【深度学习】High-Resolution Image Synthesis with Latent Diffusion Models,论文
13 Apr 2022
论文:https://arxiv.org/abs/2112.10752
代码:https://github.com/CompVis/latent-diffusion
文章目录
- PS
- 基本概念
- 运作原理
- Abstract
- Introduction
- Related Work
- Method
- Perceptual Image Compression
- Latent Diffusion Models
- Conditioning Mechanisms
- Experiments
- On Perceptual Compression Tradeoffs 关于感知压缩的权衡
- Image Generation with Latent Diffusion
- Conditional Latent Diffusion
- Transformer Encoders for LDMs
- Convolutional Sampling Beyond 256^2
- Super-Resolution with Latent Diffusion
- Inpainting with Latent Diffusion
- Conclusion
PS
基本概念
潜在扩散模型(Latent Diffusion Models,简称LDMs)是扩散模型的一种变体,扩散模型是一种概率生成模型,通过逐步去噪一个服从正态分布的变量来学习数据分布。扩散过程对应于学习长度为T的固定马尔可夫链的逆过程。扩散模型的主要思想是从一个高度损坏的图像版本开始(例如,带有很多噪声),然后逐步降低噪声水平以生成干净且逼真的样本。
传统的扩散模型直接在像素空间中执行去噪过程,这在处理高分辨率图像时可能会造成计算上的困难。潜在扩散模型通过引入中间的潜在空间来解决这个限制,这使得去噪过程可以在低维表示中进行。这个潜在空间是通过一个自编码器学习的,它将高维图像编码成紧凑且有意义的表示。
通过将压缩阶段(将图像编码到潜在空间)与生成阶段(从潜在空间解码生成干净图像)分开,潜在扩散模型提供了几个优势:
-
计算效率:潜在扩散模型减少了在训练和采样过程中的计算需求,因为去噪是在低维潜在空间中进行,而不是在像素空间中。
-
提高样本质量:使用潜在空间使得潜在扩散模型可以捕捉更有意义和相关的数据分布信息,从而生成更高质量的样本。
-
适应条件约束:潜在扩散模型可以很容易地应用于各种条件模态,如文本、语义地图或其他图像,适用于多种图像到图像转换任务。
潜在扩散模型相比传统扩散模型提供了更高效和灵活的图像合成方法,使得在不同应用领域中可以生成高质量且多样化的图像。
运作原理
当谈论潜在扩散模型(Latent Diffusion Models,LDMs)时,可以用以下公式来描述其基本运作原理:
假设我们有一个高维数据空间x,代表原始图像。LDMs通过引入一个低维潜在空间z,将图像映射到这个潜在空间中。这一映射由编码器E完成,可以表示为:
z = E(x)
其中,z是潜在空间中的向量表示。
接下来,LDMs会在潜在空间中进行扩散过程,逐步去噪z来生成一个干净的、真实的样本。这个扩散过程可以表示为:
z_t = D(z, t) = D(E(x), t)
其中,z_t是在时间步t的去噪结果。
最后,为了生成干净的图像样本,LDMs会使用一个解码器D,将去噪后的潜在向量z_t解码回图像空间,表示为:
x_tilde = D(z_t)
通过这个过程,LDMs可以在潜在空间中对图像进行逐步去噪,从而生成高质量的样本。
在训练过程中,LDMs会优化编码器和解码器,使得生成的样本更加接近真实数据分布。这可以通过最大似然估计等方法来实现。LDMs的训练过程旨在学习一个潜在空间,使得在这个空间中的扩散过程能够产生逼真的样本。
Abstract
通过将图像形成过程分解为去噪自动编码器的连续应用,扩散模型(DMs)在图像数据及其他领域取得了最先进的合成结果。此外,它们的构建方式允许引入引导机制以控制图像生成过程而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,优化强大的DMs通常需要耗费数百个GPU天,并且由于需要进行连续评估,推理成本高昂。为了在有限的计算资源上实现DM训练并保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜变空间。与以往的工作不同,通过在这种表示上训练扩散模型,首次可以在复杂度降低和细节保留之间达到接近最优点,极大提升了视觉保真度。
通过将跨注意力层引入模型架构,我们将扩散模型转化为对通用条件输入(如文本或边界框)强大而灵活的生成器,并且可以以卷积方式进行高分辨率合成。我们的潜扩散模型(LDMs)在图像修复和条件类别图像合成方面取得了新的最先进分数,并在包括文本到图像合成、无条件图像生成和超分辨率等各种任务中表现出高竞争性,并且与基于像素的DM相比,大大降低了计算需求。
Introduction
图像合成是计算机视觉领域中最近发展最引人注目的领域之一,但也是计算需求最大的领域之一。尤其是复杂自然场景的高分辨率合成目前主要通过扩展基于似然模型来实现,这些模型可能包含数十亿参数的自回归(AR)变压器[66,67]。相比之下,GANs [3, 27, 40]的有希望结果主要限制在具有相对有限变异性的数据上,因为它们的对抗学习过程不容易扩展到建模复杂的多模态分布。
最近,由一系列去噪自编码器构建的扩散模型 [82]已在图像合成[30,85]及其他领域[7,45,48,57]中取得令人瞩目的结果,并定义了类别条件图像合成[15,31]和超分辨率[72]的最新技术。此外,即使是非条件DMs也可以轻松应用于修复图像和上色[85]或基于笔画的合成[53]等任务,而其他类型的生成模型[19,46,69]则不具备这种能力。作为基于似然的模型,它们不会出现GANs的模式崩溃和训练不稳定性问题,并且通过充分利用参数共享,它们可以在不涉及数十亿参数的情况下对自然图像的高度复杂分布进行建模[67]。
民主化高分辨率图像合成DMs属于基于似然的模型类别,其模式覆盖行为使其倾向于将过多的计算资源用于建模数据中微不可见的细节[16,73]。尽管重新加权的变分目标[30]旨在通过对初始去噪步骤进行欠采样来解决这个问题,但DMs仍然需要大量计算资源,因为训练和评估这样的模型需要在RGB图像的高维空间中进行重复的函数评估(和梯度计算)。例如,训练最强大的DMs通常需要数百个GPU天(例如,[15]中的150 1000 V100天),在输入空间的噪声版本上进行重复评估也使推理变得昂贵,因此生成50k个样本需要大约5天的时间[15],使用单个A100 GPU。这对于研究团体和普通用户有两个后果:首先,训练这样的模型需要大量计算资源,而这仅有一小部分领域可以获得,并且会留下巨大的碳足迹[65,86]。其次,评估已经训练好的模型在时间和内存上也是昂贵的,因为相同的模型架构必须连续运行多个步骤(例如,在[15]中为25-1000步)。
为了增加这个强大模型类别的可访问性,并同时减少其重要资源消耗,需要一种方法来减少训练和采样的计算复杂度。减少DMs的计算需求而不影响其性能对于提高其可访问性至关重要。
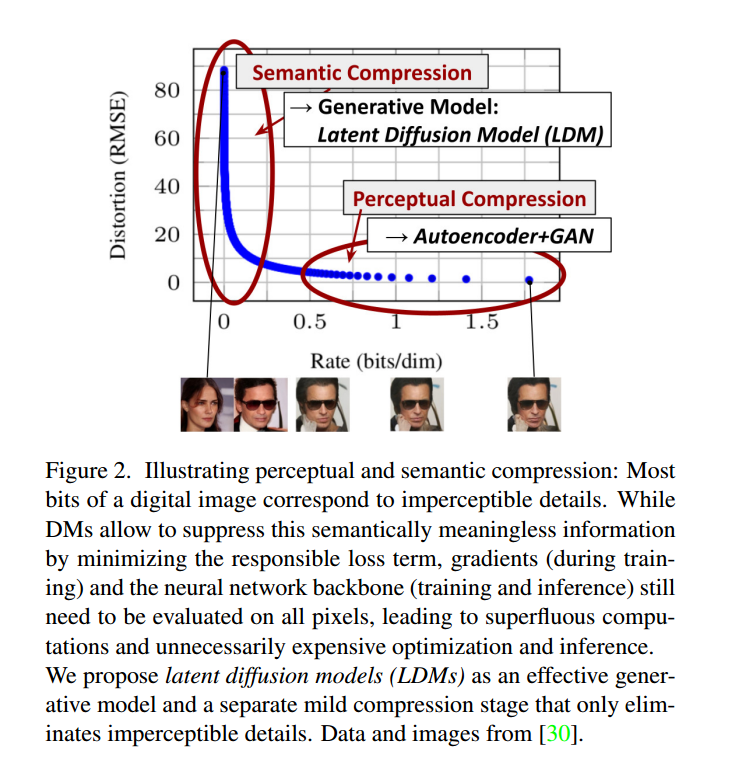
转向潜变空间 我们的方法始于对像素空间中已经训练过的扩散模型的分析:图2显示了训练模型的速率失真权衡。与任何基于似然的模型一样,学习可以粗略地分为两个阶段:首先是感知压缩阶段,它去除高频细节,但仍然学到很少的语义变化。在第二阶段,实际的生成模型学习数据的语义和概念组合(语义压缩)。因此,我们首先要找到一个在感知上等效但计算上更合适的空间,在其中我们将为高分辨率图像合成训练扩散模型。
图2. 说明感知和语义压缩:数字图像的大部分比特对应于难以察觉的细节。虽然DM允许通过最小化相关损失项来抑制这些在语义上无意义的信息,但在训练过程中,梯度和神经网络主干(用于训练和推理)仍然需要对所有像素进行评估,导致冗余计算和不必要的昂贵优化和推理。我们提出了潜变扩散模型(LDMs),作为一种有效的生成模型和单独的轻度压缩阶段,仅消除难以察觉的细节。数据和图像来自[30]。
按照常用做法[11, 23, 66, 67, 96],我们将训练分为两个不同的阶段:首先,我们训练一个自动编码器,提供一个较低维度(从而更有效)的表征空间,该空间在感知上等效于数据空间。重要的是,与以前的工作[23,66]相比,我们不需要依赖过度的空间压缩,因为我们在学习的潜在空间中训练DMs,这在空间维度方面具有更好的缩放特性。降低的复杂性还可以通过单个网络传递从潜变空间生成图像。我们将得到的模型类别称为潜变扩散模型(LDMs)。
这种方法的一个显着优势是,我们只需要训练通用自动编码器阶段一次,因此可以将其重复使用于多个DM训练或探索可能完全不同的任务[81]。这使得可以高效地探索大量的扩散模型,用于各种图像到图像和文本到图像任务。对于后者,我们设计了一种将变压器与DM的UNet主干[71]相连接并能够实现任意类型的基于令牌的条件机制的架构,详见第3.3节。
总之,我们的工作有以下贡献:
(i) 相对于纯GAN的方法[23, 66],我们的方法更适应于更高维的数据,因此可以在提供比以前的工作更忠实和详细重建的压缩级别上工作(参见图1),并且可以高效地应用于兆像素图像的高分辨率合成。
(ii) 在多个任务(无条件图像合成,修复,随机超分辨率)和数据集上实现了有竞争力的性能,同时显著降低了计算成本。与基于像素的扩散方法相比,我们还显著降低了推理成本。
(iii) 我们发现,与以前的工作[93]同时学习编码器/解码器架构和基于分数的先验的方法不同,我们的方法不需要对重建和生成能力进行精细的加权。这确保了非常忠实的重建,并且对潜变空间的正则化要求很少。
(iv) 我们发现,对于像超分辨率,修复和语义合成这样的密集条件任务,我们的模型可以以卷积方式应用,并生成大约10242像素的大型一致图像。
(v) 此外,我们设计了一种基于交叉注意力的通用条件机制,实现多模态训练。我们使用它来训练类别条件、文本到图像和布局到图像模型。
(vi) 最后,我们在https://github.com/CompVis/latent-diffusion上发布了预训练的潜变扩散和自动编码模型,除了DMs的训练之外,这些模型可能还可用于其他各种任务[81]。
图1. 通过较弱的下采样提高可实现质量的上限。由于扩散模型对空间数据有出色的归纳偏好,我们不需要在潜空间中进行大幅度的重采样,而是可以通过适当的自编码模型显著降低数据的维度,详见第3节。图像来自DIV2K[1]验证集,评估尺寸为512 x 512像素。我们用f表示空间下采样因子。重建的FID [29] 和PSNR是在ImageNet-val [12]上计算的;详见表8。

