Lesson5.3---Python 之 NumPy 统计函数、数据类型和文件操作
一、统计函数
- NumPy 能方便地求出统计学常见的描述性统计量。
- 最开始呢,我们还是先导入 numpy。
import numpy as np
1. 求平均值 mean()
- mean() 是默认求出数组内所有元素的平均值。
- 我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止值(不包含)设置为 20,步长默认为 1 的 4 行 5 列的数组。
m1 = np.arange(20).reshape((4,5))
print(m1)
m1.mean()
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#9.5
- 如果我们想求某一维度的平均值,就设置 axis 参数,多维数组的元素指定。

- axis = 0,将从上往下(按列)计算。
m1 = np.arange(20).reshape((4,5))
print(m1)
m1.mean(axis=0)
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#array([ 7.5, 8.5, 9.5, 10.5, 11.5])
- axis = 1,将从左往右(按行)计算。
m1.mean(axis=1)
#array([ 2., 7., 12., 17.])
2. 中位数 np.median
- 中位数又称中点数,中值。
- 它是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。
- 平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据;中位数:是一个不完全"虚拟"的数。
- 平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”;中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的"中等水平"。
- 接下来看两个例子,第一个中位数是数组中的元素,是一个不虚拟的数。
ar1 = np.array([1,3,5,6,8])
np.median(ar1)
#5.0
- 第二个中位数是一个虚拟的数
ar1 = np.array([1,3,5,6,8,9])
np.median(ar1)
#5.5
3. 标准差 np.std
- 在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标
- 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
- 简单来说,标准差是一组数据平均值分散程度的一种度量。
- 一个较大的标准差,代表大部分数值和其平均值之间差异较大;
- 一个较小的标准差,代表这些数值较接近平均值。
- 例如,A、B 两组各有 6 位学生参加同一次语文测验,A 组的分数为 95、85、75、65、55、45,B 组的分数为 73、72、71、69、68、67,我们分析哪组学生之间的差距大(标准差大的差距大)?
a = np.array([95,85,75,65,55,45])
b = np.array([73,72,71,69,68,67])
print(np.std(a))
print(np.std(b))
#17.07825127659933
#2.160246899469287
- 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。
4. 方差 ndarray.var()
- 方差是衡量随机变量或一组数据时离散程度的度量。
a = np.array([95,85,75,65,55,45])
b = np.array([73,72,71,69,68,67])
print('A组的方差为:',a.var())
print('B组的方准差为:',b.var())
#A组的方差为: 291.6666666666667
#B组的方准差为: 4.666666666666667
- 标准差有计量单位,而方差无计量单位,但两者的作用一样,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。
5. 最大值 ndarray.max()
- 最大值比较好理解,默认求出数组内所有元素的最大值。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.max())
print('axis=0,从上往下查找:',m1.max(axis=0))
print('axis=1,从左往右查找',m1.max(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#19
#axis=0,从上往下查找: [15 16 17 18 19]
#axis=1,从左往右查找 [ 4 9 14 19]
6. 最小值 ndarray.min()
- 最小值比较好理解,默认求出数组内所有元素的最小值。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.min())
print('axis=0,从上往下查找:',m1.min(axis=0))
print('axis=1,从左往右查找',m1.min(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#0
#axis=0,从上往下查找: [0 1 2 3 4]
#axis=1,从左往右查找 [ 0 5 10 15]
7. 求和 ndarray.sum()
- 求和比较好理解,默认求出数组内所有元素的总和。
- axis = 0,将从上往下(按列)计算。
- axis = 1,将从左往右(按行)计算。
print(m1)
print(m1.sum())
print('axis=0,从上往下查找:',m1.sum(axis=0))
print('axis=1,从左往右查找',m1.sum(axis=1))
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
#190
#axis=0,从上往下查找: [30 34 38 42 46]
#axis=1,从左往右查找 [10 35 60 85]
8. 加权平均值 numpy.average()
加权平均值就是将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
numpy.average(a, axis=None, weights=None, returned=False)
- 其中,weights 表示数组,是一个可选参数,与 a 中的值关联的权重数组。
- a 中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的 a 的大小)或与 a 具有相同的形状。
