XXL-JOB分布式任务调度框架(一)-基础入门

文章目录
- 1.什么是任务调度
- 2.常见定时任务方案
- 2.1. 传统定时任务方案示例
- 2.2. 缺点分析
- 3.什么是分布式任务调度?
- 3.1. 并行任务调度
- 3.2. 高可用
- 3.3. 弹性扩容
- 3.4. 任务管理与监测
- 4.市面上常见的分布式任务调度产品
- 5.初识xxl-job
- 6.xxl-job架构设计
- 6.1.设计思想
- 6.2.架构设计图
- 7.环境搭建
- 7.1.调度中心环境要求
- 7.2.源码仓库地址
- 7.3.初始化“调度数据库”
- 7.4.编译源码
- 7.5.配置部署“调度中心”
- 8.入门案例编写
- 8.1.搭建springboot项目(执行器)
- 8.2.配置执行器
- 8.3.测试
1.什么是任务调度
我们可以先思考一下业务场景的解决方案:
- 某电商系统需要在每天上午10点,下午3点,晚上8点发放一批优惠券。
- 某银行系统需要在信用卡到期还款日的前三天进行短信提醒。
- 某财务系统需要在每天凌晨0:10结算前一天的财务数据,统计汇总。
- 12306会根据车次的不同,设置某几个时间点进行分批放票。
以上业务场景的解决方案就是任务调度。
任务调度是指系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力,而是由系统自动去执行任务。
2.常见定时任务方案
-
While + Sleep : 通过循环加休眠的方式定时执行
-
Timer和TimerTask实现 :JDK自带的定时任务,可以实现简单的间隔执行任务(在指定时间点执行某一任务,也能定时的周期性执行),无法实现按日历去调度执行任务。
-
ScheduledExecutorService : Java并发包下,JDK1.5出现,是比较理想的定时任务实现方案。Eureka就使用的是它
-
QuartZ: 使用Quartz,它是一个异步任务调度框架,功能丰富,可以实现按日历调度,支持持久化。
-
Spring Task,Spring 3.0后提供Spring Task实现任务调度,支持按日历调度,相比Quartz功能稍简单,但是在开发基本够用,支持注解编程方式。
-
SpringBoot中的Schedule : 通过
@EnableScheduling+@Scheduled最实现定时任务,底层使用的是Spring Task
2.1. 传统定时任务方案示例
spring框架中默认就支持了一个任务调度,spring-task
(1)创建一个工程:spring-task-demo
pom文件
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.5.RELEASE</version></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency></dependencies>
(2)引导类
在启动类上使用@EnableScheduling注解,表示开启定时任务
@SpringBootApplication
@EnableScheduling
public class TaskApplication {public static void main(String[] args) {SpringApplication.run(TaskApplication.class,args);}
}
(3)编写案例
根据业务需要,在方法上使用@Scheduled注解,cron属性配置定时规则
@Component
public class ScheduledTask {private final static Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Scheduled(cron = "0/10 * * * * ?") //每10秒执行一次public void scheduledTaskByCorn() {logger.info("定时任务开始 ByCorn:" + new Date());scheduledTask();logger.info("定时任务结束 ByCorn:" + new Date());}private void scheduledTask() {try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}
}
(4)运行
启动项目就可以看控制台看到定时任务执行效果

2.2. 缺点分析
上述的定时任务都是集中式(单体项目使用)的定时任务,在分布式中将会面临一些问题或不足
- 不支持集群:集群情况下容易造成任务重复问题
- 不支持失败重试:失败即结束,不支持重试
- 不支持动态调整:修改任务参数时需要修改代码,并且要重启服务
- 无报警机制:任务失败后没有提醒功能
- 无统一管理:没有办法手动关闭或开启任务
3.什么是分布式任务调度?
当前软件的架构已经开始向分布式架构转变,将单体结构拆分为若干服务,服务之间通过网络交互来完成业务处理。在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
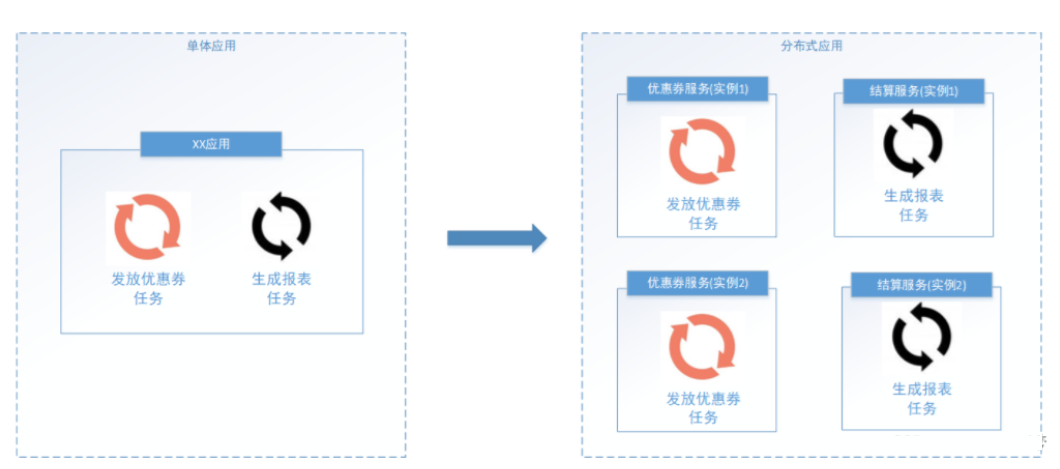
将任务调度程序分布式构建,这样就可以具有分布式系统的特点,并且提高任务的调度处理能力:
3.1. 并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。
3.2. 高可用
若某一个实例宕机,不影响其他实例来执行任务。
3.3. 弹性扩容
当集群中增加实例就可以提高并执行任务的处理效率。
3.4. 任务管理与监测
对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
4.市面上常见的分布式任务调度产品
针对分布式任务调度的需求,市场上出现了很多的产品:
1) TBSchedule:淘宝推出的一款非常优秀的高性能分布式调度框架,目前被应用于阿里、京东、支付宝、国美等很多互联网企业的流程调度系统中。但是已经多年未更新,文档缺失严重,缺少维护。
2) XXL-Job:大众点评的分布式任务调度平台,是一个轻量级分布式任务调度平台, 其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
3)Elastic-job:当当网借鉴TBSchedule并基于quartz 二次开发的弹性分布式任务调度系统,功能丰富强大,采用zookeeper实现分布式协调,具有任务高可用以及分片功能。
4)Saturn: 唯品会开源的一个分布式任务调度平台,基于Elastic-job,可以全域统一配置,统一监控,具有任务高可用以及分片功能。
5.初识xxl-job
XXL-JOB是一个开源的,具有丰富的任务管理功能以及高性能,高可用等特点的轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展、开箱即用!!!
