【Kafka】消息队列Kafka基础
目录
- 消息队列简介
- 消息队列的应用场景
- 异步处理
- 系统解耦
- 流量削峰
- 日志处理
- 消息队列的两种模式
- 点对点模式
- 发布订阅模式
- Kafka简介及应用场景
- Kafka比较其他MQ的优势
- Kafka目录结构
- 搭建Kafka集群
- 编写Kafka一键启动/关闭脚本
- Kafka基础操作
- 创建topic
- 生产消息到Kafka
- 从Kafka消费消息
- 使用 Kafka Tools 操作Kafka
- 带Security连接Kafka Tool
- Java编程操作Kafka
- 同步生产消息到Kafka中:
- 使用同步等待的方式发送消息
- 异步使用带有回调函数方法生产消息
- 从Kafka的topic中消费消息
- Kafka 重要概念
- broker
- Zookeeper
- producer(生产者)
- consumer(消费者)
- consumer group(消费者组)
- 主题(Topic)
- 分区(Partitions)
- 副本(Replicas)
- 偏移量(offset)
- 消费者组
- Kafka生产者幂等性
- 幂等性原理
- Kafka 事务
- 事务操作API:
- Kafka事务编程
- 事务相关属性配置
- Kafka事务编程案例
消息队列简介
消息队列,经常缩写为MQ。从字面上来理解,消息队列是一种用来存储消息的队列。例如Java中的队列:
// 1. 创建一个保存字符串的队列
Queue<String> stringQueue = new LinkedList<String>();
// 2. 往消息队列中放入消息
stringQueue.offer("message");
// 3. 从消息队列中取出消息并打印
System.out.println(stringQueue.poll());
上述代码,创建了一个队列,先往队列中添加了一个消息,然后又从队列中取出了一个消息。这说明了队列是可以用来存取消息的。我们可以简单理解消息队列就是将需要传输的数据存放在队列中。
消息队列中间件就是用来存储消息的软件(组件)。消息队列有很多,例如:Kafka、RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ 等。
消息队列的应用场景
异步处理
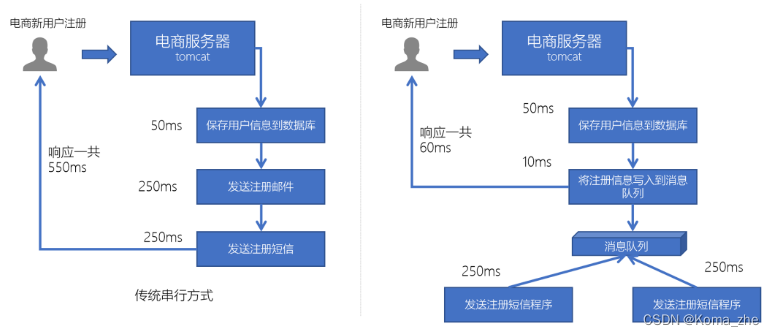
例如在电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。
但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,此时,就可以使用消息队列来进行异步处理,从而实现快速响应。
系统解耦

