4_stride_k +P4_pass |
在第一次调度的时候,假设Pi_pass最大,Pj_pass最小,这两个进程来自P1/P2/P3/P4中,那么
Stride_max-Stride_min
=Pi_pass-Pj_pass
<=Pi_pass//其中Pj_pass是一个大于1的数
<=max(P1,P2,P3,P4)//第一次调度成立假设在第K次(K>1)的调度中,那个结论是成立的,那么K+1次的调度中,那个结论成立么?
从第K次的调度中,能得到什么呢?假设P3_stride_k是第k次调度中最大的,P4_stride_k是第k次调度中最小的。那么有一个条件一定成立:
Stride_max-Stride_min=P3_stride_k-P4_stride_k<=pass_max
在第K+1次的调度中,stride算法的执行过程如上表1 stride算法调度举例。此时Stride_max可能是P3_stride_k/P4_stride_k+P4_pass,此时Stride_min可能是P1_stride_k/P2_stride_k/P4_stride_k+P4_pass。
情况1:P3_stride_k最大
P3_stride_k-P1_stride_k<=pass_max//一定成立,来自第K步的结论
P3_stride_k-P2_stride_k<=pass_max//一定成立,来自第K步的结论
P3_stride_k-(P4_stride_k+P4_pass)=(P3_stride_k-P4_stride_k)-P4_pass<=pass_max-P4_pass<=pass_max//第K+1步成立
情况2:P4_stride_k+P4_pass最大
P4_stride_k+P4_pass-P1_stride_k=P4_pass+(P4_stride_k-P1_stride_k)<=pass_max//一定成立,来自第K步的结论,P4_pass减去了一个负数
P4_stride_k+P4_pass-P2_stride_k=P4_pass+(P4_stride_k-P2_stride_k)<=pass_max//一定成立,来自第K步的结论(P4_pass加上了一个负数)
(P4_stride_k+P4_pass)-P3_stride_k=P4_pass+(P4_stride_k-P3_stride_k)<=pass_max//一定成立,来自第K步的结论(P4_pass加上了一个负数)有了该结论,在加上之前对优先级,再加上之前对优先级有Priority>1限制,我们有STRIDE_MAX - STRIDE_MIN <=BIG_STRIDE,于是我们只要将BigStride取在某个范围之内,即可保证对于任意的两个Stride支持都会在机器整数的表示范围之内。而我们可以通过与0比较结构,来得到两个Stride的大小关系。在上例中,虽然在直接的数值上98<65535,但是98-65535的结果用带符号的16位整数表示的结果是99,与理论值之差相等。所以这个意义下98>65535。基于这种特殊考虑的比较方法,即便Stride有可能溢出,我们仍能够得到理论上的当前最小Stride,并作出正确的调度决定。
提问2:在ucore中,目前Stride采用无符号的32位整数表示。则BigStride应该取多少,才能保证比较的正确性?
