cpm log2((cpm/10) + 1) nmf 1e6 1e5
Gene expression units explained: RPM, RPKM, FPKM, TPM, DESeq, TMM, SCnorm, GeTMM, and ComBat-Seq
Read count、CPM、 RPKM、FPKM和TPM的区别 - 简书 (jianshu.com)

http://zyxue.github.io/2017/06/02/understanding-TCGA-mRNA-Level3-analysis-results-files-from-firebrose.html#:~:text=The%20scaled%20estimate%20value%20on%20the%20other%20hand,%28multiplied%20by%201e6%29%20TPM%20-%20Transcripts%20Per%20Million.
FPKM,RPKM,RPM以及TPM的关系之见解
RPKM: Reads Per Kilobase of exon model per Million mapped reads (每千个碱基的转录每百万映射读取的reads)
FPKM: Fragments Per Kilobase of exon model per Million mapped fragments(每千个碱基的转录每百万映射读取的fragments)
RPM/CPM: Reads/Counts of exon model per Million mapped reads (每百万映射读取的reads)
TPM:Transcripts Per Kilobase of exon model per Million mapped reads (每千个碱基的转录每百万映射读取的Transcripts)
#####################################################################
RPKM (Reads Per Kilobase Million)
FPKM (Fragments Per Kilobase Million)
TPM(Transcripts Per Kilobase Million)
RPM (Reads per million)
CPM (Counts per million)
#####################################################################
在edgeR中,提供了一种名为CPM的定量方式,全称为count-per-millon。
假定原始的表达量矩阵为count, 计算CPM的代码如下cpm <- apply(count ,2, function(x) { x/sum(x)*1000000 })
原始的表达量除以该样本表达量的总和,在乘以一百万就得到了CPM值 。从公式可以看出, CPM其实就是相对丰度,只不过考虑到测序的reads总量很多,所以总的reads数目以百万为单位。在前面的文章中我们介绍了edgeR提供的TMM归一化算法,CPM这种求相对丰度的思想,虽然也是一种比较简单的归一化方式,但它并不用于差异分析之前的归一化。
在edgeR中,CPM主要有以下两种用途
1. 过滤表达量较低的基因
DESeq2和edgeR都是针对raw count表达量进行分析,在DESeq2中,在过滤低表达量的基因时,直接是根据reads数的总和进行判断,代码如下countData <- count[apply(count, 1, sum) > 10 , ]
由于不同样本测序的reads总数不同,所以直接将所有样本的reads相加,然后进行过滤,这种方式略显粗糙。edgeR中,利用CPM的定量结果,对低表达量的基因进行过滤,代码如下countData <- count[apply(cpm(count), 1, sum) > 2 , ]
利用相对丰度的加和进行过滤,消除了样本间reads总数不同的影响。需要注意的是,我们只是用CPM来过滤基因,而后续分析还是基于raw count的结果,因为只有raw count是基于负二项分布的。
log2 (1 + CPMi,j/10)
Read count、CPM、 RPKM、FPKM和TPM的区别 - 简书 (jianshu.com)
Normalize Data — NormalizeData • Seurat (satijalab.org)
https://github.com/broadinstitute/single_cell_classification/blob/master/src/QC_methods.R
# run Seurat methods to get gene expression clustersseuObj <- Seurat::NormalizeData(object = seuObj, normalization.method = "LogNormalize", scale.factor = 1e5, verbose = FALSE)单细胞seurat包中,这样处理之后,数据是cpm数据嘛:seuObj <- Seurat::NormalizeData(object = seuObj, normalization.method = "LogNormalize", scale.factor = 1e5, verbose = FALSE)
https://github.com/broadinstitute/single_cell_classification/blob/a06b369eae13b2dc5ca7288f8a5d4a03098a2268/src/gene_expression_classification.R#L64
