transformer实现词性标注
1、self-attention
1.1、self-attention结构图

上图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询), K(键值), V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q, K, V 正是通过 Self-Attention 的输入进行线性变换得到的。
1.2 Q,K,V的计算
Self-Attention 的输入用矩阵 X进行表示,则可以使用线性变阵矩阵 WQ, WK, WV 计算得到 Q, K, V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词
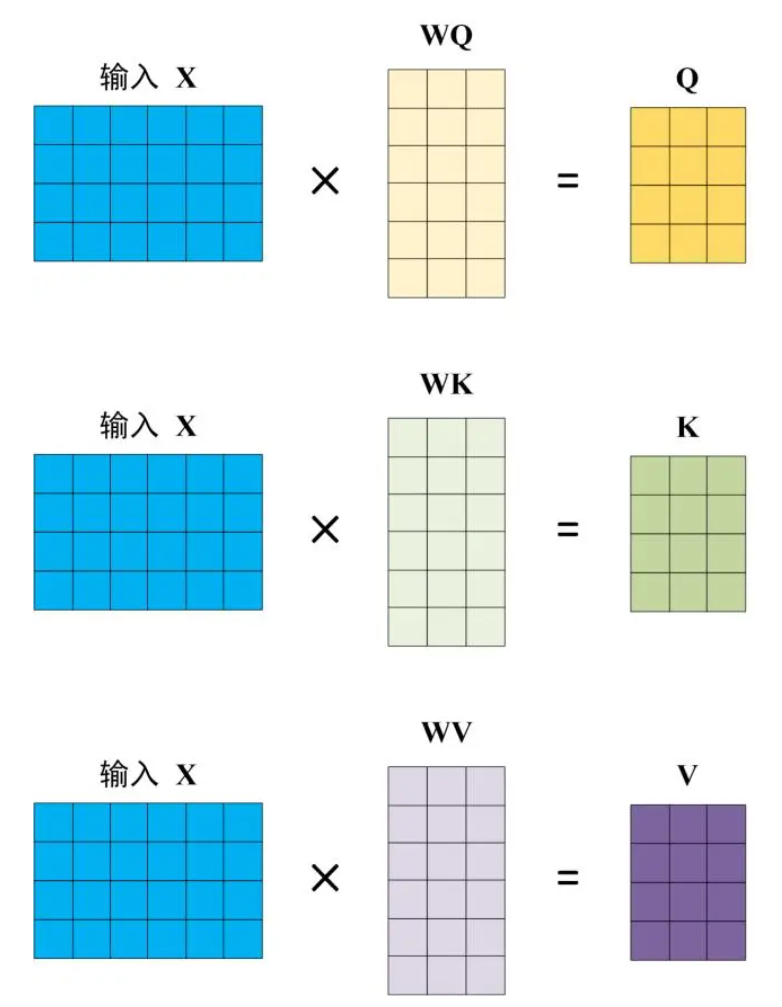
3.3 Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:
 公式中计算矩阵 Q和 K 每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q 乘以 K 的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为 Q 乘以 K 的转置,1234 表示的是句子中的单词。
公式中计算矩阵 Q和 K 每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q 乘以 K 的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为 Q 乘以 K 的转置,1234 表示的是句子中的单词。
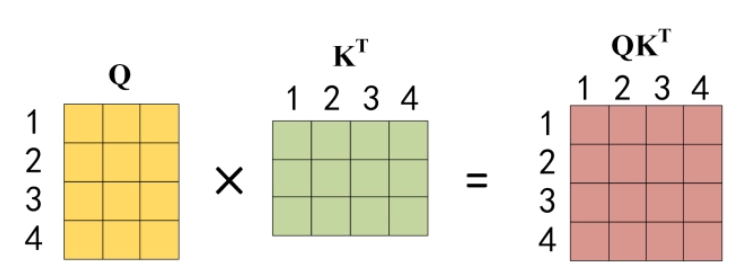
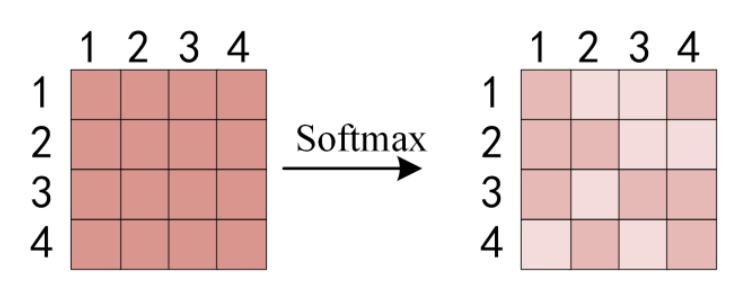
得到 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1。
得到 Softmax 矩阵之后可以和 V相乘,得到最终的输出 Z。
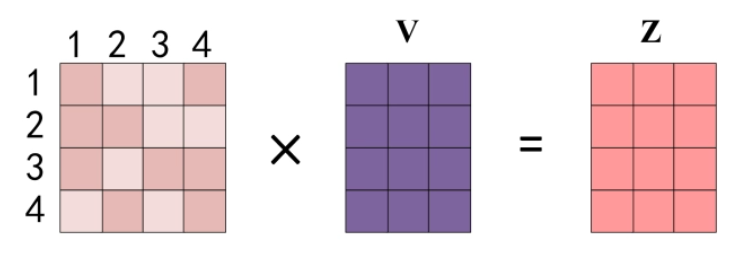
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z1 等于所有单词 i 的值 Vi 根据 attention 系数的比例加在一起得到,如下图所示:

class Attention(nn.Module):def __init__(self, input_n:int,hidden_n:int):super().__init__()self.hidden_n = hidden_nself.input_n=input_nself.W_q = torch.nn.Linear(input_n, hidden_n)self.W_k = torch.nn.Linear(input_n, hidden_n)self.W_v = torch.nn.Linear(input_n, hidden_n)def forward(self, Q, K, V, mask=None):Q = self.W_q(Q)K = self.W_k(K)V = self.W_v(V)attention_scores = torch.matmul(Q, K.transpose(-2, -1))attention_weights = softmax(attention_scores)output = torch.matmul(attention_weights, V)return output2、multi-head attention

从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入 X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵 Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵 Z。
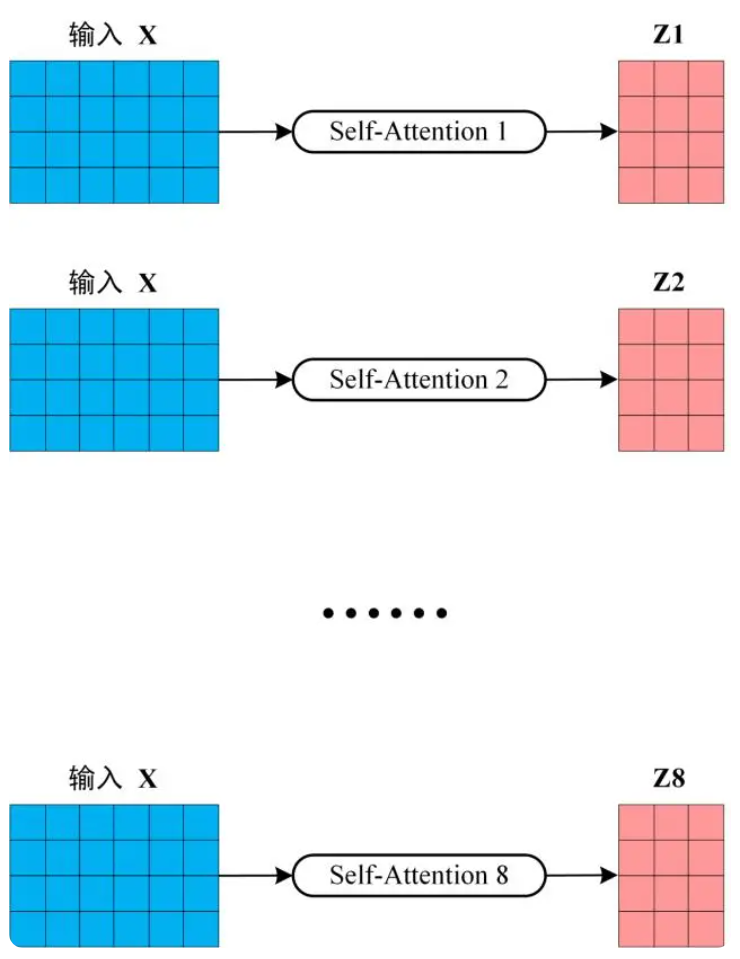
得到 8 个输出矩阵 Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个 Linear层,得到 Multi-Head Attention 最终的输出 Z。
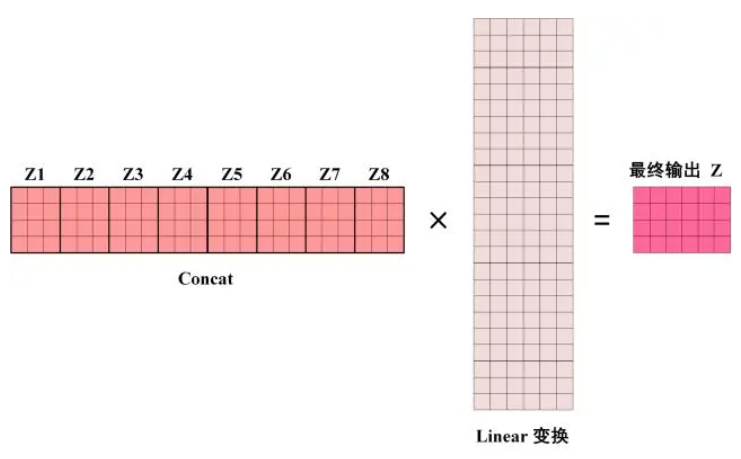