- 因为stride<i+1>=stride<i>+BIG_STRIDE/priroty。stride<i>至少是1,于是BIG_STRIDE/priroty<=2^32-1,priroty>=1于是BIG_STRIDE<=2^32-1,这就是理论上的取值。
- 因为两个进程的stride值需要大小比较,两个32位无符号的stride值相减,用一个有符号的数来表示大小,这样BIG_STRIDE就不能带有符号位,最终BIG_STRIDE=2^31。举一个反例论证如下:
#define BIG_STRIDE (0xFFFF-1)
uint16_t a = 65534;
uint16_t b = 65535;
uint16_t a_pass = BIG_STRIDE;
uint16_t b_pass = 50;
a = a + a_pass;
int16_t c = a-b;//c=-3,期望是a的stride值大于b的stride值4.2.使用优先级队列实现Stride Scheduling
在上述的实现描述中,对于每个pick_next函数,我们都需要完成的扫描来获取最小的stride及其进程。这在进程非常多的时候是非常耗时和低效的,考虑调度选择(选最小值)与优先级队列的抽象逻辑一致,我们考虑使用优先级队列来实现该调度。
优先队列是这样一种数据结构:使用者可以快速的插入和删除队列中的元素,并且在预先指定的顺序下快速取得当前在队列中的最小(或者最大)值及其对应元素。可以看到,这样的数据结构非常符合Stride调度器的实现。
本次实验提供了libs/skew_heap.h作为优先队列的一个实现,该实现定义相关的结构和接口,其中主要包括:
static inline void skew_heap_init(skew_heap_entry_t *a) __attribute__((always_inline));
static inline skew_heap_entry_t *skew_heap_merge(skew_heap_entry_t *a, skew_heap_entry_t *b,compare_f comp);
static inline skew_heap_entry_t *skew_heap_insert(skew_heap_entry_t *a, skew_heap_entry_t *b,compare_f comp) __attribute__((always_inline));
static inline skew_heap_entry_t *skew_heap_remove(skew_heap_entry_t *a, skew_heap_entry_t *b,compare_f comp) __attribute__((always_inline));其中优先队列的顺序是由比较函数comp决定的,sched_stride.c中提供了proc_stride_comp_f比较器用来比较两个stride的大小,你可以直接使用它。当使用优先队列作为Stride调度器的实现方式之后,运行队列结构也需要作相关改变,其中包括:
- structrun_queue中的lab6_run_pool指针,在使用优先队列的实现中表示当前优先队列的头元素,如果优先队列为空,则其指向空指针(NULL)。
- structproc_struct中的lab6_run_pool结构,表示当前进程对应的优先队列节点。本次实验已经修改了系统相关部分的代码,使得其能够很好地适应LAB6新加入的数据结构和接口。而在实验中我们需要做的是用优先队列实现一个正确和高效的Stride调度器,如果用较简略的伪代码描述,则有:
- init(rq):
– Initialize rq->run_list
– Set rq->lab6_run_pool to NULL
– Set rq->proc_num to 0
- enqueue(rq, proc)
– Initialize proc->time_slice
– Insert proc->lab6_run_pool into rq->lab6_run_pool
– rq->proc_num ++
- dequeue(rq, proc)
– Remove proc->lab6_run_pool from rq->lab6_run_pool
– rq->proc_num --
- pick_next(rq)
– If rq->lab6_run_pool == NULL, return NULL
– Find the proc corresponding to the pointer rq->lab6_run_pool
– proc->lab6_stride += BIG_STRIDE / proc->lab6_priority
– Return proc
- proc_tick(rq, proc):
– If proc->time_slice > 0, proc->time_slice --
– If proc->time_slice == 0, set the flag proc->need_resched
4.3.斜堆实现优先级队列举例
- 首先实现斜堆插入,插入见图4-1。
设a是堆,b是堆,则b插入a中
1)a是空,返回b
2)b是空,返回a
3)a非空,b非空,a>b,a需要插入b中。则b的右子树与a合并成堆l(递归合并),b的左子树r,b的左子树设置成l,b的右子树设置成r。
a非空,b非空,a<=b,b需要插入a中。则a的右子树与b合并成堆l(递归合并),a的左子树r,a的左子树设置成l,a的右子树设置成r。
图4-1 插入数据
实现斜堆删除,删除见图4-2。
设a是堆,删除第一个元素a
1)a的左子树和a的右子树合并成堆rep
2)返回rep图4-2 删除数据
二、练习解答
1.练习1(使用Round-Robin调度算法)
以下的问题不需要编程,具体的原理见知识点部分。
1.1.分析sched_calss中各个函数指针的用法
