Elasticsearch进行优化-使用索引拆分(Split)和索引收缩(shrink )
一、索引拆分和收缩的场景
在Elasticsearch集群部署的初期我们可能评估不到位,导致分配的主分片数量太少,单分片的数据量太大,导致搜索时性能下降,这时我们可以使用Elasticsearch提供的Split功能对当前的分片进行拆分,拆分到具有更多主分片的新索引。
而相反的,在数据规模比较大的集群中,可能存在一个数据量很小,但是分片数量非常庞大的索引,而分片的管理依赖于Master节点,一旦分片数量太大,将会降低集群的整体性能,故障恢复也更慢,这时候可以使用Elasticsearch提供的Shrink API降低分片数量。
二、索引拆分
2.1、索引拆分API和拆分逻辑
Elasticsearch提供了Split API,用于将索引拆分到具有更多主分片的新索引。Split API的格式如下:
POST /<index>/_split/<target-index>PUT /<index>/_split/<target-index>
要完成整个Split的操作需要满足以下条件:
- 索引必须是只读的。
- 集群的状态必须是green。
- 目标索引的主分片数量必须大于源索引的主分片数量。
- 处理索引拆分的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
以下API请求可以将索引设置为只读:
curl -X PUT "localhost:9200/my_source_index/_settings?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.blocks.write": true }
}
'
如果当前索引是是一个data stream的写索引,则不允许进行索引拆分,需要对data stream进行回滚,创建一个新的写索引,才可以对当前索引进行拆分。
以下是使用Split API进行索引拆分的请求案例,Split API支持settings和aliases。
curl -X POST "localhost:9200/my-index-000001/_split/split-my-index-000001?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.number_of_shards": 2},"aliases": {"my_alias":{}}
}
'
index.number_of_shards指定的主分片的数量 必须是源分片数量的倍数。
索引拆分可以拆分的分片的数量由参数index.number_of_routing_shards决定,路由分片的数量指定哈希空间,该空间在内部用于以一致性哈希的形式在各个 shard 之间分发文档。 例如,将 number_of_routing_shards 设置为30(5 x 2 x 3)的具有5个分片的索引可以拆分为 以2倍 或 3倍的形式进行拆分。换句话说,可以如下拆分:
5→10→30(拆分依次为2和3)
5→15→30(拆分依次为3和2)
5→30(拆分6)
index.number_of_routing_shards 是一个静态配置,可以在创建索引的时候指定,也可以在关闭的索引上设置。其默认值取决于原始索引中主分片的数量,默认情况下,允许按2的倍数分割最多1024个分片。但是,必须考虑主碎片的原始数量。例如,使用5个主碎片创建的索引可以被分割为10、20、40、80、160、320,或最多640个碎片。
如果源索引只有一个主分片,那么可以被拆分成为任意数量的主分片。
2.2、索引拆分的工作过程
- 创建一个与源索引定义一样的目标索引,并且具有更多的主分片。(注意,是创建了一个新的索引,而并不是在源索引上扩大分片)
- 将段(segment)从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有的段都会被复制到新的索引中,这是一个非常耗时的过程。)
- 对所有的文档进行重新散列。
- 目标索引进行Recover。
2.3、为什么不支持在源索引上增加增量分片?
我们知道其实大多数的键值存储都支持随着数据的增长实现自动分片的自动扩展。但是为什么Elasticsearch不支持呢?
其实主要是因为Elasticsearch的底层结构和数据分布逻辑决定的,Elasticsearch需要使用一定的哈希的方法找到数据到底应该存放在哪个分片,这就决定了如果新增一个分片,则需要使用不同的哈希方案重新平衡现有的数据,那么整体的操作就会变得非常复杂。
其他键值存储系统解决这个问题的方案一般是使用一致性哈希,当分片数从N增加到N+1时,一致性哈希只需要对1/N的key进行重新分配。但是Elasticsearch分片的本质实际上是Lucene的索引,而从Lucene索引删除一小部分的数据,通常比键值存储系统的成本要高得多。所以Elasticsearch选择在索引层面上进行拆分,使用硬链接进行高效的文件复制,以避免在索引间移动文档。
对于仅追加数据而没有修改、删除等场景,可以通过创建一个新索引并将新数据推送到该索引,同时添加一个用于读操作的涵盖旧索引和新索引的别名来获得更大的灵活性。假设旧索引和新索引分别有M和N个分片,这与搜索一个有M+N个分片的索引相比没有任何开销。
2.4、如何监控索引拆分的进度
使用Split API进行索引拆分,API正常返回并不意味着Split的过程已经完成,这仅仅意味着创建目标索引的请求已经完成,并且加入了集群状态,此时主分片可能还未被分配,副本分片可能还未创建成功。
一旦主分片完成了分配,状态就会转化为initializing,并且开始进行拆分过程,直到拆分过程完成,分片的状态将会变成active。
