kakfa 3.5 kafka服务端处理消费者客户端拉取数据请求源码
- 一、服务端接收消费者拉取数据的方法
- 二、遍历请求中需要拉取数据的主题分区集合,分别执行查询数据操作,
- 1、会选择合适的副本读取本地日志数据(2.4版本后支持主题分区多副本下的读写分离)
- 三、会判断当前请求是主题分区Follower发送的拉取数据请求还是消费者客户端拉取数据请求
- 1、拉取数据之前首先要得到leaderIsrUpdateLock的读锁
- 2、readFromLocalLog读取本地日志数据
- 四、读取日志数据就是读取的segment文件(忽视零拷贝的加持)
- 1、获取当前本地日志的基础数据(高水位线,偏移量等),
- 2、遍历segment,直到从segment读取到数据
- 五、创建文件日志流对象FileRecords
- 1、根据位点创建文件流FileLogInputStream
- 2、把文件流构建成数据批量迭代器对象RecordBatchIterator
- 3、DefaultRecordBatch实现iterator方法,在内存中创建数据
一、服务端接收消费者拉取数据的方法
kafka服务端接收生产者数据的API在KafkaApis.scala类中,handleFetchRequest方法
override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {//省略代码request.header.apiKey match {//消费者拉取消息请求,这个接口进行处理case ApiKeys.FETCH => handleFetchRequest(request)//省略代码} }
def handleFetchRequest(request: RequestChannel.Request): Unit = {//从请求中获取请求的API版本(versionId)和客户端ID(clientId)。val versionId = request.header.apiVersionval clientId = request.header.clientId//从请求中获取Fetch请求的数据val fetchRequest = request.body[FetchRequest]//根据请求的版本号,决定是否获取主题名称的映射关系(topicNames)。如果版本号大于等于13,则使用metadataCache.topicIdsToNames()获取主题名称映射关系,否则使用空的映射关系。val topicNames =if (fetchRequest.version() >= 13)metadataCache.topicIdsToNames()elseCollections.emptyMap[Uuid, String]()//根据主题名称映射关系,获取Fetch请求的数据(fetchData)和需要忽略的主题(forgottenTopics)。val fetchData = fetchRequest.fetchData(topicNames)val forgottenTopics = fetchRequest.forgottenTopics(topicNames)//创建一个Fetch上下文(fetchContext),用于管理Fetch请求的处理过程。该上下文包含了Fetch请求的版本号、元数据、是否来自Follower副本、Fetch数据、需要忽略的主题和主题名称映射关系。val fetchContext = fetchManager.newContext(fetchRequest.version,fetchRequest.metadata,fetchRequest.isFromFollower,fetchData,forgottenTopics,topicNames)//初始化两个可变数组erroneous和interesting,用于存储处理过程中的错误和请求需要哪些topic的数据。val erroneous = mutable.ArrayBuffer[(TopicIdPartition, FetchResponseData.PartitionData)]()val interesting = mutable.ArrayBuffer[(TopicIdPartition, FetchRequest.PartitionData)]()//Fetch请求来自Follower副本if (fetchRequest.isFromFollower) {//则需要验证权限。如果权限验证通过// The follower must have ClusterAction on ClusterResource in order to fetch partition data.if (authHelper.authorize(request.context, CLUSTER_ACTION, CLUSTER, CLUSTER_NAME)) {//遍历每个分区的数据,根据不同情况将数据添加到erroneous或interesting中fetchContext.foreachPartition { (topicIdPartition, data) =>if (topicIdPartition.topic == null)erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.UNKNOWN_TOPIC_ID)else if (!metadataCache.contains(topicIdPartition.topicPartition))erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)elseinteresting += topicIdPartition -> data}} else {//如果权限验证失败,则将所有分区的数据添加到erroneous中。fetchContext.foreachPartition { (topicIdPartition, _) =>erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.TOPIC_AUTHORIZATION_FAILED)}}} else {//如果Fetch请求来自普通的Kafka消费者// Regular Kafka consumers need READ permission on each partition they are fetching.val partitionDatas = new mutable.ArrayBuffer[(TopicIdPartition, FetchRequest.PartitionData)]fetchContext.foreachPartition { (topicIdPartition, partitionData) =>if (topicIdPartition.topic == null)erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.UNKNOWN_TOPIC_ID)elsepartitionDatas += topicIdPartition -> partitionData}//需要验证对每个分区的读取权限,根据权限验证结果,将数据添加到erroneous或interesting中。val authorizedTopics = authHelper.filterByAuthorized(request.context, READ, TOPIC, partitionDatas)(_._1.topicPartition.topic)partitionDatas.foreach { case (topicIdPartition, data) =>if (!authorizedTopics.contains(topicIdPartition.topic))erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.TOPIC_AUTHORIZATION_FAILED)else if (!metadataCache.contains(topicIdPartition.topicPartition))erroneous += topicIdPartition -> FetchResponse.partitionResponse(topicIdPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)elseinteresting += topicIdPartition -> data}}//省略代码//如果需要的topic没有校验通过或者不存在,则直接调用processResponseCallback处理响应if (interesting.isEmpty) {processResponseCallback(Seq.empty)} else {// for fetch from consumer, cap fetchMaxBytes to the maximum bytes that could be fetched without being throttled given// no bytes were recorded in the recent quota window// trying to fetch more bytes would result in a guaranteed throttling potentially blocking consumer progress//如果是Follower提取数据的请求,则maxQuotaWindowBytes设置为int类型的最大,否则从记录中得到此client以前获取数据大小,// 再和请求中、配置文件中的fetchMaxBytes比较得到下面fetchMaxBytes和fetchMinBytes两个值val maxQuotaWindowBytes = if (fetchRequest.isFromFollower)Int.MaxValueelsequotas.fetch.getMaxValueInQuotaWindow(request.session, clientId).toInt//根据请求的类型和配额限制,获取Fetch请求的最大字节数(fetchMaxBytes)和最小字节数(fetchMinBytes)val fetchMaxBytes = Math.min(Math.min(fetchRequest.maxBytes, config.fetchMaxBytes), maxQuotaWindowBytes)val fetchMinBytes = Math.min(fetchRequest.minBytes, fetchMaxBytes)val clientMetadata: Optional[ClientMetadata] = if (versionId >= 11) {// Fetch API version 11 added preferred replica logic//提取 API 版本 11以上 添加了首选副本逻辑Optional.of(new DefaultClientMetadata(fetchRequest.rackId,clientId,request.context.clientAddress,request.context.principal,request.context.listenerName.value))} else {Optional.empty()}//创建一个FetchParams对象,包含了请求的各种参数val params = new FetchParams(versionId,fetchRequest.replicaId,fetchRequest.replicaEpoch,fetchRequest.maxWait,fetchMinBytes,fetchMaxBytes,FetchIsolation.of(fetchRequest),clientMetadata)// call the replica manager to fetch messages from the local replica//replicaManager.fetchMessages方法,从本地副本获取消息,并提供回调函数processResponseCallback处理响应replicaManager.fetchMessages(params = params,fetchInfos = interesting,quota = replicationQuota(fetchRequest),responseCallback = processResponseCallback,)}
}
replicaManager.fetchMessages 最后通过这个方法获得日志
