《深入浅出OCR》第六章:OCR数据集与评价指标
一、OCR技术流程
在介绍OCR数据集开始,我将带领大家和回顾下OCR技术流程,典型的OCR技术pipline如下图所示,其中,文本检测和识别是OCR技术的两个重要核心技术。

1.1 图像预处理:
图像预处理是OCR流程的第一步,用于提高字符识别的准确性。常见的预处理操作包括灰度化、二值化和去噪。此外针对不规则文本识别,在预处理阶段可以先进行校正操作再进行识别。
1.2 文字检测
文本检测的任务是定位出输入图像中的文字区域。

1.3 文字识别
文本识别的任务是识别出图像中的文字内容。
文本识别一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。
-
规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置,如下图左半部分;
-
不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题,如下图右半部分。

二、OCR数据集统计与分类
2.1 数据集汇总统计
在之前的识别章节中,本人将识别技术分为规则(水平)文本识别与不规则(多方向)文本识别,下面本人总结了常见OCR数据集情况:

参考:github.com/HCIILAB/Sce…
2.2 数据集介绍
在上述数据集简单总结后,本人将重点对数据集展开详细介绍,覆盖规则、不规则、合成、手写数据集等多个场景,最后将总结各个识别算法在不同数据集上的识别效果,进行综合横向对比。
2.1.1 规则数据集
- IIIT5K-Words (IIIT) 2000 for Train; 3000 for Test
- Street View Text (SVT) 257 for Train; 647 for Test
- ICDAR 2003(IC03) 、ICDAR2013 (IC13)
以ICDAR2013为例:
该数据集由500张左右英文标注的自然场景图片构成,坐标格式为左上角和右下角,标注形式为两点水平标注,

2.1.2 不规则数据集
- ICDAR2015 (IC15) 4468 for Train; 2077 for Test;
- SVT Perspective (SP) 645 for Test
- CUTE80 (CT) 288 for Test
以ICDAR2015为例:
该数据集由1500张(训练1000张,测试500张)英文标注的自然场景图片构成,坐标格式依次为为左上角,右上角,右下角和左下角,标注形式为四点标注。如下图所示:

2.1.3 合成数据集
Synthetic Training Datasets
| Dataset | Description | Examples | BaiduNetdisk link |
|---|---|---|---|
| SynthText(ST) | 9 million synthetic text instance images from a set of 90k common English words. Words are rendered onto nartural images with random transformations | Scene text datasets(提取码:emco) | |
| MJSynth(MJ) | 6 million synthetic text instances. It's a generation of SynthText. | Scene text datasets(提取码:emco) |
文本检测数据集使用最为广泛的是SynthText (ST),可以说是OCR领域的 ImageNet。该数据集由牛津大学上发布。数据集采用合成的方式生成,在80万张图片中人工加入了800万个文本,而且这种合成并不是很生硬的叠加,而是作了一些处理,使文字在图片中看起来比较自然。 SynthText规模较大其他的数据集大多不足以训练一个模型。因此,通常是根据中、英文、街景等不同场景识别,先用SynthText训练,然后再用小规模数据集调优。
github:github.com/ankush-me/S…
SynthText(ST) 样例图如下:

2.1.4 中文场景数据集
Chinese Text in the Wild (CTW):

CTW数据集是一个针对中文场景文本的数据集,用于文本检测和识别任务。CTW数据集包含了超过40,000张高分辨率的中文场景图像,这些图像从不同来源和环境中获取,具有广泛的多样性。
2.1.5 手写数据集
数据集网站:CASIA Online and Offline Chinese Handwriting Databases
上述网站提供用于评估手写汉字识别的标准数据集,包括使用现有特征提取算法生成的特征数据和原始字符样本数据。具体规格如下:

2.3.数据集详细介绍
IC03、IC13和IC15是ICDAR(International Conference on Document Analysis and Recognition)2003/2013/2015 Robust Reading Challenge 比赛用数据集,数据集的每一张图片都来自真实的场景,并且做好了标注。但是样本比较少,合起来只有几千张。
1.ICDAR-2013
- 数据简介:该数据集由462(训练集229张,测试集233张)张英文标注的自然场景图片构成,标注形式为两点水平标注,坐标格式为左上角和右下角:

2.ICDAR-2015
- 数据简介:该数据集由1500张(训练集1000张,测试集500张)英文标注的自然场景图片构成,标注形式为四点标注,坐标格式依次为为左上角,右上角,右下角和左下角,如下图所示:

3.ICDAR2017-MLT
- 数据简介:该数据集由9000张(训练集7200张,测试集1800张)多种混合语言标注的自然场景图片构成,标注形式为四点标注,坐标格式依次为为左上角,右上角,右下角和左下角,如下图所示:

4.ICDAR2017-RCTW
- 数据简介:ICDAR 2017-RCTW(Reading Chinest Text in the Wild),由Baoguang Shi等学者提出。RCTW主要是中文,共12263张图像,其中包括了8034张训练集和4229张测试集,标注形式为四点标注,数据集大多是相机拍的自然场景,一些是屏幕截图;其包含了大多数场景,如室外街道、室内场景、手机截图等等。
5.天池比赛2018
- 数据简介:该数据集全部来源于网络图像,主要由合成图像,产品描述和网络广告构成。每一张图像或者包含复杂排版,或者包含密集的小文本或多语言文本,或者包含水印和典型的图片等,如图1所示:

6.ICDAR2019-MLT
- 数据简介:该数据集由20000张(训练集10000张和测试集10000张)多种混合语言标注的自然场景图片构成,标注形式为四点标注,坐标格式依次为为左上角,右上角,右下角和左下角。 10,000个图像在训练集中排序,使得:每个连续的1000个图像包含一种主要语言的文本(当然它可以包含来自1种或2种其他语言的附加文本,全部来自10种语言的集合) 00001 - 01000 :Arabic 01001 - 02000:English 02001 - 03000:French 03001 - 04000:Chinese 04001 - 05000:German 05001 - 06000:Korean 06001 - 07000:Japanese 07001 - 08000:Italian 08001 - 09000:Bangla 09001 - 10000:Hindi 如下图所示:

7.ICDAR2019-LSVT
- 数据简介:该数据集由45w中文街景图像组成,包含5w(2万测试集+3万训练集)全标注数据(文本坐标+文本内容)构成,40w弱标注数据(仅文本内容),标注形式为四点标注,如下图所示:

- 说明:其中,test数据集的label目前没有开源,如需评估结果,可去官网提交:rrc.cvc.uab.es/?ch=16
8.ICDAR2019-ReCTS
- 数据简介:ReCTS数据集包括25,000张带标签的图像,训练集包含20,000张图像,测试集包含5,000张图像。这些图像是在不受控条件下通过电话摄像机野外采集的。它主要侧重于餐厅招牌上的中文文本。数据集中的每个图像都用文本行位置,字符位置以及文本行和字符的成绩单进行注释。用具有四个顶点的多边形来标注位置,这些顶点从左上顶点开始按顺时针顺序排列。如下图所示:

9.ICDAR2019-ArT
- 数据简介:该数据集包含10,166张图像,其中训练集5603张,测试集4563张。由Total-Text、SCUT-CTW1500、Baidu Curved Scene Text (ICDAR2019-LSVT部分弯曲数据) 三部分组成,包含水平、多方向和弯曲等多种形状的文本。 如下图所示:

10.Synth800k
- 数据简介:SynthText 数据集是由牛津大学工程科学系视觉几何组于2016年在IEEE计算机视觉和模式识别会议(CVPR)上发布。数据集由包含单词的自然场景图像组成,其主要运用于自然场景中的文本检测,该数据集由 80 万个图像组成,大约有 800 万个合成单词实例。 每个文本实例均使用文本字符串、字级和字符级边界框进行注释。
11.360万中文数据集
- 数据简介:该数据集利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视和拉伸等变化随机生成共约364万张图片,按照99:1划分成训练集和验证集。 包含汉字、英文字母、数字和标点共5990个字符(字符集合:github.com/YCG09/chine…) 每个样本固定10个字符,字符随机截取于语料库中的句子,图片分辨率统一为280x32。如下图所示:

12.中文街景数据集CTW
- 数据简介:该数据集包含32285张图像,1018402个中文字符(来自于腾讯街景), 包含平面文本,凸起文本,城市文本,农村文本,低亮度文本,远处文本和部分遮挡文本。 图像大小为2048x2048,数据集大小为31GB。以(8:1:1)的比例将数据集分为训练集(25887张图像,812872个汉字),测试集(3269张图像,103519个汉字)和验证集(3129张图像,103519个汉字)。
13.百度中文场景文字识别
- 数据简介:ICDAR2019-LSVT行识别任务,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。 数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如图所示:

14.MSRA-TD500
- 数据简介:该数据集总共包括500张自然场景图片(Training:300 + Test:200)。 数据集特点:多方向文本检测、大部分文本都在引导牌上、分辨率在1296x864到1920x1280之间、包含中英文、标注以行为单位,而不是单词、每张图片都完全标注,难以识别的有difficult标注。
15.total-text
- 数据简介:总共包含500张自然场景图片(Training:1255 + Test:300)。 数据集特点:Total-Text是最大弯曲文本数据集之一-ArT(任意形状文本数据集)训练集中的一部分。
2.4 数据集下载
常见数据集下载一
项目github地址:github.com/zcswdt/OCR_…
代码仓库提供常用的OCR检测和识别中的通用公开数据集的下载链接。并且提供了json标签转成.txt标签的代码和转换好的.txt标签。
| 数据集 | 数据介绍 | 标注格式 | 下载地址 |
|---|---|---|---|
| ICDAR_2013 | 语言: 英文 train:229 test:233 | x1 y1 x2 y2 text | 下载链接1 . |
| ICDAR_2015 | 语言: 英文 train:1000 test:500 | x1,y1,x2,y2,x3,y3,x4,y4,text | 下载链接2 . |
| ICDAR2017-MLT | 语言: 混合 train:7200 test:1800 | x1,y1,x2,y2,x3,y3,x4,y4,text | 下载链接3 . 提取码: z9ey |
| ICDAR2017-RCTW | 语言: 混合 train:8034 test:4229 | x1,y1,x2,y2,x3,y3,x4,y4,<识别难易程度>,text | 下载链接4 |
| 天池比赛2018 | 语言: 混合 train:10000 test:10000 | x1,y1,x2,y2,x3,y3,x4,y4,text | 检测5 。 识别6 |
| ICDAR2019-MLT | 语言: 混合 train:10000 test:10000 | x1,y1,x2,y2,x3,y3,x4,y4,语言类别,text | 下载链接7 . 提取码: xofo |
| ICDAR2019-LSVT | 语言: 混合 train:30000 test:20000 | json格式标签 | 下载链接8 |
| ICDAR2019-ReCTS | 语言: 混合 train:20000 test:5000 | json格式标签 | 下载链接9 |
| ICDAR2019-ArT | 语言: 混合 train:5603 test:4563 | json格式标签 | 下载链接10 |
| Synth800k | 语言: 英文 80k | 基于字符标注 | 下载链接11 |
| 360万中文数据集 | 语言: 中文 360k | 每张图片由10个字符构成 | 下载链接12 . 提取码:lu7m |
| 中文街景数据集CTW | 语言:中文 32285 | 基于字符标注的中文街景图片 | 下载链接13 |
| 百度中文场景文字识别 | 语言: 混合 29万 | 下载链接14 |
常见数据集下载二
| Dataset | Description | Examples | BaiduNetdisk link |
|---|---|---|---|
| IIIT5k-Words(IIIT5K) | 3000 test images instances. Take from street scenes and from originally-digital images | Scene text datasets(提取码:emco) | |
| Street View Text(SVT) | 647 test images instances. Some images are severely corrupted by noise, blur, and low resolution | Scene text datasets(提取码:emco) | |