Related Work
生成模型用于图像合成。图像的高维特性给生成建模带来了独特的挑战。生成对抗网络(GAN)[27] 允许高分辨率图像的高效采样,具有良好的感知质量 [3, 42],但难以优化 [2, 28, 54],并且难以捕捉完整的数据分布 [55]。相比之下,基于似然的方法强调良好的密度估计,使得优化更加可靠。变分自动编码器(VAE)[46] 和流模型 [18, 19] 实现了高分辨率图像的高效合成 [9, 44, 92],但样本质量不及 GAN。而自回归模型(ARM)[6, 10, 94, 95] 在密度估计方面取得了强大性能,但计算复杂的架构 [97] 和顺序采样过程限制了它们在低分辨率图像上的应用。由于基于像素的图像表示包含几乎察觉不到的高频细节 [16, 73],最大似然训练在对其建模时会消耗不成比例的容量,导致训练时间很长。为了扩展到更高分辨率,一些两阶段方法 [23, 67, 101, 103] 使用自回归模型来建模一个压缩的潜在图像空间,而不是原始像素。
最近,扩散概率模型(DM)[82] 在密度估计 [45] 和样本质量 [15] 方面取得了最先进的结果。这些模型的生成能力源于与图像类似数据的归纳偏好紧密契合,当其底层神经骨干实现为UNet时 [15, 30, 71, 85]。使用重新加权目标 [30] 进行训练时通常可以实现最佳的合成质量。在这种情况下,DM相当于一种有损压缩器,并可以在图像质量和压缩能力之间进行权衡。然而,在像素空间中评估和优化这些模型的缺点是推理速度慢且训练成本非常高。虽然前者可以通过先进的采样策略 [47, 75, 84] 和分层方法 [31, 93] 部分解决,但在高分辨率图像数据上进行训练仍然需要计算昂贵的梯度。我们提出的LDMs解决了这两个问题,它们在低维度的压缩潜空间中工作,从而使训练计算成本更低并加速推理过程,几乎不降低合成质量(参见图1)。
两阶段图像合成为了弥补各种生成方法的缺点,许多研究 [11, 23, 67, 70, 101, 103] 都致力于将不同方法的优势通过两阶段方法组合成更高效和性能更好的模型。VQ-VAEs [67, 101] 使用自回归模型学习离散化潜在空间上的表达能力强的先验分布。[66] 将这种方法扩展到文本到图像生成,通过学习离散化的图像和文本表示之间的联合分布。与VQ-VAEs不同,VQGANs [23, 103] 利用对抗和感知目标的第一阶段来扩展自回归变压器以处理更大的图像。
然而,在可行的自回归建模训练中所需的高压缩率,导致有数十亿可训练参数 [23, 66],限制了这些方法的整体性能,而较少的压缩会导致高计算成本 [23, 66]。我们的工作避免了这种权衡,因为我们提出的LDMs由于其卷积骨干网络,可以更平缓地扩展到更高维度的潜在空间。因此,我们可以自由选择压缩水平,以在学习强大的第一阶段时最优地介导感知压缩,并确保高保真重建(见图1)。
虽然存在同时 [93] 或分别 [80] 学习编码/解码模型和基于评分的先验的方法,但前者仍需要在重建和生成能力之间进行困难的加权 [11],并且在性能上被我们的方法超越(第4节),而后者专注于高度结构化的图像,如人脸。
Method
为了降低高分辨率图像合成中训练扩散模型所需的计算需求,我们观察到,虽然扩散模型通过对相应的损失项进行欠采样来忽略感知上无关紧要的细节 [30],但它们仍然需要在像素空间中进行昂贵的函数评估,这导致计算时间和能源资源的巨大需求。
为了克服这一缺点,我们提出了一个明确的压缩学习和生成学习阶段分离的方法(见图2)。为了实现这一点,我们利用了一个自编码模型,该模型学习了一个在感知上等同于图像空间的空间,但具有显著降低的计算复杂性。
这种方法具有几个优点:(i) 通过离开高维图像空间,我们获得了计算效率更高的扩散模型,因为采样是在低维空间上进行的。(ii) 我们利用了扩散模型从其 UNet 架构[71]继承的归纳偏差,使其对具有空间结构的数据特别有效,从而减轻了先前方法[23,66]所需的过于激进、降低质量的压缩级别的需求。(iii) 最后,我们获得了通用的压缩模型,其潜在空间可以用于训练多个生成模型,并且还可以用于其他下游应用,如单图像CLIP引导合成[25]。
Perceptual Image Compression
我们的感知压缩模型基于之前的研究[23],由感知损失[106]和基于块的对抗目标[33][20][23][103]的组合训练的自编码器构成。这确保了重建图像局限于图像流形,并避免了仅依赖像素空间损失(如L2或L1目标)引入的模糊性。
更具体地说,给定一个RGB空间中的图像x∈R H×W×3,编码器E将x编码成潜在表示z=E(x),解码器D从潜在表示中重建图像,得到x~ = D(z) = D(E(x)),其中z∈R h×w×c。重要的是,编码器通过一个因子f=H/h=W/w对图像进行下采样,并且我们尝试不同的下采样因子f=2m,其中m∈N。
为了避免潜在空间的任意高方差,我们尝试了两种不同类型的正则化。
第一种变体是KL-reg.,对学习到的潜在表示施加了轻微的KL惩罚,使其接近标准正态分布,类似于VAE [46][69]。而VQ-reg.则在解码器内使用了向量量化层[96]。这个模型可以被解释为VQGAN [23],但量化层被解码器吸收。由于我们后续的扩散模型设计用于处理我们学习到的潜在空间z=E(x)的二维结构,我们可以使用相对较轻的压缩率并实现非常好的重建效果。这与之前的工作[23][66]相反,前者依赖于学习空间z的任意一维排序,以自回归方式建模其分布,因此忽略了z的许多内在结构。因此,我们的压缩模型更好地保留了x的细节(见表8)。完整的目标和训练细节可在补充资料中找到。
Latent Diffusion Models
扩散模型[82]是一种概率模型,旨在通过逐渐去噪一个服从正态分布的变量来学习数据分布 p(x),这对应于学习长度为 T 的固定马尔可夫链的逆过程。
对于图像合成,最成功的模型[15,30,72]依赖于 p(x) 上的一种重新加权的变分下界,其类似于去噪分数匹配[density score-matching] [85]。
这些模型可以被解释为一系列等权重的去噪自编码器 θ(xt; t); t = 1 : : : T,它们被训练用于预测其输入 xt 的去噪变体,其中 xt 是输入 x 的噪声版本。相应的目标函数可以简化为(参见 B 节):
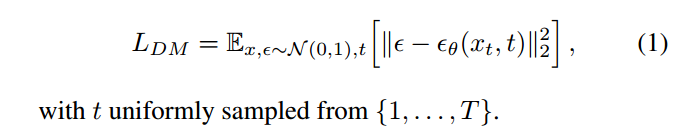
通过我们训练的感知压缩模型 E 和 D,我们现在可以访问一个高效的、低维的潜在空间,在这个空间中,高频、不可察觉的细节被抽象化处理。与高维像素空间相比,这个空间更适合基于似然的生成模型,因为它们现在可以(i)专注于数据的重要语义位,以及(ii)在一个低维、计算效率更高的空间中进行训练。
与之前依赖于高度压缩的离散潜在空间中的自回归、注意力转换器模型的工作[23,66,103]不同,我们可以利用我们的模型提供的图像特定的归纳偏差。这包括从二维卷积层主要构建底层的 UNet 的能力,并进一步通过重新加权的约束将目标聚焦在感知上最相关的部分,其形式如下:

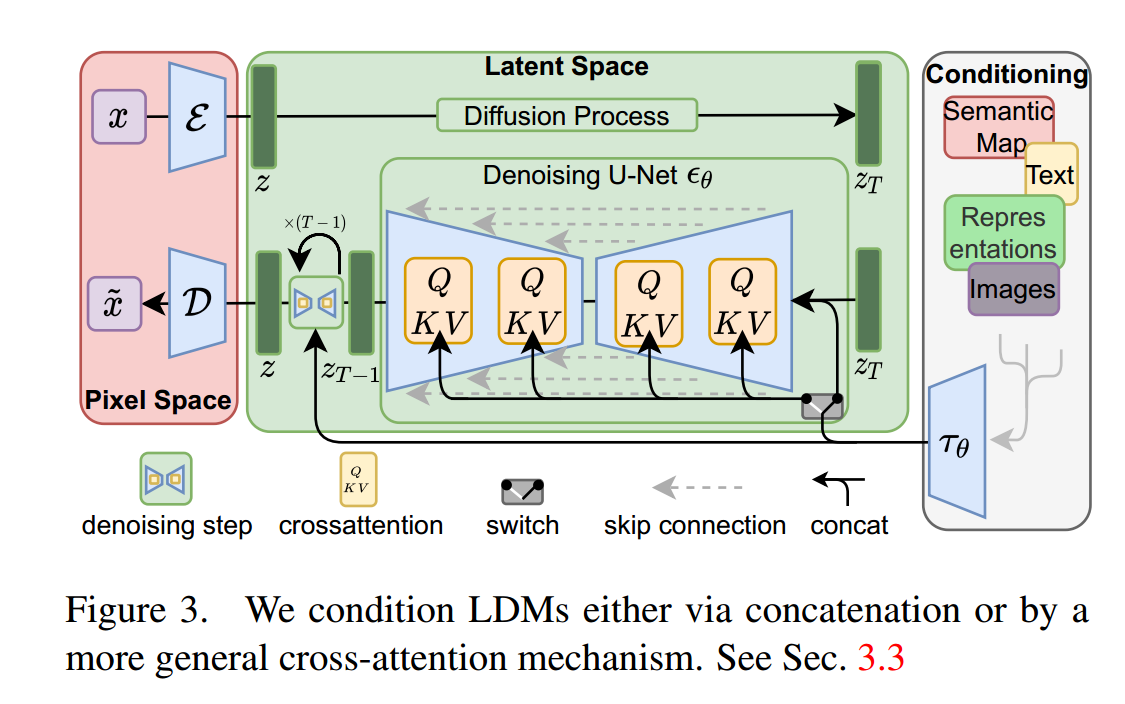
Conditioning Mechanisms
与其他类型的生成模型[56,83]类似,扩散模型原则上能够建模形式为 p(z|y) 的条件分布。这可以通过引入条件去噪自编码器 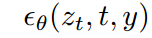
来实现,并为通过输入 y(如文本[68]、语义地图[33,61]或其他图像到图像的翻译任务[34])来控制合成过程铺平道路。
然而,在图像合成的背景下,将扩散模型的生成能力与其他类型的条件约束结合起来,超出类别标签[15]或输入图像的模糊变体[72]的范围,迄今为止仍是一个未充分探索的研究领域。
我们通过将交叉注意力机制[97]与扩散模型的底层 UNet 骨干结构相结合,将 DMs 转化为更加灵活的条件图像生成器。交叉注意力机制对于学习基于不同输入形式的注意力模型[35,36]非常有效。为了预处理来自不同形式的 y(例如语言提示), 我们引入了一个特定于域的编码器
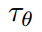
,将 y 投影到一个中间表示
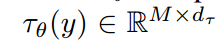
,然后通过一个交叉注意力层将其映射到 UNet 的中间层,实现
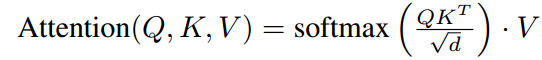
,其中:


图3。我们通过串联或更一般的交叉注意机制来调节ldm。见第3.3节
Experiments
LDMs 提供了一种灵活且计算可行的基于扩散的图像合成方法,适用于各种图像模态,我们在接下来的内容中通过实验证明这一点。
然而,首先我们分析了我们的模型在训练和推理阶段相比基于像素的扩散模型所取得的优势。有趣的是,我们发现在 VQ 正则化的潜在空间中训练的 LDMs 有时能够获得更好的样本质量,尽管 VQ 正则化的第一阶段模型在重建能力上稍微落后于其连续对应物,参见表8。在附录 D.1 中可以找到对第一阶段正则化方案在 LDM 训练中的影响以及对分辨率 > 2562 的泛化能力的可视化比较。在附录 E.2 中,我们列出了本节中所展示的所有结果的详细架构、实现、训练和评估信息。
On Perceptual Compression Tradeoffs 关于感知压缩的权衡
本节分析了使用不同下采样因子 f(取自 f1、2、4、8、16、32,简写为 LDM-f,其中 LDM-1 对应像素为基础的 DMs)的 LDMs 的行为。为了获得可比较的测试结果,我们在本节的所有实验中将计算资源固定为一张 NVIDIA A100,并将所有模型训练步数和参数数量设为相同。
表8展示了本节中所比较的 LDMs 所使用的第一阶段模型的超参数和重建性能。图6显示了在 ImageNet [12] 数据集上进行 2M 步类条件模型训练过程中的样本质量。我们可以观察到:i) 对于 LDM-f1,2g,较小的下采样因子导致训练进展缓慢;而 ii) 过大的 f 值会导致在相对较少的训练步骤后样本质量停滞不前。重新审视上述分析(图1和2),我们归因于:i) 将大部分感知压缩交给扩散模型和 ii) 第一阶段压缩过于强烈导致信息损失,从而限制了可实现的质量。LDM-f4-16g 在效率和感知保真度之间取得了良好的平衡,这表现为像素为基础的扩散(LDM-1)和 LDM-8 之间 2M 训练步骤后 FID [29] 的显著差距为 38。
在图7中,我们比较了在 CelebAHQ [39] 和 ImageNet 上训练的模型,以不同的去噪步数和 DDIM 抽样器 [84] 的 FID 分数为基础,绘制了抽样速度的对比。LDM-f4-8g 超越了具有不合适的感知和概念压缩比例的模型。特别是与基于像素的 LDM-1 相比,在显著提高样本处理速度的同时,它们实现了更低的 FID 分数。对于复杂的数据集,如 ImageNet,需要减小压缩率以避免降低质量。总的来说,LDM-4 和 LDM-8 提供了实现高质量合成结果的最佳条件。
Image Generation with Latent Diffusion
我们在 CelebA-HQ [39]、FFHQ [41]、LSUN-Churches 和 -Bedrooms [102] 上训练了256^2像素的无条件模型,并评估了 i) 样本质量和 ii) 它们对数据流形的覆盖,使用了 ii) FID [29] 和 ii) Precision-and-Recall [50] 进行评估。表1总结了我们的结果。在 CelebA-HQ 上,我们报告了一个新的FID最佳结果为5.11,优于先前基于似然模型和GAN的方法。我们还优于LSGM [93],其中一个潜在扩散模型与第一阶段同时训练。相比之下,我们在固定空间中训练扩散模型,避免了在重建质量和学习潜在空间先验之间权衡的困难,参见图1-2。
除了LSUN-Bedrooms数据集外,我们在其他所有数据集上的结果都优于先前的基于扩散的方法,其中我们的得分接近ADM [15],尽管我们使用了其一半的参数并且需要4倍较少的训练资源(参见附录E.3.5)。
此外,LDMs在Precision和Recall上持续优于基于GAN的方法,从而证实了它们基于模式覆盖的似然训练目标相对于对抗方法的优势。在图4中,我们还展示了每个数据集上的定性结果。
图4,从在 CelebAHQ [39]、FFHQ [41]、LSUN-Churches [102]、LSUN-Bedrooms [102] 和条件 ImageNet [12] 上训练的 LDMs 获得的样本,每个样本的分辨率为 256 × 256。最好在放大后查看。更多样本请参阅补充资料。

