10- 天猫用户复购预测 (机器学习集成算法) (项目十) *
项目难点
- merchant: 商人
- 重命名列名: user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)
- 数据类型转换: user_log['item_id'] = user_log['item_id'].astype('int32')
- 主要使用方法: xgboost, lightbm
- 竞赛地址: 天猫复购预测之挑战Baseline_学习赛_天池大赛-阿里云天池
- 排名: 448/9361 score: 0.680989
项目简介:
阿里巴巴天池天猫复购预测的机器学习项目, 使用数据分析, 通过机器学习中的线性分类算法, 进行建模, 从而预测消费者行为, 复购情况 .
- 数据分析
- 特征工程
- 算法使用
- 算法集成
1 数据处理
1.1 模型导入
import gc # 垃圾回收
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')# 导入分析库
# 数据拆分
from sklearn.model_selection import train_test_split
# 同分布数据拆分
from sklearn.model_selection import StratifiedGroupKFold
import lightgbm as lgb
import xgboost as xgb1.2 加载数据
%%time
# 加载数据
# 用户行为日志
user_log = pd.read_csv('./data_format1/user_log_format1.csv', dtype = {'time_stamp':'str'})
# 用户画像
user_info = pd.read_csv('./data_format1/user_info_format1.csv')
# 训练数据和测试数据
train_data = pd.read_csv('./data_format1/train_format1.csv')
test_data = pd.read_csv('./data_format1/test_format1.csv')1.3 查看数据
print('---data shape---')
for data in [user_log, user_info, train_data, test_data]:print(data.shape) 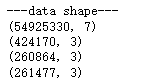
print('---data info ---')
for data in [user_log, user_info, train_data, test_data]:print(data.info()) 
display(user_info.head()) 
display(train_data.head(),test_data.head()) 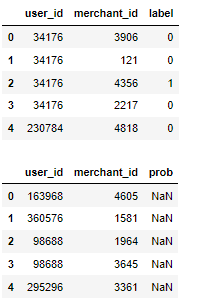
1.4 数据集成
train_data['origin'] = 'train'
test_data['origin'] = 'test'
# 集成
all_data = pd.concat([train_data, test_data], ignore_index=True, sort=False)
# prob测试数据中特有的一列
all_data.drop(['prob'], axis=1, inplace=True) # 删除概率这一列
display(all_data.head(),all_data.shape) 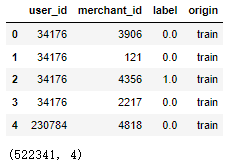
# 连接user_info表,通过user_id关联
all_data = all_data.merge(user_info, on='user_id', how='left')
display(all_data.shape,all_data.head()) 
# 使用 merchant_id(原列名seller_id)
user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)del train_data,test_data,user_info
gc.collect()1.5 数据类型转换
%%time
display(user_log.info()) 
%%time
display(user_log.head()) 
%%time
# 用户行为数据类型转换
user_log['user_id'] = user_log['user_id'].astype('int32')
user_log['merchant_id'] = user_log['merchant_id'].astype('int32')
user_log['item_id'] = user_log['item_id'].astype('int32')
user_log['cat_id'] = user_log['cat_id'].astype('int32')
user_log['brand_id'].fillna(0, inplace=True)
user_log['brand_id'] = user_log['brand_id'].astype('int32')
user_log['time_stamp'] = pd.to_datetime(user_log['time_stamp'], format='%H%M')
user_log['action_type'] = user_log['action_type'].astype('int32')
display(user_log.info(),user_log.head()) 
display(all_data.isnull().sum()) 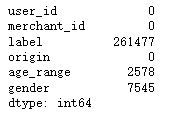
# 缺失值填充
all_data['age_range'].fillna(0, inplace=True)
all_data['gender'].fillna(2, inplace=True)
all_data.isnull().sum() 
all_data.info() 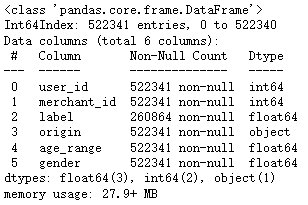
all_data['age_range'] = all_data['age_range'].astype('int8')
all_data['gender'] = all_data['gender'].astype('int8')
all_data['label'] = all_data['label'].astype('str')
all_data['user_id'] = all_data['user_id'].astype('int32')
all_data['merchant_id'] = all_data['merchant_id'].astype('int32')
all_data.info() 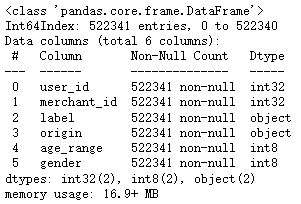
1.6 用户特征工程(5min)
%%time
##### 特征处理
##### User特征处理
groups = user_log.groupby(['user_id'])# 用户交互行为数量 u1
temp = groups.size().reset_index().rename(columns={0:'u1'})