/*** Fetch messages from a replica, and wait until enough data can be fetched and return;* the callback function will be triggered either when timeout or required fetch info is satisfied.* Consumers may fetch from any replica, but followers can only fetch from the leader.* 从副本中获取消息,并等待可以获取足够的数据并返回;* 当满足超时或所需的获取信息时,将触发回调函数。* 消费者可以从任何副本中获取,但追随者只能从领导者那里获取。*/def fetchMessages(params: FetchParams,fetchInfos: Seq[(TopicIdPartition, PartitionData)],quota: ReplicaQuota,responseCallback: Seq[(TopicIdPartition, FetchPartitionData)] => Unit): Unit = {// check if this fetch request can be satisfied right away//调用readFromLocalLog函数从本地日志中读取消息,并将结果保存在logReadResults中。val logReadResults = readFromLocalLog(params, fetchInfos, quota, readFromPurgatory = false)var bytesReadable: Long = 0var errorReadingData = falsevar hasDivergingEpoch = falsevar hasPreferredReadReplica = falseval logReadResultMap = new mutable.HashMap[TopicIdPartition, LogReadResult]//根据读取结果更新一些变量,如bytesReadable(可读取的字节数)、errorReadingData(是否读取数据时发生错误)、hasDivergingEpoch(是否存在不同的epoch)和hasPreferredReadReplica(是否存在首选读取副本)。logReadResults.foreach { case (topicIdPartition, logReadResult) =>brokerTopicStats.topicStats(topicIdPartition.topicPartition.topic).totalFetchRequestRate.mark()brokerTopicStats.allTopicsStats.totalFetchRequestRate.mark()if (logReadResult.error != Errors.NONE)errorReadingData = trueif (logReadResult.divergingEpoch.nonEmpty)hasDivergingEpoch = trueif (logReadResult.preferredReadReplica.nonEmpty)hasPreferredReadReplica = truebytesReadable = bytesReadable + logReadResult.info.records.sizeInByteslogReadResultMap.put(topicIdPartition, logReadResult)}// respond immediately if 1) fetch request does not want to wait 不需要等待// 2) fetch request does not require any data 不需要任何数据// 3) has enough data to respond 有足够的数据// 4) some error happens while reading data 读取数据时发生错误// 5) we found a diverging epoch 存在不同的epoch// 6) has a preferred read replica 存在首选读取副本if (params.maxWaitMs <= 0 || fetchInfos.isEmpty || bytesReadable >= params.minBytes || errorReadingData ||hasDivergingEpoch || hasPreferredReadReplica) {val fetchPartitionData = logReadResults.map { case (tp, result) =>val isReassignmentFetch = params.isFromFollower && isAddingReplica(tp.topicPartition, params.replicaId)tp -> result.toFetchPartitionData(isReassignmentFetch)}responseCallback(fetchPartitionData)} else {//将构建一个延迟处理的DelayedFetch对象,并将其放入延迟处理队列(delayedFetchPurgatory)中,以便在满足特定条件时完成请求。// construct the fetch results from the read resultsval fetchPartitionStatus = new mutable.ArrayBuffer[(TopicIdPartition, FetchPartitionStatus)]fetchInfos.foreach { case (topicIdPartition, partitionData) =>logReadResultMap.get(topicIdPartition).foreach(logReadResult => {val logOffsetMetadata = logReadResult.info.fetchOffsetMetadatafetchPartitionStatus += (topicIdPartition -> FetchPartitionStatus(logOffsetMetadata, partitionData))})}val delayedFetch = new DelayedFetch(params = params,fetchPartitionStatus = fetchPartitionStatus,replicaManager = this,quota = quota,responseCallback = responseCallback)// create a list of (topic, partition) pairs to use as keys for this delayed fetch operationval delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => TopicPartitionOperationKey(tp) }// try to complete the request immediately, otherwise put it into the purgatory;// this is because while the delayed fetch operation is being created, new requests// may arrive and hence make this operation completable.delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys)}}
通过readFromLocalLog查询数据日志
二、遍历请求中需要拉取数据的主题分区集合,分别执行查询数据操作,
/*** Read from multiple topic partitions at the given offset up to maxSize bytes* 以给定的偏移量从多个主题分区读取最大最大大小字节*/def readFromLocalLog(params: FetchParams,readPartitionInfo: Seq[(TopicIdPartition, PartitionData)],quota: ReplicaQuota,readFromPurgatory: Boolean): Seq[(TopicIdPartition, LogReadResult)] = {val traceEnabled = isTraceEnableddef read(tp: TopicIdPartition, fetchInfo: PartitionData, limitBytes: Int, minOneMessage: Boolean): LogReadResult = {//从fetchInfo中获取一些数据,包括fetchOffset(拉取偏移量)、maxBytes(拉取的最大字节数)和logStartOffset(日志起始偏移量)。val offset = fetchInfo.fetchOffsetval partitionFetchSize = fetchInfo.maxBytesval followerLogStartOffset = fetchInfo.logStartOffset//计算调整后的最大字节数adjustedMaxBytes,取fetchInfo.maxBytes和limitBytes的较小值。val adjustedMaxBytes = math.min(fetchInfo.maxBytes, limitBytes)try {if (traceEnabled)trace(s"Fetching log segment for partition $tp, offset $offset, partition fetch size $partitionFetchSize, " +s"remaining response limit $limitBytes" +(if (minOneMessage) s", ignoring response/partition size limits" else ""))//获取指定分区的Partition对象val partition = getPartitionOrException(tp.topicPartition)//获取当前时间戳fetchTimeMsval fetchTimeMs = time.milliseconds//检查拉取请求或会话中的主题ID是否与日志中的主题ID一致,如果不一致则抛出InconsistentTopicIdException异常。val topicId = if (tp.topicId == Uuid.ZERO_UUID) None else Some(tp.topicId)if (!hasConsistentTopicId(topicId, partition.topicId))throw new InconsistentTopicIdException("Topic ID in the fetch session did not match the topic ID in the log.")// If we are the leader, determine the preferred read-replica//根据一些条件选择合适的副本(replica)进行后续的数据抓取(fetch)。val preferredReadReplica = params.clientMetadata.asScala.flatMap(metadata => findPreferredReadReplica(partition, metadata, params.replicaId, fetchInfo.fetchOffset, fetchTimeMs))if (preferredReadReplica.isDefined) {//如果不存在,则跳过读取操作,直接构建一个LogReadResult对象,表示从非Leader副本获取数据的结果。