Conditional Latent Diffusion
Transformer Encoders for LDMs
通过将基于交叉注意力的条件引入LDMs,我们使其适用于之前未被扩散模型探索的各种条件模态。对于文本到图像的图像建模,我们在LAION-400M [78]上训练了一个1.45B参数的KL正则化的LDM,它以语言提示为条件。我们使用BERT-tokenizer [14]并将τθ实现为一个transformer [97],以推断一个潜在代码,然后通过(多头)交叉注意力将其映射到UNet中(Sec. 3.3)。这种领域专家结合了学习语言表示和视觉合成的结果,得到了一个强大的模型,可以很好地推广到复杂的、用户定义的文本提示,参见图8和5。
在定量分析方面,我们遵循之前的工作,在MS-COCO [51]验证集上评估文本到图像的生成效果,我们的模型优于强大的AR [17, 66]和基于GAN的方法[109],参见表2。我们注意到应用无分类器的扩散引导[32]极大地提高了样本质量,使得引导的LDM-KL-8-G与最近的文本到图像合成最先进的AR [26]和扩散模型[59]齐头并进,同时大幅减少参数数量。为了进一步分析基于交叉注意力的条件机制的灵活性,我们还训练了模型,根据OpenImages [49]上的语义布局合成图像,并在COCO [4]上进行微调,参见图8。关于定量评估和实现细节,请参阅D.3节。