struct sched_class {// the name of sched_classconst char *name;// Init the run queuevoid (*init)(struct run_queue *rq);// put the proc into runqueue, and this function must be called with rq_lockvoid (*enqueue)(struct run_queue *rq, struct proc_struct *proc);// get the proc out runqueue, and this function must be called with rq_lockvoid (*dequeue)(struct run_queue *rq, struct proc_struct *proc);// choose the next runnable taskstruct proc_struct *(*pick_next)(struct run_queue *rq);// dealer of the time-tickvoid (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);/* for SMP support in the future* load_balance* void (*load_balance)(struct rq* rq);* get some proc from this rq, used in load_balance,* return value is the num of gotten proc* int (*get_proc)(struct rq* rq, struct proc* procs_moved[]);*/
};void (*init)(struct run_queue *rq);初始化运行队列
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);向运行队列中添加可以执行的进程控制块
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);在找到需要删除的进程控制块后,删除进程控制块,表明之后该进程退出了,不需要继续运行
struct proc_struct *(*pick_next)(struct run_queue *rq);根据调度算法选择一个合适的运行进程进行调度。
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);运行队列中的该进程用完一个tick的时间,进行时间的更新。
1.2.描述Round Robin调度算法在ucore执行过程
首先,sched_init进行调度算法的初始化。
然后,调度过程,这个过程可以抽象成如下步骤,对于进程的调度过程是固定的,它的流程如下:
1)触发:trigger scheduling
2)入队:‘enqueue’
3)选取:pick up
4)出队:‘dequeue’
5)切换:process switch最后,调度算法和ucore的调度框架结合。
虽然进程各种状态变化的原因和导致的调度处理各异,但其实仔细观察各个流程的共性部分,会发现其中只涉及了三个关键调度相关函数:wakup_proc、shedule、run_timer_list。如果我们能够让这三个调度相关函数的实现与具体调度算法无关,那么就可以认为ucore实现了一个与调度算法无关的调度框架。
wakeup_proc函数其实完成了把一个就绪进程放入到就绪进程队列中的工作,为此还调用了一个调度类接口函数sched_class_enqueue,这使得wakeup_proc的实现与具体调度算法无关。
void
wakeup_proc(struct proc_struct *proc) {assert(proc->state != PROC_ZOMBIE);bool intr_flag;local_intr_save(intr_flag);{if (proc->state != PROC_RUNNABLE) {proc->state = PROC_RUNNABLE;proc->wait_state = 0;if (proc != current) {sched_class_enqueue(proc);}}else {warn("wakeup runnable process.\n");}}local_intr_restore(intr_flag);
}schedule函数完成了与调度框架和调度算法相关三件事情:把当前继续占用CPU执行的运行进程放放入到就绪进程队列中,从就绪进程队列中选择一个“合适”就绪进程,把这个“合适”的就绪进程从就绪进程队列中摘除。
void
schedule(void) {bool intr_flag;struct proc_struct *next;local_intr_save(intr_flag);{current->need_resched = 0;if (current->state == PROC_RUNNABLE) {sched_class_enqueue(current);}if ((next = sched_class_pick_next()) != NULL) {sched_class_dequeue(next);}if (next == NULL) {next = idleproc;}next->runs ++;cprintf("current process name=%s\n",current->name);cprintf("next process name=%s\n",next->name);if (next != current) {proc_run(next);}}local_intr_restore(intr_flag);
}在每次timer中断处理过程中被调用,从而可用来调用调度算法所需的timer时间事件感知操作,调整相关进程的进程调度相关的属性值。通过调用调度类接口函数sched_class_proc_tick使得此操作与具体调度算法无关。
static void
trap_dispatch(struct trapframe *tf)
{//...case IRQ_OFFSET + IRQ_TIMER://LAB5ticks++;//0.01s is one clock interrupt,update LAB5 CODE//LAB6sched_class_proc_tick(current);break;//...