可以使用_cat recovery API来监控Split进程,或者可以使用集群健康API通过将wait_for_status参数设置为黄色来等待所有主分片分配完毕。
三、索引收缩
3.1、索引收缩API和收缩逻辑
对于索引分片数量,我们一般在模板中统一定义,在数据规模比较大的集群中,索引分片数一般也大一些,在我的集群中设置为 24。但是,并不是所有的索引数据量都很大,这些小数据量的索引也同样有较大的分片数。在 elasticsearch 中,主节点管理分片是很大的工作量,降低集群整体分片数量可以降低 recovery 时间,减小集群状态的大小。很多时候,冷索引不会再有数据写入,此时,可以使用 shrink API 缩小索引分配数。缩小完成后,源索引可删除。
shrink API 是 ES5.0之后提供的新功能,他并不对源索引进行操作,他使用与源索引相同的配置创建一个新索引,仅仅降低分片数。由于添加新文档时使用对分片数量取余获取目的分片的关系,原分片数量是新分片倍数。如果源索引的分片数为素数,目标索引的分片数只能为1.
将现有索引缩小为具有更少主分片的新索引,一个索引要能够被shrink进行缩小,需要满足以下三个条件:
- 索引是可读的
- 索引中每个分片的副本必须位于同一个节点上。(注意,“所有分片副本”不是指索引的全部分片,无论主分片还是副分片,满足任意一个就可以,分配器也不允许将主副分片分配到同一节点。所以可以是删除了所有的副本分片,也可以是把所有的副本分片全部放在同一个节点上。)
- 索引的状态必须为green
为了使分片分配更容易,可以先删除索引的复制分片,等完成了shrink操作以后再重新添加复制分片。
可以使用以下代码,实现删除所有的副本分片,将所有的主分片分配到同一个节点上,并且设置索引状态为只读:
curl -X PUT "localhost:9200/my_source_index/_settings?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.number_of_replicas": 0, "index.routing.allocation.require._name": "shrink_node_name", "index.blocks.write": true }
}
'
重新分配源索引的分片可能需要一段时间,可以使用_cat API跟踪进度,或者使用集群健康API通过wait_for_no_relocating_shards参数等待所有分片完成重新分配。
当完成以上步骤以后就可以进行shrink操作了,以下为_shrink API的格式:
POST /<index>/_shrink/<target-index>PUT /<index>/_shrink/<target-index>
以下案例将索引my-index-000001缩小主分片到shrunk-my-index-000001索引。
curl -X POST "localhost:9200/my-index-000001/_shrink/shrunk-my-index-000001?pretty"
{"settings": {"index.number_of_replicas": 1,"index.number_of_shards": 1,"index.codec": "best_compression""index.routing.allocation.require._name": null, "index.blocks.write": null }"aliases": {"my_search_indices": {}}
}
收缩索引API允许您将现有索引收缩为主分片更少的新索引。目标索引中请求的主分片数量必须是源索引中主分片数量的一个因子。例如,包含8个主碎片的索引可以收缩为4个、2个或1个主碎片,或者包含15个主碎片的索引可以收缩为5个、3个或1个主碎片。如果索引中的碎片数量是一个质数,那么它只能收缩为一个主分片。在收缩之前,索引中每个分片的一个(主或副本)副本必须存在于同一个节点上。
如果当前索引是是一个data stream的写索引,则不允许进行索引收缩,需要对data stream进行回滚,创建一个新的写索引,才可以对当前索引进行收缩。
3.2、索引收缩的工作过程
整个索引收缩的过程如下:
- 创建一个新的目标索引,其定义与源索引相同,但主分片的数量较少。
- 将段从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有的段都被复制到新的索引中,这是一个非常耗时的过程。此外,如果使用多个数据路径,不同数据路径上的分片需要一个完整的段文件拷贝,如果它们不在同一个磁盘上,因为硬链接不能跨磁盘工作)
- 恢复目标索引
虽然Elasticsearch提供了Split和Shrink API,但是更建议的应该是做好更好的索引创建前的评估工作,因为使用Split和Shrink都有一定的成本。
相关文章:
和索引收缩(shrink ))
Elasticsearch进行优化-使用索引拆分(Split)和索引收缩(shrink )
一、索引拆分和收缩的场景 在Elasticsearch集群部署的初期我们可能评估不到位,导致分配的主分片数量太少,单分片的数据量太大,导致搜索时性能下降,这时我们可以使用Elasticsearch提供的Split功能对当前的分片进行拆分,…...
)
数论 —— 高斯记号(Gauss mark)
定义 数学上,高斯记号(Gauss mark)是指对取整符号和取小符号的统称,用于数论等领域。 设 x∈Rx \in \textbf{R}x∈R,用 [x][x][x] 表示不超过 xxx 的最大整数。也可记作 [x][x][x]。设 x∈Rx \in \textbf{R}x∈R&…...