| StreetViewText-Perspective(SVT-P) | 639 test images instances. It is specifically designed to evaluate perspective distorted textrecognition. It is built based on the original SVT dataset by selecting the images at the sameaddress on Google Street View but with different view angles. Therefore, most text instancesare heavily distorted by the non-frontal view angle. | Scene text datasets(提取码:emco) | |
| ICDAR 2003(IC03) | 867 test image instances | Scene text datasets(提取码:mfir) | |
| ICDAR 2013(IC13) | 1015 test images instances | Scene text datasets(提取码:emco) | |
| ICDAR 2015(IC15) | 2077 test images instances. As text images were taken by Google Glasses without ensuringthe image quality, most of the text is very small, blurred, and multi-oriented | Scene text datasets(提取码:emco) | |
| CUTE80(CUTE) | 288 It focuses on curved text recognition. Most images in CUTE have acomplex background, perspective distortion, and poor resolution | Scene text datasets(提取码:emco) |
参考:zhuanlan.zhihu.com/p/356842725
三、数据生成
在深度学习系统目标检测完成后,往往还需用分类器对检测区域进行识别。针对实际业务场景,需要根据具体的业务分析所需的背景、字体、颜色、形变以及语料等信息。
目前主流的识别数据生成方法可大致分为三类:基于特征变换的图像增强、基于深度学习的图像增强和GAN生成法。
3.1 基于特征变换的图像增强
这类方法是对现有的数据进行图像增广进而扩充数据量。在文字识别的训练中,由于文字的特殊性,能够选择的增强方法有限,主要有以下4种类型:
1)模糊。
2)对比度变化。
3)拉伸。
4)旋转。
3.2 深度学习OCR数据生成
此方法也是对现有的数据进行图像增广而扩充数据规模,具体的文本生成过程分为六步:
1)字体渲染。
2)描边、加阴影、着色。
3)基础着色。
4)仿射投影扭曲。模拟3D环境。
5)自然数据混合。
6)加噪声。
参考资源:
1)物体检测的增强。Imgaug:github.com/aleju/imgau…
2)Augmentor:github.com/mdbloice/Au…
3.3 对抗网络GAN数据生成
在实际应用中由于身份证数据、银行卡数据等涉及个人信息的数据往往很难获取,且容易违反法律规定。借助GAN(Generative Adversarial Network,生成对抗网络)可以在一定程度上缓解上述问题。目前GAN的应用场景基本上覆盖了AI的所有领域,例如图像和音频的生成、图像风格迁移、图像修复(去噪和去马赛克)、NLP中的文本生成等。
**生成对抗网络是在生成模型的基础上引入对抗博弈的思想。**假设我们有一个图像生成模型Generator,它的目标是生成一张比较真实的图像,与此同时,我们还有一个图像判别模型Discriminator,它的目标是正确的判别一张图像是生成的还是真实的。具体流程如下:
1)生成模型Generator生成一批图像。
2)判别模型Discriminator学习区分生成图像和真实图像。
3)生成模型根据判别模型反馈结果来改进生成模型,迭代生成新图像。
4)判别模型继续学习区分生成图像和真实图像。
直到二者收敛,此时生成模型和判别模型都能达到比较好的效果。上述的博弈类似《射雕英雄传》中周伯通的左右互搏术,能循环提升生成模型和判别模型的能力。在生成模型中采用神经网络作为主干/backbone,则称之为生成对抗网络。GAN模型结构如下图所示。

3.4 文本图片数据合成工具
3.4.1 图像合成相关论文
衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。

