Hive基操
数据交换
//hive导出到hdfs /outstudentpt 目录
0: jdbc:hive2://guo146:10000> export table student_pt to '/outstudentpt';//从hdfs导入到hive
0: jdbc:hive2://guo146:10000> import table studentpt from '/outstudentpt';
数据排序
Order by会对所给的全部数据进行全局排序,只启动一个reduce来处理。
Sort by是局部排序,它可以根据数据量的大小启动一到多个reducer来工作,并且在每个reduce中单独排序。
Distribute by 类似于mr中的partition,采用hash算法,在map端将查询结果中hash值相同的结果分发到对应的reduce中,结合sort by使用
Cluster by 可以看作是distribute by 和sort by的结合,当两者后面所跟的字段列名相同时,效果就等同于使用cluster by,但是cluster by最终的结果只能是降序,无法指定升序和降序
分桶及抽样查询
分桶的好处
1、基于分桶字段查询时,减少全表扫描
2、join时可以提高MR程序效率,减少笛卡尔积数量
3、分桶表数据进行高效抽样// 任务数量两个,开启分桶设置
set map.reduce.tasks=2; --根据任务分配
set hive.enforce.bucketing=true;
//分桶表
首先创建一个内部表,分桶表需要通过insert into 插入数据
create table employee_id_buckets
(name string,employee_id int,work_place array<string>,gender_age struct<gender:string,age:string>,skills_score map<string,int>,depart_title map<string,array<string>>
)clustered by (employee_id) into 2 buckets -- 分成两个桶,分桶的字段一定是表中已经存在的字段row format delimited fields terminated by '|'collection items terminated by ','map keys terminated by ':';//使用insert+select 语法将数据加载到分桶表中
insert into table employee_id_buckets select * from employee_id;分桶规则:编号相同的数据会被分到同一个桶当中
Bucket number=hash_function(bucketing_colum) mod num_buckets
分桶编号 = 哈希方法(分桶字段) 取模 分桶个数
hash_function取决于分桶字段 bucketing_colum 的类型:
1、int类型 hash_function(int)==int
2、其他类型 则是从该类型派生的某个数字select * from employee_id_buckets tablesample(bucket x out of y);
y 必须是 table 总 bucket 数的倍数或者因子。hive 根据 y 的大小,决定抽样的比例。例
如,table 总共分了 4 份,当 y=2 时,抽取(4/2=)2 个 bucket 的数据,当 y=8 时,抽取(4/8=)1/2个 bucket 的数据。x 表示从哪个 bucket 开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上
y。例如,table 总 bucket 数为 4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2 个bucket 的数据,抽取第 1(x)个和第 3(x+y)个 bucket 的数据。
注意:x 的值必须小于等于 y 的值,否则
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
WordCount案例
create table if not exists word_count
(line string
);
//传参数
load data local inpath '/opt/stufile/wordcount.txt' overwrite into table word_count;with t1 as (select explode(split(line, ' ')) word from word_count)
select t1.word, count(1) num
from t1
group by t1.word
order by num desc视图
视图是一种虚拟表,只保存定义,不实际存储数据
使用视图的好处
1、将真实表中特定的列数提供给客户,保护数据隐私
2、降低查询的复杂度,优化查询语句
-- 创建视图
create view emp as select * from employee limit 2;-- 显示当前已有的视图 v2.2.0之后支持
show views;-- 查看视图定义
show create table emp;-- 删除视图
drop view emp-- 侧视图
select name,wps,gender_age.gender,gender_age.age,skill,score,depart,title
from bigdata.employee lateral view explode(work_place) work_pplace_single as wpslateral view explode(skills_score) sks as skill, scorelateral view explode(depart_title) dt as depart, title;相关文章:

Hive基操
数据交换 //hive导出到hdfs /outstudentpt 目录 0: jdbc:hive2://guo146:10000> export table student_pt to /outstudentpt; //从hdfs导入到hive 0: jdbc:hive2://guo146:10000> import table studentpt from /outstudentpt; 数据排序 Order by会对所给的全部数据进行…...