- 如果 weights=None,则假定 a 中的所有数据的权重等于 1。一维计算是:
avg = sum(a * weights) / sum(weights)
- 对权重的唯一限制是 sum(weights) 不能为 0。`
average_a1 = [20,30,50]
print(np.average(average_a1))
print(np.mean(average_a1))
#33.333333333333336
#33.333333333333336
二、数据类型
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
1. 数据存储
- 我们可以将数组中的类型存储为浮点型。
a = np.array([1,2,3,4],dtype=np.float64)
a
#array([1., 2., 3., 4.])
- 我们可以将数组中的类型存储为布尔类型。
a = np.array([0,1,2,3,4],dtype=np.bool_)
print(a)
a = np.array([0,1,2,3,4],dtype=np.float_)
print(a)
#[False True True True True]
#[0. 1. 2. 3. 4.]
- 其中 str_ 和 string_ 区别如下:
str1 = np.array([1,2,3,4,5,6],dtype=np.str_)
string1 = np.array([1,2,3,4,5,6],dtype=np.string_)
str2 = np.array(['我们',2,3,4,5,6],dtype=np.str_)
print(str1,str1.dtype)
print(string1,string1.dtype)
print(str2,str2.dtype)
#['1' '2' '3' '4' '5' '6'] <U1
#[b'1' b'2' b'3' b'4' b'5' b'6'] |S1
#['我们' '2' '3' '4' '5' '6'] <U2
- 在内存里统一使用 unicode, 记录到硬盘或者编辑文本的时候都转换成了utf8 UTF-8 将 Unicode 编码后的字符串保存到硬盘的一种压缩编码方式
2. 定义结构化数据
- 在上述数据存储的过程种,我们对于 U1、S1、U2 并不能直接理解,这里使用其实是数据类型标识码。
| 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 |
|---|---|---|---|---|---|---|---|
| b | 代表布尔型 | i | 带符号整型 | u | 无符号整型 | f | 浮点型 |
| c | 复数浮点型 | m | 时间间隔(timedelta) | M | datatime(日期时间) | O | Python对象 |
| S,a | 字节串(S)与字符串(a) | U | Unicode | V | 原始数据(void) |
-还可以将两个字符作为参数传给数据类型的构造函数。
- 此时,第一个字符表示数据类型, 第二个字符表示该类型在内存中占用的字节数(2、4、8分别代表精度为16、32、64位的 浮点数)。
- 首先,我们创建结构化数据类型,然后,将数据类型应用于 ndarray 对象。
dt = np.dtype([('age','U1')])
print(dt)
students = np.array([("我们"),(128)],dtype=dt)
print(students,students.dtype,students.ndim)
print(students['age'])
#[('age', '<U1')]
#[('我',) ('1',)] [('age', '<U1')] 1
#['我' '1']
- 以下示例描述了一位老师的姓名、年龄、工资的特征,该结构化数据其包含以下字段:
- str 字段:name。
- int 字段:age。
- float 字段:salary。
import numpy as np
teacher = np.dtype([('name',np.str_,2), ('age', 'i1'), ('salary', 'f4')])
b = np.array([('wl', 32, 8357.50),('lh', 28, 7856.80)], dtype = teacher)
print(b)
b['name']
b['age']
#[('wl', 32, 8357.5) ('lh', 28, 7856.8)]
#array([32, 28], dtype=int8)
3. 结构化数据操作
我们可以使用数组名 [结构化名],取出数组中的所有名称,取出数据中的所有年龄。
print(b)
print(b['name'])
print(b['age'])
#[('wl', 32, 8357.5) ('lh', 28, 7856.8)]
#['wl' 'lh']
#[32 28]
三、操作文件 loadtxt
loadtxt 可以读取 txt 文本和 csv 文件。
loadtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0,encoding='bytes')
其中参数具有如下含义:
(1) fname:指定文件名称或字符串。支持压缩文件,包括 gz、bz 格式。
(2) dtype:数据类型。默认 float。
(3) comments:字符串或字符串组成的列表。表示注释字符集开始的标志,默认为 #。
(4) delimiter:字符串。分隔符。
(5) converters:字典。将特定列的数据转换为字典中对应的函数的浮点型数据。例如将空值转换为 0,默认为空。
(6) skiprows:跳过特定行数据。例如跳过前 1 行(可能是标题或注释),默认为 0。
(7) usecols:元组。用来指定要读取数据的列,第一列为 0。例如(1, 3, 5),默认为空。
(8) unpack:布尔型。指定是否转置数组,如果为真则转置,默认为 False。
(9) ndmin:整数型。指定返回的数组至少包含特定维度的数组。值域为 0、1、2,默认为 0。
(10) encoding:编码, 确认文件是 gbk 还是 utf-8 格式
返回:从文件中读取的数组。
1. 读取文件内数据
例如 data1.txt 存在数据:
0 1 2 3 4 5 6 7 8 9
…
20 21 22 23 24 25 26 27 28 29
- 我们在读取普通文件时,可以不用设置分隔符(空格 制表符)。
data = np.loadtxt(r'D:\桌面\数据分析-班级\1-2班\data1.txt',dtype=np.int32)
print(data,data.shape)
#[[ 0 1 3 3 4 5 6 7 8 9]
# [20 21 22 23 24 25 26 27 28 29]] (2, 10)
- 我们在读取 csv 文件时,与普通文件不同,需要设置分隔符,csv 默认为 , 号。
data = np.loadtxt('csv_test.csv',dtype=np.int32,delimiter=',')