replicaSelectorOpt.foreach { selector =>debug(s"Replica selector ${selector.getClass.getSimpleName} returned preferred replica " +s"${preferredReadReplica.get} for ${params.clientMetadata}")}// If a preferred read-replica is set, skip the readval offsetSnapshot = partition.fetchOffsetSnapshot(fetchInfo.currentLeaderEpoch, fetchOnlyFromLeader = false)LogReadResult(info = new FetchDataInfo(LogOffsetMetadata.UNKNOWN_OFFSET_METADATA, MemoryRecords.EMPTY),divergingEpoch = None,highWatermark = offsetSnapshot.highWatermark.messageOffset,leaderLogStartOffset = offsetSnapshot.logStartOffset,leaderLogEndOffset = offsetSnapshot.logEndOffset.messageOffset,followerLogStartOffset = followerLogStartOffset,fetchTimeMs = -1L,lastStableOffset = Some(offsetSnapshot.lastStableOffset.messageOffset),preferredReadReplica = preferredReadReplica,exception = None)} else {// Try the read first, this tells us whether we need all of adjustedFetchSize for this partition//尝试进行读取操作。根据读取结果构建一个LogReadResult对象,表示从分区获取数据的结果。val readInfo: LogReadInfo = partition.fetchRecords(fetchParams = params,fetchPartitionData = fetchInfo,fetchTimeMs = fetchTimeMs,maxBytes = adjustedMaxBytes,minOneMessage = minOneMessage,updateFetchState = !readFromPurgatory)val fetchDataInfo = if (params.isFromFollower && shouldLeaderThrottle(quota, partition, params.replicaId)) {// If the partition is being throttled, simply return an empty set.new FetchDataInfo(readInfo.fetchedData.fetchOffsetMetadata, MemoryRecords.EMPTY)} else if (!params.hardMaxBytesLimit && readInfo.fetchedData.firstEntryIncomplete) {// For FetchRequest version 3, we replace incomplete message sets with an empty one as consumers can make// progress in such cases and don't need to report a `RecordTooLargeException`new FetchDataInfo(readInfo.fetchedData.fetchOffsetMetadata, MemoryRecords.EMPTY)} else {readInfo.fetchedData}//返回构建的LogReadResult对象LogReadResult(info = fetchDataInfo,divergingEpoch = readInfo.divergingEpoch.asScala,highWatermark = readInfo.highWatermark,leaderLogStartOffset = readInfo.logStartOffset,leaderLogEndOffset = readInfo.logEndOffset,followerLogStartOffset = followerLogStartOffset,fetchTimeMs = fetchTimeMs,lastStableOffset = Some(readInfo.lastStableOffset),preferredReadReplica = preferredReadReplica,exception = None)}} catch {//省略代码}}var limitBytes = params.maxBytesval result = new mutable.ArrayBuffer[(TopicIdPartition, LogReadResult)]var minOneMessage = !params.hardMaxBytesLimitreadPartitionInfo.foreach { case (tp, fetchInfo) =>val readResult = read(tp, fetchInfo, limitBytes, minOneMessage)//记录批量的大小(以字节为单位)。val recordBatchSize = readResult.info.records.sizeInBytes// Once we read from a non-empty partition, we stop ignoring request and partition level size limits//如果 recordBatchSize 大于 0,则将 minOneMessage 设置为 false,表示从非空分区读取了消息,不再忽略请求和分区级别的大小限制。if (recordBatchSize > 0)minOneMessage = falselimitBytes = math.max(0, limitBytes - recordBatchSize)//将 (tp -> readResult) 添加到 result 中result += (tp -> readResult)}result}
val readResult = read(tp, fetchInfo, limitBytes, minOneMessage)遍历主题分区分别执行read内部函数执行查询操作
方法内部通过partition.fetchRecords查询数据
1、会选择合适的副本读取本地日志数据(2.4版本后支持主题分区多副本下的读写分离)
在上面readFromLocalLog方法中,read内部方法
val preferredReadReplica = params.clientMetadata.asScala.flatMap(metadata => findPreferredReadReplica(partition, metadata, params.replicaId, fetchInfo.fetchOffset, fetchTimeMs))
def findPreferredReadReplica(partition: Partition,clientMetadata: ClientMetadata,replicaId: Int,fetchOffset: Long,currentTimeMs: Long): Option[Int] = {//partition.leaderIdIfLocal返回一个Option[Int]类型的值,表示分区的领导者副本的ID。// 如果本地是领导者副本,则返回该副本的ID,否则返回None。partition.leaderIdIfLocal.flatMap { leaderReplicaId =>// Don't look up preferred for follower fetches via normal replication//如果存在领导者副本ID(leaderReplicaId),则执行flatMap中的代码块;否则直接返回None。if (FetchRequest.isValidBrokerId(replicaId))Noneelse {replicaSelectorOpt.flatMap { replicaSelector =>//通过metadataCache.getPartitionReplicaEndpoints方法获取分区副本的端点信息val replicaEndpoints = metadataCache.getPartitionReplicaEndpoints(partition.topicPartition,new ListenerName(clientMetadata.listenerName))//创建一个可变的mutable.Set[ReplicaView]类型的集合replicaInfoSet,用于存储符合条件的副本信息。val replicaInfoSet = mutable.Set[ReplicaView]()//遍历分区的远程副本集合(partition.remoteReplicas),对每个副本进行以下操作://获取副本的状态快照(replica.stateSnapshot)。//如果副本的brokerId存在于ISR中,并且副本的日志范围包含了指定的fetchOffset,则将副本信息添加到replicaInfoSet中。partition.remoteReplicas.foreach { replica =>val replicaState = replica.stateSnapshotif (partition.inSyncReplicaIds.contains(replica.brokerId) &&replicaState.logEndOffset >= fetchOffset &&replicaState.logStartOffset <= fetchOffset) {replicaInfoSet.add(new DefaultReplicaView(replicaEndpoints.getOrElse(replica.brokerId, Node.noNode()),replicaState.logEndOffset,currentTimeMs - replicaState.lastCaughtUpTimeMs))}}//创建一个DefaultReplicaView对象,表示领导者副本的信息,并将其添加到replicaInfoSet中。val leaderReplica = new DefaultReplicaView(replicaEndpoints.getOrElse(leaderReplicaId, Node.noNode()),partition.localLogOrException.logEndOffset,0L)replicaInfoSet.add(leaderReplica)//创建一个DefaultPartitionView对象,表示分区的信息,其中包含了副本信息集合和领导者副本信息。val partitionInfo = new DefaultPartitionView(replicaInfoSet.asJava, leaderReplica)//调用replicaSelector.select方法,根据特定的策略选择合适的副本。然后通过collect方法将选择的副本转换为副本的ID集合。replicaSelector.select(partition.topicPartition, clientMetadata, partitionInfo).asScala.collect {// Even though the replica selector can return the leader, we don't want to send it out with the// FetchResponse, so we exclude it here//从副本的ID集合中排除领导者副本,并返回剩余副本的ID集合。case selected if !selected.endpoint.isEmpty && selected != leaderReplica => selected.endpoint.id}}}}}
其中 replicaSelector.select(partition.topicPartition, clientMetadata, partitionInfo).asScala.collect选合适副本默认首先Leader副本,但是2.4版本后支持主题分区非Leader副本中读取数据,即Follower副本读取数据
在代码上:
- 通过
case selected if !selected.endpoint.isEmpty && selected != leaderReplica => selected.endpoint.id判断设置,
在配置上:
- 在
broker端,需要配置参数replica.selector.class,其默认配置为LeaderSelector,意思是:消费者从首领副本获取消息,改为RackAwareReplicaSelector,即消费者按照指定的rack id上的副本进行消费。还需要配置broker.rack参数,用来指定broker在哪个机房。 - 在
consumer端,需要配置参数client.rack,且这个参数和broker端的哪个broker.rack匹配上,就会从哪个broker上去获取消息数据。
读写分离在2.4之前为什么之前不支持,后面支持了呢?