流量削峰
日志处理
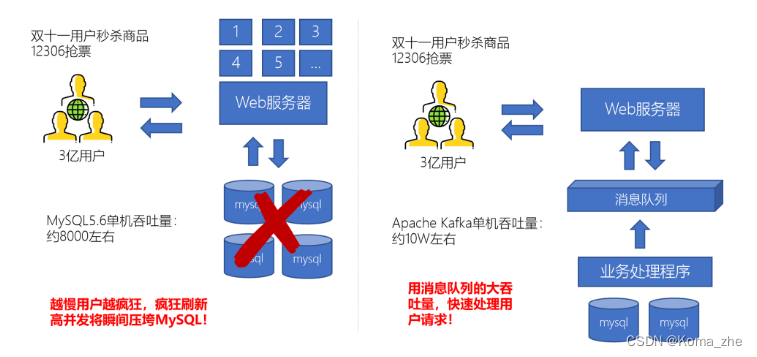
大型电商网站(淘宝、京东、国美、苏宁…)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息。
消息队列的两种模式
点对点模式
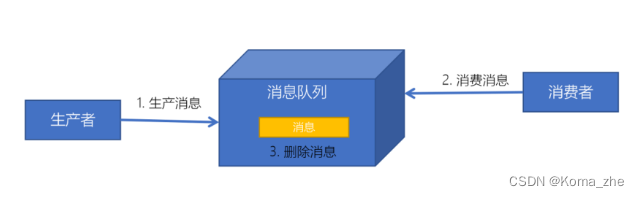
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
发布订阅模式
特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
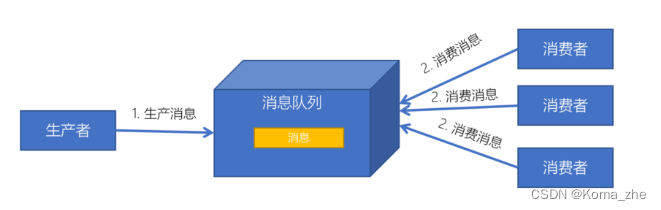
Kafka简介及应用场景
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
- 处理数据流
通常将Apache Kafka用在两类程序:
-
建立实时数据管道,以可靠地在系统或应用程序之间获取数据
-
构建实时流应用程序,以转换或响应数据流
Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中。
Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到数据库中。
Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
Kafka比较其他MQ的优势
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
Kafka目录结构
使用的Kafka版本为2.4.1。
| 目录名称 | 说明 |
|---|---|
| bin | Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等 |
| config | Kafka的所有配置文件 |
| libs | 运行Kafka所需要的所有JAR包 |
| logs | Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息 |
| site-docs | Kafka的网站帮助文件 |
搭建Kafka集群
使用的Kafka版本为2.4.1,是2020年3月12日发布的版本。
注:Kafka 的版本号为:kafka_2.12-2.4.1,因为Kafka 主要是使用scala语言开发的,2.12为scala 的版本号。
创建并解压:
sudo mkdir export
cd /export
sudo mkdir server
sudo mkdir software
sudo chmod 777 software/
sudo chmod 777 server/
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
修改 server.properties:
# 创建Kafka数据的位置
mkdir /export/server/kafka_2.12-2.4.1/data
vim /export/server/kafka_2.12-2.4.1/config/server.properties
# 指定broker的id
broker.id=0
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=10.211.55.8:2181,10.211.55.9:2181,10.211.55.7:2181
其余两台服务器重复以上步骤,仅修改 broker.id 为不同。
配置KAFKA_HOME环境变量:
sudo su
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
#源文件无下面这条需手动添加
export PATH每个节点加载环境变量
source /etc/profile
启动服务器:
# 启动ZooKeeper
# 启动Kafka,需要在kafka根目录下启动
cd /export/server/kafka_2.12-2.4.1nohup bin/kafka-server-start.sh config/server.properties &
# 测试Kafka集群是否启动成功
bin/kafka-topics.sh --bootstrap-server 10.211.55.8:9092 --list
# 无报错,打印为空
编写Kafka一键启动/关闭脚本
为了方便将来进行一键启动、关闭Kafka,可以编写一个shell脚本来操作,只要执行一次该脚本就可以快速启动或关闭Kafka。
准备 slave 配置文件,用于保存要启动哪几个节点上的kafka:
# 创建 /export/onekey 目录
sudo mkdir onekeycd /export/onekey
sudo su
#新建slave文件
touch slave#slave中写入以下内容
10.211.55.8
10.211.55.9
10.211.55.7
编写start-kafka.sh脚本:
vim start-kafka.shcat /export/onekey/slave | while read line
do
{echo $linessh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "wait
}&
done
编写stop-kafka.sh脚本:
vim stop-kafka.shcat /export/onekey/slave | while read line
do
{echo $linessh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"wait
}&
done
给start-kafka.sh、stop-kafka.sh配置执行权限:
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh# 执行一键启动、一键关闭,注:执行shell脚本需实现服务器间ssh免密登录
./start-kafka.sh
./stop-kafka.sh# 当查看日志发生Error connecting to node ubuntu2:9092错误时需在三台服务器上配置如下命令,以ubuntu2为例,另外两台同样的规则配置
# sudo vim /etc/hosts
# 10.211.55.8 ubuntu1
# 10.211.55.7 ubuntu3
Kafka基础操作
创建topic
创建一个topic(主题)。Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server 10.211.55.8:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server 10.211.55.8:9092
# 成功打印出 test
生产消息到Kafka
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中。
bin/kafka-console-producer.sh --broker-list 10.211.55.8:9092 --topic test
# “>”表示等待输入
从Kafka消费消息
再开一个窗口:
# 使用消费 test 主题中的消息。
bin/kafka-console-consumer.sh --bootstrap-server 10.211.55.8:9092 --topic test --from-beginning# 实现了生产者发送消息,消费者接受消息
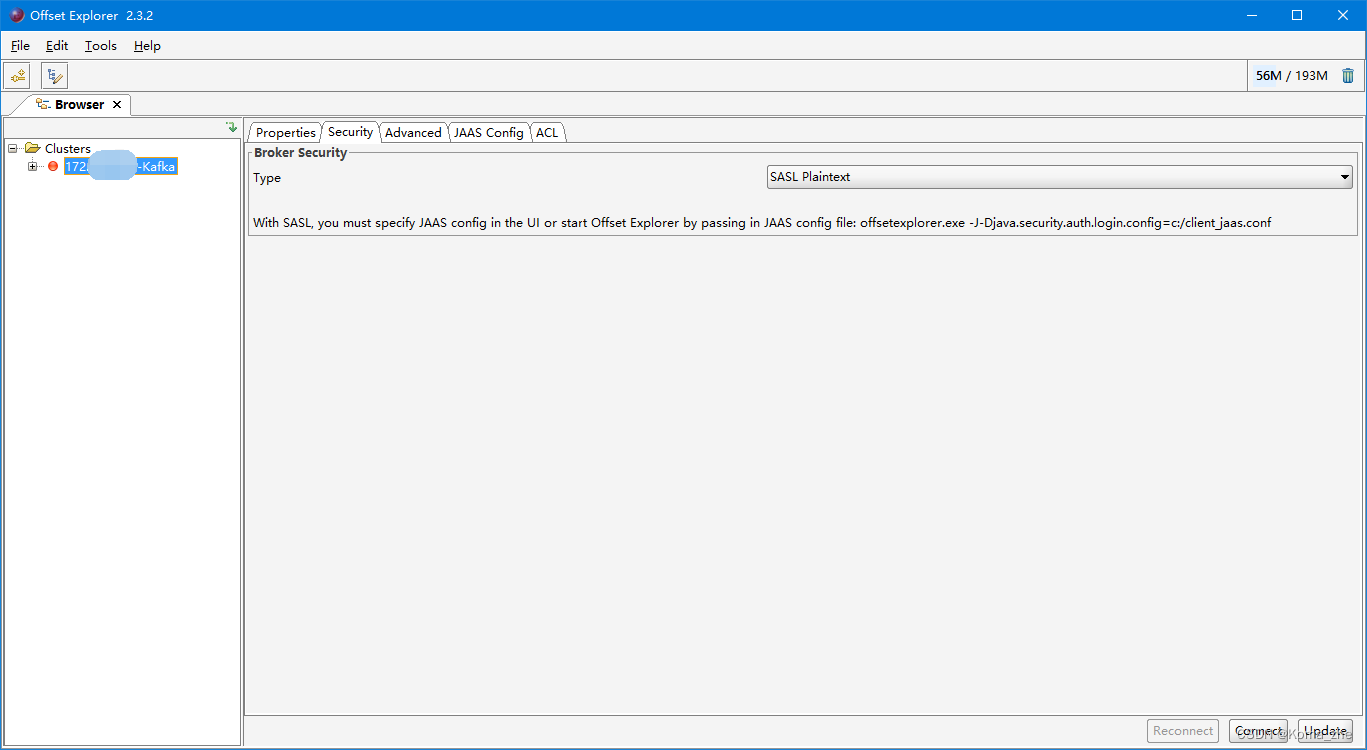
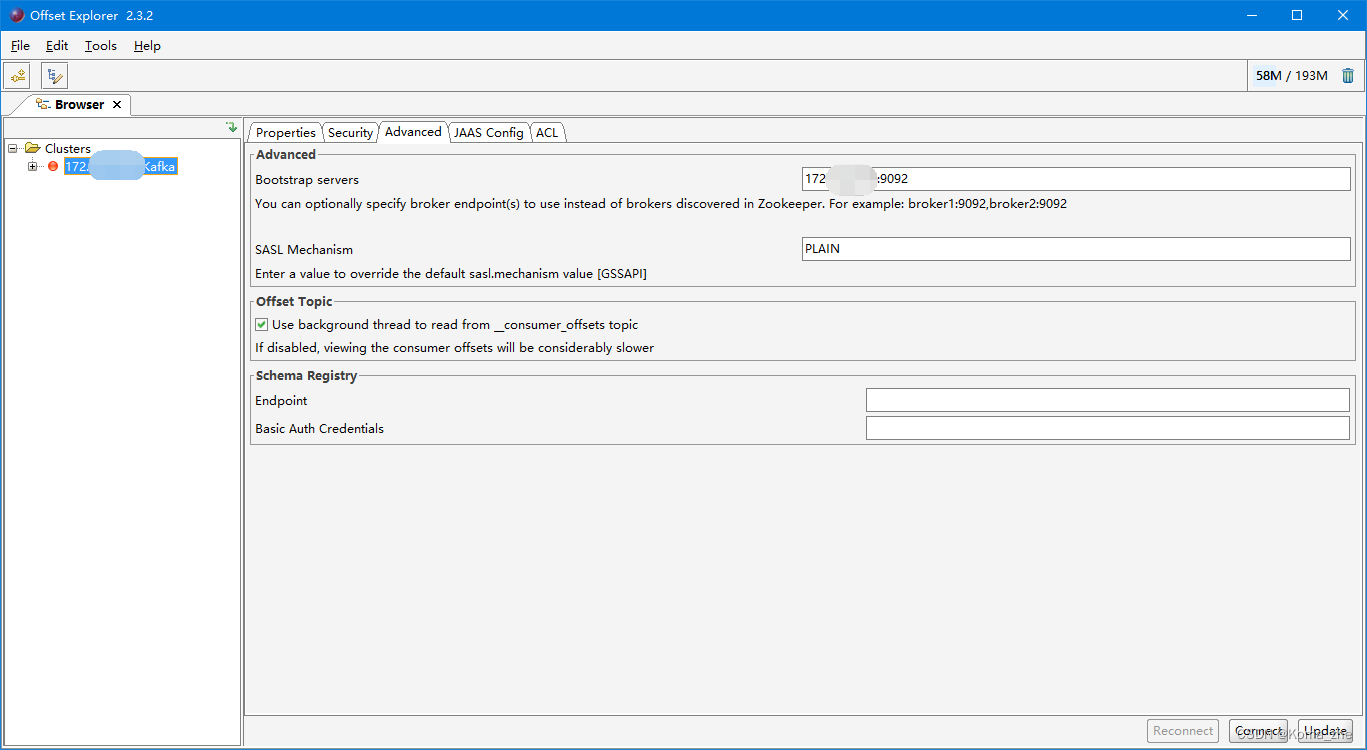
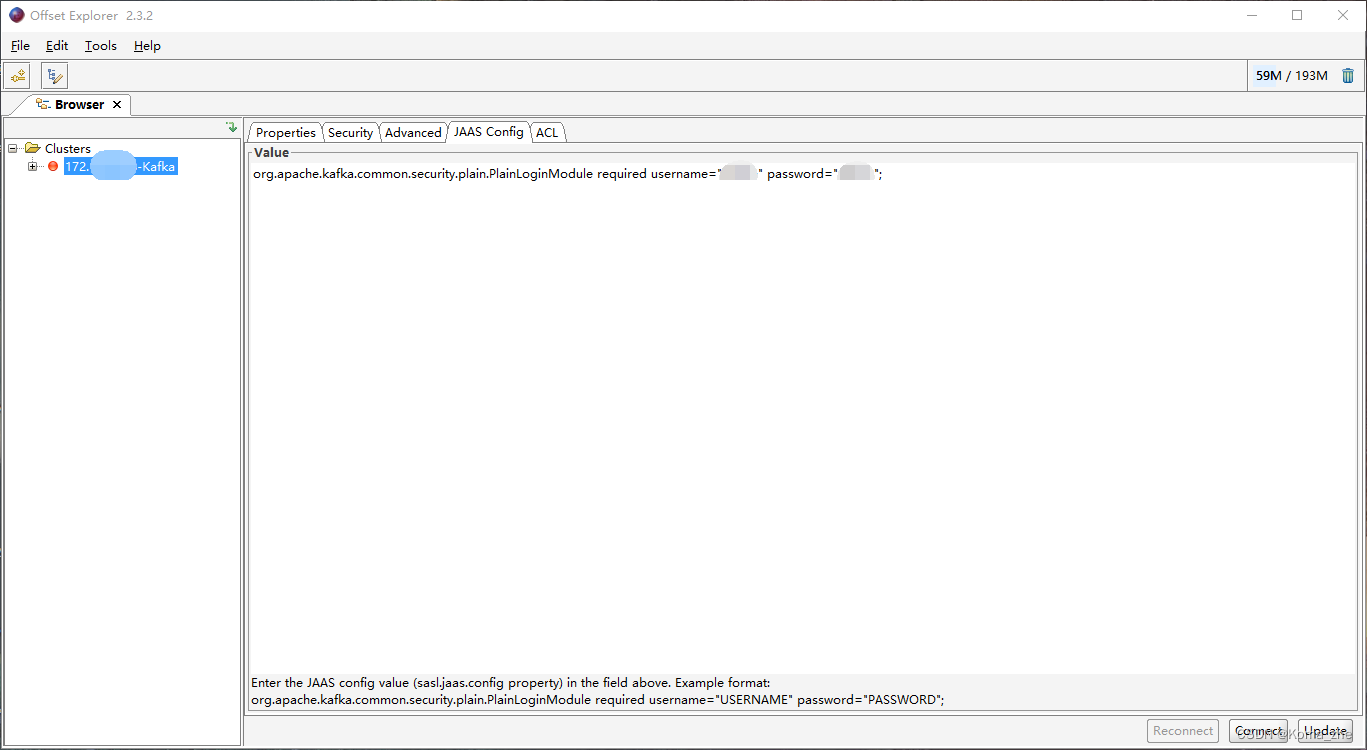
使用 Kafka Tools 操作Kafka
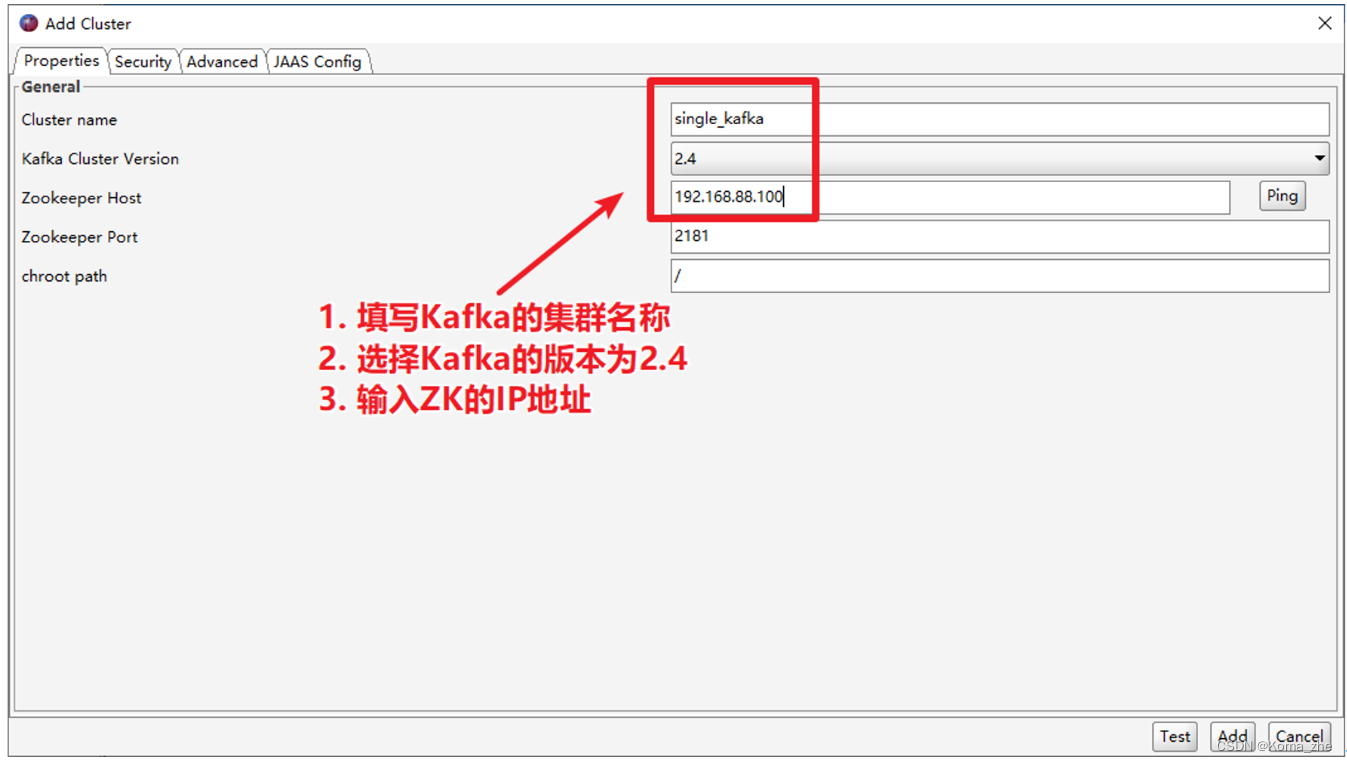