可以看到 Multi-Head Attention 输出的矩阵 Z与其输入的矩阵 X 的维度是一样的。
class MultiHeadAttention(nn.Module):def __init__(self,hidden_n:int, h:int = 2):"""hidden_n: hidden dimensionh: number of heads"""super().__init__()embed_size=hidden_nheads=hself.embed_size = embed_sizeself.heads = heads# 每个head的处理的特征个数self.head_dim = embed_size // heads# 如果不能整除就报错assert (self.head_dim * self.heads == self.embed_size), 'embed_size should be divided by heads'# 三个全连接分别计算qkvself.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)# 输出层self.fc_out = nn.Linear(self.head_dim * self.heads, embed_size)def forward(self, Q, K, V, mask=None):query,values,keys=Q,K,VN = query.shape[0] # batch# 获取每个句子有多少个单词value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 维度调整 [b,seq_len,embed_size] ==> [b,seq_len,heads,head_dim]values = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)# 对原始输入数据计算q、k、vvalues = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# 爱因斯坦简记法,用于张量矩阵运算,q和k的转置矩阵相乘# queries.shape = [N, query_len, self.heads, self.head_dim]# keys.shape = [N, keys_len, self.heads, self.head_dim]# energy.shape = [N, heads, query_len, keys_len]energy = torch.einsum('nqhd, nkhd -> nhqk', [queries, keys])# 是否使用mask遮挡t时刻以后的所有q、kif mask is not None:# 将mask中所有为0的位置的元素,在energy中对应位置都置为 -1*10^10energy = energy.masked_fill(mask==0, torch.tensor(-1e10))# 根据公式计算attention, 在最后一个维度上计算softmaxattention = torch.softmax(energy/(self.embed_size**(1/2)), dim=3)# 爱因斯坦简记法矩阵元素,其中query_len == keys_len == value_len# attention.shape = [N, heads, query_len, keys_len]# values.shape = [N, value_len, heads, head_dim]# out.shape = [N, query_len, heads, head_dim]out = torch.einsum('nhql, nlhd -> nqhd', [attention, values])# 维度调整 [N, query_len, heads, head_dim] ==> [N, query_len, heads*head_dim]out = out.reshape(N, query_len, self.heads*self.head_dim)# 全连接,shape不变output = self.fc_out(out)return output3、transformer block
3.1 encoder blockg构架图

上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