CSS(配合html的网页编程)
续上一篇博客,CSS是前端三大将中其中的一位,主要负责前端的皮,也就是负责html的装饰.一、基本语法规则也就是:选择器若干属性声明(选中一个元素然然后进行属性声明)CSS代码是放在style标签中,它可以放在head中也可以放在body中 ,可以放到代码的任意位置.color也就是设置想要输入…...
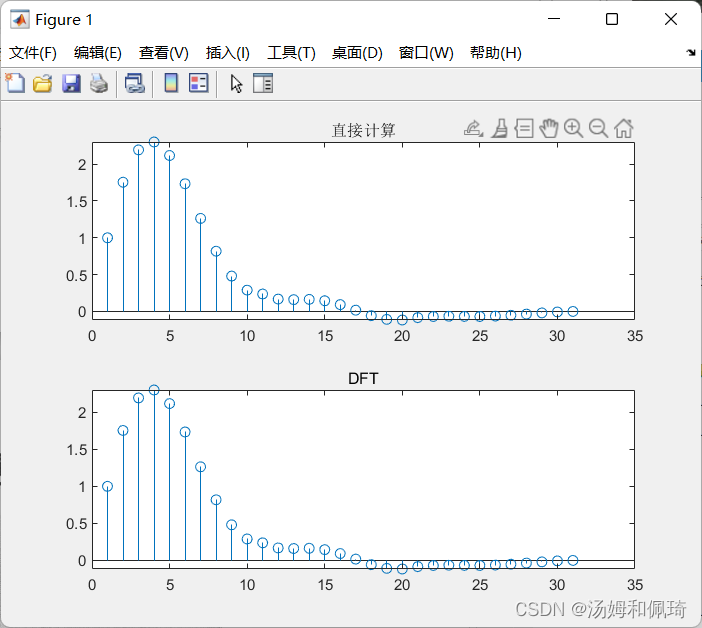
MATLAB/Simulink 通信原理及仿真学习(三)
文章目录MATLAB/Simulink 通信原理及仿真学习(三)3. 通信信号与系统分析3.1 离散信号和系统3.1.1 离散信号3.1.2 离散时间信号3.1.3 信号的能量和功率3.2 傅里叶(Fourier)分析3.2.1 连续时间信号的Fourier变换3.2.2 离散时间信号的…...
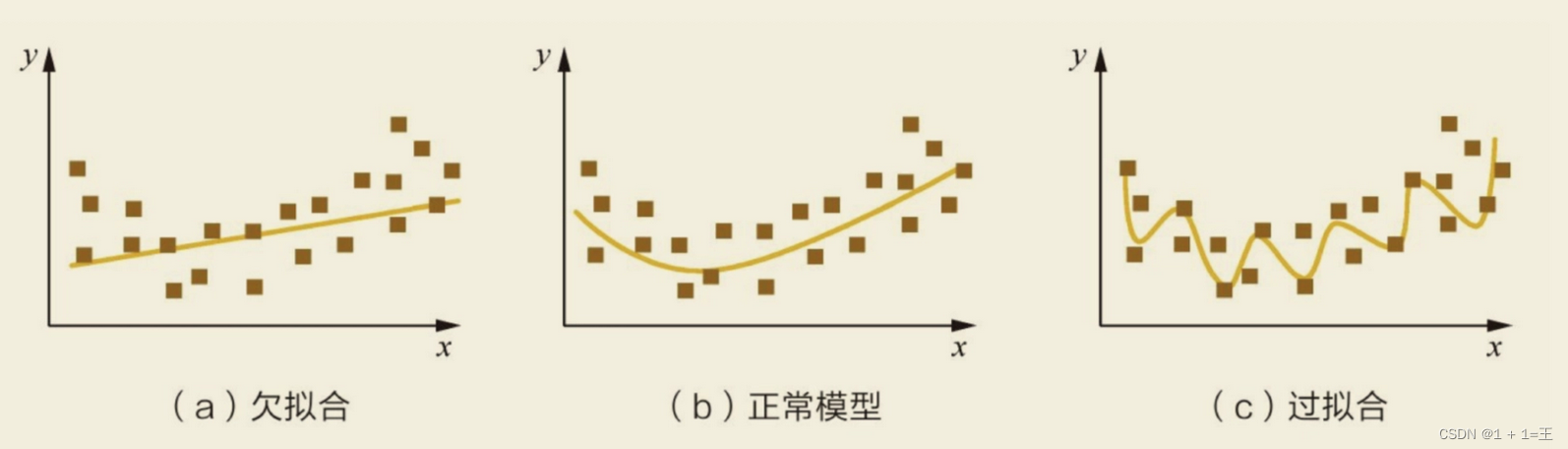
如何解决过拟合与欠拟合,及理解k折交叉验证
模型欠拟合:在训练集以及测试集上同时具有较⾼的误差,此时模型的偏差较⼤; 模型过拟合:在训练集上具有较低的误差,在测试集上具有较⾼的误差,此时模型的⽅差较⼤。 如何解决⽋拟合: 添加其他特…...
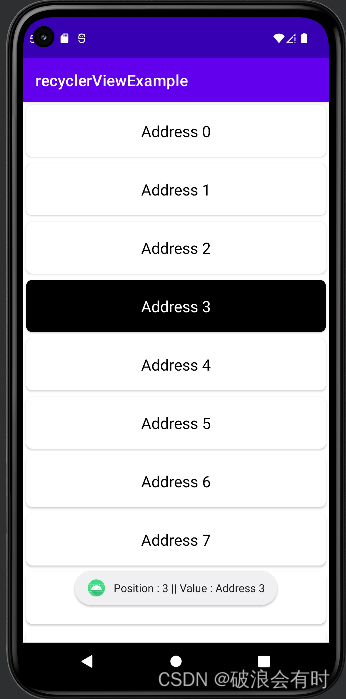
Kotlin 34. recyclerView 案例:显示列表
Kotlin 案例1. recyclerView:显示列表 这里,我们将通过几个案例来介绍如何使用recyclerView。RecyclerView 是 ListView 的高级版本。 当我们有很长的项目列表需要显示的时候,我们就可以使用 RecyclerView。 它具有重用其视图的能力。 在 Re…...