之前不支持的原因:其实对于kakfa而言,主题分区的水平扩展完全可以解决消息的处理量,增加broker也可以降低系统负载,所以没有必要费力不讨好增加一个读写分离。
现在支持的原因:有一种场景不是很适合,跨机房或者说跨数据中心的场景,当其中一个数据中心需要向另一个数据中心同步数据的时候,如果只能从首领副本进行数据读取的话,需要跨机房来完成,而这些流量带宽又比较昂贵,而利用本地跟随者副本进行消息读取就成了比较明智的选择。
所以kafka推出这一个功能,目的并不是降低broker的系统负载,分摊消息处理量,而是为了节约流量资源。
三、会判断当前请求是主题分区Follower发送的拉取数据请求还是消费者客户端拉取数据请求
关于Follower发请求可以看一下kafka 3.5 主题分区的Follower创建Fetcher线程从Leader拉取数据源码
def fetchRecords(fetchParams: FetchParams,fetchPartitionData: FetchRequest.PartitionData,fetchTimeMs: Long,maxBytes: Int,minOneMessage: Boolean,updateFetchState: Boolean): LogReadInfo = {def readFromLocalLog(log: UnifiedLog): LogReadInfo = {readRecords(log,fetchPartitionData.lastFetchedEpoch,fetchPartitionData.fetchOffset,fetchPartitionData.currentLeaderEpoch,maxBytes,fetchParams.isolation,minOneMessage)}//判断获取数据的请求是否来自Followerif (fetchParams.isFromFollower) {// Check that the request is from a valid replica before doing the readval (replica, logReadInfo) = inReadLock(leaderIsrUpdateLock) {val localLog = localLogWithEpochOrThrow(fetchPartitionData.currentLeaderEpoch,fetchParams.fetchOnlyLeader)val replica = followerReplicaOrThrow(fetchParams.replicaId,fetchPartitionData)val logReadInfo = readFromLocalLog(localLog)(replica, logReadInfo)}if (updateFetchState && !logReadInfo.divergingEpoch.isPresent) {updateFollowerFetchState(replica,followerFetchOffsetMetadata = logReadInfo.fetchedData.fetchOffsetMetadata,followerStartOffset = fetchPartitionData.logStartOffset,followerFetchTimeMs = fetchTimeMs,leaderEndOffset = logReadInfo.logEndOffset,fetchParams.replicaEpoch)}logReadInfo} else {//来自消费者客户端请求inReadLock(`leaderIsrUpdateLock`) {val localLog = localLogWithEpochOrThrow(fetchPartitionData.currentLeaderEpoch,fetchParams.fetchOnlyLeader)readFromLocalLog(localLog)}}}
1、拉取数据之前首先要得到leaderIsrUpdateLock的读锁
上面的方法逻辑中
//Follower的请求val (replica, logReadInfo) = inReadLock(leaderIsrUpdateLock)
//来自消费者客户端请求inReadLock(`leaderIsrUpdateLock`)
2、readFromLocalLog读取本地日志数据
def readFromLocalLog(log: UnifiedLog): LogReadInfo = {readRecords(log,fetchPartitionData.lastFetchedEpoch,fetchPartitionData.fetchOffset,fetchPartitionData.currentLeaderEpoch,maxBytes,fetchParams.isolation,minOneMessage)}
四、读取日志数据就是读取的segment文件(忽视零拷贝的加持)
1、获取当前本地日志的基础数据(高水位线,偏移量等),
private def readRecords(localLog: UnifiedLog,lastFetchedEpoch: Optional[Integer],fetchOffset: Long,currentLeaderEpoch: Optional[Integer],maxBytes: Int,fetchIsolation: FetchIsolation,minOneMessage: Boolean): LogReadInfo = {//localLog的高水位标记(initialHighWatermark)、、。val initialHighWatermark = localLog.highWatermark//日志起始偏移(initialLogStartOffset)val initialLogStartOffset = localLog.logStartOffset//日志结束偏移(initialLogEndOffset)val initialLogEndOffset = localLog.logEndOffset//和最后一个稳定偏移(initialLastStableOffset)val initialLastStableOffset = localLog.lastStableOffset//省略代码//代码调用localLog的read方法,读取指定偏移量处的数据val fetchedData = localLog.read(fetchOffset,maxBytes,fetchIsolation,minOneMessage)//返回一个包含读取数据的LogReadInfo对象。new LogReadInfo(fetchedData,Optional.empty(),initialHighWatermark,initialLogStartOffset,initialLogEndOffset,initialLastStableOffset)}
def read(startOffset: Long,maxLength: Int,isolation: FetchIsolation,minOneMessage: Boolean): FetchDataInfo = {checkLogStartOffset(startOffset)val maxOffsetMetadata = isolation match {case FetchIsolation.LOG_END => localLog.logEndOffsetMetadatacase FetchIsolation.HIGH_WATERMARK => fetchHighWatermarkMetadatacase FetchIsolation.TXN_COMMITTED => fetchLastStableOffsetMetadata}localLog.read(startOffset, maxLength, minOneMessage, maxOffsetMetadata, isolation == FetchIsolation.TXN_COMMITTED)}
2、遍历segment,直到从segment读取到数据
/*** @param startOffset 起始偏移量(startOffset)* @param maxLength 最大长度(maxLength)* @param minOneMessage 是否至少读取一个消息(minOneMessage)* @param maxOffsetMetadata 最大偏移元数据(maxOffsetMetadata)* @param includeAbortedTxns 是否包含已中止的事务(includeAbortedTxns)* @throws* @return 返回一个FetchDataInfo对象*/def read(startOffset: Long,maxLength: Int,minOneMessage: Boolean,maxOffsetMetadata: LogOffsetMetadata,includeAbortedTxns: Boolean): FetchDataInfo = {maybeHandleIOException(s"Exception while reading from $topicPartition in dir ${dir.getParent}") {trace(s"Reading maximum $maxLength bytes at offset $startOffset from log with " +s"total length ${segments.sizeInBytes} bytes")//获取下一个偏移元数据(endOffsetMetadata)和对应的偏移量(endOffset)val endOffsetMetadata = nextOffsetMetadataval endOffset = endOffsetMetadata.messageOffset//获得segment的集合,比如会获得某个位点后所有的segment的列表,有序var segmentOpt = segments.floorSegment(startOffset)// return error on attempt to read beyond the log end offset//如果起始偏移量大于结束偏移量或者找不到日志段,则抛出OffsetOutOfRangeException异常。if (startOffset > endOffset || segmentOpt.isEmpty)throw new OffsetOutOfRangeException(s"Received request for offset $startOffset for partition $topicPartition, " +s"but we only have log segments upto $endOffset.")//如果起始偏移量等于最大偏移量元数据的偏移量,函数返回一个空的FetchDataInfo对象if (startOffset == maxOffsetMetadata.messageOffset)emptyFetchDataInfo(maxOffsetMetadata, includeAbortedTxns)else if (startOffset > maxOffsetMetadata.messageOffset)//如果起始偏移量大于最大偏移量元数据的偏移量,函数返回一个空的FetchDataInfo对象,并将起始偏移量转换为偏移元数据emptyFetchDataInfo(convertToOffsetMetadataOrThrow(startOffset), includeAbortedTxns)else {//函数在小于目标偏移量的基本偏移量的日志段上进行读取var fetchDataInfo: FetchDataInfo = null//首先fetchDataInfo不为null,和大于start位点的segment要存在while (fetchDataInfo == null && segmentOpt.isDefined) {val segment = segmentOpt.getval baseOffset = segment.baseOffsetval maxPosition =// Use the max offset position if it is on this segment; otherwise, the segment size is the limit.//如果它在此段上,请使用最大偏移位置;否则,段大小是限制。if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) maxOffsetMetadata.relativePositionInSegmentelse segment.sizefetchDataInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)if (fetchDataInfo != null) {//则根据条件判断,如果includeAbortedTxns为真,则调用addAbortedTransactions方法添加中断的事务到fetchDataInfo中。if (includeAbortedTxns)fetchDataInfo = addAbortedTransactions(startOffset, segment, fetchDataInfo)}//如果fetchDataInfo为null,则将segmentOpt设置为segments中大于baseOffset的下一个段。else segmentOpt = segments.higherSegment(baseOffset)}//成功读取到消息,函数返回FetchDataInfo对象if (fetchDataInfo != null) fetchDataInfoelse {//如果已经超过了最后一个日志段的末尾且没有读取到任何数据,则返回一个空的FetchDataInfo对象,其中包含下一个偏移元数据和空的内存记录(MemoryRecords.EMPTY)new FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY)}}}}