3.2 Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
3.3 Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。

X是输入,Feed Forward 最终得到的输出矩阵的维度与 X 一致。
class TransformerBlock(nn.Module):def __init__(self, hidden_n:int, h:int = 2):"""hidden_n: hidden dimensionh: number of heads"""super().__init__()embed_size=hidden_nheads=h# 实例化自注意力模块self.attention =MultiHeadAttention (embed_size, heads)# muti_head之后的layernormself.norm1 = nn.LayerNorm(embed_size)# FFN之后的layernormself.norm2 = nn.LayerNorm(embed_size)forward_expansion=1dropout=0.2# 构建FFN前馈型神经网络self.feed_forward = nn.Sequential(# 第一个全连接层上升特征个数nn.Linear(embed_size, embed_size * forward_expansion),# relu激活nn.ReLU(),# 第二个全连接下降特征个数nn.Linear(embed_size * forward_expansion, embed_size))# dropout层随机杀死神经元self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask=None):attention = self.attention(value, key, query, mask)# 输入和输出做残差连接x = query + attention# layernorm标准化x = self.norm1(x)# dropoutx = self.dropout(x)# FFNffn = self.feed_forward(x)# 残差连接输入和输出forward = ffn + x# layernorm + dropoutout = self.dropout(self.norm2(forward))return outtransformer
import torch.nn as nn
class Transformer(nn.Module):def __init__(self,vocab_size, emb_n: int, hidden_n: int, n:int =3, h:int =2):"""emb_n: number of token embeddingshidden_n: hidden dimensionn: number of layersh: number of heads per layer"""embedding_dim=emb_nsuper().__init__()self.embedding_dim = embedding_dimself.embeddings = nn.Embedding(vocab_size,embedding_dim)self.layers=nn.ModuleList([TransformerBlock(hidden_n,h) for _ in range(n) ])def forward(self,x):N,seq_len=x.shapeout=self.embeddings(x)for layer in self.layers:out=layer(out,out,out)return out相关文章:
transformer实现词性标注
1、self-attention 1.1、self-attention结构图 上图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询), K(键值), V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q, K, V…...

Java中异或操作和OTP算法
最近在研究加密算法,发现异或操作在加密算法中用途特别广,也特别好用。下面以Java语言为例,简单记录一下异或操作,以及在算法中的使用,包括常用的OTP算法。 一,异或操作特征 1, 相同出0&#…...
