安装torch113、cuda116并运行demo【Transformer】
文章目录
- 01. 导读
- 02. 显卡驱动版本
- 03. 创建环境、下载安装必要包
- 04. 运行参考代码:
01. 导读
安装torch113、cuda116并运行demo【Transformer】
02. 显卡驱动版本
C:\Users\Administrator>nvidia-smi -l 10
Wed Sep 13 23:35:08 2023
±----------------------------------------------------------------------------+
| NVIDIA-SMI 512.89 Driver Version: 512.89 CUDA Version: 11.6 |
|-------------------------------±---------------------±---------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=++==============|
| 0 NVIDIA GeForce … WDDM | 00000000:01:00.0 On | N/A |
| N/A 73C P0 47W / N/A | 2210MiB / 4096MiB | 99% Default |
| | | N/A |
±------------------------------±---------------------±---------------------+
03. 创建环境、下载安装必要包
创建一个gpy38torch 的虚拟环境,并配置到改路径地址D:/AworkStation/Anaconda3/envs
conda create -p D:/AworkStation/Anaconda3/envs/gpy38torch python=3.8 【不知为何,管理员的windows身份了,仍然需要使用管理员身份运行】
pip install pandas transformers scipy ipykernel
pip install torch==1.13.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
python -m ipykernel install --user --name gpy38torch
04. 运行参考代码:
# -*- coding: utf-8 -*-'''
@Author : Corley Tang
@contact : cutercorleytd@gmail.com
@Github : https://github.com/corleytd
@Time : 2023-08-14 22:22
@Project : Hands-on NLP with HuggingFace Transformers-sentiment_analysis_with_rbt3
使用3层RoBERTa模型进行评论情感分析
'''# 导入所需的库
import pandas as pd
import torch
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
from transformers import set_seed# 超参数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
seed = 20230814
batch_size = 8
max_length = 256
lr = 2e-5
num_epochs = 2
log_interval = 100
train_ratio = 0.8
model_path = 'hfl/rbt3'
model_path = r'D:\Auser\YZH\Pytorch深度学习入门与实战\Models\rbt3'# 设置随机种子、保证结果可复现
set_seed(seed)
# 1.构造数据
## (1)查看数据# 读取酒店评论数据:https://github.com/SophonPlus/ChineseNlpCorpus
path = 'ChnSentiCorp_htl_all.csv' # 在我当前路径
data = pd.read_csv(path)
data.head()
# 查看缺失值
data.info() # review有1条缺失值
# 删除缺失值
data.dropna(inplace=True)
data.info() # 不存在缺失值
## (2)构造数据集
# 定义数据集类
class ReviewDataset(Dataset):def __init__(self, path):super().__init__()self.data = pd.read_csv(path)self.data.dropna(inplace=True)def __len__(self):return self.data.shape[0]def __getitem__(self, index):item = self.data.iloc[index]return item['review'], item['label']
# 实例化
dataset = ReviewDataset(path)for i in range(5):print(dataset[i])
# 划分数据集
sample_length = len(dataset)
train_length = int(train_ratio * sample_length)
train_set, valid_set = random_split(dataset, lengths=[train_length,sample_length - train_length]) # PyTorch从1.13及以后的版本中也支持lengths使用浮点数比例
len(train_set), len(valid_set)
# 查看训练集
for i in range(5):print(train_set[i])