首先获得segment列表var segmentOpt = segments.floorSegment(startOffset),
通过 fetchDataInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage) 从segment获取数据
五、创建文件日志流对象FileRecords
def read(startOffset: Long,maxSize: Int,maxPosition: Long = size,minOneMessage: Boolean = false): FetchDataInfo = {if (maxSize < 0)throw new IllegalArgumentException(s"Invalid max size $maxSize for log read from segment $log")val startOffsetAndSize = translateOffset(startOffset)// if the start position is already off the end of the log, return null//则表示起始位置已经超出了日志的末尾,则返回 nullif (startOffsetAndSize == null)return null//起始偏移量、基准偏移量和起始位置创建一个LogOffsetMetadata对象val startPosition = startOffsetAndSize.positionval offsetMetadata = new LogOffsetMetadata(startOffset, this.baseOffset, startPosition)val adjustedMaxSize =if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)else maxSize// return a log segment but with zero size in the case belowif (adjustedMaxSize == 0)return new FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)// calculate the length of the message set to read based on whether or not they gave us a maxOffset//根据给定的maxOffset计算要读取的消息集的长度,将其限制为maxPosition和起始位置之间的较小值,并将结果赋给fetchSize变量。val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)//创建一个FetchDataInfo对象,其中包含偏移量元数据、从起始位置开始的指定大小的日志切片(log slice)以及其他相关信息//其中log.slice(startPosition, fetchSize)是日志数据new FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize),adjustedMaxSize < startOffsetAndSize.size, Optional.empty())}
log.slice 获取文件数据
public FileRecords slice(int position, int size) throws IOException {int availableBytes = availableBytes(position, size);int startPosition = this.start + position;return new FileRecords(file, channel, startPosition, startPosition + availableBytes, true);}
这里生成一个新的文件数据对象,下面就是FileRecords的构造方法
FileRecords(File file,FileChannel channel,int start,int end,boolean isSlice) throws IOException {this.file = file;this.channel = channel;this.start = start;this.end = end;this.isSlice = isSlice;this.size = new AtomicInteger();//表示这只是一个切片视图,不需要检查文件大小,直接将size设置为end - start。if (isSlice) {// don't check the file size if this is just a slice viewsize.set(end - start);} else {//如果isSlice为false,表示这不是一个切片,需要检查文件的大小。如果文件大小超过了Integer.MAX_VALUE,将抛出KafkaException异常。if (channel.size() > Integer.MAX_VALUE)throw new KafkaException("The size of segment " + file + " (" + channel.size() +") is larger than the maximum allowed segment size of " + Integer.MAX_VALUE);//否则,将文件大小和end之间的较小值设置为limit,并将size设置为limit - start。然后,将文件通道的位置设置为limit,即文件末尾的位置。int limit = Math.min((int) channel.size(), end);size.set(limit - start);// if this is not a slice, update the file pointer to the end of the file// set the file position to the last byte in the filechannel.position(limit);}batches = batchesFrom(start);}
1、根据位点创建文件流FileLogInputStream
/*** Get an iterator over the record batches in the file, starting at a specific position. This is similar to* {@link #batches()} except that callers specify a particular position to start reading the batches from. This* method must be used with caution: the start position passed in must be a known start of a batch.* @param start The position to start record iteration from; must be a known position for start of a batch* @return An iterator over batches starting from {@code start}*///它的作用是从FileRecords直接返回一个batch的iterator
public Iterable<FileChannelRecordBatch> batchesFrom(final int start) {return () -> batchIterator(start);}private AbstractIterator<FileChannelRecordBatch> batchIterator(int start) {final int end;if (isSlice)end = this.end;elseend = this.sizeInBytes();//创建一个FileLogInputStream对象inputStream,并传入this、start和end作为参数。FileLogInputStream inputStream = new FileLogInputStream(this, start, end);//创建一个RecordBatchIterator对象,并将inputStream作为参数传入。//将创建的RecordBatchIterator对象作为返回值返回。return new RecordBatchIterator<>(inputStream);}
}
FileLogInputStream类实现了nextBatch()接口,这个接口是从基础输入流中获取下一个记录批次。
public class FileLogInputStream implements LogInputStream<FileLogInputStream.FileChannelRecordBatch> {/*** Create a new log input stream over the FileChannel* @param records Underlying FileRecords instance* @param start Position in the file channel to start from* @param end Position in the file channel not to read past*/FileLogInputStream(FileRecords records,int start,int end) {this.fileRecords = records;this.position = start;this.end = end;}@Overridepublic FileChannelRecordBatch nextBatch() throws IOException {//首先获取文件的通道(channel)FileChannel channel = fileRecords.channel();//检查是否达到了文件末尾或者下一个记录批次的起始位置。如果达到了文件末尾,则返回空(null)。