K8S最新版本集群部署(v1.28) + 容器引擎Docker部署(下)
温故知新 📚第三章 Kubernetes各组件部署📗安装kubectl(可直接跳转到安装kubeadm章节,直接全部安装了)📕下载kubectl安装包📕执行kubectl安装📕验证kubectl 📗安装kubead…...

女子垒球运动的发展·垒球1号位
女子垒球运动的发展 1. 女子垒球运动的起源和发展概述 女子垒球运动,诞生于19世纪末的美国,作为棒球运动的衍生品,经过百年的积淀,已在全球范围内广泛传播,形成了丰富的赛事文化。她的起源,可以追溯到19世…...

Debian 30 周年,生日快乐!
导读近日是 Debian 日,也是由伊恩-默多克(Ian Murdock)创立的 Debian GNU/Linux 通用操作系统和社区支持的 Debian 项目 30 周年纪念日。 不管你信不信,从已故的伊恩-默多克于 1993 年 8 月 16 日宣布成立 Debian 项目,…...
字符串匹配的Rabin–Karp算法
leetcode-28 实现strStr() 更熟悉的字符串匹配算法可能是KMP算法, 但在Golang中,使用的是Rabin–Karp算法 一般中文译作 拉宾-卡普算法,由迈克尔拉宾与理查德卡普于1987年提出 “ 要在一段文本中找出单个模式串的一个匹配,此算法具有线性时间的平均复杂度࿰…...
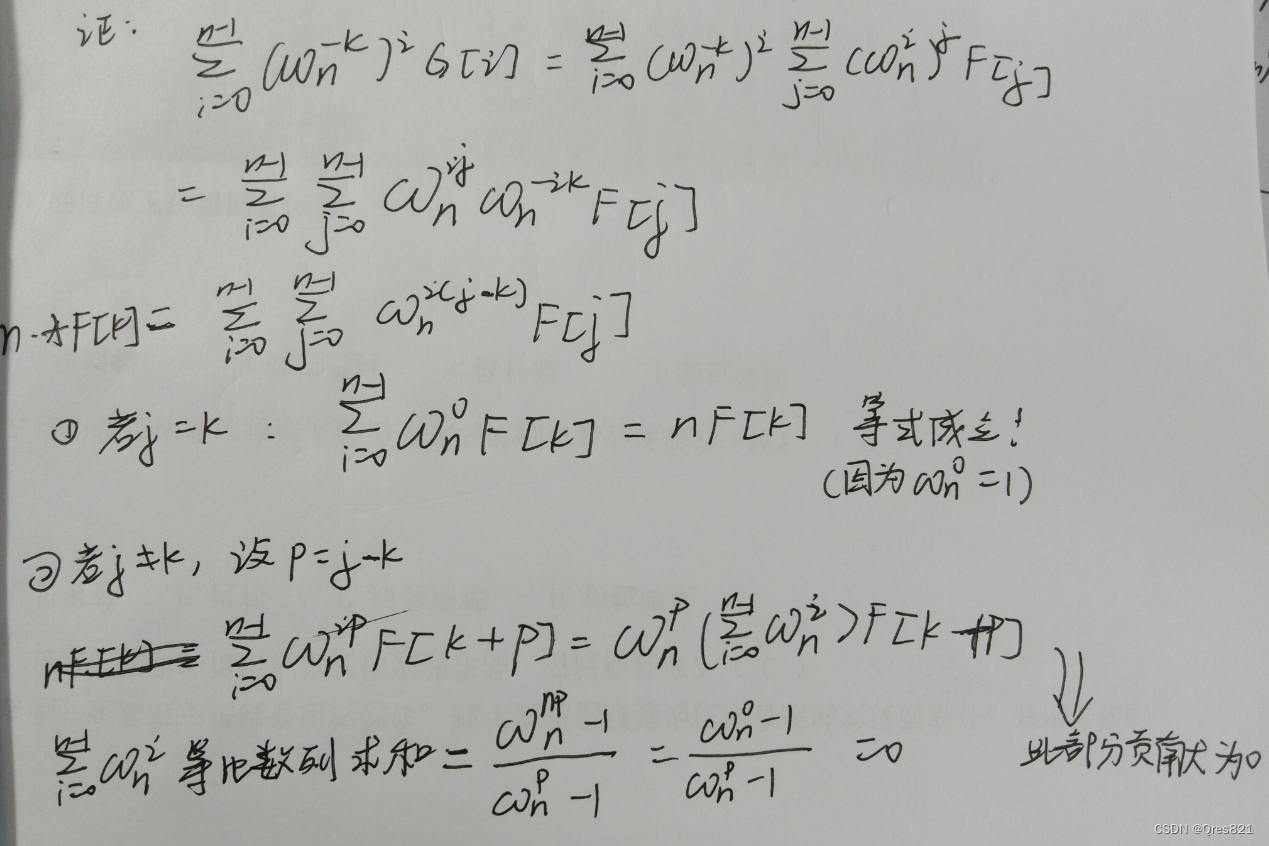
傅里叶变换(FFT)笔记存档
参考博客:https://www.luogu.com.cn/blog/command-block/fft-xue-xi-bi-ji 目录: FFT引入复数相关知识单位根及其相关性质DFT过程(难点)DFT结论(重要)IDFT结论(重要)IDFT结论证明&…...