print(data,data.shape)
#[[ 0 1 2 3 4 5 6 7 8 9]
# [10 11 12 13 14 15 16 17 18 19]
# [20 21 22 23 24 25 26 27 28 29]] (3, 10)
2. 不同列标识不同信息,数据读取
我们有如下数据:
| 姓名 | 年龄 | 性别 | 身高 |
|---|---|---|---|
| 小王 | 21 | 男 | 170 |
| ... | ... | ... | ... |
| 老王 | 50 | 男 | 180 |
- 文件:
has_title.txt。
(1) 以上数据由于不同列数据标识的含义和类型不同,因此我们需要自定义数据类型。
user_info = np.dtype([('name','U10'),('age','i1'),('gender','U1'),('height','i2')])
(2) 使用我们自定义的数据类型,进行读取数据操作。
data = np.loadtxt('has_title.txt',dtype=user_info,skiprows=1, encoding='utf-8')
这里需要注意的是,以上参数中,(1) 设置类型;(2) 跳过第一行;(3) 编码。
print(data['age'])
#[21 25 19 40 24 21 19 26 21 21 19 20]
在读取到文件数据后,我们可以对其数据进行一定的操作。
首先,我们可以获取年龄的数组,计算年龄的中位数。
ages = data['age']
ages.mean()
# 23.0
我们也可以计算女生的平均身高(设置一个读取条件即可)。
isgirl = data['gender'] == '女'
print(isgirl)
print(data['height'])
data['height'][isgirl]
girl_mean = np.mean(data['height'][isgirl])
'{:.2f}'.format(girl_mean)
#[False True True False False True True False False True True True]
#[170 165 167 180 168 167 159 170 168 175 160 167]
#'165.71'
3. 读取指定的列
读取指定的列 usecols=(1,3) 标识只读取第 2 列和第 4 列(索引从 0 开始)。
user_info = np.dtype([('age','i1'),('height','i2')])
print(user_info)
#[('age', 'i1'), ('height', '<i2')]
然后,使用自定义的数据类型,读取数据。
data = np.loadtxt('has_title.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(1,3))
这里需要注意的是,在以上参数中:(1) 设置类型;(2) 跳过第一行;(3) 分隔符。
print(data)
#[(22, 170) (25, 165) (19, 167) (20, 169) (21, 161) (19, 159) (27, 177)]
4. 数据中存在空值进行处理
需要借助用于 converters 参数,传递一个字典,key 为列索引,value 为对列中值的处理。
比如,我们具体如下数据,csv 中学生信息中存在空的年龄信息:
| 姓名 | 年龄 | 性别 | 身高 |
|---|---|---|---|
| 小王 | 21 | 男 | 170 |
| ... | ... | ... | ... |
| 老谭 | 50 | 男 | 180 |
文件:has_empty_data.csv。
如果我们直接读取指定的列 usecols=(1,3) ,会出现错误。
因此,在需要处理空数据的时候,我们需要创建一个函数接收列的参数,并加以处理。
def parse_age(age):try:return int(age)except:return 0
和之前一样的步骤,使用自定义的数据类型,读取数据
print(user_info)
data = np.loadtxt('has_empty_data.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(1,3),converters={1:parse_age,3:parse_age})
print(data)
#[('age', 'i1'), ('height', '<i2')]
#[(21, 170) (25, 165) (19, 167) ( 0, 169) (21, 161) (19, 0) (27, 177)]age_arr = data['age']
age_arr
#array([21, 25, 19, 0, 21, 19, 27], dtype=int8)age_arr[age_arr == 0] = np.median(age_arr[age_arr != 0])
age_arr.mean()
#21.857142857142858
计算班级年龄的平均值,由于存在 0 的数据,因此一般做法是将中位数填充。
首先,我们填充中位数,然后,我们计算平均值。
ages = data['age']
ages[ages==0] = np.median(ages)
print(ages)
np.round(np.mean(ages),2)
#[22 25 19 20 21 19 27]
#21.86
相关文章:
Lesson5.3---Python 之 NumPy 统计函数、数据类型和文件操作
一、统计函数 NumPy 能方便地求出统计学常见的描述性统计量。最开始呢,我们还是先导入 numpy。 import numpy as np1. 求平均值 mean() mean() 是默认求出数组内所有元素的平均值。我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止…...
Puppeteer 爬虫学习
puppeteer简介: Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议 控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行, 但是可以通过修改配置文件运行“有头”模式。能作什么?: 生成…...
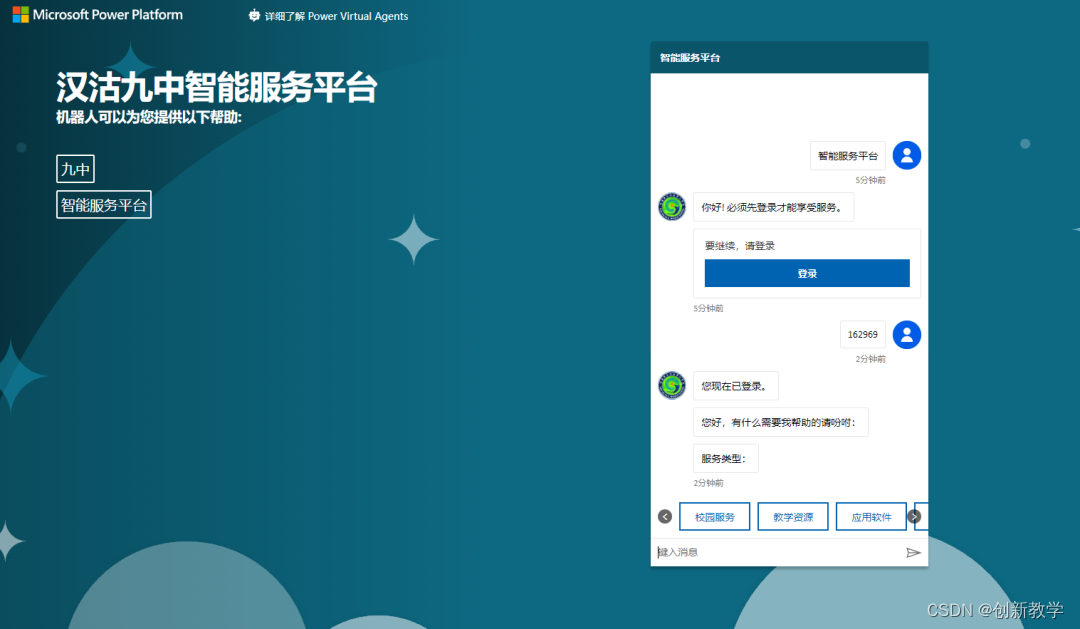
如何在Power Virtual Agents中实现身份验证
今天我们介绍一下如何通过身份验证的方式来使用Power Virtual Agents。首先进入“Microsoft 365-管理-Azure Active Directory管理中心”。 进入“Azure Active Directory管理中心”后选择“Azure Active Directory”中的“应用注册”-“新注册”。 输入新创建的应用程序名称后…...