# (3)创建DataLoader
# 创建Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)def text_collate(batch):'''将单个样本数据组成的列表转换成一个批次的数据,通常会对数据进行一些处理:param batch: 一个批次数据的列表,一个元素为一条样本(包含输入和标签等):return: 一个批次的数据,可以是一个列表、元组或者字典'''texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])# 先将数据整理成一批、再进行分词,效率更高inputs = tokenizer(texts, max_length=max_length, padding='max_length', truncation=True, return_tensors='pt')inputs['labels'] = torch.tensor(labels)return (inputs)
# 构造DataLoader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, collate_fn=text_collate) # 自定义数据处理方式
valid_loader = DataLoader(valid_set, batch_size=batch_size * 2, collate_fn=text_collate)
# 查看验证集
next(enumerate(valid_loader))[1] # 为字典形式
# 2.搭建模型
## (1)创建模型
model = AutoModelForSequenceClassification.from_pretrained(model_path) # 选择带序列分类头的模型
model.to(device)
model
## (2)定义优化器
optimizer = optim.AdamW(model.parameters(), lr=lr)
optimizer
# 3.训练与预测
# 评估
def evaluate():total_correct = 0 # 计数model.eval()with torch.inference_mode(): # 在推断模式下优化内存使用和计算量,以提高推断性能(只允许进行前向传播操作,不支持反向传播或梯度计算)for batch in valid_loader:batch = {k: v.to(device) for k, v in batch.items()}output = model(**batch)preds = output.logits.argmax(-1)total_correct += (preds == batch['labels']).sum().item()return total_correct / len(valid_set)# 训练
def train():global_step = 0 # 计数for epoch in range(num_epochs):model.train()for batch in train_loader:batch = {k: v.to(device) for k, v in batch.items()}output = model(**batch)output.loss.backward()optimizer.step()optimizer.zero_grad()if global_step % log_interval == 0:print(f'Epoch: {epoch}, Step: {global_step:4d}, Loss: {output.loss.item():.6f}')global_step += 1acc = evaluate()print(f'Epoch: {epoch}, Acc: {acc:.2%}')
# 开始训练
train()
# 手动实现预测
review = '总体来说还是不错,不足之处可以谅解,毕竟价格放在这里,要求不能太高。'
id2label = {0: '差评', 1: '好评'}
model.eval()
with torch.inference_mode():inputs = tokenizer(review, return_tensors='pt')inputs = {k: v.to(device) for k, v in inputs.items()}logits = model(**inputs).logitspred = logits.argmax(-1).item()print(f'评论:{review}\n预测结果:{id2label.get(pred)}')
# 借助pipeline
model.config.id2label = id2label
pipe = pipeline('text-classification', model=model, tokenizer=tokenizer, device=device)
# 进行评价
pipe(review)
相关文章:
安装torch113、cuda116并运行demo【Transformer】
文章目录 01. 导读02. 显卡驱动版本03. 创建环境、下载安装必要包04. 运行参考代码: 01. 导读 安装torch113、cuda116并运行demo【Transformer】 02. 显卡驱动版本 C:\Users\Administrator>nvidia-smi -l 10 Wed Sep 13 23:35:08 2023 ----------------------…...

基于scRNA-seq的GRN分析三阴性乳腺癌的肿瘤异质性
三阴性乳腺癌即TNBC是一种肿瘤异质性高的乳腺癌亚型。最近的研究表明,TNBC患者可能包含具有不同分子亚型的细胞。此外,基于scRNA-seq数据构建的GRN已经证明了对关键调控因子研究的重要性。作者使用scRNA-seq对TNBC患者的GRN进行了全面分析。从scRNA-seq数…...

Python:二进制文件实现等间隔取相同数据量并合并
举例:每3byte为一页,每3页为一wl。将所有wl的第一页/第二页/第三页分别合并为一个文件。 data b\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x0…...

python使用openvc库进行图像数据增强
以下是使用Python和OpenCV库实现图像数据增强的简单示例代码,其中包括常用的数据增强操作: import cv2 import numpy as np import os# 水平翻转 def horizontal_flip(image):return cv2.flip(image, 1)# 垂直翻转 def vertical_flip(image):return cv2…...

如何利用Api接口获取手机当前的网络位置信息
在移动互联网时代,手机定位已经成为了一个日常化的需求,无论是导航、社交还是打车等服务都需要获取手机的位置信息。而获取手机位置信息最基础的一步就是获取手机当前的网络位置信息,本文将介绍如何利用API接口获取手机当前的网络位置信息。 …...

