[Machine Learning] decision tree 决策树
(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍)
(祝,本文同时用于比赛学习笔记和机器学习基础课程)
俺前两天参加了一个ai类的比赛,其中用到了一种名为baseline的模型来进行一些数据的识别。而这个识别的底层原理就是决策树。正好原本的学习进度刚刚完成这部分,所以集成一个笔记了,本文中所有的截图绝大多数来自吴恩达老师的公开课程,为了方便理解,把相关的图片搬过来了)
决策树是什么
决策树是一种机器学习算法,在一个类似二叉树的结构上实现的分支判断算法。每个节点都视为一个“判断语句”,将一批数据划分成不同的部分。节点上(除了叶子)都要判断“是”/“否”。

一个具体化以后的模型差不多长这样子:给出一堆宠物的数据,根据不同的特征(耳朵,脸型什么的),我们判断输入案例是狗还是猫猫。
如果还是不好理解,那么想象一下我们平时在写代码时候大量if else嵌套,展开以后也是一模一样的结构。去别在于可能if构成的判断树的后代可能多于决策树,决策树只能是二叉树,输出“是”“不是”这种问题,当面对多个离散的特征值的时候,我们还有别的技术可以使用.
简而言之,决策树是一种区别于神经网络的另一种判断算法,在一些数据的处理上可能比神经网络更快更有效,由于其结构类似二叉树,所以称之为决策树(decision tree).决策树的生成是要根据已经给出的数据案例创建的,数据有多少特征用于区分,就会有多少个节点进行分裂(split).
具体的训练过程和训练中遇到的问题会在下面解释
在训练之前要接触的一些名词
纯净(purity)/杂质(impurity):纯度和不纯是根据某个节点来说的,例如我们输入一堆宠物的数据(包括耳朵形状,毛发长度,脸型这些特征),在判断某个属性的节点上,我们会根据"符合"/"不符合"把已有的数据划分为两拨.比如这样子
原型的部分中,有四个是猫猫,三个是狗子.对于这个节点来说,我们可以认为这个节点的纯度是(4/7)
同理,另一个节点的纯度视为(1/3)
(纯度是一个相对的概念,如果你判断的是狗子,那么纯度就要变了)
熵:这个熵不是化学中的概念,而是代表混乱程度,当纯度和为0.5的时候,代表两种东西对半开,也就是最混乱的情况.根据纯度,我们有相关的公式可以计算出纯度对应熵的大小(假设纯度为p)
整个函数的图像大概就是这样子

信息增益:信息增益也是根据某一个点来说的,这个数值是训练时候的重要依据,信息增益越大,代表整个节点进行的划分越有效,信息增益的计算方式为
0.5对应的熵,减去左侧的熵和右侧的熵的加权平均和即可.比如上面的图,我们可以计算为
决策树如何进行训练
决策树底层的训练原理其实很简单,首先我们需要给定一个数据集合,这个数据集合中的每个事物都有一些共同的特征,类似这样,通常我们可以把有效的特征组合起来形成一个表格.

前面的特征为输入,而cat一列作为输出,决定这个宠物到底是不是猫,由此构成一系列符合监督学习要求的训练数据集合.
然后会从这些信息中,选择分裂时产生更小熵的特征,算法会基于某种标准(例如信息增益、基尼不纯度等)来评估每个可能的划分,并选择最优的划分特征。这些标准用于衡量数据的不纯度和分割后的纯度。这里我们使用上面讲到的信息增益来判断这个划分成都

由此可见,以耳朵形状作为划分所产生的分裂节点,信息增益更大,纯度也更好.
接下来再根据其他的特征进行划分即可,当遇到以下几种情况的时候,我们可以认为这个节点不用再继续分裂了
- 树的高度达到某些限制
- 纯度已经是100%
- 数据全部低于阈值
- ........
两个特殊情况
(1)分裂时候的数据不是二元的离散数值,而是一个连续的情况
这个很简单,设置一个阈值,比如0.5,0,7,....反正到最后还是二元的
(2)分裂的时候,可能数据是多元的离散数值,比如毛发可能是长发,短发,卷发这三种.我们总不能搞出三叉树来,所以这里我们把"是什么"转变为"是不是"的问题.比如这样一个特征,我们可以划分为"是不是长发,是不是短发,是不是卷毛"三个二元的特征
随机森林算法
给定一个数据集合,我们可以计算出一个决策树来进行一些判断,给定一个动物,决策树最红会给出我们这个是不是猫猫的答案.但是这有两个问题,节点不一定是纯净的(虽然大多数情况下,只要不超过我们的限定高度,是可以把一个决策树修炼到高度纯净的),造成判断结果不一定准确.
另一个问题就是,一些数据发生扰动以后,可能会影响决策树这个依托信息增益产生的精密系统.
最简单粗暴的方法就是,训练多个树,形成一个森林.但是一个数据集合练出来的树是一样的,没啥必要,所以我们产生了随机森林算法.
sampling with replacement(放回抽样)这东西我们在高中就学过,所以这里不加简述了.我们要做的就是确定一个规模,比如10,每次从原始数据集中抽取10个案例,然后用来训练一棵树.
如此循环多次,我们就能得到多个决策树,组成一个森林,这其中难免会有一些决策树是一样的,我们忽视掉它