if (position >= end - HEADER_SIZE_UP_TO_MAGIC)return null;//读取文件通道中的记录头部数据,并将其存储在一个缓冲区(logHeaderBuffer)logHeaderBuffer.rewind();Utils.readFullyOrFail(channel, logHeaderBuffer, position, "log header");//记录头部数据中解析出偏移量(offset)和记录大小(size)logHeaderBuffer.rewind();long offset = logHeaderBuffer.getLong(OFFSET_OFFSET);int size = logHeaderBuffer.getInt(SIZE_OFFSET);// V0 has the smallest overhead, stricter checking is done laterif (size < LegacyRecord.RECORD_OVERHEAD_V0)throw new CorruptRecordException(String.format("Found record size %d smaller than minimum record " +"overhead (%d) in file %s.", size, LegacyRecord.RECORD_OVERHEAD_V0, fileRecords.file()));//检查是否已经超过了文件末尾减去记录开销和记录大小的位置。如果超过了,则返回空(null)if (position > end - LOG_OVERHEAD - size)return null;//代码会根据记录头部的(magic)byte magic = logHeaderBuffer.get(MAGIC_OFFSET);//创建一个记录批次对象(batch)final FileChannelRecordBatch batch;if (magic < RecordBatch.MAGIC_V个LUE_V2)//则创建一个旧版本的记录批次对象batch = new LegacyFileChannelRecordBatch(offset, magic, fileRecords, position, size);else//否则创建一个默认版本的记录批次对象batch = new DefaultFileChannelRecordBatch(offset, magic, fileRecords, position, size);//代码会更新当前位置(position),以便下次读取下一个记录批次。position += batch.sizeInBytes();return batch;}
}
2、把文件流构建成数据批量迭代器对象RecordBatchIterator
上文中的batchIterator方法会把文件流构造RecordBatchIterator对象
class RecordBatchIterator<T extends RecordBatch> extends AbstractIterator<T> {private final LogInputStream<T> logInputStream;RecordBatchIterator(LogInputStream<T> logInputStream) {this.logInputStream = logInputStream;}@Overrideprotected T makeNext() {try {T batch = logInputStream.nextBatch();if (batch == null)return allDone();return batch;} catch (EOFException e) {throw new CorruptRecordException("Unexpected EOF while attempting to read the next batch", e);} catch (IOException e) {throw new KafkaException(e);}}
}
AbstractIterator抽象类
public abstract class AbstractIterator<T> implements Iterator<T> {private enum State {READY, NOT_READY, DONE, FAILED}private State state = State.NOT_READY;private T next;@Overridepublic boolean hasNext() {switch (state) {case FAILED:throw new IllegalStateException("Iterator is in failed state");case DONE:return false;case READY:return true;default:return maybeComputeNext();}}@Overridepublic T next() {if (!hasNext())throw new NoSuchElementException();state = State.NOT_READY;if (next == null)throw new IllegalStateException("Expected item but none found.");return next;}@Overridepublic void remove() {throw new UnsupportedOperationException("Removal not supported");}public T peek() {if (!hasNext())throw new NoSuchElementException();return next;}protected T allDone() {state = State.DONE;return null;}protected abstract T makeNext();private Boolean maybeComputeNext() {state = State.FAILED;next = makeNext();if (state == State.DONE) {return false;} else {state = State.READY;return true;}}}
调用RecordBatchIterator类的makeNext()方法,之后调用第五章节的FileLogInputStream中的nextBatch()
DefaultFileChannelRecordBatch这个是默认的
static class DefaultFileChannelRecordBatch extends FileLogInputStream.FileChannelRecordBatch {DefaultFileChannelRecordBatch(long offset,byte magic,FileRecords fileRecords,int position,int batchSize) {super(offset, magic, fileRecords, position, batchSize);}@Overrideprotected RecordBatch toMemoryRecordBatch(ByteBuffer buffer) {return new DefaultRecordBatch(buffer);}@Overridepublic long baseOffset() {return offset;}//省略代码}
3、DefaultRecordBatch实现iterator方法,在内存中创建数据
之后看一下哪里调用的
DefaultFileChannelRecordBatch中的toMemoryRecordBatch方法
DefaultRecordBatch,再通过这个batch的iterator方法获取到Iterator<Record>的
public class DefaultRecordBatch extends AbstractRecordBatch implements MutableRecordBatch {@Override public Iterator<Record> iterator() {if (count() == 0)return Collections.emptyIterator();if (!isCompressed())return uncompressedIterator();// for a normal iterator, we cannot ensure that the underlying compression stream is closed,// so we decompress the full record set here. Use cases which call for a lower memory footprint// can use `streamingIterator` at the cost of additional complexitytry (CloseableIterator<Record> iterator = compressedIterator(BufferSupplier.NO_CACHING, false)) {List<Record> records = new ArrayList<>(count());while (iterator.hasNext())records.add(iterator.next());return records.iterator();}}
}
DefaultFileChannelRecordBatch是FileChannelRecordBatch的一个子类。FileChannelRecordBatch表示日志是通过FileChannel的形式来保存的。在遍历日志的时候不需要将日志全部读到内存中,而是在需要的时候再读取。我们直接看最重要的iterator方法
public abstract static class FileChannelRecordBatch extends AbstractRecordBatch {protected final long offset;protected final byte magic;protected final FileRecords fileRecords;protected final int position;protected final int batchSize;private RecordBatch fullBatch;private RecordBatch batchHeader;FileChannelRecordBatch(long offset,byte magic,FileRecords fileRecords,int position,int batchSize) {this.offset = offset;this.magic = magic;this.fileRecords = fileRecords;this.position = position;this.batchSize = batchSize;}//省略代码@Overridepublic Iterator<Record> iterator() {return loadFullBatch().iterator();}//省略代码}
protected RecordBatch loadFullBatch() {if (fullBatch == null) {batchHeader = null;fullBatch = loadBatchWithSize(sizeInBytes(), "full record batch");}return fullBatch;}
最后会调用DefaultFileChannelRecordBatch类型的toMemoryRecordBatch方法在内存中生成批量数据
private RecordBatch loadBatchWithSize(int size, String description) {FileChannel channel = fileRecords.channel();try {ByteBuffer buffer = ByteBuffer.allocate(size);Utils.readFullyOrFail(channel, buffer, position, description);buffer.rewind();//在内存中生成数据return toMemoryRecordBatch(buffer);} catch (IOException e) {throw new KafkaException("Failed to load record batch at position " + position + " from " + fileRecords, e);}}
相关文章:

kakfa 3.5 kafka服务端处理消费者客户端拉取数据请求源码
一、服务端接收消费者拉取数据的方法二、遍历请求中需要拉取数据的主题分区集合,分别执行查询数据操作,1、会选择合适的副本读取本地日志数据(2.4版本后支持主题分区多副本下的读写分离) 三、会判断当前请求是主题分区Follower发送的拉取数据请求还是消费…...