带Security连接Kafka Tool
Java编程操作Kafka
导入Maven Kafka pom.xml 依赖:
<repositories><!-- 代码库 --><repository><id>central</id><url>http://maven.aliyun.com/nexus/content/groups/public//</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled><updatePolicy>always</updatePolicy><checksumPolicy>fail</checksumPolicy></snapshots></repository>
</repositories><dependencies><!-- kafka客户端工具 --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version></dependency><!-- 工具类 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-io</artifactId><version>1.3.2</version></dependency><!-- SLF桥接LOG4J日志 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.6</version></dependency><!-- SLOG4J日志 --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.16</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.7.0</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins>
</build>log4j.properties:(放入到resources文件夹中)
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
同步生产消息到Kafka中:
- 创建用于连接Kafka的Properties配置
Properties props = new Properties();
//这个配置是 Kafka 生产者和消费者必须要指定的一个配置项,它用于指定 Kafka 集群中的一个或多个 broker 地址,生产者和消费者将使用这些地址与 Kafka 集群建立连接。
props.put("bootstrap.servers", "192.168.88.100:9092");
//这行代码将 acks 配置设置为 all。acks 配置用于指定消息确认的级别。在此配置下,生产者将等待所有副本都成功写入后才会认为消息发送成功。这种配置级别可以确保数据不会丢失,但可能会影响性能。
props.put("acks", "all");
//这行代码将键(key)序列化器的类名设置为 org.apache.kafka.common.serialization.StringSerializer。键和值都需要被序列化以便于在网络上传输。这里使用的是一个字符串序列化器,它将字符串序列化为字节数组以便于发送到 Kafka 集群。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//这行代码将值(value)序列化器的类名设置为 org.apache.kafka.common.serialization.StringSerializer。这里同样使用的是一个字符串序列化器,它将字符串序列化为字节数组以便于发送到 Kafka 集群。
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- 创建一个生产者对象 KafkaProducer
- 调用 send 发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
- 再调用一个Future.get() 方法等待响应
- 关闭生产者
使用同步等待的方式发送消息
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;/*** Kafka的生产者程序,会将消息创建出来,并发送到Kafka集群中* 1. 创建用于连接Kafka的Properties配置* 2. 创建一个生产者对象KafkaProducer* 3. 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值* 4. 再调用一个Future.get()方法等待响应* 5. 关闭生产者*/
public class KafkaProducerTest {public static void main(String[] args) throws ExecutionException, InterruptedException {// 创建用于连接Kafka的Properties配置Properties props = new Properties();props.put("bootstrap.servers", "172.xx.xx.1x8:9092");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("security.protocol", "SASL_PLAINTEXT");props.put("sasl.mechanism", "PLAIN");props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\";");// 实现生产者的幂等性props.put("enable.idempotence",true);// 创建一个生产者对象KafkaProducerKafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);// 发送1-100的消息到指定的topic中for (int i = 0; i < 100; ++i) {// 一、使用同步等待的方式发送消息// 构建一条消息,直接new ProducerRecord//"test":这个参数是指定 Kafka 主题(topic)的名称,表示这条记录将被发送到哪个主题中。// null:这个参数表示记录的键(key)。在 Kafka 中,每条消息都可以有一个键值对,键是一个可选参数,如果没有设置,则为 null。//i + "":这个参数表示记录的值(value)。这里的 i 是一个整数,通过将它转换为字符串来设置记录的值。这个值将被序列化为字节数组并被发送到 Kafka 集群。ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", null, i + "");Future<RecordMetadata> future = kafkaProducer.send(producerRecord);// 调用Future的get方法等待响应future.get();System.out.println("第" + i + "条消息写入成功!");}// 关闭生产者kafkaProducer.close();}
}
异步使用带有回调函数方法生产消息
如果想获取生产者消息是否成功,或者成功生产消息到 Kafka 中后,执行一些其他动作。此时,可以很方便地使用带有回调函数来发送消息。
- 在发送消息出现异常时,能够及时打印出异常信息
- 在发送消息成功时,打印 Kafka 的 topic 名字、分区id、offset
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;/*** Kafka的生产者程序,会将消息创建出来,并发送到Kafka集群中* 1. 创建用于连接Kafka的Properties配置* 2. 创建一个生产者对象KafkaProducer* 3. 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值* 4. 再调用一个Future.get()方法等待响应* 5. 关闭生产者*/
public class KafkaProducerTest {public static void main(String[] args) throws ExecutionException, InterruptedException {// 创建用于连接Kafka的Properties配置Properties props = new Properties();props.put("bootstrap.servers", "172.16.4.158:9092");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("security.protocol", "SASL_PLAINTEXT");props.put("sasl.mechanism", "PLAIN");props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin\";");//实现生产者的幂等性props.put("enable.idempotence",true);// 创建一个生产者对象KafkaProducerKafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);// 发送1-100的消息到指定的topic中for (int i = 0; i < 100; ++i) {// 二、使用异步回调的方式发送消息ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", null, i + "");//使用匿名内部类实现Callback接口,该接口中表示Kafka服务器响应给客户端,会自动调用onCompletion方法//metadata:消息的元数据(属于哪个topic、属于哪个partition、对应的offset是什么)//exception:这个对象Kafka生产消息封装了出现的异常,如果为null,表示发送成功,如果不为null,表示出现异常。kafkaProducer.send(producerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {// 1. 判断发送消息是否成功if(exception == null) {// 发送成功// 主题String topic = metadata.topic();// 分区idint partition = metadata.partition();// 偏移量long offset = metadata.offset();System.out.println("topic:" + topic + " 分区id:" + partition + " 偏移量:" + offset);}else {// 发送出现错误System.out.println("生产消息出现异常!");// 打印异常消息System.out.println(exception.getMessage());// 打印调用栈System.out.println(exception.getStackTrace());}}});}// 4.关闭生产者kafkaProducer.close();}
}
从Kafka的topic中消费消息
从 test topic中,将消息都消费,并将记录的offset、key、value打印出来。
- 创建Kafka消费者配置
Properties props = new Properties();
//这一行将属性"bootstrap.servers"的值设置为"node1.itcast.cn:9092"。这是Kafka生产者和消费者所需的Kafka集群地址和端口号。
props.setProperty("bootstrap.servers", "node1.itcast.cn:9092");
//这一行将属性"group.id"的值设置为"test"。这是消费者组的唯一标识符。所有属于同一组的消费者将共享一个消费者组ID。
props.setProperty("group.id", "test");
//这一行将属性"enable.auto.commit"的值设置为"true"。这表示消费者是否应该自动提交偏移量。
props.setProperty("enable.auto.commit", "true");
//这一行将属性"auto.commit.interval.ms"的值设置为"1000"。这是消费者自动提交偏移量的时间间隔,以毫秒为单位。
props.setProperty("auto.commit.interval.ms", "1000");
//这两行将属性"key.deserializer"和"value.deserializer"的值都设置为"org.apache.kafka.common.serialization.StringDeserializer"。这是用于反序列化Kafka消息的Java类的名称。在这种情况下,消息的键和值都是字符串类型,因此使用了StringDeserializer类来反序列化它们。
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- 创建Kafka消费者
- 订阅要消费的主题
- 使用一个while循环,不断从Kafka的topic中拉取消息
- 将将记录(record)的offset、key、value都打印出来
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** 消费者程序* 1.创建Kafka消费者配置* 2.创建Kafka消费者* 3.订阅要消费的主题* 4.使用一个while循环,不断从Kafka的topic中拉取消息* 5.将将记录(record)的offset、key、value都打印出来*/
public class KafkaConsumerTest {public static void main(String[] args) throws InterruptedException {// 创建Kafka消费者配置Properties props = new Properties();props.setProperty("bootstrap.servers", "172.16.4.158:9092");props.setProperty("group.id", "test");props.setProperty("enable.auto.commit", "true");props.setProperty("auto.commit.interval.ms", "1000");props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("security.protocol", "SASL_PLAINTEXT");props.put("sasl.mechanism", "PLAIN");props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\";");// 创建Kafka消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);// 订阅要消费的主题// 指定消费者从哪个topic中拉取数据kafkaConsumer.subscribe(Arrays.asList("test"));// 使用一个while循环,不断从Kafka的topic中拉取消息while(true) {// Kafka的消费者一次拉取一批的数据ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));// 将将记录(record)的offset、key、value都打印出来for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {// 主题String topic = consumerRecord.topic();// offset:这条消息处于Kafka分区中的哪个位置long offset = consumerRecord.offset();// key和valueString key = consumerRecord.key();String value = consumerRecord.value();System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);}}}
}
Kafka 重要概念
broker
一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错。broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态。一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能。
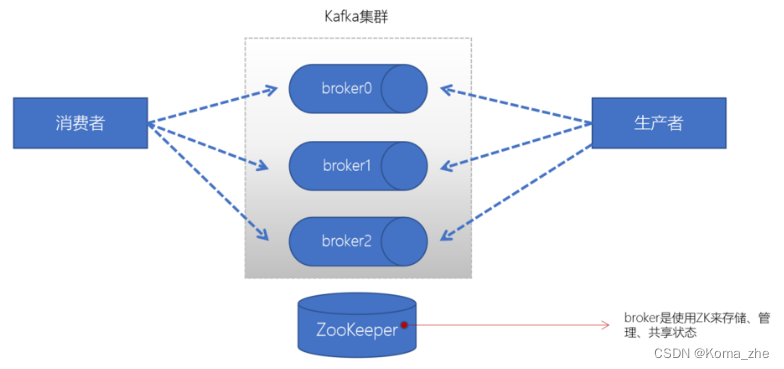
Zookeeper
ZK 用来管理和协调 broker,并且存储了 Kafka 的元数据(例如:有多少topic、partition、consumer)。ZK 服务主要用于通知生产者和消费者 Kafka 集群中有新的 broker 加入、或者 Kafka 集群中出现故障的 broker。
注:Kafka正在逐步想办法将 ZooKeeper 剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据。
Kafka Tool 可以查看ZooKeeper配置
producer(生产者)
生产者负责将数据推送给broker的 topic
consumer(消费者)
消费者负责从broker的 topic 中拉取数据,并自己进行处理
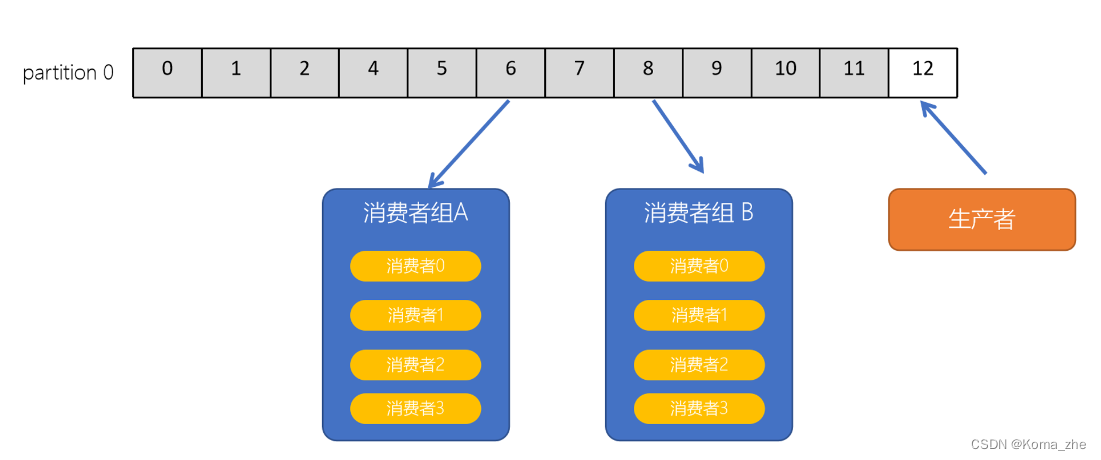
consumer group(消费者组)
consumer group是 Kafka 提供的可扩展且具有容错性的消费者机制。一个消费者组可以包含多个消费者。一个消费者组有一个唯一的ID(group Id)。组内的消费者一起消费主题的所有分区数据。
主题(Topic)
主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据。Kafka 中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制。在主题中的消息是有结构的,一般一个主题包含某一类消息。一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
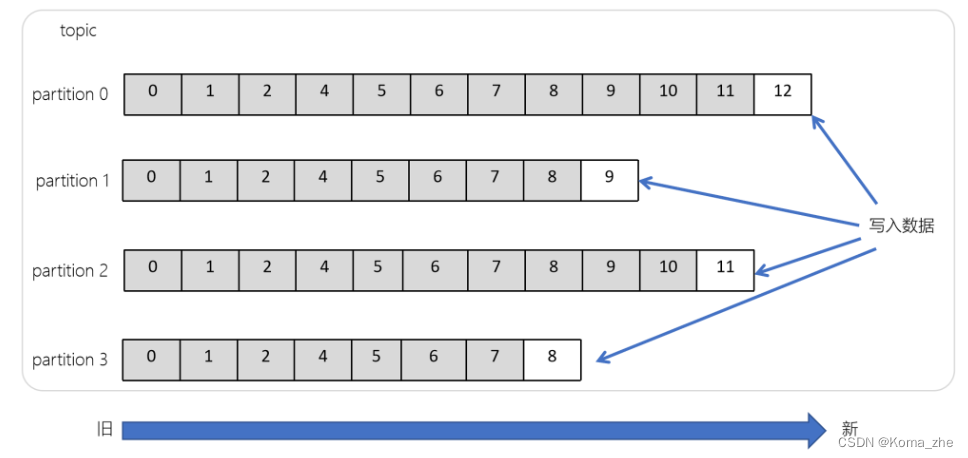
分区(Partitions)
在Kafka集群中,主题被分为多个分区。在 Kafka 中,同一个 topic 的消息可以被分配到不同的分区中,具体分配规则取决于 partitioner。
Kafka 提供了默认的 partitioner 实现,称为 DefaultPartitioner,其将消息的 key(如果存在)进行哈希,然后根据哈希值确定该消息应该被分配到哪个分区。如果消息没有 key,则采用轮询的方式将消息分配到不同的分区中。
除了默认的 partitioner,用户还可以自定义 partitioner 实现,以满足不同的需求。自定义 partitioner 实现需要实现 Kafka 提供的 Partitioner 接口,并在生产者配置中指定使用该 partitioner。
无论是使用默认的 partitioner 还是自定义 partitioner,都需要遵循以下规则:
- 对于同一个 key,始终分配到同一个分区中。
- 对于没有 key 的消息,应该采用随机或轮询的方式将消息分配到不同的分区中。
需要注意的是,分区数的变化也可能导致消息分配到不同的分区中。例如,当某个 topic 的分区数发生变化时,之前已经写入的消息可能会被重新分配到不同的分区中。因此,在生产者代码中应该谨慎处理分区数的变化,以避免数据丢失或重复。