#compute summed counts across cells for each cluster, then CPM transform
clust_cpm <- plyr::laply(levels(seuObj), function(clust) {Matrix::rowSums(Seurat::GetAssayData(seuObj, slot = 'counts')[, names(Seurat::Idents(seuObj)[Seurat::Idents(seuObj) == clust])])
}) %>%t() %>%edgeR::cpm(prior.count = 1, log = TRUE)
这看起来是一个 R 语言中使用 edgeR 包的代码片段,用于计算表达矩阵的 counts per million (CPM) 值,并且在计算时使用了先验计数为 1,以及进行对数转换。下面是对每个参数的解释:
-
edgeR::cpm(): 这是 edgeR 包中的一个函数,用于计算 counts per million (CPM) 值。CPM 是一种常用的规范化方法,用于在不同样本或条件之间比较基因表达水平。它将原始计数转化为每百万个读取的表达值。
-
prior.count = 1: 这个参数指定了在计算 CPM 值时使用的先验计数。通常,当样本的计数非常低时,为了避免出现无限大的值,可以设置一个小的先验计数。在这里,使用了 1 作为先验计数。
-
log = TRUE: 这个参数指定是否在计算后对 CPM 值进行对数转换。对数转换可以使数据更符合正态分布,有时在分析中会更有用。
在计算 CPM(Counts Per Million)时,公式是将每个基因的计数除以总的读取数,然后乘以一百万。例如,如果一个基因在一个样本中有 10 个计数,而总的读取数是 1,000,000,那么它的 CPM 就是 (10 / 1,000,000) * 1,000,000 = 10。
然而,当样本的计数非常低时,例如只有很少的几个计数,会导致计算结果变得不稳定。这是因为分母非常小,可能接近零,这将使分子除以一个接近零的数,导致结果变得非常大或无限大,这在统计分析中是不合理的。
为了解决这个问题,可以在计算 CPM 值时引入一个小的常数,称为先验计数(prior count)。这个常数在分母上加上,从而避免出现除以零的情况。通常情况下,使用一个小的常数,比如 1,作为先验计数。
所以,在给定的函数中,prior.count = 1 表示在计算 CPM 值时,会在每个基因的计数上加上一个先验计数值 1,然后再进行计算。这样做可以确保即使基因的计数非常低,也不会出现分母为零的情况,从而得到更合理的结果。
https://github.com/gabrielakinker/CCLE_heterogeneity/blob/master/nmf_programs.R
library(nmf)nmf_programs <- function(cpm, is.log=F, rank, method="snmf/r", seed=1) {if(is.log==F) CP100K_log <- log2((cpm/10) + 1) else CP100K_log <- cpmCP100K_log <- CP100K_log[apply(CP100K_log, 1, function(x) length(which(x > 3.5)) > ncol(CP100K_log)*0.02),]CP100K_log <- CP100K_log - rowMeans(CP100K_log)CP100K_log[CP100K_log < 0] <- 0nmf_programs <- nmf(CP100K_log, rank=rank, method=method, seed=seed)nmf_programs_scores <- list(w_basis=basis(nmf_programs), h_coef=t(coef(nmf_programs)))return(nmf_programs_scores)
}相关文章:
cpm log2((cpm/10) + 1) nmf 1e6 1e5
Gene expression units explained: RPM, RPKM, FPKM, TPM, DESeq, TMM, SCnorm, GeTMM, and ComBat-Seq Read count、CPM、 RPKM、FPKM和TPM的区别 - 简书 (jianshu.com) http://zyxue.github.io/2017/06/02/understanding-TCGA-mRNA-Level3-analysis-results-files-from-fir…...
竞赛项目 深度学习的视频多目标跟踪实现
文章目录 1 前言2 先上成果3 多目标跟踪的两种方法3.1 方法13.2 方法2 4 Tracking By Detecting的跟踪过程4.1 存在的问题4.2 基于轨迹预测的跟踪方式 5 训练代码6 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的视频多目标跟踪实现 …...

如何避免用waveformRecord复制数组
这里描述如何使用数组字段内存管理特定。这使得数组数据能够被移入和移出waveform,aai和aao类型的值字段(BPTR)。 使用这种特定包括用另一个(用户分配的)字段替代存储在BPTR字段的指针。基本规则是: 1、BPTR以及它当前指向的内存,只能在这个…...