金三银四必备软件测试必问面试题
初级软件测试必问面试题1、你的测试职业发展是什么?测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前 3 年积累测试经验,按如何做好测试工程…...
Java反序列化漏洞——CommonsCollections6链分析
一、前因因为在jdk8u71之后的版本中,sun.reflect.annotation.AnnotationInvocationHandler#readObject的逻辑发生了变化,导致CC1中的两个链条都不能使用,所有我们需要找一个在高版本中也可用的链条。/* Gadget chain: java.io.ObjectInputStr…...

Selenium浏览器自动化测试框架
Selenium浏览器自动化测试框架 目录:导读 1、selenium简介 介绍 功能 优势 2、基本使用 3、获取单节点 4、获取多节点 5、节点交互 6、动作链 7、执行JavaScript代码 8、获取节点信息 9、切换frame 10、延时等待 11、前进和后退 12、cookies 13、选…...
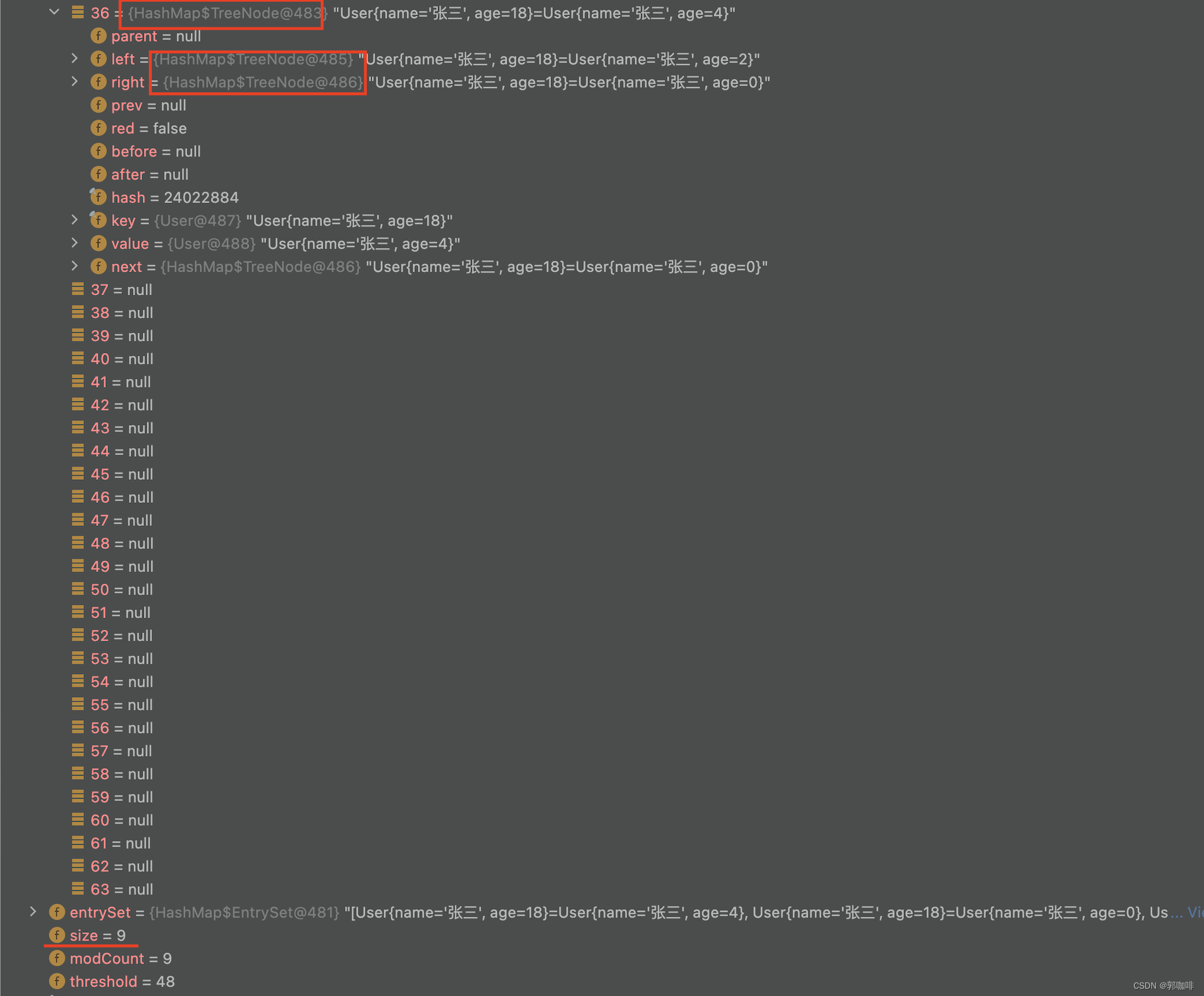
Hashmap链表长度大于8真的会变成红黑树吗?
1、本人博客《HashMap、HashSet底层原理分析》 2、本人博客《若debug时显示的Hashmap没有table、size等元素时,查看第19条》 结论 1、链表长度大于8时(插入第9条时),会触发树化(treeifyBin)方法,但是不一定会树化,若数组大小小于…...

