改善神经网络——优化算法(mini-batch、动量梯度下降法、Adam优化算法)
改善神经网络——优化算法
- 梯度下降
- Mini-batch 梯度下降(Mini-batch Gradient Descent)
- 指数加权平均
- 包含动量的梯度下降
- RMSprop算法
- Adam算法
优化算法可以使神经网络运行的更快,机器学习的应用是一个高度依赖经验的过程,伴随着大量迭代的过程,你需要训练诸多模型,才能找到合适的那一个,所以,优化算法能够帮助你快速训练模型。
其中一个难点在于,深度学习没有在大数据领域发挥最大的效果,我们可以利用一个巨大的数据集来训练神经网络,而在巨大的数据集基础上进行训练速度很慢。因此,你会发现,使用快速的优化算法,使用好用的优化算法能够大大提高你和团队的效率
梯度下降
在机器学习中,最简单就是没有任何优化的梯度下降(GD,Gradient Descent),我们每一次循环都是对整个训练集进行学习,这叫做批量梯度下降(Batch Gradient Descent),参考文章 机器学习——梯度下降算法。
使用梯度下降算法时,假设对 m 个样本进行计算,把训练样本放大巨大的矩阵 X X X 当中去, X = [ x ( 1 ) x ( 2 ) x ( 3 ) . . . x ( m ) ] X=[x^{(1)}x^{(2)}x^{(3)}...x^{(m)}] X=[x(1)x(2)x(3)...x(m)] , Y Y Y 也是如此, Y = [ y ( 1 ) y ( 2 ) y ( 3 ) . . . y ( m ) ] Y=[y^{(1)}y^{(2)}y^{(3)}...y^{(m)}] Y=[y(1)y(2)y(3)...y(m)] ,向量化能够让你相对较快地处理所有 m 个样本。如果 m 很大的话,处理速度仍然缓慢。比如说,如果 m 是500万或5000万或者更大的一个数,在对整个训练集执行梯度下降法时,你要做的是,你必须处理整个训练集,然后才能进行一步梯度下降法,然后你需要再重新处理500万个训练样本,才能进行下一步梯度下降法。所以如果你在处理完整个500万个样本的训练集之前,先让梯度下降法处理一部分,你的算法速度会更快。
Mini-batch 梯度下降(Mini-batch Gradient Descent)
把训练集分割为小一点的子集训练,这些子集被取名为mini-batch。
梯度下降算法演变来的有随机梯度下降(SGD)算法和小批量梯度下降算法(Mini-batch Gradient Descent)。随机梯度下降相当于小批量梯度下降,但是和mini-batch不同的是其中每个小批量(mini-batch)仅有1个样本,和梯度下降不同的是你一次只能在一个训练样本上计算梯度,而不是在整个训练集上计算梯度。
在随机梯度下降中,在更新梯度之前,只使用1个训练样本。 当训练集较大时,随机梯度下降可以更快,但是参数会向最小值摆动,而不是平稳地收敛,我们来看一下比较图:
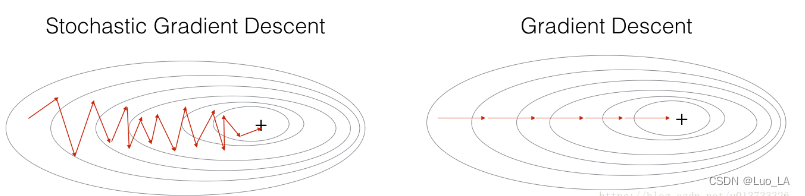
在实际中,更好的方法是使用小批量(mini-batch)梯度下降法,小批量梯度下降法是一种综合了梯度下降法和随机梯度下降法的方法,在它的每次迭代中,既不是选择全部的数据来学习,也不是选择一个样本来学习,而是把所有的数据集分割为一小块一小块的来学习,它会随机选择一小块(mini-batch),块大小一般为2的n次方倍。
假设每一个子集中只有1000个样本,那么把其中的 x ( 1 ) x^{(1)} x(1)到 x ( 1000 ) x^{(1000)} x(1000) 取出来,将其称为第一个子训练集,也叫做mini-batch,然后你再取出接下来的1000个样本,从 x ( 1001 ) x^{(1001)} x(1001)到 x ( 2000 ) x^{(2000)} x(2000) ,然后再取1000个样本,以此类推。