【随笔】程序员眼中的 CPU,“没有灵魂的躯体”
引言 先引用一段比较有意思的论述: 现实中每个人是由两部分构成,灵魂和躯体,灵魂依附于躯体游走于世间,现实中我们面对的每个人其实面对的是其灵魂而非肉体,肉体不过是表象而已。 灵魂本性乃一恶物,寄生于…...

算法的时间复杂度
算法在编写成可执行程序后,运行时需要消耗时间资源和空间(内存)资源,因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的。 时间复杂度主要衡量一个算法运行的快慢,而空间复杂度主要衡量一个算法运…...
 | 机试题算法思路 【2023】)
华为OD机试 - 叠放书籍(Python) | 机试题算法思路 【2023】
最近更新的博客 华为OD机试 - 寻找路径 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 五键键盘 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - IPv4 地址转换成整数 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 对称美学 | 备考思路,刷题要点,答疑 …...
进程间通信(重点)
概念 进程是一个独立的资源分配单元,不同进程之间的资源是独立的进程并非孤立的,不同进程需要进行信息的交互和状态的传递,因此需要进程之间的通信【IPC: Inter processes communication】 如qq聊天,qq在每个人的手机上是独立的…...
Reverse入门[不断记录]
文章目录前言一、[SWPUCTF 2021 新生赛]re1二、[SWPUCTF 2021 新生赛]re2三、[GFCTF 2021]wordy[花指令]四、[NSSRound#3 Team]jump_by_jump[花指令]五、[NSSRound#3 Team]jump_by_jump_revenge[花指令]前言 心血来潮,想接触点Reverse,感受下Reverse&am…...
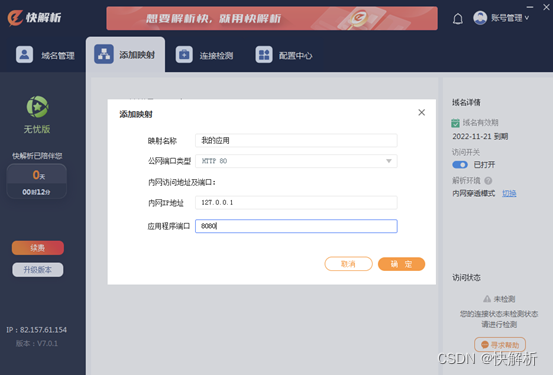
如何实现外网访问内网ip?公网端口映射或内网映射来解决
本地搭建服务器应用,在局域网内可以访问,但在外网不能访问。如何实现外网访问内网ip?主要有两种方案:路由器端口映射和快解析内网映射。根据自己本地网络环境,结合是否有公网IP,是否有路由权限,…...

[acwing周赛复盘] 第 91 场周赛20230218
[acwing周赛复盘] 第 91 场周赛20230218 一、本周周赛总结二、 4861. 构造数列1. 题目描述2. 思路分析3. 代码实现三、4862. 浇花1. 题目描述2. 思路分析3. 代码实现四、4863. 构造新矩阵1. 题目描述2. 思路分析3. 代码实现六、参考链接一、本周周赛总结 这周挺难的。T1 贪心分…...

蓝桥12届
小蓝准备用 256MB 的内存空间开一个数组,数组的每个元素都是 32 位 二进制整数,如果不考虑程序占用的空间和维护内存需要的辅助空间,请问 256MB 的空间可以存储多少个 32 位二进制整数?1MB 1024KB 1KB 1024字节(byte) 1字节 8位…...
)
华为OD机试 - 斗地主(JS)
斗地主 题目 斗地主起源于湖北十堰房县, 据传是一位叫吴修全的年轻人根据当地流行的扑克玩法“跑得快”改编的, 如今已风靡整个中国,并流行于互联网上 牌型: 单顺,又称顺子,最少5张牌,最多12张牌(3...A),不能有2, 也不能有大小王,不计花色 例如:3-4-5-7-8,7-8-9-1…...