JAVA练习58-汉明距离、颠倒二进制位
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目1-汉明距离 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 二、题目2-颠倒二进制位 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示…...

优炫数据库百城巡展,成都首站圆满举行
2月17日,由四川省大数据发展研究会、北京优炫软件股份有限公司联合举办的“首届四川省推进信息技术应用创新产业服务研讨会暨优炫数据库百城巡展成都首站隆重举行。此次活动是优炫数据库百城巡展的起点站,更是国产数据库市场美好乐章的一次强力鸣奏。 来…...

【20230210】二叉树小结
二叉树的种类二叉树的主要形式:满二叉树和完全二叉树。满二叉树深度为k,有2^k-1个节点的二叉树完全二叉树除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。二叉搜索树…...
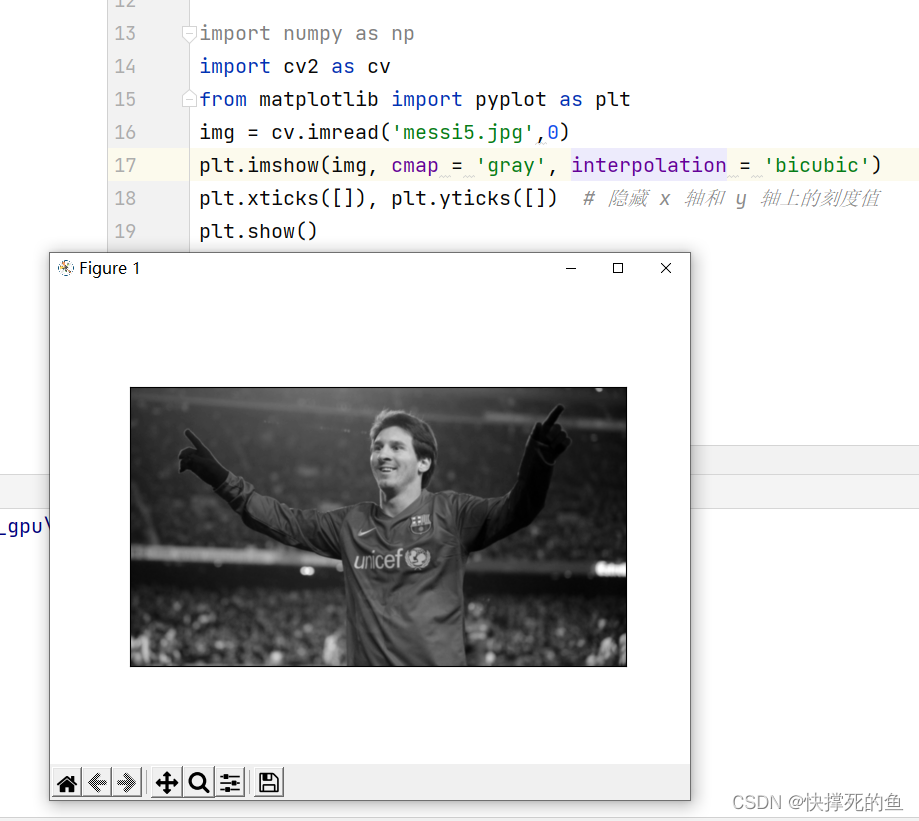
openCV—图像入门(python)
目录 目标 使用OpenCV 显示图像 写入图像 总结使用 使用Matplotlib 注:图片后续补充 目标 在这里,你将了解如何使用Python编程语言中的OpenCV库,实现读取、显示和保存图像的功能。具体来说,你将学习以下函数的用法…...
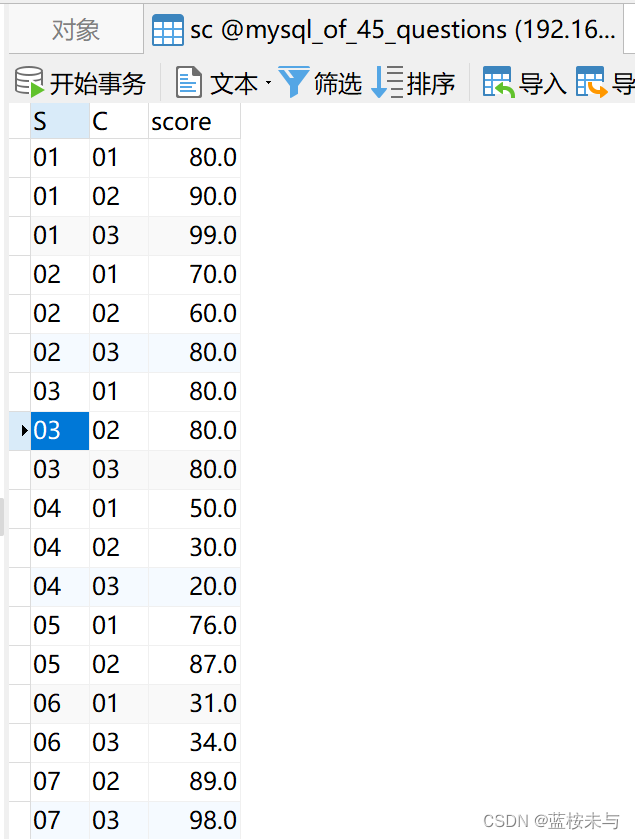
关于一个Java程序员马上要笔试了,临时抱佛脚,一晚上恶补45道简单SQL题,希望笔试能通过
MySQL随手练 / DQL篇 MySQL随手练——DQL篇 题目网盘下载:https://pan.baidu.com/s/1Ky-RJRNyfvlEJldNL_yQEQ?pwdlana 初始数据 表 course 表 student 表 teacher 表 sc 答案 :) —> :( —> :) 1. 查询 "01"课程比"02"课程成绩高的学生…...

