机器学习的第一节基本概念的相关学习
目录
1.1 决策树的概念
1.2 KNN的概念
1.2.1KNN的基本原理
1.2.2 流程:
1.2.3 优缺点
1.3 深度学习
1.4 梯度下降
损失函数
1.5 特征与特征选择
特征选择的目的
1.6 python中dot函数总结
一维数组的点积:
二维数组(矩阵)的乘法:
多维数组的乘法:
1.7 suffler 打乱
1.8 特征和标签
1.9 Python中 X.shape的含义及其使用
1.1 决策树的概念
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树是一种描述对实例进行分类的树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。分类决策树模型是一种树形结构。 决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。
 1.2
1.2
1.2 KNN的概念
K-NearestNeighbor简称KNN,中文名K最近邻,其作用通俗来说就是将数据集合中每一个样本进行分类的方法,机器学习常用算法之一,属于有监督分类算法。
1.2.1KNN的基本原理
如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
简单理解就是: 简单来说就是设定k值,取样本点范围最近的k个点,其中哪类数量最多则预测的点就为那一类

1.2.2 流程:
1) 计算已知类别数据集中的点与当前点之间的距离
2) 按距离递增次序排序
3) 选取与当前点距离最小的k个点
4) 统计前k个点所在的类别出现的频率
5) 返回前k个点出现频率最高的类别作为当前点的预测分类
1、K值的选定
通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的 K 值开始,不断增加 K 的值,然后计算验证集合的方差,最终找到一个比较合适的 K 值。
1.2.3 优缺点
优点:
1、简单易用,对异常值不敏感
2、重新训练代价低
3、算法复杂度低
4、适合类域交叉样本
5、适用大样本自动分类
特点:非参数的,惰性的算法模型即:不会对数据做出任何假设,而线性回归总会假设一条直线,惰性的意思是没有明确的训练数据过程,或者过程很短不像逻辑回归需要先对数据进行大量的训练
缺点:
1、对内存要求较高
2、类别分类不标准化
3、输出可解释性不强
4、不均衡性
5、计算量较大
6、惰性学习,预测阶段可能会慢,对不相关的功能和数据规模敏感
1.3 深度学习
深度学习是在机器学习之后=要学习的课程,要知道深度学习和神经网络有关系,比如说那个下棋的机器人就用到了神经网络。
- 深度学习是机器学习的一个分支(最重要的分支)
- 机器学习是人工智能的一个分支
深度学习的概念源于人工神经网络的研究,但是并不完全等于传统神经网络。
不过在叫法上,很多深度学习算法中都会包含"神经网络"这个词,比如:卷积神经网络、循环神经网络。
所以,深度学习可以说是在传统神经网络基础上的升级,约等于神经网络。