假设训练样本 m = 500万,每个mini-batch 都有1000个样本,也就是说,有5000个mini-batch。把 x ( 1 ) x^{(1)} x(1)到 x ( 1000 ) x^{(1000)} x(1000) 称为 X { 1 } X^{\{1\}} X{1}, x ( 1001 ) x^{(1001)} x(1001)到 x ( 2000 ) x^{(2000)} x(2000) 称为 X { 2 } X^{\{2\}} X{2},以此类推直到 X ( 5000 ) X^{(5000)} X(5000), 对 Y Y Y 进行同样的处理。mini-batch的数量 t 组成了 X { t } X^{\{t\}} X{t}, Y { t } Y^{\{t\}} Y{t}。 X { t } X^{\{t\}} X{t}的维数是 ( n x , 1000 ) (n_{x},1000) (nx,1000), n x n_{x} nx 是样本输入单元个数, Y { t } Y^{\{t\}} Y{t} 的维数是 ( 1 , 1000 ) (1,1000) (1,1000)
之前我们使用了上角小括号 ( i ) 表示训练集里的值,所以 x ( i ) x^{(i)} x(i)是第 i 个训练样本。我们用了上角中括号 [ l ] 来表示神经网络的层数, z [ l ] z^{[l]} z[l] 表示神经网络中第 l 层的 z 值,我们现在引入了大括号 t 来代表不同的 mini-batch,所以我们有 X { t } X^{\{t\}} X{t}, Y { t } Y^{\{t\}} Y{t}。
在训练集上运行mini-batch梯度下降法,你运行for t=1……5000,因为我们有5000个各有1000个样本的组,在for循环里你要做得基本就是对 X { t } X^{\{t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t} 执行一步梯度下降法。
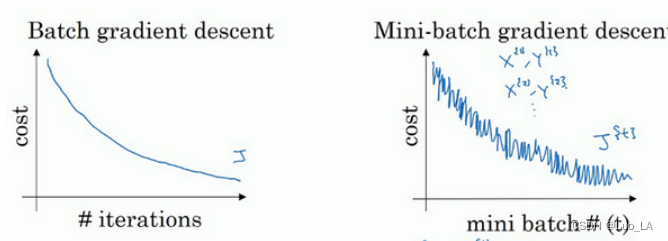
使用batch梯度下降法时,每次迭代都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数 J 是迭代次数的一个函数,它应该会随着每次迭代而减少,如果 J 在某次迭代中增加了,那肯定出了问题,也许你的学习率太大。
使用mini-batch梯度下降法,如果你作出成本函数在整个过程中的图,则并不是每次迭代都是下降的,特别是在每次迭代中,你要处理的是 X { t } X^{\{t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t} ,作出成本函数 J { t } J^{\{t\}} J{t} 的图只和 X { t } X^{\{t\}} X{t} , Y { t } Y^{\{t\}} Y{t} 有关,成本函数 J 的图的结果走向朝下,但有更多的噪声。这是因为每次迭代下你都在训练不同的样本集或者说训练不同的mini-batch。
使用mini-batch梯度下降法时,需要决定的变量之一是mini-batch的大小, m 就是训练集的大小,极端情况下,如果mini-batch的大小等于 m ,其实就是batch梯度下降法;假设mini-batch大小为1,就是随机梯度下降法。
在随机梯度下降法中,从某一点开始,我们重新选取一个起始点,每次迭代,你只对一个样本进行梯度下降,大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此。
另外,随机梯度下降法的一大缺点是,你会失去所有向量化带给你的加速,因为一次性只处理了一个训练样本,这样效率过于低下,所以实践中最好选择不大不小的mini-batch尺寸,实际上学习率达到最快。一方面,你得到了大量向量化,如果mini-batch大小为1000个样本,你就可以对1000个样本向量化,比你一次性处理多个样本快得多。另一方面,你不需要等待整个训练集被处理完就可以开始进行后续工作。
指数加权平均