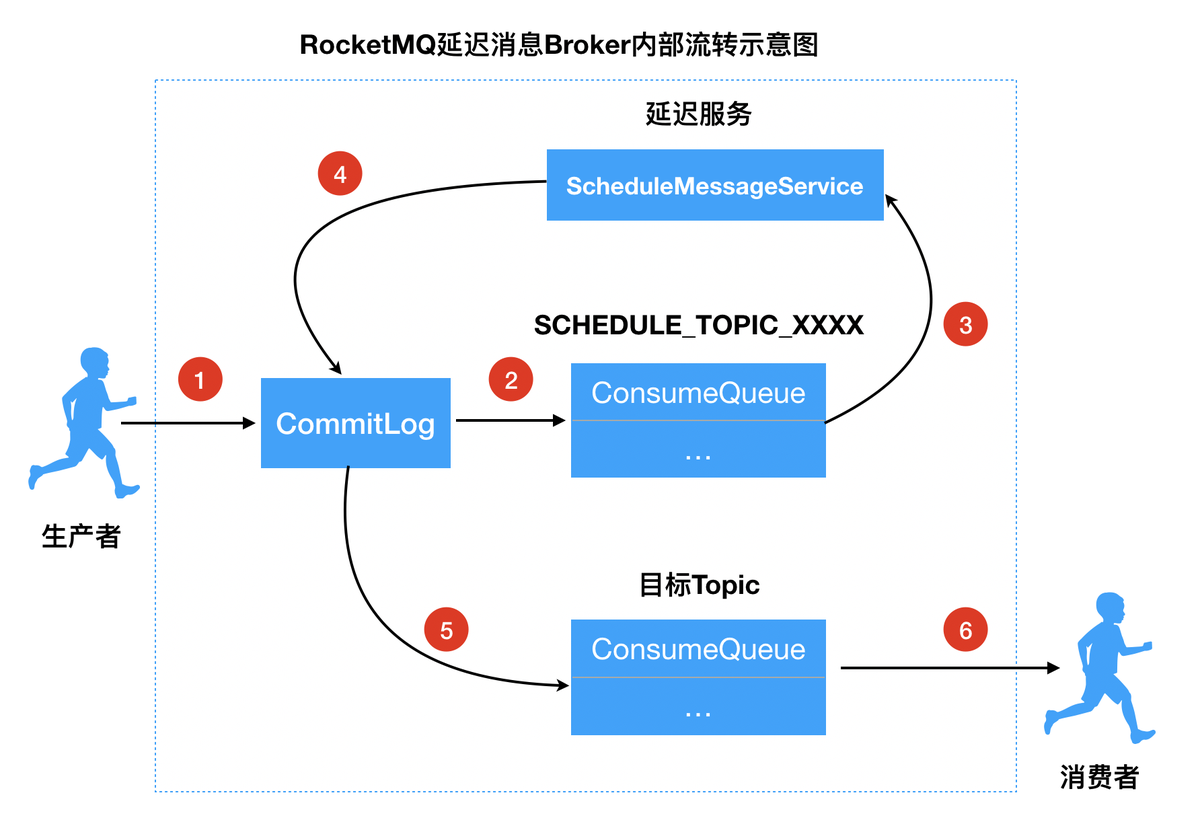
RocketMQ 延迟消息
RocketMQ 延迟消息 RocketMQ 消费者启动流程 什么是延迟消息 RocketMQ 延迟消息是指,生产者发送消息给消费者消息,消费者需要等待一段时间后才能消费到。 使用场景 用户下单之后,15分钟未支付,对支付账单进行提醒或者关单处理…...
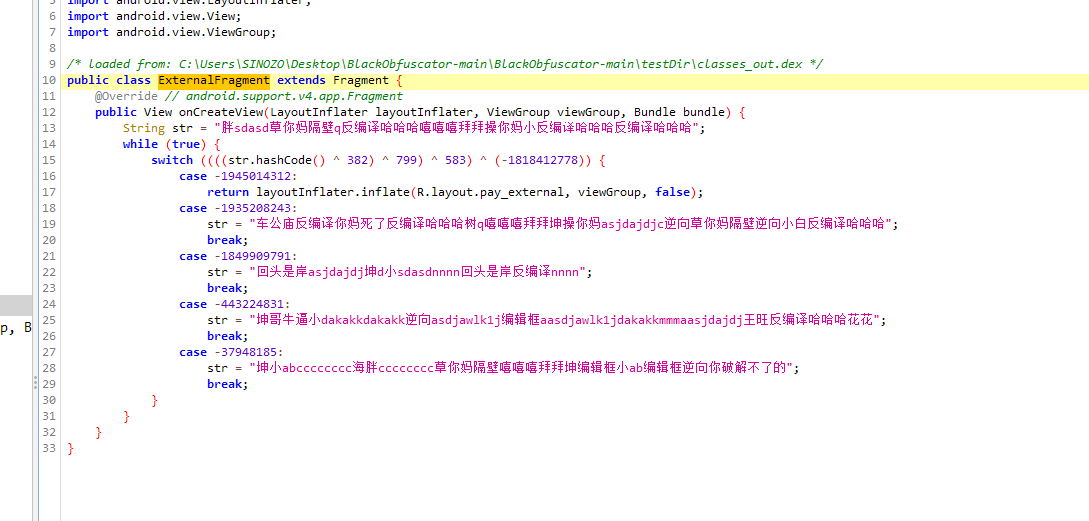
Dex文件混淆(一):BlackObfuscator
Dex文件混淆(一):BlackObfuscator 首发地址:http://zhuoyue360.com/crack/105.html 文章目录 Dex文件混淆(一):BlackObfuscator1. 前言2.小试牛刀3. 参考学习1. dex2jar源码简析2. BlackObfuscator简析1. 控制流平坦化1. 控制流平坦化基本介绍 2. Dex解析…...