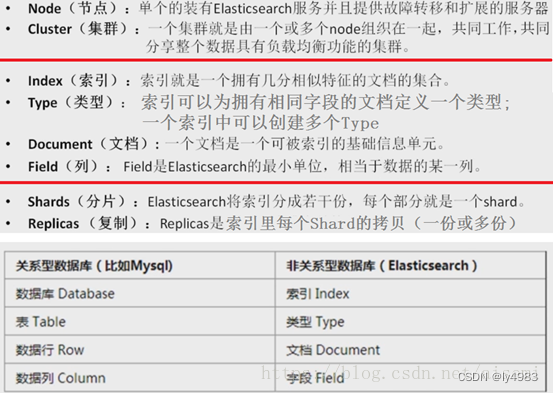
ELK安装、部署、调试 (二) ES的安装部署
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口操作ES,也可以利用Java API。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业…...
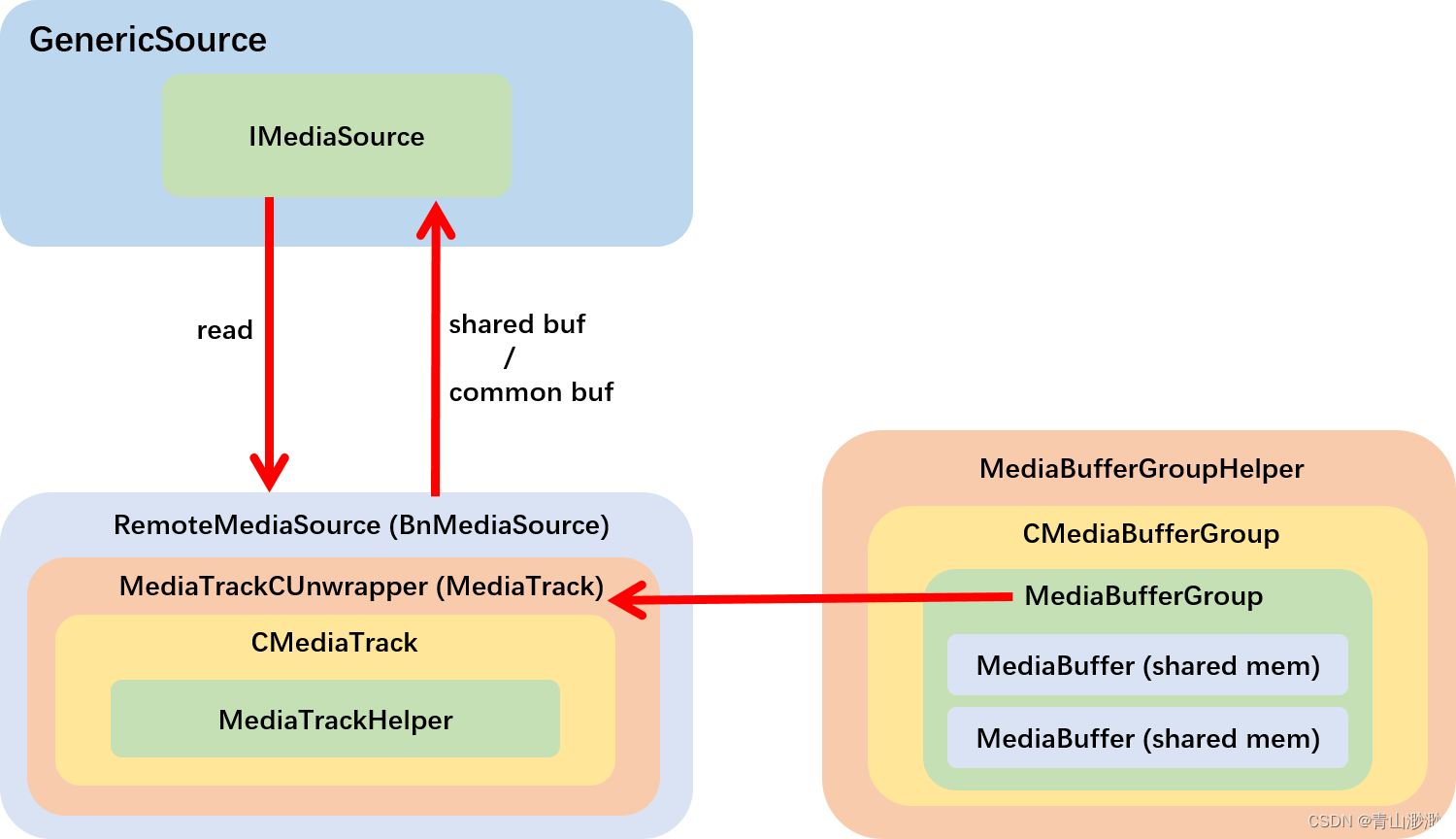
Android 13 - Media框架(8)- MediaExtractor
上一篇我们了解了 GenericSource 需要依赖 IMediaExtractor 完成 demux 工作,这一篇我们就来学习 android media 框架中的第二个服务 media.extractor,看看 IMediaExtractor 是如何创建与工作的。 1、MediaExtractorService media.extractor 和 media.p…...