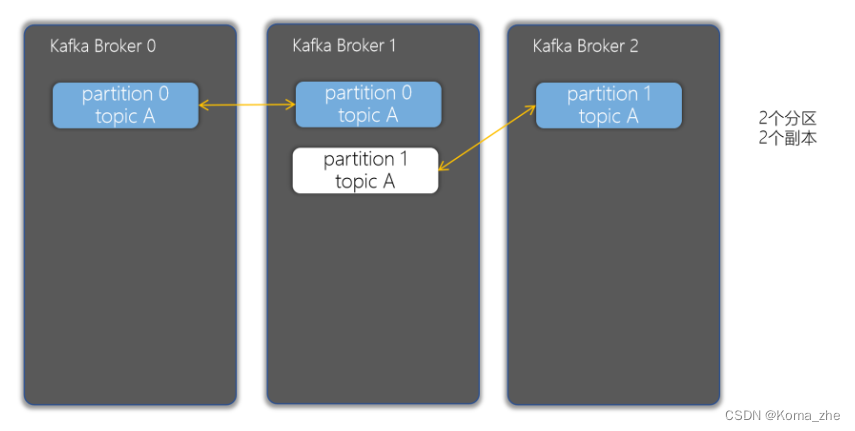
副本(Replicas)
副本可以确保某个服务器出现故障时,确保数据依然可用。在Kafka中,一般都会设计副本的个数>1。
偏移量(offset)
offset 记录着下一条将要发送给 Consumer 的消息的序号。默认 Kafka 将 offset 存储在ZooKeeper 中。在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset。偏移量在分区中才是有意义的。在分区之间,offset 是没有任何意义的。
消费者组
Kafka 支持有多个消费者同时消费一个主题中的数据。启动两个消费者共同来消费 test 主题的数据。
修改生产者程序,让生产者不停地每3秒生产1-100个数字:
// 发送1-100数字到Kafka的test主题中
while(true) {for (int i = 1; i <= 100; ++i) {// 注意:send方法是一个异步方法,它会将要发送的数据放入到一个buffer中,然后立即返回// 这样可以让消息发送变得更高效producer.send(new ProducerRecord<>("test", i + ""));}Thread.sleep(3000);
}
同时运行两个消费者:
可以发现,只有一个消费者程序能够拉取到消息。想要让两个消费者同时消费消息,必须要给 test 主题,添加一个分区。
# 设置 test topic为2个分区
bin/kafka-topics.sh --zookeeper 10.211.55.8:2181 -alter --partitions 2 --topic test
重新运行生产者、两个消费者程序,就可以看到两个消费者都可以消费Kafka Topic的数据了。
Kafka生产者幂等性
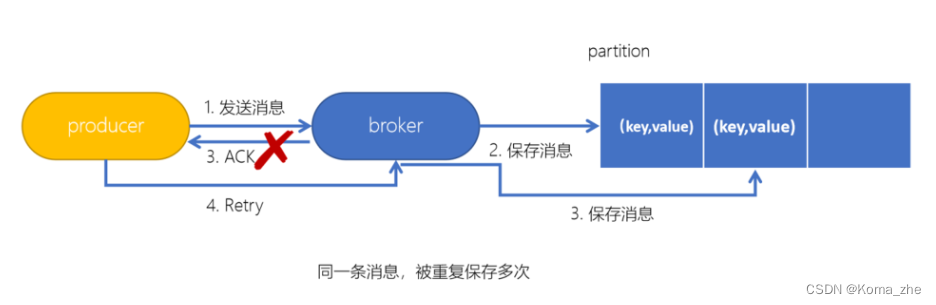
拿http举例来说,一次或多次请求,得到地响应是一致的(网络超时等问题除外),换句话说,就是执行多次操作与执行一次操作的影响是一样的。如果,某个系统是不具备幂等性的,如果用户重复提交了某个表格,就可能会造成不良影响。例如:用户在浏览器上点击了多次提交订单按钮,会在后台生成多个一模一样的订单。
Kafka生产者幂等性:在生产者生产消息时,如果出现 retry 时,有可能会一条消息被发送了多次,如果 Kafka 不具备幂等性的,就有可能会在 partition 中保存多条一模一样的消息。
//配置幂等性
props.put("enable.idempotence",true);
幂等性原理
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的 Sequence Number。