all_data = all_data.merge(temp, on='user_id', how='left')# 细分
# 使用 agg 基于列的聚合操作,统计唯一值个数 item_id, cat_id, merchant_id, brand_id
# 用户,交互行为:点了多少商品呢?
temp = groups['item_id'].agg([('u2', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')# 用户,交互行为,具体统计:类目多少
temp = groups['cat_id'].agg([('u3', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')temp = groups['merchant_id'].agg([('u4', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')temp = groups['brand_id'].agg([('u5', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')# 购物时间间隔特征 u6 按照小时
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['u6'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id', 'u6']], on='user_id', how='left')# 统计操作类型为0,1,2,3的个数
temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'u7', 1:'u8', 2:'u9', 3:'u10'})
all_data = all_data.merge(temp, on='user_id', how='left')del temp,groups
gc.collect()all_data.head() 
1.7 店铺特征工程(5min)
%%time
##### 商家特征处理
groups = user_log.groupby(['merchant_id'])# 商家被交互行为数量 m1
temp = groups.size().reset_index().rename(columns={0:'m1'})
all_data = all_data.merge(temp, on='merchant_id', how='left')# 统计商家被交互的 user_id, item_id, cat_id, brand_id 唯一值
temp = groups['user_id', 'item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(columns={'user_id':'m2','item_id':'m3', 'cat_id':'m4', 'brand_id':'m5'})
all_data = all_data.merge(temp, on='merchant_id', how='left')# 统计商家被交互的 action_type 唯一值
temp = groups['action_type'].value_counts().unstack().reset_index().rename( columns={0:'m6', 1:'m7', 2:'m8', 3:'m9'})
all_data = all_data.merge(temp, on='merchant_id', how='left')del temp
gc.collect()display(all_data.tail()) 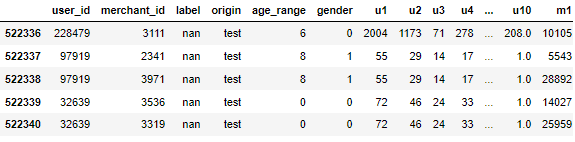
1.8 用户和店铺联合特征工程(4min)
%%time
##### 用户+商户特征
groups = user_log.groupby(['user_id', 'merchant_id'])# 用户在不同商家交互统计
temp = groups.size().reset_index().rename(columns={0:'um1'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')# 统计用户在不同商家交互的 item_id, cat_id, brand_id 唯一值
temp = groups['item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(columns={'item_id':'um2','cat_id':'um3','brand_id':'um4'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')# 统计用户在不同商家交互的 action_type 唯一值
temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'um5',1:'um6',2:'um7',3:'um8'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')# 统计用户在不同商家购物时间间隔特征 um9 按照小时
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['um9'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id','merchant_id','um9']], on=['user_id', 'merchant_id'], how='left')del temp,groups
gc.collect()display(all_data.head()) 
1.9 购买点击比
all_data['r1'] = all_data['u9']/all_data['u7'] # 用户购买点击比
all_data['r2'] = all_data['m8']/all_data['m6'] # 商家购买点击比
all_data['r3'] = all_data['um7']/all_data['um5'] # 不同用户不同商家购买点击比
display(all_data.head()) 
1.10 空数据填充
display(all_data.isnull().sum()) 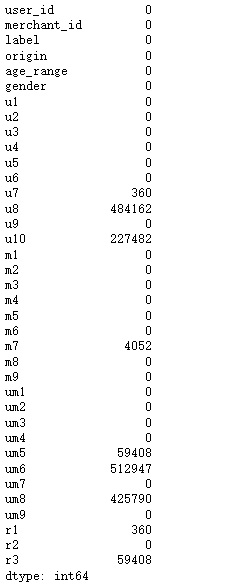
all_data.fillna(0, inplace=True)
all_data.isnull().sum()1.11 年龄性别类别型转换
all_data['age_range'] 
%%time
# 修改age_range字段名称为 age_0, age_1, age_2... age_8
# 独立编码
temp = pd.get_dummies(all_data['age_range'], prefix='age')
display(temp.head(10))
all_data = pd.concat([all_data, temp], axis=1) 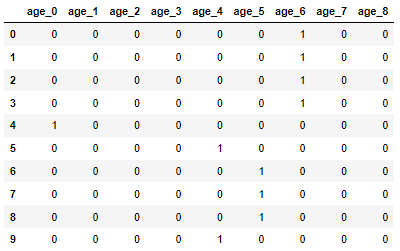
# 性别转换
temp = pd.get_dummies(all_data['gender'], prefix='g')
all_data = pd.concat([all_data, temp], axis=1) # 列进行合并# 删除原数据
all_data.drop(['age_range', 'gender'], axis=1, inplace=True)del temp
gc.collect()all_data.head() 
1.12 数据存储
%%time
# train_data、test-data
train_data = all_data[all_data['origin'] == 'train'].drop(['origin'], axis=1)
test_data = all_data[all_data['origin'] == 'test'].drop(['label', 'origin'], axis=1)train_data.to_csv('train_data.csv')
test_data.to_csv('test_data.csv')2 算法建模预测
# 训练数据和目标值
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']# 数据拆分保留20%作为测试数据
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_y, test_size=.2)2.1 LGB 模型
def lgb_train(X_train, y_train, X_valid, y_valid, verbose=True):model_lgb = lgb.LGBMClassifier(max_depth=10, # 8 # 树最大的深度n_estimators=5000, # 集成算法,树数量min_child_weight=100, colsample_bytree=0.7, # 特征筛选subsample=0.9, # 样本采样比例learning_rate=0.1) # 学习率model_lgb.fit(X_train, y_train,eval_metric='auc',eval_set=[(X_train, y_train), (X_valid, y_valid)],verbose=verbose, # 是否打印输出训练过程early_stopping_rounds=10) # 早停,等10轮决策,评价指标不在变化,停止print(model_lgb.best_score_['valid_1']['auc'])return model_lgbX_train 
model_lgb = lgb_train(X_train.values, y_train, X_valid.values, y_valid, verbose=True) 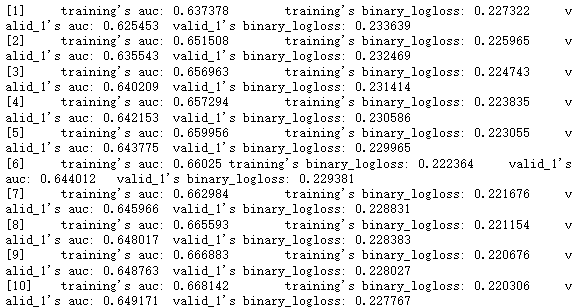
%%time
prob = model_lgb.predict_proba(test_data.values) # 预测