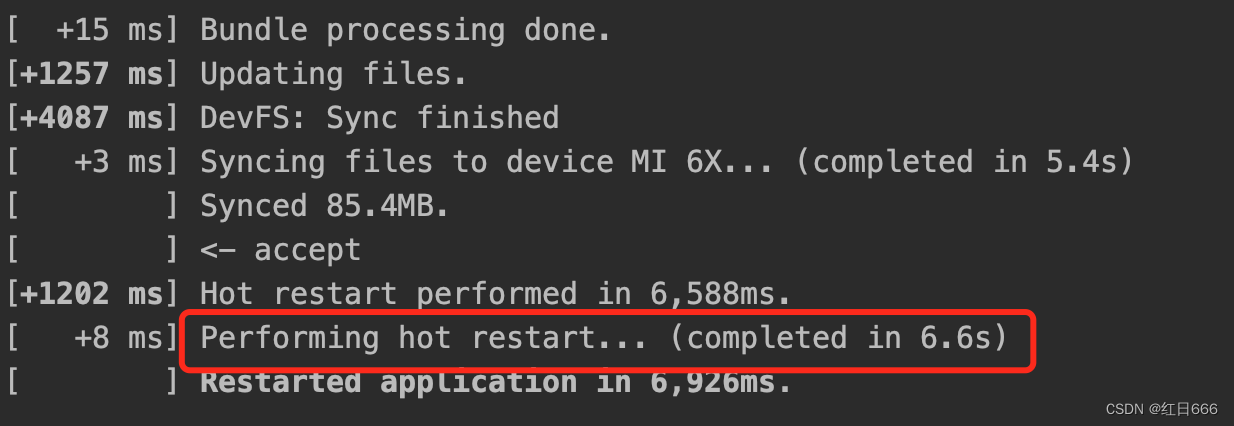
Flutter 混合开发调试
针对Flutter开发的同学来说,大部分的应用还是Native Flutter的混合开发,所以每次改完Flutter代码,运行整个项目无疑是很费时间的。所以Flutter官方也给我们提供了混合调试的方案【在混合开发模式下进行调试】,这里以Android Stud…...

C语言每日一练------(Day3)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今天练习题的关键字: 尼科彻斯定理 等差数列 💓博主csdn个人主页:…...
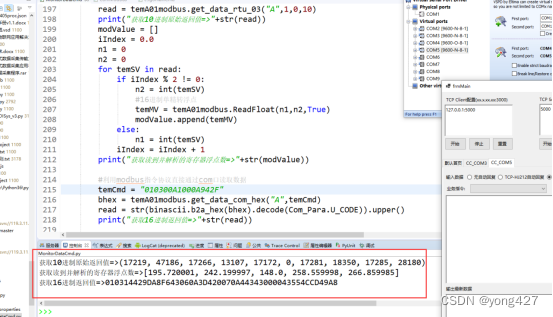
14、监测数据采集物联网应用开发步骤(10)
监测数据采集物联网应用开发步骤(9.2) Modbus rtu协议开发 本章节在《监测数据采集物联网应用开发步骤(7)》基础上实现可参考《...开发步骤(7)》调试工具,本章节代码需要调用modbus_tk组件,阅读本章节前建议baidu熟悉modbus rtu协议内容 组件安装modb…...
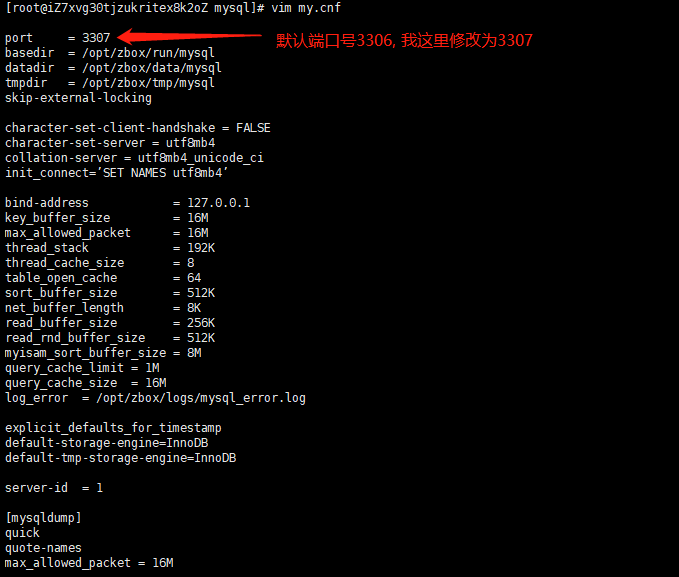
Linux禅道上修改Apache 和 MySQL 默认端口号
1. 修改Apache默认端口号 80 cd /opt/zbox/etc/apachevim httpd.conf :wq 保存 2. 修改MySQL默认端口号 3306 cd /opt/zbox/etc/mysql vim my.cnf :wq 保存 3. 重启服务 ./zbox restart...