1.4 梯度下降
在生活中,我们可以通过一个简单的例子来说明梯度下降的概念。
假设你是一位学生,每天早上需要赶去上学。你发现离学校的距离与你起床的时间之间存在着某种关系。你想找到一个起床时间,使得你花费的时间最短,也就是找到最优的起床时间。
你开始进行实验,每天记录自己起床的时间和到达学校所需的时间。你建立了一个简单的模型,假设到达学校的时间与起床时间之间存在线性关系,即到达学校的时间等于起床时间乘以一个参数k,再加上一个常数b,即到达学校的时间等于k * 起床时间 + b。
现在的问题是,如何通过梯度下降算法来找到最优的起床时间,使得到达学校的时间最短。
首先,你需要收集一些数据,包括起床时间和到达学校的时间。假设你收集了一周的数据。
然后,你需要定义一个损失函数,用于衡量到达学校时间与实际记录之间的差距。可以选择均方误差作为损失函数,即将每天的差距平方后求和再除以天数。
接下来,你随机初始化起床时间参数k和常数b的值。
然后,通过梯度下降算法进行迭代更新。根据梯度下降算法的原理,你需要计算损失函数对于起床时间参数k和常数b的偏导数,并根据学习率进行参数的更新。
在每次迭代中,你将根据实际数据计算损失函数,并通过梯度下降算法不断调整起床时间的参数k和常数b,使得损失函数逐渐减小,直到收敛到一个最优解。
最后,当损失函数收敛到一个较小的值时,你就找到了最优的起床时间,使得到达学校的时间最短。
通过这个例子,你可以理解梯度下降算法在寻找最优解的过程中的应用。在生活中,我们可以通过这种迭代、优化的方式来改进自己的决策和行为,以获得更好的结果。
损失函数
在机器学习和优化问题中,损失函数(Loss Function)是用来衡量模型预测值与真实值之间的差距或误差的函数。它是模型训练中的关键组成部分,用于评估模型的性能并指导参数的优化。
1.5 特征与特征选择
在机器学习中,将属性称为“特征(Feature)”,对当前学习任务有用的属性称为“相关特征(Relevant Feature)”,没有什么用的属性称为“无关特征(Irrelevant Feature)”。从给定的特征集合中选择出相关特征子集的过程,称为“特征选择(Feature Selection)”
特征选择是一个重要的数据预处理过程。在现在的机器学习中,获得数据之后通常先进行特征选择,此后再训练学习器。
特征选择过程必须确保不丢失重要特征,否则后续学习过程会因为重要信息的缺失而无法获得好的性能。给定数据集,若学习任务不同,则相关特征很可能不同。
另外,有一类特征称为“冗余特征(Redundant Feature)”,它们所包含的信息能从其它特征中推演出来。那么,去除冗余特征会减轻学习过程的负担。
特征选择的目的
在机器学习的实际应用中,特征数量往往较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
特征个数越多,分析特征、训练模型所需的时间就越长。
特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
特征选择能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化了模型,使研究人员易于理解数据产生的过程。
特征选择主要有两个目的:
减少特征数量、降维,避免维度灾难,这样能使模型泛化能力更强,减少过拟合,缩短模型训练时间。
增强对特征和特征值之间的理解
两个特征的时候还有图像,三个特征的时候就没有图像了,是一个面,四个特征得靠推导
降维就是降特征
1.6 python中dot函数总结
在NumPy中,dot函数用于计算两个数组的点积(内积)或矩阵乘法。dot函数的用法有一些细微的差别,取决于输入的数组是一维数组、二维数组(矩阵)还是多维数组。
一维数组的点积:

在这个例子中,dot函数计算了两个一维数组a和b的点积,即14 + 25 + 3*6 = 32。
二维数组(矩阵)的乘法:

在这个例子中,dot函数计算了两个二维数组(矩阵)A和B的矩阵乘法
多维数组的乘法:

-
在这个例子中,
dot函数计算了两个三维数组的乘法。
需要注意的是,dot函数在进行矩阵乘法时,要求第一个数组的列数与第二个数组的行数相等
1.7 suffler 打乱
在机器学习中,"shuffle"(洗牌)通常指的是随机打乱数据集中的样本顺序。这个操作在数据预处理阶段非常常见,特别是在训练模型之前。通过打乱数据集中的样本顺序,可以避免模型对样本的顺序产生依赖,从而更好地训练和泛化模型。
以下是为什么在机器学习中执行数据集洗牌的一些原因:
-
避免顺序偏差:如果数据集中的样本按照某种特定顺序排列,模型可能会因为学习到数据顺序中的规律,而不是真正的数据关系。通过洗牌,可以消除这种顺序偏差,确保模型不会因为数据的排列方式而受到影响。
-
提高泛化性能:如果模型在没有见过的数据上表现良好,称为具有良好的泛化性能。通过在训练过程中使用洗牌数据,模型可以学习到更广泛的数据分布,从而更有可能在未见过的数据上表现良好。
-
减少过拟合:过拟合是指模型在训练数据上表现得很好,但在新数据上表现不佳。通过在训练数据上引入随机性,洗牌可以帮助减少模型对特定样本的过度学习,从而减轻过拟合问题。
在 Python 中,你可以使用不同的库来实现数据集的洗牌,例如在 sklearn.utils 模块中的 shuffle 函数,或者直接使用 NumPy 库的随机抽样函数。下面是一个使用 sklearn.utils.shuffle 的示例:

这里,X 是特征矩阵,y 是标签向量。通过调用 shuffle 函数,你可以随机打乱特征矩阵和标签向量的对应关系,确保它们的顺序是随机的。
1.8 特征和标签
在机器学习中,特征(Features)和标签(Labels)是用于训练和评估模型的两个关键概念。它们通常用于监督学习任务,如分类和回归。
1.特征(Features):
特征是指用来描述每个样本的属性或输入变量。在一个机器学习问题中,一个样本可以由多个特征组成。特征可以是任何能够表示样本属性的数据,例如数字、文本、图像等。在训练模型时,模型会根据特征的不同值来学习样本之间的模式和关系。
举例来说,考虑一个房价预测的问题。每个房子可以有多个特征,如房子的面积、卧室数量、浴室数量、地理位置等。在这种情况下,特征就是用来描述房子的各种属性。
2.标签(Labels):
标签是指机器学习问题中的目标变量或输出变量,它表示我们希望模型预测或分类的内容。标签通常是我们要预测的值或类别。在监督学习中,我们为每个样本提供相应的标签,以便模型可以通过学习特征和标签之间的关系来进行预测。
沿着房价预测的例子,标签就是房子的实际销售价格。我们的目标是通过给定的特征(如面积、卧室数量等)来预测房价。
在训练模型时,我们将一组包含特征和相应标签的数据样本输入给模型。模型使用这些样本来学习特征和标签之间的关系,从而能够在未见过的样本上进行预测或分类。通常,我们会将数据集划分为训练集和测试集,用训练集来训练模型,用测试集来评估模型的性能。
总结起来,特征是用来描述每个样本属性的数据,标签是我们要预测或分类的目标变量。在监督学习中,我们希望模型能够从特征学习到如何准确地预测或分类标签。
1.9 Python中 X.shape的含义及其使用
在 Python 中,.shape 是一个用于获取数组或矩阵维度信息的属性。它通常用于 NumPy 数组、Pandas 数据框等多维数据结构。
例如,假设你有一个 NumPy 数组 X,它表示一个数据集,你可以使用 X.shape 来获取该数据集的维度信息。返回的结果将是一个元组,其中包含了数组在各个维度上的大小。

在这个例子中,X 是一个2行3列的数组,所以 X.shape 返回的是 (2, 3),分别表示行数和列数。
同样,对于多维数组,比如一个三维的数组,.shape 会返回一个包含三个维度大小的元组,如 (2, 3, 4),表示一个2x3x4的三维数组。
怎样去取它的一个维度呢?

相关文章:
机器学习的第一节基本概念的相关学习
目录 1.1 决策树的概念 1.2 KNN的概念 1.2.1KNN的基本原理 1.2.2 流程: 1.2.3 优缺点 1.3 深度学习 1.4 梯度下降 损失函数 1.5 特征与特征选择 特征选择的目的 1.6 python中dot函数总结 一维数组的点积: 二维数组(矩阵)的乘法&am…...

Python 之__name__的用法以及解释
文章目录 介绍代码 介绍 __name__ 是一个在 Python 中特殊的内置变量,用于确定一个 Python 文件是被直接运行还是被导入为模块。 文件作为模板导入,则其 __name__属性值被自动设置为模块名 文件作为程序直接运行,则__name__属性属性值被自动设…...

【FPGA零基础学习之旅#12】三线制数码管驱动(74HC595)串行移位寄存器驱动
🎉欢迎来到FPGA专栏~三线制数码管驱动 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:FPGA学习之旅 文章作者技术和水平有限,如果文中出现错误,希望大家能指…...