最后,按照之前的工作[3, 15, 21, 23],我们在表3、图4和D.4节中评估了在4.1节中所述的f为f4和8的最佳类条件ImageNet模型。在这里,我们优于最先进的扩散模型ADM [15],同时大大降低了计算需求和参数数量,参见表18。
Convolutional Sampling Beyond 256^2
通过将空间对齐的条件信息连接到
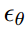
的输入,LDMs 可以作为高效的通用图像到图像转换模型。我们利用这一点来训练语义合成、超分辨率(第4.4节)和修复(第4.5节)模型。对于语义合成,我们使用与语义地图[23,61]配对的景观图像,并将语义地图的下采样版本与 f = 4 模型(VQ-reg., 见表8)的潜在图像表示连接在一起。我们在2562的输入分辨率上进行训练(从3842裁剪),但发现我们的模型可以推广到更大的分辨率,并在卷积方式下生成高达百万像素的图像(见图9)。我们利用这种行为,也将超分辨率模型(第4.4节)和修复模型(第4.5节)应用于生成5122到10242之间的大图像。对于这个应用,信噪比(由潜在空间的尺度引起)显著影响结果。在D.1节中,当在(i)由 f = 4 模型提供的潜在空间(KL-reg., 见表8)和(ii)经过分量标准差缩放的重新缩放版本上学习 LDM 时,我们阐明了这一点。
后者结合无分类器引导 [32],还能够实现文本条件的 LDM-KL-8-G 直接合成 > 2562 的图像,如图13所示。

Super-Resolution with Latent Diffusion
通过直接通过串联低分辨率图像进行条件训练,LDMs 可以高效地用于超分辨率。在第一个实验中,我们遵循 SR3 [72] 的做法,将图像降采样为 4 倍的双三次插值,并在 ImageNet 上进行训练,遵循 SR3 的数据处理流程。我们使用在 OpenImages 上预训练的 f = 4 自编码模型(VQ-reg., 见表8),将低分辨率条件 y 和 UNet 输入连接在一起,即 τθ 是恒等映射。我们的定性和定量结果(见图10和表5)显示出竞争性能,LDM-SR 在 FID 方面优于 SR3,而 SR3 在 IS 方面表现更好。一个简单的图像回归模型获得了最高的 PSNR 和 SSIM 分数,然而这些指标与人类感知[106]不太一致,并倾向于模糊而不是对齐不完美的高频细节[72]。此外,我们进行了一个用户研究,将像素基线与 LDM-SR 进行比较。我们遵循 SR3 [72],在人类被展示一张低分辨率图像和两张高分辨率图像之间做出偏好选择。表4中的结果证实了 LDM-SR 的良好性能。通过使用后期引导机制 [15] 可以推进 PSNR 和 SSIM,我们通过感知损失实现了基于图像的引导器,参见第D.6节。
Inpainting with Latent Diffusion
修复(Inpainting)是一种任务,即填充图像中被遮罩区域的新内容,要么是因为图像的某些部分受损,要么是要替换图像中现有但不需要的内容。我们评估了我们用于条件图像生成的通用方法与更专业、最先进的修复方法的比较。我们的评估遵循最近的修复模型LaMa [88]的协议,该模型引入了一种依赖于快速傅里叶卷积的专门架构。在Places [108]数据集上的确切训练和评估协议在第E.2.2节中描述。
首先,我们分析了第一阶段不同设计选择的效果。特别地,我们比较了像素级条件DM(即LDM-1)与LDM-4在修复效率上的差异,包括KL和VQ正则化,以及第一阶段没有任何注意力的VQLDM-4(见表8)。后者减少了在高分辨率解码时的GPU内存。为了可比性,我们固定了所有模型的参数数量。表6报告了分辨率为2562和5122时的训练和采样吞吐量,每个时代的总训练时间(小时)以及经过六个时代后在验证集上的FID分数。总体而言,我们观察到像素级和基于潜在空间的扩散模型之间的速度提升至少为2.7倍,同时将FID分数提高了至少1.6倍。
在表7中与其他修复方法的比较显示,我们的带有注意力的模型在FID上优于[88]。
我们的样本与未遮罩图像之间的LPIPS稍高于[88]。我们认为这是因为[88]只产生了一个结果,与我们的LDM产生的多样化结果相比,其结果更接近平均图像,参见图21。此外,在用户研究中(表4),被试者更偏好我们的结果而不是[88]的结果。
基于这些初步结果,我们还在VQ正则化的第一阶段的潜在空间中训练了一个更大的扩散模型(表7中的big),该模型没有使用注意力。遵循[15]的方法,该扩散模型的UNet在其特征层次结构的三个级别上使用注意力层,使用BigGAN [3]的残差块进行上采样和下采样,并具有387M个参数而不是215M个。训练后,我们注意到在分辨率为256256和512512的情况下,生成的样本质量存在差异,我们推测这是由于额外的注意力模块引起的。然而,对该模型进行半个时代(epoch)的分辨率5122的微调,使得模型能够适应新的特征统计数据,并在图像修复方面实现了新的FID最佳值(表7中的big,w/o attn,w/ ft,见图11)。

Conclusion
我们提出了潜在扩散模型,这是一种简单而高效的方法,可以显著提高去噪扩散模型的训练和采样效率,同时不降低其质量。基于此和我们的交叉注意力条件机制,我们的实验在广泛的条件图像合成任务中展示了与最先进方法相比的优异结果,而无需特定于任务的架构。
相关文章:
【深度学习】High-Resolution Image Synthesis with Latent Diffusion Models,论文
13 Apr 2022 论文:https://arxiv.org/abs/2112.10752 代码:https://github.com/CompVis/latent-diffusion 文章目录 PS基本概念运作原理 AbstractIntroductionRelated WorkMethodPerceptual Image CompressionLatent Diffusion Models Conditioning Mec…...