于2015问世,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。其具备且不止如下能力:
-
简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
-
动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
-
调度中心HA(中心式):调度采用中心式设计,“调度中心”基于集群Quartz实现并支持集群部署,可保证调度中心HA;执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
-
弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
-
路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
-
故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
-
任务失败告警:默认提供邮件方式失败告警,同时预留扩展接口,可方面的扩展短信、钉钉等告警方式;
源码地址:https://gitee.com/xuxueli0323/xxl-job
文档地址:https://www.xuxueli.com/xxl-job/
6.xxl-job架构设计
6.1.设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
6.2.架构设计图
xxl-job分为 调度中心和执行器两大模块
调度模块(调度中心): 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
执行模块(执行器): 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等
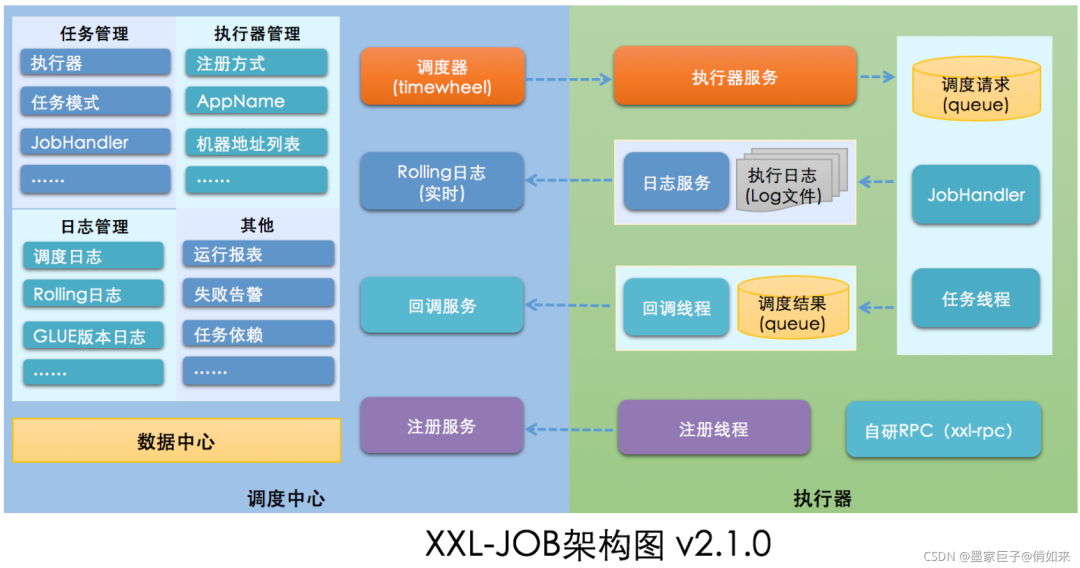
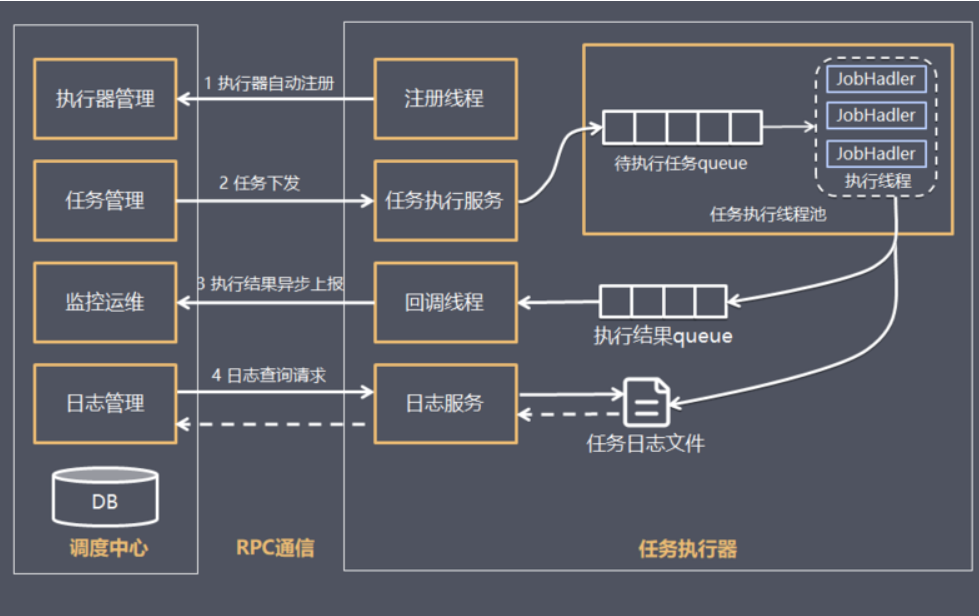
调度中心:负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。
任务执行器:负责接收调度请求并执行任务逻辑。
任务:专注于任务的处理。
调度中心会发出调度请求,任务执行器接收到请求之后会去执行任务,任务则专注于任务业务的处理。
7.环境搭建
7.1.调度中心环境要求
- Maven3+
- Jdk1.8+
- Mysql5.7+
7.2.源码仓库地址
- github: https://github.com/xuxueli/xxl-job
- gitee: http://gitee.com/xuxueli0323/xxl-job
7.3.初始化“调度数据库”
请下载项目源码并解压,获取 “调度数据库初始化SQL脚本” 并执行即可。
位置:/xxl-job/doc/db/tables_xxl_job.sql 共8张表
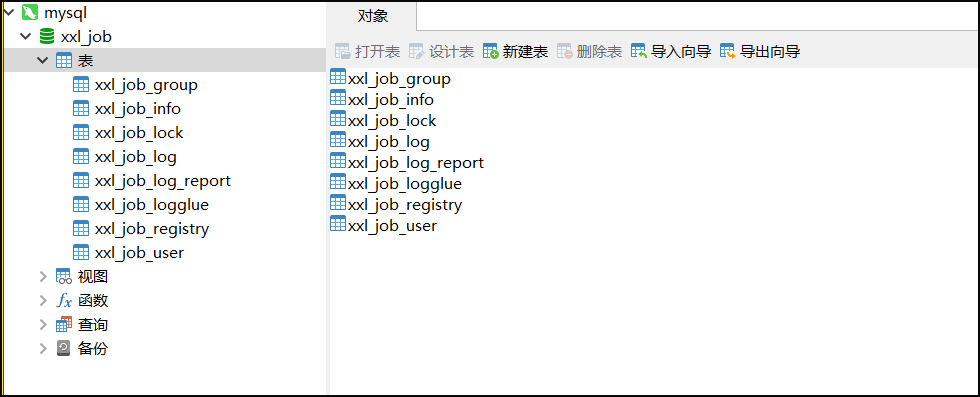
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表:用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表:用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例; 如果mysql做主从,调度中心集群节点务必强制走主库;
7.4.编译源码
解压源码,按照maven格式将源码导入IDE, 使用maven进行编译即可,源码结构如下:

- doc :文档,即SQL脚本所在目录
- db : “调度数据库”建表脚本
- xxl-job-admin : 调度中心项目源码
- xxl-job-core : 核心模块,公共Jar依赖
- xxl-job-executor-samples : 执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
7.5.配置部署“调度中心”
调度中心项目:xxl-job-admin
作用:统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平
台。
步骤一:调度中心配置
调度中心配置文件地址:/xxl-job/xxl-job-admin/src/main/resources/application.properties
数据库的连接信息修改为自己的数据库
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.############# mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000### xxl-job, email
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.from=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory### xxl-job, access token
xxl.job.accessToken=default_token### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100### xxl-job, log retention days
xxl.job.logretentiondays=30
步骤二:部署项目
如果已经正确进行上述配置,可将项目编译打包部署。这是一个springboot项目,也可以在idea中直接启动.