【MyBatis】| MyBatis的注解式开发
目录 一:MyBatis的注解式开发 1. Insert注解 2. Delete注解 3. Update注解 4. Select注解 5. Results注解 一:MyBatis的注解式开发 MyBatis中也提供了注解式开发⽅式,采⽤注解可以减少Sql映射⽂件的配置。 当然,使⽤注…...
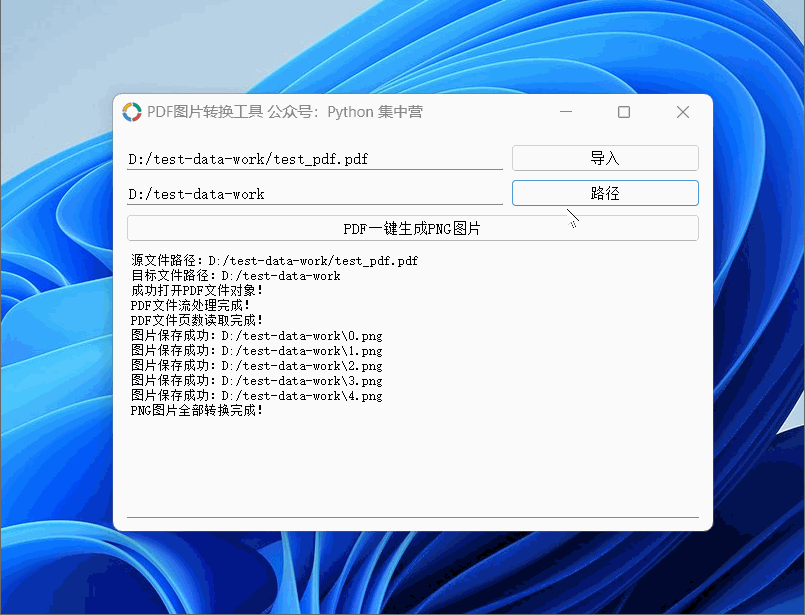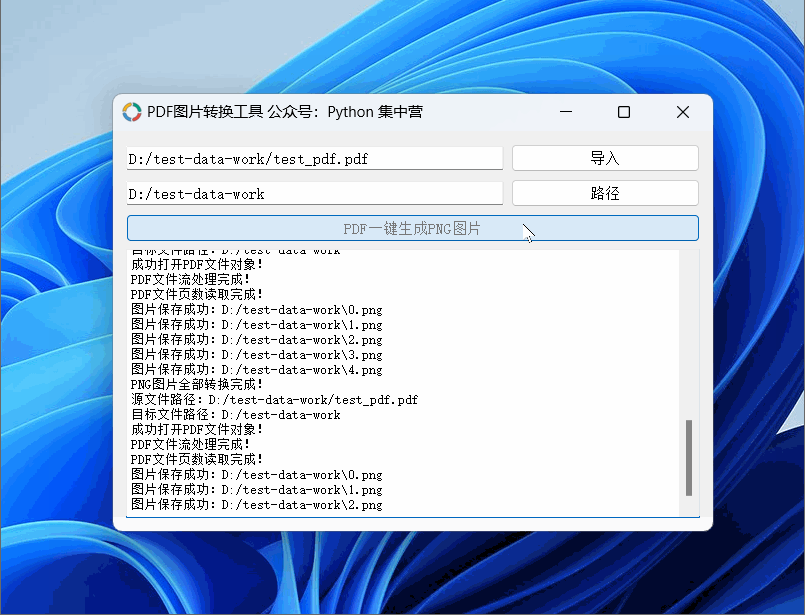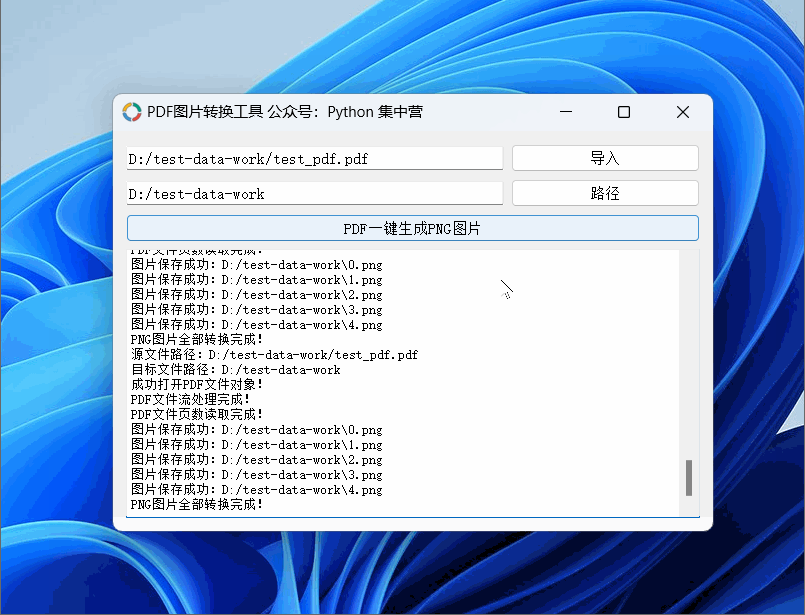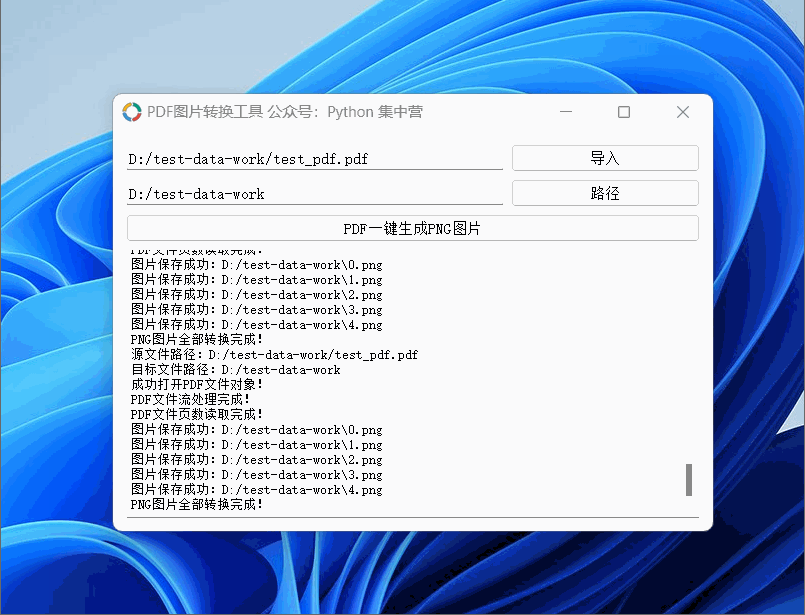
python自制PDF转换.PNG格式图片(按每页生成图片完整源码)小工具!
使用PyQt5应用程序制作PDF转换成图片的小工具,可以导入PDF文档后一键生成对应的PNG图片。 PDF图片转换小工具使用的中间件: python版本:3.6.8 UI应用版本:PyQt5 PDF文件操作非标准库:PyPDF2 PNG图片生成库࿱…...