指数加权平均值,也被称为移动平均值,从名字可以看出来它其实也是一种求平均值的算法,在后面介绍动量、RMSProp和Adam的时候都需要用到它。
计算
指数加权平均计算公式:
v t = β v t − 1 + ( 1 − β ) θ t v_t = \beta v_{t-1} + (1- \beta)\theta _t vt=βvt−1+(1−β)θt
其中 β \beta β指的是系数通常取0.9, v n v_n vn 表示的是当前的指数加权平均值, θ \theta θ表示的是当前的值。下面用一个例子来介绍。
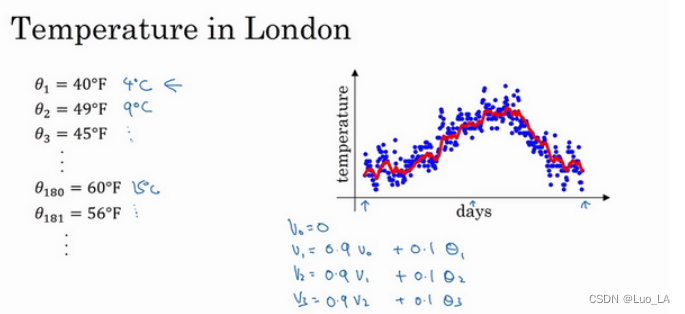
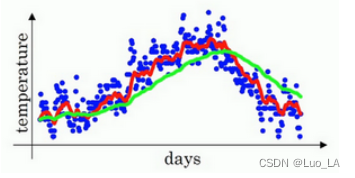
如上图是某年英国伦敦一年的温度散点图,用该数据计算温度的移动平均值。
你要做的是,首先使 v 0 = 0 v_0=0 v0=0, 每天,需要使用0.9的加权数之前的数值加上当日温度的0.1倍,即 v 1 = 0.9 v 0 + 0.1 θ 1 v_1=0.9v_0+0.1\theta_1 v1=0.9v0+0.1θ1,所以这里是第一天的温度值。
第二天,又可以获得一个加权平均数,0.9乘以之前的值加上当日的温度0.1倍,即 v 2 = 0.9 v 0 + 0.1 θ 2 v_2=0.9v_0+0.1\theta_2 v2=0.9v0+0.1θ2,以此类推。
如此计算,然后用红线作图,便得到如下图所示的结果。
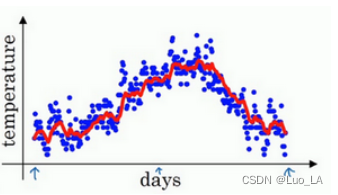
在计算时,可视 v t v_t vt 大概是 1 1 − β \frac{1}{1-\beta} 1−β1 的每日平均温度,如果 β \beta β是0.9, v t v_t vt将是十天的平均值,也就是上图红心部分。
如果将 β \beta β设置为接近1的一个值,比如0.98,计算 1 1 − 0.98 = 50 \frac{1}{1-0.98}=50 1−0.981=50 ,这就是粗略平均了一下过去50天的温度,作图得到下图所示的绿线。
对于 β = 0.98 \beta=0.98 β=0.98 时,要注意几点,你得到的曲线要平坦一些,原因在于你多平均了几天的温度,所以这个曲线,波动更小,更加平坦,缺点是曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟,因为当 β = 0.98 \beta=0.98 β=0.98 ,相当于给前一天的值加了太多权重,只有0.02的权重给了当日的值,所以温度变化时,温度上下起伏,当 β \beta β 较大时,指数加权平均值适应地更缓慢一些。
如果将 β \beta β设置为0.5, 将只平均了两天的温度。
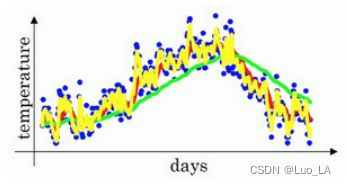
由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,有可能出现异常值,但是这个曲线能够更快适应温度变化。
通过调整这个参数( β \beta β 在后面的学习算法中将是一个很重要的参数),可以取得稍微不同的效果,往往中间有某个值效果最好, β \beta β 为中间值时得到的红色曲线,比起绿线和黄线更好地平均了温度。
指数加权平均数公式的好处之一在于,它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了,正因为这个原因,其效率,它基本上只占用一行代码,计算指数加权平均数也只占用单行数字的存储和内存。
偏差修正
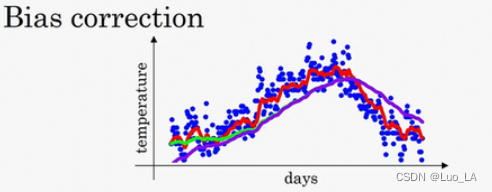