调度中心访问地址:http://localhost:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
用户名和密码:admin/123456
至此“调度中心”项目已经部署成功。
8.入门案例编写
8.1.搭建springboot项目(执行器)
新建项目:在test模块下新建xxl-job-demo子模块
(1)pom文件
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--xxl-job--><dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.3.0</version></dependency></dependencies>
(2)配置有两个,一个是application.yml,另外一个是日志配置:logback.xml
# web port
server.port=8881
# no web
#spring.main.web-environment=false# log config
logging.config=classpath:logback.xml### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin### xxl-job, access token
xxl.job.accessToken=default_token### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-test
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30检查执行器中appname是否为:xxl_job_sharding_sample
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds"><contextName>logback</contextName><property name="log.path" value="/data/applogs/xxl-job/xxl-job-executor-sample-springboot.log"/><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern></rollingPolicy><encoder><pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n</pattern></encoder></appender><root level="info"><appender-ref ref="console"/><appender-ref ref="file"/></root></configuration>(3)引导类:
package com.xxl.job;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class XxlJobApplication {public static void main(String[] args) {SpringApplication.run(XxlJobApplication.class,args);}
}(4)添加xxl-job配置
添加配置类:
这个类主要是创建了任务执行器,参考官方案例编写,无须改动
package com.xxl.job.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}
}(5)创建任务
package com.xxl.job.config;import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;import java.time.LocalDateTime;@Component
public class HelloJob {@Value("${server.port}")private String port;@XxlJob("demoJobHandler")public ReturnT helloJob() {System.out.println("简单任务执行了。。。。" + port);return ReturnT.SUCCESS;}
}@XxlJob(“demoJobHandler”)这个一定要与调度中心新建任务的JobHandler的值保持一致!
8.2.配置执行器
在任务调度中心,点击进入"执行器管理"界面, 如下图:
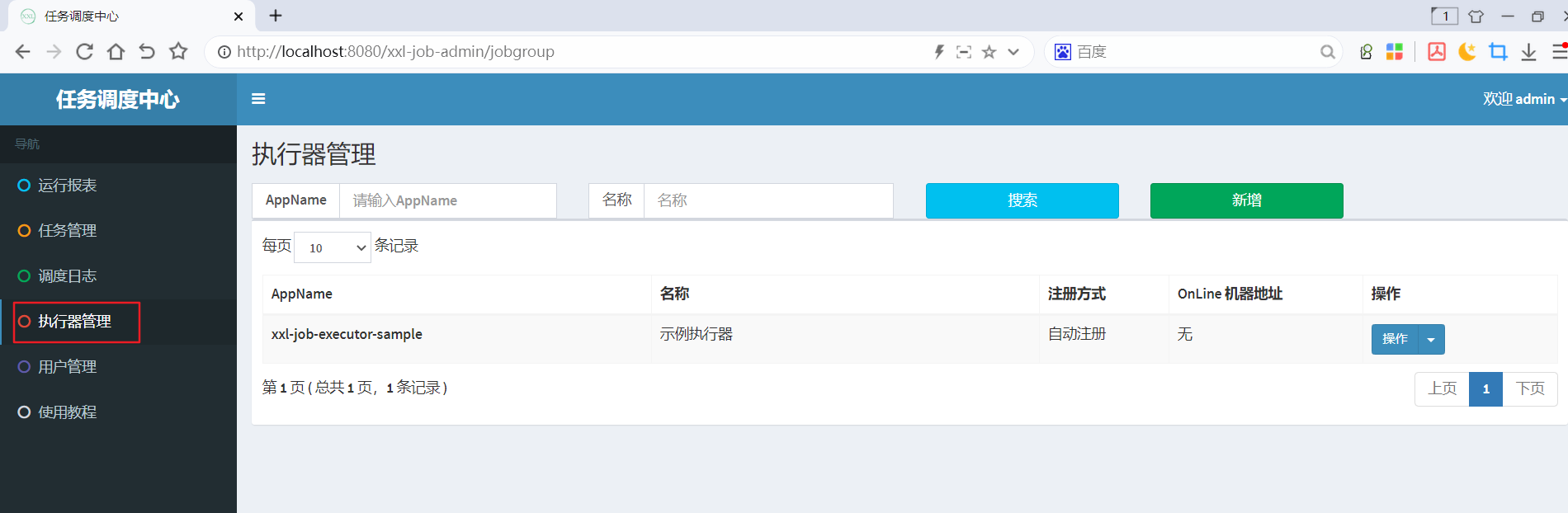
1、此处的AppName,会在创建任务时被选择,每个任务必然要选择一个执行器。
2、“执行器列表” 中显示在线的执行器列表, 支持编辑删除。
以下是执行器的属性说明:
| 属性名称 | 说明 |
|---|---|
| AppName | 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用; |
| 名称 | 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性; |
| 排序 | 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表; |
| 注册方式 | 调度中心获取执行器地址的方式; |
| 机器地址 | 注册方式为"手动录入"时有效,支持人工维护执行器的地址信息; |
具体操作:
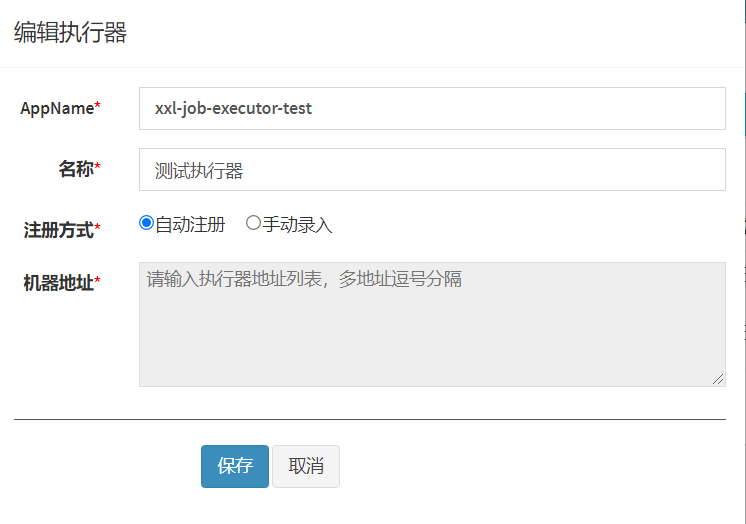