)
Linux下编译arm 32 出错(/bin/bash: arm-none-linux-gnueabi-gcc: command not found )
一、arm-none-linux-gnueabi-gcc不能再64位系统下下编译ARM的32位库的问题解决方法如下: sudo apt-get install lib32stdc6 sudo apt-get install lib32ncurses5 sudo apt-get install lib32z1 二、交叉编译工具没有写入环境变量或写错,重新写入环境变量…...

最近遇到的两个小问题总结:git问题和node问题
这两个问题都是我帮别人看问题的解决的,在windows系统上遇到的: 1、git没有配置全局变量 在使用git的时候,报’git‘不是内部或外部命令,也不是可运行的程序。然后再在其他文件下面试一下(git --version)…...
)
Java # Spring(1)
一、概念 1、核心技术:依赖注入(DI),AOP,事件(events),资源,i18n,验证,数据绑定,类型转换,SpEL。 2、测试:模…...

SCL更换阿里数据源
问题: zabbix安装前端环境报错 yum install zabbix-web-mysql-scl zabbix-apache-conf-scl -y 报错:Could not retrieve mirrorlist http://mirrorlist.centos.org/ 能上网 但是不能ping通http://mirrorlist.centos.org/ 解决: 修改repo数…...
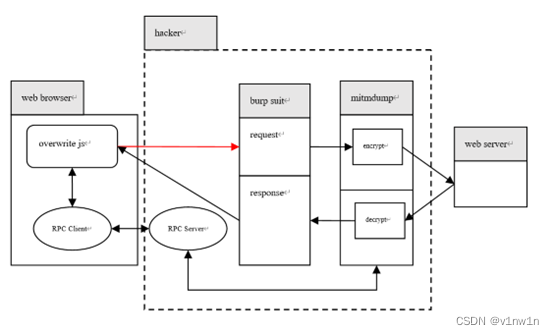
【web逆向】全报文加密流量的去加密测试方案
aHR0cHM6Ly90ZGx6LmNjYi5jb20vIy9sb2dpbg 国密混合 WEB JS逆向篇 先看报文:请求和响应都是全加密,这种情况就不像参数加密可以方便全文搜索定位加密代码,但因为前端必须解密响应的密文,因此万能的方法就是搜索拦截器,…...
Django实现音乐网站 ⑼
使用Python Django框架制作一个音乐网站, 本篇主要是后台对专辑、首页轮播图原有功能的基础上进行部分功能实现和显示优化。 目录 专辑功能优化 新增编辑 专辑语种改为下拉选项 添加单曲优化显示 新增单曲多选 更新歌手专辑数、专辑单曲数 获取歌手专辑数 保…...
【脚踢数据结构】
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,Linux基础,ARM开发板,软件配置等领域博主🌍快上🚘,一起学习,让我们成为一个强大的攻城狮!送给自己和读者的一句鸡汤🤔&…...

uni-app使用vue语法进行开发注意事项
目录 uni-app 项目目录结构 生命周期 路由 路由跳转 页面栈 条件编译 文本渲染 样式渲染 条件渲染 遍历渲染 事件处理 事件修饰符 uni-app 项目目录结构 组件/标签 使用(类似)小程序 语法/结构 使用vue 具体项目目录如下: 生命…...