这样我们计算结果的时候,要考虑到整个森林所有树木的输出效果,然后综合考虑我们怎样确定输出效果
XGBoost算法和使用
在众多随机森林算法中,XGBoost是一种使用很广泛的随机森林算法,并且XGBoost也是一个开源库(不是放在tf或者pytorch的库中的).XGBoost非常像我们之前聊过的增强算法(啥,哦博客还没写出来,8好意思,尽快补上)
XGBoost算法和普通决策树的区别在于放回抽样的不疯魔,传统的决策树是平等地抽取,xgb算法则是会根据上一次,估计错了哪些数值,在本次抽取中优先提取上一次参与训练并且估计失败的数值案例.
比如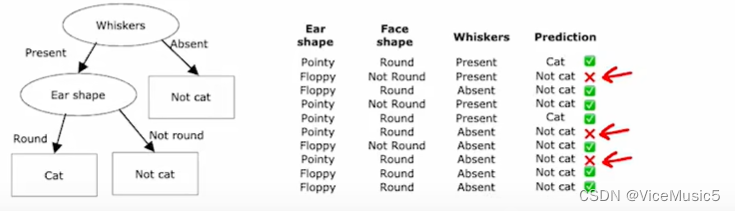
构建某一次决策树的时候,2,6,8号数据估计错误,则下一次会优先提取出这些作为训练案例之一.
当然这些主要是底层实现了(注意对应的函数从xgboost包中导入,这个包需要提前下载)
下面来看一下具体的使用案例.
pip3 install xgboost#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"预测结果: {prediction}")#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"预测结果: {prediction}")和神经网络有什么区别捏?
相比于神经网络来说,决策树和随机森林算法更适合一些有固定相似数据结构的数据集合.换句话说,更容易处理那种可以形成表格的数据.
而神经网络则用来处理一些非相似结构的数据,这一点就是他们的主要区别
决策树同样是一种很重要的监督学习算法.
关于baseline(未完待续)
baseline是一种基于决策树的大模型,适用于多重二元分析等操作,在竞赛和论文中应用很广泛.
(至少与我们之前用到tensorflow要广泛.....tf都快开摆了)
不过这个模型我现在也不是很熟悉,仅仅是停留在"用过"这个层面上,后面有机会我会继续在这里补充这个模型的使用和优缺点,
相关文章:
[Machine Learning] decision tree 决策树
(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍) (祝,本文同时用于比赛学习笔记和机器学习基础课程&a…...

【数学建模】-- 数学规划模型
概述: 什么是数学规划? 数学建模中的数学规划是指利用数学方法和技巧对问题进行数学建模,并通过数学规划模型求解最优解的过程。数学规划是一种数学优化方法,旨在找到使目标函数达到最大值或最小值的变量取值,同时满足…...

SpringBoot使用RabbitMQ自动创建Exchange和Queue
背景 小项目,使用RabbitMQ作为消息队列,发布到不同的新环境时,由于新搭建的MQ中不存在Exchange和Queue,就会出错,还得手动去创建,比较麻烦,于是想在代码中将这些定义好后,自动控制M…...
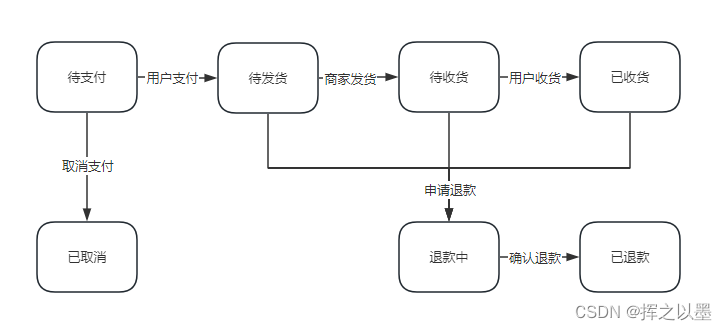
【设计模式】订单状态流传中的状态机与状态模式
文章目录 1. 前言2.状态模式2.1.订单状态流转案例2.1.1.状态枚举定义2.1.2.状态接口与实现2.1.3.状态机2.1.4.测试 2.2.退款状态的拓展2.2.1.代码拓展2.2.2.测试 2.3.小结 3.总结 1. 前言 状态模式一般是用在对象内部的状态流转场景中,用来实现状态机。 什么是状态…...
用来修改或者添加属性或者属性值)
2.js中attr()用来修改或者添加属性或者属性值
attr()可以用来修改或者添加属性或者属性值 例:<input type"button" class"btn btn-info" id"subbtn" style"font-size:12px" value"我也说一句"/>1.如果想获取input中value的值 $(#subbtn).attr(value);…...