在实际的计算过程中,在 β \beta β 等于 0.98 的时候,得到的并不是绿色曲线,而是紫色曲线,你可以注意到紫色曲线的起点较低。这是因为在计算移动平均数的时候,初始化 v 0 = 0 v_0=0 v0=0, v 1 = 0.9 v 8 0 + 0.02 θ 1 v_1=0.9v8_0+0.02\theta_1 v1=0.9v80+0.02θ1,但是 v 0 = 0 v_0=0 v0=0,所以计算得 v 1 = 0.02 θ 1 v_1=0.02\theta_1 v1=0.02θ1,因此得到得值会小很多,第一天温度的估测是不准的,同样代入 v 2 v_2 v2得计算公式, v 2 v_2 v2也不能很好得估测出这一年得前两天的温度。
有个办法可以修改这一估测,让估测变得更好,更准确,特别是在估测初期,也就是不用 v t v_t vt ,而是用 v t 1 − β t \frac{v_t}{1-\beta^t} 1−βtvt。
举个例子,当 t = 2 t=2 t=2时, 1 − β t = 1 − 0.9 8 2 = 0.0396 1-\beta^t=1-0.98^2=0.0396 1−βt=1−0.982=0.0396,因此对第二天温度的估测变成了 v 2 0.0396 = 0.0196 θ 1 + 0.02 θ 2 0.0396 \frac{v_2}{0.0396}=\frac{0.0196\theta_1+0.02\theta_2}{0.0396} 0.0396v2=0.03960.0196θ1+0.02θ2,也就是 θ 1 \theta_1 θ1 和 θ 2 \theta_2 θ2的加权平均数,并去除了偏差。你会发现随着 t t t 增加, β t \beta^t βt 接近于0,所以当 t t t 很大的时候,偏差修正几乎没有作用,因此当 t t t 较大的时候,紫线基本和绿线重合了。
包含动量的梯度下降
在普通的梯度下降中,如果遇到了比较复杂的情况,就会出现:如果学习率过大,摆动过大,误差较大;如果学习率过小,又会使得迭代次数增加,学习时间会很长。在神经网络模型中就常常会遇到上面这些情况,总是会出现解一种在小范围震荡而很难达到最优解的情况。
而动量梯度则可以比较好的避免上述问题。它的过程类似于一个有质量的小球在函数曲线上向下滚落。当球滚到最低点后,由于具有惯性还会继续上升一段,然后再滚落回来,再经过最低点上去…最终小球就停留到最低点处。而且由于小球具有惯性这一点,当函数曲线或曲面比较陡峭复杂时,它便可以越过这些而尽快地达到最低点。
动量梯度下降算法在梯度下降算法的基础上做了一些优化,梯度下降算法的收敛如下图所示。
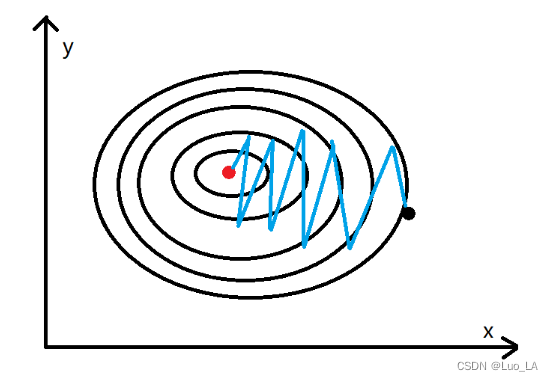
其中黑点表示的是起点,红点表示的是终点。通过梯度下降算法不停的迭代,慢慢的从黑点移动到红点的位置,通过上图可以发现黑点的移动轨迹在y方向上一直存在上下波动,而这个对于黑点移动到红点的位置没有任何的帮助,反而是在浪费时间,因为我们更希望减少这种不必要的计算,加速x轴方向上的移动步伐,如下图所示
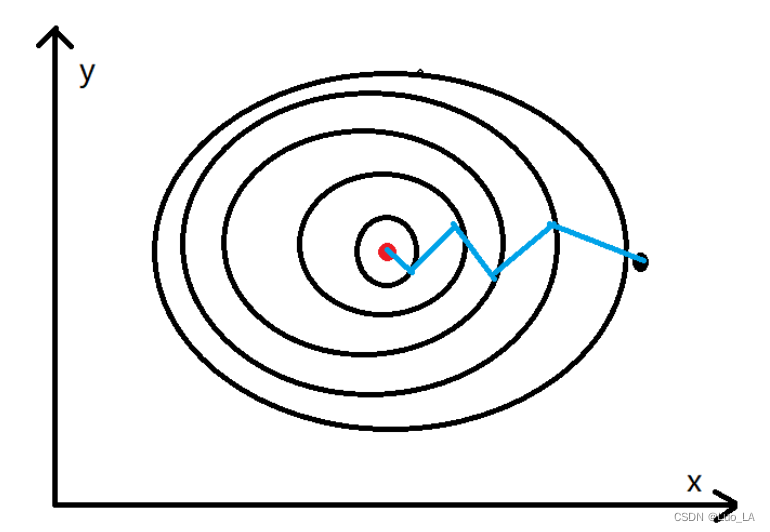
实现
梯度下井算法的参数更新公式:
w = w − α ∗ d w w=w-\alpha*dw w=w−α∗dw
b = b − α ∗ d b b=b-\alpha*db b=b−α∗db
动量梯度下降算法参数更新公式:
v w = β v w + ( 1 − β ) d w v_w = \beta v_w + (1- \beta)dw vw=βvw+(1−β)dw
v b = β v b + ( 1 − β ) d b v_b = \beta v_b + (1- \beta)db vb=βvb+(1−β)db
w = w − α ∗ v w w=w-\alpha*v_w w=w−α∗vw
b = b − α ∗ v b b=b-\alpha*v_b b=b−α∗vb
上式中 α \alpha α 表示学习率,通过上式可以发现,动量梯度下降算法在更新参数的时候并不是直接使用的梯度,它还利用到以前的梯度,具体到多少,与 β \beta β 的大小有关, β \beta β 越大使用到以前的梯度越多, β \beta β 越小使用到以前的梯度越小。