}2.练习2(实现Stride Scheding调度算法)
以下的关键实现部分通过了测试,具体的原理见知识点部分。
2.1.初始化队列
static void
stride_init(struct run_queue *rq) {/* LAB6: YOUR CODE * (1) init the ready process list: rq->run_list* (2) init the run pool: rq->lab6_run_pool* (3) set number of process: rq->proc_num to 0 */list_init(&(rq->run_list));rq->lab6_run_pool = NULL;rq->proc_num = 0;
}2.2.入队和出列
利用斜堆的数据结构进行优先级队列的实现,这样的队列的队首元素始终是优先级最高的元素,那么每次调度的时候,只需要O(1)的时间就能找到调度的进程。在插入或删除一个进程后,一定要更新rq->lab6_run_pool指针!
static void
stride_enqueue(struct run_queue *rq, struct proc_struct *proc) {/* LAB6: YOUR CODE * (1) insert the proc into rq correctly* NOTICE: you can use skew_heap or list. Important functions* skew_heap_insert: insert a entry into skew_heap* list_add_before: insert a entry into the last of list * (2) recalculate proc->time_slice* (3) set proc->rq pointer to rq* (4) increase rq->proc_num*/rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool,&proc->lab6_run_pool,proc_stride_comp_f);if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {proc->time_slice = rq->max_time_slice;}proc->rq = rq;rq->proc_num++;
}/** stride_dequeue removes the process ``proc'' from the run-queue* ``rq'', the operation would be finished by the skew_heap_remove* operations. Remember to update the ``rq'' structure.** hint: see libs/skew_heap.h for routines of the priority* queue structures.*/
static void
stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {/* LAB6: YOUR CODE * (1) remove the proc from rq correctly* NOTICE: you can use skew_heap or list. Important functions* skew_heap_remove: remove a entry from skew_heap* list_del_init: remove a entry from the list*/rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool,&proc->lab6_run_pool,proc_stride_comp_f);rq->proc_num--;
}2.3.选择调度的进程
由于uCore中的函数proc_stride_comp_f已经给出源码,结合对应斜堆代码的理解,我们可以得出:stride值最小的进程在斜堆的最顶端。所以pick_next函数中我们可以直接选取rq->lab6_run_pool所指向的进程。
而stride值可以直接加上BIG_STRIDE / p->lab6_priority来完成该值的更新。不过这里有个需要注意的地方,除法运算是不能除以0的,所以我们需要在alloc_proc函数中将每个进程的priority都初始化为1
static int
proc_stride_comp_f(void *a, void *b)
{struct proc_struct *p = le2proc(a, lab6_run_pool);struct proc_struct *q = le2proc(b, lab6_run_pool);int32_t c = p->lab6_stride - q->lab6_stride;if (c > 0) return 1;else if (c == 0) return 0;else return -1;
}
static struct proc_struct *
stride_pick_next(struct run_queue *rq) {/* LAB6: YOUR CODE * (1) get a proc_struct pointer p with the minimum value of stride(1.1) If using skew_heap, we can use le2proc get the p from rq->lab6_run_pool(1.2) If using list, we have to search list to find the p with minimum stride value* (2) update p;s stride value: p->lab6_stride* (3) return p*/skew_heap_entry_t * skew = rq->lab6_run_pool;if(skew!=NULL){struct proc_struct *proc = le2proc(skew,lab6_run_pool);proc->lab6_stride = proc->lab6_stride + BIG_STRIDE/proc->lab6_priority;return proc;}return NULL;
}
相关文章:
实验六 调度器-实验部分
目录 一、知识点 1.进程调度器设计的目标 1.1.进程的生命周期 1.2.用户进程创建与内核进程创建 1.3.进程调度器的设计目标 2.ucore 调度器框架 2.1.调度初始化 2.2.调度过程 2.2.1.调度整体流程 2.2.2.设计考虑要点 2.2.3.数据结构 2.2.4.调度框架应与调度算法无关…...

基于飞桨paddle波士顿房价预测练习模型测试代码
基于飞桨paddle波士顿房价预测练习模型测试代码 导入基础库 #paddle:飞桨的主库,paddle 根目录下保留了常用API的别名,当前包括:paddle.tensor、paddle.framework、paddle.device目录下的所有API; import paddle #Lin…...
只会“点点点”,凭什么让开发看的起你?