vue-elementPlus自动按需导入和主题定制
elementPlus自动按需导入 装包 -> 配置 1. 装包(主包和两个插件包) $ npm install element-plus --save npm install -D unplugin-vue-components unplugin-auto-import 2. 配置 在vite.config.js文件中配置,配置完重启(n…...

idea中dataBase模板生成
controller.java.vm ##定义初始变量 #set($tableName $tool.append($tableInfo.name, "Controller")) ##设置回调 $!callback.setFileName($tool.append($tableName, ".java")) $!callback.setSavePath($tool.append($tableInfo.savePath, "/contro…...
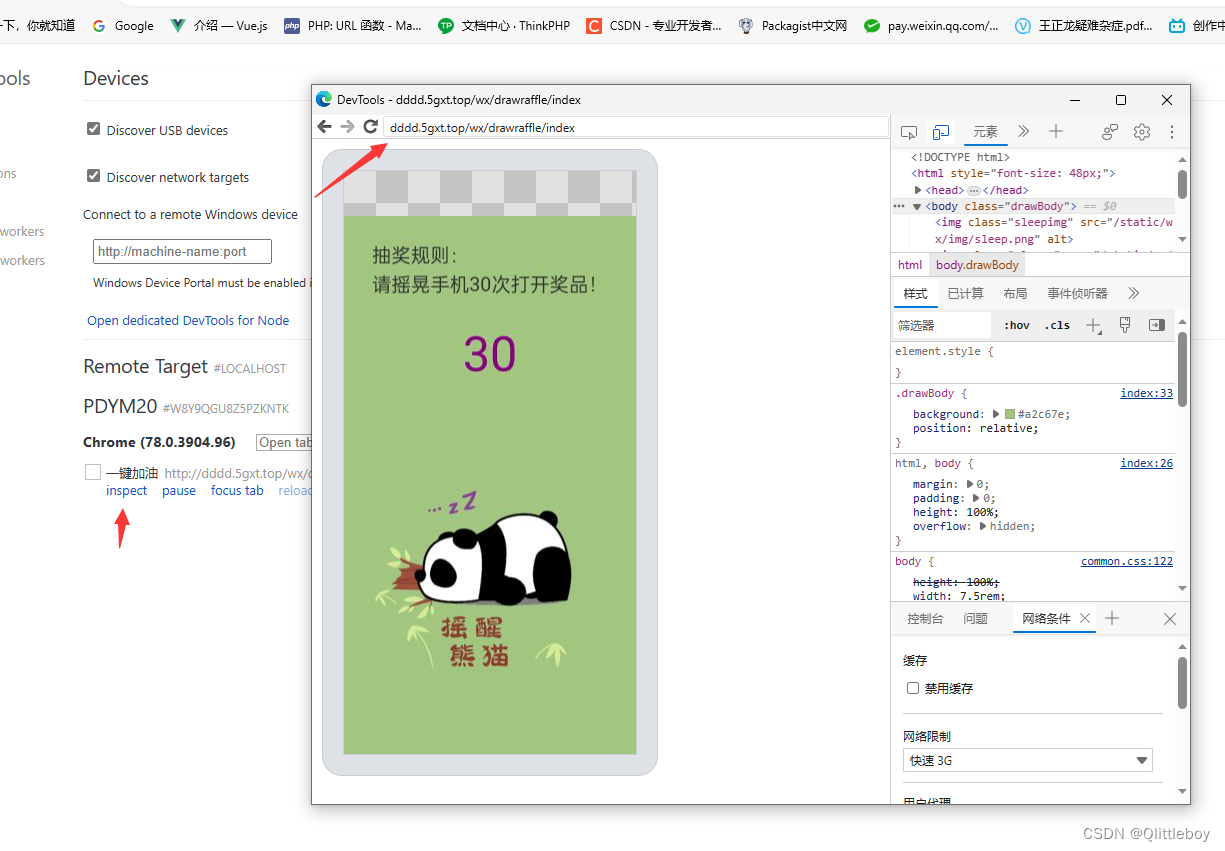
pc端测试手机浏览器运行情况,主要是测试硬件功能
测试h5震动摇晃等功能时不方便测试,需要连电脑显示调试数据 方法: 1.需要手机下载谷歌浏览器,pc端用edge或这谷歌浏览器 2.手机打开USB调试,打开要测试的网页 3.pc端地址栏输入edge://inspect/#devices(这里用的edge浏…...