Kafka 事务
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。
类似于数据库的事务。Kafka事务指的是 生产者生产消息 以及消费者提交offset 的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。(consumer-transform-producer模式)
事务操作API:
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作。
- beginTransaction(开始事务):启动一个Kafka事务。
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交。
- commitTransaction(提交事务):提交事务。
- abortTransaction(放弃事务):取消事务。
Kafka事务编程
事务相关属性配置
生产者:
// 配置事务的id,开启了事务会默认开启幂等性
props.put("transactional.id", "first-transactional");
消费者:
// 消费者需要设置隔离级别
props.put("isolation.level","read_committed");
// 关闭自动提交,开启事务的,不能开启offset自动提交,假设每秒提交一次,offset不受事务控制
props.put("enable.auto.commit", "false");
Kafka事务编程案例
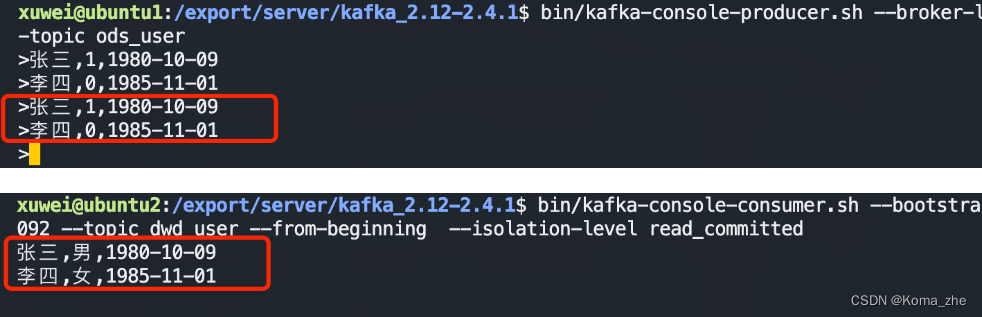
需求:在Kafka的 topic 【ods_user】中有一些用户数据,数据格式如下:
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
需要编写程序,将用户的性别转换为 男、女(1-男,0-女),转换后将数据写入到topic 【dwd_user】中。
要求使用事务保障,要么消费了数据同时写入数据到 topic,提交offset。要么全部失败。
启动生产者控制台程序模拟数据:
# 创建名为ods_user和dwd_user的主题
bin/kafka-topics.sh --create --bootstrap-server 10.211.55.8:9092 --topic ods_user
bin/kafka-topics.sh --create --bootstrap-server 10.211.55.8:9092 --topic dwd_user# 窗口一:生产数据到 ods_user
bin/kafka-console-producer.sh --broker-list 10.211.55.8:9092 --topic ods_user# 窗口二:从 dwd_user 消费数据
bin/kafka-console-consumer.sh --bootstrap-server 10.211.55.8:9092 --topic dwd_user --from-beginning --isolation-level read_committed
创建消费者代码:
createConsumer方法,该方法中返回一个消费者,订阅【ods_user】主题。注意:需要配置事务隔离级别、关闭自动提交。
//创建消费者public static Consumer<String, String> createConsumer() {// 1. 创建Kafka消费者配置Properties props = new Properties();props.setProperty("bootstrap.servers", "10.211.55.8:9092");props.setProperty("group.id", "ods_user");props.put("isolation.level","read_committed");props.setProperty("enable.auto.commit", "false");props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 2. 创建Kafka消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 3. 订阅要消费的主题consumer.subscribe(Arrays.asList("ods_user"));return consumer;
}
编写创建生产者代码:
createProducer方法,返回一个生产者对象。注意:需要配置事务的id,开启了事务会默认开启幂等性。
注:如果使用了事务,不要使用异步发送
//创建生产者public static Producer<String, String> createProduceer() {// 1. 创建生产者配置Properties props = new Properties();props.put("bootstrap.servers", "10.211.55.8:9092");props.put("transactional.id", "dwd_user");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 2. 创建生产者Producer<String, String> producer = new KafkaProducer<>(props);return producer;}
编写代码消费并生产数据:
步骤:
- 调用之前实现的方法,创建消费者、生产者对象 。
- 生产者调用 initTransactions 初始化事务。
- 编写一个while死循环,在while循环中不断拉取数据,进行处理后,再写入到指定的topic。
while循环中:
- 生产者开启事务
- 消费者拉取消息
- 遍历拉取到的消息,并进行预处理(将1转换为男,0转换为女)
- 生产消息到 topic【dwd_user】中
- 提交偏移量到事务中
- 提交事务
- 捕获异常,如果出现异常,则取消事务
public static void main(String[] args) {// 调用之前实现的方法,创建消费者、生产者对象Consumer<String, String> consumer = createConsumer();Producer<String, String> producer = createProducer();// 初始化事务producer.initTransactions();// 在while死循环中不断拉取数据,进行处理后,再写入到指定的topicwhile (true) {try {// 1. 开启事务producer.beginTransaction();// 2. 定义Map结构,用于保存分区对应的offsetMap<TopicPartition, OffsetAndMetadata> offsetCommits = new HashMap<>();// 2. 拉取消息ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(2));for (ConsumerRecord<String, String> record : records) {// 3. 保存偏移量//将当前消息所属分区的偏移量保存到HashMap中,并且将偏移量加1,以便下次从此偏移量开始消费消息。offsetCommits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1));// 4. 进行转换处理String[] fields = record.value().split(",");fields[1] = fields[1].equalsIgnoreCase("1") ? "男" : "女";String message = fields[0] + "," + fields[1] + "," + fields[2];// 5. 生产消息到dwd_userproducer.send(new ProducerRecord<>("dwd_user", message));}// 6. 提交偏移量到事务,producer.sendOffsetsToTransaction(offsetCommits, "ods_user");// 7. 提交事务producer.commitTransaction();}catch (Exception e) {// 8. 放弃事务producer.abortTransaction();}}}
将已消费的消息的偏移量提交到生产者的事务中,是为了确保在生产者发送消息到新的主题之前,已经消费的消息的偏移量已经被记录下来并保存在事务中。
如果不提交偏移量,则可能会导致已经消费的消息在下一次启动消费者时重复消费。
因此,将偏移量提交到生产者的事务中是非常重要的,可以确保消费者在下一次启动时可以正确地从上次停止的位置继续消费。
测试:
成功转化并消费:
模拟异常测试事务:
// 3. 保存偏移量
offsetCommits.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 1));// 4. 进行转换处理
String[] fields = record.value().split(",");
fields[1] = fields[1].equalsIgnoreCase("1") ? "男":"女";
String message = fields[0] + "," + fields[1] + "," + fields[2];// 模拟异常
int i = 1/0;// 5. 生产消息到dwd_user
producer.send(new ProducerRecord<>("dwd_user", message));
启动程序一次,抛出异常。再启动程序一次,还是抛出异常。直到我们处理该异常为止。
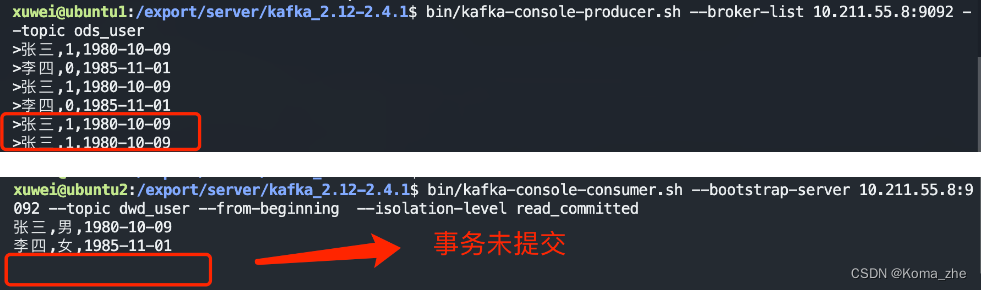
可以消费到消息,但如果中间出现异常的话,offset是不会被提交的,除非消费、生产消息都成功,才会提交事务。
相关文章:
【Kafka】消息队列Kafka基础
目录 消息队列简介消息队列的应用场景异步处理系统解耦流量削峰日志处理 消息队列的两种模式点对点模式发布订阅模式 Kafka简介及应用场景Kafka比较其他MQ的优势Kafka目录结构搭建Kafka集群编写Kafka一键启动/关闭脚本 Kafka基础操作创建topic生产消息到Kafka从Kafka消费消息使…...
Java的第十五篇文章——网络编程(后期再学一遍)
目录 学习目的 1. 对象的序列化 1.1 ObjectOutputStream 对象的序列化 1.2 ObjectInputStream 对象的反序列化 2. 软件结构 2.1 网络通信协议 2.1.1 TCP/IP协议参考模型 2.1.2 TCP与UDP协议 2.2 网络编程三要素 2.3 端口号 3. InetAddress类 4. Socket 5. TCP网络…...