【虫洞攻击检测】使用多层神经网络的移动自组织网络中的虫洞攻击检测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微分流形学习之一:基本定义
微分流形学习之一:基本定义引入 引言一、微分流形的历史简介二、拓扑空间三、微分流形 引言 本文是作者在学习微分流形的时候的笔记,尽量严格完整,并带有一定理解,绝不是结论的简单罗列。如果读者知道数学分析中的 ϵ − δ \ep…...
[C++]笔记-制作自己的静态库
一.静态库的创建 在项目属性c/c里面,选用无预编译头,创建头文件与cpp文件,需要注意release模式下还是debug模式,在用库时候要与该模式相匹配,库的函数实现是外界无法看到的,最后在要使用的项目里面导入.h文件和.lib文件 二.使用一个循环给二维数组赋值 行数 : 第几个元素 / …...

优酷视频码率、爱奇艺视频码率、B站视频码率、抖音视频码率对比
优酷视频码率、爱奇艺视频码率与YouTube视频码率对比 优酷视频码率: 优酷的视频码率可以根据视频质量、分辨率和内容类型而变化。一般而言,优酷提供了不同的码率选项,包括较低的标清(SD)码率和较高的高清(…...
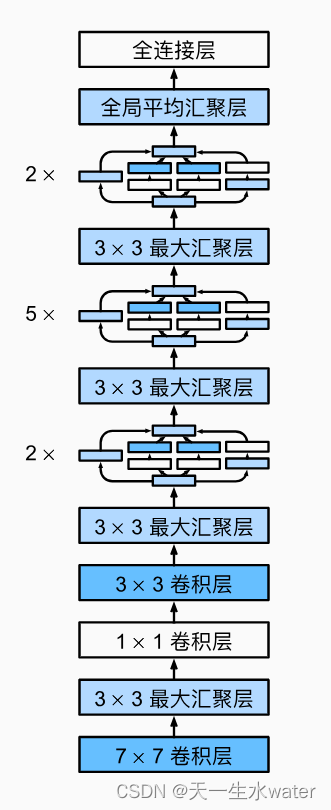
用pytorch实现google net
GoogleNet(也称为Inception v1)是由Google在2014年提出的一个深度卷积神经网络架构。它在ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014比赛中取得了优秀的成绩,并引起了广泛的关注。 GoogleNet的设计目标是构建一个更…...

2023-8-15差分矩阵
题目链接:差分矩阵 #include <iostream>using namespace std;const int N 1010;int n, m, q; int a[N][N], b[N][N];void insert(int x1, int y1, int x2, int y2, int c) {b[x1][y1] c;b[x1][y2 1] - c;b[x2 1][y1] - c;b[x2 1][y2 1] c; }int main…...

物理公式分类
(99 封私信 / 81 条消息) 定义式和决定式有什么区别,怎么区分? - 知乎 (zhihu.com) 1、首先,定义一个物理符号(物理量)来表征物理世界最直观/最基本的物理现象,例如,长度(米…...

vue实现登录注册
目录 一、登录页面 二、注册页面 三、配置路由 一、登录页面 <template><div class"login_container" style"background-color: rgb(243,243,243);height: 93.68vh;background-image: url(https://ts1.cn.mm.bing.net/th/id/R-C.f878c96c4179c501a6…...
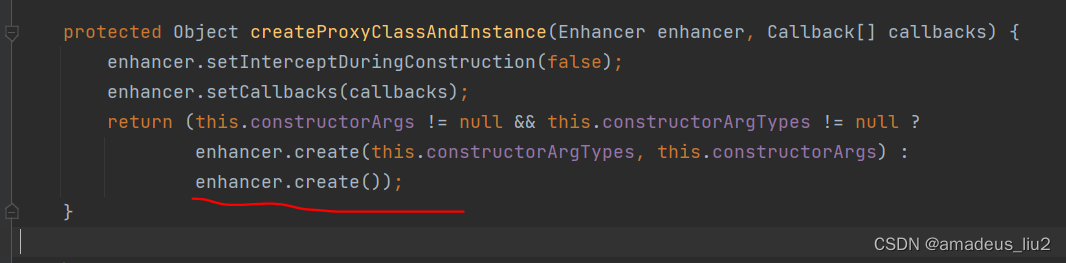
SpringBoot复习:(55)在service类中的方法上加上@Transactional注解后,Spring底层是怎么生成代理对象的?
SpringBoot run方法代码如下: 可以看到它会调用refreshContext方法来刷新Spring容器,这个refreshContext方法最终会调用AbstractApplicationContext的refresh方法,代码如下 如上图,refresh方法最终会调用finisheBeanFactoryInit…...