)
软件概要设计-架构真题(二十五)
软件概要设计包括软件设计的结构、确定系统功能模块及其相互关系,主要采用()描述程序的结构。(2018年) 程序流程图、PAD图和伪代码模块结构图、数据流图和盒图模块结构图、层次图和HIPO图程序流程图、数据流图和层次图…...

CSDN发文表情包整理
文章目录 简介部分Emoji表情符号简表人物自然物品地点符号 各种Emoji表情链接 简介 CSDN支持Markdown语法及Emoji表情,使用各种Emoji表情可以使得自己的博文更加生动多彩。一般有两种在支持Markdown的语法环境中添加Emoji表情:1.直接将表情包复制到文档…...
springBoot对接Apache POI 实现excel下载和上传
搭建springboot项目 此处可以参考 搭建最简单的SpringBoot项目_Steven-Russell的博客-CSDN博客 配置Apache POI 依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.2</version> </…...
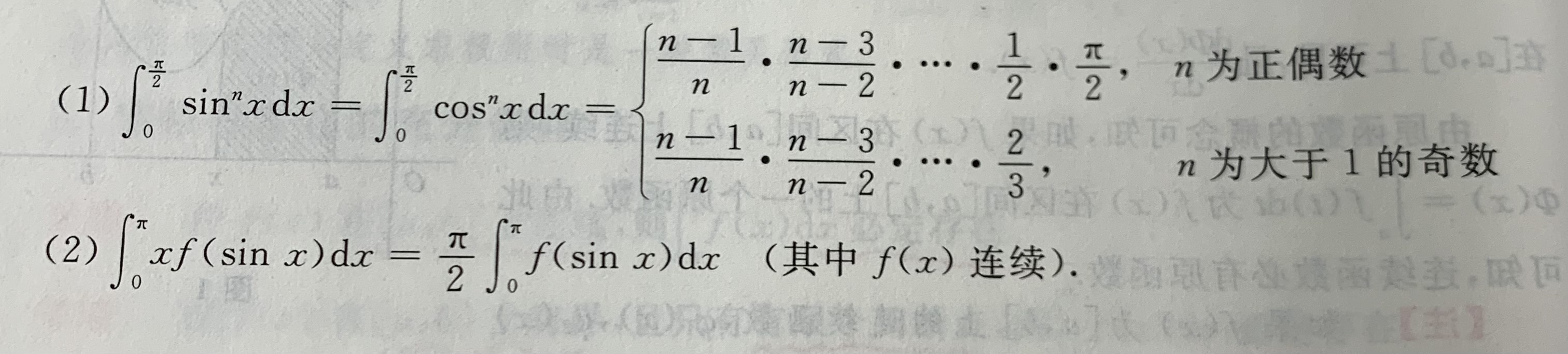
定积分的计算:牛顿-莱布尼茨公式
目录 牛顿-莱布尼茨公式 用C语言代码实现 利用换元积分法和分部积分法 利用奇偶性和周期性求积分 利用已有公式求积分 牛顿-莱布尼茨公式 牛顿-莱布尼茨公式(Newton-Leibniz formula)是微积分学中的基本定理之一,它反映了定积分与被积函…...

shell脚本之case 的用法
shell脚本之case case是Shell脚本中的一种控制流语句,它允许根据变量的值选择不同的执行路径。case语句的语法如下: case word in pattern [| pattern]...) command-list ;; pattern [| pattern]...) command-list ;; ... *) command-list ;; esa…...