【Linux】进程概念I --操作系统概念与冯诺依曼体系结构
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法…感兴趣就关注我吧!你定不会失望。 本篇导航 1. 冯诺依曼体系结构为什么这样设计? 2. 操作系统概念为什么我们需要操作系统呢?操作系统怎么进行管理? 计算机是由两部分组…...
BRAM/URAM资源介绍
BRAM/URAM资源简介 Bram和URAM都是FPGA(现场可编程门阵列)中的RAM资源。 Bram是Block RAM的缩写,是Xilinx FPGA中常见的RAM资源之一,也是最常用的资源之一。它是一种单独的RAM模块,通常用于存储大量的数据࿰…...

分享一个基于python的个性推荐餐厅系统源码 餐厅管理系统代码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、Node.js、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! …...

Mysql5.7开启SSL认证且支持Springboot客户端验证
Mysql5.7开启SSL认证 一、查看服务端mysql环境 1.查看是否开启了ssl,"have_ssl" 为YES的时候,数据库是开启加密连接方式的。 show global variables like %ssl%;2.查看数据库版本 select version();3.查看数据库端口 show variables like port;4.查看数据库存放…...

微信小程序的页面滚动事件监听
微信小程序中可以通过 Page 的 onPageScroll 方法来监听页面滚动事件。具体步骤如下: 在页面的 onLoad 方法中注册页面滚动事件监听器: Page({onLoad: function () {wx.pageScrollTo({scrollTop: 0,duration: 0});wx.showLoading({title: 加载中,});wx…...

数据可视化:四大发明的现代转化引擎
在科技和工业的蓬勃发展中,中国的四大发明——造纸术、印刷术、火药和指南针,早已不再是古代创新的象征,而是催生了众多衍生行业的崭新可能性。其中,数据可视化技术正成为这些行业的一颗璀璨明珠,开启了全新的时代。 1…...

HarmonyOS实现几种常见图片点击效果
一. 样例介绍 HarmonyOS提供了常用的图片、图片帧动画播放器组件,开发者可以根据实际场景和开发需求,实现不同的界面交互效果,包括:点击阴影效果、点击切换状态、点击动画效果、点击切换动效。 相关概念 image组件:图片…...
)
3D视觉测量:计算两个平面之间的夹角(附源码)
文章目录 1. 基本内容2. 代码实现文章目录:形位公差测量关键内容:通过视觉方法实现平面之间夹角的计算1. 基本内容 要计算两个平面之间的夹角,首先需要知道这两个平面的法向量。假设有两个平面,它们的法向量分别为 N 1 和 N 2 N_1 和 N_2...
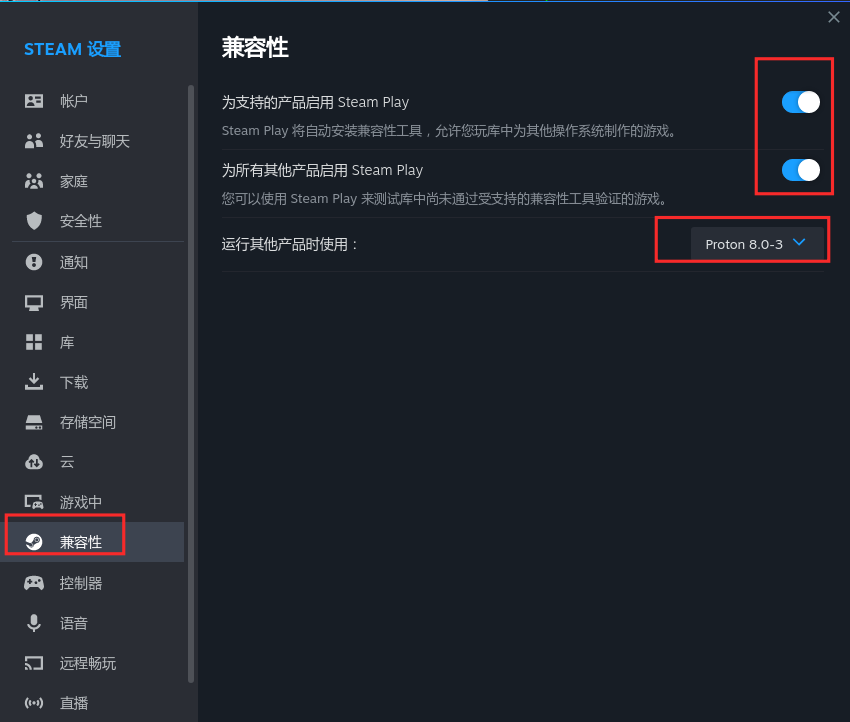
deepin V23通过flathub安装steam畅玩游戏
deepin V23缺少32位库,在星火商店安装的steam,打开报错,无法使用! 通过flathub网站安装steam,可以正常使用,详细教程如下: flathub网址:主页 | Flathub 注意:flathub下载速度慢,只…...
C语言是否快被时代所淘汰?
今日话题,C语言是否快被时代所淘汰?在移动互联网的冲击下,windows做的人越来越少,WP阵营没人做,后台简单的php,复杂的大数据处理的java,要求性能的c。主流一二线公司基本上没多少用C#的了。其实…...
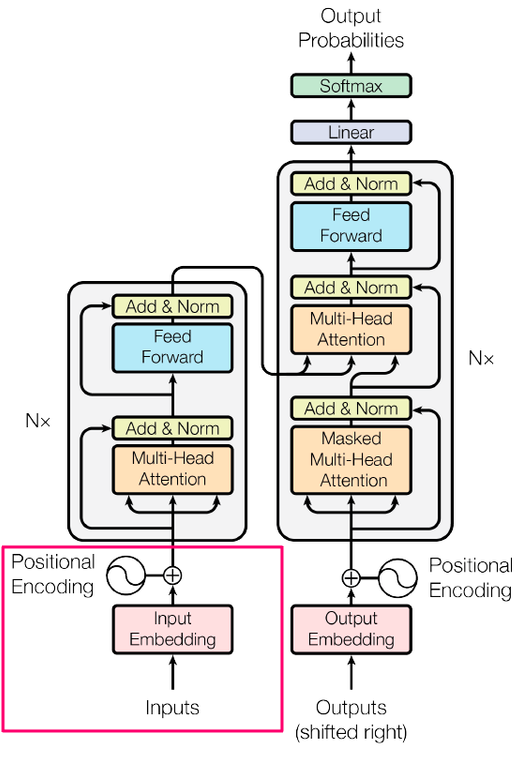
简化转换器:使用您理解的单词进行最先进的 NLP — 第 1 部分 — 输入
一、说明 变形金刚是一种深度学习架构,为人工智能的发展做出了杰出贡献。这是人工智能和整个技术领域的一个重要阶段,但也有点复杂。截至今天,变形金刚上有很多很好的资源,那么为什么要再制作一个呢?两个原因ÿ…...