(1)新增执行器: xxl-job-executor-test
(2)在调度中心新建任务
在任务管理->新建,填写以下内容
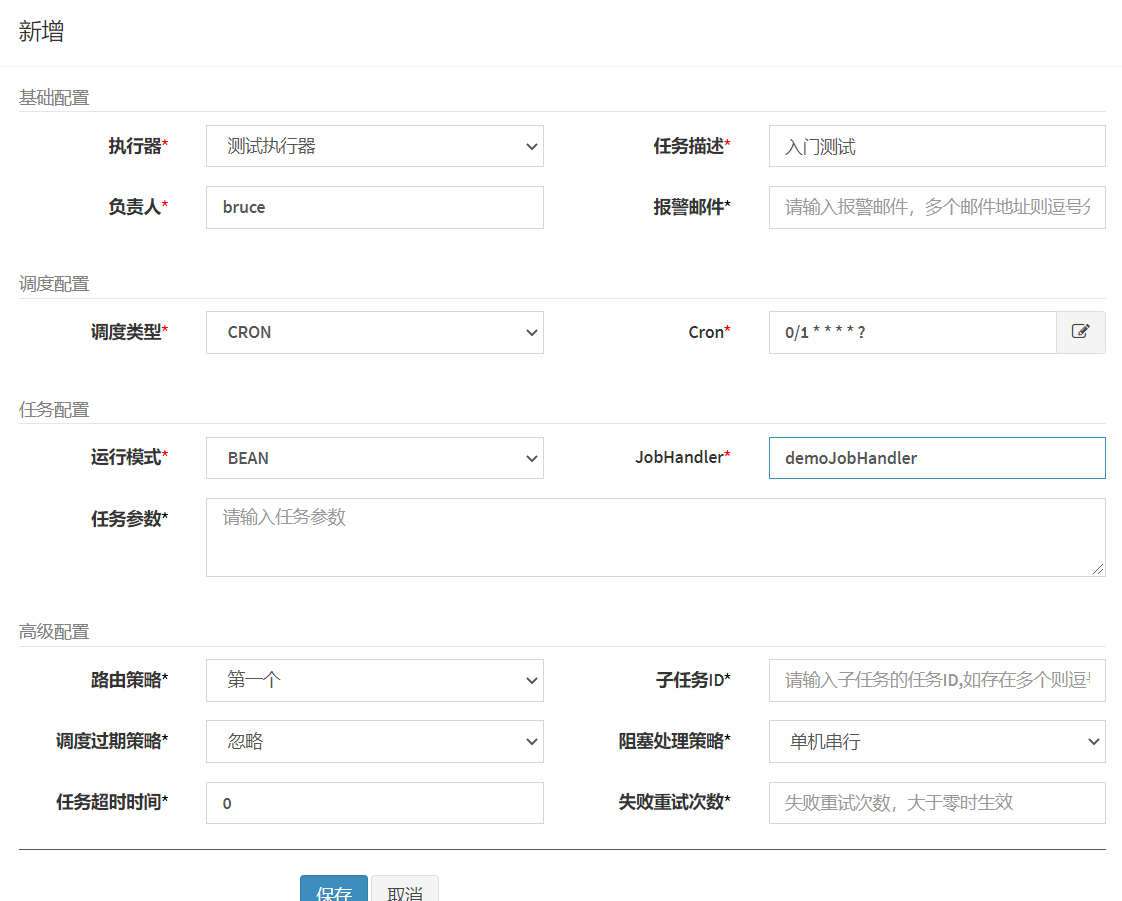
8.3.测试
(1)首先启动调度中心,xxl-job-admin
(2)启动xxl-job-demo项目
(3)启动任务:任务调度中心
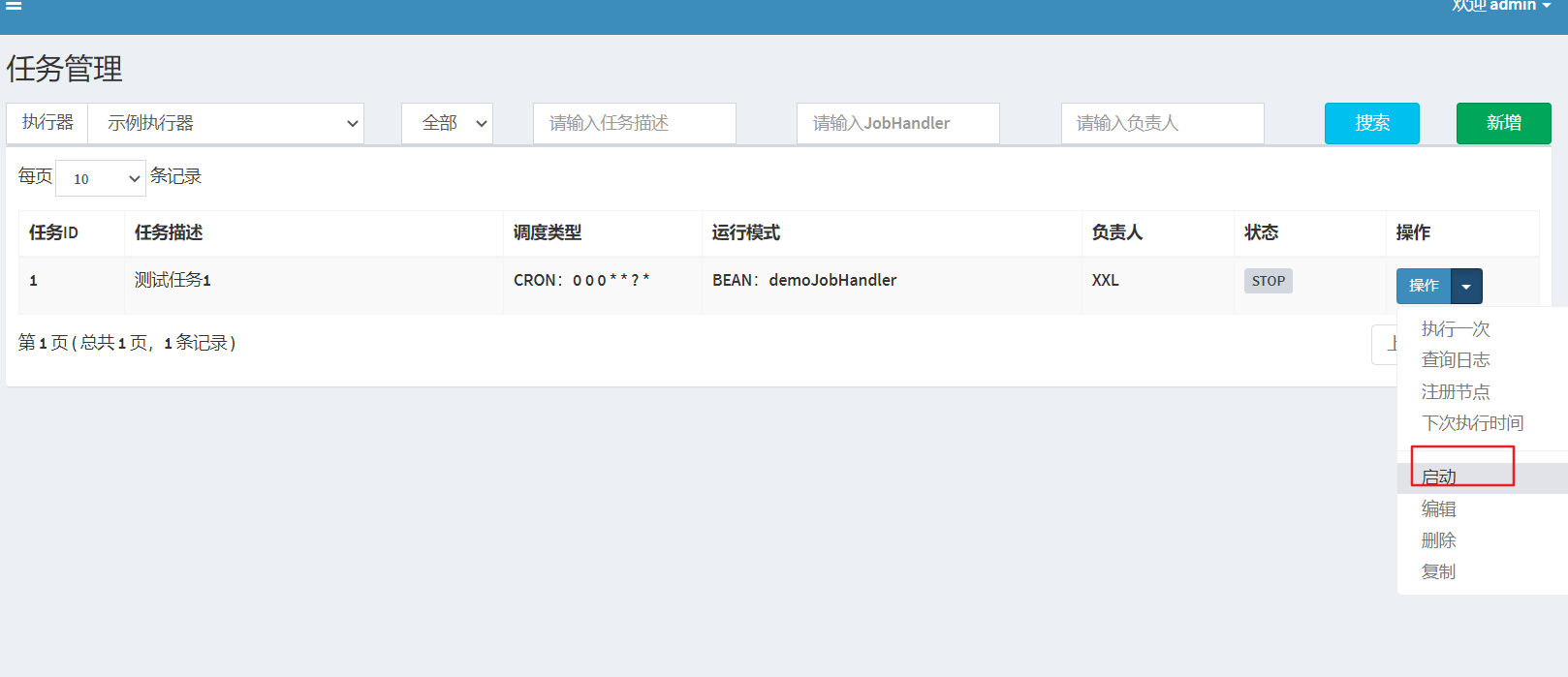
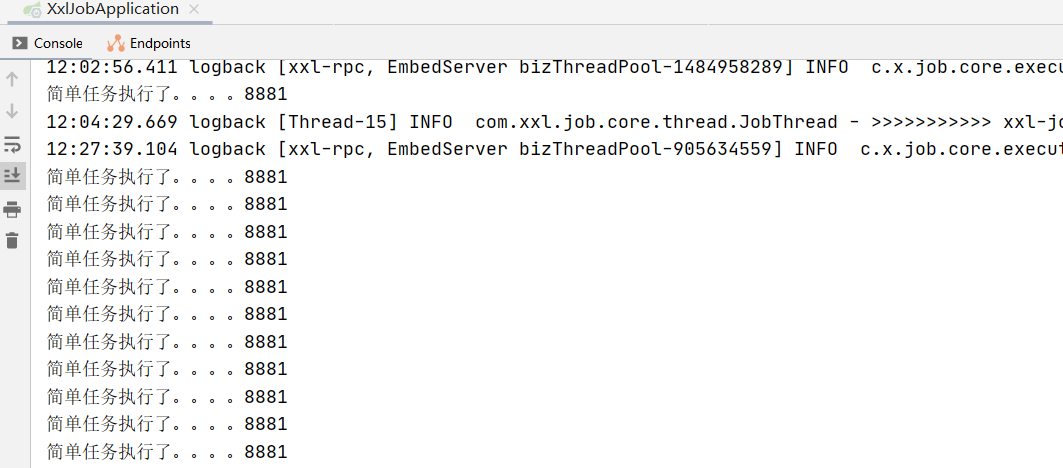
(4)打开idea控制台,查看任务执行情况:
相关文章:
XXL-JOB分布式任务调度框架(一)-基础入门
文章目录1.什么是任务调度2.常见定时任务方案2.1. 传统定时任务方案示例2.2. 缺点分析3.什么是分布式任务调度?3.1. 并行任务调度3.2. 高可用3.3. 弹性扩容3.4. 任务管理与监测4.市面上常见的分布式任务调度产品5.初识xxl-job6.xxl-job架构设计6.1.设计思想6.2.架构…...

基于CentOS 7 搭建Redis 7集群
我们的目标是使用2台(多台服务器类似)服务器搭建一个3主3从的redis集群。 我们为什么要使用redis 7呢?因为6、7的版本都做了大量优化,比如6引入了多线程(一些JAVA八股文面试还喜欢问redis为什么是单线程)&…...

Lesson5.3---Python 之 NumPy 统计函数、数据类型和文件操作
一、统计函数 NumPy 能方便地求出统计学常见的描述性统计量。最开始呢,我们还是先导入 numpy。 import numpy as np1. 求平均值 mean() mean() 是默认求出数组内所有元素的平均值。我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止…...
Puppeteer 爬虫学习
puppeteer简介: Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议 控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行, 但是可以通过修改配置文件运行“有头”模式。能作什么?: 生成…...
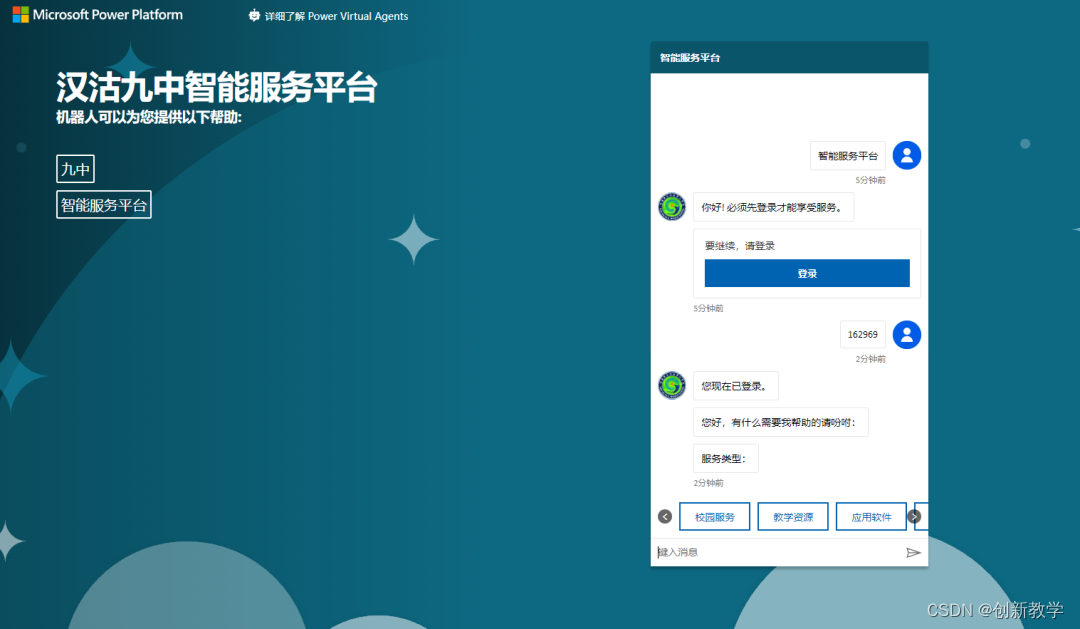
如何在Power Virtual Agents中实现身份验证
今天我们介绍一下如何通过身份验证的方式来使用Power Virtual Agents。首先进入“Microsoft 365-管理-Azure Active Directory管理中心”。 进入“Azure Active Directory管理中心”后选择“Azure Active Directory”中的“应用注册”-“新注册”。 输入新创建的应用程序名称后…...