submission = pd.read_csv('./data_format1/test_format1.csv')# 复购的概率
submission['prob'] = pd.Series(prob[:,1]) # 预测数据赋值给提交数据
display(submission.head())
submission.to_csv('submission_lgb.csv', index=False)del submission
gc.collect() 
2.2 XGB 模型
def xgb_train(X_train, y_train, X_valid, y_valid, verbose=True):model_xgb = xgb.XGBClassifier(max_depth=10, # raw8n_estimators=5000,min_child_weight=300, colsample_bytree=0.7, subsample=0.9, learing_rate=0.1)model_xgb.fit(X_train, y_train,eval_metric='auc',eval_set=[(X_train, y_train), (X_valid, y_valid)],verbose=verbose,early_stopping_rounds=10) # 早停法,如果auc在10epoch没有进步就stopprint(model_xgb.best_score)return model_xgb模型训练
model_xgb = xgb_train(X_train, y_train, X_valid, y_valid, verbose=False)模型预测
%%time
prob = model_xgb.predict_proba(test_data)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pd.Series(prob[:,1])
submission.to_csv('submission_xgb.csv', index=False)
display(submission.head())
del submission
gc.collect()3 交叉验证多轮建模
# 构造训练集和测试集
def get_train_test_datas(train_df,label_df):skv = StratifiedKFold(n_splits=10, shuffle=True)trainX = []trainY = []testX = []testY = []# 索引:训练数据索引train_index,目标值的索引test_indexfor train_index, test_index in skv.split(X=train_df, y=label_df): # 10轮for循环train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \train_df.iloc[test_index, :], label_df.iloc[test_index]trainX.append(train_x)trainY.append(train_y)testX.append(test_x)testY.append(test_y)return trainX, testX, trainY, testY3.1 LGB 模型(1min)
%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']# 拆分为10份训练数据和验证数据
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)print('----训练数据,长度',len(X_train))
print('----验证数据,长度',len(X_valid))pred_lgbms = [] # 列表,接受目标值,10轮,平均值for i in range(10):print('\n=========LGB training use Data {}/10===========\n'.format(i+1))model_lgb = lgb.LGBMClassifier(max_depth=10, # 8n_estimators=1000,min_child_weight=100,colsample_bytree=0.7,subsample=0.9,learning_rate=0.05)model_lgb.fit(X_train[i].values, y_train[i],eval_metric='auc',eval_set=[(X_train[i].values, y_train[i]), (X_valid[i].values, y_valid[i])],verbose=False,early_stopping_rounds=10)print(model_lgb.best_score_['valid_1']['auc'])pred = model_lgb.predict_proba(test_data.values)pred = pd.DataFrame(pred[:,1]) # 将预测概率(复购)去处理,转换成DataFramepred_lgbms.append(pred)# 求10轮平均值生成预测结果,保存
# 每一轮的结果,作为一列,进行了添加
pred_lgbms = pd.concat(pred_lgbms, axis=1) # 级联,列进行级联# 加载提交数据
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_lgbms.mean(axis=1) # 10轮训练的平均值
submission.to_csv('submission_KFold_lgb.csv', index=False)3.2 XGB 模型(4min)
# 构造训练集和测试集
def get_train_test_datas(train_df,label_df):skv = StratifiedKFold(n_splits=20, shuffle=True)trainX = []trainY = []testX = []testY = []# 索引:训练数据索引train_index,目标值的索引test_indexfor train_index, test_index in skv.split(X=train_df, y=label_df):# 10轮for循环train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \train_df.iloc[test_index, :], label_df.iloc[test_index]trainX.append(train_x)trainY.append(train_y)testX.append(test_x)testY.append(test_y)return trainX, testX, trainY, testY%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']# 拆分为20份训练数据和验证数据
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)print('------数据长度',len(X_train),len(y_train))pred_xgbs = []
for i in range(20):print('\n============XGB training use Data {}/20========\n'.format(i+1))model_xgb = xgb.XGBClassifier(max_depth=10, # raw8n_estimators=5000,min_child_weight=200, colsample_bytree=0.7, subsample=0.9,learning_rate = 0.1)model_xgb.fit(X_train[i], y_train[i],eval_metric='auc',eval_set=[(X_train[i], y_train[i]), (X_valid[i], y_valid[i])],verbose=False,early_stopping_rounds=10 # 早停法,如果auc在10epoch没有进步就stop) print(model_xgb.best_score)pred = model_xgb.predict_proba(test_data)pred = pd.DataFrame(pred[:,1])pred_xgbs.append(pred)# 求20轮平均值生成预测结果,保存
pred_xgbs = pd.concat(pred_xgbs, axis=1)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_xgbs.mean(axis=1)
submission.to_csv('submission_KFold_xgb.csv', index=False)相关文章:
10- 天猫用户复购预测 (机器学习集成算法) (项目十) *
项目难点 merchant: 商人重命名列名: user_log.rename(columns{seller_id:merchant_id}, inplaceTrue)数据类型转换: user_log[item_id] user_log[item_id].astype(int32)主要使用方法: xgboost, lightbm竞赛地址: 天猫复购预测之挑战Baseline_学习赛_天池大赛-阿里云天池…...

对于《MySQL 实战45讲》的理解
一.理论 一条SQL执行过程 连接器分析器优化器执行器 索引 索引的出现其实就是为了提高数据查询的效率,就像书的目录一样 常见索引数据结构(每碰到一个新数据库,我们需要先关注它的数据模型,这样才能从理论上分析出这个数据库的适用场景) 哈希…...

XQuery 函数
XQuery 1.0、XPath 2.0 以及 XSLT 2.0 共享相同的函数库。 XQuery 函数 XQuery 含有超过 100 个内建的函数。这些函数可用于字符串值、数值、日期以及时间比较、节点和 QName 操作、序列操作、逻辑值等等。您也可在 XQuery 中定义自己的函数。 XQuery 内建函数 XQuery 函数命…...