networkX-03-连通度、全局网络效率、局部网络效率、聚类系数计算
文章目录 1.连通度1.1 检查图是否连通1.2 检查有向图是否为强连通1.3 点连通度、边连通度: 2.网络效率2.1全局效率2.2 局部效率2.2.1 查找子图2.2.3 局部效率源码分析 3.聚类系数(Clustering Coefficient)3.1 聚类系统源码分析 教程仓库地址&…...
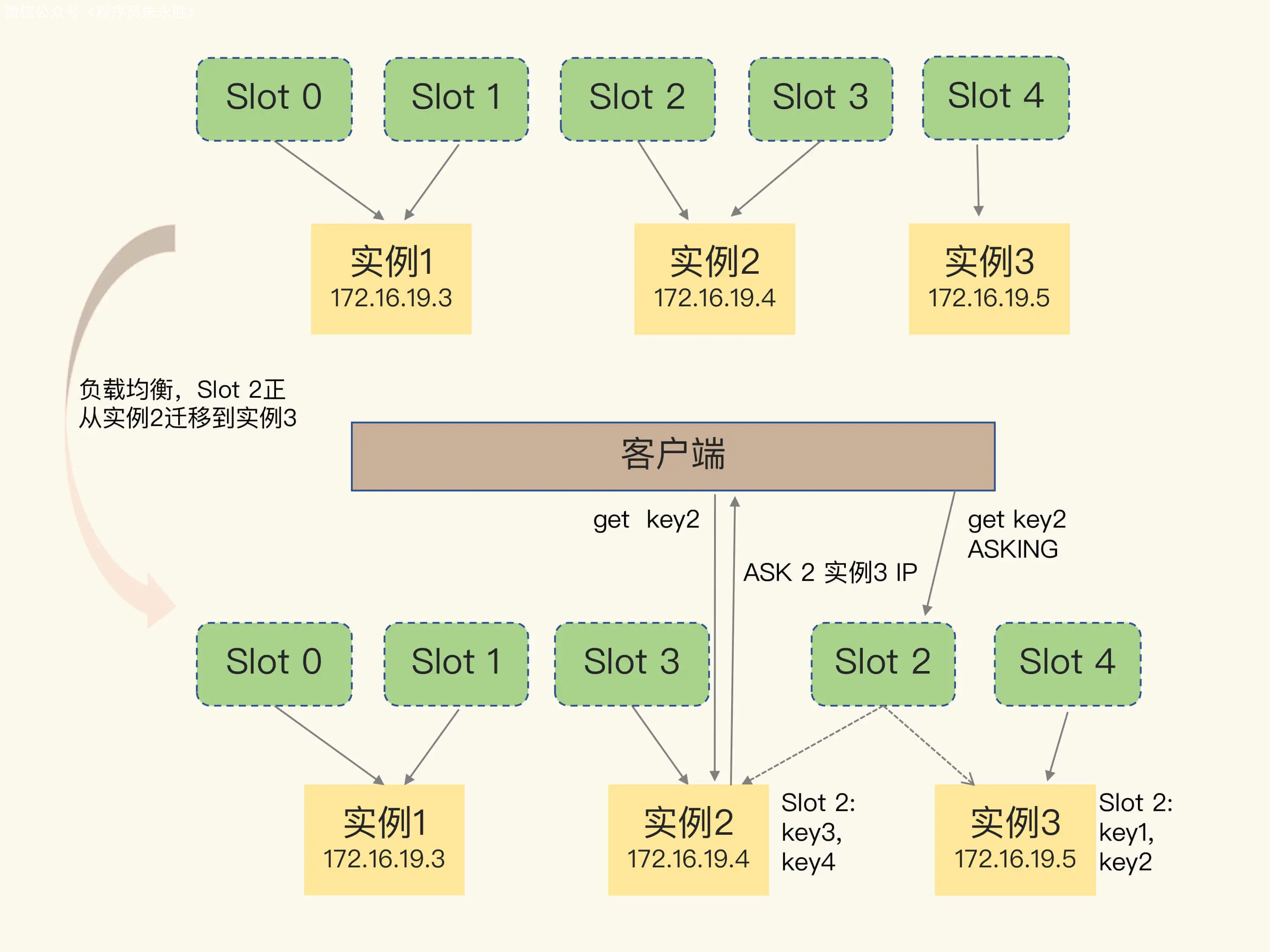
【深入解读Redis系列】Redis系列(五):切片集群详解
首发博客地址 https://blog.zysicyj.top/ 系列文章地址[1] 如果 Redis 内存很大怎么办? 假设一台 32G 内存的服务器部署了一个 Redis,内存占用了 25G,会发生什么? 此时最明显的表现是 Redis 的响应变慢,甚至非常慢。 这…...

无涯教程-JavaScript - NORMDIST函数
NORMDIST函数替代Excel 2010中的NORM.DIST函数。 描述 该函数返回指定均值和标准差的正态分布。此功能在统计中有非常广泛的应用,包括假设检验。 语法 NORMDIST(x,mean,standard_dev,cumulative)争论 Argument描述Required/OptionalXThe value for which you want the dis…...

递归应用判断是否循环引用
var data await _IDBInstance.DBOperation.QueryAsync<FormulaReference>(sql);//向上查询引用公式 List<FormulaReference> GetSonNode(long id, List<FormulaReference> nodeList, List<long> path null){if (path null){path new List<long…...