众所周知,如今无论是大厂还是中小厂,自动化测试基本是标配了,毕竟像双 11、618 这种活动中庞大繁杂的系统,以及多端发布、多版本、机型发布等需求,但只会“写一些自动化脚本”很难胜任。这一点在招聘要求中就能看出来。…...

35.图片幻灯片
图片幻灯片 html部分 <div class"carousel"><div class"image-container"><img src"./static/20180529205331_yhGyf.jpeg" alt"" srcset""><img src"./static/20190214214253_hsjqw.webp"…...
CentOS7系统Nvidia Docker容器基于TensorFlow2.12测试GPU
CentOS7系统Nvidia Docker容器基于TensorFlow1.15测试GPU 参考我的另一篇博客 1. 安装NVIDIA-Docker的Tensorflow2.12.0版本 1. 版本依赖对应关系:从源代码构建 | TensorFlow GPU 版本Python 版本编译器构建工具cuDNNCUDAtensorflow-2.6.03.6-3.9GCC 7.3.1Ba…...
Go 下载安装教程
1. 下载地址:The Go Programming Language (google.cn) 2. 下载安装包 3. 安装 (1)下一步 (2)同意 (3)修改安装路径,如果不修改,直接下一步 更改后,点击下一…...
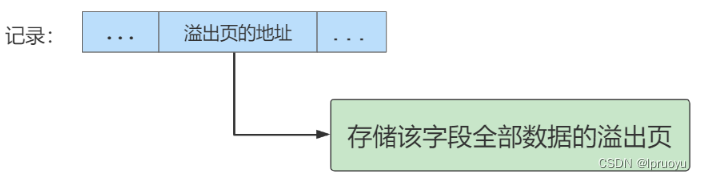
InnoDB数据存储结构
一. InnoDB的数据存储结构:页 索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读取和写入工作。不同存储引擎中存放的格式一般不同的,甚至有的存储引擎比如Memory都不用磁盘来存储数据,这里讲讲InooDB存储引擎…...
)
基于ts的浏览器缓存工具封装(含源码)
cache.ts缓存工具 浏览器缓存工具封装实现使用方法示例代码 浏览器缓存工具封装 在前端开发中,经常会遇到需要缓存数据的情况,例如保存用户的登录状态、缓存部分页面数据等 但有时候需要缓存一些复杂的对象,例如用户信息对象、设置配置等。…...

GIT涵盖工作中用的相关指令
git安装一直默认点击下去,安装完成,右键会看见gitBash git --version 查看git安装的版本 使用git前配置git git config --global user.name 提交人姓名 git config --global user.email 提交人邮箱 git config --list 查看git配置信息 使用git中配置…...
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
系列文章 【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一) 【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二) 【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三) 【如何训…...
[JAVAee]文件操作-IO
本文章讲述了通过java对文件进行IO操作 IO:input/output,输入/输出. 建议配合文章末尾实例食用 目录 文件 文件的管理 文件的路径 文件的分类 文件系统的操作 File类的构造方法 File的常用方法 文件内容的读写 FileInputStream读取文件 构造方法 常用方法 Scan…...