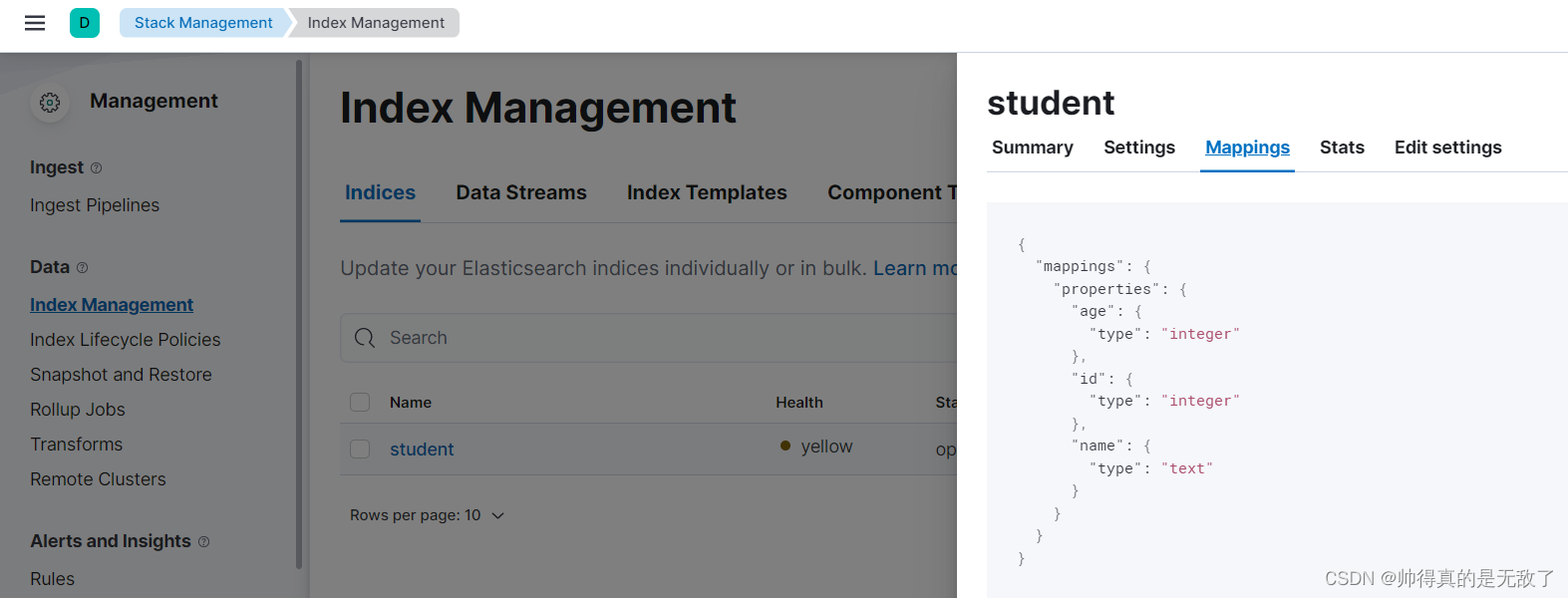
Elasticsearch的安装及常用操作
文章目录一、Elasticsearch的介绍1、Elasticsearch索引2、Elasticsearch的介绍二、Elasticsearch的安装1、安装ES服务2、安装kibana3、Docker安装ES4、Docker安装Kibana三、ES的常用操作1、索引操作2、文档操作3、域的属性3.1 index3.2 type3.3 store总结一、Elasticsearch的介…...
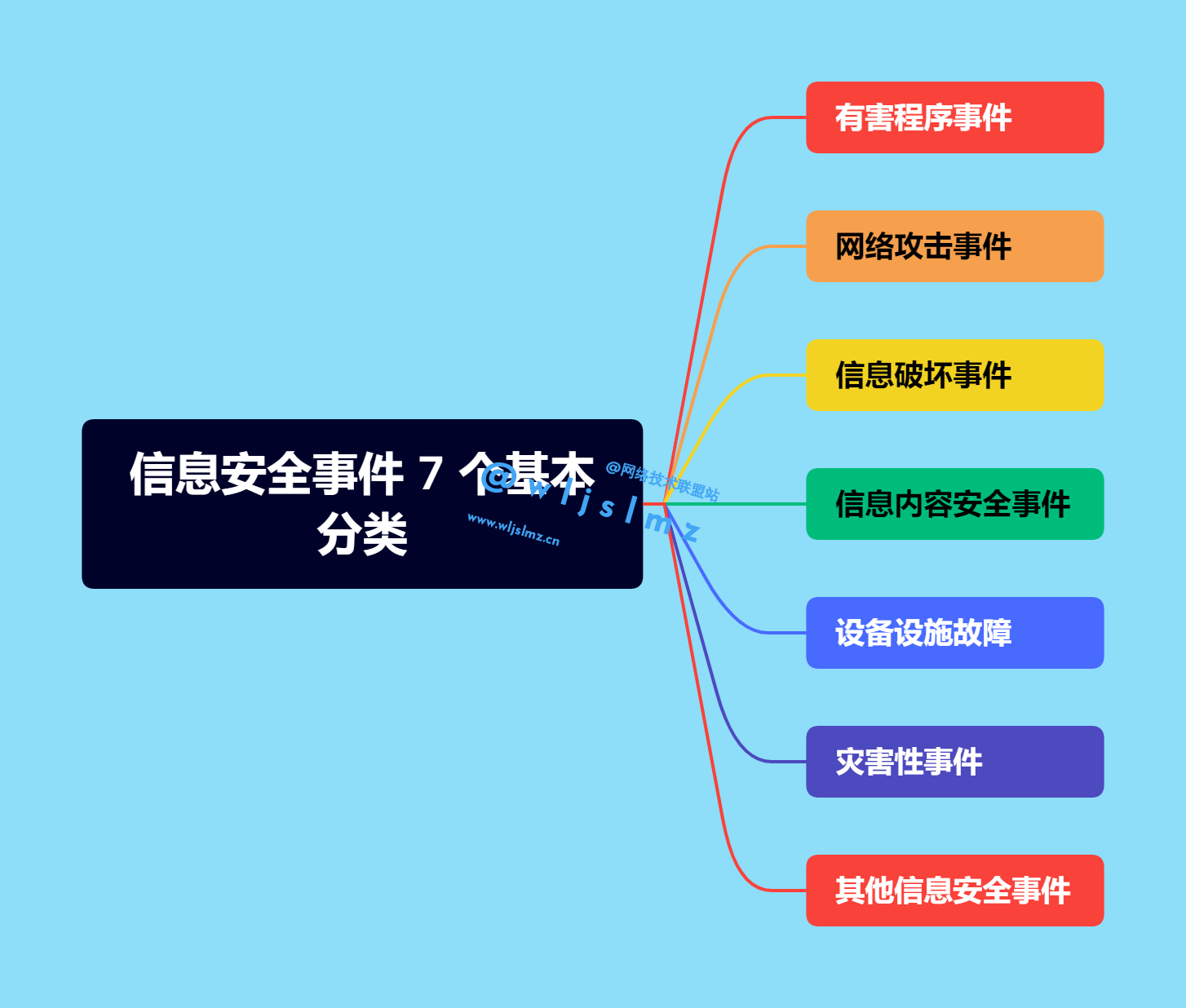
网络安全应急响应服务方案怎么写?包含哪些阶段?一文带你了解!