关于接地:数字地、模拟地、信号地、交流地、直流地、屏蔽地、浮地
除了正确进行接地设计、安装,还要正确进行各种不同信号的接地处理。控制系统中,大致有以下几种地线: (1)数字地:也叫逻辑地,是各种开关量(数字量)信号的零电位。 (2&am…...

排序
一、数据流中的中位数题目描述:如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。…...
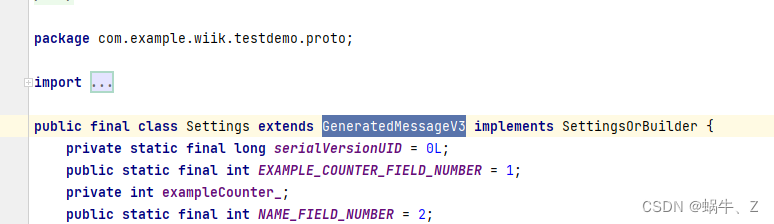
Android DataStore Proto存储接入流程详解与使用
一、介绍 通过前面的文字,我们已掌握了DataStore 的存储,但是留下一个尾巴,那就是Proto的接入。 Proto是什么? Protobuf,类似于json和xml,是一种序列化结构数据机制,可以用于数据通讯等场景&a…...

HiEV洞察 | 卖一台亏半台,激光雷达第一股禾赛隐忧仍在
作者 | 感知君Alex 编辑 | 王博2月9日晚,禾赛在万众瞩目下登陆纳斯达克,发行价19美元每股,首日涨超11%,市值超过Luminar,登顶全球市值最高的激光雷达公司。 随后两个交易日,其股价均有不同程度的涨幅&#…...
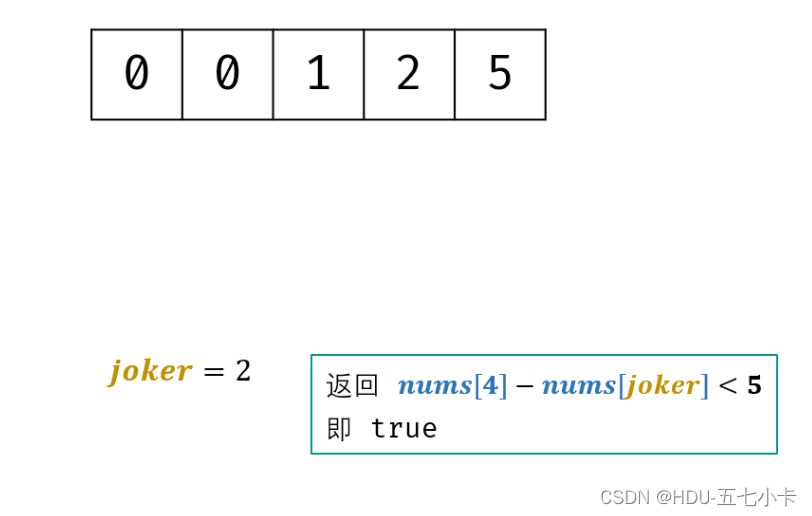
面试题61. 扑克牌中的顺子
题目 从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视…...
有特别有创意的网站设计案例
有人说 UI 设计师集艺术性与科学性于一身,不仅需要对工具的使用熟练,更需要对美术艺术有一定的基础了解。如果想要成为优秀的 UI 设计师是一个需要磨砺的过程,需要不断的学习和积累,多看多练多感受,其中对于优质的设计…...