3.4.2 文本图片数据合成工具
开源工具代码:
- ✨text_renderer
- SynthText
- SynthText_Chinese_version
- TextRecognitionDataGenerator
- SynthText3D
- UnrealText
- synthtiger
- ✨PaddleOCR/StyleText
- SRNet
其他数据生成项目:
Github :BADBADBADBOY genete_ocr_data
其余待补充!!!
四、OCR评价指标
4.1 OCR常用的评估指标:
对于两阶段可以分开来看,分别是检测和识别阶段。
(1)检测阶段:先按照检测框和标注框的IOU评估,IOU大于某个阈值判断为检测准确。这里检测框和标注框不同于一般的通用目标检测框,是采用多边形进行表示。
检测准确率: 正确的检测框个数在全部检测框的占比,主要是判断检测指标。
检测召回率: 正确的检测框个数在全部标注框的占比,主要是判断漏检的指标。
(2)识别阶段: 字符识别准确率,即正确识别的文本行占标注的文本行数量的比例,只有整行文本识别对才算正确识别。
(3)端到端统计:
端对端召回率: 准确检测并正确识别文本行在全部标注文本行的占比;
端到端准确率: 准确检测并正确识别文本行在 检测到的文本行数量 的占比;
准确检测的标准是检测框与标注框的IOU大于某个阈值,正确识别的的检测框中的文本与标注的文本相同。
另外从单词角度分,OCR评价指标包括字段粒度和字符粒度的识别效果评价指标。
- 以字段为单位的统计和分析,适用于卡证类、 票据类等结构化程度较高的OCR 应用评测。
- 以字符 (文字和标点符号) 为单位的统计和分析,适用于通用印刷体、手写体类非结构化数据的OCR应用评测。
此外,从服务角度来说,识出率、平均耗时等也是衡量OCR系统好坏的指标之一。
4.2 编辑距离:
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。在莱文斯坦距离中,可以删除、加入、替换字符串中的任何一个字元,也是较常用的编辑距离定义,常常提到编辑距离时,指的就是莱文斯坦距离。

公式如下:


- 平均识别率:[ 1 - (编辑距离 / max(1, groundtruth字符数, predict字符数) ) ] * 100.0% 的平均值;
- 平均编辑距离:编辑距离,用来评估整体的检测和识别模型;
- 平均替换错误:编辑距离计算时的替换操作,用于评估识别模型对相似字符的区分能力;
- 平均多字错误:编辑距离计算时的删除操作,用来评估检测模型的误检和识别模型的多字错误;
- 平均漏字错误:编辑距离计算时的插入操作,用来评估检测模型的漏检和识别模型的少字错误;
代码实现:
ini
复制代码
#代码 import Levenshtein def evaluate_measure(str_algorithm, str_ground_truth): # 编辑距离 insert + delete + replace edit_dist = Levenshtein.distance(str_algorithm, str_ground_truth) sum_len_two_str = len(str_algorithm) + len(str_ground_truth) ratio = Levenshtein.ratio(str_algorithm, str_ground_truth) ldist = sum_len_two_str - (float(ratio) * float(sum_len_two_str)) # 替换操作 replace_dist = ldist - edit_dist if len(str_algorithm) > len(str_ground_truth): more_word_error = len(str_algorithm) - len(str_ground_truth) less_word_error = 0 else: more_word_error = 0 less_word_error = len(str_ground_truth) - len(str_algorithm) # - 平均识别率:[1 - (编辑距离 / max(1, groundtruth字符数, predict字符数))] * 100.0 % 的平均值; recg_rate = "{:.2%}".format(1 - (edit_dist / max(1, len(str_algorithm), len(str_ground_truth)))) print("识别率, 编辑距离, 替换错误, 漏字错误, 多字错误") print(recg_rate, edit_dist, replace_dist, less_word_error, more_word_error) return recg_rate, edit_dist, replace_dist, less_word_error, more_word_error
4.3 归一化编辑距离:


五、常见OCR识别模型评估对比
注:评价指标为准确率。
| Regular Dataset | Irregular dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Year | IIIT | SVT | IC13(857) | IC13(1015) | IC15(1811) | IC15(2077) | SVTP | CUTE | |
| CRNN | 2015 | 78.2 | 80.8 | - | 86.7 | - | - | - | - | |
| ASTER(L2R) | 2015 | 92.67 | 91.16 | - | 90.74 | 76.1 | - | 78.76 | 76.39 | |
| CombBest | 2019 | 87.9 | 87.5 | 93.6 | 92.3 | 77.6 | 71.8 | 79.2 | 74 | |
| ESIR | 2019 | 93.3 | 90.2 | - | 91.3 | - | 76.9 | 79.6 | 83.3 | |
| SE-ASTER | 2020 | 93.8 | 89.6 | - | 92.8 | 80 | 81.4 | 83.6 | ||
| DAN | 2020 | 94.3 | 89.2 | - | 93.9 | - | 74.5 | 80 | 84.4 | |
| RobustScanner | 2020 | 95.3 | 88.1 | - | 94.8 | - | 77.1 | 79.5 | 90.3 | |
| AutoSTR | 2020 | 94.7 | 90.9 | - | 94.2 | 81.8 | - | 81.7 | - | |
| Yang et al. | 2020 | 94.7 | 88.9 | - | 93.2 | 79.5 | 77.1 | 80.9 | 85.4 | |
| SATRN | 2020 | 92.8 | 91.3 | - | 94.1 | - | 79 | 86.5 | 87.8 | |
| SRN | 2020 | 94.8 | 91.5 | 95.5 | - | 82.7 | - | 85.1 | 87.8 | |
| GA-SPIN | 2021 | 95.2 | 90.9 | - | 94.8 | 82.8 | 79.5 | 83.2 | 87.5 | |
| PREN2D | 2021 | 95.6 | 94 | 96.4 | - | 83 | - | 87.6 | 91.7 | |
| Bhunia et al. | 2021 | 95.2 | 92.2 | - | 95.5 | - | 84 | 85.7 | 89.7 | |
| Luo et al. | 2021 | 95.6 | 90.6 | - | 96.0 | 83.9 | 81.4 | 85.1 | 91.3 | |
| VisionLAN | 2021 | 95.8 | 91.7 | 95.7 | - | 83.7 | - | 86 | 88.5 | |
| ABINet | 2021 | 96.2 | 93.5 | 97.4 | - | 86.0 | - | 89.3 | 89.2 | |
| MATRN | 2021 | 96.7 | 94.9 | 97.9 | 95.8 | 86.6 | 82.9 | 90.5 | 94.1 |
六、OCR资料整理分享:
本篇文章最后,免费分享博主本人参考开源资料整理的OCR相关论文汇总,将其按年份、数据集、所属方法及论文关键词等信息进行全面分类总结,最近几年论文正在整理中,欢迎大家持续关注和学习交流!另外,文中如有错误,欢迎指正!

总结:本篇《第六章:OCR数据集与评价指标主要介绍OCR的数据集分类、应用场景及检测、识别等评价指标等进行介绍,方便学习者快速了解OCR方向知识。
相关文章:
《深入浅出OCR》第六章:OCR数据集与评价指标
一、OCR技术流程 在介绍OCR数据集开始,我将带领大家和回顾下OCR技术流程,典型的OCR技术pipline如下图所示,其中,文本检测和识别是OCR技术的两个重要核心技术。 1.1 图像预处理: 图像预处理是OCR流程的第一步…...
15. 线性代数 - 克拉默法则
文章目录 克拉默法则矩阵运算Hi,大家好。我是茶桁。 上节课我们在最后提到了一个概念「克拉默法则」,本节课,我们就来看看到底什么是克拉默法则。 克拉默法则 之前的课程我们一直在强调,矩阵是线性方程组抽象的来的。那么既然我们抽象出来了,有没有一种比较好的办法高效…...
【LeetCode】剑指 Offer <二刷>(6)
目录 题目:剑指 Offer 12. 矩阵中的路径 - 力扣(LeetCode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 13. 机器人的运动范围 - 力扣&#…...
jsp页面出现“String cannot be resolved to a type”错误解决办法
篇首语:小编为大家整理,主要介绍了jsp页面出现“String cannot be resolved to a type”错误解决办法相关的知识,希望对你有一定的参考价值。 jsp页面出现“String cannot be resolved to a type”错误解决办法 解决办法: 右键项目…...