文章目录一、服务范围及流程1.1 服务范围1.2 服务流程及内容二、准备阶段2.1 负责人准备内容2.2 技术人员准备内容(一)服务需求界定(二)主机和网络设备安全初始化快照和备份2.3市场人员准备内容(1)预防和预…...

11、事务原理和实战,MVCC
事务原理和实战 1. 认识事务2. 事务控制语句2.1 开启事务2.2 事务提交2.3 事务回滚3. 事务的实现方式3.1 原子性3.2 一致性3.3 隔离性3.3 持久性4purge thread线程5事务统计QPS与TPS5.1 QPS5.2 TPS6. 事务隔离级别6.1 隔离级别6.2 查看隔离级别6.3 设置隔离级别6.4 不同隔离级别…...
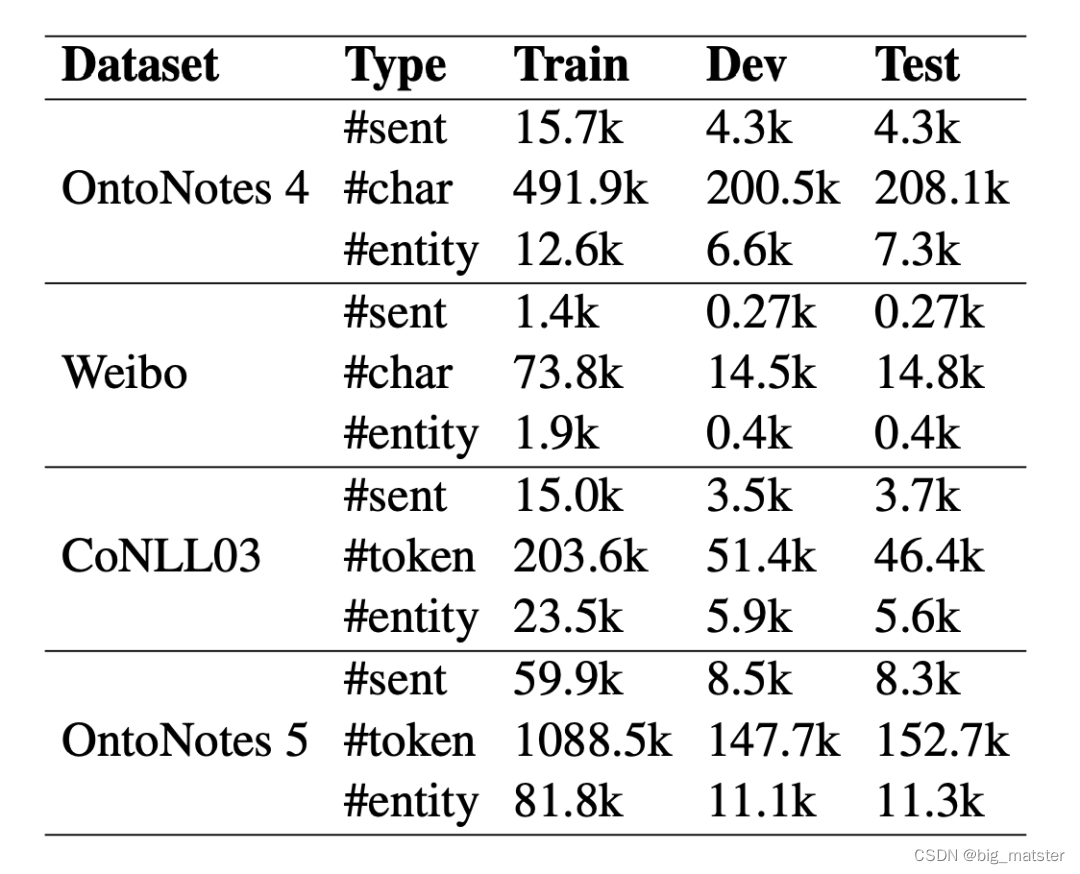
Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
摘要 近年来,自我增强成为在低资源场景下提升命名实体识别性能的研究热点。Token substitution and mixup (token替换和表征混合)是两种有效提升NER性能的自增强方法。明显,自增强方法得到的增强数据可能由潜在的噪声。先前的研究…...

Java基础-xml
1.xml 1.1概述 万维网联盟(W3C) 万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。 建立者: Tim Berners-Lee (蒂姆伯纳斯李)。 是Web技术领域最具权威和影响力的国际中立性技术标准机构。 到目前为止&#…...

TCP的Nagle算法和delayed ack---延时发送和延时应答与稍带应答选项
本文目录提高TCP的网络利用率的二个思考解决方案:Nagle算法和delayed ack(延时发送和延时应答与稍带应答选项)Nagle算法和delayed ack算法同时启动可能会导致的问题提高TCP的网络利用率的二个思考 我们都知道,TCP是一个基于字节流…...