因为在y轴方向上梯度是有正有负的,所以均值就近似为0,即在y轴方向上不会有太大的变化。而x轴方向上的梯度都是一致的,所以能够为x轴方向上提供动量加速更新。由于动量梯度下降算法,在更新参数的时候不仅使用到了当前的梯度还使用到了以前梯度的均值作为动量,当陷入到局部极小值(梯度接近于0),在更新的时候动量梯度下降算法还可以利用以前梯度的均值来跳出局部极小值,而梯度下降算法只会陷入到局部极小值。
RMSprop算法
RMSprop算法全称root mean square prop,RMSprop算法的思想和Moment算法的思想是一致的都是通过减少在y轴方向上的抖动,加大x轴方向上的移动步长。而在实现上略有不同,Moment主要是利用累积以前的梯度来实现加速,而RMSprop算法的思想是利用梯度下降算法在y轴方向上的梯度比较大,而在x轴方向上的梯度相对较小。在进行参数更新的时候,让y轴方向上的梯度( d b db db)除以一个大的数,这样y轴更新的幅度就小。而x轴方向上的梯度( d w dw dw)除以一个小的数,这样x轴更新的幅度就大。从而实现了,减小了y轴方向上的更新步长,增大了x轴方向上的更新步长,使得算法能够更快的收敛。更新公式如下:
S d w = β S d w + ( 1 − β ) d w 2 S_{dw} = \beta S_{dw} + (1- \beta)dw^2 Sdw=βSdw+(1−β)dw2
S d b = β S d b + ( 1 − β ) d b 2 S_{db} = \beta S_{db} + (1- \beta)db^2 Sdb=βSdb+(1−β)db2
w = w − α ∗ d w S d w + ε w=w-\alpha*\frac{dw}{\sqrt{S_{dw}}+\varepsilon } w=w−α∗Sdw+εdw
b = b − α ∗ d w S d b + ε b=b-\alpha*\frac{dw}{\sqrt{S_{db}}+\varepsilon } b=b−α∗Sdb+εdw
为了避免在更新参数的时候,分母为0,所以需要在分母上加上一个极小的数 ε \varepsilon ε,通常取 1 0 − 8 10^{-8} 10−8。 d w 2 dw^2 dw2 表示的是参数 w w w 的梯度的平方也称为微分的平方。
把纵轴和横轴方向分别称为 b b b 和 w w w ,只是为了方便展示而已。实际中,你会处于参数的高维度空间,所以需要消除摆动的垂直维度,你需要消除摆动,实际上是参数 w 1 , w 2 w_1,w_2 w1,w2 等的合集,水平维度可能 w 3 , w 4 w_3,w_4 w3,w4 等等,因此把 b b b 和 w w w 分开只是方便说明。实际中 d w dw dw 是一个高维度的参数向量, d b db db 也是一个高维度参数向量。
Adam算法
Adam算法全称Adaptive Moment Estimation,主要是结合了Moment算法和RMSprop算法。公式如下:
v d w = 0 , v d b = 0 , S d w = 0 , S d b = 0 v_{dw}=0,v_{db}=0,S_{dw}=0,S_{db}=0 vdw=0,vdb=0,Sdw=0,Sdb=0
v d w = β 1 v d w + ( 1 − β 1 ) d w v_{dw} = \beta_1 v_{dw} + (1- \beta_1)dw vdw=β1vdw+(1−β1)dw
v d b = β 1 v d b + ( 1 − β 1 ) d b v_{db} = \beta_1 v_{db} + (1- \beta_1)db vdb=β1vdb+(1−β1)db
S d w = β 2 S d w + ( 1 − β ) d w 2 S_{dw} = \beta_2 S_{dw} + (1- \beta)dw^2 Sdw=β2Sdw+(1−β)dw2