前端学习——Vue (Day6)
路由进阶 路由的封装抽离 //main.jsimport Vue from vue import App from ./App.vue import router from ./router/index// 路由的使用步骤 5 2 // 5个基础步骤 // 1. 下载 v3.6.5 // 2. 引入 // 3. 安装注册 Vue.use(Vue插件) // 4. 创建路由对象 // 5. 注入到new Vue中&…...
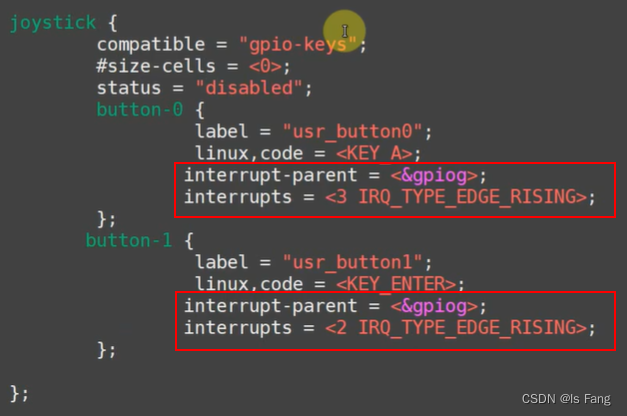
STM32MP157驱动开发——按键驱动(tasklet)
文章目录 “tasklet”机制:内核函数定义 tasklet使能/ 禁止 tasklet调度 tasklet删除 tasklet tasklet软中断方式的按键驱动程序(stm32mp157)tasklet使用方法:button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “tasklet”机制: …...
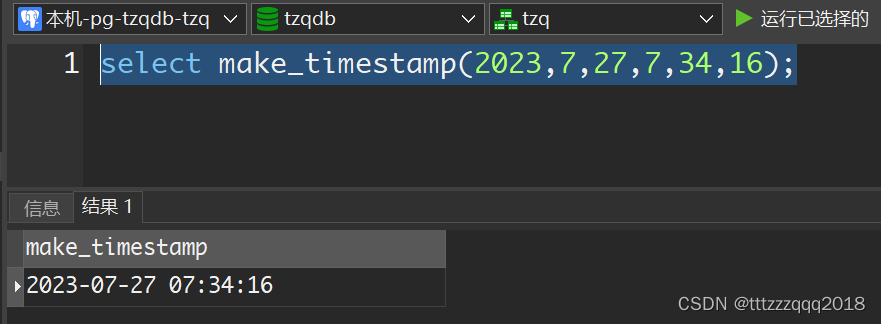
PostgreSQL构建时间
– PostgreSQL构建时间 select make_timestamp(2023,7,27,7,34,16);...

2023-将jar包上传至阿里云maven私有仓库(云效制品仓库)
一、背景介绍 如果要将平时积累的代码工具jar包,上传至云端,方便团队大家一起使用,一般的方式就是上传到Maven中心仓库(但是这种方式步骤多,麻烦,而且上传之后审核时间比较长,还不太容易通过&a…...

嵌入式linux之OLED显示屏SPI驱动实现(SH1106,ssd1306)
周日业余时间太无聊,又不喜欢玩游戏,大家的兴趣爱好都是啥?我觉得敲代码也是一种兴趣爱好。正巧手边有一块儿0.96寸的OLED显示屏,一直在吃灰,何不把玩一把?于是说干就干,最后在我的imax6ul的lin…...
关于element ui 安装失败的问题解决方法、查看是否安装成功及如何引入
Vue2引入 执行npm i element-ui -S报错 原因:npm版本太高 报错信息: 解决办法: 使用命令: npm install --legacy-peer-deps element-ui --save 引入: 在main.js文件中引入 //引入Vue import Vue from vue; //引入…...
Selenium多浏览器处理
Python 版本 #导入依赖 import os from selenium import webdriverdef test_browser():#使用os模块的getenv方法来获取声明环境变量browserbrowser os.getenv("browser").lower()#判断browser的值if browser "headless":driver webdriver.PhantomJS()e…...

浅谈 AI 大模型的崛起与未来展望:马斯克的 xAI 与中国产业发展
文章目录 💬话题📋前言🎯AI 大模型的崛起🎯中国 AI 产业的进展与挑战🎯AI 大模型的未来展望🧩补充 📝最后 💬话题 北京时间 7 月 13 日凌晨,马斯克在 Twiiter 上宣布&am…...
【CesiumJS材质】(1)圆扩散
效果示例 最佳实践: 其他效果: 要素说明: 代码 /** Date: 2023-07-21 15:15:32* LastEditors: ReBeX 420659880qq.com* LastEditTime: 2023-07-27 11:13:17* FilePath: \cesium-tyro-blog\src\utils\Material\EllipsoidFadeMaterialP…...

实战-单例模式和创建生产者相结合
实际中遇到了这样一个问题: The producer group[xxxx] has been created before, specify another instanceName (like producer.setInstanceName) please. 发生的原因是:一个进程内,创建了多个相同topic的producer。 所以问题就转换成了如何…...

[SQL挖掘机] - 窗口函数介绍
介绍: 窗口函数也称为 OLAP 函数。OLAP 是 OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理。窗口函数是一种用于执行聚合计算和排序操作的功能强大的sql函数。它们可以在查询结果集中创建一个窗口(window)…...