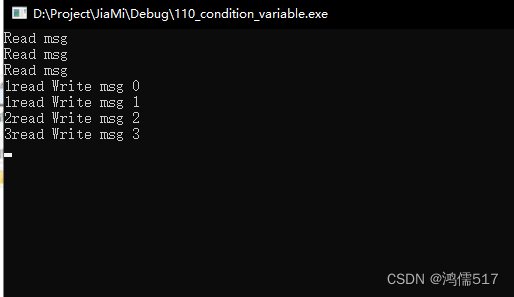
C++多线程编程(第三章 案例2,条件变量,生产者-消费者模型)
目录 1、condition_variable1.1、生产者消费者模型1.2、改变共享变量的线程步骤1.3、等待信号读取共享变量的线程步骤1.3.1、获得改变共享变量线程共同的mutex1.3.2、wait()等待信号通知1.3.2.1、无lambda表达式1.3.2.2 lambda表达式 样例代码 1、condition_variable 等待中&a…...

Go语言使用AES加密解密
Go语言提供了标准库中的crypto/aes包来支持AES加密和解密。下面是使用AES-128-CBC模式加密和解密的示例代码: package mainimport ("crypto/aes""crypto/cipher""encoding/base64""fmt" )func main() {key : []byte("…...
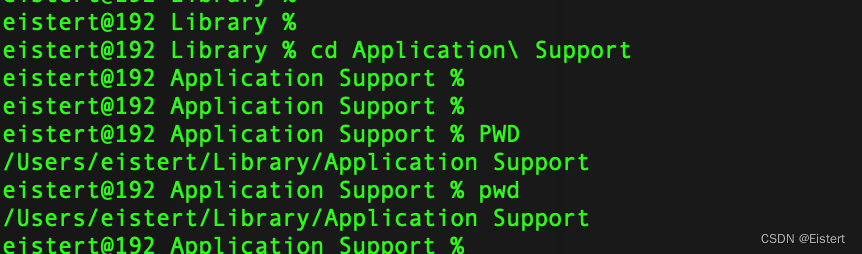
MAC ITEM 解决cd: string not in pwd的问题
今天使用cd 粘贴复制的路径的时候,报了这么一个错. cd: string not in pwd eistert192 Library % cd Application Support cd: string not in pwd: Application eistert192 Library % 让人一脸懵逼. 对比一下,发现中文路径里的空格截断了路径 导致后面的路径就没有办法被包含…...

解决跨域的几种方式
解决跨域的几种方式 JSONPCORS(跨域资源共享)代理 JSONP 利用script标签可以跨域加载资源的特性,通过动态创建一个script标签,然后将响应数据作为回调函数的参数返回,从而实现跨域请求资源。该方式只支持 GET 请求方式…...
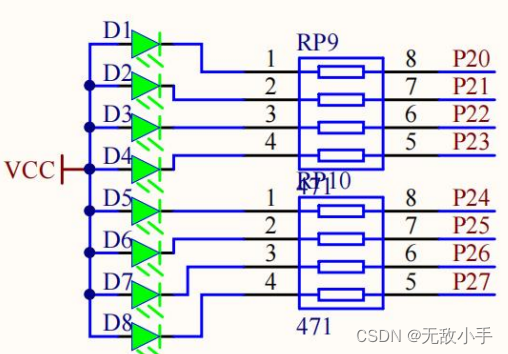
单片机-LED介绍
简介 LED 即发光二极管。它具有单向导电性,通过 5mA 左右电流即可发光 电流 越大,其亮度越强,但若电流过大,会烧毁二极管,一般我们控制在 3 mA-20mA 之间,通常我们会在 LED 管脚上串联一个电阻,…...

ERROR:GLOBAL_INITIALISERS: do not initialise globals to 0
错误信息 ERROR:GLOBAL_INITIALISERS: do not initialise globals to 0 表示全局变量的初始化值不应该为0。这个错误通常出现在一些编程语言(如C、C)的编译过程中,以帮助程序员避免一些潜在的问题。 在一些编程语言中,全局变量的…...
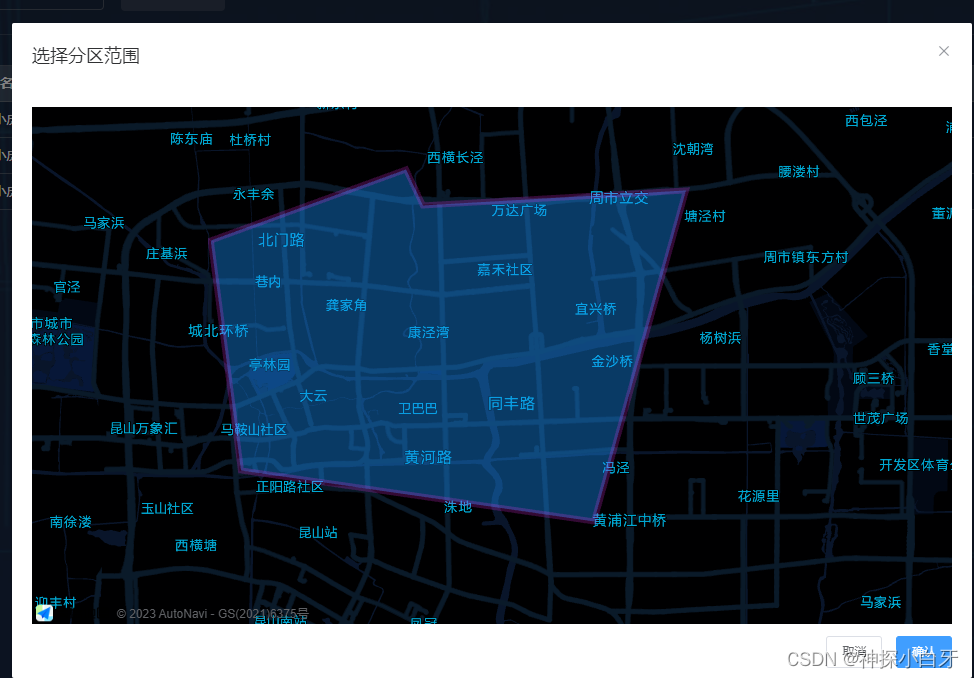
高德地图,绘制矢量图形并获取经纬度
效果如图 我用的是AMapLoader这个地图插件,会省去很多配置的步骤,非常方便 首先下载插件,然后在局部引入 import AMapLoader from "amap/amap-jsapi-loader";然后在methods里面使用 // 打开地图弹窗mapShow() {this.innerVisible true;this.$nextTick(() > {…...

【100天精通Python】Day59:Python 数据分析_Pandas高级功能-多层索引创建访问切片和重塑操作,pandas自定义函数和映射功能
目录 1 多层索引(MultiIndex) 1.1 创建多层索引 1.1.1 从元组创建多层索引 1.1.2 使用 set_index() 方法创建多层索引 1.2 访问多层索引数据 1.3 多层索引的层次切片 1.4 多层索引的重塑 2 自定义函数和映射 2.1 使用 apply() 方法进行自定义函…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...