常用的图像校正方法
在数字图像处理中,常用的校正方法包括明场均匀性校正、查找表(LUT)校正和伽玛(Gamma)校正。这些校正方法分别针对不同的图像问题,可以改善图像质量,提升图像的可读性和可分析性。下面是这三种校…...

AWS security 培训笔记
云计算的好处 Amazon S3 (Storage) Amazon EC2 (Compute) 上图aws 的几个支柱:安全是其中一个啦 其中安全有几个方面 IAMdetection基础架构保护数据保护应急响应 关于云供应商的责任 data center 原来长这样 ,据说非常之隐蔽的 如果有天退役了…...
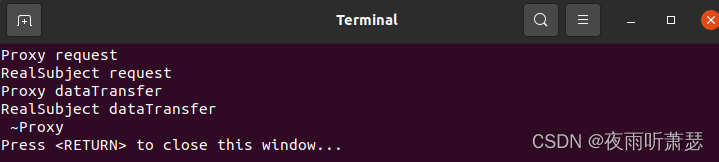
设计模式之代理模式(Proxy)的C++实现
1、代理模式的提出 在组件的开发过程中,有些对象由于某种原因(比如对象创建的开销很大,或者对象的一些操作需要做安全控制,或者需要进程外的访问等),会使Client使用者在操作这类对象时可能会存在问题&…...
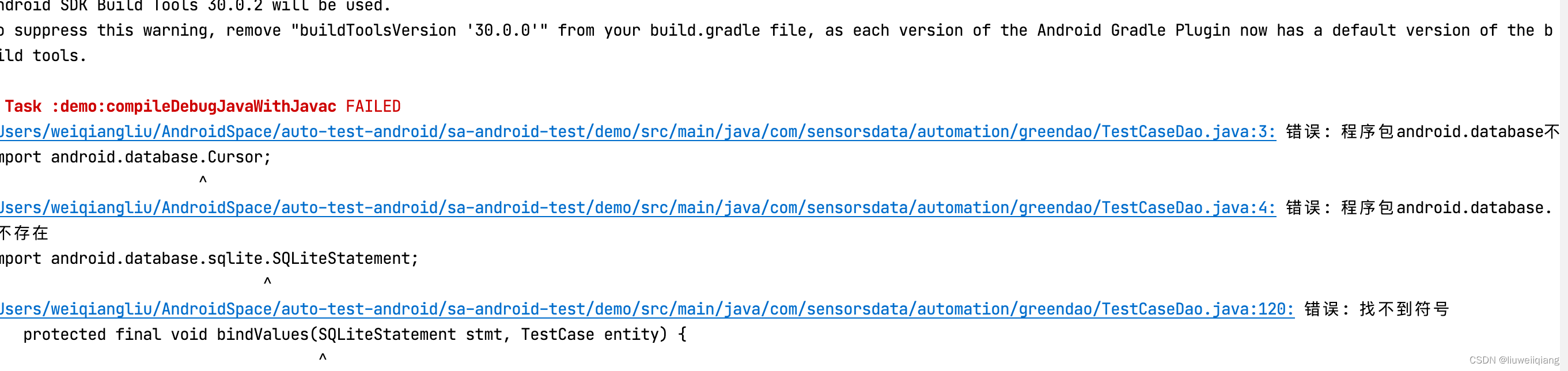
vim 配置环境变量与 JDK 编译器异常
vim 配置环境变量 使用 vim 打开系统中的配置信息(不存在将会创建): vim ~/.bash_profile 以配置两个版本 JDK 为例(前提是已安装 JDK),使用上述命令打开配置信息: 输入法调成英文,输入 i&…...

TiDB v7.1.0 跨业务系统多租户解决方案
本文介绍了 TiDB 数据库的资源管控技术,并通过业务测试验证了效果。资源管控技术旨在解决多业务共用一个集群时的资源隔离和负载问题,通过资源组概念,可以限制不同业务的计算和 I/O 资源,实现资源隔离和优先级调度,提高…...
)
【题解】二叉树中和为某一值的路径(一)
二叉树中和为某一值的路径(一) 题目链接:二叉树中和为某一值的路径(一) 解题思路1:递归 我们或许想记录下每一条从根节点到叶子节点的路径,计算出该条路径的和,但此种思路用递归稍麻烦,我们可以试着把和转换为差&am…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...