金三银四必备软件测试必问面试题
初级软件测试必问面试题1、你的测试职业发展是什么?测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前 3 年积累测试经验,按如何做好测试工程…...
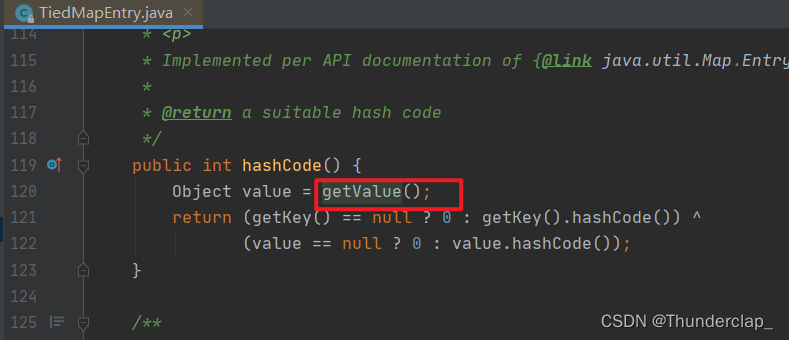
Java反序列化漏洞——CommonsCollections6链分析
一、前因因为在jdk8u71之后的版本中,sun.reflect.annotation.AnnotationInvocationHandler#readObject的逻辑发生了变化,导致CC1中的两个链条都不能使用,所有我们需要找一个在高版本中也可用的链条。/* Gadget chain: java.io.ObjectInputStr…...

Selenium浏览器自动化测试框架
Selenium浏览器自动化测试框架 目录:导读 1、selenium简介 介绍 功能 优势 2、基本使用 3、获取单节点 4、获取多节点 5、节点交互 6、动作链 7、执行JavaScript代码 8、获取节点信息 9、切换frame 10、延时等待 11、前进和后退 12、cookies 13、选…...
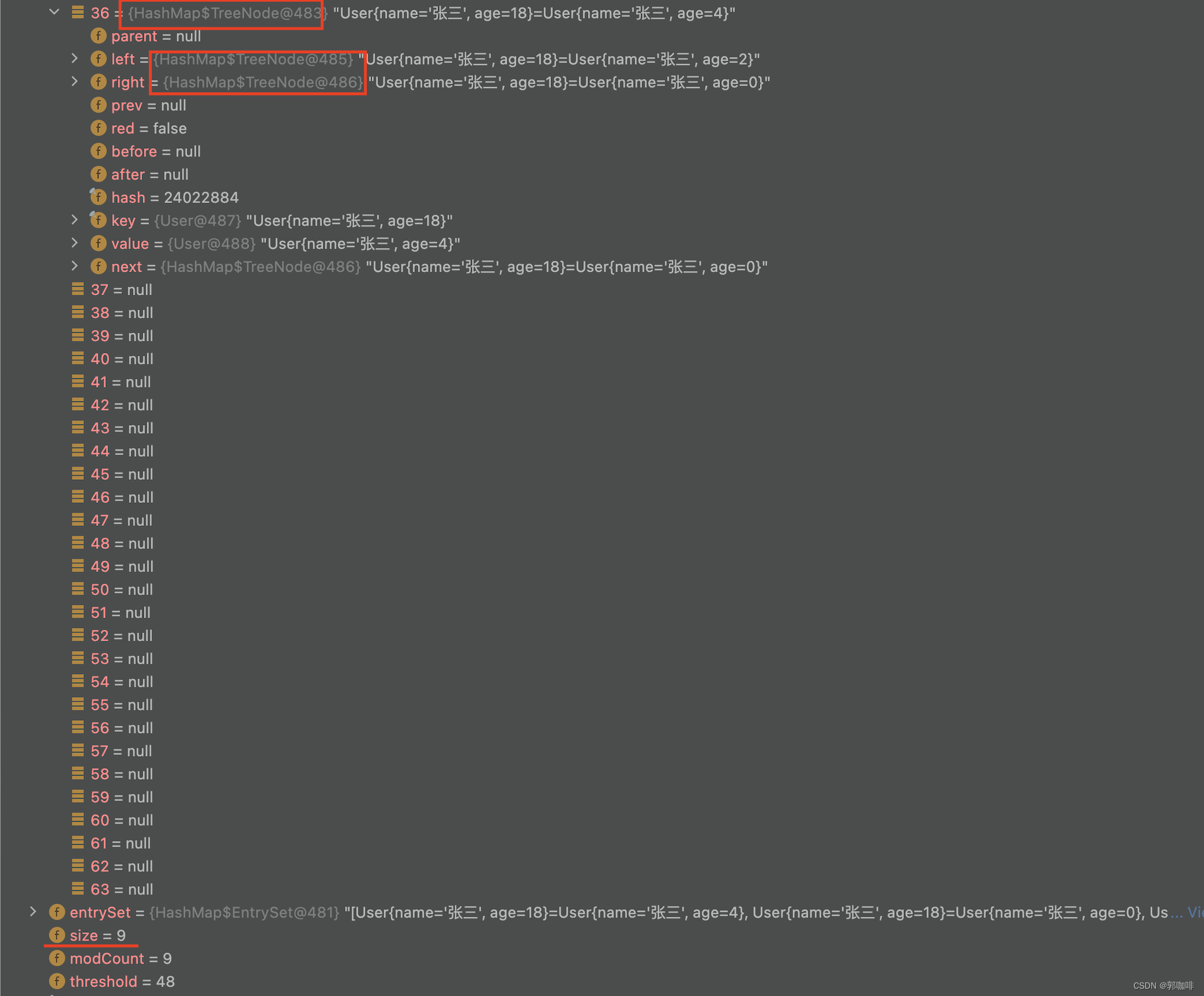
Hashmap链表长度大于8真的会变成红黑树吗?