Python基础-数据类型之列表
一、列表的定义 name ["小明", "小红", "笑笑"] 二、列表的使用 除了序列中的操作,列表还有一些其他的操作。 (1)不使用列表方法对列表进行修改 1:通过索引修改列表中的值 name ["Kit…...
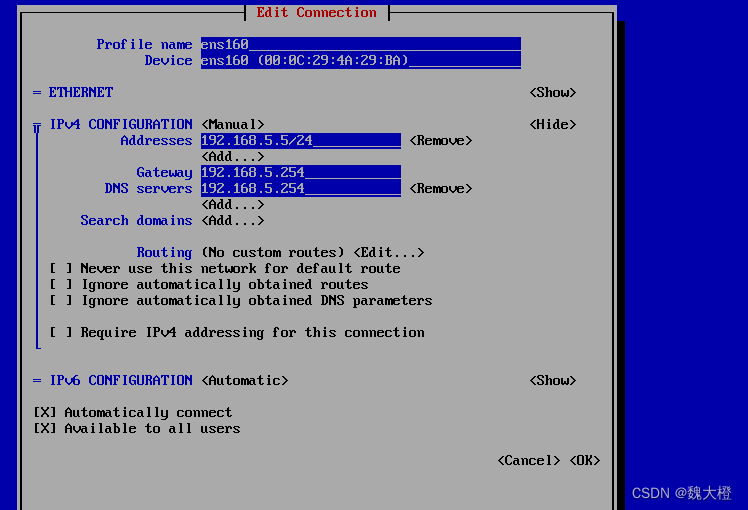
Linux系统基本设置:网络设置(三种界面网络地址配置)
网络地址配置:图形界面配置、命令行界面配置、文本图形界面配置 命令行界面配置 查看网络命令: 想要知道你有多少网卡,都可以通过这两个命令来查看 手动设置网络参数,我们可以使用nmcli这个命令来设置,我们需要知道…...
:查询性能分析)
MySQL(二):查询性能分析
文章目录一、使用explain进行分析二、如何优化数据的访问三、如何重构大查询一、使用explain进行分析 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。 比较重要的字段有: select_type : 查询类型,有…...
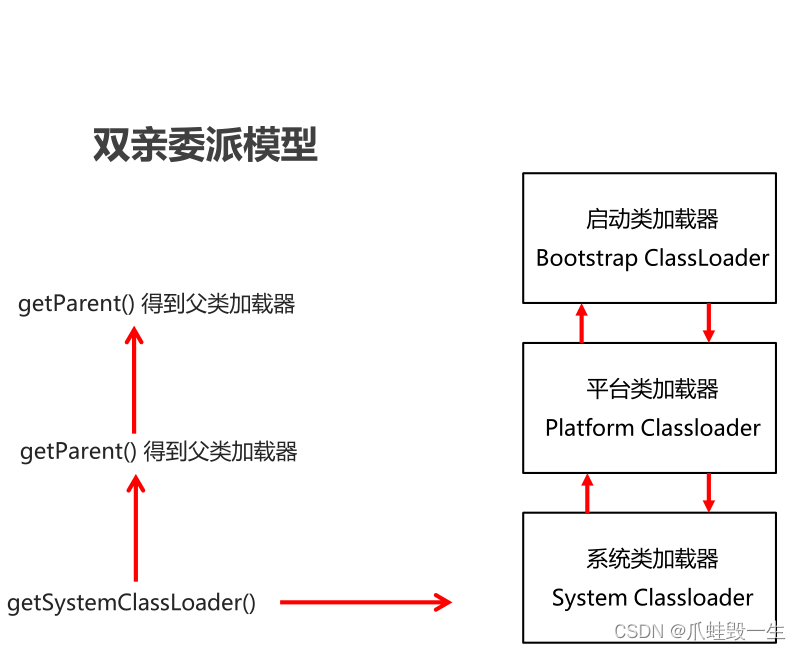
Java基础-类加载器
写在前面的话: 基础加强包含了: 反射,动态代理,类加载器,xml,注解,日志,单元测试等知识点 其中最难的是反射和动态代理,其他知识点都非常简单 由于B站P数限制,…...