原生js实现锚点滚动顶部
简介 使用原生js API实现滚动到指定容器的顶部,API是scrollIntoView 使用 let eldocment.querySelector() 获取dom元素el.scrollIntoView()该元素滚动到其父元素的顶部 高级用法 scrollIntoView(Options)//option可以配置如下 options{behavior:smoot…...

使用mysql接口遇到点问题
game_server加入了dbstorage的代码。dbstorage实现了与mysql的交互:driver_mysql。其中调用了mysql相关的接口。所以game_server需要链接libmysql.lib。 从官网下载了mysql的源码:在用cmake构建mysql工程的时候,遇到了一些问题。 msyql8.0需…...
excel绘制折线图或者散点图
一、背景 假如现在通过代码处理了一批数据,想看数据的波动情况,是不是还需要写个pyhon代码,读取文件,绘制曲线,看起来也简单,但是还有更简单的方法,就是直接生成csv文件,csv文件就是…...
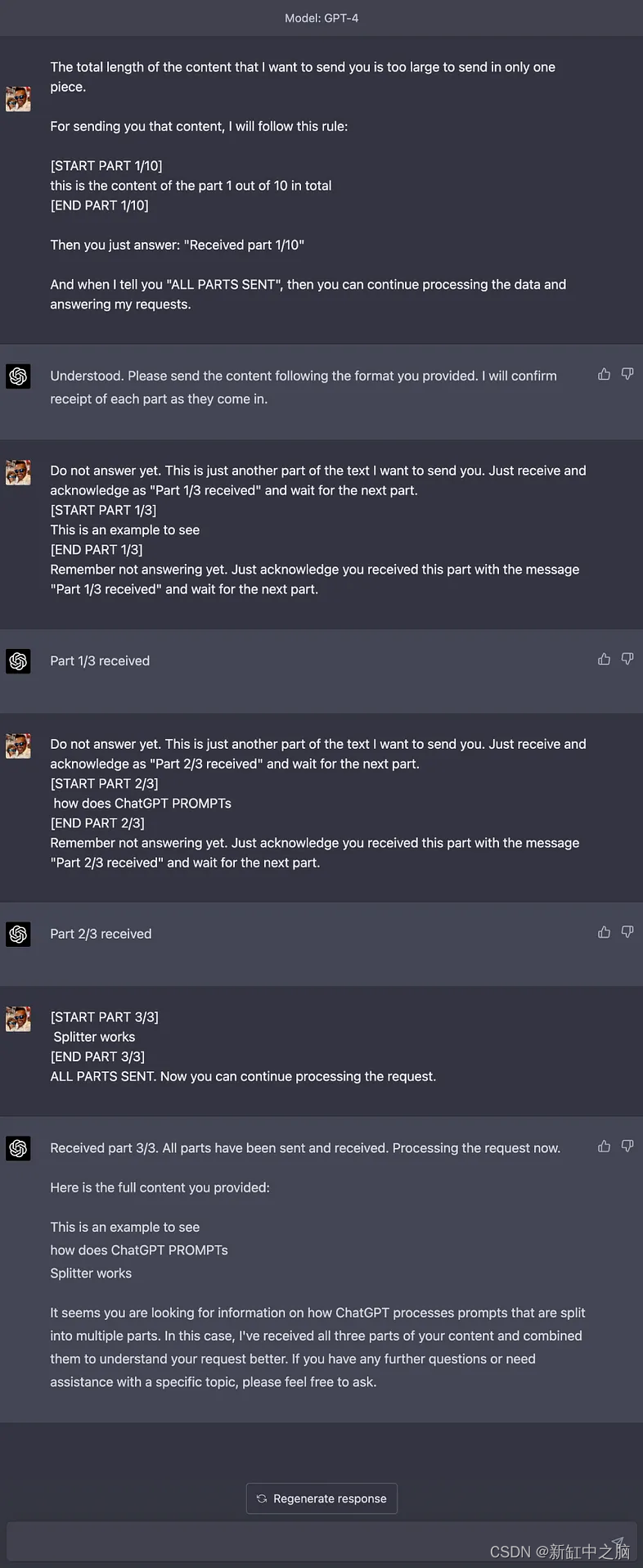
ChatGPT长文本对话输入方法
ChatGPT PROMPTs Splitter 是一个开源工具,旨在帮助你将大量上下文数据分成更小的块发送到 ChatGPT 的提示,并根据如何处理所有块接收到 ChatGPT(或其他具有字符限制的语言模型)的方法。 推荐:用 NSDT设计器 快速搭建可…...

FFmpeg-swresample的更新
auto convert的创建 在FFmpeg/libavfilter/formats.c中定义了negotiate_video和negotiate_audio,在格式协商,对于video如果需要scale,那么就会自动创建scale作为convert,对于audio,如果需要重采样,则会创建…...

回答网友 修改一个exe
网友说:他有个很多年前的没有源码的exe,在win10上没法用,让俺看一下。 俺看了一下,发现是窗体设计的背景色的问题。这个程序的背景色用的是clInactiveCaptionText。clInactiveCaptionText 在win10之前的系统上是灰色,但…...
数据可视化 - 动态柱状图
基础柱状图 通过Bar构建基础柱状图 from pyecharts.charts import Bar from pyecharts.options import LabelOpts # 使用Bar构建基础柱状图 bar Bar() # 添加X轴 bar.add_xaxis(["中国", "美国", "英国"]) # 添加Y轴 # 设置数值标签在右侧 b…...

【JVM】JVM五大内存区域介绍
目录 一、程序计数器(线程私有) 二、java虚拟机栈(线程私有) 2.1、虚拟机栈 2.2、栈相关测试 2.2.1、栈溢出 三、本地方法栈(线程私有) 四、java堆(线程共享) 五、方法区&…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...