操作教程|通过1Panel开源Linux面板快速安装DataEase
DataEase开源数据可视化分析工具(dataease.io)的在线安装是通过在服务器命令行执行Linux命令来进行的。但是在实际的安装部署过程中,很多数据分析师或者业务人员经常会因为不熟悉Linux操作系统及命令行操作方式,在安装DataEase的过…...
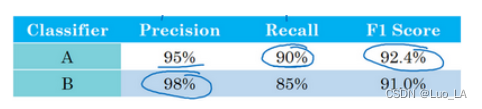
机器学习策略——优化深度学习系统
正交化(Orthogonalization) 老式电视机,有很多旋钮可以用来调整图像的各种性质,对于这些旧式电视,可能有一个旋钮用来调图像垂直方向的高度,另外有一个旋钮用来调图像宽度,也许还有一个旋钮用来…...

ES6中Proxy和Proxy实例
1.Proxy Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器” 使用方法 let p new Proxy(target, handler);其中,target 为被代理对象。handler 是一个对象,其声明了代理 target 的一些操作。p 是…...

UDP协议的重要知识点
UDP,即用户数据报协议(User Datagram Protocol),是一个简单的无连接的传输层协议。与TCP相比,UDP提供了更少的错误检查机制,并允许数据包在网络上更快地传输。在这篇博客中,我们将深入探讨UDP的…...
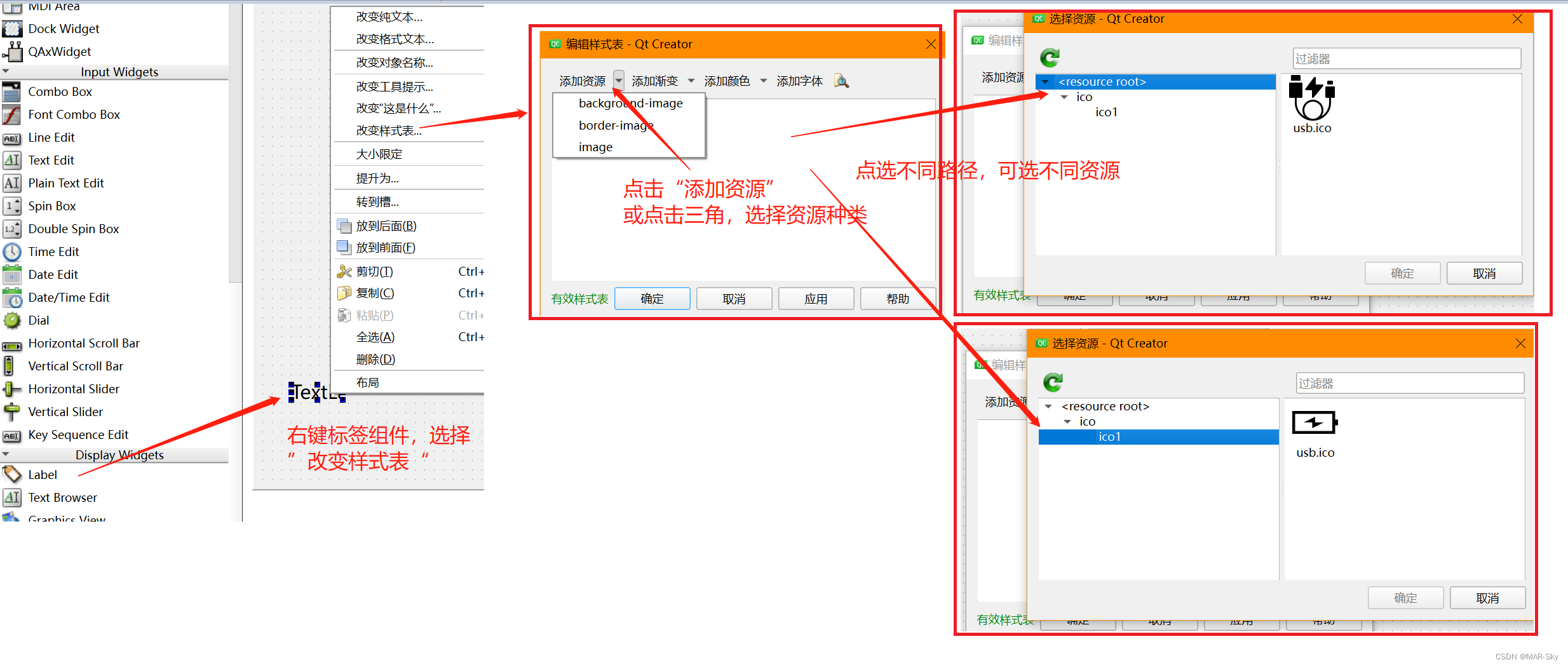
QT6为工程添加资源文件,并在ui界面引用
以添加图片资源为例 右键工程名字(不是最上面的名字),点击添加现有文件 这种方式虽然添加到了工程中,但不能在UI设计界面完成引用。主要原因可能是未把文件放入到项目资源文件中,以下面一种方式可以看出区别。 点击添…...