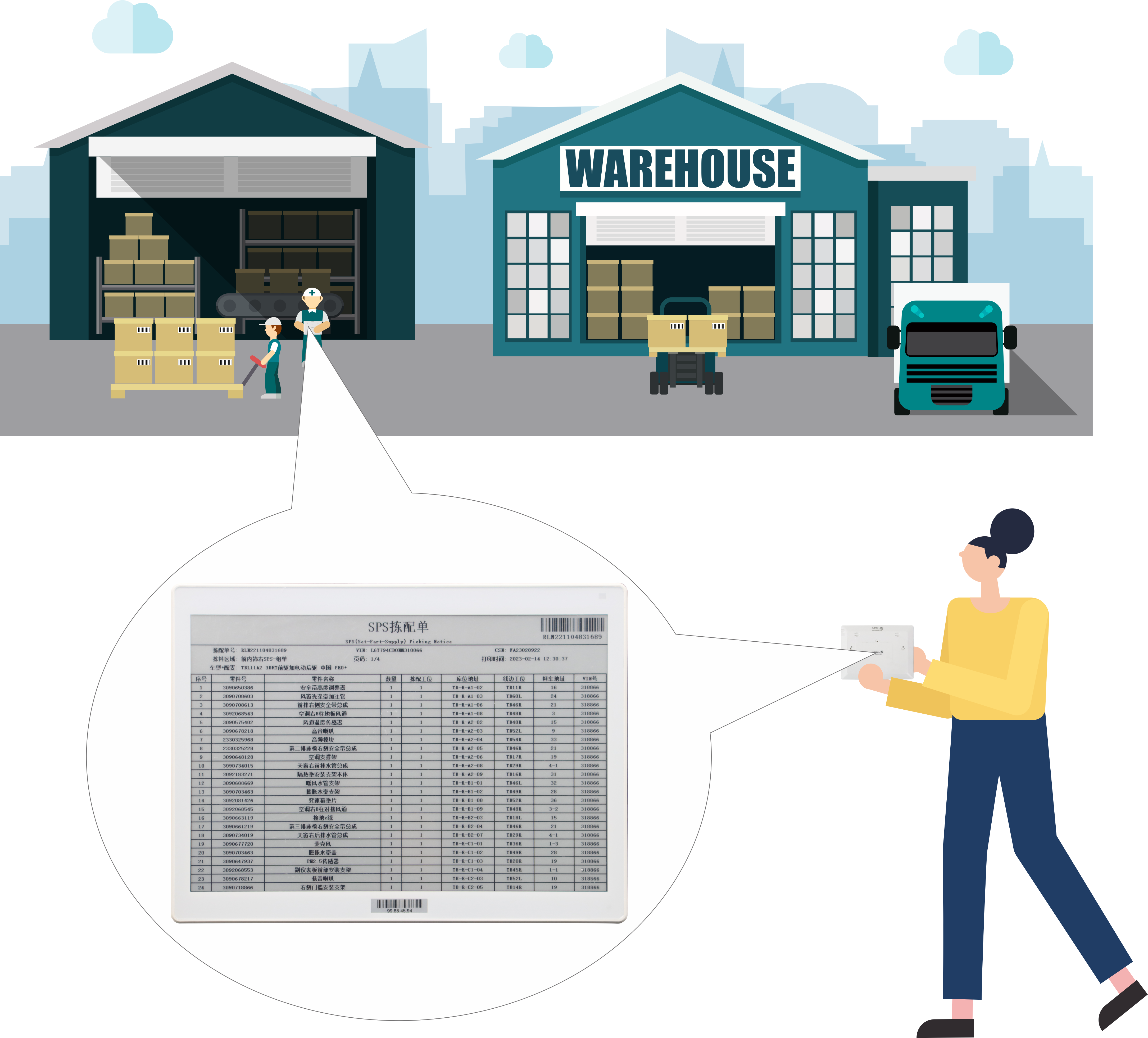
智能拣配单解决方案
电子货架标签系统(ESLs),是一种放置在货架上、可替代传统纸质价格标签的电子显示装置, 每一个电子货架标签通过有线或者无线网络与商场计算机数据库相连, 并将最新的商品价格通过电子货架标签上的屏显示出来。 电子…...

如何防御入侵服务器
根据中华人民共和国刑法: 第二百八十六条违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的ÿ…...
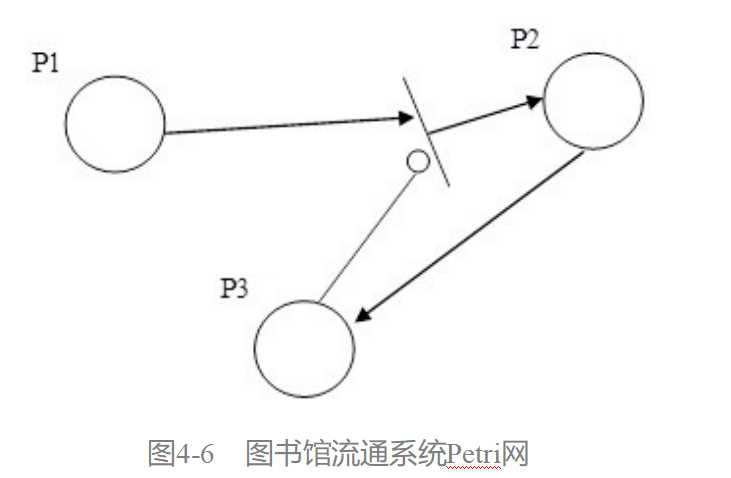
[软件工程导论(第六版)]第4章 形式化说明技术(课后习题详解)
文章目录1. 举例对比形式化方法和欠形式化方法的优缺点。2. 在什么情况下应该使用形式化说明技术?使用形式化说明技术时应遵守哪些准则?3. 一个浮点二进制数的构成是:一个可选的符号(+或-)&…...
Premiere基础操作
一:设置缓存二:ctrI导入素材三:导入图像序列四:打开吸附。打开吸附后素材会对齐。五:按~键可以全屏窗口。六:向前选择轨道工具。在时间线上点击,向前选中时间线上素材。向后选择轨道工具&#x…...