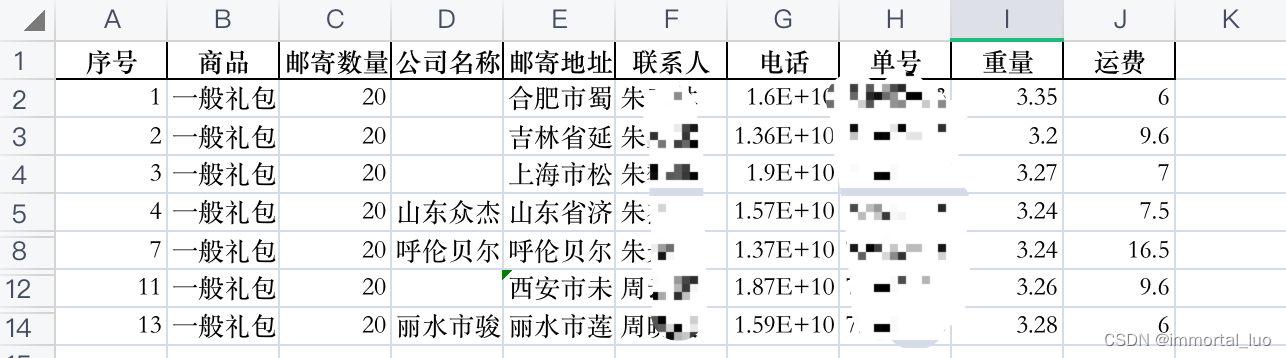
Python 使用pandas处理Excel —— 快递订单处理 数据匹配 邮费计算
问题背景 有表A,其数据如下 关键信息是邮寄地址和单号。 表B: 关键信息是运单号和重量 我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。 在表A中新增一列重量,将刚才查到的…...
【黑马SpringCloud(7)】分布式事务
分布式事务事务的ACID原则分布式事务理论基础CAP定理BASE理论Seataseata的部署seata的集成事务模式XA模式Seata的XA模型优缺点实现XA模式AT模式案例:AT模式更新数据脏写问题优缺点实现AT模式TCC模式流程分析Seata的TCC模型事务悬挂和空回滚实现TCC模式优缺点SAGA模式…...
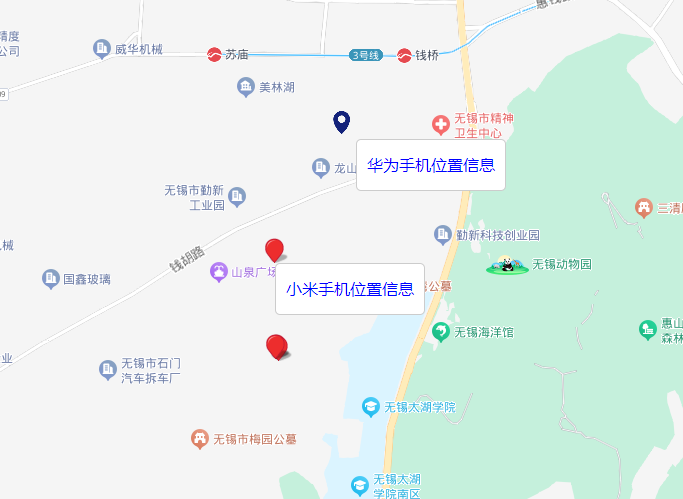
百度地图API添加自定义标记解决单html文件跨域
百度地图API添加自定义标记解决单html文件跨域 因为要往百度地图上添加一些标注点,而且这些标注点要用自定义的图片,而且只能使用单html文件,不能使用服务器(也别问为什么,就是这么个需求),做起…...