Python小知识 - 如何使用Python的Flask框架快速开发Web应用
如何使用Python的Flask框架快速开发Web应用 现在越来越多的人把Python作为自己的第一语言来学习,Python的简洁易学的语法以及丰富的第三方库让人们越来越喜欢上了这门语言。本文将介绍如何使用Python的Flask框架快速开发Web应用。 Flask是一个使用Python编写的轻量级…...
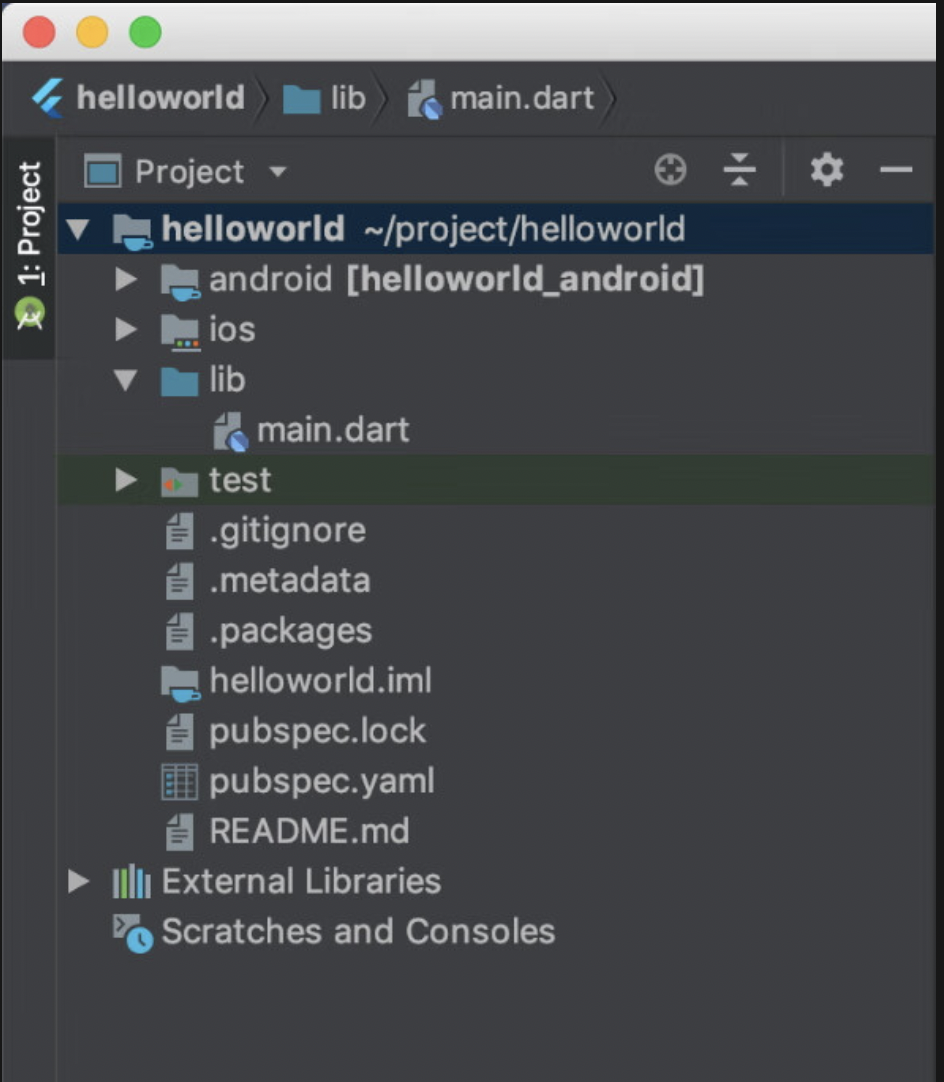
Flutter 项目结构文件
1、Flutter项目的文件结构 先helloworld项目,看看它都包含哪些组成部分。首先,来看一下项目的文件结构,如下图所示。 2、介绍上图的内容。 -litb/main.dart文件:整个应用的入口文件,其中的main函数是整个Flutter应…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...