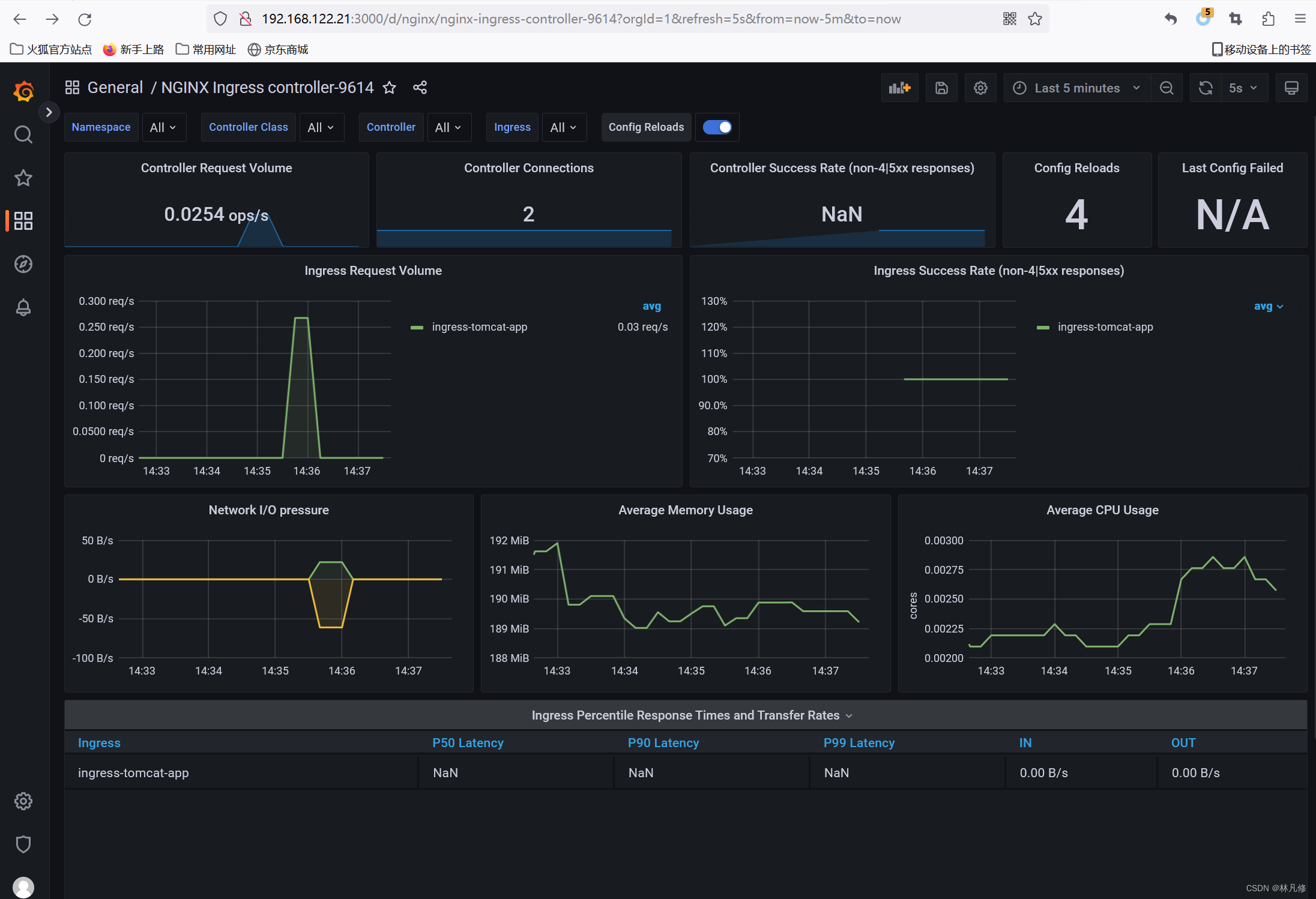
Prometheus监控案例-tomcat、mysql、redis、haproxy、nginx
监控tomcat tomcat自身并不能提供监控指标数据,需要借助第三方exporter实现:https://github.com/nlighten/tomcat_exporter 构建镜像 基于tomcat官方镜像,重新制作一个镜像,将tomcat-exporter和tomcat整合到一起。Ddockerfile如…...
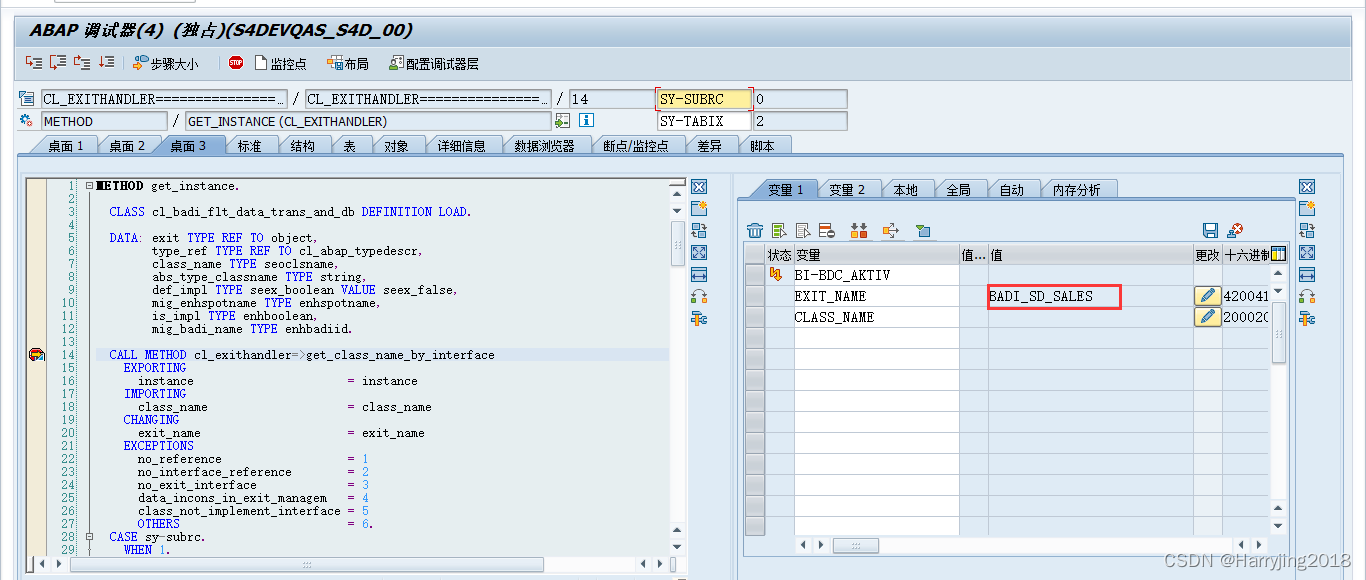
如何寻找SAP中的增强
文章目录0 简介1 寻找一代增强2 寻找二代增强2.2 在包里也可以看到2.3 在出口对象里输入包的名字也可以找到2.4 通过以下函数可以发现已有的增强2.5 也可以在cmod里直接找2.6 总结3 寻找第三代增强0 简介 在SAP中,对原代码的修改最不容易的是找增强,以下…...

算法刷题打卡第95天: 最大平均通过率
最大平均通过率 难度:中等 一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali…...