【go-zero】使用自带Redis方法
yaml配置文件 RedisS:Host: Type: Pass: config增加 RedisS struct {Host stringType stringPass string}svc文件 type * struct {RedisClient *redis.Redis } func *(c config.Config) * {sqlConn : sqlx.NewMysql(c.DB.DataSource)return &*{RedisClient: redis.New(c…...
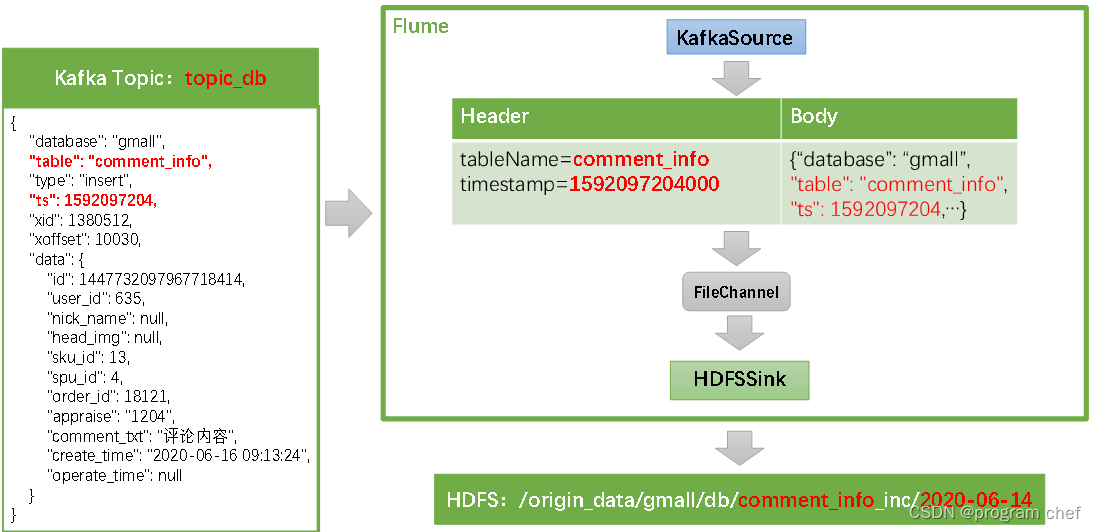
离线数仓同步数据3
业务数据_增量表数据同步 1)Flume配置概述2)Flume配置实操3)通道测试4)编写Flume启停脚本 1)Flume配置概述 Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSinkÿ…...
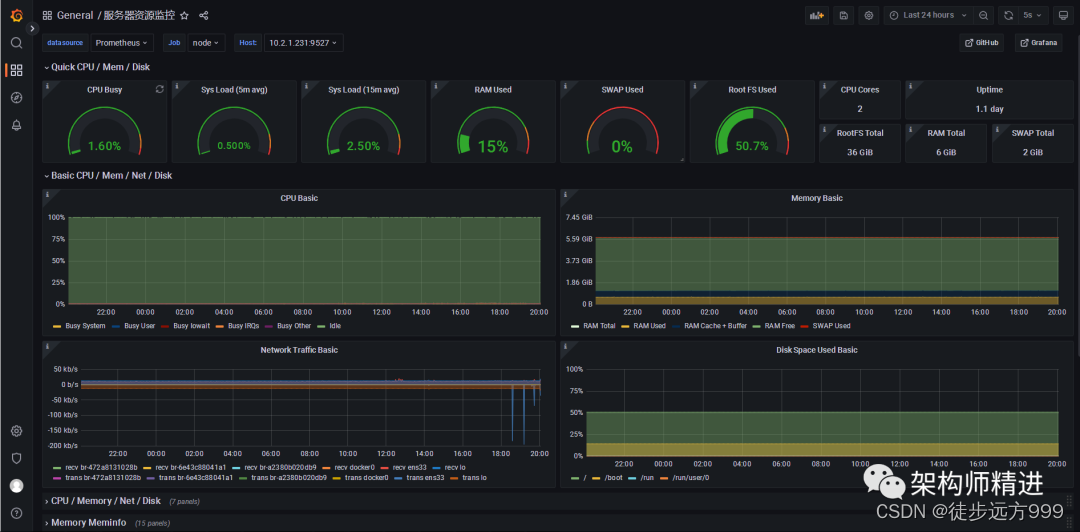
Prometheus+Grafana 搭建应用监控系统
一、背景 完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus Grafana搭建完整的应用监控系统。 …...