【深度学习】High-Resolution Image Synthesis with Latent Diffusion Models,论文
13 Apr 2022 论文:https://arxiv.org/abs/2112.10752 代码:https://github.com/CompVis/latent-diffusion 文章目录 PS基本概念运作原理 AbstractIntroductionRelated WorkMethodPerceptual Image CompressionLatent Diffusion Models Conditioning Mec…...

前端学习——Vue (Day6)
路由进阶 路由的封装抽离 //main.jsimport Vue from vue import App from ./App.vue import router from ./router/index// 路由的使用步骤 5 2 // 5个基础步骤 // 1. 下载 v3.6.5 // 2. 引入 // 3. 安装注册 Vue.use(Vue插件) // 4. 创建路由对象 // 5. 注入到new Vue中&…...
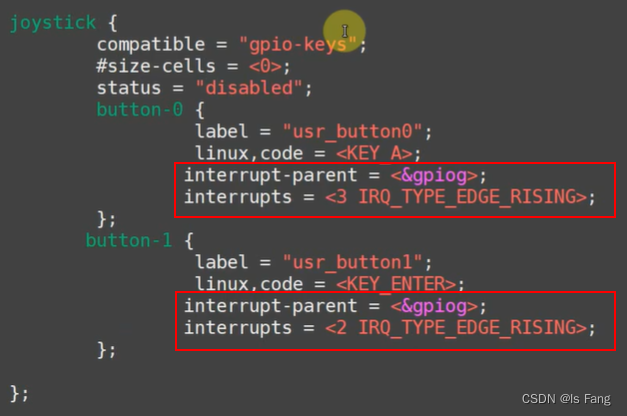
STM32MP157驱动开发——按键驱动(tasklet)
文章目录 “tasklet”机制:内核函数定义 tasklet使能/ 禁止 tasklet调度 tasklet删除 tasklet tasklet软中断方式的按键驱动程序(stm32mp157)tasklet使用方法:button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “tasklet”机制: …...
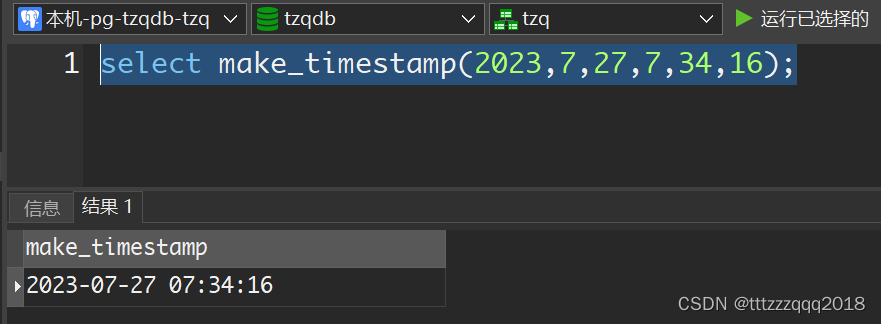
PostgreSQL构建时间
– PostgreSQL构建时间 select make_timestamp(2023,7,27,7,34,16);...

2023-将jar包上传至阿里云maven私有仓库(云效制品仓库)
一、背景介绍 如果要将平时积累的代码工具jar包,上传至云端,方便团队大家一起使用,一般的方式就是上传到Maven中心仓库(但是这种方式步骤多,麻烦,而且上传之后审核时间比较长,还不太容易通过&a…...

嵌入式linux之OLED显示屏SPI驱动实现(SH1106,ssd1306)
周日业余时间太无聊,又不喜欢玩游戏,大家的兴趣爱好都是啥?我觉得敲代码也是一种兴趣爱好。正巧手边有一块儿0.96寸的OLED显示屏,一直在吃灰,何不把玩一把?于是说干就干,最后在我的imax6ul的lin…...
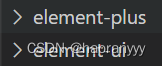
关于element ui 安装失败的问题解决方法、查看是否安装成功及如何引入
Vue2引入 执行npm i element-ui -S报错 原因:npm版本太高 报错信息: 解决办法: 使用命令: npm install --legacy-peer-deps element-ui --save 引入: 在main.js文件中引入 //引入Vue import Vue from vue; //引入…...
Selenium多浏览器处理
Python 版本 #导入依赖 import os from selenium import webdriverdef test_browser():#使用os模块的getenv方法来获取声明环境变量browserbrowser os.getenv("browser").lower()#判断browser的值if browser "headless":driver webdriver.PhantomJS()e…...

浅谈 AI 大模型的崛起与未来展望:马斯克的 xAI 与中国产业发展
文章目录 💬话题📋前言🎯AI 大模型的崛起🎯中国 AI 产业的进展与挑战🎯AI 大模型的未来展望🧩补充 📝最后 💬话题 北京时间 7 月 13 日凌晨,马斯克在 Twiiter 上宣布&am…...
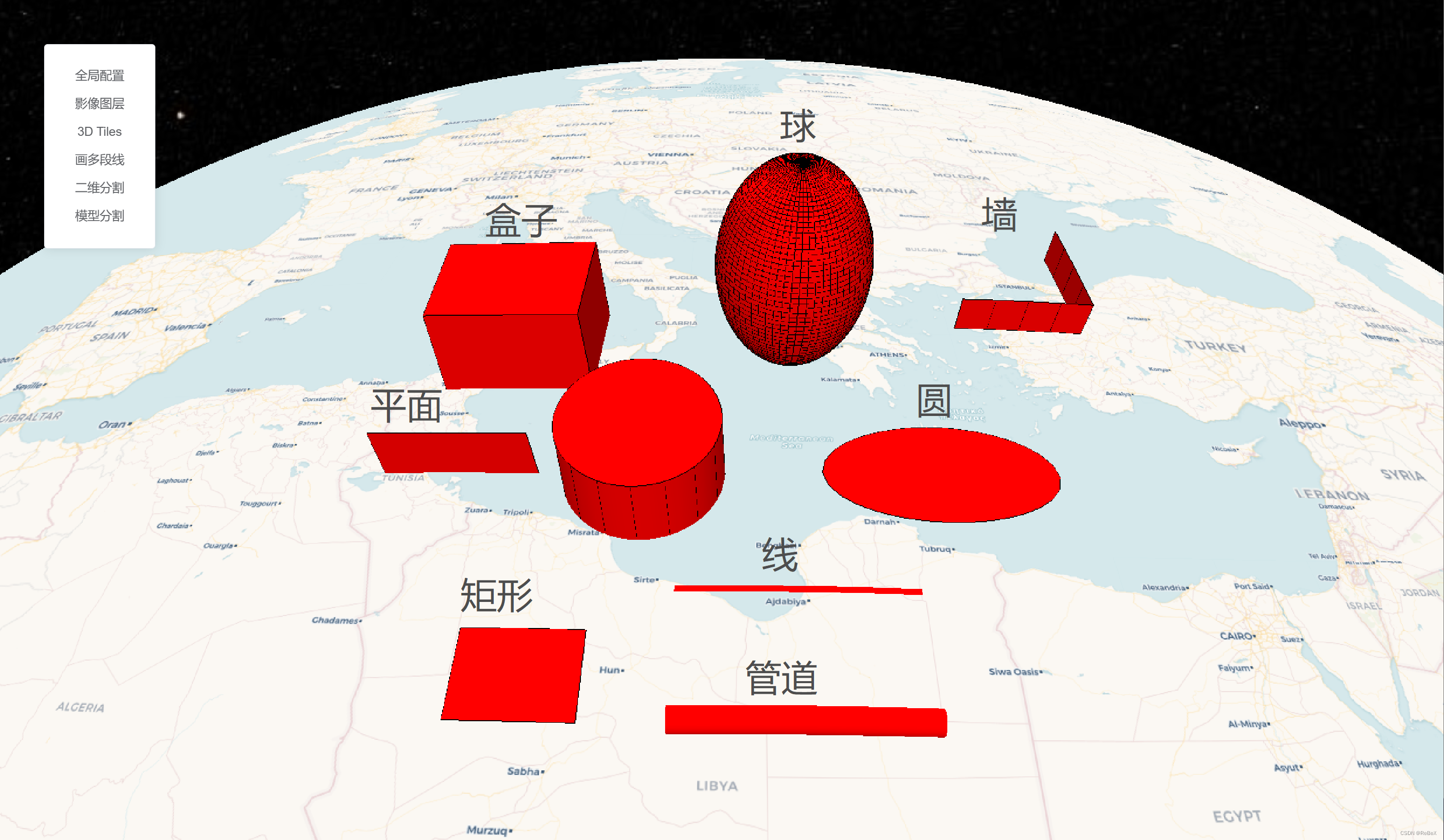
【CesiumJS材质】(1)圆扩散
效果示例 最佳实践: 其他效果: 要素说明: 代码 /** Date: 2023-07-21 15:15:32* LastEditors: ReBeX 420659880qq.com* LastEditTime: 2023-07-27 11:13:17* FilePath: \cesium-tyro-blog\src\utils\Material\EllipsoidFadeMaterialP…...

实战-单例模式和创建生产者相结合
实际中遇到了这样一个问题: The producer group[xxxx] has been created before, specify another instanceName (like producer.setInstanceName) please. 发生的原因是:一个进程内,创建了多个相同topic的producer。 所以问题就转换成了如何…...

[SQL挖掘机] - 窗口函数介绍
介绍: 窗口函数也称为 OLAP 函数。OLAP 是 OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理。窗口函数是一种用于执行聚合计算和排序操作的功能强大的sql函数。它们可以在查询结果集中创建一个窗口(window)…...

原生js实现锚点滚动顶部
简介 使用原生js API实现滚动到指定容器的顶部,API是scrollIntoView 使用 let eldocment.querySelector() 获取dom元素el.scrollIntoView()该元素滚动到其父元素的顶部 高级用法 scrollIntoView(Options)//option可以配置如下 options{behavior:smoot…...