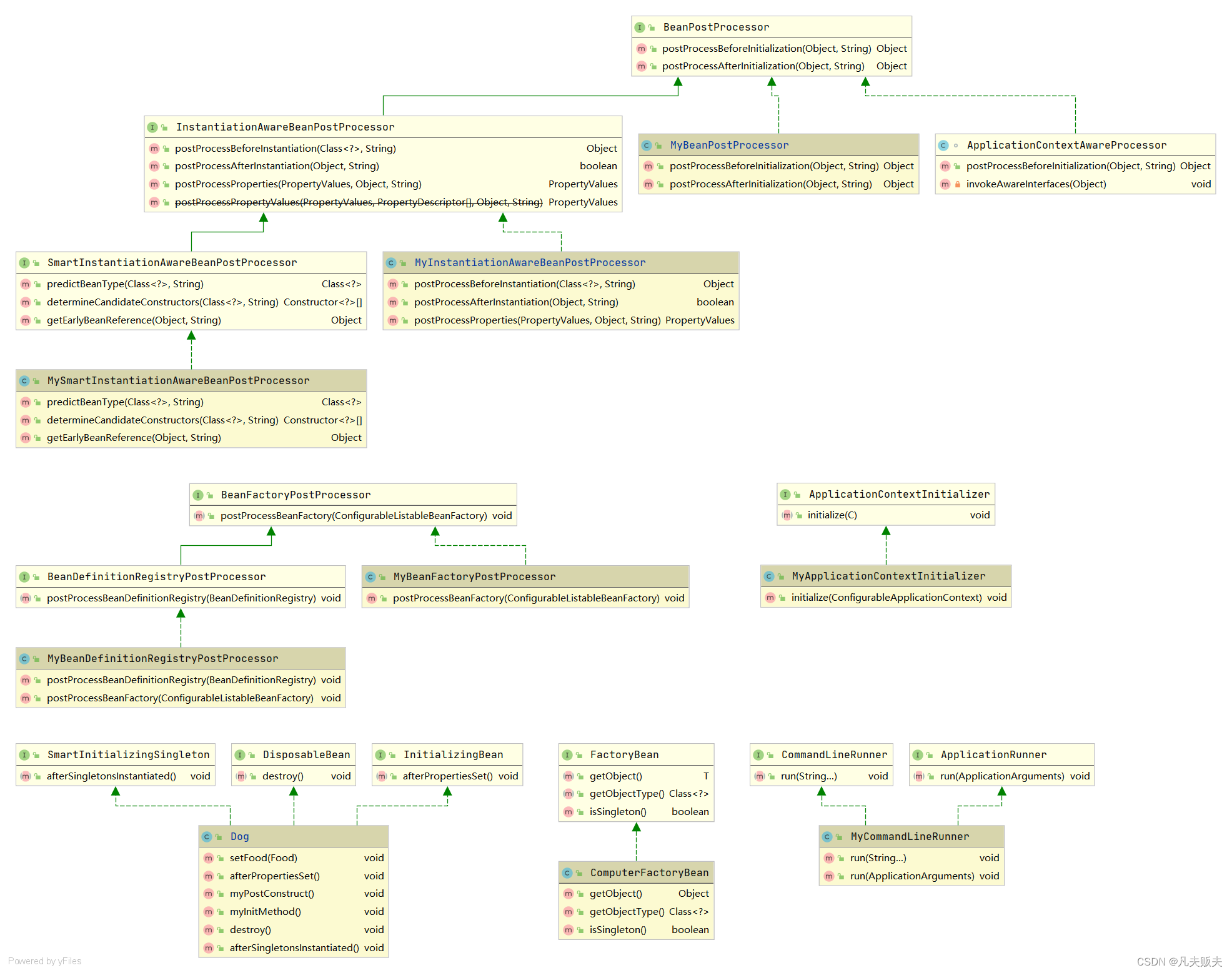
Springboot扩展点系列之终结篇:Bean的生命周期
前言关于Springboot扩展点系列已经输出了13篇文章,分别梳理出了各个扩展点的功能特性、实现方式和工作原理,为什么要花这么多时间来梳理这些内容?根本原因就是这篇文章:Spring bean的生命周期。你了解Spring bean生命周期…...
OnGUI Color 控件||Unity 3D GUI 简介||OnGUI TextField 控件
Unity 3D Color 控件与 Background Color 控件类似,都是渲染 GUI 颜色的,但是两者不同的是 Color 不但会渲染 GUI 的背景颜色,同时还会影响 GUI.Text 的颜色。具体使用时,要作如下定义:public static var color:Color;…...

【日刻一诗】
日刻一诗 1)LeetCode总结(线性表)_链表类 2)LeetCode总结(线性表)_栈队列类 3)LeetCode总结(线性表)_滑动窗口 4)LeetCode总结(线性表&#x…...
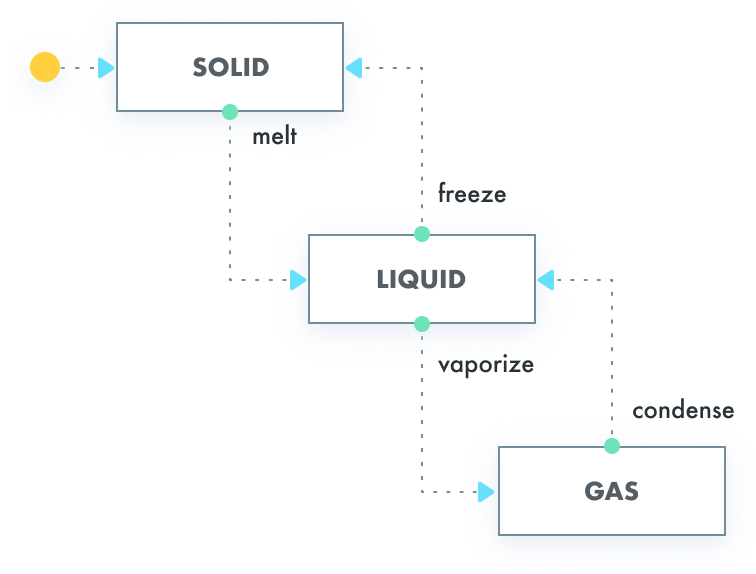
设计模式 状态机
前言 本文梳理状态机概念,在实操中状态机和状态模式类似,只是被封装起来,可以很方便的实现状态初始化和状态转换。 概念 有限状态机(finite-state machine)又称有限状态自动机(英语:finite-s…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...