Spring Boot整合Log4j2.xml的问题
文章目录 问题解决参考 问题 Spring Boot整合Log4j2.xml的时候返回以下错误: Caused by: org.apache.logging.log4j.LoggingException: log4j-slf4j-impl cannot be present with log4j-to-slf4j 进行了解决。 解决 Spring Boot整合Log4j2.xml经过以下操作&#…...
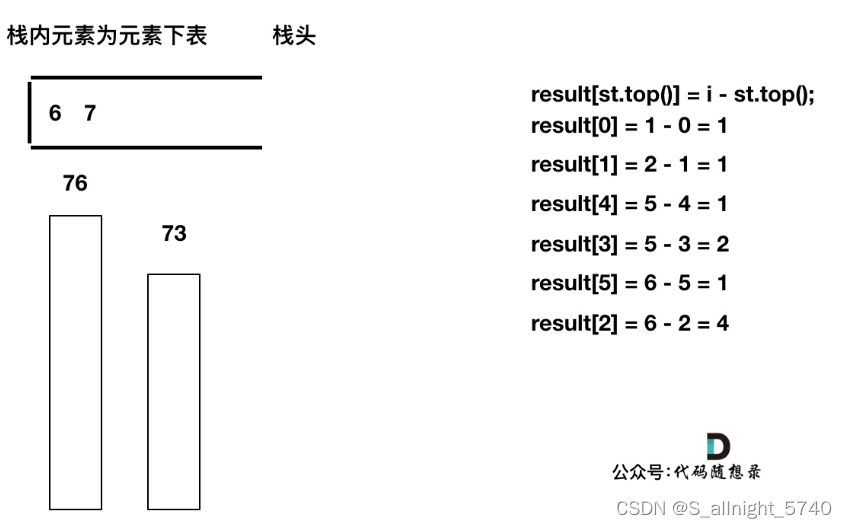
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 739. 每日温度 题目链接 视频讲解 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answe…...

【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
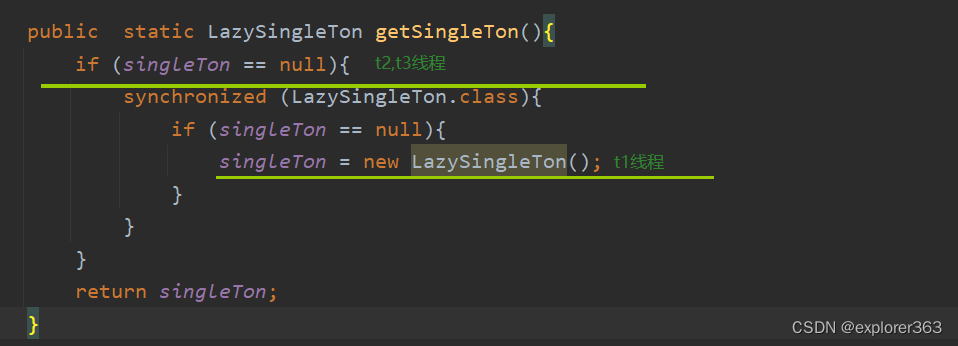
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
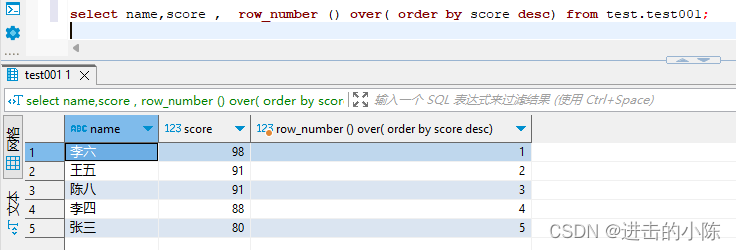
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...