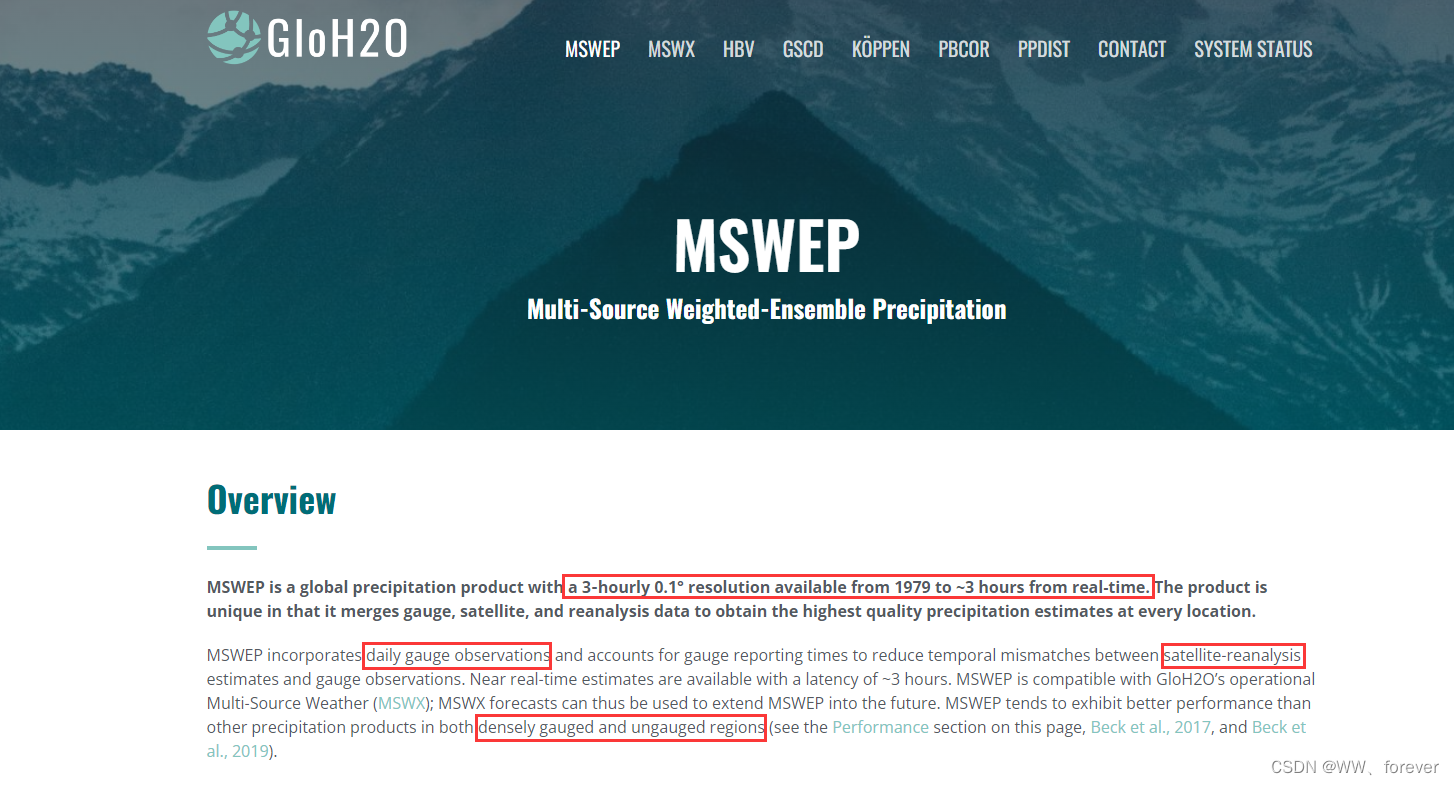
【数据集】3小时尺度降水数据集-MSWEPV2
1 MSWEP V2 precipitation product 官网-MSWEP V2降水产品 参考...
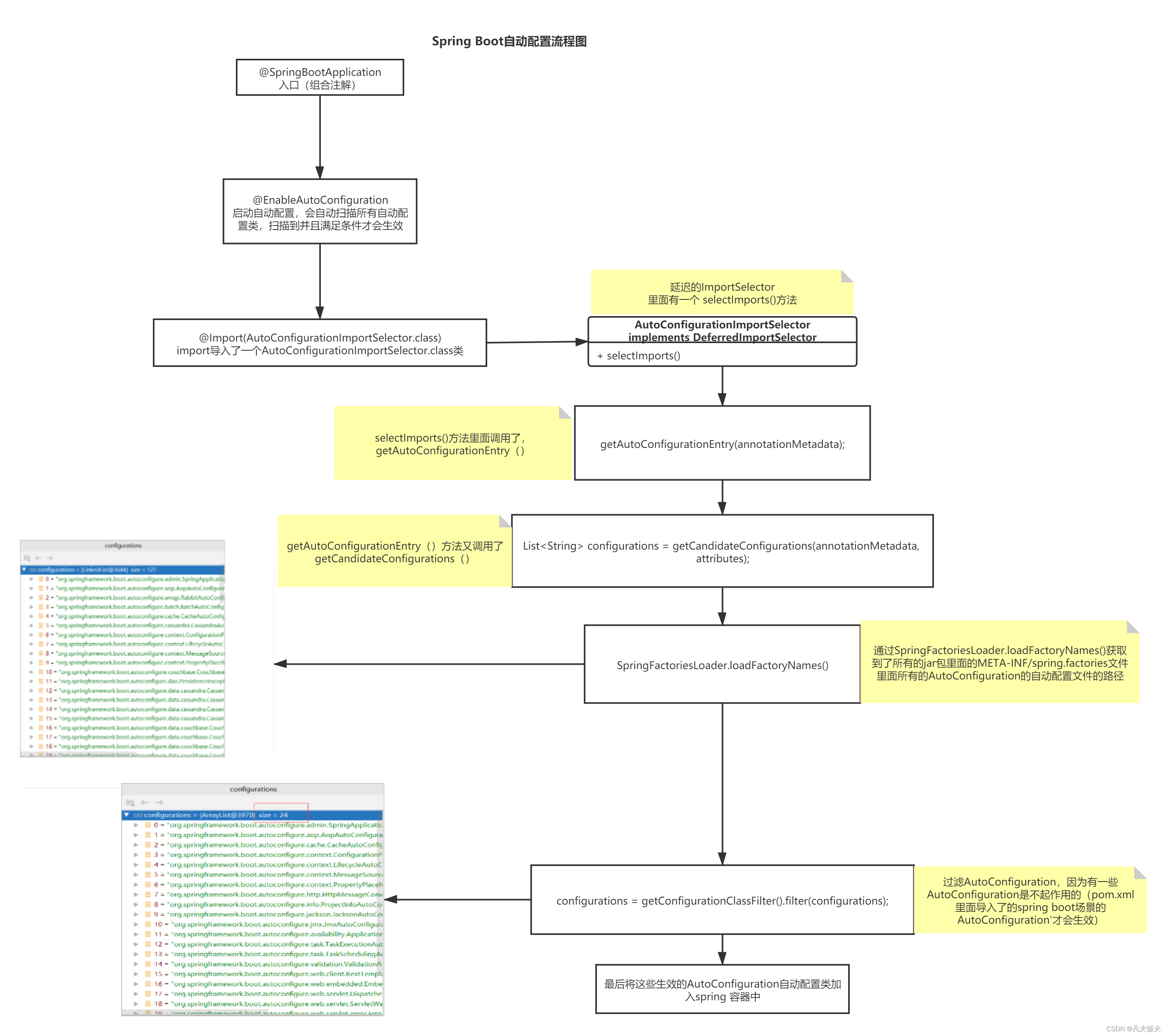
Springboot之把外部依赖包纳入Spring容器管理的两种方式
前言 在Spring boot项目中,凡是标记有Component、Controller、Service、Configuration、Bean等注解的类,Spring boot都会在容器启动的时候,自动创建bean并纳入到Spring容器中进行管理,这样就可以使用Autowired等注解,…...

更安全,更省心丨DolphinDB 数据库权限管理系统使用指南
在数据库产品使用过程中,为保证数据不被窃取、不遭破坏,我们需要通过用户权限来限制用户对数据库、数据表、视图等功能的操作范围,以保证数据库安全性。为此,DolphinDB 提供了具备以下主要功能的权限管理系统: 提供用户…...
WPS本地镜像化在线文档操作以及样例
一个客户项目有引进在线文档操作需求,让我这边做一个demo调研下,给我的对接文档里有相关方法的说明,照着对接即可。但在真正对接过程中还是踩过不少坑,这儿对之前的对接工作做个记录。 按照习惯先来一个效果: Demo下载…...