使用nginx-lua配置统一url自动跳转到hadoop-ha集群的active节点
下载安装nginx所用的依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel下载nginx wget http://nginx.org/download/nginx-1.12.2.tar.gz tar -xvf nginx-1.12.2.tar.gz稍后安装nginx 安装lua语言 yum install readline-develcurl -R -O http://w…...
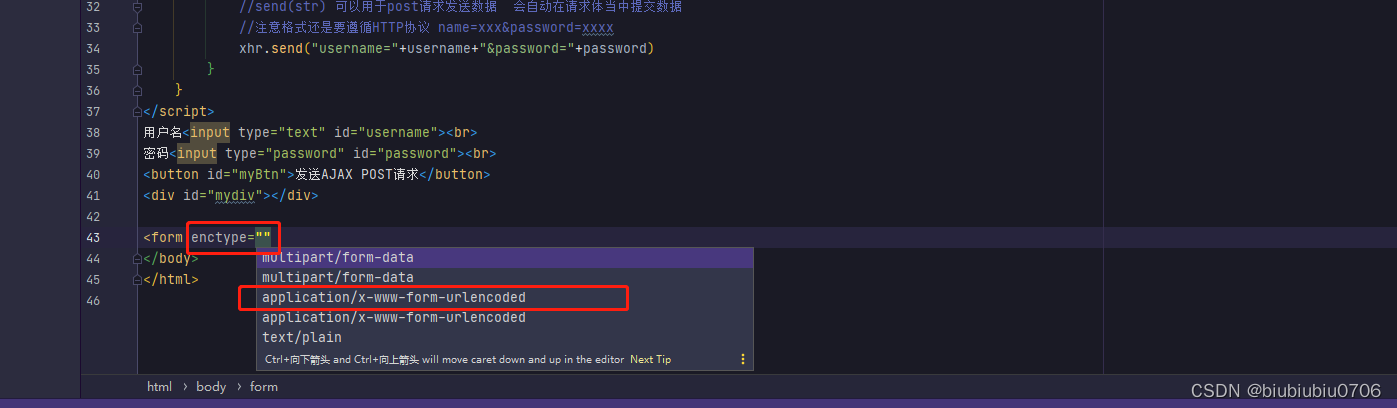
AJAX学习笔记2发送Post请求
AJAX学习笔记1发送Get请求_biubiubiu0706的博客-CSDN博客 继续 AJAX发送POST请求 无参数 测试 改回来 测试 AJAX POST请求 请求体中提交参数 测试 后端打断点 如何用AJAX模拟form表单post请求提交数据呢? 设置请求头必须在open之后,send之前 请求头里的设置好比…...