使用mysql接口遇到点问题
game_server加入了dbstorage的代码。dbstorage实现了与mysql的交互:driver_mysql。其中调用了mysql相关的接口。所以game_server需要链接libmysql.lib。 从官网下载了mysql的源码:在用cmake构建mysql工程的时候,遇到了一些问题。 msyql8.0需…...
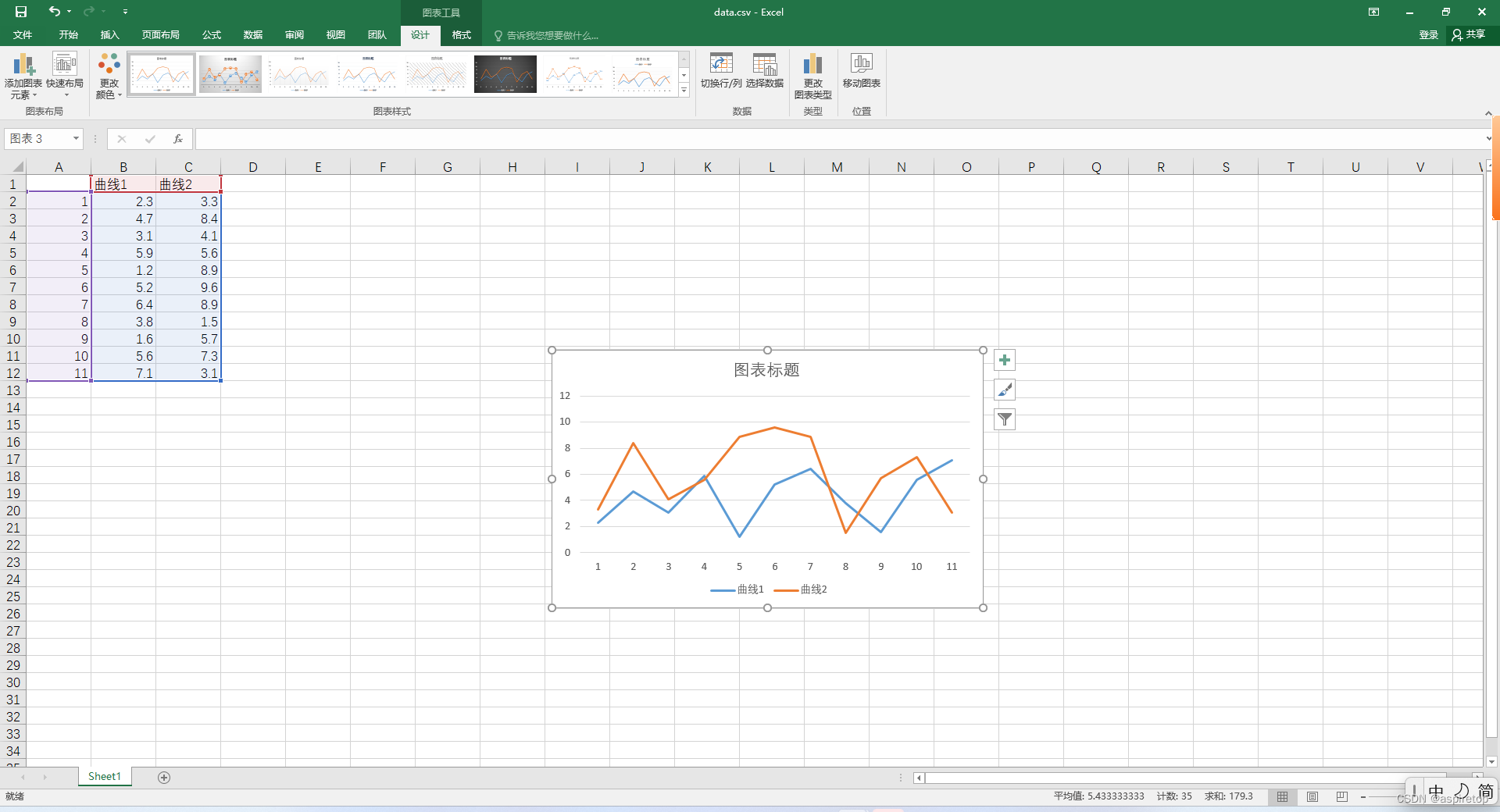
excel绘制折线图或者散点图
一、背景 假如现在通过代码处理了一批数据,想看数据的波动情况,是不是还需要写个pyhon代码,读取文件,绘制曲线,看起来也简单,但是还有更简单的方法,就是直接生成csv文件,csv文件就是…...
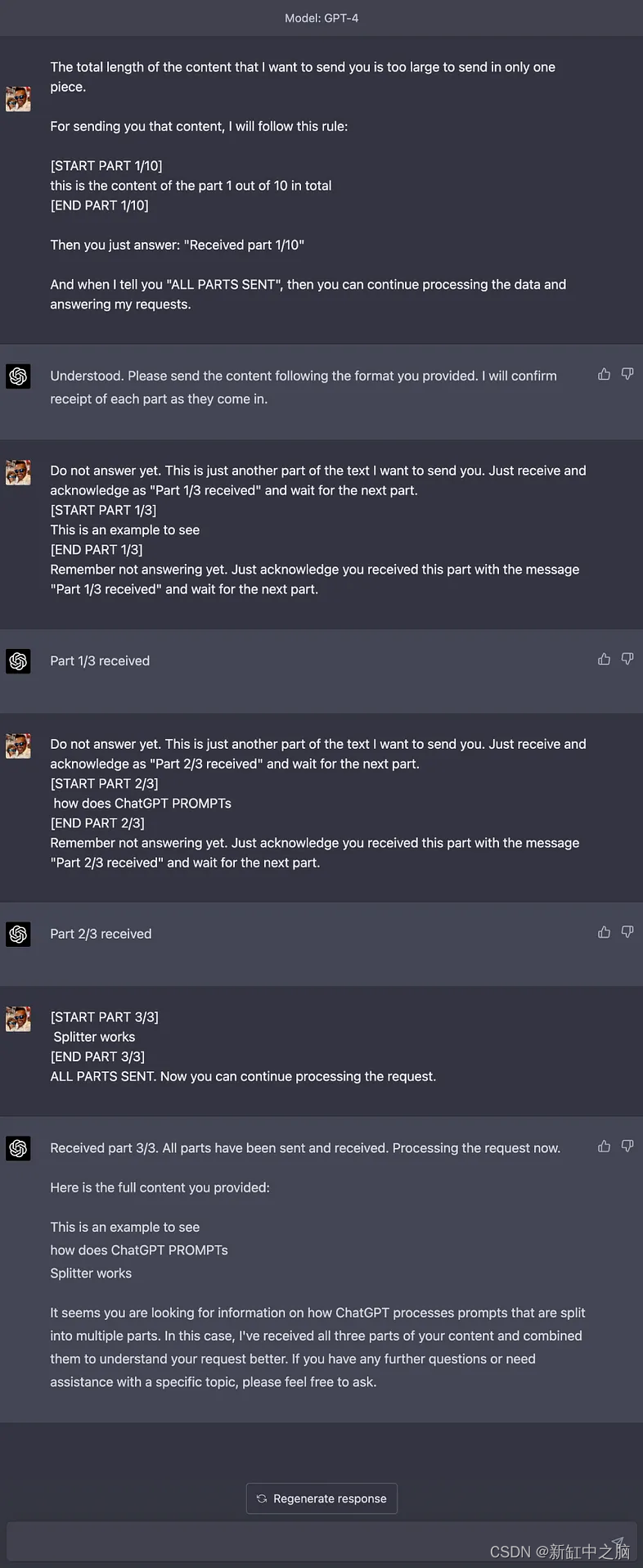
ChatGPT长文本对话输入方法
ChatGPT PROMPTs Splitter 是一个开源工具,旨在帮助你将大量上下文数据分成更小的块发送到 ChatGPT 的提示,并根据如何处理所有块接收到 ChatGPT(或其他具有字符限制的语言模型)的方法。 推荐:用 NSDT设计器 快速搭建可…...

FFmpeg-swresample的更新
auto convert的创建 在FFmpeg/libavfilter/formats.c中定义了negotiate_video和negotiate_audio,在格式协商,对于video如果需要scale,那么就会自动创建scale作为convert,对于audio,如果需要重采样,则会创建…...

回答网友 修改一个exe
网友说:他有个很多年前的没有源码的exe,在win10上没法用,让俺看一下。 俺看了一下,发现是窗体设计的背景色的问题。这个程序的背景色用的是clInactiveCaptionText。clInactiveCaptionText 在win10之前的系统上是灰色,但…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...