)
第3章 helloworld 驱动实验(iTOP-RK3568开发板驱动开发指南 )
在学习C语言或者其他语言的时候,我们通常是打印一句“helloworld”来开启编程世界的大门。学习驱动程序编程亦可以如此,使用helloworld作为我们的第一个驱动程序。 接下来开始编写第一个驱动程序—helloworld。 3.1 驱动编写 本小节来编写一个最简单的…...
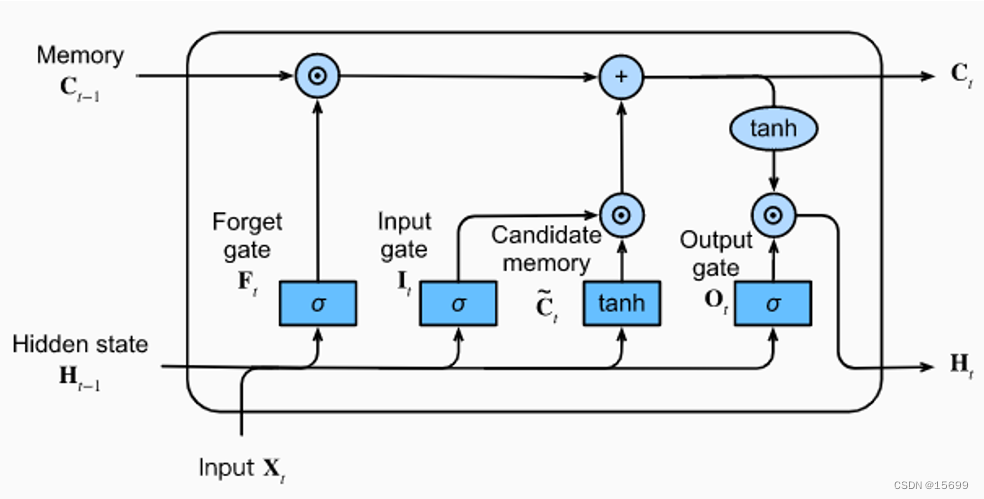
基于PyTorch使用LSTM实现新闻文本分类任务
本文参考 PyTorch深度学习项目实战100例 https://weibaohang.blog.csdn.net/article/details/127154284?spm1001.2014.3001.5501 文章目录 本文参考任务介绍做数据的导入 环境介绍导入必要的包介绍torchnet和keras做数据的导入给必要的参数命名加载文本数据数据前处理模型训…...

Flutter插件的制作和发布
Flutter制作插件有两种方式(以下以android和ios为例): 目录 1.直接在主工程下的android和ios项目内写插件代码:2.创建独立Flutter Plugin项目,制作各端插件后,再引入项目:1. 创建Flutter Plugin…...
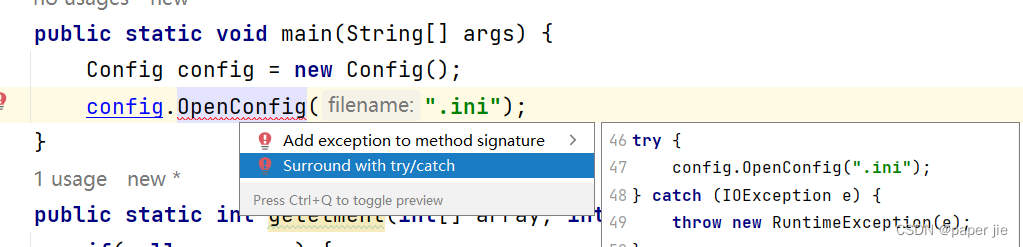
【JAVA】异常
作者主页:paper jie 的博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JAVASE语法系列》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和…...