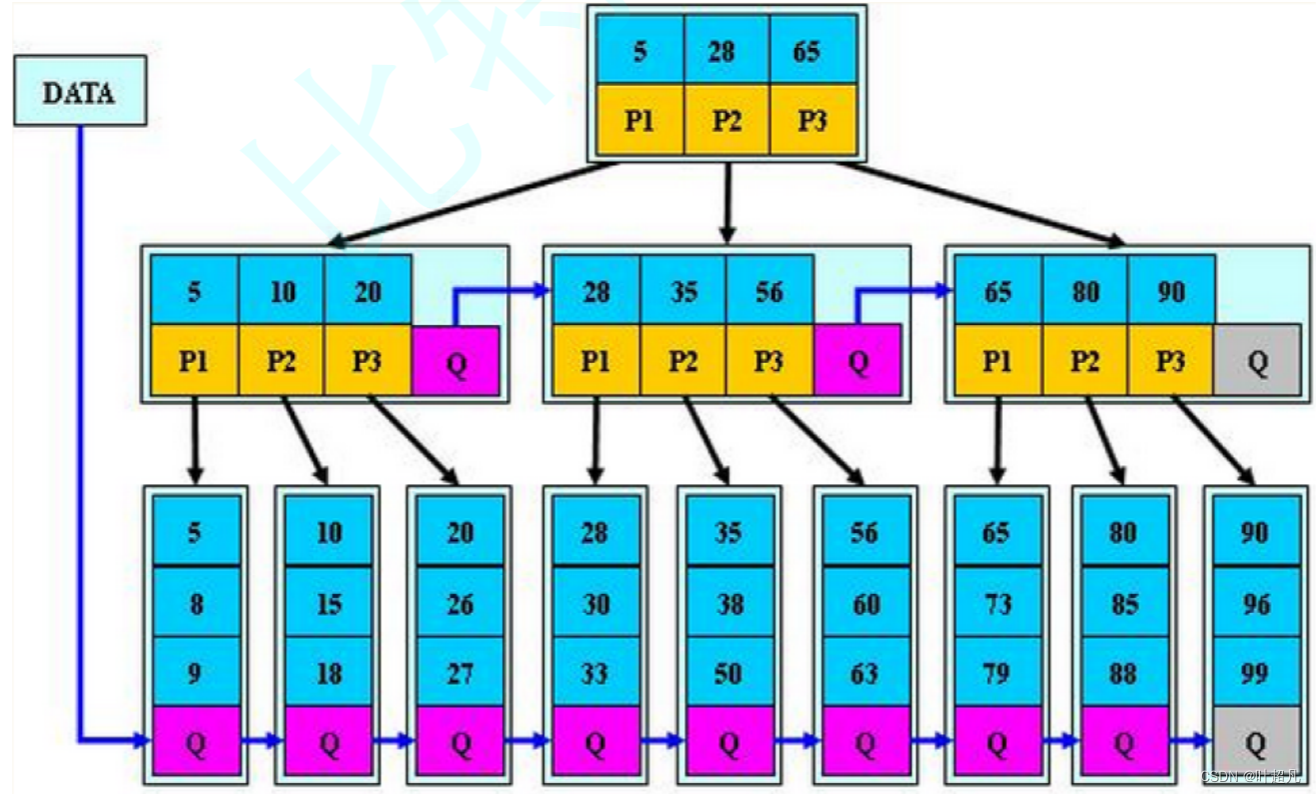
数据结构---B树
目录标题 B-树的由来B-树的规则和原理B-树的插入分析B-树的插入实现准备工作find函数insert中序遍历 B-树的性能测试B-树的删除B树B树的元素插入B*树的介绍 B-树的由来 在前面的学习过程中,我们见过很多搜索结构比比如说顺序查找,二分查找,搜…...
)
c++11以后c++标准库定义的固定位宽的整数类型(Fixed width integer types)
Fixed width integer types Fixed width integer types (since C11) - cppreference.com 相关定义文件如下: Windows系统MSVC: Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\include\cstdint Linux系统GCC: gcc\libstdc-v3\include\c_g…...
)
Object.values()
Object.values() 是ES2017新增的一个对象方法,它可以将一个对象自身的所有可枚举属性值,组成一个数组返回。 基本语法: Object.values(obj)示例: jsCopy codeconst obj {foo: bar,baz: 42 };Object.values(obj); // [bar, 42]Object.values()的特点: 只返回可枚举的属性值…...

Oracle 开发篇+Java调用OJDBC访问Oracle数据库
标签:JAVA语言、Oracle数据库、Java访问Oracle数据库释义:OJDBC是Oracle公司提供的Java数据库连接驱动程序 ★ 实验环境 ※ Oracle 19c ※ OJDBC8 ※ JDK 8 ★ Java代码案例 package PAC_001; import java.sql.Connection; import java.sql.ResultSet…...

linux 查询后台任务及杀掉进程
查看后台任务命令 jobs -l删除后台进程命令 kill -9 28719...
【Vue3 博物馆管理系统】使用Vue3、Element-plus菜单组件构建前台用户菜单
系列文章目录 第一章 定制上中下(顶部菜单、底部区域、中间主区域显示)三层结构首页 第二章 使用Vue3、Element-plus菜单组件构建菜单 [第三章 使用Vue3、Element-plus菜单组件构建轮播图] [第四章 使用Vue3、Element-plus菜单组件构建组图文章] 文章目…...

Windows 11清除无效、回收站、过期、缓存、补丁更新文件
Windows 11与之前的Windows版本类似,也需要定期清理无效、垃圾、过期、缓存文件来保持系统性能和存储空间的优化。以下是在Windows 11中进行这些清理操作的一些建议方法: 磁盘清理工具 Windows 11内置了磁盘清理工具,可以帮助你删除临时文件…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...