S d b = β 2 S d b + ( 1 − β ) d b 2 S_{db} = \beta_2 S_{db} + (1- \beta)db^2 Sdb=β2Sdb+(1−β)db2
参数更新:
w = w − α ∗ v d w S d w + ε w=w-\alpha*\frac{v_{dw}}{\sqrt{S_{dw}}+\varepsilon } w=w−α∗Sdw+εvdw
b = b − α ∗ v d b S d b + ε b=b-\alpha*\frac{v_{db}}{\sqrt{S_{db}}+\varepsilon } b=b−α∗Sdb+εvdb
在使用指数加权平均值算法的时候,可能存在初始化的偏差比较大的情况,可以通过下面的方法进行偏差修正:
v d w c o r r e c t e d = v d w 1 − β 1 t v_{dw}^{corrected}=\frac{v_{dw}}{1-\beta_{1}^{t}} vdwcorrected=1−β1tvdw, v d b c o r r e c t e d = v d b 1 − β 1 t v_{db}^{corrected}=\frac{v_{db}}{1-\beta_{1}^{t}} vdbcorrected=1−β1tvdb
S d w c o r r e c t e d = S d w 1 − β 2 t S_{dw}^{corrected}=\frac{S_{dw}}{1-\beta_{2}^{t}} Sdwcorrected=1−β2tSdw, S d b c o r r e c t e d = S d b 1 − β 2 t S_{db}^{corrected}=\frac{S_{db}}{1-\beta_{2}^{t}} Sdbcorrected=1−β2tSdb
w = w − α ∗ v d w c o r r e c t e d S d w c o r r e c t e d + ε w=w-\alpha*\frac{v_{dw}^{corrected}}{\sqrt{S_{dw}^{corrected}}+\varepsilon } w=w−α∗Sdwcorrected+εvdwcorrected, b = b − α ∗ v d b c o r r e c t e d S d b c o r r e c t e d + ε b=b-\alpha*\frac{v_{db}^{corrected}}{\sqrt{S_{db}^{corrected}}+\varepsilon } b=b−α∗Sdbcorrected+εvdbcorrected
上式中 t t t 表示迭代次数, β 1 \beta_1 β1 是Momentum的超参数通常取0.9, β 2 \beta_2 β2 是RMSprop的超参数通常取0.999, ε \varepsilon ε 是用来避免分母为0的情况取 1 0 − 8 10^{-8} 10−8。
参考文章
https://blog.csdn.net/weixin_36815313/article/details/105432576
https://blog.csdn.net/sinat_29957455/article/details/88088720
相关文章:
改善神经网络——优化算法(mini-batch、动量梯度下降法、Adam优化算法)
改善神经网络——优化算法 梯度下降Mini-batch 梯度下降(Mini-batch Gradient Descent)指数加权平均包含动量的梯度下降RMSprop算法Adam算法 优化算法可以使神经网络运行的更快,机器学习的应用是一个高度依赖经验的过程,伴随着大量…...
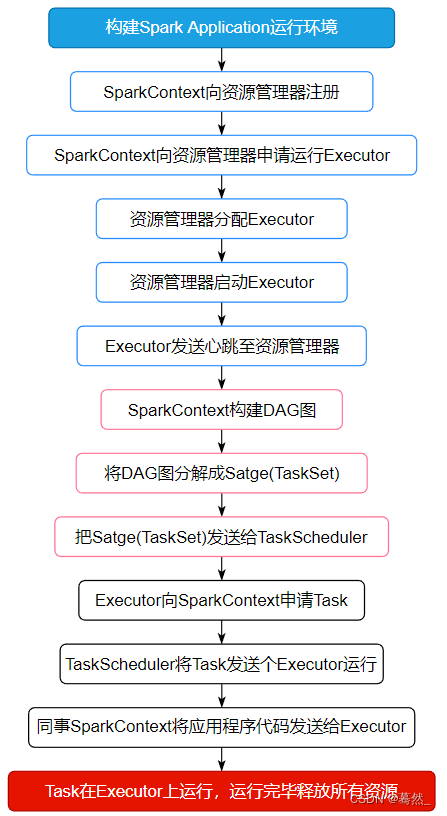
大数据面试题:Spark的任务执行流程
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:1)Spark的工作流程?2)Spark的调度流程;3)Spark的任务调度原理…...