合同矩阵充要条件
两个实对称矩阵合同的充要条件是它们的正负惯性指数相同。 正惯性指数是矩阵正特征值个数,负惯性指数是矩阵负特征值个数。 即合同矩阵的充分必要条件是特征值的正负号个数相同。 证明: 本论证中的所有矩阵都是对称矩阵。 根据定义,若矩…...
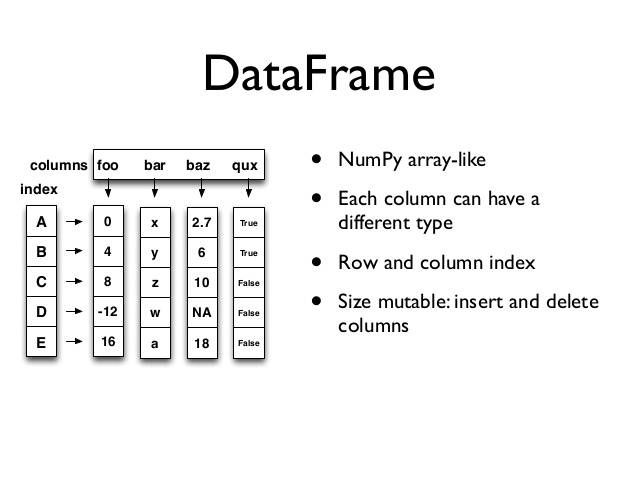
数据分析三剑客之Pandas
1.引入 前面一篇文章我们介绍了numpy,但numpy的特长并不是在于数据处理,而是在它能非常方便地实现科学计算,所以我们日常对数据进行处理时用的numpy情况并不是很多,我们需要处理的数据一般都是带有列标签和index索引的࿰…...

Spring Boot自动装配原理
简介 Spring Boot是一个开源的Java框架,旨在简化Spring应用程序的搭建和开发。它通过自动装配的机制,大大减少了繁琐的配置工作,提高了开发效率。本文将深入探讨Spring Boot的自动装配原理。 自动装配的概述 在传统的Spring框架中…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...
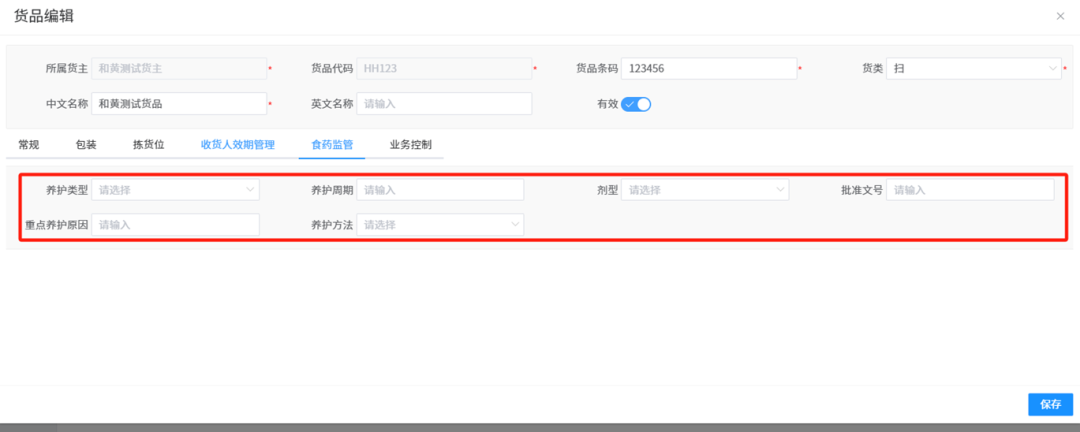
针对药品仓库的效期管理问题,如何利用WMS系统“破局”
案例: 某医药分销企业,主要经营各类药品的批发与零售。由于药品的特殊性,效期管理至关重要,但该企业一直面临效期问题的困扰。在未使用WMS系统之前,其药品入库、存储、出库等环节的效期管理主要依赖人工记录与检查。库…...