1、本人博客《HashMap、HashSet底层原理分析》 2、本人博客《若debug时显示的Hashmap没有table、size等元素时,查看第19条》 结论 1、链表长度大于8时(插入第9条时),会触发树化(treeifyBin)方法,但是不一定会树化,若数组大小小于…...

关于接地:数字地、模拟地、信号地、交流地、直流地、屏蔽地、浮地
除了正确进行接地设计、安装,还要正确进行各种不同信号的接地处理。控制系统中,大致有以下几种地线: (1)数字地:也叫逻辑地,是各种开关量(数字量)信号的零电位。 (2&am…...

排序
一、数据流中的中位数题目描述:如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。…...
Android DataStore Proto存储接入流程详解与使用
一、介绍 通过前面的文字,我们已掌握了DataStore 的存储,但是留下一个尾巴,那就是Proto的接入。 Proto是什么? Protobuf,类似于json和xml,是一种序列化结构数据机制,可以用于数据通讯等场景&a…...

HiEV洞察 | 卖一台亏半台,激光雷达第一股禾赛隐忧仍在
作者 | 感知君Alex 编辑 | 王博2月9日晚,禾赛在万众瞩目下登陆纳斯达克,发行价19美元每股,首日涨超11%,市值超过Luminar,登顶全球市值最高的激光雷达公司。 随后两个交易日,其股价均有不同程度的涨幅&#…...
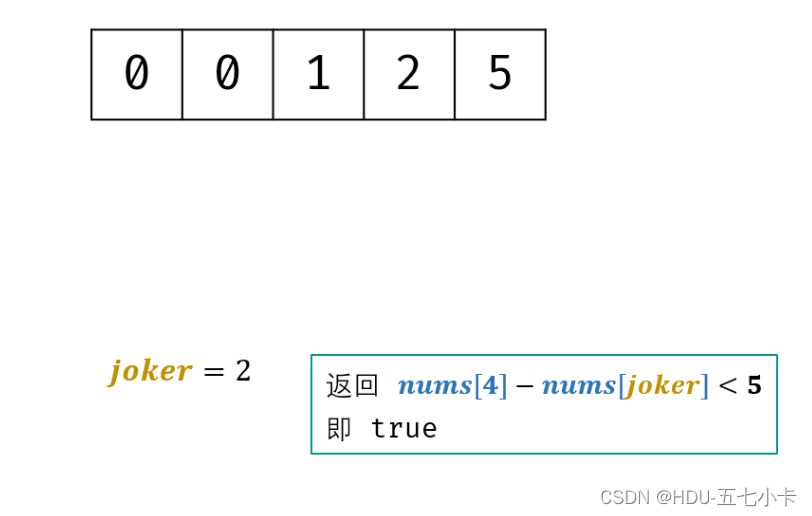
面试题61. 扑克牌中的顺子
题目 从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视…...
有特别有创意的网站设计案例
有人说 UI 设计师集艺术性与科学性于一身,不仅需要对工具的使用熟练,更需要对美术艺术有一定的基础了解。如果想要成为优秀的 UI 设计师是一个需要磨砺的过程,需要不断的学习和积累,多看多练多感受,其中对于优质的设计…...

Python基础-数据类型之列表
一、列表的定义 name ["小明", "小红", "笑笑"] 二、列表的使用 除了序列中的操作,列表还有一些其他的操作。 (1)不使用列表方法对列表进行修改 1:通过索引修改列表中的值 name ["Kit…...
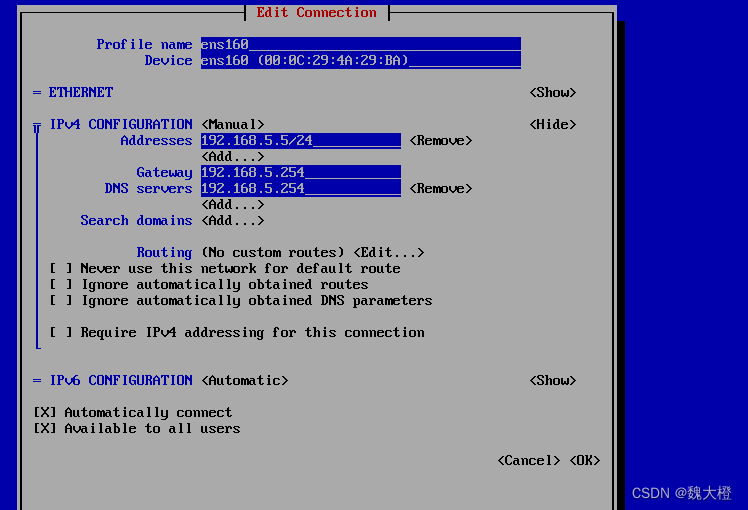
Linux系统基本设置:网络设置(三种界面网络地址配置)
网络地址配置:图形界面配置、命令行界面配置、文本图形界面配置 命令行界面配置 查看网络命令: 想要知道你有多少网卡,都可以通过这两个命令来查看 手动设置网络参数,我们可以使用nmcli这个命令来设置,我们需要知道…...
:查询性能分析)
MySQL(二):查询性能分析
文章目录一、使用explain进行分析二、如何优化数据的访问三、如何重构大查询一、使用explain进行分析 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。 比较重要的字段有: select_type : 查询类型,有…...
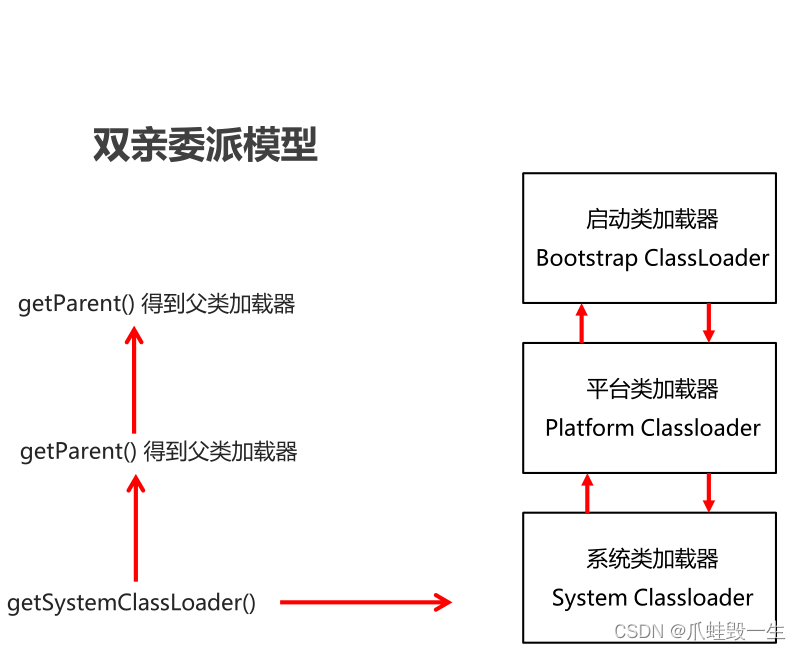
Java基础-类加载器
写在前面的话: 基础加强包含了: 反射,动态代理,类加载器,xml,注解,日志,单元测试等知识点 其中最难的是反射和动态代理,其他知识点都非常简单 由于B站P数限制,…...