产品团队的需求分析指南
需求分析是软件开发流程中需求识别与管理的关键环节,需求分析的目的在于确保所有产品需求准确地代表了利益相关者的需求和要求。选择合适的需求分析方式可以帮助我们获取准确的产品需求,从而保证我们所交付的成果与利益相关者预期相符。 一、什么是需求…...
)
Python算法——排序算法(冒泡、选择、插入、快速、堆排序、并归排序、希尔、计数、桶排序、基数排序)
本文章只展示代码实现 ,原理大家可以参考: https://zhuanlan.zhihu.com/p/42586566 一、冒泡排序 def bubble_sort(lst):for i in range(len(lst) - 1): # 表示第i趟exchange False # 每一趟做标记for j in range(len(lst)-i-1): # 表示箭头if ls…...
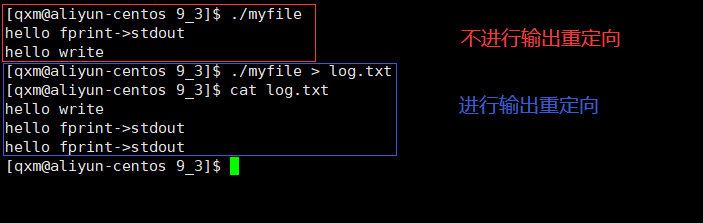
[Linux]文件描述符(万字详解)
[Linux]文件描述符 文章目录 [Linux]文件描述符文件系统接口open函数close函数write函数read函数系统接口与编程语言库函数的关系 文件描述符文件描述符的概念文件数据交换的原理理解“一切皆文件”进程默认文件描述符文件描述符和编程语言的关系 重定向输出重定向输入重定向追…...
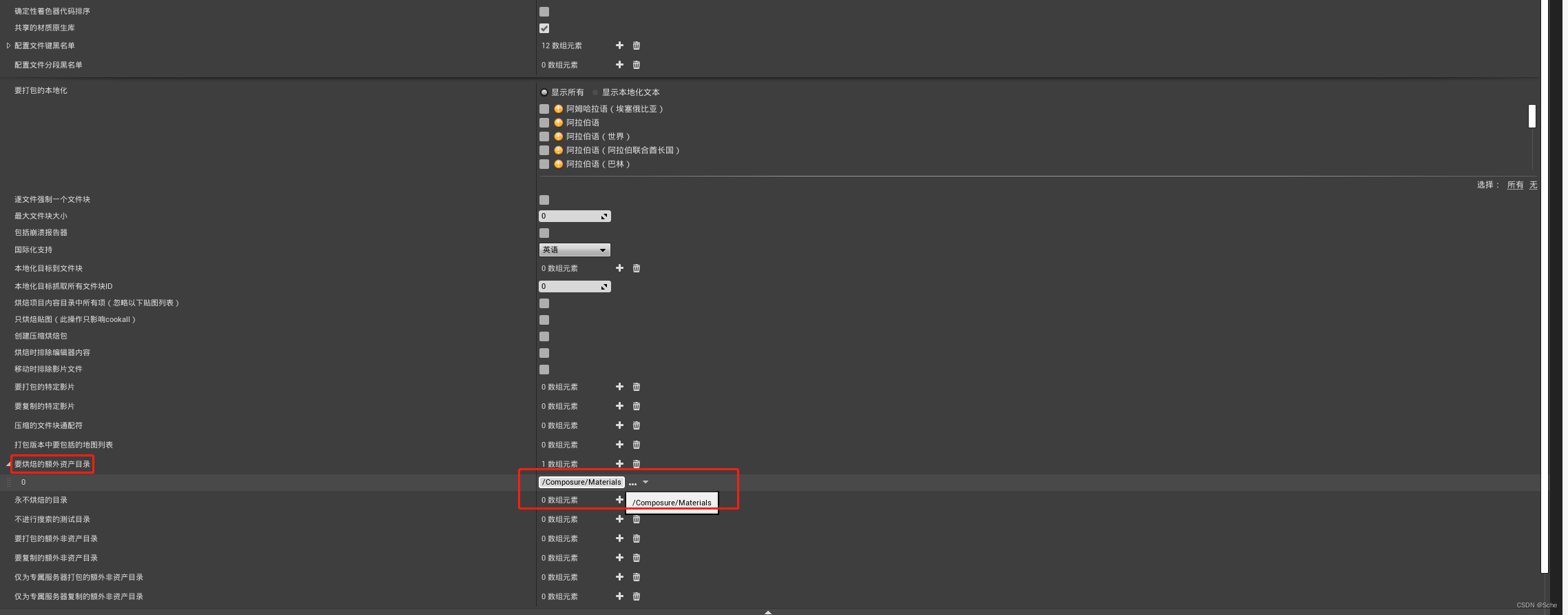