通过 Amazon SageMaker JumpStart 部署 Llama 2 快速构建专属 LLM 应用
来自 Meta 的 Llama 2 基础模型现已在 Amazon SageMaker JumpStart 中提供。我们可以通过使用 Amazon SageMaker JumpStart 快速部署 Llama 2 模型,并且结合开源 UI 工具 Gradio 打造专属 LLM 应用。 Llama 2 简介 Llama 2 是使用优化的 Transformer 架构的自回归语…...

ansible远程执行命令
一、ansible简介 需要在一台机器上搭建ansible环境,且配置目的ip的密码,通道没有问题即可下发命令 使用的通道是ssh(端口:36000) 二、搭建细节 1、安装ansible yum install -y ansible 2、把目的ip密码写到配置…...

Windows快速恢复丢失的颜色校准
场景 有时开机或启动某个软件后,颜色校准(设置项:校准显示器颜色)会丢失,每次重新设置很麻烦。 文章首发及后续更新:https://mwhls.top/4723.html,无图/无目录/格式错误/更多相关请至首发页查看…...

Vue安装单文件组件
安装 npm npm 全称为 Node Package Manager,是一个基于Node.js的包管理器,也是整个Node.js社区最流行、支持的第三方模块最多的包管理器。 npm -v由于网络原因 安装 cnpm npm install -g cnpm --registryhttps://registry.npm.taobao.org安装 vue-cli…...

小白的Node.js学习笔记大全---不定期更新
Node.js是什么 Node. js 是一个基于 Chrome v8 引擎的服务器端 JavaScript 运行环境Node. js 是一个事件驱动、非阻塞式I/O 的模型,轻量而又高效Node. js 的包管理器 npm 是全球最大的开源库生态系统 特性 单一线程 Node.js 沿用了 JavaScript 单一线程的执行特…...
)
第二周晨考自测(2.0)
1.冒泡排序 冒泡排序是数组解构中的常见排序算法之一。规则如下:先遍历数组,让相邻的两个数据进行比较,如果前一个比后一个大,那么就把这两个数据交换位置,经过一轮遍历之后,最大的那个数字就排在数组最后…...
(单视图测量))
计算机视觉之三维重建(三)(单视图测量)
2D变换 等距变换 旋转平移保留形状、面积通常描述刚性物体运动 相似变换 在等距变换的基础增加缩放特点 射影变换 共线性、四共线点的交比保持不变 仿射变换 面积比值、平行关系等不变仿射变换是特殊的射影变换 影消点与影消线 2D无穷远点 两直线的交点可由两直线的…...

docker 批量快速删除容器和镜像
一、批量删除镜像 如果你想要批量删除 Docker 镜像,可以使用各种命令。以下是一些示例: 1. 删除所有镜像: docker rmi $(docker images -q) 2. 删除所有未标记的镜像(即 <none> 镜像): docker rmi $(docker images -f "dangling=true" -q) 请注意…...

【数据分析入门】Matplotlib
目录 零、图形解析与工作流0.1 图形解析0.2 工作流 一、准备数据1.1 一维数据1.2 二维数据或图片 二、绘制图形2.1 画布2.2 坐标轴 三、绘图例程3.1 一维数据3.2 向量场3.3 数据分布3.4 二维数据或图片 四、自定义图形4.1 颜色、色条与色彩表4.2 标记4.3 线型4.4 文本与标注4.5…...