PyTorch深度学习实战
本专栏分为两大部分,专栏内容如下: 第1部分 探讨PyTorch与其他深度学习框架的区别。 如何在PyTorch Hub中下载和运行模型。 PyTorch的基本构建组件——张量 展示不同类型的数据如何被表示为张量,以及深度学习模型期望构造什么样的张量。 梯度…...
leetcode 1011. Capacity To Ship Packages Within D Days(D天内运送包裹的容量)
数组的每个元素代表每个货物的重量,注意这个货物是有先后顺序的,先来的要先运输,所以不能改变这些元素的顺序。 要days天内把这些货物全部运输出去,问所需船的最小载重量。 思路: 数组内数字顺序不能变,就…...

支持向量机SVM详细原理,Libsvm工具箱详解,svm参数说明,svm应用实例,神经网络1000案例之15
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的股票价格预测 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型&a…...
Mac 上搭建 iOS WebDriverAgent 环境
文章目录Mac环境搭建配置 Xcode 生成 WDA常见问题brew 安装失败Mac环境搭建 macOS 系统电脑:12.6.2 Xcode:14.0.1(xcodebuild -version) appium Desktop:1.21.0 (下载链接) Appium Desktop 1.22.0 ,从该版…...

python学习笔记之例题篇NO.3
获得用户输入的一个整数N,输出N中所出现不同数字的和。 s list(set(list(input())))# ① r…...
【Kubernetes】第七篇 - Service 服务介绍和使用
一,前言 上一篇,通过配置一个 Deployment 对象,在内部创建副本集对象,副本集帮我们创建了 3 个 pod 副本 由于 pod 存在 IP 漂移现象,pod 的创建和重启会导致 IP 变化; 本篇,介绍 Service 服…...
Linux 终端复用器Tmux
目录 Tmux讲解 配置tmux 配置tmux会话 配置tmux窗口(在会话界面进行配置) 配置tmux面板 配置窗口共享同步 Tmux讲解 RHEL5/6/7使用的是screen软件包 RHEL8使用的是tumx软件包(功能更强大,更易用) tmux的三个基本…...

Hadoop集群模式安装(Cluster mode)
1、Hadoop源码编译 安装包、源码包下载地址 Index of /dist/hadoop/common/hadoop-3.3.0为什么要重新编译Hadoop源码? 匹配不同操作系统本地库环境,Hadoop某些操作比如压缩、IO需要调用系统本地库(*.so|*.dll) 修改源码、重构源码 如何…...
PTA L1-054 福到了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “福”字倒着贴,寓意“福到”。不论到底算不算民俗,本题且请你编写程序,把各种汉字倒过来输出。这里要处理的每…...

python -- 魔术方法
魔术方法就算定义在类里面的一些特殊的方法 特点:这些func的名字前面都有两个下划线 __new__方法 相当于一个类的创建一个对象的过程 __init__方法 相当于为这个类创建好的对象分配地址初始化的过程 __del__方法 一个类声明这个方法后,创建的对象如果…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...