RenderTarget导出成图片,CineCamera相机
一、获取Cinecamera相机图像 1.1、启用UE自带插件 1.2、在UE编辑器窗口栏找到Composure合成,打开窗口 1. 3、右键空白处,新建合成,默认名称为 0010_comp;再右键新建的 0010_comp,新建图层元素 CGLayer层,默…...
深入探讨Java虚拟机(JVM):执行流程、内存管理和垃圾回收机制
目录 什么是JVM? JVM 执行流程 JVM 运行时数据区 堆(线程共享) Java虚拟机栈(线程私有) 什么是线程私有? 程序计数器(线程私有) 方法区(线程共享) JDK 1.8 元空…...
3D 碰撞检测
推荐:使用 NSDT场景编辑器快速搭建3D应用场景 轴对齐边界框 与 2D 碰撞检测一样,轴对齐边界框 (AABB) 是确定两个游戏实体是否重叠的最快算法。这包括将游戏实体包装在一个非旋转(因此轴对齐)的框中&#…...
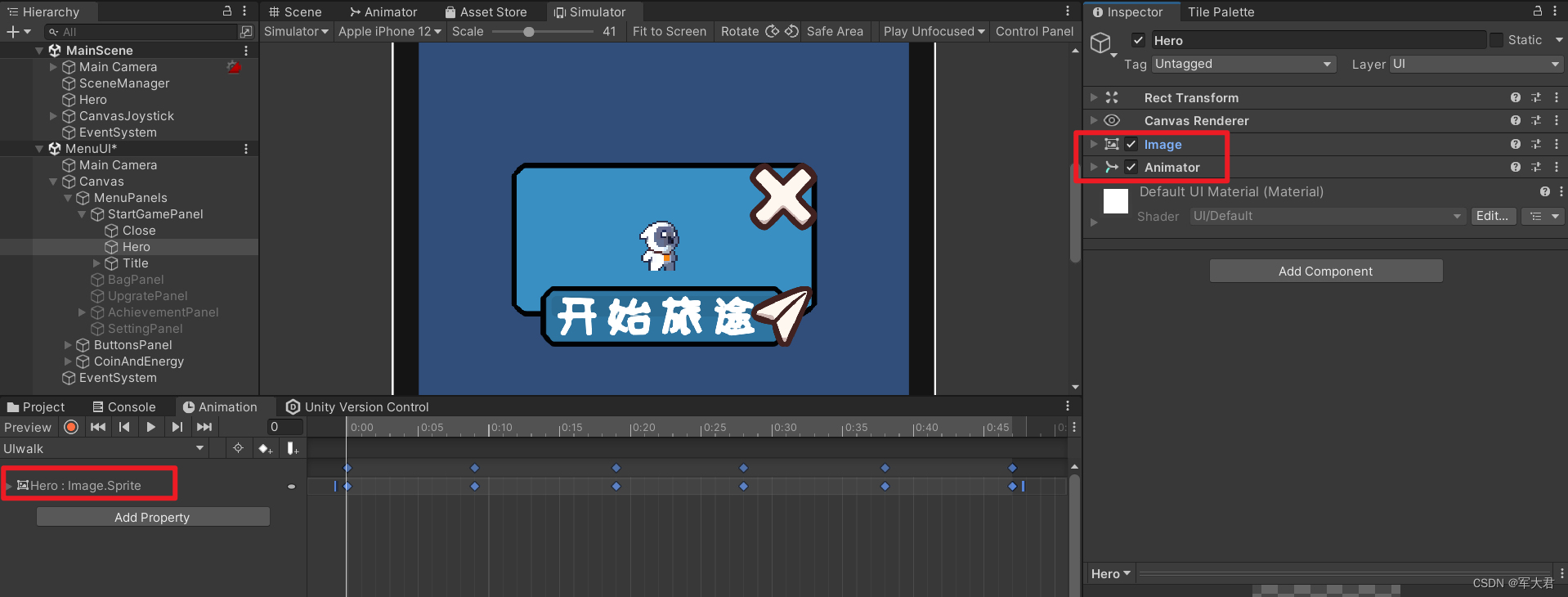
Unity Canvas动画不显示的问题
问题描述: 我通过角色创建了一个walk的动画,当我把这个动画给到Canvas里面的一个image上,这个动画就不能正常播放了,经过一系列的查看我才发现,canvas里面动画播放和非canvas得动画播放,他们的动画参数是不一样的。一个…...