Go 数组和切片反思
切片的底层数据结构是数组,所以,切片是基于数组的上层封装,使用数组的场景,也完全可以使用切片。 类型比较 我看到 go 1.17 有对切片和数组转换的优化,禁不住纳闷,有什么场景是必须数组来完成的呢&#x…...
win10电脑性能优化设置
win10电脑性能优化设置 目录win10电脑性能优化设置1.桌面图标显示2.wini2.1 “系统”2.1.1专注助手 关2.1.2 电源和睡眠 设置为从不2.1.3 存储 开2.2 网络和Internet2.3 个性化2.4 应用2.5 账户2.6 游戏2.7 隐私墨迹书写和键入个性化:关活动历史记录:全部…...

作为初学者必须要了解的几种常用数据库!
现在已经存在了很多优秀的商业数据库,如甲骨文(Oracle)公司的 Oracle 数据库、IBM 公司的 DB2 数据库、微软公司的 SQL Server 数据库和 Access 数据库。同时,还有很多优秀的开源数据库,如 MySQL 数据库,Po…...

小红书日常实习一面面经
时间:2月13下午 平台:赛码网,视频面大概70分钟顺序大致是下面,讲到哪问到哪,基础知识最好要结合项目或者实际回答,没录音不完全,有错误请指正首先面试官人超级好,细心提问,耐心解答问…...
)
将Nginx 核心知识点扒了个底朝天(一)
什么是Nginx? Nginx是一个 轻量级/高性能的反向代理Web服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用ngin…...

SSM项目搭建保姆级教程
文章目录1、什么是SSM框架1.1、持久层1.2、业务层1.3、表现层1.4、View层1.5、SpringMVC执行流程1.6、MyBatis2、SSM实战搭建2.1、创建工程2.2、添加依赖2.3、配置spring.xml文件2.4、配置web.xml文件2.5、log4j.properties2.6、准备表2.7、实体类2.8、mapper2.9、service2.10、…...

LeetCode 350. 两个数组的交集 II
原题链接 难度:easy\color{Green}{easy}easy 题目描述 给你两个整数数组 nums1nums1nums1 和 nums2nums2nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...