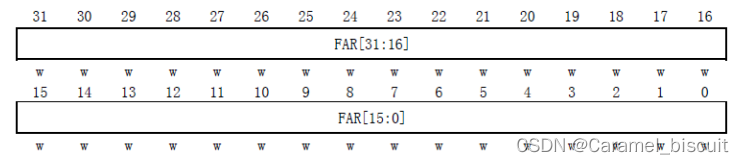
STM32 Flash学习(一)
STM32 FLASH简介 不同型号的STM32,其Flash容量也不同。 MiniSTM32开发板选择的STM32F103RCT6的FLASH容量为256K字节,属于大容量产品。 STM32的闪存模块由:主存储器、信息块和闪存存储器接口寄存器等3部分组成。 主存储器,该部分…...
Spring中IOC容器常用的接口和具体的实现类
在Spring框架没有出现之前,在Java语言中,程序员们创建对象一般都是通过关键字new来完成,那时流行一句话“万物即可new,包括女朋友”。但是这种创建对象的方式维护成本很高,而且对于类之间的相互关联关系很不友好。鉴于…...

【MySQL】索引特性
🌠 作者:阿亮joy. 🎆专栏:《零基础入门MySQL》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉没…...

【深度学习笔记】动量梯度下降法
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下: 神经网络和…...
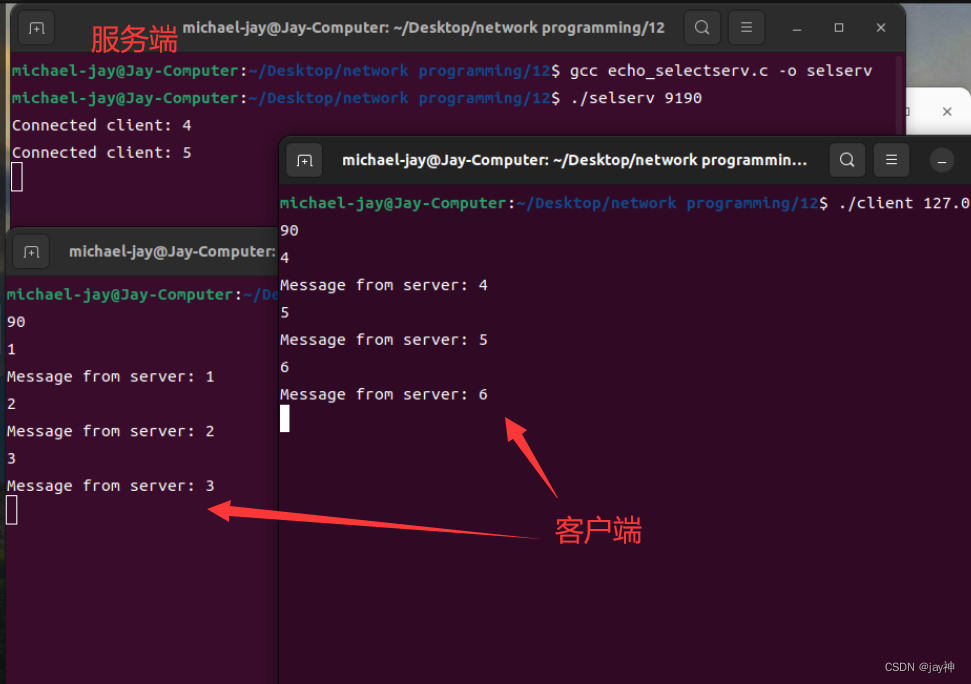
《TCP IP网络编程》第十二章
第 12 章 I/O 复用 12.1 基于 I/O 复用的服务器端 多进程服务端的缺点和解决方法: 为了构建并发服务器,只要有客户端连接请求就会创建新进程。这的确是实际操作中采用的一种方案,但并非十全十美,因为创建进程要付出很大的代价。…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...