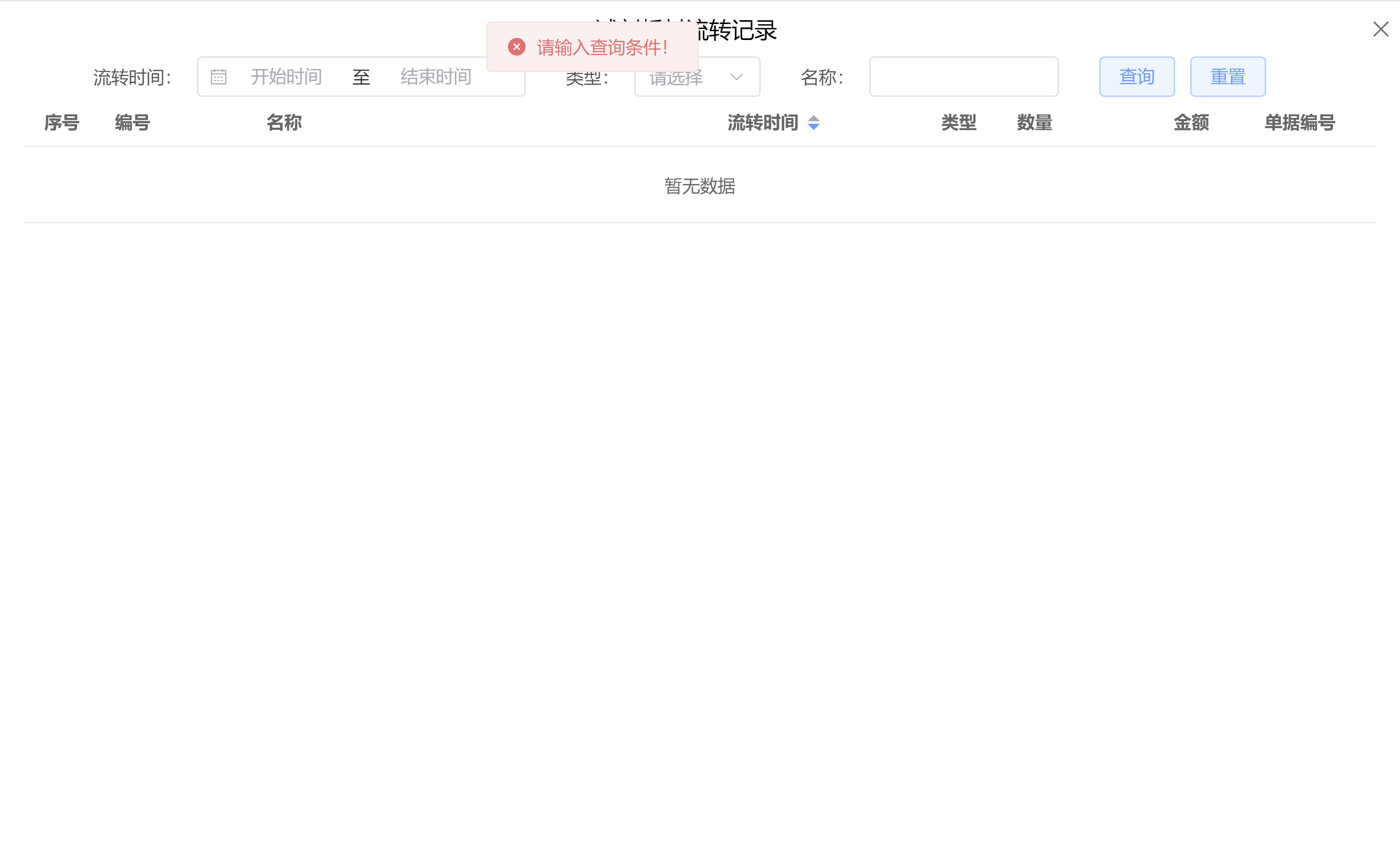
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...