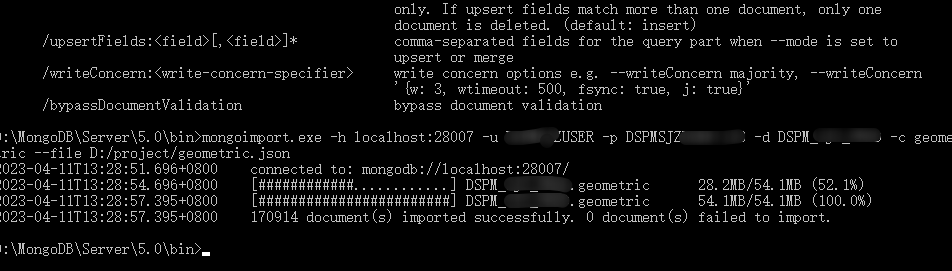
mongodb.使用自带命令工具导出导入数据
在一次数据更新中,同事把老数据进行了清空操作,但是新的逻辑数据由于某种原因(好像是她的电脑中病毒了),一直无法正常连接数据库进行数据插入,然后下午2点左右要给甲方演示,所以要紧急恢复本地的…...

IndexError: tensors used as indices must be long, byte or bool tensors
运行出现报错。修改数据格式 输出sample_ids的值,可以看到数据类型是 torch.int32 解决 需要将sample_ids类型转为long,修改方式: idx idx.type(torch.long)或 idx self.tensor(idx, dtypetorch.long)参考: IndexError: tenso…...

设计模式 : 单例模式笔记
文章目录 一.单例模式二.单例模式的两种实现方式饿汉模式懒汉模式 一.单例模式 一个类只能创建一个对象,这样的类的设计模式就称为单例模式,该模式保证系统中该类只能有一个实例(并且父子进程共享),一个很典型的单例类就是CSTL的内存池C单例模式的基本设计思路: 私有化构造函数…...

深度优先搜索算法
目录 4.1 二叉树的最大深度(简单):深度优先搜索 4.2 对称二叉树(简单):递归 4.3 岛屿数量(中等):深度优先搜索 4.4 岛屿的最大面积(中等)&…...

k8s ----POD控制器详解
目录 一:pod控制器 1、Pod控制器及其功用 2、pod控制器类型 3、Pod与控制器之间的关系 二:Deployment 三:SatefulSet 1、StatefulSet组成 2、为什么要有headless? 3、为什么要有volumeClaimTemplate? 4、实现…...
ReactNative进阶(三十四):ipa Archive 阶段报错error: Multiple commands produce问题修复及思考
文章目录 一、前言二、问题描述三、问题解决四、拓展阅读五、拓展阅读 一、前言 在应用RN开发跨平台APP阶段,从git中拉取项目,应用Jenkins进行组包时,发现最终生成的ipa安装包版本号始终与项目中设置的版本号不一致。 二、问题描述 经过仔…...

MySQL索引ES索引
MySQL MySQL索引的种类 按照索引列值的唯一性:索引可分为唯一索引和非唯一索引; 唯一索引:此索引的每一个索引值只对应唯一的数据记录,对于单列唯一性索引,这保证单列不包含重复的值。对于多列唯一性索引,保证多个值的组合不重复。主键索引是唯一索引的特定类型。该索引…...
webSocket 聊天室 node.js 版
全局安装vue脚手架 npm install vue/cli -g 创建 vue3 ts 脚手架 vue create vue3-chatroom 后端代码 src 同级目录下建 server: const express require(express); const app express(); const http require(http); const server http.createServer(app);const io req…...
iptables防火墙(SNAT与DNAT)
目录 1 SNAT 1.1 SNAT原理与应用 1.2 SNAT工作原理 1.3 SNAT转换前提条件 2 SNAT示例 编辑 2.1 网关服务器配置 2.1.1 网关服务器配置网卡 2.1.2 开启SNAT命令 2.2 内网服务器端配置 2.3 外网服务器端配置 2.4 网卡服务器端添加规则 2.5 SNAT 测试 3 DNAT 3.1 网卡…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...
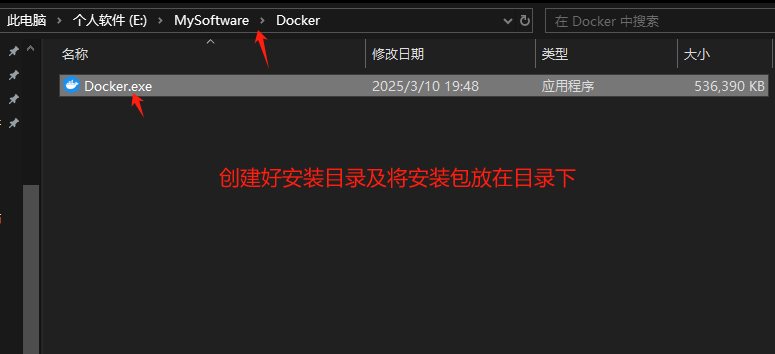
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...