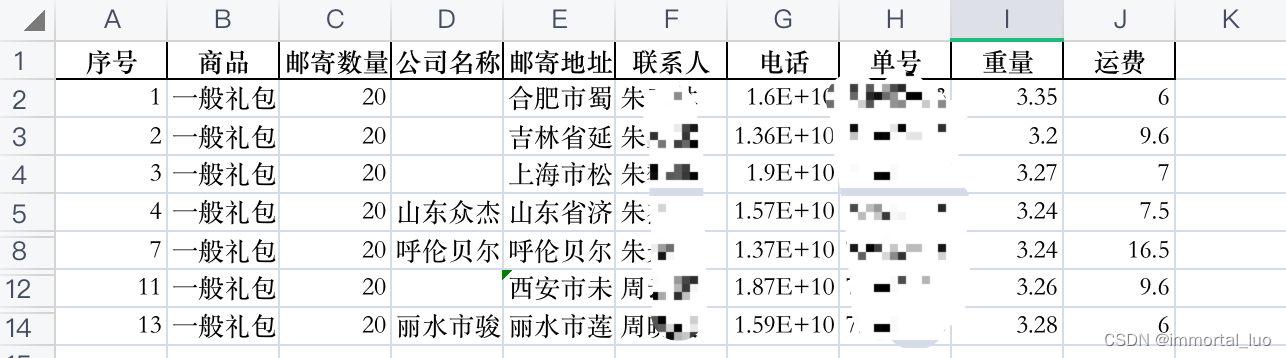
Python 使用pandas处理Excel —— 快递订单处理 数据匹配 邮费计算
问题背景 有表A,其数据如下 关键信息是邮寄地址和单号。 表B: 关键信息是运单号和重量 我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。 在表A中新增一列重量,将刚才查到的…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...
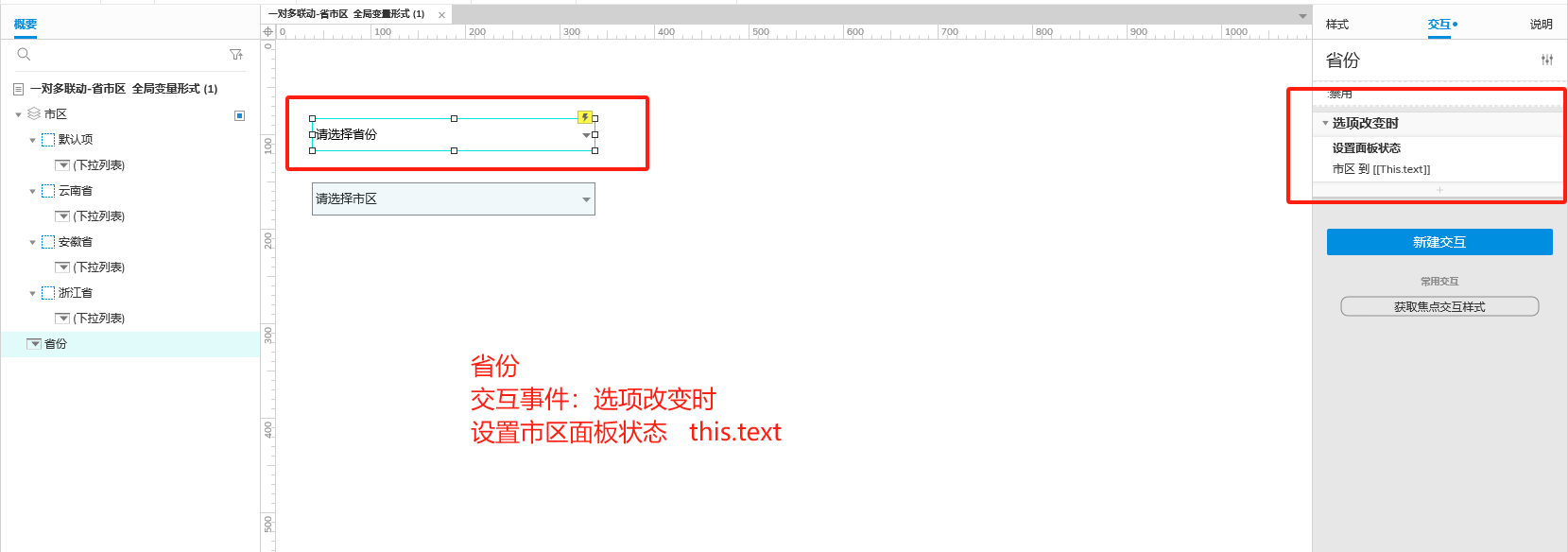
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
如何做好一份技术文档?从规划到实践的完整指南
如何做好一份技术文档?从规划到实践的完整指南 🌟 嗨,我是IRpickstars! 🌌 总有一行代码,能点亮万千星辰。 🔍 在技术的宇宙中,我愿做永不停歇的探索者。 ✨ 用代码丈量世界&…...
项目进度管理软件是什么?项目进度管理软件有哪些核心功能?
无论是建筑施工、软件开发,还是市场营销活动,项目往往涉及多个团队、大量资源和严格的时间表。如果没有一个系统化的工具来跟踪和管理这些元素,项目很容易陷入混乱,导致进度延误、成本超支,甚至失败。 项目进度管理软…...

Qt学习及使用_第1部分_认识Qt---Qt开发基本流程
前言 学以致用,通过QT框架的学习,一边实践,一边探索编程的方方面面. 参考书:<Qt 6 C开发指南>(以下称"本书") 标识说明:概念用粗体倾斜.重点内容用(加粗黑体)---重点内容(红字)---重点内容(加粗红字), 本书原话内容用深蓝色标识,比较重要的内容用加粗倾…...