NSSCTF2nd与羊城杯部分记录
文章目录 前言[NSSCTF 2nd]php签到[NSSCTF 2nd]MyBox[NSSCTF 2nd]MyHurricane[NSSCTF 2nd]MyJs[NSSCTF 2nd]MyAPK羊城杯[2023] D0nt pl4y g4m3!!!羊城杯[2023]ezyaml羊城杯[2023]Serpent羊城杯[2023]EZ_web羊城杯[2023]Ez_misc总结 前言 今天周日,有点无聊没事干&a…...

数据库(一) 基础知识
概述 数据库是按照数据结构来组织,存储和管理数据的仓库 数据模型 数据库系统的核心和基础是数据模型,数据模型是严格定义的一组概念的集合。因此数据模型一般由数据结构、数据操作和完整性约束三部分组成。数据模型主要分为三种:层次模型,网状模型和关…...
vue从零开始学习
npm install慢解决方法:删掉nodel_modules。 5.0.3:表示安装指定的5.0.3版本 ~5.0.3:表示安装5.0X中最新的版本 ^5.0.3: 表示安装5.x.x中最新的版本。 yarn的优点: 1.速度快,可以并行安装 2.安装版本统一 项目搭建: 安装nodejs查看node版本:node -v安装vue clie : np…...
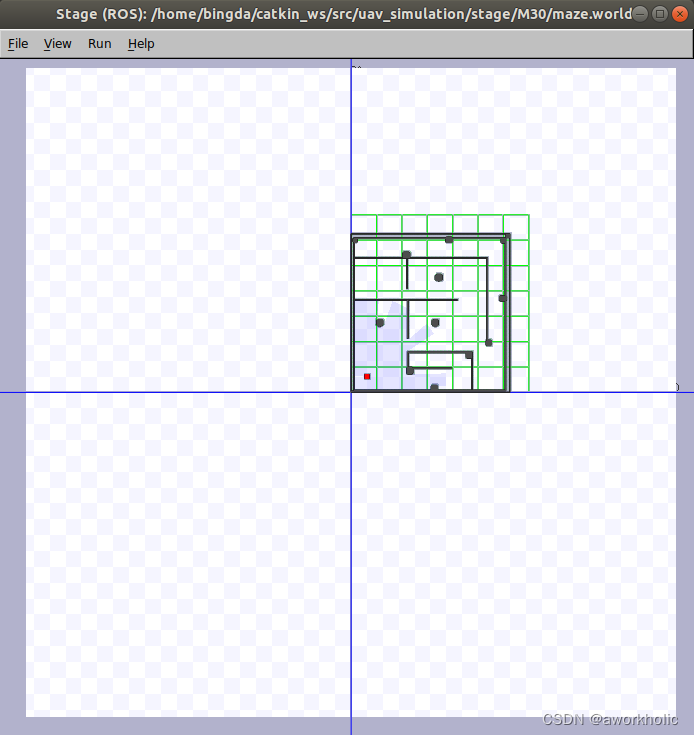
dji uav建图导航系列(三)模拟建图、导航
前面博文【dji uav建图导航系列()建图】、【dji uav建图导航系列()导航】 使用真实无人机和挂载的激光雷达完成建图、导航的任务。 当需要验证某一个slam算法时,我们通常使用模拟环境进行测试,这里使用stageros进行模拟测试,实际就是通过模拟器,虚拟一个带有传感器(如…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...
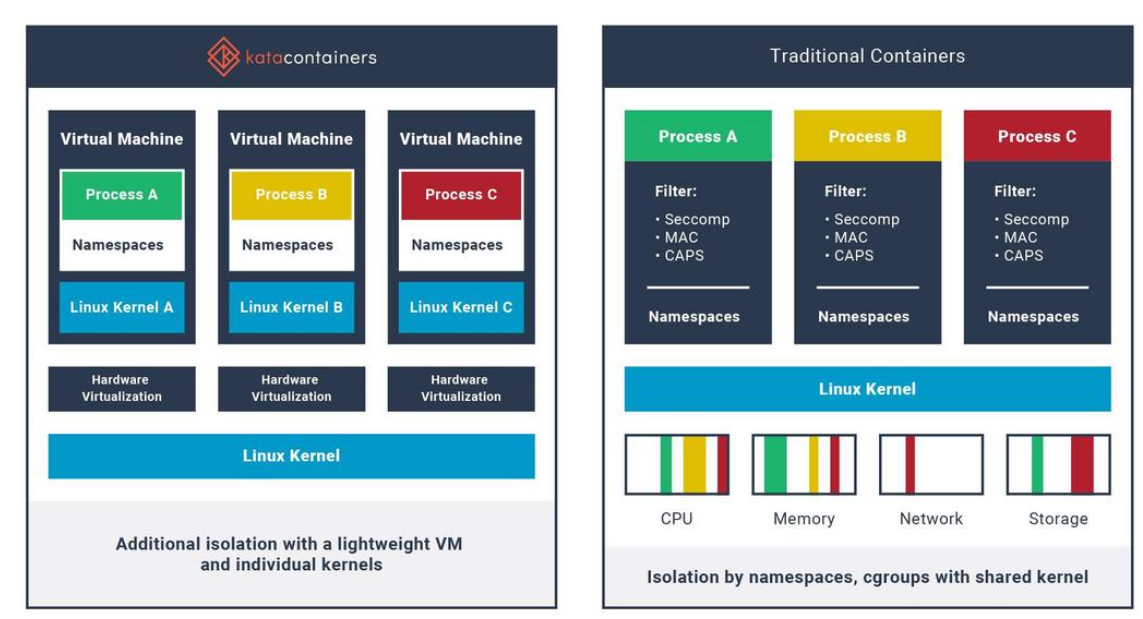
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

RFID推动新能源汽车零部件生产系统管理应用案例
RFID推动新能源汽车零部件生产系统管理应用案例 一、项目背景 新能源汽车零部件场景 在新能源汽车零部件生产领域,电子冷却水泵等关键部件的装配溯源需求日益增长。传统 RFID 溯源方案采用 “网关 RFID 读写头” 模式,存在单点位单独头溯源、网关布线…...

Linux 中替换文件中的某个字符串
如果你想在 Linux 中替换文件中的某个字符串,可以使用以下命令: 1. 基本替换(sed 命令) sed -i s/原字符串/新字符串/g 文件名示例:将 file.txt 中所有的 old_text 替换成 new_text sed -i s/old_text/new_text/g fi…...