SecGPT-14B作品分享:自动生成OWASP ASVS 4.0合规检查清单与测试用例
SecGPT-14B作品分享:自动生成OWASP ASVS 4.0合规检查清单与测试用例 1. SecGPT-14B简介 SecGPT是由云起无垠推出的开源大语言模型,专门针对网络安全领域设计开发。该模型于2023年正式发布,旨在通过人工智能技术提升安全防护的效率和效果。 …...

STM32F103C8T6轻量级学习板硬件设计解析
1. 项目概述STM32F103C8T6“芙宁娜轻涟”开发板是一款面向嵌入式学习与快速原型验证的紧凑型ARM Cortex-M3硬件平台。该板以意法半导体(STMicroelectronics)主流入门级MCU STM32F103C8T6为核心,兼顾功能完整性、电气鲁棒性与物理可制造性&…...

Figo义商本体论AI人格测评问卷的技术构建与工程化实践
义商本体论AI人格测评问卷的技术构建与工程化实践 作者:Figo Cheung, Figo AI Team 一、引言:从"规则约束"到"人格培育"的AI伦理转向 当前AI伦理研究多聚焦于"价值对齐"的外部规则设计,通过预设禁忌清单实现行为合规&…...

C语言高级编程_动态内存池管理器
这段代码实现了一个**动态内存池管理器**,其核心设计理念是通过集中化管理多个动态分配的内存块,实现批量分配与统一释放的自动化内存管理机制。下面从数据结构设计、函数实现逻辑、技术优势及潜在风险四个维度进行深度解析。### 一、数据结构架构分析c …...

如何使用 Git 分支管理、代码合并与 Code Review 流程,保障团队协作规范。
一、Git 分支管理规范(业界主流实践)首先要建立清晰的分支模型,推荐使用 Git Flow 简化版(兼顾规范与易用性),适合大多数中小团队:1. 分支命名与用途分支类型命名规范用途主分支main/master生产…...

ComfyUI工作流集成:SenseVoice-Small语音识别驱动AI图像生成
ComfyUI工作流集成:SenseVoice-Small语音识别驱动AI图像生成 你有没有想过,有一天动动嘴皮子,就能让电脑把你脑海里的画面画出来?比如,你对着麦克风说“一只戴着宇航员头盔的橘猫,在月球上喝咖啡”&#x…...

数据可视化实战 | Tableau数据建模与预处理技巧全解析
1. 为什么Tableau是数据可视化的首选工具 我第一次接触Tableau是在五年前的一个电商数据分析项目上。当时团队用Excel处理几十万行订单数据,每次刷新数据都要等上十分钟。直到项目经理扔给我一个Tableau安装包,说"试试这个"——那感觉就像从自…...

Tesseract OCR完全掌握指南:从入门到实战的全方位解析
Tesseract OCR完全掌握指南:从入门到实战的全方位解析 【免费下载链接】tesseract Tesseract Open Source OCR Engine (main repository) 项目地址: https://gitcode.com/gh_mirrors/tes/tesseract 一、认知篇:揭开OCR引擎的神秘面纱 什么是Tess…...

3小时漫画全流程:AI驱动的创作革命
3小时漫画全流程:AI驱动的创作革命 【免费下载链接】TaleStreamAI AI小说推文全自动工作流,自动从ID到视频 项目地址: https://gitcode.com/gh_mirrors/ta/TaleStreamAI 你是否曾遇到这样的困境:脑海中充满精彩的漫画故事,…...

Qwen1.5-1.8B GPTQ企业级应用:基于.NET框架的智能文档处理系统
Qwen1.5-1.8B GPTQ企业级应用:基于.NET框架的智能文档处理系统 想象一下,你的团队每天要处理成百上千份合同、报告和邮件。人工阅读、摘要、提取关键信息,不仅耗时费力,还容易出错。如果有一个系统,能像一位不知疲倦的…...